VAEって結局何者なの?
はじめに
今回は、満を持してVAE(Variational Auto Encoder)をちゃんと理解していこうと思います。
VAEに関しては、だいたい知っていますが、MusicGenという音楽生成AIを理解しようと思った時に、関連してRVQ-GANが出てきたので、再勉強をしています。
今後、下記の流れで記事を書いていく予定です。
VAE(今回)
↓
VQ-VAE
↓
RQ-VAE,RVQ-GAN
↓
MusicGen
今回は、流れの最初であり、現在でも非常に重要な概念であるVAEに関して記事を書きます。
VAEは、Stable Diffusionの中でも中核として使われていたりと、比較的古い概念でありながら、まだまだ活躍が期待できる汎用ネットワークです。
本記事が、みなさまの理解の手助けになれば、これほど嬉しいことはございません。
参考文献
VAEの論文です。
圧倒的な名著シリーズである「ゼロから作るDeep Learning」シリーズの5作目である、生成モデル編です。
この本では、最終的に拡散モデルを理解することを目的に、VAEや混合ガウスモデル、正規分布まで遡り、本当にゼロから中身を理解しながら実装をすることができる、大変素晴らしい書籍になっています。
本書の後半にもVAEやELBOについての簡単な記載があり、本記事を書くうえで表現を参考にさせていただきました。
確率分布のどの部分が計算可能で、どの部分が計算不可能なのかが常に明示されながら進んでいくので、初学者には非常に分かりやすい書籍でした!
特に、VAEなどの生成AIをただ使うだけでなく、ちゃんと理論を理解したいと思った場合、論文や理論書を理解するために「線形代数」や「微積分学」の事前知識が必要になります。
本書は、初学者が一番最初に読んで必要な基礎知識が習得できる良本になります。
生成 Deep Learning 第2版 ―絵を描き、物語や音楽を作り、ゲームをプレイする
本書の序盤で、Auto EncoderとVAEの違いを説明してくれています。しかもそれぞれの潜在空間の分布を可視化してくれているので、違いが分かりやすく、理解もしやすいです。
さらに、本書はVAEだけでなくGANや画像生成、音楽生成、テキスト生成など、ありとあらゆる生成AIの紹介と解説をしてくれており、必読の一冊となっております。
(書籍のリンクはAmazonアフィリエイトリンクになっております)
関連記事
VAEに関連した記事は過去のも書いております。
こちらの記事もご覧いただけると嬉しいです!
Auto Encoder
Auto Encoderの紹介
VAEを語る上で欠かせないのは、Auto Encoderの存在です。
Auto Encoderというのは、ニューラルネットワークにより構築されたネットワーク構造の一つで、入力と出力を一致させるように学習させるネットワークです。

最も単純なAuto Encoderは上記のような構造をしています。
前段は、入力データから、それより次元の小さな潜在表現を生成するEncoderです。
上の図では、入力データを重みデータによる線形変換(+活性化層における非線形変換)で成り立っています。
Encoderでは、次元の大きな入力データを、次元の小さい潜在表現に圧縮する処理を行います。
後段は、潜在表現から、それより次元の大きな出力データを生成するDecoderです。
出力データは入力と一致するように学習がなされています。
このとき、Decoderでは、次元の小さな潜在表現から、出力データ(入力データ)を復元する処理を行います。
この「圧縮(符号化)」と「復元(複合化)」の構造から、「Encoder」「Decoder」と名付けられており、この圧縮・復元をデータを与えれば自動で実施するニューラルネットワークなので、「Auto Encoder」と呼ばれます。
Auto Encoderの本質
ここでの本質は、次元の大きい入力データを、潜在表現に圧縮し、その潜在表現から、入力データを再構成することです。
小さな潜在表現から元データを復元できる理由
これが達成される理由は2つあります。
1つ目は、世の中にあるデータは冗長であることです。
世の中に存在するデータを冗長なデータが多いです。例えば画像データであれば、生の01でデータを保持するよりも、pngなどの圧縮形式を利用してデータを保存した方が、データ量を抑えることができます。
これは、画像中の「隣接する画素は、近い値が多い」という事前知識を用いることで、データを効率的に圧縮することができるからです。
2つ目は、Auto Encoderの重みデータに、入力データを復元するための情報を学習しているからです。
例えば画像であれば、Auto Encoderを利用する際に、事前に大規模画像データセットを利用して学習が行われます。その学習を通して、Decoderは「どうやったら少ない潜在表現から画像データを品質高く復元できるのか」、Encoderは「大量の画像データのうち、どの情報を潜在表現に埋め込めば、Decoderが元の画像を復元できるのか」を学習しています。
その結果、ちょうどpngで説明した通り、「隣接する画素は、近い値が多い」のような自然画像全般に通ずる事前知識を獲得し、その情報を用いることで、少ないデータ量から、元の入力データを復元するようなネットワークを構築することができるというわけです。
構造
先ほど記載した通り、Auto Encoderの本質は、次元の大きい入力データを、潜在表現に圧縮し、小さな潜在表現から、入力データを再構成することです。
そして、これが達成できるのであれば、どんなEncoder,Decoderの構造をしていたとしても、それはAuto Encoderの一種であると考えることができます。
例えば画像を処理する際には、しばしば畳み込みニューラルネットワークやTransformerなどが使われます。
当然、これらを利用したAuto Encoderも考えることができます。
潜在表現も単純な1次元データだけではなく、画像のような3次元(縦, 横, チャネル)データを考えることができます。
(ResNetなどのGAP前の層の出力結果をEncoderの出力として利用することもできます)
したがって、以降ではEncoder Decoder構造を記載する際には、下記のように記載することにします。

Auto Encoerの課題
Auto Encoerはそれ単体では、それなりに優れた情報圧縮器ではありますが、それ以外での活用可能性が難しいネットワークではありました。
入力データと形状は同じな、出力データを出力する際には、ネットワーク構造が使われることも多いです(例えばセマンティックセグメンテーションタスクでU-Netが利用されるなど)が、同じ入出力になるように学習することというのは、情報圧縮以外の文脈で利用するのは難しいです。
そこで、生成モデルとしての活用可能性が考えられました、
例えば、潜在表現を何らかの形で得ることができれば、その潜在表現をDecoderに入力することで、対応した出力データ(画像など)を得ることができます。
これが達成されれば、AIに絵を描かせたり、音楽を生成させたりすることが可能です。
ただし、Auto Encoderでは、その潜在表現をEncoderを利用すること以外で取得することは困難です。
ここで、Auto Encoderによる画像生成の夢は途絶えたかのように見えました。
VAE(Variational Auto Encoder)
VAEと生成モデル
生成モデルの観点から見たVAE
VAEというのは、生成モデルとして重要な「対数尤度の最大化」問題を解くために必要な構造を用意したら、
結果的にAuto Encoderのような形になったというモデルです。
すなわち、Auto Encoderの構造があって、それをこうしたら生成モデルとして使えるようになった。というよりは、生成モデルを作る上で重要な「対数尤度を最大化する」という方向性で、理論的に式変形を繰り返し、計算不可能な部分を取り除き、計算が難しい部分をニューラルネットで近似することで、結果としてAuto Encoderの構造が現れたという解釈があっているような気がします。
対数尤度の最大化からモデル構造を考える
対数尤度の最大化に関しての軽い復習
「対数尤度の最大化」に関しては下記の記事で解説しておりますので、そちらをご覧ください。
上記の記事では詳細に記載していますが、簡単に解説すると、生成モデルにおいて重要なのは、対数尤度
ここで、
したがって、
生成モデルのパラメータ自体にはランダム性がないため、様々なバリエーションのデータを生成するためには、入力にランダムにサンプリングされたデータや定数を入力し、生成モデルがデータを再構成します。
イメージとしては下記のイメージです。

しかし、上記で計算しているのは、尤度
(なぜなら、Decoderはパラメータ
これを用いて対数尤度
この中で、事後分布
そうすることで、第三項のKLダイバージェンスは非負であるため、この項を除いた部分(ELBO)を最大化することで、間接的に対数尤度を最大化することができます。
このとき必要な、近似事後分布
詳しくは上述した記事をご覧ください。
Encoderが平均と分散を出力する理由
ここまでの議論を考慮すると、下記のようなモデル構造になります。

上述した通り、Decoderの場合は、Decoderが出力するデータ
一方で、Encoderは確率分布を生成する必要があります。
さらにいうと、ELBOの式の中で、Encoderが出力する確率分布を用いて下記の式を計算する必要があります。
ここで、
ネットワークは、こちらが設定した事前分布が成立するように学習します。
今回の場合、真の事前分布がどんな形状になるのかの事前情報を持っていないので、あまりバイアス情報が入らないような分布を設定することが望ましいです。
問題は、
この分布は特殊な分布になってはいけません。
なぜなら、KLダイバージェンスを計算できる分布の種類はあまり多くないからです。
したがって、Encoderが生成する確率分布に、何らかの制限を加える必要があります。
今回は、確率分布が正規分布になるように制限をかけます。
その場合、Encoderは、平均
そして、Encoderが出力した、平均
この場合、計算効率化のため、事前分布
標準正規分布
これを達成するためのモデル構造は下記になります。

これでVAEを構築することができました。
上の図をよく見ると、
まるでAuto Encoderのような構造になっていると思います。
VAEの挙動・振る舞い
VAEの目的関数
改めてVAEの目的関数は下記になります。
このELBOを最大化するようにVAEのネットワークパラメータ(
ここで、先日書いた記事にも記載しましたが、第1項は「再構成誤差」、第2項は「正則化項」になります。
式変形を行うと、第1項はDecoderの出力
したがってELBOを最大化する際には、2乗誤差を最小化する方向にVAEのネットワークパラメータ(
第2項は、Encoderが出力する
したがってELBOを最大化する際には、KLダイバージェンス自体を最小化する方向にVAEのEncoderパラメータ(
KLダイバージェンスは、2つの分布が一致しているときに最小値
ELBOの第2項
第1項は再構成誤差のため、分かりやすいと思いますが、第2項がどう言う意味を含むのかが分かりにくいと思います。
ここでは、潜在表現
また、実は、Encoderが出力する近似事後分布
この詳細は、以前書いた記事をご覧ください。
これは主に、Encoderが出力する近似事後分布
その上で、ELBOの第2項では、Encoderが出力する近似事後分布
したがって、上記の議論をまとめると、Encoderが出力する近似事後分布
さらに言うと、真の事後分布
この場合、真の事後分布
したがってDecoder側は、過度に複雑な事後分布をEncoder側に近似することを要求せず、ある程度、真の事後分布が標準正規分布に近づくように、(すなわち標準正規分布からデータを再構成できるように)学習が協力して進んでいく挙動をします。
以上を考慮すると、Decoderは、Encoderがないときには、事前分布として仮定した、標準正規分布
この特性から、VAEは「生成モデル」として利用できることがわかります。
Decoderが学習する潜在表現のランダム性
VAEの全体の構造を改めて下記に提示します。
こちらを見ると、Decoderに入力される潜在表現
すなわち、学習時にDecoderが見る潜在表現
これは、Encoderに入力されるデータが同じデータであっても、decoderはランダムに異なる潜在表現
そしてこのサンプリングは、平均ベクトル
このことを考えると、Decoderは毎回若干異なる潜在表現
したがって、Decoderが入力データ
これを大量の入力
これが達成されると、潜在表現
この特性のおかげで、VAEは、2種類のデータ(例えば、男性の顔写真と女性の顔写真)を構成する潜在表現
これはよくVAEの解説サイトなどで見ることのできる挙動だと思います。
VAEはどうやって学習しているのか
もう一度VAEの構成図を表示します。
ここまで読んで、勘のいい読者は、下記のように考えるかもしれません。
「確率分布からのSampling処理は微分不可能なため、学習できないのでないか」と
その疑問はおっしゃる通りです。
ではここから、VAEの構造を損なわない形で、上記の図中からSampling構造を取り除くことを考えます。
Decoder出力部分
図を見ると、Decoderの出力部分にてSampling構造があります。
生成モデルは、「対数尤度を最大化する」という目的のため、確率分布を出力することが求められますが、Decoderの出力はベクトルです。したがって、出力ベクトル
この形で、目的関数ELBOを計算すると、出力ベクトル
したがって、Sampling処理をなくすため、Decoderが出力するベクトル
したがって、これを考慮すると下記のような図になります。

Encoder出力部分
続いて、Samplingが残っている箇所は、Encoderの出力する平均
この部分では、微分可能な計算グラフにするために、「Reparameterization Trick」という手法を利用しています。
統計学に詳しい方には、「標準化の逆」という説明がしっくりくるかもしれません。
VAEでは、Encoderが平均
このようなサンプリングの操作を、計算グラフの外に出すことで計算可能にする手法をReparameterizetion Trickと呼びます。
具体的には、計算グラフの外であらかじめ、平均
その後、潜在表現
この処理を反映させると下記のような図になります。

この処理により、DeocderとEncoderを繋ぐ部分にはSampling処理が現れなくなったため、Decoder側からEncoder側に勾配が正しく伝播するようになるため、学習が可能なネットワークになりました。
VAEを生成モデルとして利用する
VAEの特徴
さて、ここまでの議論からVAEには下記の特徴を持つことが言えます。
- VAEの潜在表現
z z x' - この特徴より、潜在空間内において、2地点を行き来することで、滑らかに画像を変化させることができる
- 例えば、男性の顔写真から女性の顔写真へと滑らかに生成データを変化させることができる
- この特徴より、潜在空間内において、2地点を行き来することで、滑らかに画像を変化させることができる
- VAEの潜在表現の事前分布
p(z) \mathcal{N}(0, 1) - 標準正規分布
\mathcal{N}(0, 1) z x'
- 標準正規分布
したがって、新しいデータを生成できるという観点で、生成モデルと呼ぶことができます。
落とし穴
と、私も昔は思っておりました。
いや、完全に間違っている訳ではないのですが、時には理論通りに進まないものです。
正確には、VAEの特徴は場合によっては正しくて、場合によっては正しくないです。
「目的関数の再構成誤差と正則化項のバランス」が崩れた場合に、VAEの特徴は機能しなくなります。
(正確には、ある程度その特徴は持っているが、だんだん機能しなくなってくるというイメージ)
これから、説明させていただきます。
ここで、VAEの目的関数であるELBOを再提示します。
この式は、第1項の再構成誤差項と、第2項の正則化項の「バランス」をとって学習が進むことがわかっています。
このバランスは、例えば、第2項に対してハイパーパラメータを導入し、その寄与割合を変化させることによっても変わります。
(これを β-VAE(ベータVAE)と呼びます)
そしてもう一つ、潜在表現の次元数によっても変わります。
よく見るVAEの解説記事では、MNISTなどの簡単な画像に対して、潜在表現の次元を2次元に設定して検証している記事が多いと思います。
これは、VAEの潜在表現の分布と、手描き文字の数字を対応付けて可視化するために非常に優れた例示の仕方だと思っております。
一方で、「VAEであれば、必ず、潜在表現の事前分布が正規分布に落ち着く」というようなミスリードを読者に引き起こす危険性もはらんでいると思っております。
潜在表現の次元が小さい場合
他記事のように、VAEの潜在表現
2次元の潜在表現
この場合、VAEは、潜在空間
そして、潜在空間
すると、潜在表現
この場合は、上記の「VAEの特徴」で記載した生成モデルとしての特徴を強く持つことになります。
これは、ELBOの正則化項の寄与率を大きくしても発生します。
潜在変数の次元が多い場合
一方で、潜在変数の次元数が多い場合はどうか。
潜在変数の次元数が多い場合は、あまり解説に向かないため、解説記事は少ないです。
しかし、潜在変数の次元数が多いVAEが使われており、比較的解析しやすい技術はわかります。
みなさんご存知、Stable Diffusionです。
Stable Diffusionのモデル構造
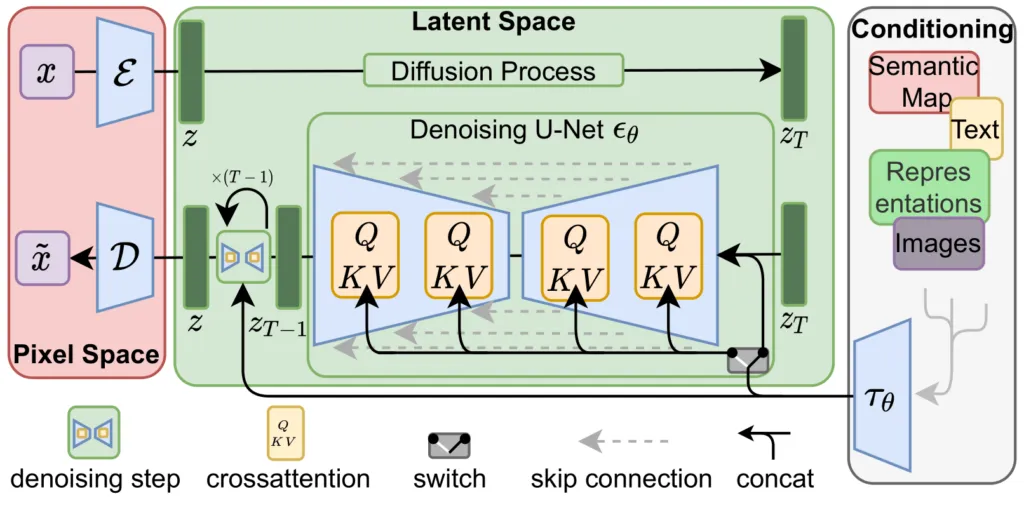
(引用:https://github.com/CompVis/latent-diffusion/blob/main/assets/modelfigure.png)
Stable Diffusionのモデル構造は上記のようになっております。
Conditioningブロック
一番右の「Conditioning」ブロックは、画像の条件付けに使われる部分です。
例えば Stable Diffusionにおける、Text to Imageモデルの場合、プロンプトと呼ばれる呪文で、生成される画像のテーマを制御することができます。
なぜかというと、まず、「Conditioning」ブロックで使われいてる、CLIPやT5 Encoderと呼ばれるtext Encoderにより、プロンプトを特徴量に変換しています。
このとき、CLIPは、「画像とテキストの特徴量が一致」するように学習されているため、プロンプトからCLIPを通じて得られた特徴量は、画像の特徴量と同様に取り扱うことができます。
そのため、プロンプトの特徴量を、画像特徴量として、後述する「クロスアテンション」にて、計算することができるようになるからです。
Latent Spaceブロック
真ん中の「Latent Space」ブロックでは、潜在表現
ここでは、「拡散モデル」というモデルを利用して、潜在表現
(拡散モデルに関してはこちらの記事もご覧ください)
また、拡散モデルでは、TransformerやU-netというモデルが利用されていますが、そのどちらにおいても、CLIPから得られたプロンプト特徴量を「クロスアテンション」により注入しています。
クロスアテンションとは、処理中の画像特徴量と、プロンプト特徴量の類似度を計算し、類似度が高い画像特徴量を増幅させるような処理が行われており、この処理により、プロンプトに適した画像になるように潜在表現
(アテンションに関しては、こちらの記事でも解説しております。)
Pixel Spaceブロック
最後に、一番右側の「Pixel Space」ブロックが、VAEが担当する部分です。
上の段の
そして、下の段の
すなわち、拡散モデルが生成した潜在表現
さて、ここで重要なのは、Stable Diffusionでは、VAEが使われてるはずですが、画像を生成する際に標準正規分布
ちなみに、(詳しい方向けに補足しておくと)Stable Diffusion XLで使われているのは、VQ-VAEではなく、VAEです。
(これはDiffusersライブラリでSDXLの部分を見ればわかります。Diffusersライブラリにて実装されているのは、通常のVAEです。)
該当コード
該当コードは下記です。
src/diffusers/pipelines/stable_diffusion_xl/pipeline_stable_diffusion_xl.py
from ...models import AutoencoderKL, ImageProjection, UNet2DConditionModel
・・・
class StableDiffusionXLPipeline(
DiffusionPipeline,
StableDiffusionMixin,
FromSingleFileMixin,
StableDiffusionXLLoraLoaderMixin,
TextualInversionLoaderMixin,
IPAdapterMixin,
):
・・・
def __init__(
self,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
text_encoder_2: CLIPTextModelWithProjection,
tokenizer: CLIPTokenizer,
tokenizer_2: CLIPTokenizer,
unet: UNet2DConditionModel,
scheduler: KarrasDiffusionSchedulers,
image_encoder: CLIPVisionModelWithProjection = None,
feature_extractor: CLIPImageProcessor = None,
force_zeros_for_empty_prompt: bool = True,
add_watermarker: Optional[bool] = None,
):
上記により、StableDiffusionXLPipelineのvaeにおいて、AutoencoderKLが使われていることがわかります。
AutoencoderKLが定義されいているコードは下記です。
AutoencoderKLの学習時は下記のforwardメソッドが使われているはずなので、そちらを確認します。
def forward(
self,
sample: torch.Tensor,
sample_posterior: bool = False,
return_dict: bool = True,
generator: Optional[torch.Generator] = None,
) -> Union[DecoderOutput, torch.Tensor]:
x = sample
posterior = self.encode(x).latent_dist
if sample_posterior:
z = posterior.sample(generator=generator)
else:
z = posterior.mode()
dec = self.decode(z).sample
if not return_dict:
return (dec,)
return DecoderOutput(sample=dec)
上記のコードでは、Encoderはデータxから、posteriorを出力します。これはガウス分布で近似した近似事後分布
その後、posterior.sampleメソッドにより、ガウス分布から潜在表現zをサンプリングしており、その潜在表現をself.decodeメソッドにて画像化していることがわかります。
加えて、self.encodeの中身を見ると下記のようになっています。
@apply_forward_hook
def encode(
self, x: torch.Tensor, return_dict: bool = True
) -> Union[AutoencoderKLOutput, Tuple[DiagonalGaussianDistribution]]:
if self.use_slicing and x.shape[0] > 1:
encoded_slices = [self._encode(x_slice) for x_slice in x.split(1)]
h = torch.cat(encoded_slices)
else:
h = self._encode(x)
posterior = DiagonalGaussianDistribution(h)
if not return_dict:
return (posterior,)
return AutoencoderKLOutput(latent_dist=posterior)
重要なのは、下記の部分です。
h = self._encode(x)
posterior = DiagonalGaussianDistribution(h)
ここでEncoderの出力hには、潜在表現
(詳しくは書かないですが、こちらのEncoder構造の定義スクリプトをご覧ください)
その後、DiagonalGaussianDistributionクラスに、そのパラメータを入力し、近似事後分布
このDiagonalGaussianDistributionクラスのコードはこちらに記載されております。
この中で、上記で使われていたsampleメソッドを確認すると、下記のようになっています。
def sample(self, generator: Optional[torch.Generator] = None) -> torch.Tensor:
# make sure sample is on the same device as the parameters and has same dtype
sample = randn_tensor(
self.mean.shape,
generator=generator,
device=self.parameters.device,
dtype=self.parameters.dtype,
)
x = self.mean + self.std * sample
return x
まさしく、標準正規分布から乱数
以上から、少なくともSDXLにて使われているVAEは、VQ-VAEではなく、一般的なVAEであることがわかります。
Stable Diffusionでは何をやっているのかというと、標準正規分布
すなわち、上述した「VAEの特徴:標準正規分布
Stable Diffusion内部のVAEの特徴
実際、単純な標準正規分布
そのあたりは下記の記事などもご参照ください。
上記の記事中のgifを見ると、最初の方は砂嵐のようなノイズ画像が表示されており、だんだん拡散モデルにより潜在表現
そのときVAEに何が起きているのか!?
これは何が起きているのかというと、第一に、VAEの潜在表現
これは、学習時に、ELBO第2項の正則化項が入っているのにも関わらず・・・です。
正則化項は、下記のコードのDiagonalGaussianDistribution.klメソッドにて計算がされています。
では、なぜVAEの潜在表現
上述した通り、Stable Diffusionの潜在表現
Stable Diffusion XLでは、学習される画像のサイズは「1024x1024」画素が一般的です。
このとき、潜在表現
65536という数字は、MNISTの実験で使っていた2次元の潜在表現の次元数と比較して、非常に大きな次元数であることがわかります。
このレベルで潜在表現
2次元しか潜在表現
しかし、今回の場合は、潜在表現
これは、すなわち正則化項よりも、再構成損失項の方が強いバランスになります。
潜在表現に画像情報を埋め込むことによって、正則化項の損失が大きくなったとしても、その分大幅に再構成損失項の損失を減少させることができるからです。
その結果、潜在表現
その代わり、Stable Diffusionでは、より高品質な画像が生成できるようになっているわけです。
だから拡散モデルがいる
ただし、VAEが正則化項を無視し始めると、画質が良くなる代わりに、潜在表現
この意味のわからない分布を、人間は把握することはできず、その分布からサンプリングした潜在表現
そこで、その潜在表現の事前分布
そして、その学習ずみ拡散モデルが、VAEの潜在表現
(だから、これだけ騒がれて、めちゃくちゃ使われているわけですね)
最後にVAEの課題
ここまでVAEのいいところを説明してきましたが、VAEを単体で利用する場合は、まだまだ課題があります。
Posterior Collapse
一つは「Posterior Collapse(事後崩壊)」の問題です。
これは、VAEの目的関数ELBOの正則化項が強すぎる場合、Encoderが出力する近似事後分布
この場合、画像の再構成情報が完全にDecoderに入ってしまい、潜在表現
posterior collapseの対策として、学習初期は正則化項の寄与率を下げて学習させ、だんだん寄与率を大きくしていくことが挙げられます。
画像がボケやすい
もう一つは、生成される画像がボケやすい点です。
Stable Diffusionに搭載されているVAEのように、事前分布
これは、上述した通り、Decoderに入力される潜在表現
すると、似たような画像
一方で、decoder側は、潜在表現
これは、潜在表現
これの対処法は、VAEの潜在表現の次元を増やすことか、第2項の寄与率を下げるくらいしかありませんでした。
しかし、これを行うと、どうしても生成モデルとしての特徴である、「潜在表現zの事前分布
したがって、バランス調整が難しい問題で、VAEが持つ悪い特徴の一つでしたが、後日記事を書くVQ-VAEでは、この問題を解消しています。
まとめ
ここまで読んでくださってありがとうございました!
生成モデルと言えば、Transformerや拡散モデルが主流ですが、非常に長い系列長(音声など)を生成する場合には、まだまだVAEが使われいてるように見えます。
VAEは一度に全てのデータを生成できるため、速度が必要なアプリケーションにも適していますし、圧縮器としての機能もあるため、大きなデータを潜在表現に圧縮し、その潜在表現をTransformerや拡散モデルによって再構成するといった使い方がよくなされており、古い概念ではありますが、まだまだVAEには価値があるなと感じております。
わかった気になっていましたが、VAEに関して詳細に色々調べていると、まだまだ理解があやふやな部分もあり、記事を書きながら理解度を高めることができました!
この記事が、何らかの形でみなさまの手助けになれば幸いです!
ここまで読んでくださり、ありがとうございました!
参考文献
VAEの論文です。
圧倒的な名著シリーズである「ゼロから作るDeep Learning」シリーズの5作目である、生成モデル編です。
この本では、最終的に拡散モデルを理解することを目的に、VAEや混合ガウスモデル、正規分布まで遡り、本当にゼロから中身を理解しながら実装をすることができる、大変素晴らしい書籍になっています。
本書の後半にもVAEやELBOについての簡単な記載があり、本記事を書くうえで表現を参考にさせていただきました。
確率分布のどの部分が計算可能で、どの部分が計算不可能なのかが常に明示されながら進んでいくので、初学者には非常に分かりやすい書籍でした!
特に、VAEなどの生成AIをただ使うだけでなく、ちゃんと理論を理解したいと思った場合、論文や理論書を理解するために「線形代数」や「微積分学」の事前知識が必要になります。
本書は、初学者が一番最初に読んで必要な基礎知識が習得できる良本になります。
生成 Deep Learning 第2版 ―絵を描き、物語や音楽を作り、ゲームをプレイする
本書の序盤で、Auto EncoderとVAEの違いを説明してくれています。しかもそれぞれの潜在空間の分布を可視化してくれているので、違いが分かりやすく、理解もしやすいです。
さらに、本書はVAEだけでなくGANや画像生成、音楽生成、テキスト生成など、ありとあらゆる生成AIの紹介と解説をしてくれており、必読の一冊となっております。
(書籍のリンクはAmazonアフィリエイトリンクになっております)
Discussion