LLMの性能における重要補題【Johnson–Lindenstrauss lemma】のお気持ち〜Attentionの数式理解を添えて〜
はじめに
本記事は、AI声づくり技術研究会 Advent Calendar 2024の17日目の記事です。
(音声合成関係ないテーマでごめんなさい・・・)
私の好きなyoutuberさんの一人として、「3Blue1BrownJapan」さんがいるのですが、その方の動画で面白い補題について触れていたため、今回はその内容について書きたいと思います。
該当の動画は「LLMはどう知識を記憶しているか | Chapter 7, 深層学習」です。
この動画の後半で「Johnson–Lindenstrauss lemma(ジョンソン-リンデンシュトラウスの補題)」という補題に触れており、興味深い実験も一緒にされております。
今回は、「Johnson–Lindenstrauss lemma」についての簡単な説明と、それが、現在のLLMに対してどう関わってくるのかを自分なりに考察したいと思います。
参考文献
Johnson–Lindenstrauss lemmaについて
書籍:
Pythonではじめる教師なし学習 ―機械学習の可能性を広げるラベルなしデータの利用
(あまりJohnson–Lindenstrauss lemmaについては説明されていないですが、書籍の中で触れているだけで貴重だと思いました。実装方法の説明が軽く記載されています)
動画:
「LLMはどう知識を記憶しているか | Chapter 7, 深層学習」
Webページ:
Johnson–Lindenstrauss lemma:Wikipedia
johnson-lindenstrauss lemma preserves angles:mathoverflow
定理と補題について
書籍:
数学書の読みかた
Attensionについて
書籍:
大規模言語モデル入門
補題と定理とは
まず、そもそも補題(Lemma)とは何なのか?という点が疑問だと思います。
補題は、数学的な命題を表します。
命題とは、真偽が論理的に定まる主張のことを指します。
つまり、この部分だけ見れば、補題(Lemma)と定理(Theorem)は同じです。
しかし、補題と定理、それぞれの役割や目的には違いがあります。
補題は、主に、他の命題の証明を助けるために用いられる補助的な命題です。
つまり、補題が出てきた場合は、その後の重要な定理を導くために、この補題が使われるという意味です。
一方で、定理は、数学的な研究や応用の中心的な命題で、重要性や一般性を持つものです。定理は補題に比べて理論や応用上の重要性が高いものになります。
今回の記事で取り扱うのは、「Johnson–Lindenstrauss lemma」なので、補題の方になります。
こうかくと、重要性の低い命題のように見えますが、そうではありません。
補題として証明された命題の中には、のちに、とても重要な命題だとわかったものもあり、そのような補題は特定の名前で呼ばれることが多いです。
「Johnson–Lindenstrauss lemma」は補題でありながら、数学的にも実用的にも定理に匹敵する、非常に重要な命題の一つです。
Johnson–Lindenstrauss lemma
まずは、wikiに記載されている定義をそのまま書くことにします。
つまり、Johnson–Lindenstrauss lemmaは、高次元空間に存在する点の集合を、距離をほぼ保ったまま低次元空間に埋め込むことができることを保証する数学的な定理です。
式を見てみましょう。
したがって、
上記の式は、写像
距離が変わらないとは?
2点間の距離が変わらないというのは、直感に反します。
例えば、私は以前、主成分分析についての記事を書きました。
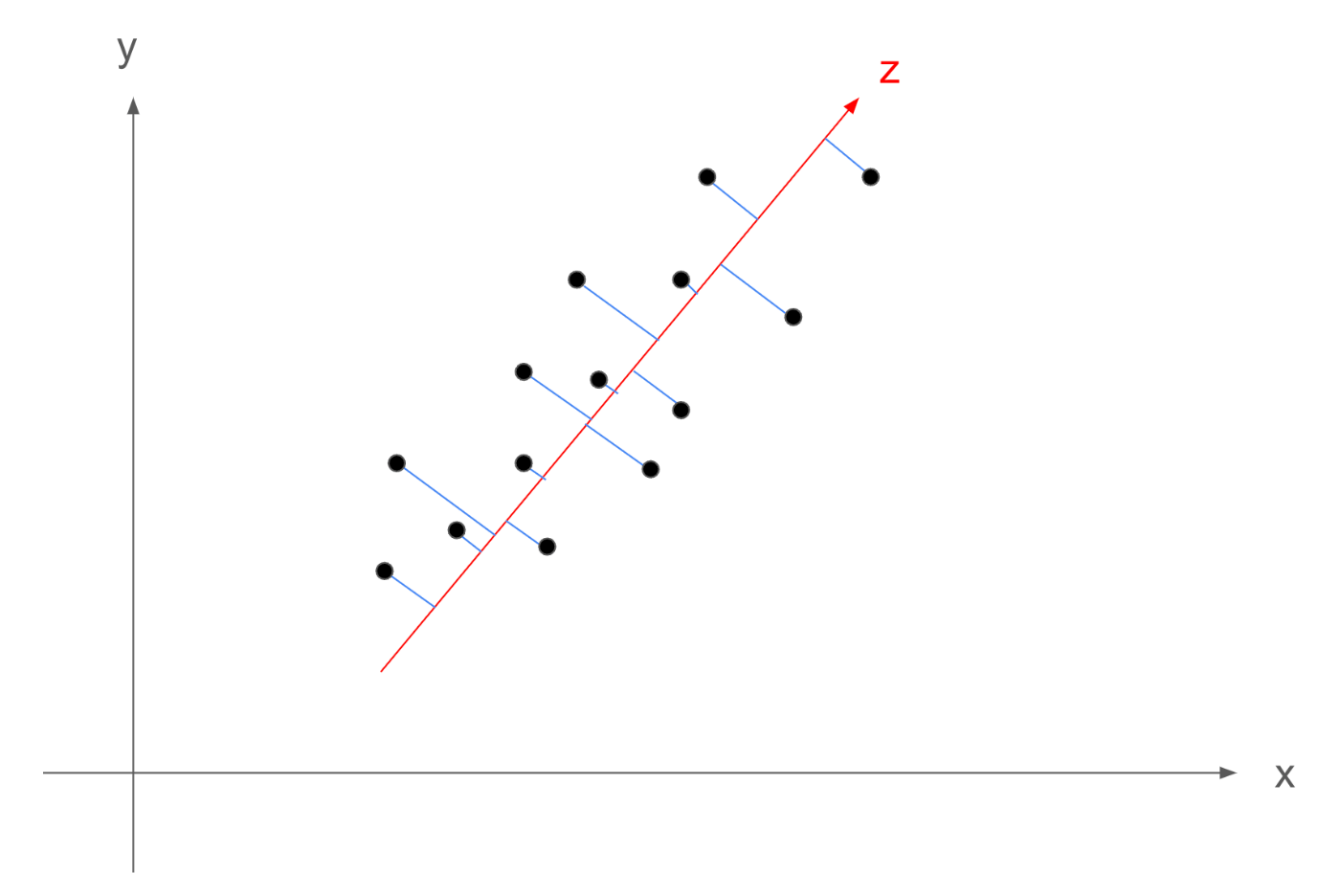
記事中の図の通り(ここでは2次元の図ですが)、次元を圧縮する場合、基本的には、点同士の距離は近くなってしまうことが多いです。
そして、「点同士の距離が短くなってしまう」というのは、情報が削られるという意味です。
次元を削減することで、情報が削られるというのは直感通りです。
しかし、Johnson–Lindenstrauss lemmaでは、高次元空間において、次元を削減しても、2点間の距離は相対誤差
つまり、情報を(ほとんど)保持できる(ような写像
これが、Johnson–Lindenstrauss lemmaが直感に反しており、面白いところです。
距離が変わらないなら、区別・学習ができるということ
距離が変わらないと言うことは、次元削減前後で、異なるクラス間の点を区別する難易度が大きく変わらないことを意味します。
例えば、SVM(サポートベクターマシン)のような機械学習モデルを考えます。SVMはクラス間のマージンを最大化する分離超平面を引き、クラス分類を行います。
Johnson–Lindenstrauss lemmaでは、次元削減前後で、任意の2点間の距離が相対的に保たれることを示しています。
したがって、SVMを考えたときに、次元削減前後で、クラス間のマージンを最大化するような分離超平面を引く難易度が大きく変わらないと言えます。
距離が変わらない=角度が変わらない
Johnson–Lindenstrauss lemmaでは、高次元空間において、「任意」の2点間の距離が、次元削減後もほとんど変わらないような写像
任意の2点間の距離が変わらないということは、ある3点をとってきた時に、その3点が作る三角形の3辺の長さが、次元削減前後で、ほとんど変わらないことを示しています。
「3辺の辺の長さがほとんど変わらない」ということは、余弦定理により、その3点が作る三角形の内角が、次元削減前後で変わらないことを示しています。
詳細は下記をご覧ください。
つまり、Johnson–Lindenstrauss lemmaでは、高次元空間において次元削減前後で、点間の距離と、角度を保存するような写像
角度が変わらない=基底ベクトルが保存される
Johnson–Lindenstrauss lemmaでは、高次元空間において、適切な写像
すなわち、高次元空間における基底ベクトルも、次元削減後に(相対誤差
具体的にいうと、1,000万次元の基底ベクトルは、長さが1のものに限定すると、1,000万個のベクトルが存在するはずです。
それらの基底ベクトルは、互いに直交しているはずです。
Johnson–Lindenstrauss lemmaでは、適切な写像
実験
では、一旦、実験をしてみたいと思います。
ここでの実験は、参考にした動画内で実施していた実験と同様の実験になります。
(コード含め動画に記載されていたものを利用させていただいております)
詳細に知りたい方は動画をご覧ください。
上記の動画では、ランダムな10,000個の100次元ベクトルを用意して、それらのベクトルが89度から91度の範囲にほとんど収まるようなことを示しています。
実際のコード
実際のコードは下記をご覧ください。(興味がある方は実行してみてください)
コード自体は、動画にちょろっと映ったコードを元に記載しております。
加えて、Google ColabのGPUが利用して高速化できるようにしています。
下記の実行結果は、上記のコードを最後まで実行すると得られます。
実行結果
まず、下記に、最適化前のランダムに作成した10,000個の100次元ベクトルから2つの組のなす角度をヒストグラムとして表示すると下記になります。(組の数は99,990,000組)

10,000個のベクトルが100次元空間の中ですべて直交した場合、10,000次元の基底ベクトルの構造が100次元に次元削減しても保存されたと言うことができます。
実際に、最適化を250回実施した後のヒストグラムは下記になります。

上記の通り、89度から91度の範囲内に、ほぼすべてのベクトルの組が入っています。
どの程度入っているかは、下記の通りです
全データ数: 99990000
89度から91度の範囲にあるデータの個数: 98294342
割合:98.30%
したがって、全組のうち98%以上の組み合わせにおいて、ベクトルのなす角が、89度から91度の範囲内に入っていることがわかります。
以上のことから、100次元空間において、10000次元空間の基底ベクトルの構造が保存されていることがわかります。
角度が準直交していることの重要性
さて、ここまでの議論で、Johnson–Lindenstrauss lemmaにおいて、高次元の基底ベクトルが、次元削減のあとでも、準直交の形で構造が保たれることがわかりました。
角度が直交しているとは?
2次元の平面を考えてみましょう。

横軸は、性別を表しており、右に行くと男性、左に行くと女性を示します。
縦軸は、年齢を表しており、上にいくと大人、下に行くと子供を示します。
そのような平面を考えた時に、(男性、女性、男子、女子)の単語を平面に埋め込んだ場合、下記のようなイメージになることが想定されます。

つまり、単語をベクトルとして考えた時に、その平面の軸は、単語を構成する意味を表します。(つまり性別や年齢)
その上で、この2軸にそれぞれ直行している3軸目として、「家族度合い」を表すような軸を追加した場合、「お父さん」や「お母さん」と言った単語も表現ができるようになります。
このように、単語をベクトルとして表現するとき、
全体として次元数分の意味を表現することができる
ベクトル空間上での一点として表現することができます。
つまり、100次元空間上では100の意味を表現でき、10,000次元の空間上では10,000の意味を表現することができます。
これは、
すべての軸(基底ベクトル)が互いに直交している
から成り立っています。
すべての規定ベクトルと直交していないベクトルを考えた時、そのベクトルは基底ベクトルの線型結合で表現することができる(一次従属)ため、基底ベクトルが持つ意味以上の概念を持つことはできないということです。
基底ベクトルが準直交で構造が保たれるとは
NNは、データとパラメータ同士の内積計算をしている
では、この基底ベクトルが準直交で構造が保たれるというのが何が良いのかを考えます。
例えば、全結合層を考えると下記のような線形演算が含まれます。
ただし、
また、バイアスは考えず、
ここで、k行目に着目すると
となり、内積によって表現できることがわかります。
上記では全結合層(の線形変換部分)で考えましたが、CNNの畳み込みでも同じです。
畳み込みは下記の式で表現できます。
ただし、簡単のために1チャンネルを想定しており、また、
-
Z_{i,j} (i,j) -
X_{i,j} (i,j) H \times W -
W_{i,j} (i,j) M \times N
となります。
そして、上記は2次元表示なのでわかりにくいですが、上記の表現もまた、
(補足:この記事内では、ユークリッド内積(高校で習う一般的な内積)のことを内積と呼んでいます)
内積は類似度を判定する
内積は下記の形で表現されます。
ただし、
前節で議論していた内積は、主に、
そして、内積であるならば、
ここで重要なのは、
すなわち、内積は、下記のような性質があります。
- 2つのベクトルが同じ方向を向いている場合(
\theta = 0^\circ \|\mathbf{a}\| \|\mathbf{b}\| - この場合、2つのベクトルは概念として近い
- 2つのベクトルが逆方向を向いている場合(
\theta = 180^\circ -\|\mathbf{a}\| \|\mathbf{b}\| - この場合、2つのベクトルはある概念として正反対
- 2つのベクトルが直交している場合(
\theta = 90^\circ - この場合。2つのベクトルはどの概念を考えても、全くの無関係
これにより、内積とは、2つのベクトルの方向が類似しているかどうかにより、値が変わる指標であると言えます。
したがって、2つのベクトルの方向が類似しているかどうかは、
内積の場合は、厳密にはベクトルの大きさも入ってくるため、内積が大きいから2つのベクトルが類似しているとは必ずしも言えないですが、大まかには同様の解釈をすることができます。
改めて角度が準直交している=次元以上の表現能力を得る
さて、Johnson–Lindenstrauss lemmaに戻ります。
Johnson–Lindenstrauss lemmaは、適切な写像
実際に、前章の「実験」では、100次元のベクトル空間において、10,000個のベクトルのなす角のペアのうち、98.3%の組が準直交していました。
準直交の角度を
(これは
すなわち、準直交している場合、内積の値は、ノルム積に0.01程度の値がかけられることになるため、非常に小さい値になります。
つまり、とても大雑把にいうと、準直交しているベクトルにおいて、その内積を計算した結果は0に近い値が出力されることが期待されます。
上記の話を整理すると、
100次元ベクトル空間において、10,000個のベクトルのほとんどは、互いに準直交していると言えます。
準直交している場合は、内積の結果が0に近くなるため、100次元空間には、約10,000もの独立した表現を組み込むことができていることになります。
これは、100次元空間のすべての軸に対して、準直交のであるベクトルを追加で用意することができることを示しており、結果として、100次元空間に、100以上の意味の概念を与えることができる直感的な説明です。
LLMではどうなのか
さて、ここまでで、Johnson–Lindenstrauss lemmaについての説明と、CNNや全結合層では内積計算をしているため、角度が準直交で保存されることの重要性がわかっていただけたかと思います。
では、LLMではどうなのかについて、記載しようと思います。
LLMではTransfomerと呼ばれる構造が利用されています。
Transfomerは大雑把に分割するとSelf-Attensionと全結合層によって構成されます。
全結合層は上述したため、ここではSelf-Attensionに絞って解説します。
Self-Attensionとは
数式の提示
Self-Attensionは下記で表現されます。
ここでいう
私たちが入力として与えたプロンプトをベクトル化したものを
であり、
という関係性があります。
ここで、
部分ごとに解説
その場合、下記のSelf-Attensionに対して、次の順番に説明していきます。
-
QK^\top -
\sqrt{m} m -
\text{softmax} - 類似度マップと
V
類似度マップの計算
まずは
が入力tokenの内積(類似度)を計算していること QK^\top
を考えます。
となります。
したがって、
すなわち、
と書けます。
したがって、
前述しましたが、内積というのは類似度になります。
下記の通り、2つのベクトル
- 同じ方向を向いている場合(
\theta = 0^\circ \|q_{i}\| \|k_{j}\| - 逆方向を向いている場合(
\theta = 180^\circ -\|q_{i}\| \|k_{j}\| - 直交している場合(
\theta = 90^\circ
となります。
したがって、
標準化
続いて、
それを、
なぜ割るかというと、標準化と同じです。
下記で解説します。
たとえば、
その上で、内積を考えるので、下記のように
それぞれが分散
したがって、
となります。
であるから、
より、各特徴量の分散の積にまでスケールを落とす効果があることがわかります。
逆にいうと、このスケールダウンを行わない場合、分散が次元数
Attensionの計算において、このスケーリングを行わないと、次元数が多い場合に、内積計算時に足し合わされる項が多いので、その分値が大きくなってしまい、Softmaxの計算が不安定になります。
この段階で
Softmaxによる正規化
続いて、
ここでは、最終的に類似度マップを作成したいです。
その上で、Softmaxをかけています。
Softmaxは、行方向もしくは列方向に対して、すべての要素が0以上かつ、総和が1になるように変換してくれます。
すなわち、値を確率として評価できるようになります。
今回、
したがって、ある行に着目したときに、内積の大小関係はそのままに、確率として表現できるように変換してくれます。
下記のように、ある行
ただし、
です。
つまり、
類似度マップとVとの全範囲畳み込み
最後です。
を考えます。
ここでは、ここまでで作成した類似度マップと、入力tokenの(線形変換)の値
実はこれは、全範囲をカバーするカーネルを持つ畳み込みを行っています。
詳しく記載します。
まず、最後の式は下記のように書けます。
ただし、
となります。
ここで前節と同様に、ある行
ここで、
つまり、ある特定のtoken
そして、注目するtokenと変更(
たとえば、ある特定のtoken
その他のtokenとは全く類似していなかった場合は、
そして、次の層では、類似度の高いtokenの特徴量の情報を得られた
これを繰り返すことで、transfomerでは、あるtokenには文章全体の概念が、ベクトルとしてだんだん埋め込まれていくことで文章を処理することができます。
LLMとJohnson–Lindenstrauss lemma
さて、Attensionの計算を見ていく中で、内積や類似度というのがたくさん出てきました。
この内積や類似度は、あくまでベクトル同士のなす角によって計算されます。(
最初に見た通りJohnson–Lindenstrauss lemmaでは高次元空間においては、次元の数以上に準直交という形の構造を持つベクトルを持つことができます。
また、ベクトルが直交しているというのは、概念として合っているわけでも正反対というわけでもなく、全く関係ない概念であるということでした。
以上のことを考えると、仮説ではありますが、LLMにおいて、LLMが持っている次元以上に、準直交という形で、全く関係ない概念を処理することができるということが示唆されます。
もっと知りたいと思ったら
Johnson–Lindenstrauss lemmaによるニューラルネットワークの挙動に関しては、すでに研究されています。
例えば上記の記事中に、下記の言及がございます。
この研究では、多義性の原因が「特徴量の重ね合わせ(スーパーポジション)」にあると仮説を立てています。つまり、言語モデルが限られた次元数の中で、可能な限り多くの特徴量を学習しようとするために、個々のニューロンが複数の意味を担ってしまうというわけです。実際、言語モデルの内部表現を可視化すると、1つの軸方向が複数の意味を持っていることが確認されています。
この、「1つの軸方向が複数の意味を持っている」というのがまさしく、準直交を考えて、ニューラルネットワークが持つ次元よりも多くの特徴を表現していることを示しています。
より詳細に知りたい方は、下記のページをご覧ください。
こちらは「Toy Models of Superposition」という論文のプロジェクトページになります。
こちらの論文では、特にニューラルネットワークの特徴にスパース性があることが、性能減衰なく重ね合わせを可能にしていると言及されており、実際に実験でも明らかにしています。
興味があれば、ぜひご覧ください。
まとめ
ここまで読んでくださってありがとうございます。
まだまだ勉強中の身ではございますが、忘れないうちに現時点での理解をアウトプットしました。
皆様の理解の一助になれば幸いです。
Discussion