こんにちは。ZENKIGENデータサイエンスチームの栗原です。現在は面接対話分析など自然言語処理周りの研究開発に携わっています。
所属チームで Xアカウント を運用しており、AIに関する情報を発信していますので、よろしければこちらも覗いてみてください。
現在ZENKIGENでは、LLMを活用して、人と人、人とAIなど、様々なコミュニケーションに関する研究開発を行っています。
その中で、人とAIの対話において、AIが単なる「評価者」や「情報収集者」として一方的に質問を繰り返すだけでは、相手は緊張してしまい、本来の良さや考えを十分に引き出すことができません。まるで経験豊富な面接官やカウンセラーが、時には雑談を交えながら相手の緊張をほぐし、本音を引き出すように、AIにも同様の対話能力が求められます。
つまり、「特定の目的(例:候補者のスキルや価値観の理解)を達成する(タスク指向)」と、「相手がリラックスして話せる雰囲気を作る(雑談)」 という、一見すると相反する要素を両立させる必要があるのです。
そこで今回は、このようなユーザーフレンドリーな目的達成型の対話AIを設計する上で参考となる、「雑談」と「タスク指向対話」の融合に関する論文を3本調査し、まとめました。
Injecting Salesperson’s Dialogue Strategies in Large Language Models with Chain-of-Thought Reasoning
Injecting Salesperson’s Dialogue Strategies in Large Language Models with Chain-of-Thought Reasoning (Chang & Chen, Findings 2024)
概要
これまでの対話システム研究はタスク指向型対話(task-oriented dialogues, TOD)と、オープンエンド型対話(雑談)の2つの "異なる分野" として発展してきましたが、実世界ではこれら2つの対話(TODと雑談)は分離されるものではなく、対話システムにおいても統合が必要です。
本論文は、2022年に提案された、雑談からTOD対話に移行する対話データを生成するセールスパーソン用[1]のフレームワークである「SalesBot(1.0)」に対し、LLMの言語能力を用いてより人間らしい雑談対話と、よりスムーズなTOD対話への移行を行うことを目指し、「SalesBot 2.0」を構築したものです。
SalesBot 2.0
フレームワーク
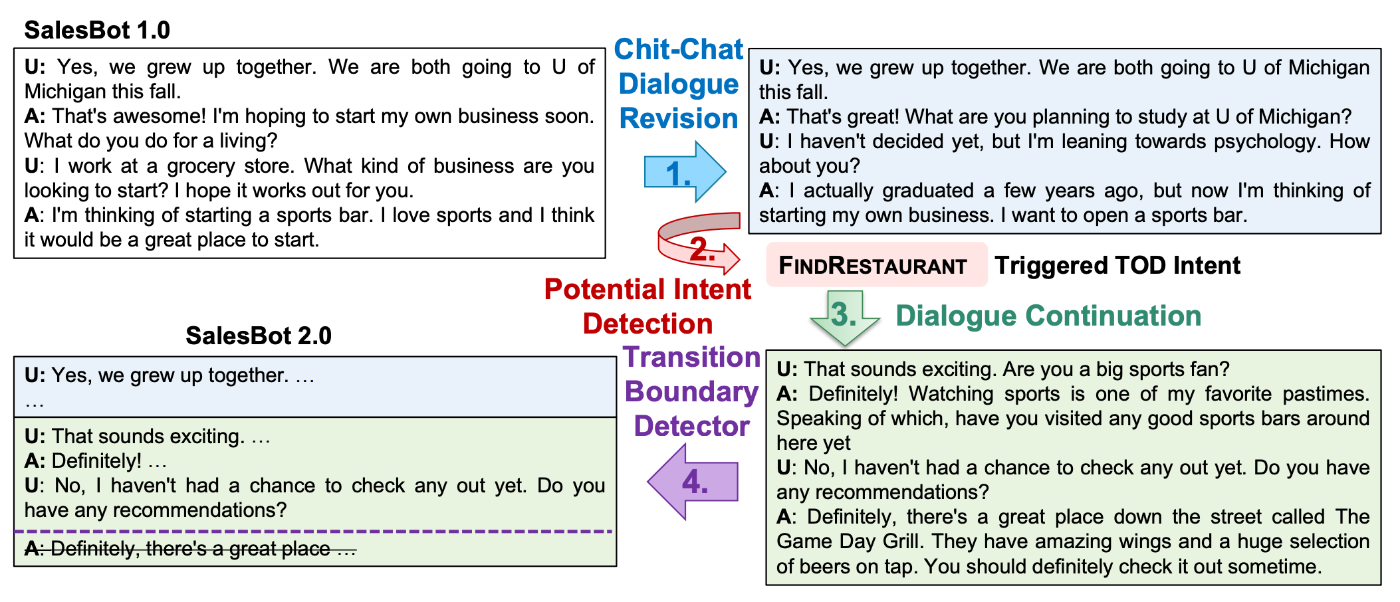
図1: SalesBot 2.0の対話生成パイプライン(論文より引用)
図1は、SalesBot 2.0がSalesBot 1.0を改良し、会話の一貫性の向上とTODへの移行の積極性低減を図るためのパイプラインです。
具体的には、以下4つの手順で構成されています。
-
雑談対話の修正 (Chit-Chat Dialogue Revision):
SalesBot 1.0が文脈との一貫性を欠くデータが多いという問題に対処するため、LLM[2]に一貫性の低い発話を特定させ、対話全体を修正。

図2: Chit-Chat Dialogue Revisionのプロンプトテンプレート(論文より引用)
日本語訳
2人の会話が提示されます。以下の手順に従ってください:
1. 不一致な発言を特定してください。
2. なぜ不一致なのか、その理由をいくつか挙げてください。
3. 事前に特定した発言に基づいて、会話を修正してください。
4. 修正後の会話は6ターン以上である必要があります。
以下が会話です:
<Dialogue>
以下の形式に従って入力してください:
<output_format>
図1との対応:
SalesBot 1.0の対話が、ユーザーの「私たちはミシガン大学に進学します。」という発言に対して「私は近いうちに自分のビジネスを始めてみたいと思っています。」という返答をしていますが、会話の一貫性がなく無理矢理な誘導です。
そこで、Chit-Chat Dialogue Revisionにより、「ミシガン大学では何を勉強する予定ですか?」という、より自然な返答に修正します。
-
潜在的意図の検出 (Potential Intent Detection):
雑談対話から潜在的なタスクに関連する意図を特定。

図3: Potential Intent Detectionのプロンプトテンプレート(論文より引用)
日本語訳
対話文と会話のトピック一覧が提示されます。
以下のトピックのうち、対話の中で最も適切なトピックを選択してください。
以下が対話文です:
<Dialogue>
以下がトピックのリストです:
<Intent List>
注意:
1. 上記のトピックから必ず1つを選択してください。
2. 上記にリストされていないトピックを作成しないでください。
3. トピックと最も関連性の高いものを選択してください。
出力形式は以下に従ってください:
<output_format>
図1との対応:
エージェントの「スポーツバーを開きたいと思っています。」という発言を受けて、FINDRESTAURANTのタスク指向対話のトリガーとしています。
ユーザーが明示的に「レストランを探したい」という意図は示していないですが、雑談の流れの中でエージェントの発話がIntentリスト内の「レストランを見つける(FINDRESTAURANT)」というタスクに関連する潜在的な機会となると判断し、対話をそちら(レストラン探し)の方向に寄せていきます。
-
対話の継続 (Dialogue Continuation):
修正された対話とLLMによって特定された潜在的意図を入力として使用し、雑談対話を続行。


図4: Dialogue Continuationのプロンプトテンプレート(論文より引用)
日本語訳
以下は潜在的な意図(説明付き)と未完成の会話例です:
<Intent>
<Dialogue>
あなたの目標は以下の通りです:
1. 過去の文脈を考慮した合理的な応答で会話を継続する。
2. 上記の意図と暗に関連したトピックで会話を継続する。
3. 移行が難しい場合は、文脈と意図に関連する他のトピックを探し、最終的な移行前に数ターン会話してください。
4. トピックがまだ終了に近づいていない場合は、トピックを継続してください。
5. 各トピックにつき、少なくとも5ターンを生成してください。
6. エージェントは会話をスムーズに転換すべきで、これは転換に長い会話が含まれることを意味します。
7. ユーザーは、転換後の会話で、与えられた意図を何らかの形で言及する必要があります。
8. 会話のトピックを切り替える際は、より適切な表現を使用してください。
9. 対話をタスク指向型スタイル(TOD)で終了し、エージェントが上記で示されたユーザーの意図を満たすようにしてください。
ユーザーとエージェントは意図を明示的に開示せず、対話が自然に潜在的な目的へと導かれるように注意してください。
-----
出力は以下の形式に従ってください:
<output_format>
図1との対応:
FINDRESTAURANTのタスク指向対話がトリガーされたので、レストランの話へ誘導します。
「この辺りで良いスポーツバーに行ったことある?」や、お店の提案("there's a great place down the street called The Game Day Grill.")をしています。
-
移行境界の検出 (Transition Boundary Detection):
TODプロセスを正確に開始するための、検出された意図に関連する発言をユーザーが初めて言及または示唆した発話の特定。この境界で、TODを直ちに開始するか、対話を継続するかを決定する材料にする。

図5: Transition Boundary Detectionのプロンプトテンプレート(論文より引用)
日本語訳
以下の対話文と、その対話文に関連する意図が示されます:
<Intent>
<Dialogue>
あなたの目標は以下の通りです:
1. 上記の意図を明示的に言及している最初の発言を特定してください。
2. 指定された対話文から、1つのターンを選択してください。
3. 選択したターンはユーザーが発言したものとします。
出力形式は以下の通りです:
<output_format>
図1との対応:
FINDRESTAURANTのタスク指向対話に関連するユーザーの発話の位置を特定するもので、図1の例では、ユーザーの "Do you have any recommendations?" が FINDRESTAURANT に関する明確な意図を示す発話として特定しています。
データセット
上記フレームワークにより作成されたSalesBot 2.0は、意図のカバー範囲が改善され、コンテキストとしての雑談対話が長くなり、長い移行ターンが特徴です(図6)。

図6: SalesBot 1.0とSalesBot 2.0の対話ターン数の比較。1.0は雑談からTODへの移行(Trans.)に1ターンであるのに対し、2.0は平均4.55ターンと、ターン数をかけて自然に移行しようとしているのが特徴的。(論文より引用)
SALESAGENT: LLMへの対話戦略の注入
SalesBot 2.0データセットを利用し、SALESAGENTを構築します。
llama-2-7b-chatをベースモデルとして、QLoRAファインチューニングを行います。
ファインチューニング時のプロンプトとして、CoT(Chain-of-Thought)推論を導入します(入力テンプレートは図7)。

図7: CoT推論の入力テンプレート(論文より引用)
日本語訳
ダイアログ履歴:
{dialogue_history}
ユーザーが参照する可能性のある意図のリストです:
{intents}
上記のダイアログ履歴を考慮し、適切な意図を慎重に判断し、適切な応答を提供してください。
出力形式:
思考: <thought>
応答: <response>
モデルは、以下の4種類の思考(Thought)を生成するようにガイドされます。
- ユーザーが潜在的な意図を暗黙的に言及していない場合、雑談を続けるべき。
- ユーザーが{intent}を暗黙的に言及した場合、会話を{intent}のトピックにスムーズに転換すべき。
- ユーザーが{intent}のトピックを変更しなかった場合、トピックを継続すべき。
- ユーザーが{intent}を明示的に示した場合、タスク指向型対話エージェントに進むべき。
このCoTアプローチにより、ファインチューニングされたLLMは設計された戦略に従い、より制御可能で説明可能な対話を提供できるようになると主張しています(図8)。

図8: SALESAGENTがユーザーの応答をどう理解し、対話戦略を選択するかの例。ex. 括弧書き1つ目: "Do you have any hobbies to take your mind off it?"というユーザー発話に対し、SALESAGENTは「ユーザーが潜在的な意図を暗黙的に言及していない」と理解(Understanding)し、「雑談を続けるべき」という対話戦略(Policy)を選択している。(論文より引用)
評価
SalesBot2.0のデータで構築したSALESAGENTを評価するために、ベースラインモデルとして、SalesBot1.0のデータで構築したSALESAGENTと、微調整なしで詳細な指示を与えたllama-2-7b-chatモデルを用いました(ただ、微調整なしモデルは制御性に欠けるとのことで、評価からは除外されたとのことです)。

図9: SalesBot1.0のデータとSalesBot2.0のデータそれぞれで構築したSALESAGENTのターンレベル評価と対話レベル評価。(論文より引用)
GPT-4を用いてターンレベルと対話レベルの両方で評価を行いました(図9)。
ターンレベル評価(Turn-Level)
ターンレベル評価では、SalesBot 2.0がSALESAGENTの意図検出(Intent Detection, 39.61)、ポリシー選択(Policy Selection, 39.05)、それぞれの能力をSalesBot 1.0と比較し大幅に向上させていることがわかります。
対話レベル評価(Dialogue-Level)
平均ターン数(# Turns)とTODへの進行率(Proceed TOD Rate) では、平均ターン数はSalesBot 2.0の方が多く、TODへの進行率はSalesBot 1.0の方が高く100%となっています。
これは、SalesBot 1.0が、多くのシナリオでユーザーが望んでいないにも関わらず、会話を「積極的に」タスク指向対話に誘導する傾向を示唆しています。
対話としての、自然さ (Naturalness), 一貫性 (Coherence), エージェントの一貫性 (Agent Consistency), エージェントの積極性 (Agent Aggressiveness), 滑らかさ (Smoothness) においては、SalesBot 2.0が全ての項目でSalesBot 1.0を大きく上回りました。
A Few-shot Approach to Task-oriented Dialogue Enhanced with Chitchat
A Few-shot Approach to Task-oriented Dialogue Enhanced with Chitchat (Stricker & Paroubek, SIGDIAL 2024)
概要
本論文は、汎用的なLLMをタスク指向対話(TOD)に応用するものです。
few-shotプロンプティングによるアプローチを強化する方法として、関数呼び出しを用いた対話状態追跡(dialogue state tracking, DST)と雑談検出機能を追加することで、システムが自然な会話の流れに対応し、タスク関連の情報と日常会話を区別して処理できるようになることを目指します。
人手評価と自動評価の両方で、この改良されたパイプラインが既存の手法と比較して優れた性能を発揮することが示されました。
手法

図10: 本手法のパイプライン。ユーザーからの発話(ex. "We want to...")に対し、雑談検出(ChitChat Detection)と発話のドメイン検出(Domain Detection)が走り、対話状態としてBase(エンティティとその値を 「entity:value」の形式で抽出。ex. food: Thai), SQL(DBから必要な情報を取得するためのSQLクエリ), Function Call(ツールや外部APIなどを呼び出すための文字列)の3種類の追跡(DST)方法を検証。(論文より引用)
図10が本手法のパイプラインです。以下で各項目のプロンプトを示します。
ChitChat Detection[3]

図11: ChitChat Detectionのプロンプト(論文より引用)
日本語訳
System Message
現在、ケンブリッジのタウンインフォセンターが提供する情報アシスタントをご利用中のユーザーがいます。
このアシスタントは、情報検索や予約業務においてユーザーをサポートします。
これらの業務には特定の専門分野が設定されています。
主な業務分野は以下の通りです:
- 鉄道(列車チケットの予約)
- レストラン(飲食店の検索・予約)
- ホテル(宿泊施設の検索・予約)
- 観光スポット(例:「建築」「スポーツ」「エンターテインメント」「映画館」「博物館」「コンサート」「劇場」...)
- タクシー(ある地点から別の地点へのタクシー手配)
あなたは、ユーザーの発話内容が業務に関連する情報または要求を含んでいるかどうかを判断できる専門家です。
User Message
対話コンテキストとユーザー発話内容に基づき、ユーザー発話を「chitchat」か「task」のいずれかに分類してください。
分類基準は以下の通りです:
ユーザー発話に以下のいずれかが含まれている場合:
- 個人の生活や意見、経験に関するコメント
- ケンブリッジ市や上記の専門分野(レストラン、鉄道、ホテル、タクシー、観光スポット)に関する気軽なコメント
その場合、ユーザー発話は「chitchat」と分類されます。
一方、ユーザー発話に以下のいずれかが含まれている場合:
- 業務分野(レストラン、鉄道、ホテル、観光スポット、タクシー)に関する明示的な情報要求
- 業務分野(レストラン、鉄道、ホテル、観光スポット、タクシー)における特定の行動依頼
- 業務分野(レストラン、鉄道、ホテル、観光スポット、タクシー)に関連する重要な情報
その場合、ユーザー発話は「task」と分類されます。
対話コンテキスト:
ユーザー発話:
Customer: 土曜日にイタリア料理店を探しています。
回答は一語でお願いします。<label>と</label>タグの間に「chitchat」または「task」と記入してください。
Label:
Domain Detection

図12: Domain Detectionのプロンプト(論文より引用)
日本語訳
System Message
あなたは会話型AIであり、ユーザーのリクエストのドメインを特定する能力を持っています。
可能なドメインは以下の通りです:
- 列車予約(列車チケットの予約)
- レストラン検索・予約(飲食店の検索と予約)
- ホテル検索・予約(宿泊施設の検索と予約)
- 観光スポット検索(例:「建築」「スポーツ」「エンターテインメント」「映画館」「博物館」「コンサート」「劇場」「公園」「教会」「ホテル」「ナイトクラブ」「スイミングプール」「大学」「コンサートホール」「ボート」「歴史的建造物」「ギャラリー」「ショッピングエリア」「自然保護区」「スポーツ施設」「テーマパーク」)
- タクシー予約(ある場所から別の場所へのタクシー手配)
回答にはドメイン名のみを記載してください。
User Message
顧客のリクエストに基づいて適切なドメインを選択してください。
回答はドメイン名を1語のみで記載してください。
意思決定を行う際には、顧客の現在のリクエストに焦点を絞ることが非常に重要です。
Context:
Customer: 土曜日にイタリア料理店を探しています。
Domain:
Base DST

図13: Base DSTのプロンプト(論文より引用)
日本語訳
User Message
会話の最後の発話から、例に従ってエンティティ値を取得してください。
最後の発話で言及された値のみを対象としてください。
コロンで区切られ、間にスペースを含まない「entity:value」のペアを取得します。
entity:value のペアはハイフンで区切ってください。
取得すべき値は以下の通りです:
- レストランの価格帯を指定する「pricerange」(安い/中程度/高級)
- レストランの所在地エリアを指定する「area」(北/東/西/南/中心部)
- レストランが提供する料理の種類を指定する「food」
- レストランの名称を指定する「name」
- 予約日を指定する「bookday」
- 予約時間を指定する「booktime」
- 予約人数を指定する「bookpeople」
その他の値は一切取得しないでください!
指定がない場合は、値を空のままにしておいてください。
------
---------------------Example 0:
Context:
Customer: 土曜日にイタリア料理店を探しています。
Assistant: bookday:'saturday’-food:italian’
---------
次に、以下の例を完成させてください:
Context:
Customer: こんにちは。ケンブリッジにあるレストランを探しています。「ゴールデン・ウォック」という名前だったと思います。
SQL DST

図14: SQL DSTのプロンプト(論文より引用)
日本語訳
System Message
あなたはタスク指向型の会話型AIアシスタントです。ユーザーがレストランを予約するのを支援する役割を担っています。有効なSQLiteを使用して、以下に示すテーブルに基づいて、次の複数回にわたる会話形式の質問に答えてください。
CREATE TABLE restaurant(
name text,
food text,
pricerange text CHECK (pricerange IN ('dontcare', 'cheap', 'moderate', 'expensive')),
area text CHECK (area IN ('centre', 'east', 'north', 'south', 'west')),
booktime text,
bookday text,
bookpeople int
)
/*
5 example rows:
SELECT * FROM restaurant LIMIT 5;
name food pricerange area booktime bookday bookpeople
pizza hut city centre italian dontcare centre 13:30 wednesday 7
the missing sock international moderate east dontcare dontcare 2
golden wok chinese moderate north 17:11 friday 4
cambridge chop house dontcare expensive center 08:43 monday 5
darrys cookhouse and wine shop modern european expensive center 11:20
saturday 8
*/
User Message
顧客のリクエストに基づいて、指定されたテーブルから情報を抽出するための有効なSQLクエリを作成してください。必ずセミコロンで終了してください。最後の発話で言及されている値のみに焦点を当ててください。
------
---------------------例 0:
Context:
Customer: 土曜日にイタリア料理店を探しています。
Assistant: SELECT * FROM restaurant WHERE bookday = 'saturday' AND food = 'italian';
---------
それでは、以下の例を完成させてください:
Context:
Customer: こんにちは。ケンブリッジにあるレストランを探しています。店名は「ゴールデン・ウォック」だったと思います。
Function calling DST

図15: Function calling DSTのプロンプト(論文より引用)
日本語訳
System Message
あなたはタスク指向型の会話型AIアシスタントです。ユーザーがレストランを予約するのを支援する役割を担っています。以下の関数定義を使用して、ユーザーの予約に必要な正しい引数を指定して関数呼び出しを作成してください。
{"name": "find_book_restaurant",
"description": "レストランを検索してテーブルを予約する",
"parameters": {
"type": "object",
"properties": {
"pricerange": {
"type": "string",
"description": "レストランの価格帯",
"possible_values": ["安い", "中程度", "高級"],
"default_value": None},
"area": {
"type": "string",
"description": "レストランの所在地エリア",
"possible_values": ["北", "東", "西", "南", "中心部"],
"default_value": None},
...
"call_example": "find_book_restaurant(pricerange=None, area=’中心部', food='イタリアン', name='ピザハット シティセンター', bookday='水曜日', booktime='13:30', bookpeople=7)"
}
User Message
顧客のリクエストに基づいて、正しい関数引数を指定して関数呼び出しを出力してください。必ず関数定義に従ってください。最後の発話で言及されている値のみに焦点を当ててください。
------
---------------------Example 0:
Context:
Customer: 土曜日にイタリア料理店を探しています。
Assistant: <<function>>find_book_train(bookday=’Saturday’, food=’Italian’)
---------
それでは、以下の例を完成させてください:
Context:
Customer: こんにちは。ケンブリッジにあるレストランを探しています。「ゴールデン・ウォック」という名前だったと思います。
評価
評価は主に、自動評価と人手評価の2側面から行われています。
自動評価

図16: 3つの異なるシード値での平均スコアに基づくエンドツーエンド評価結果。*印は、最良の値と第2位の値の間に統計的有意差(p < 0.05、対応のあるt検定)が存在することを示す。黄色行: 先行する教師あり学習結果 △Youngら(2022年)、▲Stricker and Paroubek(2024年)、♣Sunら(2023年)、♢Huangら(2023年)、♡Fengら(2023年)。青色行: 汎用LLMを用いたDSTタスクにおいてfew-shotプロンプティングを採用したもの。緑色行: 様々な機能呼び出しタスク用にチューニングされたモデルの結果。Gorilla-v2はDSTタスク専用に使用されており、応答生成にはLlama3-8B-Instructを採用。応答生成はすべてのケースでfew-shot方式を採用。各Llamaモデルサイズにおける最良の結果は太字で表示。右端: MultiWOZとFusedChatの結果間におけるJGA値の相対的な低下率。(論文より引用)
図16はエンドツーエンドの自動評価の結果です。
3つのベンチマーク(FusedChat, InterfereChat, MultiWOZ 2.2)と、最大5つの評価指標(BLEU, BLEU-aug, JGA, Slot-F1, Success)[4]で評価されました。
主な結果として、関数呼び出しアプローチ(Function calling DST)は、他のアプローチ(Base DST, SQL DST)を一貫して上回るパフォーマンスを示しました。
Llama3-70B-Instructに対し関数呼び出しのfew-shotプロンプティングを採用したものが、以前の教師ありの最先端モデル(Supervised SotA)をJGAで上回ったものの、タスクの成功率は上回っておらず、JGAの改善が必ずしもタスク成功度の向上には繋がらないことが観察されました。
人手評価

図17: 人手評価結果。Clarify: 対話あたりに必要とされた再質問の平均回数。(論文より引用)
人手評価結果を図17に示します。
特徴的なのは、自動評価と比べ、対話成功率(Success)が非常に高い点です。
これは、最新のLLMが持つ対話能力の高さに加えて、雑談とタスクの混合という複雑なシナリオを効果的に処理するための本研究の工夫(特にFunction CallingによるDSTの改善)が、人間評価での成功率向上に大きく貢献したと見ることができます。
An Interactive Monitoring Robot for Dementia Mitigation via Daily Conversations with Multiple LLMs
An Interactive Monitoring Robot for Dementia Mitigation via Daily Conversations with Multiple LLMs (Numao & Kawamura, AAAI Symposium Series 2025)
概要
本論文は、高齢者の認知症の診断と介護負担軽減を目的とした対話型認知機能評価システムの開発を行なったものです。
ユーザーの意図を特定する「Detector」、日常会話を担う「ChitChat」、タスク指向の対話を行う「StrictTask」の3つのモジュール(LLM)で構成されます。
評価実験では、既存のルールベースシステムと比較して、厳密な診断の正確性には課題があるものの、対話の柔軟性、即応性、ユーザーエンゲージメントにおいて優れていることが示されました。
提案システム

図18: 複数LLMによる認知機能評価対話システム概略図(論文より引用)

図19: システムが入力を受け取ってから出力を生成するアルゴリズム(論文より引用)
システムフロー
図18にシステムの概略図、図19にアルゴリズムを示します。
システムは、ユーザーの入力(音声)情報に基づいて、Detectorモジュールがユーザーの意図を評価します。
検出された意図に応じて、システムはChitChatまたはStrictTaskのいずれかをアクティブにし、意図が事前定義されたタスクリストの一部であるかどうかを確認します。
選択されたモデルの出力はConcatChainによって処理され、音声としてユーザーに届けられます。
以降でそれぞれのモジュールについて説明します。
Detector
Detectorはユーザーの意図を決定する役割を担います。
応答の精度を高めるために、複数の例を組み込んだFew-shotプロンプティングが使用されます。Chain-of-Thought(CoT)プロンプトも精度を向上させることができますが、対話履歴全体を渡すと遅延が発生し、会話の流暢さが損なわれるため、採用されていません。
以下図20がDetectorの具体的なプロンプトです。

図20: Detectorのプロンプト[5](論文より引用)
日本語訳
AIは、直近の話題と対話履歴の組み合わせに基づいて、次の話題を推定します。
さらに、直近の話題がHDS-Rの場合、ユーザーが一時停止を要求するまでHDS-Rが引き続き次の話題として提示されます。
・話題推定の具体例:挨拶:「今日の夕食はとても美味しかったです」→食事
・HDS-R:「私は24歳です」→HDS-R
・HDS-R:「自宅です」→HDS-R
・天気:「最近体調が優れません」→健康
・趣味:「音楽を聴くと気分が晴れます」→趣味
・趣味:「わかりません」→趣味
・HDS-R:「終わりました」→終了
・挨拶:「おはようございます」→挨拶
・HDS-R:「一時停止したいです」→一時停止
・挨拶:「診断をお願いします」→HDS-R
上記の例を参考に、以下の直近の話題と対話履歴の組み合わせから、次の話題を推定してください。
ChitChat
ChitChatはカジュアルな対話を生成します。
高齢ユーザーがターゲットグループであるため、プロンプトは日常生活の話題に合わせて調整されています。
さらに、先行研究から、ユーザーエンゲージメントを維持するためにシステムが積極的に話題を導入します。
答えられない質問に直面した場合は「分かりません」と答えるようにシステムが指示されています。
以下図21がChitChatの具体的なプロンプトです。

図21: ChitChatのプロンプト(論文より引用)
日本語訳
深呼吸をしてください。
ケアスタッフとしてのあなたの役割は、利用者の話に耳を傾けることです。
共感を示し、温かく配慮のある言葉をかけてあげてください。
質問には明確かつ簡潔に、2文以内で答えてください。
可能な限り、利用者の興味や関心をより深く知るための質問をしましょう。
もし答えがわからない場合は、「わかりません」と正直に伝えてください。
さらに、回答を裏付ける必要がある場合には、以下の文脈情報を参照してください:
###
施設利用に関するQ&A:{qa_content}
###
StrictTask
StrictTaskはタスク指向の対話を処理するモデルです。
HDS-R評価[5:1]に特化したスロットを用意し、ユーザーへ質問しながらスロットを埋めていきます。
以下図22がStrictTaskの具体的なプロンプトです。

図22: StrictTaskのプロンプト(論文より引用)
日本語訳
AIは以下の条件に基づいて、ユーザーの入力スロットを段階的に埋めていきます:
・ユーザーが「診断してください」や「認知症診断を実施してください」といった依頼を含む発話を行った場合、質問プロセスが開始されます。
・AIは会話形式(対話履歴を参照しながら)で、ユーザーに対して質問を1つずつ順番に投げかけます。
・質問への回答内容に基づき、AIはユーザーの各入力スロットを順次、1つずつ埋めていきます。
・AIは会話を通じて得られた情報をもとに、ユーザーの各入力スロットに適切な値を入力します。
・ユーザーが回答の繰り返しや質問のスキップを求めた場合、AIはそれに応じて対応します。
・ユーザーが「わからない」と回答した場合、AIはヒントを提供するか、次の質問へと進みます。
前提条件:
・スロット6は、スロット5の回答が正しく行われた場合にのみ埋められます。
・スロット8は、スロット7の回答が正しく行われた場合にのみ埋められます。
ユーザー入力スロット:
1. 年齢
2. 本日の年・月・日・曜日
3. ユーザーの現在の所在地
4. 3つの単語(「桜」「猫」「電車」)の繰り返し
5. 計算問題:100から7を引いた値
6. 計算問題:93から7を引いた値
7. 逆順数字スパンテスト(2, 8, 6)
8. 逆順数字スパンテスト(3, 5, 2, 9)
9. 先に繰り返した3つの単語の想起
10. 可能な限り多くの野菜の名称を挙げる
評価
評価として、Suzakiら(2023)が開発した既存のシステムと比較がされました。
Suzakiらのシステムは、ルールベースのアプローチであり、厳密な条件分岐を行うことで一貫した性能を保証しています。
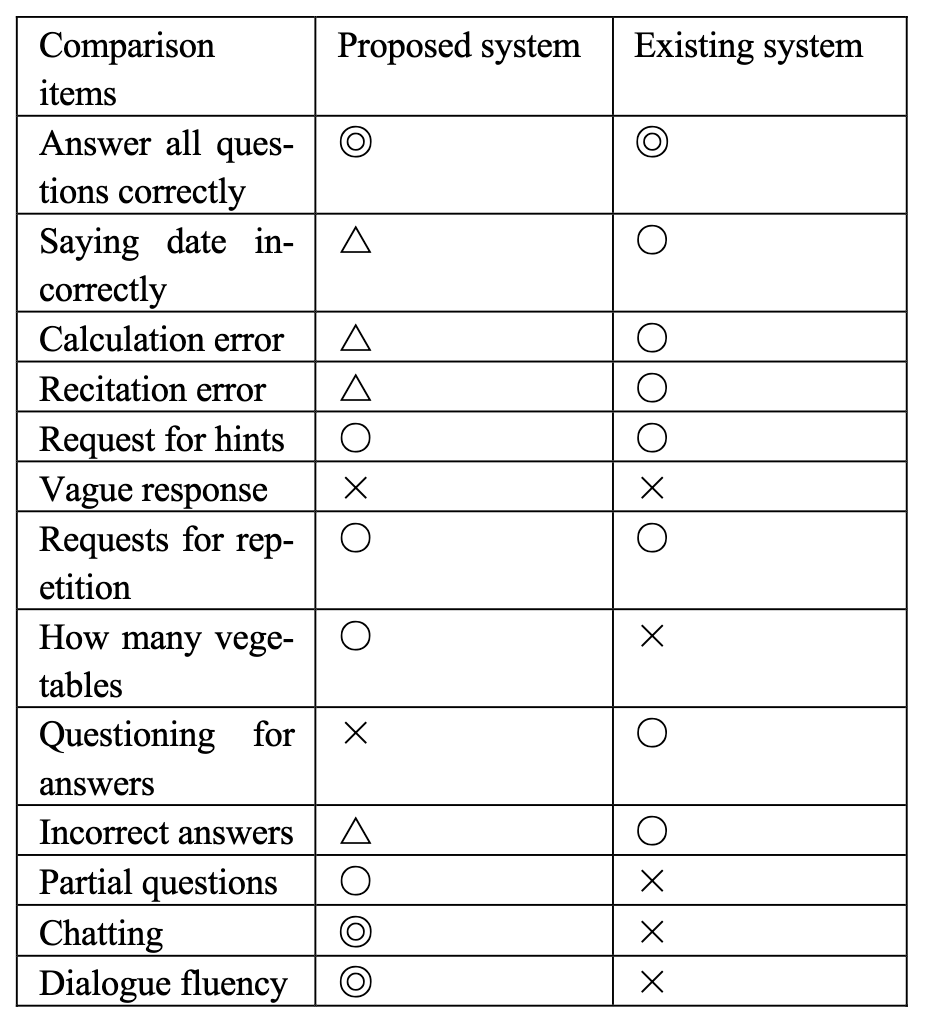
図23: 既存システムとの比較(論文より引用)
図23が比較結果です。
提案システムはユーザーの割り込みへの柔軟な対応やユーザー入力への適応性を示したとのことです。
一方で、厳密な条件分岐に関しては、既存システムと比較して精度が低いことが示されました。
これは、既存のシステムが事前に応答パターンを定義することで一貫した性能を保証するルールベースのアプローチを採用しているためです。
提案システムは自由形式の対話において強みを発揮しましたが、厳密に制御された診断コンテキストでは信頼性が低い場合がありました。
この比較により、提案システムは対話品質(柔軟な応答、即時反応、魅力的な雑談機能)の面で従来のシステムを大幅に上回ることが示され、ユーザーフレンドリーな認知機能評価ツールとしての強みが示されました。
まとめ
今回は、「雑談」と「タスク指向対話(TOD)」の融合を目指した3本の論文をご紹介しました。
Injecting Salesperson’s Dialogue Strategies in Large Language Models with Chain-of-Thought Reasoning は、セールストークという具体例を通して、CoT(思考の連鎖)を用いて対話戦略自体をモデルに学習させ、いかに自然に雑談から本題へ移行するかに焦点を当てていました。
A Few-shot Approach to Task-oriented Dialogue Enhanced with Chitchat は、Few-shotプロンプティングを主軸に、特にFunction Callingを用いることで対話の状態(どこまでタスクが進んだか)を正確に追跡するアプローチの有効性を示しました。
An Interactive Monitoring Robot for Dementia Mitigation via Daily Conversations with Multiple LLMs は、認知症診断という応用場面で、役割の異なる複数のLLM(意図検出、雑談、タスク遂行)を組み合わせるアーキテクチャを提案し、対話の柔軟性を高めていました。
これらの研究は、目的は共通していても、「対話戦略の注入」「対話状態の正確な管理」「役割分担によるシステム設計」 といった異なる角度からアプローチしており、興味深いです。
目的達成の効率だけを求めれば、対話は無機質になりがちです。一方で、ただ楽しいだけの雑談ではビジネス上の目的は達成できません。これからの対話AIには、今回紹介したような研究を参考に、目的達成と優れたユーザー体験を両立する対話設計 がますます重要になると感じました。
私たちのチームでも、これらの知見を活かし、ユーザーがもっと自然に、そして心地よく対話できるAIの開発を進めていきたいと思います。
お知らせ
少しでも弊社にご興味を持っていただけた方は、お気軽にご連絡頂けますと幸いです。まずはカジュアルにお話を、という形でも、副業を検討したいという形でも歓迎しています。
-
セールスパーソンは、雑談から開始してユーザーの興味に合わせて商品を提案するという、雑談とTODの統合を検討するのに適したドメインでしょう。 ↩︎
-
4つの手順全てで gpt-3.5-turbo を使用。 ↩︎
-
ChitChat Detectionによりユーザー発話を「chitchat」と判断した場合は雑談を継続します。その際のプロンプトは以下:
 「task」と判断した場合は、Domain Detection以降のフローが走ります。 ↩︎
「task」と判断した場合は、Domain Detection以降のフローが走ります。 ↩︎ -
BLEU, BLEU-aug: 応答品質評価。Joint Goal Accuracy (JGA), Slot-F1: 対話状態予測性能評価。Success rate: 対話全体の成功率を評価。 ↩︎ -
HDS-R(改訂長谷川式簡易知能評価)とは、特定の質問項目(具体的な質問項目はこちら)への回答の結果として点数が20点以下だった場合、認知症の疑いありと評価するものです。 ↩︎ ↩︎

Discussion