ポアソン分布とガンマ分布の関係
動機のための例:信頼区間の紹介
単に母比率の信頼区間というとき,普通は二項分布モデルに基づく信頼区間を指す.二項分布に比べると見かける機会は少ないがポアソン分布でも比率を考えることがある.二項分布のパラメータは上限が 1 なので,上限が明確には決まっていないときはポアソン分布の方が使いやすい.
例えば,単位時間
このようなとき,故障回数や本数
このポアソン分布は比
左辺を
次のように適当な数を選んで R で確認できる.
Ti = 10 #上ではT
r = 0.9
k = 11 #上ではx
> ppois(k-1, lambda = Ti*r, lower.tail = FALSE) #上側(補分布関数)
[1] 0.2940117
> pgamma(r, shape = k, rate = Ti, lower.tail = TRUE) # 下側(分布関数)
[1] 0.2940117
(1)より次の(2)も成り立つ.
この信頼区間は R では poisson.test という関数で実装されている.
> res = poisson.test(x = k, T = tau, r = r, alternative = "two.sided")
> res$conf.int
[1] 0.549116 1.968204
attr(,"conf.level")
[1] 0.95
> c(qgamma(0.025, shape = k, rate = tau),
+ qgamma(0.975, shape = k+1, rate = tau))
[1] 0.549116 1.968204
加えて,ベイズ信頼区間も考えてみる.
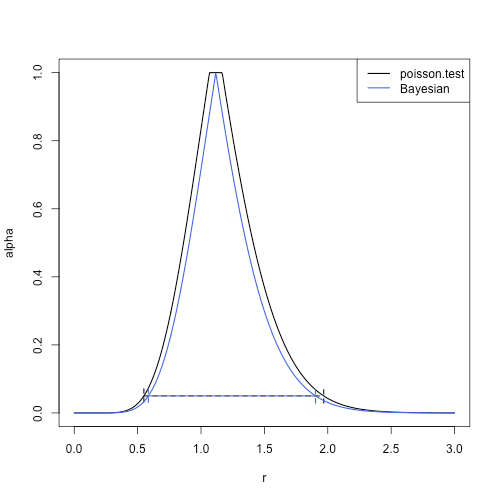
縦軸を
このように出発点の考え方が違っても似た結果が得られるというのは,数理的なことを学ぶ上でおもしろいポイントの一つだと思う.
以上により,(1)の関係を理解したい動機が得られたことにして,次節のシミュレーションに進む.
数値計算してみる
(1) は次のように捉えるとわかりやすい.
過去のイベント発生時刻に依存せず,一定の確率でイベントが起こるとし,イベントの生起間隔が連続型とするとこれは指数分布に従う.
次のようにシミュレーションを書くと「
#イベントの回数を固定し待ち時間をシミュレーション
sim_waitingtime = function(iter, k){
x = numeric(iter)
for(it in seq_len(iter)){
u = 0
j = 1L
while(j < k){
ep = dqrng::dqrexp(1)
u = u + ep
j = j+1L
}
x[it] = u
}
return(x)
}
#待ち時間を固定しイベントの回数をシミュレーション
sim_count = function(iter, tau){
x=integer(iter)
for(it in seq_len(iter)){
u=0
j=0L
while(u < tau){
ep = dqrng::dqrexp(1)
u = u + ep
j = j+1L
}
x[it] = j-1L
}
return(x)
}
下の図で回数はポアソン分布,待ち時間はガンマ分布になることが確かめられる.
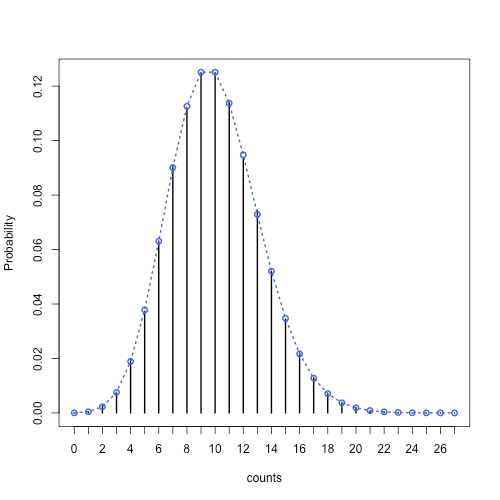
イベントの回数の分布.青いマーカーはポアソン分布の確率関数
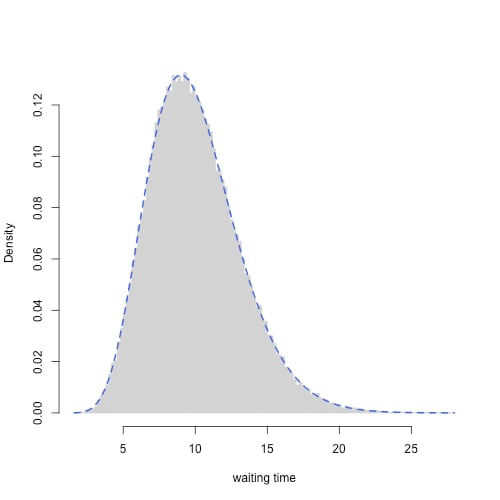
イベントの待ち時間の分布.青い点線はガンマ分布の密度関数
手計算してみる
(1) の左辺を
微分して整理する.
これで (1) がわかった.
関連記事など
指数分布が出てくるところはやや唐突に感じられるかもしれない.ベルヌーイ試行の待ち時間(幾何分布)の連続版として指数分布が出てくることを知ると納得感があるのではないかと思う.これについて,私家版・ポアソン分布の起源 で書いた.
より細かい話として,信頼区間の取り方は一通りではなく,今回の方針は片側P値の小さい方の2倍に対応する.これについては R の exact test についてのノート に書いた.
どの信頼区間を使うのがいいかは議論の余地があるが,こういう「微妙に数値が合わない」みたいな問題への対処としては,とりあえず分析に使ったコードを公開しておくのがいいと思う.
この投稿に使用したコードは以下におく:
Discussion