生成AIをGoogle Colabで簡単に 【Part10 SDXL+ANIMAGINE +ControlNet+LoRA編(全部載せ)】
はじめに
今回は、初心者向けにGoogle Colaboratoryで、簡単に生成AIを使えるようにする環境を作ります。
Part10の今回は、画像生成AIの最後?かなと思います。
これまでに説明した内容で、可能な限り高品質なセットを試します。(全部のせです)
(本来であればSD3を利用するのが最高品質ではありますが、私の好きなアニメイラストの場合だと、SD3のベースモデルよりもSDXLにて特化Finetuningモデルの方が「まだ」現時点では高品質なのでこのセットを試します)
使う技術の概要に関しては
Stable Diffusion XL (SDXL)はpart6の記事
ANIMAGINE XL 3.1 はPart6.5の記事
ControlNetはpart9の記事をご覧ください。
(それ以外の記事に関しては、本記事を読む上では読む必要はありません。また、上記の記事を読まなくても、本記事の内容は理解できるように記事を記載します)
LoRAに関しては下記に簡単に記載します。
LoRAとは
LoRA(Low-Rank Adaptation)とは、少ない学習リソースで、モデルに対して高品質なカスタマイズができる技術です。
LoRAとはモデルのFine Tuningの技術です。
今回の記事でも利用している「ANIMAGINE XL 3.1」に関してもFine Tuningによって生まれたモデルでありますが、こちらはFull parameter tuningと呼ばれるもので、モデル内のすべての重みを学習可能な状態にして、大量の画像(キャプション付き)と大規模な学習リソースの元、学習を行なったモデルになります。
一方でLoRAというのは、モデルの重み自体を学習するのではなく、モデルの重みに、少量の学習可能モジュールを並列で接続し、本モデルの重みを固定した状態で、追加で接続したモジュールの重みだけを学習可能にして少量の画像で学習した重みになります。
こうすることで、例えば特定のキャラクターを追加したり、漫画のスタイルやアニメのスタイルなどに画風を変換するなどといった、元のモデルに付け加えるような機能を持つことができます。
また、元のモデルに付け加えるもののため、デフォルトのSDXLのベースモデルに対してのみではなく、「ANIMAGINE XL 3.1」といった、別のFine Tuningモデルにも利用できるといった、自由度の高いモデルになります。
LoRAに関しては、さまざまなものが既に作成されています。今回の記事では私が直感的に気に入ったLoRAを一つだけ試しますが、その他のLoRAも利用可能です。
今回利用したモデルは下記です。
もちろん、モデルとの相性もあるので、効果の出にくいLoRAモデルがあることもあります。そのあたりは試行錯誤して試してください。
成果物
下記のリポジトリをご覧ください。
今回の実験
下記に実施した実験の内容を記載します。実験結果については最後にご紹介しています。
-
実験1
- LoRAなし、ControlNetなしでの実験
-
実験2
- LoRAなし
- 各種、ControlNetでの実験
- OpenPose
- OpenPose Face
- OpenPose Face only
- OpenPose Full
- Canny
- Depth
- Zoe Depth
- Tile
-
実験3
- LoRAの導入
- ControlNetなしでの実験
-
実験4
- LoRAの導入
- ControlNet Zoe Depthありでの実験
事前準備
利用するLoRAモデルを保存する
今回は下記のLoRAモデルを利用します。
利用するモデルは好きなものを探して選んでください。
重要なのは2つです。
一つは、このモデルをダウンロードして、後述するフォルダの「inputs」フォルダに格納すること
もう一つは、このLoRAモデルの「Trigger Words」をプロンプトに追加することです。
両方とも、上記のページから取得することができます。
ダウンロードは上記のページの下記ボタンから

「Trigger Words」は上記のページの下記部分の、コピーボタンからコピーしてください。
文字的には大文字で書かれていますが、実際コピーすると「Dreamyvibes Artstyle」のようになりますので、こちらを利用してください。

参照画像をダウンロードする
コントロールネットの入力に利用する画像を取得し、後述するフォルダの「inputs」フォルダに格納してください。
記事で使っている画像をそのまま利用したい場合は、記事の画像を保存して「refer.webp」と名前をつけて、後述するフォルダの「inputs」フォルダに格納してください。
解説
下記の通り、解説を行います。
まずは上記のリポジトリをcloneしてください。
git clone https://github.com/personabb/colab_AI_sample.git
その後、cloneしたフォルダ「colab_AI_sample」をマイドライブの適当な場所においてください。
ディレクトリ構造
Google Driveのディレクトリ構造は下記を想定します。
MyDrive/
└ colab_AI_sample/
└ colab_SDXLControlNet_sample/
├ configs/
| └ config.ini
├ inputs/
| | refer.webp
| └ DreamyvibesartstyleSDXL.safetensors
├ outputs/
├ module/
| └ module_sd3c.py
└ SDXLControlNet_sample.ipynb
-
colab_AI_sampleフォルダは適当です。なんでも良いです。1階層である必要はなく下記のように複数階層になっていても良いです。MyDrive/hogehoge/spamspam/hogespam/colab_AI_sample
-
outputsフォルダには、生成後の画像が格納されます。最初は空です。- 連続して生成を行う場合、過去の生成内容を上書きするため、ダウンロードするか、名前を変えておくことをオススメします。
-
inputsフォルダには、ControlNetで利用する参照画像を格納しています。詳細は後述します。- 加えて、先ほどダウンロードしたLoRAモデルも格納します
- 名前に空白が入っているのが気持ち悪かったのでリネームしています。
- 加えて、先ほどダウンロードしたLoRAモデルも格納します
使い方解説
SDXLControlNet_sample.ipynbをGoogle Colabratoryアプリで開いてください。
ファイルを右クリックすると「アプリで開く」という項目が表示されるため、そこからGoogle Colabratoryアプリを選択してください。
もし、ない場合は、「アプリを追加」からアプリストアに行き、「Google Colabratory」で検索してインストールをしてください。
Google Colabratoryアプリで開いたら、SDXLControlNet_sample.ipynbのメモを参考にして、一番上のセルから順番に実行していけば、問題なく最後まで動作して、画像生成をすることができると思います。
また、最後まで実行後、パラメータを変更して再度実行する場合は、「ランタイム」→「セッションを再起動して全て実行する」をクリックしてください。
コード解説
主に、重要なSDXLControlNet_sample.ipynbとmodule/module_sdc.pyについて解説します。
SDXLControlNet_sample.ipynb
該当のコードは下記になります。
下記に1セルずつ解説します。
1セル目
#SDXL で必要なモジュールのインストール
!pip install -U peft tensorflow-metadata diffusers transformers scikit-learn ftfy accelerate invisible_watermark safetensors controlnet-aux mediapipe timm
ここでは、必要なモジュールをインストールしています。
Google colabではpytorchなどの基本的な深層学習パッケージなどは、すでにインストール済みなため上記だけインストールすれば問題ありません。
(過去のインストールコマンドを使い回しているので、いらないモジュールが紛れ込んでいる可能性大です・・・。 tensorflow-metadataは入れないとバージョンのエラーが発生するので入れています)
2セル目
#Google Driveのフォルダをマウント(認証入る)
from google.colab import drive
drive.mount('/content/drive')
# カレントディレクトリを本ファイルが存在するディレクトリに変更する。
import glob
import os
pwd = os.path.dirname(glob.glob('/content/drive/MyDrive/colabzenn/**/colab_SDXLControlNet_sample/SDXLControlNet_sample.ipynb', recursive=True)[0])
print(pwd)
%cd $pwd
!pwd
ここでは、Googleドライブの中身をマウントしています。
マウントすることで、Googleドライブの中に入っているファイルを読み込んだり、書き込んだりすることが可能になります。
マウントをする際は、Colabから、マウントの許可を行う必要があります。
ポップアップが表示されるため、指示に従い、マウントの許可を行なってください。
また、続けて、カレントディレクトリを/から/content/drive/MyDrive/**/colab_SDXLControlNet_sampleに変更しています。
(**はワイルドカードです。任意のディレクトリ(複数)が入ります)
カレントディレクトリは必ずしも変更する必要はないですが、カレントディレクトリを変更することで、これ以降のフォルダ指定が楽になります
3セル目
#モジュールをimportする
from module.module_sdc import SDXLC
import time
module/module_sdc.pyのSDXLCクラスをモジュールとしてインポートします。
この中身の詳細は後の章で解説します。
また、実行時間の計測のためtimeモジュールも読み込んでいます。
4セル目
#モデルの設定を行う。
#sdxlのモデルはvariant = "fp16"で読み込んでいるため、モデルのsafetensor名にfp16と入ってるモデルを利用してください。
config_text = """
[SDXLC]
device = auto
n_steps=28
high_noise_frac=None
seed=42
vae_model_path = None
base_model_path = Asahina2K/Animagine-xl-3.1-diffuser-variant-fp16
refiner_model_path = None
;controlnet_path = xinsir/controlnet-openpose-sdxl-1.0
;controlnet_path = diffusers/controlnet-canny-sdxl-1.0
controlnet_path = diffusers/controlnet-depth-sdxl-1.0
;controlnet_path = diffusers/controlnet-zoe-depth-sdxl-1.0
;controlnet_path = xinsir/controlnet-tile-sdxl-1.0
;control_mode = openpose
;control_mode = openpose_face
;control_mode = openpose_faceonly
;control_mode = openpose_full
;control_mode = canny
control_mode = depth
;control_mode = zoe_depth
;control_mode = tile
lora_weight_path = ./inputs/DreamyvibesartstyleSDXL.safetensors
lora_scale = 1.0
use_karras_sigmas = True
scheduler_algorithm_type = dpmsolver++
solver_order = 2
cfg_scale = 7.0
width = 832
height = 1216
output_type = pil
aesthetic_score = 6
negative_aesthetic_score = 2.5
save_latent_simple = False
save_latent_overstep = False
save_latent_approximation = False
"""
with open("configs/config.ini", "w", encoding="utf-8") as f:
f.write(config_text)
ここでは設定を行なっています。「;」を最初につけることでコメントアウトできることを利用して、よく利用するControlNetのモデルなども一緒に記載しています。
なお、今回は「Animagine-xl-3.1」モデルを利用していますが、そのほかの例えばSDXLのベースモデルを利用しても問題なく動作することを確認しています。
一つ一つの説明などは、過去の記事を参照してください。
過去に説明していないのは、lora_weight_pathとlora_scaleかなと思います。
lora_weight_pathはinputsフォルダに格納したモデルのPATHを指定してください。他のLoRAモデルをダウンロードして利用することもできます。
lora_scaleは出力にどの程度LoRAのパラメータが影響を与えるかを制御するパラメータなのですが、詳しい仕組みはあまりよくわかっていません。(詳しい方いたら教えてください)
おそらく下記の箇所にて制御されています。
(興味のある方だけ展開してください)
lora_scale
まず、lora_scaleは、StableDiffusionXLPipelineのcross_attention_kwargsに入力され、それはself.unetで利用されます。
class StableDiffusionXLPipeline(
・・・
def __call__(
・・・
noise_pred = self.unet(
latent_model_input,
t,
encoder_hidden_states=prompt_embeds,
timestep_cond=timestep_cond,
cross_attention_kwargs=self.cross_attention_kwargs,
added_cond_kwargs=added_cond_kwargs,
return_dict=False,
)[0]
・・・
ここで。self.unetはデフォルトでUNet2DConditionModelを利用しています。
その上で、UNet2DConditionModelクラスのforwardメソッドにて下記のように使われています。
class UNet2DConditionModel(
・・・
def forward(
・・・
if cross_attention_kwargs is not None:
cross_attention_kwargs = cross_attention_kwargs.copy()
lora_scale = cross_attention_kwargs.pop("scale", 1.0)
else:
lora_scale = 1.0
if USE_PEFT_BACKEND:
# weight the lora layers by setting `lora_scale` for each PEFT layer
scale_lora_layers(self, lora_scale)
・・・
上記では、cross_attention_kwargsの中のscaleキーを取得します。
pipelineをcallする際には下記のように利用するため、このscaleの中に、lora_scaleの値が入ります。
cross_attention_kwargs={"scale": self.lora_scale},
そして、得られた値はscale_lora_layers関数にて利用されます。この関数は下記にて定義されます。
def scale_lora_layers(model, weight):
"""
Adjust the weightage given to the LoRA layers of the model.
Args:
model (`torch.nn.Module`):
The model to scale.
weight (`float`):
The weight to be given to the LoRA layers.
"""
from peft.tuners.tuners_utils import BaseTunerLayer
if weight == 1.0:
return
for module in model.modules():
if isinstance(module, BaseTunerLayer):
module.scale_layer(weight)
これを見ると、モデルの中のBaseTunerLayerのクラスインスタンスであるmoduleに対して、scale_layerメソッドを実行しています。
このscale_layerメソッドは下記にて定義されます。
class LoraLayer(BaseTunerLayer):
・・・
def scale_layer(self, scale_factor: float) -> None:
if scale_factor != 1:
for active_adapter in self.active_adapters:
if active_adapter not in self.lora_A.keys():
continue
alpha = self.lora_alpha[active_adapter]
r = self.r[active_adapter]
self.scaling[active_adapter] = (alpha / r) * scale_factor
これ以降はまだ、追えていませんが、peft/src/peft/tuners/lora/layer.pyの下部に、畳み込み層と全結合層の使用例が記載されており、それを見ると、LoRAを通した結果をself.scaling[active_adapter]倍して元の処理に追加する形になっていそうです。つまりlora_scaleが1.0の場合は、元のモデルの出力とLoRAモジュールの出力が1対1の重みで足し算されるイメージかなと思います。
scaling = self.scaling[active_adapter]
result += lora_B(lora_A(dropout(x))) * scaling
5セル目
#読み上げるプロンプトを設定する。
main_prompt = """
1 girl ,Yellowish-white hair ,short hair ,red small ribbon,red eyes,red hat ,school uniform ,solo ,smile ,upper body ,Anime ,Japanese,best quality,high quality,ultra highres,ultra quality
"""
use_lora = False
if use_lora:
main_prompt += ", Dreamyvibes Artstyle"
negative_prompt="""
nsfw, lowres, (bad), text, error, fewer, extra, missing, worst quality, jpeg artifacts, low quality, watermark, unfinished, displeasing, oldest, early, chromatic aberration, signature, extra digits, artistic error, username, scan, [abstract]
"""
input_refer_image_path = "./inputs/refer.webp"
output_refer_image_path = "./inputs/refer.png"
ここでは生成されるpromptを指定しています。
使うプロンプトはPart6.5のものをそのまま流用しています
また、LoRAを利用する場合と利用しない場合でトリガーワードを追加するかどうかが変わるため、それを考慮して実装していますが、正直普通にプロンプトに追加するでも良いです。
加えて参照画像のpathをinput_refer_image_pathで指定しています。
controlNetを利用する際に、OpenPoseの骨格や、線画を用意する必要がありますが、普通のユーザはそんなの持っていないと思いますので、ここでは普通の画像を指定すると、output_refer_image_pathに指定したpathにOpenPoseの骨格や、線画など、今回の実行で利用する参照画像を、普通の画像から生成して保存するようにしています。
すなわち、以下のような画像を入力することで、自動的にOpenPoseの骨格や、線画に変換してControlNetにて利用できます。(画像はSD3 Mediumで作成しました)
参照画像

OpenPose Full

線画

深度マップ

上記の画像を見てもわかるように、参照画像に対して、リサイズが行われます。
このリサイズはは4セル目に設定している解像度に対して行われます。
元々の参照画像の解像度が1024x1024で、ControlNetに入力する画像が832x1216です。
6セル目
sd = SDXLC()
sd.prepare_referimage(input_refer_image_path = input_refer_image_path, output_refer_image_path = output_refer_image_path, low_threshold = 100, high_threshold = 200)
ここで、SDXLCクラスのインスタンスを作成します。
その上で、上記5セル目の説明でもしたように、通常の参照画像から、OpenPoseの骨格や、線画の画像に変換するprepare_referimageメソッドを実行しています。
こちらを実行するとoutput_refer_image_path = "./inputs/refer.png"のpathにControlNetに入力される画像が保存されます。
low_threshold = 100, high_threshold = 200の値は、線画用に画像からcanny edgeを取得する際の閾値になります。特に変更しなくても多くの画像でそこそこ良い結果になります。
7セル目
for i in range(3):
start = time.time()
image = sd.generate_image(main_prompt, neg_prompt = negative_prompt,image_path = output_refer_image_path, controlnet_conditioning_scale = 0.5)
print("generate image time: ", time.time()-start)
image.save("./outputs/SDXLC_result_{}.png".format(i))
ここではSDXL+ControlNetで画像を生成します。
3回for文を回すことで、3枚の画像を生成し、outputsフォルダに保存します。
また、1枚生成するのにかかる時間を計測して表示しています。
実行結果(生成される画像)などは、のちの実験結果の章で提示します。
画像はoutputsフォルダに保存されますが、実行のたびに同じ名前で保存されるので、過去に保存した画像は上書きされるようになりますので注意してください。
(seed値という乱数表の値を変更しない限り、実行のたびに必ず同じ画像が生成されます。seedは設定ファイル(4セル目)で変更できます。)
また、引数のcontrolnet_conditioning_scale = 0.5の値を変更することで、どの程度、参照画像が生成される画像に影響を与えるかを指定できます。
1.0はMAXの値で、0が最小の値です。0を指定すると全く参照画像の影響がなくなり、プロンプトのみによって生成されます。1.0の場合は、参照画像の影響が強くなります。
いい感じにプロンプトも反映させたい場合は、0.5-0.7付近で設定することをおすすめします。
module/module_sdc.py
続いて、SDXLControlNet_sample.ipynbから読み込まれるモジュールの中身を説明します。
下記にコード全文を示します。
コード全文
from diffusers import DiffusionPipeline, AutoencoderKL, StableDiffusionXLControlNetPipeline, ControlNetModel
from diffusers.utils import load_image
from diffusers.pipelines.stable_diffusion_xl.pipeline_output import StableDiffusionXLPipelineOutput
import torch
from diffusers.schedulers import DPMSolverMultistepScheduler
from controlnet_aux.processor import Processor
import os
import configparser
# ファイルの存在チェック用モジュール
import errno
import cv2
from PIL import Image
import time
import numpy as np
class SDXLCconfig:
def __init__(self, config_ini_path = './configs/config.ini'):
# iniファイルの読み込み
self.config_ini = configparser.ConfigParser()
# 指定したiniファイルが存在しない場合、エラー発生
if not os.path.exists(config_ini_path):
raise FileNotFoundError(errno.ENOENT, os.strerror(errno.ENOENT), config_ini_path)
self.config_ini.read(config_ini_path, encoding='utf-8')
SDXLC_items = self.config_ini.items('SDXLC')
self.SDXLC_config_dict = dict(SDXLC_items)
class SDXLC:
def __init__(self,device = None, config_ini_path = './configs/config.ini'):
SDXLC_config = SDXLCconfig(config_ini_path = config_ini_path)
config_dict = SDXLC_config.SDXLC_config_dict
if device is not None:
self.device = device
else:
device = config_dict["device"]
self.device = "cuda" if torch.cuda.is_available() else "cpu"
if device != "auto":
self.device = device
self.last_latents = None
self.last_step = -1
self.last_timestep = 1000
self.n_steps = int(config_dict["n_steps"])
if not config_dict["high_noise_frac"] == "None":
self.high_noise_frac = float(config_dict["high_noise_frac"])
else:
self.high_noise_frac = None
self.seed = int(config_dict["seed"])
self.generator = torch.Generator(device=self.device).manual_seed(self.seed)
self.controlnet_path = config_dict["controlnet_path"]
self.control_mode = config_dict["control_mode"]
if self.control_mode == "None":
self.control_mode = None
self.vae_model_path = config_dict["vae_model_path"]
self.VAE_FLAG = True
if self.vae_model_path == "None":
self.vae_model_path = None
self.VAE_FLAG = False
self.base_model_path = config_dict["base_model_path"]
self.REFINER_FLAG = True
self.refiner_model_path = config_dict["refiner_model_path"]
if self.refiner_model_path == "None":
self.refiner_model_path = None
self.REFINER_FLAG = False
self.LORA_FLAG = True
self.lora_weight_path = config_dict["lora_weight_path"]
if self.lora_weight_path == "None":
self.lora_weight_path = None
self.LORA_FLAG = False
self.lora_scale = float(config_dict["lora_scale"])
self.use_karras_sigmas = config_dict["use_karras_sigmas"]
if self.use_karras_sigmas == "True":
self.use_karras_sigmas = True
else:
self.use_karras_sigmas = False
self.scheduler_algorithm_type = config_dict["scheduler_algorithm_type"]
if config_dict["solver_order"] != "None":
self.solver_order = int(config_dict["solver_order"])
else:
self.solver_order = None
self.cfg_scale = float(config_dict["cfg_scale"])
self.width = int(config_dict["width"])
self.height = int(config_dict["height"])
self.output_type = config_dict["output_type"]
self.aesthetic_score = float(config_dict["aesthetic_score"])
self.negative_aesthetic_score = float(config_dict["negative_aesthetic_score"])
self.save_latent_simple = config_dict["save_latent_simple"]
if self.save_latent_simple == "True":
self.save_latent_simple = True
print("use vallback save_latent_simple")
else:
self.save_latent_simple = False
self.save_latent_overstep = config_dict["save_latent_overstep"]
if self.save_latent_overstep == "True":
self.save_latent_overstep = True
print("use vallback save_latent_overstep")
else:
self.save_latent_overstep = False
self.save_latent_approximation = config_dict["save_latent_approximation"]
if self.save_latent_approximation == "True":
self.save_latent_approximation = True
print("use vallback save_latent_approximation")
else:
self.save_latent_approximation = False
self.use_callback = False
if self.save_latent_simple or self.save_latent_overstep or self.save_latent_approximation:
self.use_callback = True
if self.save_latent_simple and self.save_latent_overstep:
raise ValueError("save_latent_simple and save_latent_overstep cannot be set at the same time")
self.base , self.refiner = self.preprepare_model()
def preprepare_model(self):
controlnet = ControlNetModel.from_pretrained(
self.controlnet_path,
use_safetensors=True,
torch_dtype=torch.float16)
if self.VAE_FLAG:
vae = AutoencoderKL.from_pretrained(
self.vae_model_path,
torch_dtype=torch.float16)
base = StableDiffusionXLControlNetPipeline.from_pretrained(
self.base_model_path,
controlnet=controlnet,
vae=vae,
torch_dtype=torch.float16,
variant="fp16",
use_safetensors=True
)
base.to(self.device)
if self.REFINER_FLAG:
refiner = DiffusionPipeline.from_pretrained(
self.refiner_model_path,
text_encoder_2=base.text_encoder_2,
vae=vae,
requires_aesthetics_score=True,
torch_dtype=torch.float16,
variant="fp16",
use_safetensors=True
)
refiner.enable_model_cpu_offload()
else:
refiner = None
else:
base = StableDiffusionXLControlNetPipeline.from_pretrained(
self.base_model_path,
controlnet=controlnet,
torch_dtype=torch.float16,
variant="fp16",
use_safetensors=True
)
base.to(self.device, torch.float16)
if self.REFINER_FLAG:
refiner = DiffusionPipeline.from_pretrained(
self.refiner_model_path,
text_encoder_2=base.text_encoder_2,
requires_aesthetics_score=True,
torch_dtype=torch.float16,
variant="fp16",
use_safetensors=True
)
refiner.enable_model_cpu_offload()
else:
refiner = None
if self.LORA_FLAG:
base.load_lora_weights(self.lora_weight_path)
if self.solver_order is not None:
base.scheduler = DPMSolverMultistepScheduler.from_config(
base.scheduler.config,
use_karras_sigmas=self.use_karras_sigmas,
Algorithm_type =self.scheduler_algorithm_type,
solver_order=self.solver_order,
)
return base, refiner
else:
base.scheduler = DPMSolverMultistepScheduler.from_config(
base.scheduler.config,
use_karras_sigmas=self.use_karras_sigmas,
Algorithm_type =self.scheduler_algorithm_type,
)
return base, refiner
def prepare_referimage(self,input_refer_image_path,output_refer_image_path, low_threshold = 100, high_threshold = 200):
mode = None
if self.control_mode is not None:
mode = self.control_mode
else:
raise ValueError("control_mode is not set")
def prepare_openpose(input_refer_image_path,output_refer_image_path, mode):
# 初期画像の準備
init_image = load_image(input_refer_image_path)
init_image = init_image.resize((self.width, self.height))
processor = Processor(mode)
processed_image = processor(init_image, to_pil=True)
processed_image.save(output_refer_image_path)
def prepare_canny(input_refer_image_path,output_refer_image_path, low_threshold = 100, high_threshold = 200):
init_image = load_image(input_refer_image_path)
init_image = init_image.resize((self.width, self.height))
# コントロールイメージを作成するメソッド
def make_canny_condition(image, low_threshold = 100, high_threshold = 200):
image = np.array(image)
image = cv2.Canny(image, low_threshold, high_threshold)
image = image[:, :, None]
image = np.concatenate([image, image, image], axis=2)
return Image.fromarray(image)
control_image = make_canny_condition(init_image, low_threshold, high_threshold)
control_image.save(output_refer_image_path)
def prepare_depthmap(input_refer_image_path,output_refer_image_path):
# 初期画像の準備
init_image = load_image(input_refer_image_path)
init_image = init_image.resize((self.width, self.height))
processor = Processor("depth_midas")
depth_image = processor(init_image, to_pil=True)
depth_image.save(output_refer_image_path)
def prepare_zoe_depthmap(input_refer_image_path,output_refer_image_path):
torch.hub.help(
"intel-isl/MiDaS",
"DPT_BEiT_L_384",
force_reload=True
)
model_zoe_n = torch.hub.load(
"isl-org/ZoeDepth",
"ZoeD_NK",
pretrained=True
).to("cuda")
init_image = load_image(input_refer_image_path)
init_image = init_image.resize((self.width, self.height))
depth_numpy = model_zoe_n.infer_pil(init_image) # return: numpy.ndarray
from zoedepth.utils.misc import colorize
colored = colorize(depth_numpy) # numpy.ndarray => numpy.ndarray
# gamma correction
img = colored / 255
img = np.power(img, 2.2)
img = (img * 255).astype(np.uint8)
Image.fromarray(img).save(output_refer_image_path)
if "openpose" in mode:
prepare_openpose(input_refer_image_path,output_refer_image_path, mode)
elif mode == "canny":
prepare_canny(input_refer_image_path,output_refer_image_path, low_threshold = low_threshold, high_threshold = high_threshold)
elif mode == "depth":
prepare_depthmap(input_refer_image_path,output_refer_image_path)
elif mode == "zoe_depth":
prepare_zoe_depthmap(input_refer_image_path,output_refer_image_path)
elif mode == "tile" or mode == "scribble":
init_image = load_image(input_refer_image_path)
init_image.save(output_refer_image_path)
else:
raise ValueError("control_mode is not set")
def generate_image(self, prompt, neg_prompt, image_path, seed = None, controlnet_conditioning_scale = 1.0):
def decode_tensors(pipe, step, timestep, callback_kwargs):
if self.save_latent_simple:
callback_kwargs = decode_tensors_simple(pipe, step, timestep, callback_kwargs)
elif self.save_latent_overstep:
callback_kwargs = decode_tensors_residual(pipe, step, timestep, callback_kwargs)
else:
raise ValueError("save_latent_simple or save_latent_overstep must be set or 'save_latent_approximation = False'")
return callback_kwargs
def decode_tensors_simple(pipe, step, timestep, callback_kwargs):
latents = callback_kwargs["latents"]
imege = None
if self.save_latent_simple and not self.save_latent_approximation:
image = latents_to_rgb_vae(latents,pipe)
elif self.save_latent_approximation:
image = latents_to_rgb_approximation(latents,pipe)
else:
raise ValueError("save_latent_simple or save_latent_approximation is not set")
gettime = time.time()
formatted_time_human_readable = time.strftime("%Y%m%d_%H%M%S", time.localtime(gettime))
image.save(f"./outputs/latent_{formatted_time_human_readable}_{step}_{timestep}.png")
return callback_kwargs
def decode_tensors_residual(pipe, step, timestep, callback_kwargs):
latents = callback_kwargs["latents"]
if step > 0:
residual = latents - self.last_latents
goal = self.last_latents + residual * ((self.last_timestep) / (self.last_timestep - timestep))
#print( ((self.last_timestep) / (self.last_timestep - timestep)))
else:
goal = latents
if self.save_latent_overstep and not self.save_latent_approximation:
image = latents_to_rgb_vae(goal,pipe)
elif self.save_latent_approximation:
image = latents_to_rgb_approximation(goal,pipe)
else:
raise ValueError("save_latent_simple or save_latent_approximation is not set")
gettime = time.time()
formatted_time_human_readable = time.strftime("%Y%m%d_%H%M%S", time.localtime(gettime))
image.save(f"./outputs/latent_{formatted_time_human_readable}_{step}_{timestep}.png")
self.last_latents = latents
self.last_step = step
self.last_timestep = timestep
if timestep == 0:
self.last_latents = None
self.last_step = -1
self.last_timestep = 100
return callback_kwargs
def latents_to_rgb_vae(latents,pipe):
pipe.upcast_vae()
latents = latents.to(next(iter(pipe.vae.post_quant_conv.parameters())).dtype)
images = pipe.vae.decode(latents / pipe.vae.config.scaling_factor, return_dict=False)[0]
images = pipe.image_processor.postprocess(images, output_type='pil')
pipe.vae.to(dtype=torch.float16)
return StableDiffusionXLPipelineOutput(images=images).images[0]
def latents_to_rgb_approximation(latents, pipe):
weights = (
(60, -60, 25, -70),
(60, -5, 15, -50),
(60, 10, -5, -35)
)
weights_tensor = torch.t(torch.tensor(weights, dtype=latents.dtype).to(latents.device))
biases_tensor = torch.tensor((150, 140, 130), dtype=latents.dtype).to(latents.device)
rgb_tensor = torch.einsum("...lxy,lr -> ...rxy", latents, weights_tensor) + biases_tensor.unsqueeze(-1).unsqueeze(-1)
image_array = rgb_tensor.clamp(0, 255)[0].byte().cpu().numpy()
image_array = image_array.transpose(1, 2, 0) # Change the order of dimensions
return Image.fromarray(image_array)
if seed is not None:
self.generator = torch.Generator(device=self.device).manual_seed(seed)
control_image = load_image(image_path)
image = None
if self.use_callback:
if self.LORA_FLAG:
if self.REFINER_FLAG:
image = self.base(
prompt=prompt,
negative_prompt=neg_prompt,
image=control_image,
cfg_scale=self.cfg_scale,
controlnet_conditioning_scale=controlnet_conditioning_scale,
num_inference_steps=self.n_steps,
denoising_end=self.high_noise_frac,
output_type="latent",
width = self.width,
height = self.height,
generator=self.generator,
cross_attention_kwargs={"scale": self.lora_scale},
callback_on_step_end=decode_tensors,
callback_on_step_end_tensor_inputs=["latents"],
).images[0]
image = self.refiner(
prompt=prompt,
negative_prompt=neg_prompt,
cfg_scale=self.cfg_scale,
aesthetic_score = self.aesthetic_score,
negative_aesthetic_score = self.negative_aesthetic_score,
num_inference_steps=self.n_steps,
denoising_start=self.high_noise_frac,
callback_on_step_end=decode_tensors,
callback_on_step_end_tensor_inputs=["latents"],
image=image[None, :]
).images[0]
#refiner を利用しない場合
else:
image = self.base(
prompt=prompt,
negative_prompt=neg_prompt,
image=control_image,
cfg_scale=self.cfg_scale,
controlnet_conditioning_scale=controlnet_conditioning_scale,
num_inference_steps=self.n_steps,
denoising_end=self.high_noise_frac,
output_type=self.output_type,
width = self.width,
height = self.height,
generator=self.generator,
callback_on_step_end=decode_tensors,
callback_on_step_end_tensor_inputs=["latents"],
cross_attention_kwargs={"scale": self.lora_scale},
).images[0]
#LORAを利用しない場合
else:
if self.REFINER_FLAG:
image = self.base(
prompt=prompt,
negative_prompt=neg_prompt,
image=control_image,
cfg_scale=self.cfg_scale,
controlnet_conditioning_scale=controlnet_conditioning_scale,
num_inference_steps=self.n_steps,
denoising_end=self.high_noise_frac,
output_type="latent",
width = self.width,
height = self.height,
callback_on_step_end=decode_tensors,
callback_on_step_end_tensor_inputs=["latents"],
generator=self.generator
).images[0]
image = self.refiner(
prompt=prompt,
negative_prompt=neg_prompt,
cfg_scale=self.cfg_scale,
aesthetic_score = self.aesthetic_score,
negative_aesthetic_score = self.negative_aesthetic_score,
num_inference_steps=self.n_steps,
denoising_start=self.high_noise_frac,
callback_on_step_end=decode_tensors,
callback_on_step_end_tensor_inputs=["latents"],
image=image[None, :]
).images[0]
#refiner を利用しない場合
else:
image = self.base(
prompt=prompt,
negative_prompt=neg_prompt,
image=control_image,
cfg_scale=self.cfg_scale,
controlnet_conditioning_scale=controlnet_conditioning_scale,
num_inference_steps=self.n_steps,
denoising_end=self.high_noise_frac,
output_type=self.output_type,
width = self.width,
height = self.height,
callback_on_step_end=decode_tensors,
callback_on_step_end_tensor_inputs=["latents"],
generator=self.generator
).images[0]
#latentを保存しない場合
else:
if self.LORA_FLAG:
if self.REFINER_FLAG:
image = self.base(
prompt=prompt,
negative_prompt=neg_prompt,
image=control_image,
cfg_scale=self.cfg_scale,
controlnet_conditioning_scale=controlnet_conditioning_scale,
num_inference_steps=self.n_steps,
denoising_end=self.high_noise_frac,
output_type="latent",
width = self.width,
height = self.height,
generator=self.generator,
cross_attention_kwargs={"scale": self.lora_scale},
).images[0]
image = self.refiner(
prompt=prompt,
negative_prompt=neg_prompt,
cfg_scale=self.cfg_scale,
aesthetic_score = self.aesthetic_score,
negative_aesthetic_score = self.negative_aesthetic_score,
num_inference_steps=self.n_steps,
denoising_start=self.high_noise_frac,
image=image[None, :]
).images[0]
# refiner を利用しない場合
else:
image = self.base(
prompt=prompt,
negative_prompt=neg_prompt,
image=control_image,
cfg_scale=self.cfg_scale,
controlnet_conditioning_scale=controlnet_conditioning_scale,
num_inference_steps=self.n_steps,
denoising_end=self.high_noise_frac,
output_type=self.output_type,
width = self.width,
height = self.height,
generator=self.generator,
cross_attention_kwargs={"scale": self.lora_scale},
).images[0]
# LORAを利用しない場合
else:
if self.REFINER_FLAG:
image = self.base(
prompt=prompt,
negative_prompt=neg_prompt,
image=control_image,
cfg_scale=self.cfg_scale,
controlnet_conditioning_scale=controlnet_conditioning_scale,
num_inference_steps=self.n_steps,
denoising_end=self.high_noise_frac,
output_type="latent",
width = self.width,
height = self.height,
generator=self.generator
).images[0]
image = self.refiner(
prompt=prompt,
negative_prompt=neg_prompt,
cfg_scale=self.cfg_scale,
aesthetic_score = self.aesthetic_score,
negative_aesthetic_score = self.negative_aesthetic_score,
num_inference_steps=self.n_steps,
denoising_start=self.high_noise_frac,
image=image[None, :]
).images[0]
# refiner を利用しない場合
else:
image = self.base(
prompt=prompt,
negative_prompt=neg_prompt,
image=control_image,
cfg_scale=self.cfg_scale,
controlnet_conditioning_scale=controlnet_conditioning_scale,
num_inference_steps=self.n_steps,
denoising_end=self.high_noise_frac,
output_type=self.output_type,
width = self.width,
height = self.height,
generator=self.generator
).images[0]
return image
では一つ一つ解説していきます。
SDXLCconfigクラス
class SDXLCconfig:
def __init__(self, config_ini_path = './configs/config.ini'):
# iniファイルの読み込み
self.config_ini = configparser.ConfigParser()
# 指定したiniファイルが存在しない場合、エラー発生
if not os.path.exists(config_ini_path):
raise FileNotFoundError(errno.ENOENT, os.strerror(errno.ENOENT), config_ini_path)
self.config_ini.read(config_ini_path, encoding='utf-8')
SDXLC_items = self.config_ini.items('SDXLC')
self.SDXLC_config_dict = dict(SDXLC_items)
ここではconfig_ini_path = './configs/config.ini'で指定されている設定ファイルをSDXLC_config_dictとして読み込んでいます。
辞書型で読み込んでいるため、設定ファイルの中身をpythonの辞書として読み込むことが可能になります。
SDXLCクラスのinitメソッド
class SDXLC:
def __init__(self,device = None, config_ini_path = './configs/config.ini'):
SDXLC_config = SDXLCconfig(config_ini_path = config_ini_path)
config_dict = SDXLC_config.SDXLC_config_dict
if device is not None:
self.device = device
else:
device = config_dict["device"]
self.device = "cuda" if torch.cuda.is_available() else "cpu"
if device != "auto":
self.device = device
self.last_latents = None
self.last_step = -1
self.last_timestep = 1000
self.n_steps = int(config_dict["n_steps"])
if not config_dict["high_noise_frac"] == "None":
self.high_noise_frac = float(config_dict["high_noise_frac"])
else:
self.high_noise_frac = None
self.seed = int(config_dict["seed"])
self.generator = torch.Generator(device=self.device).manual_seed(self.seed)
self.controlnet_path = config_dict["controlnet_path"]
self.control_mode = config_dict["control_mode"]
if self.control_mode == "None":
self.control_mode = None
self.vae_model_path = config_dict["vae_model_path"]
self.VAE_FLAG = True
if self.vae_model_path == "None":
self.vae_model_path = None
self.VAE_FLAG = False
self.base_model_path = config_dict["base_model_path"]
self.REFINER_FLAG = True
self.refiner_model_path = config_dict["refiner_model_path"]
if self.refiner_model_path == "None":
self.refiner_model_path = None
self.REFINER_FLAG = False
self.LORA_FLAG = True
self.lora_weight_path = config_dict["lora_weight_path"]
if self.lora_weight_path == "None":
self.lora_weight_path = None
self.LORA_FLAG = False
self.lora_scale = float(config_dict["lora_scale"])
self.use_karras_sigmas = config_dict["use_karras_sigmas"]
if self.use_karras_sigmas == "True":
self.use_karras_sigmas = True
else:
self.use_karras_sigmas = False
self.scheduler_algorithm_type = config_dict["scheduler_algorithm_type"]
if config_dict["solver_order"] != "None":
self.solver_order = int(config_dict["solver_order"])
else:
self.solver_order = None
self.cfg_scale = float(config_dict["cfg_scale"])
self.width = int(config_dict["width"])
self.height = int(config_dict["height"])
self.output_type = config_dict["output_type"]
self.aesthetic_score = float(config_dict["aesthetic_score"])
self.negative_aesthetic_score = float(config_dict["negative_aesthetic_score"])
self.save_latent_simple = config_dict["save_latent_simple"]
if self.save_latent_simple == "True":
self.save_latent_simple = True
print("use vallback save_latent_simple")
else:
self.save_latent_simple = False
self.save_latent_overstep = config_dict["save_latent_overstep"]
if self.save_latent_overstep == "True":
self.save_latent_overstep = True
print("use vallback save_latent_overstep")
else:
self.save_latent_overstep = False
self.save_latent_approximation = config_dict["save_latent_approximation"]
if self.save_latent_approximation == "True":
self.save_latent_approximation = True
print("use vallback save_latent_approximation")
else:
self.save_latent_approximation = False
self.use_callback = False
if self.save_latent_simple or self.save_latent_overstep or self.save_latent_approximation:
self.use_callback = True
if self.save_latent_simple and self.save_latent_overstep:
raise ValueError("save_latent_simple and save_latent_overstep cannot be set at the same time")
self.base , self.refiner = self.preprepare_model()
まず、設定ファイルの内容をconfig_dictに格納しています。これは辞書型のため、config_dict["device"]のような形で設定ファイルの内容を文字列として取得することができます。
あくまで、すべての文字を文字列として取得するため、int型やbool型にしたい場合は、適宜型変更をする必要があることに注意してください。
続いて下記の順番で処理を行います。
- モデルを動作させる
deviceを指定する - 設定ファイルの各種設定を取得する
- モデルを定義する。
- 設定ファイルに合わせて、適切なモデルを定義する
-
self.preprepare_model()メソッドで定義する
SDXLCクラスのpreprepare_modelメソッド
class SDXLC:
・・・
def preprepare_model(self):
controlnet = ControlNetModel.from_pretrained(
self.controlnet_path,
use_safetensors=True,
torch_dtype=torch.float16)
if self.VAE_FLAG:
vae = AutoencoderKL.from_pretrained(
self.vae_model_path,
torch_dtype=torch.float16)
base = StableDiffusionXLControlNetPipeline.from_pretrained(
self.base_model_path,
controlnet=controlnet,
vae=vae,
torch_dtype=torch.float16,
variant="fp16",
use_safetensors=True
)
base.to(self.device)
if self.REFINER_FLAG:
refiner = DiffusionPipeline.from_pretrained(
self.refiner_model_path,
text_encoder_2=base.text_encoder_2,
vae=vae,
requires_aesthetics_score=True,
torch_dtype=torch.float16,
variant="fp16",
use_safetensors=True
)
refiner.enable_model_cpu_offload()
else:
refiner = None
else:
base = StableDiffusionXLControlNetPipeline.from_pretrained(
self.base_model_path,
controlnet=controlnet,
torch_dtype=torch.float16,
variant="fp16",
use_safetensors=True
)
base.to(self.device, torch.float16)
if self.REFINER_FLAG:
refiner = DiffusionPipeline.from_pretrained(
self.refiner_model_path,
text_encoder_2=base.text_encoder_2,
requires_aesthetics_score=True,
torch_dtype=torch.float16,
variant="fp16",
use_safetensors=True
)
refiner.enable_model_cpu_offload()
else:
refiner = None
if self.LORA_FLAG:
base.load_lora_weights(self.lora_weight_path)
if self.solver_order is not None:
base.scheduler = DPMSolverMultistepScheduler.from_config(
base.scheduler.config,
use_karras_sigmas=self.use_karras_sigmas,
Algorithm_type =self.scheduler_algorithm_type,
solver_order=self.solver_order,
)
return base, refiner
else:
base.scheduler = DPMSolverMultistepScheduler.from_config(
base.scheduler.config,
use_karras_sigmas=self.use_karras_sigmas,
Algorithm_type =self.scheduler_algorithm_type,
)
return base, refiner
基本的にはこれまでにSD3(+ControlNet)の記事(Part8,part9)やSDXL(Part6,Part6.5)の記事と同様です。
変わっている箇所としては、下記の位置にてLoRAを定義しています。
if self.LORA_FLAG:
base.load_lora_weights(self.lora_weight_path)
SDXLCクラスのprepare_referimageメソッド
class SDXLC:
・・・
def prepare_referimage(self,input_refer_image_path,output_refer_image_path, low_threshold = 100, high_threshold = 200):
mode = None
if self.control_mode is not None:
mode = self.control_mode
else:
raise ValueError("control_mode is not set")
def prepare_openpose(input_refer_image_path,output_refer_image_path, mode):
# 初期画像の準備
init_image = load_image(input_refer_image_path)
init_image = init_image.resize((self.width, self.height))
processor = Processor(mode)
processed_image = processor(init_image, to_pil=True)
processed_image.save(output_refer_image_path)
def prepare_canny(input_refer_image_path,output_refer_image_path, low_threshold = 100, high_threshold = 200):
init_image = load_image(input_refer_image_path)
init_image = init_image.resize((self.width, self.height))
# コントロールイメージを作成するメソッド
def make_canny_condition(image, low_threshold = 100, high_threshold = 200):
image = np.array(image)
image = cv2.Canny(image, low_threshold, high_threshold)
image = image[:, :, None]
image = np.concatenate([image, image, image], axis=2)
return Image.fromarray(image)
control_image = make_canny_condition(init_image, low_threshold, high_threshold)
control_image.save(output_refer_image_path)
def prepare_depthmap(input_refer_image_path,output_refer_image_path):
# 初期画像の準備
init_image = load_image(input_refer_image_path)
init_image = init_image.resize((self.width, self.height))
processor = Processor("depth_midas")
depth_image = processor(init_image, to_pil=True)
depth_image.save(output_refer_image_path)
def prepare_zoe_depthmap(input_refer_image_path,output_refer_image_path):
torch.hub.help(
"intel-isl/MiDaS",
"DPT_BEiT_L_384",
force_reload=True
)
model_zoe_n = torch.hub.load(
"isl-org/ZoeDepth",
"ZoeD_NK",
pretrained=True
).to("cuda")
init_image = load_image(input_refer_image_path)
init_image = init_image.resize((self.width, self.height))
depth_numpy = model_zoe_n.infer_pil(init_image) # return: numpy.ndarray
from zoedepth.utils.misc import colorize
colored = colorize(depth_numpy) # numpy.ndarray => numpy.ndarray
# gamma correction
img = colored / 255
img = np.power(img, 2.2)
img = (img * 255).astype(np.uint8)
Image.fromarray(img).save(output_refer_image_path)
if "openpose" in mode:
prepare_openpose(input_refer_image_path,output_refer_image_path, mode)
elif mode == "canny":
prepare_canny(input_refer_image_path,output_refer_image_path, low_threshold = low_threshold, high_threshold = high_threshold)
elif mode == "depth":
prepare_depthmap(input_refer_image_path,output_refer_image_path)
elif mode == "zoe_depth":
prepare_zoe_depthmap(input_refer_image_path,output_refer_image_path)
elif mode == "tile":
init_image = load_image(input_refer_image_path)
init_image.save(output_refer_image_path)
else:
raise ValueError("control_mode is not set")
下記のような普通の画像を、OpenPoseの骨格や線画、深度マップに変換するメソッドです。
参照画像
OpenPose Full
線画

深度マップ
ここではまず下記で、参照画像をどのように変換するべきかを設定します。
mode = None
if self.control_mode is not None:
mode = self.control_mode
else:
raise ValueError("control_mode is not set")
そしてmodeの値によって下記のように、参照画像を生成しています。
if "openpose" in mode:
prepare_openpose(input_refer_image_path,output_refer_image_path, mode)
elif mode == "canny":
prepare_canny(input_refer_image_path,output_refer_image_path, low_threshold = low_threshold, high_threshold = high_threshold)
elif mode == "depth":
prepare_depthmap(input_refer_image_path,output_refer_image_path)
elif mode == "zoe_depth":
prepare_zoe_depthmap(input_refer_image_path,output_refer_image_path)
elif mode == "tile":
init_image = load_image(input_refer_image_path)
init_image.save(output_refer_image_path)
else:
raise ValueError("control_mode is not set")
openposeの場合はOpenPoseの骨格画像をoutput_refer_image_pathに保存します
cannyの場合はCanny Edgeを取得して同様に保存します。
というように、参照画像からコントロールネットに入力する画像に変換します。
その際に、生成したい画像の解像度にリサイズしてから変更することになります。
SDXLCクラスのgenerate_imageメソッド
class SDXLC:
・・・
def generate_image(self, prompt, neg_prompt, image_path, seed = None, controlnet_conditioning_scale = 1.0):
def decode_tensors(pipe, step, timestep, callback_kwargs):
if self.save_latent_simple:
callback_kwargs = decode_tensors_simple(pipe, step, timestep, callback_kwargs)
elif self.save_latent_overstep:
callback_kwargs = decode_tensors_residual(pipe, step, timestep, callback_kwargs)
else:
raise ValueError("save_latent_simple or save_latent_overstep must be set or 'save_latent_approximation = False'")
return callback_kwargs
def decode_tensors_simple(pipe, step, timestep, callback_kwargs):
latents = callback_kwargs["latents"]
imege = None
if self.save_latent_simple and not self.save_latent_approximation:
image = latents_to_rgb_vae(latents,pipe)
elif self.save_latent_approximation:
image = latents_to_rgb_approximation(latents,pipe)
else:
raise ValueError("save_latent_simple or save_latent_approximation is not set")
gettime = time.time()
formatted_time_human_readable = time.strftime("%Y%m%d_%H%M%S", time.localtime(gettime))
image.save(f"./outputs/latent_{formatted_time_human_readable}_{step}_{timestep}.png")
return callback_kwargs
def decode_tensors_residual(pipe, step, timestep, callback_kwargs):
latents = callback_kwargs["latents"]
if step > 0:
residual = latents - self.last_latents
goal = self.last_latents + residual * ((self.last_timestep) / (self.last_timestep - timestep))
#print( ((self.last_timestep) / (self.last_timestep - timestep)))
else:
goal = latents
if self.save_latent_overstep and not self.save_latent_approximation:
image = latents_to_rgb_vae(goal,pipe)
elif self.save_latent_approximation:
image = latents_to_rgb_approximation(goal,pipe)
else:
raise ValueError("save_latent_simple or save_latent_approximation is not set")
gettime = time.time()
formatted_time_human_readable = time.strftime("%Y%m%d_%H%M%S", time.localtime(gettime))
image.save(f"./outputs/latent_{formatted_time_human_readable}_{step}_{timestep}.png")
self.last_latents = latents
self.last_step = step
self.last_timestep = timestep
if timestep == 0:
self.last_latents = None
self.last_step = -1
self.last_timestep = 100
return callback_kwargs
def latents_to_rgb_vae(latents,pipe):
pipe.upcast_vae()
latents = latents.to(next(iter(pipe.vae.post_quant_conv.parameters())).dtype)
images = pipe.vae.decode(latents / pipe.vae.config.scaling_factor, return_dict=False)[0]
images = pipe.image_processor.postprocess(images, output_type='pil')
pipe.vae.to(dtype=torch.float16)
return StableDiffusionXLPipelineOutput(images=images).images[0]
def latents_to_rgb_approximation(latents, pipe):
weights = (
(60, -60, 25, -70),
(60, -5, 15, -50),
(60, 10, -5, -35)
)
weights_tensor = torch.t(torch.tensor(weights, dtype=latents.dtype).to(latents.device))
biases_tensor = torch.tensor((150, 140, 130), dtype=latents.dtype).to(latents.device)
rgb_tensor = torch.einsum("...lxy,lr -> ...rxy", latents, weights_tensor) + biases_tensor.unsqueeze(-1).unsqueeze(-1)
image_array = rgb_tensor.clamp(0, 255)[0].byte().cpu().numpy()
image_array = image_array.transpose(1, 2, 0) # Change the order of dimensions
return Image.fromarray(image_array)
if seed is not None:
self.generator = torch.Generator(device=self.device).manual_seed(seed)
control_image = load_image(image_path)
image = None
if self.use_callback:
if self.LORA_FLAG:
if self.REFINER_FLAG:
image = self.base(
prompt=prompt,
negative_prompt=neg_prompt,
image=control_image,
cfg_scale=self.cfg_scale,
controlnet_conditioning_scale=controlnet_conditioning_scale,
num_inference_steps=self.n_steps,
denoising_end=self.high_noise_frac,
output_type="latent",
width = self.width,
height = self.height,
generator=self.generator,
cross_attention_kwargs={"scale": self.lora_scale},
callback_on_step_end=decode_tensors,
callback_on_step_end_tensor_inputs=["latents"],
).images[0]
image = self.refiner(
prompt=prompt,
negative_prompt=neg_prompt,
cfg_scale=self.cfg_scale,
aesthetic_score = self.aesthetic_score,
negative_aesthetic_score = self.negative_aesthetic_score,
num_inference_steps=self.n_steps,
denoising_start=self.high_noise_frac,
callback_on_step_end=decode_tensors,
callback_on_step_end_tensor_inputs=["latents"],
image=image[None, :]
).images[0]
#refiner を利用しない場合
else:
image = self.base(
prompt=prompt,
negative_prompt=neg_prompt,
image=control_image,
cfg_scale=self.cfg_scale,
controlnet_conditioning_scale=controlnet_conditioning_scale,
num_inference_steps=self.n_steps,
denoising_end=self.high_noise_frac,
output_type=self.output_type,
width = self.width,
height = self.height,
generator=self.generator,
callback_on_step_end=decode_tensors,
callback_on_step_end_tensor_inputs=["latents"],
cross_attention_kwargs={"scale": self.lora_scale},
).images[0]
#LORAを利用しない場合
else:
if self.REFINER_FLAG:
image = self.base(
prompt=prompt,
negative_prompt=neg_prompt,
image=control_image,
cfg_scale=self.cfg_scale,
controlnet_conditioning_scale=controlnet_conditioning_scale,
num_inference_steps=self.n_steps,
denoising_end=self.high_noise_frac,
output_type="latent",
width = self.width,
height = self.height,
callback_on_step_end=decode_tensors,
callback_on_step_end_tensor_inputs=["latents"],
generator=self.generator
).images[0]
image = self.refiner(
prompt=prompt,
negative_prompt=neg_prompt,
cfg_scale=self.cfg_scale,
aesthetic_score = self.aesthetic_score,
negative_aesthetic_score = self.negative_aesthetic_score,
num_inference_steps=self.n_steps,
denoising_start=self.high_noise_frac,
callback_on_step_end=decode_tensors,
callback_on_step_end_tensor_inputs=["latents"],
image=image[None, :]
).images[0]
#refiner を利用しない場合
else:
image = self.base(
prompt=prompt,
negative_prompt=neg_prompt,
image=control_image,
cfg_scale=self.cfg_scale,
controlnet_conditioning_scale=controlnet_conditioning_scale,
num_inference_steps=self.n_steps,
denoising_end=self.high_noise_frac,
output_type=self.output_type,
width = self.width,
height = self.height,
callback_on_step_end=decode_tensors,
callback_on_step_end_tensor_inputs=["latents"],
generator=self.generator
).images[0]
#latentを保存しない場合
else:
if self.LORA_FLAG:
if self.REFINER_FLAG:
image = self.base(
prompt=prompt,
negative_prompt=neg_prompt,
image=control_image,
cfg_scale=self.cfg_scale,
controlnet_conditioning_scale=controlnet_conditioning_scale,
num_inference_steps=self.n_steps,
denoising_end=self.high_noise_frac,
output_type="latent",
width = self.width,
height = self.height,
generator=self.generator,
cross_attention_kwargs={"scale": self.lora_scale},
).images[0]
image = self.refiner(
prompt=prompt,
negative_prompt=neg_prompt,
cfg_scale=self.cfg_scale,
aesthetic_score = self.aesthetic_score,
negative_aesthetic_score = self.negative_aesthetic_score,
num_inference_steps=self.n_steps,
denoising_start=self.high_noise_frac,
image=image[None, :]
).images[0]
# refiner を利用しない場合
else:
image = self.base(
prompt=prompt,
negative_prompt=neg_prompt,
image=control_image,
cfg_scale=self.cfg_scale,
controlnet_conditioning_scale=controlnet_conditioning_scale,
num_inference_steps=self.n_steps,
denoising_end=self.high_noise_frac,
output_type=self.output_type,
width = self.width,
height = self.height,
generator=self.generator,
cross_attention_kwargs={"scale": self.lora_scale},
).images[0]
# LORAを利用しない場合
else:
if self.REFINER_FLAG:
image = self.base(
prompt=prompt,
negative_prompt=neg_prompt,
image=control_image,
cfg_scale=self.cfg_scale,
controlnet_conditioning_scale=controlnet_conditioning_scale,
num_inference_steps=self.n_steps,
denoising_end=self.high_noise_frac,
output_type="latent",
width = self.width,
height = self.height,
generator=self.generator
).images[0]
image = self.refiner(
prompt=prompt,
negative_prompt=neg_prompt,
cfg_scale=self.cfg_scale,
aesthetic_score = self.aesthetic_score,
negative_aesthetic_score = self.negative_aesthetic_score,
num_inference_steps=self.n_steps,
denoising_start=self.high_noise_frac,
image=image[None, :]
).images[0]
# refiner を利用しない場合
else:
image = self.base(
prompt=prompt,
negative_prompt=neg_prompt,
image=control_image,
cfg_scale=self.cfg_scale,
controlnet_conditioning_scale=controlnet_conditioning_scale,
num_inference_steps=self.n_steps,
denoising_end=self.high_noise_frac,
output_type=self.output_type,
width = self.width,
height = self.height,
generator=self.generator
).images[0]
return image
このメソッドは、ここまでで読み込んだモデルと設定を利用して、実際に画像を生成するメソッドです。
潜在表現と保存する場合は、LoRAを利用する場合、Refinerを利用する場合などで条件分岐をして、実行するPipelineを変更しています。
実験結果
ここからは、上記のコードによってGoogle Colabでパラメータを変更して、様々な実験を実施したため、その詳細を記載します。
実験1
まずは、LoRAのControlNetも導入しない、ノーマルの状態で実験をします。
以降の実験は、この実験1の結果をベースに比較するために実施します。
設定
config_text = """
[SDXLC]
device = auto
n_steps=28
high_noise_frac=None
seed=42
vae_model_path = None
base_model_path = Asahina2K/Animagine-xl-3.1-diffuser-variant-fp16
refiner_model_path = None
controlnet_path = xinsir/controlnet-openpose-sdxl-1.0
control_mode = openpose
lora_weight_path = None
lora_scale = 0.0
use_karras_sigmas = True
scheduler_algorithm_type = dpmsolver++
solver_order = 2
cfg_scale = 7.0
width = 832
height = 1216
output_type = pil
aesthetic_score = 6
negative_aesthetic_score = 2.5
save_latent_simple = False
save_latent_overstep = False
save_latent_approximation = False
"""
with open("configs/config.ini", "w", encoding="utf-8") as f:
f.write(config_text)
use_lora = False
controlnet_conditioning_scale = 0.0
7セル目のようにcontrolnet_conditioning_scale = 0.0を指定することで、ControlNet自体は読み込まれて、計算には使用されますが、影響を0にできます。
(計算時間は、長くなってしまうので、本当にControlNetを利用しない場合は、Part6や6.5の記事の内容を利用した方が良いです。)
また4セル目のlora_weight_path = Noneを指定することで、LoRAを利用しない設定になります。
結果
実行時間
generate image time: 36.22908902168274
generate image time: 34.59099340438843
generate image time: 33.817437410354614
生成された画像は下記に示します。



Part6.5の記事と見比べていただければわかるかと思いますが、全く同じ画像が生成されていると思います。
したがって、意図通りの画像が生成されました。
以降はこの画像をベースに、ControlNetなどを試していければと思います。
実験2
LoRAを利用しない形で、各種ControlNetを試してみます。
設定
config_text = """
[SDXLC]
device = auto
n_steps=28
high_noise_frac=None
seed=42
vae_model_path = None
base_model_path = Asahina2K/Animagine-xl-3.1-diffuser-variant-fp16
refiner_model_path = None
controlnet_path = xinsir/controlnet-openpose-sdxl-1.0
;controlnet_path = diffusers/controlnet-canny-sdxl-1.0
;controlnet_path = diffusers/controlnet-depth-sdxl-1.0
;controlnet_path = diffusers/controlnet-zoe-depth-sdxl-1.0
;controlnet_path = xinsir/controlnet-tile-sdxl-1.0
control_mode = openpose
;control_mode = openpose_face
;control_mode = openpose_faceonly
;control_mode = openpose_full
;control_mode = canny
;control_mode = depth
;control_mode = zoe_depth
;control_mode = tile
lora_weight_path = None
lora_scale = 1.0
use_karras_sigmas = True
scheduler_algorithm_type = dpmsolver++
solver_order = 2
cfg_scale = 7.0
width = 832
height = 1216
output_type = pil
aesthetic_score = 6
negative_aesthetic_score = 2.5
save_latent_simple = False
save_latent_overstep = False
save_latent_approximation = False
"""
with open("configs/config.ini", "w", encoding="utf-8") as f:
f.write(config_text)
use_lora = False
controlnet_conditioning_scale = 0.5
以降の実験はcontrol_modeとcontrolnet_pathを変化させていきながら実施します。
controlnet_conditioning_scale = 0.5なので、ControlNetの影響をあまり受けない画像も生成されると思います。
結果2-1
設定
controlnet_path = xinsir/controlnet-openpose-sdxl-1.0
control_mode = openpose
参照画像の変換前

参照画像の変換後
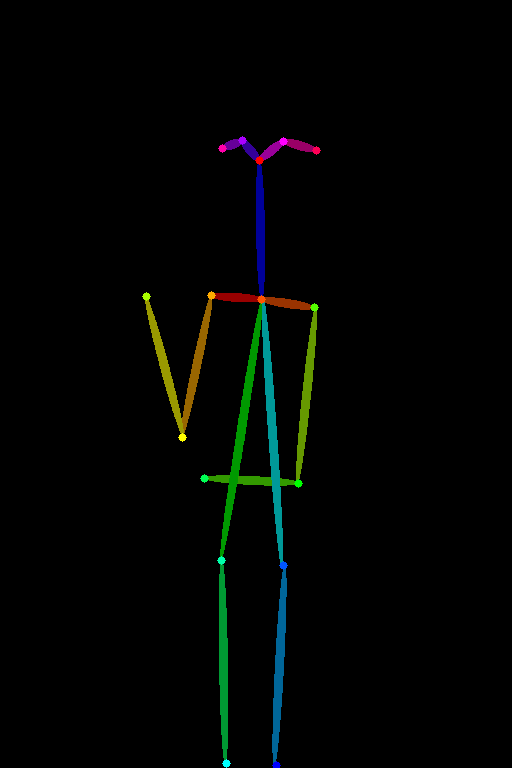
実行時間
generate image time: 36.401485204696655
generate image time: 34.710044145584106
generate image time: 33.80799460411072
生成画像



おおよそ、参照画像と近いポーズになりました。
結果2-2
設定
controlnet_path = xinsir/controlnet-openpose-sdxl-1.0
control_mode = openpose_face
参照画像の変換前
上と同じ
参照画像の変換後

実行時間
generate image time: 34.58041715621948
generate image time: 33.101900815963745
generate image time: 34.591469526290894
生成画像



前回の結果と比べて、顔の向きがより正面を向くようになったと思います。
結果2-3
設定
controlnet_path = xinsir/controlnet-openpose-sdxl-1.0
control_mode = openpose_faceonly
参照画像の変換前
上と同じ
参照画像の変換後

実行時間
generate image time: 34.97057867050171
generate image time: 33.347087383270264
generate image time: 33.509255170822144
生成画像



今回はあまり反映されませんでした。顔の向きは正面でしたが、位置はあまり反映されなかったです。
結果2-4
設定
controlnet_path = xinsir/controlnet-openpose-sdxl-1.0
control_mode = openpose_full
参照画像の変換前
上と同じ
参照画像の変換後

実行時間
generate image time: 36.971638202667236
generate image time: 34.228318214416504
generate image time: 33.53951096534729
生成画像



ポーズはそこそこ反映されていますが、手の形は反映されませんでした。
OpenPose系統では、これを使うのが無難かもしれない。
結果2-5
設定
controlnet_path = diffusers/controlnet-canny-sdxl-1.0
control_mode = canny
参照画像の変換前
上と同じ
参照画像の変換後

実行時間
generate image time: 35.687371253967285
generate image time: 34.79979658126831
generate image time: 34.74956750869751
生成画像



参照画像をキープしながら、プロンプトの内容を反映してくれました。
リサイズされたせいで、かなり顔が面長ですね。
結果2-6
設定
controlnet_path = diffusers/controlnet-depth-sdxl-1.0
control_mode = depth
参照画像の変換前
上と同じ
参照画像の変換後

実行時間
generate image time: 35.34699082374573
generate image time: 35.2352192401886
generate image time: 33.86982488632202
生成画像



cannyと比較して自由度が高いため、バリエーション豊かな画像が生成されました。
元の画像の構図をキープしながら、プロンプトを反映させたい場合、一番使いやすそうに感じました。
(Cannyだと線画に引っ張られすぎるのと、OpenPose Fullだと手とか反映されないことがあるので)
結果2-7
設定
controlnet_path = diffusers/controlnet-zoe-depth-sdxl-1.0
control_mode = zoe_depth
参照画像の変換前
上と同じ
参照画像の変換後

実行時間
generate image time: 34.49560046195984
generate image time: 34.84618639945984
generate image time: 33.521161794662476
生成画像



こちらはDepthと比較すると、人の顔はうまく生成できている気がしますが、たまたまかもしれません。
ContolNetに入力する画像を参照画像から作る処理に、少し時間がかかるのでその点が少し使いにくいです。
少しでも質の高い画像を生成したい場合は、Depthよりもこちらを利用すると良いかもしれないです。
結果2-8
設定
controlnet_path = xinsir/controlnet-tile-sdxl-1.0
control_mode = tile
参照画像の変換前
上と同じ
参照画像の変換後

実行時間
generate image time: 35.9168918132782
generate image time: 34.8120903968811
generate image time: 33.69835591316223
生成画像



元の画像に対して、プロンプトを反映させたような画像になりました。
実写画像からアニメ風画像に変換するなどの用途に使えそうです。
実験3
続いてはLoRAを導入します。
ControlNetは導入せず実験します。
設定
config_text = """
[SDXLC]
device = auto
n_steps=28
high_noise_frac=None
seed=42
vae_model_path = None
base_model_path = Asahina2K/Animagine-xl-3.1-diffuser-variant-fp16
refiner_model_path = None
controlnet_path = diffusers/controlnet-depth-sdxl-1.0
control_mode = depth
lora_weight_path = ./inputs/DreamyvibesartstyleSDXL.safetensors
lora_scale = 1.0
use_karras_sigmas = True
scheduler_algorithm_type = dpmsolver++
solver_order = 2
cfg_scale = 7.0
width = 832
height = 1216
output_type = pil
aesthetic_score = 6
negative_aesthetic_score = 2.5
save_latent_simple = False
save_latent_overstep = False
save_latent_approximation = False
"""
with open("configs/config.ini", "w", encoding="utf-8") as f:
f.write(config_text)
use_lora = True
controlnet_conditioning_scale = 0.0
7セル目のようにcontrolnet_conditioning_scale = 0.0を指定することで、ControlNet自体は読み込まれて、計算には使用されますが、影響を0にできます。
また4セル目のlora_weight_path = ./inputs/DreamyvibesartstyleSDXL.safetensorsを指定することで、指定したパスに格納されたLoRAモデルを利用します。
さらに5セル目でuse_lora = Trueとすることで、既存のプロンプトに対して、トリガーワードを追加します。
結果
実行時間
generate image time: 43.232848167419434
generate image time: 40.214457988739014
generate image time: 40.839759826660156
生成された画像は下記に示します。



元のモデルよりも、より可愛い画像になっている気がします。
実験4
続いてはLoRAを導入した状態で、一つControlNetを試します。
設定
config_text = """
[SDXLC]
device = auto
n_steps=28
high_noise_frac=None
seed=42
vae_model_path = None
base_model_path = Asahina2K/Animagine-xl-3.1-diffuser-variant-fp16
refiner_model_path = None
controlnet_path = diffusers/controlnet-depth-sdxl-1.0
control_mode = depth
lora_weight_path = ./inputs/DreamyvibesartstyleSDXL.safetensors
lora_scale = 1.0
use_karras_sigmas = True
scheduler_algorithm_type = dpmsolver++
solver_order = 2
cfg_scale = 7.0
width = 832
height = 1216
output_type = pil
aesthetic_score = 6
negative_aesthetic_score = 2.5
save_latent_simple = False
save_latent_overstep = False
save_latent_approximation = False
"""
with open("configs/config.ini", "w", encoding="utf-8") as f:
f.write(config_text)
use_lora = True
controlnet_conditioning_scale = 0.7
参照画像

(使った画像がバリバリ版権画像だったため、depth画像だけで失礼します。元の画像はANIMAGINE XL 3.1の公式が提供しているチュートリアルで使われているプロンプトで作成した画像の一つです。(おそらくseed42-47のあたり)
結果
実行時間
generate image time: 43.19255384778535
generate image time: 40.45602893829346
generate image time: 40.45509457588196
生成された画像は下記に示します。



髪の色が赤色になるという謎生成は一部ありますが、ここまで構図を指定した状態で、ここまで可愛い神絵が生成できるようになっているとは驚きました。
どんな構図、どんなキャラクター、どんなスタイルでも、ControlNetとLoRAを組み合わせたら生成できそうな手応えがありますね
まとめ
今回は、初心者向けにGoogle Colaboratoryで、簡単に生成AIを使えるようにする環境を作りました。
SDXLの性能の高さを思い知りました。
SD3でもコミュニティが盛り上がって、高性能なFineTuningモデルとLoRAモデルが出るといいですね。今後に期待です。
この辺りで字数制限の8万字ギリギリなのでこのくらいで終わらせていただきます!
ありがとうございました!
Discussion