はじめに
こんにちは。ZENKIGENデータサイエンスチームの栗原です。現在は『harutaka EF(エントリーファインダー)』の自然言語処理周りの研究開発などに携わっています。
ZENKIGENでは面接や自己PR動画などの動画データを扱うことが多く、そこから言語情報を解析する上で、ASR(Automatic Speech Recognition, 自動音声認識)技術を多く利用しています。
その際に問題となるのが音声認識誤りです。
応募者や面接担当者の発言内容の書き起こしが誤っていることでうまく解析できないことは大きな問題となり得ます。
そのため、現在我々はASRモデルの出力を訂正する技術に注目し、検討を進めています。
今回は、ここ数年の音声認識誤り訂正の論文を10本ピックアップし、まとめ(1本詳説、9本概説)てみました。
UCorrect: An Unsupervised Framework for Automatic Speech Recognition Error Correction [Guo+, ICASSP2023]
概要
UCorrectはASR誤り訂正のための教師なしフレームワークで、以下の3つのパートからなります。
- Detector
入力の書き起こし文字列から誤りである箇所を検出する検出器。 - Generator
Detectorが検出した誤り候補に対して訂正候補を生成する生成器。 - Selector
Generatorが生成した訂正候補から最も信頼性の高いトークンを選択して誤りトークンを置き換える選択器。
実験により、ASR誤り訂正におけるUCorrectの有効性が示されました。
- 微調整なしでも6.83%、微調整後では14.29%という大幅なWER削減を達成。
- 一般的なNAR(non-autoregressive)補正モデルよりも大きなマージンを持ち、競争力のある低遅延を実現。
- 異なる復号戦略を持つASRモデル全てでWERの削減、異なるデータセットで学習したASRモデルの全てでWERの削減を達成。データセットやASRモデルに依存しない普遍的な手法。
自動音声認識誤り訂正の導入
自動音声認識(Automatic Speech Recognition, ASR)誤り訂正は、本論文では、ASRのWER(Word Error Rate, 単語誤り率)を下げるための研究とされています。
ASR誤り訂正のタスク設定
一般的にASR誤り訂正はSeq2Seqのタスクとして取り組まれており、入出力は以下の通りです。
- 入力 : ASRモデルが音声を書き起こした文
- 出力 : 書き起こし誤りを訂正した文
ASR誤り訂正の一般的な手法
手法としては、end2endの生成モデルを採用することが一般的で、大きく2パターンに分かれます。
- AR(autoregressive, 自己回帰)モデル
👍 大きなWER削減を達成できる傾向。
🤔 デコード速度が遅い。 - NAR(non-autoregressive, 非自己回帰)モデル
👍 ターゲット側(デコード側)でトークンを並列生成することで高速化できる。
🤔 ARモデルより精度は悪くなる傾向。
ASR誤り訂正の課題
end2endの教師あり誤り訂正モデルにおける課題をいくつか挙げています。
学習データの課題
ASR誤り訂正の教師データの作成方法は大きく2パターンとなっています。
- Pseudo(擬似)ペアデータ
クロールしてきたテキストデータに対し、テキスト内のトークンをランダムに削除、挿入、置換を行ったものをソースとし、元テキストをターゲットとするペアデータ。 - オリジナルペアデータ
ソースをASRモデルの出力、ターゲットを人間が修正した正解文字起こしとするペアデータ。いくつかデータセットが存在(著者らが中国語を対象として研究しているため、中国語のデータセットが挙げられています)。-
AISHELL-1
中国語の音声-書き起こし対コーパス。 -
WenetSpeech
YouTubeとPodcastから収集された10,000時間以上のマルチドメイン書き起こし北京語音声コーパス。
-
AISHELL-1
これら2つのペアデータ(擬似ペアデータ、オリジナルペアデータ)による学習には課題があると述べられています。
- 擬似ペアデータ
エラー分布が実データのエラー分布と一致しない可能性が高くなります。これにより、擬似ペアデータで学習しただけの誤り訂正モデルはオリジナルのASRモデル出力よりもWERが悪くなることさえあるとしています。 - オリジナルペアデータ
ソースを作成するASRモデルに依存することになり、使用したASRモデル固有のASR誤り訂正用データセットとなってしまいます。
訂正結果の制御の課題
end2endモデルは説明可能性に乏しく、出力結果を制御することが難しいことを挙げています。
最近ではASRモデル自体の精度が高くなっているので、誤り自体が少なく、正しい文字を変更される可能性が高くなります。
そのような場合に説明可能性に乏しいことは深刻な問題になると述べており、本論文ではFAR(False Alarm Rate)を利用し、訂正する必要のない箇所を誤って訂正した率でも検証を行っています。
本論文の立ち位置
本論文は、BERTベースのDetector-Generator-SelectorフレームワークであるUcorrectの提案となっています。
貢献として以下を挙げています。
- 教師なしのフレームワークであり、ペアデータに依存しない手法であること。
- ファインチューニングの有無に関わらず訂正精度を大幅に向上し、低いレイテンシを実現。
- 説明可能性が高く、FARを減らすことができる。エラーが検出された後、モデルは正しい修正を行える可能性が高くなる。
以上がASR誤り訂正研究の導入と、その中での本論文の立ち位置になります。
ここから、本論文の提案手法 Ucorrect の詳細に入ります。
Ucorrectのアーキテクチャ
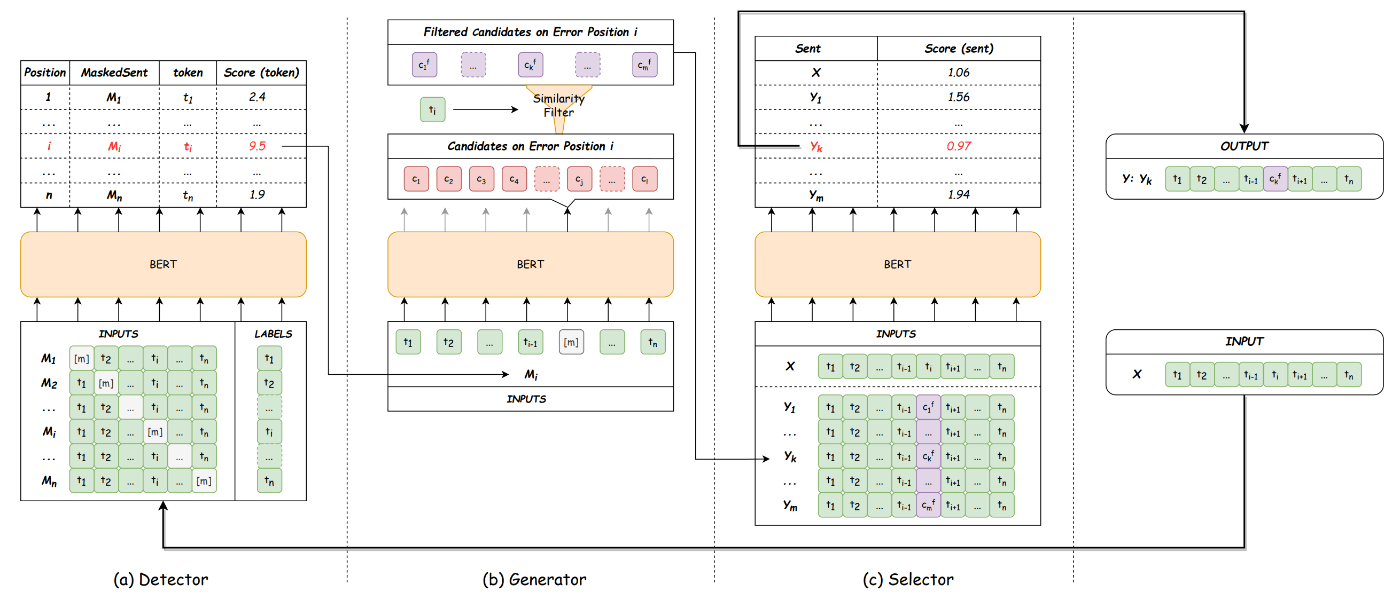
図1: Ucorrectのアーキテクチャ概要。論文から引用。
Ucorrectは図1のように、Detector-Generator-Selectorからなるパイプラインです。
以下でそれぞれについて説明します。
Detector
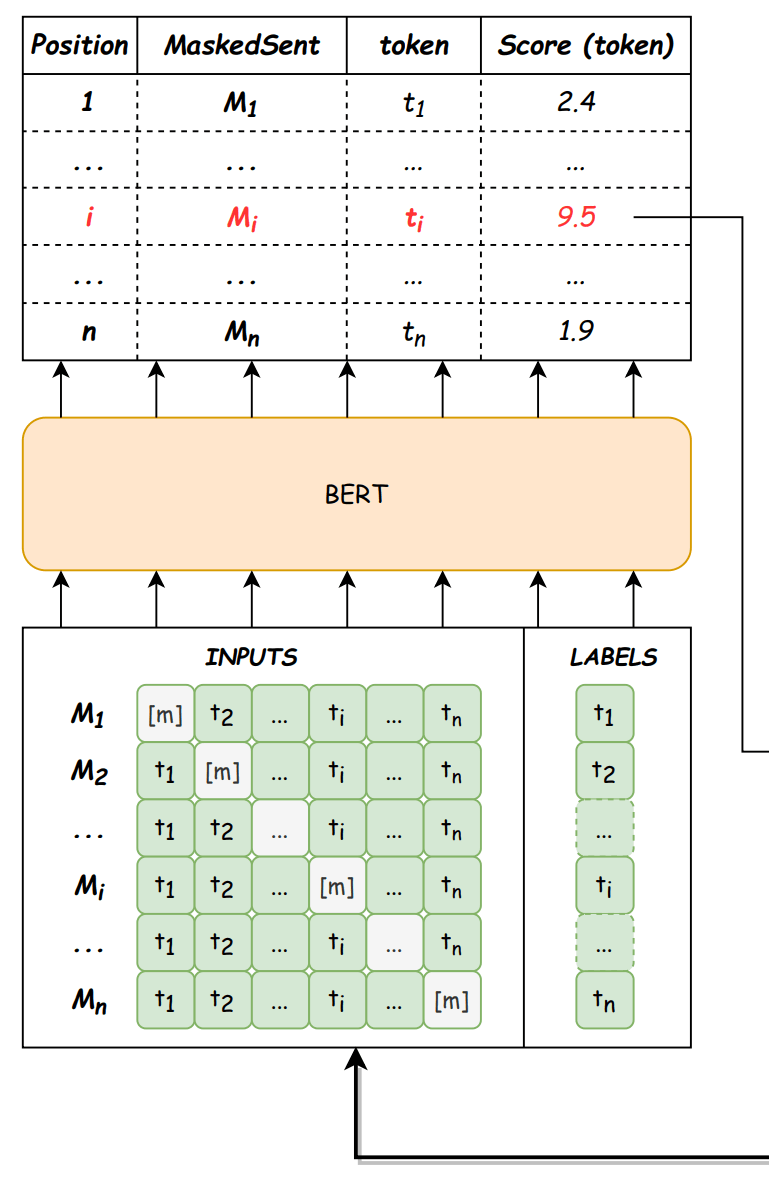
図2: Detector。論文から引用。
Detectorの入出力は以下の通りです。
- 入力 :
n X=(t_1, t_2, ..., t_n) - 出力 : 書き起こし誤りと判断できるトークン位置
i [m] M_i=(t_1, t_2, ..., t_{i-1}, [m], t_{i+1}, ...t_n
フローは以下の通りです。
- 入力の各トークンを1つずつマスクトークン
[m] {M_1, M_2, ..., M_i, ..., M_n} - BERTを利用し、マスク済み系列とマスクされた位置にある元トークンとの尤度をトークンスコアとして計算し、最もスコアが高い系列をマスクされた位置が誤っている可能性が高い系列として選択します。トークンスコア関数は以下の通りです[1]。
Generator
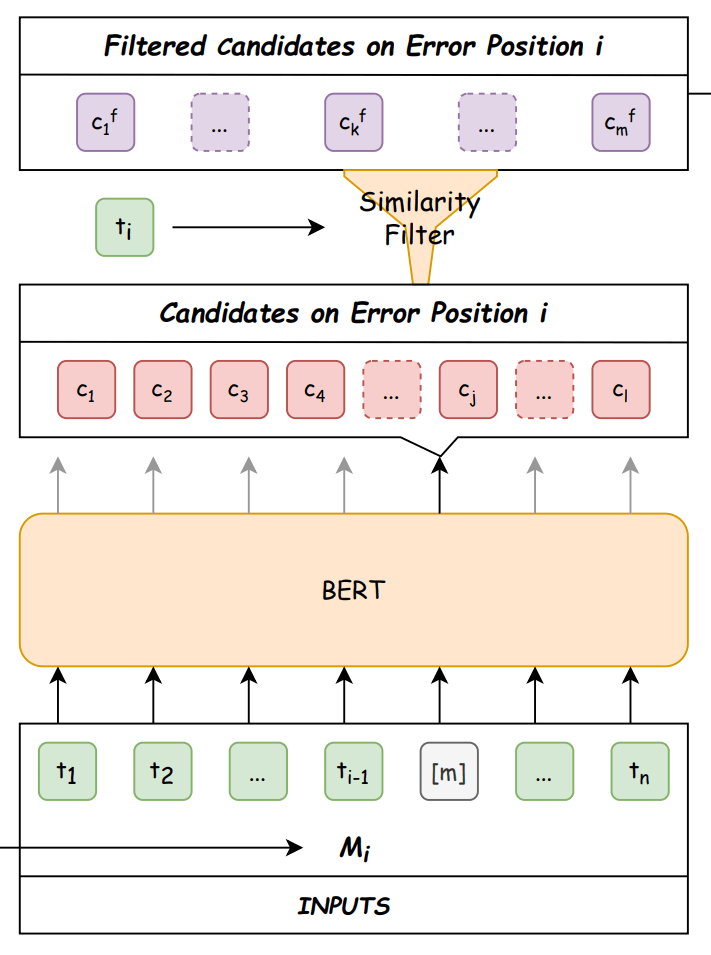
図3: Generator。論文から引用。
Generatorの入出力は以下の通りです。
- 入力 : Detectorが誤りを含むと推定し、誤り推定位置をマスクした系列
M_i=(t_1, t_2, ..., t_{i-1}, [m], t_{i+1}, ..., t_n) - 出力 : マスクトークン
[m] m \mathcal{Y}=\{Y_1, Y_2, ..., Y_k, ..., Y_m\}
フローは以下の通りです。
- BERTで入力系列中のマスクトークンに挿入されるトークン候補を
l \mathcal{C}=\{c_1, c_2, ..., c_j, ..., c_l\} - マスクトークン
[m] t_i m \mathcal{C}^{f}=\{c_1^{f}, c_2^{f}, ..., c_k^{f}, ..., c_m^{f}\} - それぞれの
c_k^f M_i [m] \mathcal{Y}=\{Y_1, Y_2, ..., Y_k, ..., Y_m\}
Selector
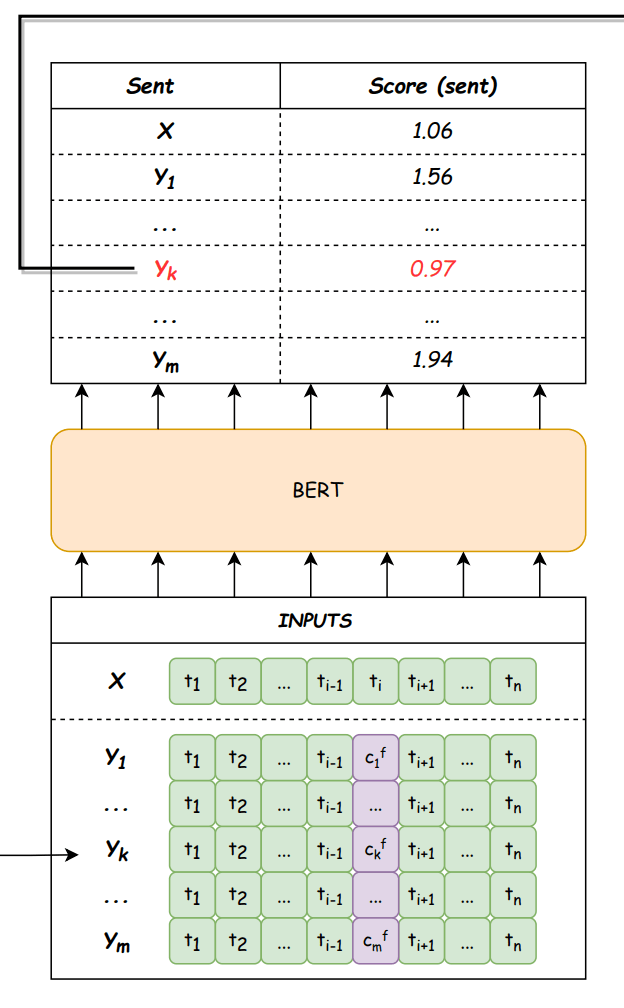
図4: Selector。論文から引用。
Selectorの入出力は以下の通りです。
- 入力 : マスクトークン
[m] m \mathcal{Y}=\{Y_1, Y_2, ..., Y_k, ..., Y_m\} - 出力 : 訂正候補系列集合と元系列の集合
\mathcal{Y} \cup \{X\}
スコア計算関数は以下の通りです。
以上がUcorrectのフレームワークになります。
実験
データセット
中国語の2つのデータセットで実験を行っています。
-
AISHELL-1
- 中国語(北京語)の音声-書き起こし対コーパス。
-
WenetSpeech
- YouTubeとPodcastから収集された10000時間以上のマルチドメイン書き起こし北京語音声コーパス。
ASRモデル
ASR誤り訂正モデルの入力となる音声認識結果を出力するASRモデルとして、以下の2モデルを利用しています。
-
Conformer
- CNNとTransformerを組み合わせることで、音声のローカルおよびグローバルな依存関係をパラメータ効率の高い方法でモデル化する手法。
- ESPnet toolkit(espnet)を利用し、AISHELL-1データセットで学習。ASRモデル性能改善のためのいくつかのデータ拡張テクニック(SpecAugment, Speed perturbation)を利用。
-
U2++
- 音声認識のための双方向エンドツーエンドモデル。U2モデルを拡張し、双方向デコーダによる精度向上と、新たなデータ拡張手法による堅牢性の向上を実現。
比較対象となる既存ASR誤り訂正システム
比較対象となるASR誤り訂正システムとして、NAR(non-autoregressive, 非自己回帰)モデルとAR(autoregressive)モデルを使用しています。
- NARモデル
-
LevT(Levenshtein Transformer)
- 編集操作(挿入、削除、置換)を通じてテキストの変換を学習するテキスト生成モデル。ASRモデルとして学習して検証に利用する。
- FastCorrect
-
LevT(Levenshtein Transformer)
- ARモデル
- Transformerベースのモデル。
実験結果
既存ASR誤り訂正システムとの比較
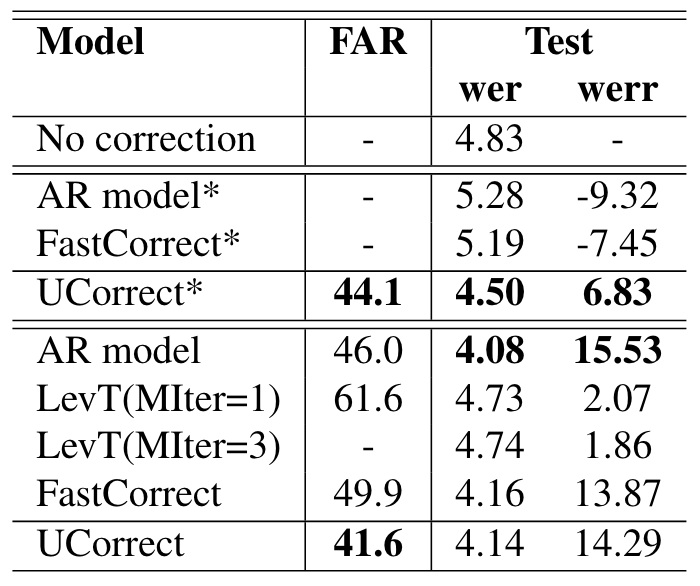
図5: AISHELL-1データセットの音声に対するConformer ASRモデルの出力の訂正精度比較。* はファインチューニングなしの結果。論文から引用。

図6: AISHELL-1データセットの音声に対するConformer ASRモデルの出力の訂正におけるレイテンシ比較。論文から引用。
図5より、提案手法は、ファインチューニングなし(UCorrect*)で、他のファインチューニングなしモデルがWERが増加している(訂正前がWER=4.83のところ、5.28や5.19)中で、WERの削減(4.83→4.50)を達成しています。
さらに、ファインチューニング後では、提案手法が最も低いFAR(false alarm rate, 間違って訂正した率)を達成しています。
図6より、提案手法はレイテンシが低く、ARモデルと比較し4倍以上高速になっています。FastCorrectに速度は及ばないものの、精度と速度のバランスが良い手法となっています。
様々なASRモデルの出力に対する有効性
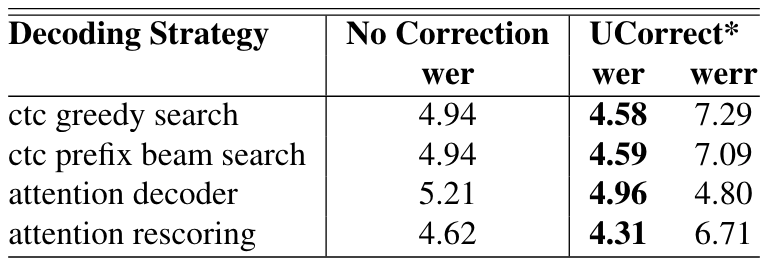
図7: 様々なデコード戦略でのU2++ ASRモデルの出力に対し、Ucorrect(ファインチューニングなし)で訂正させた場合のWER。論文から引用。
デコード戦略の異なる4つのASRモデルに対しUCorrectでの訂正を試み、どの戦略でもWERの減少を確認しています。
特定のASRモデルに寄らない普遍的な訂正システムであることを示しています。
様々なASRデータセットでの評価
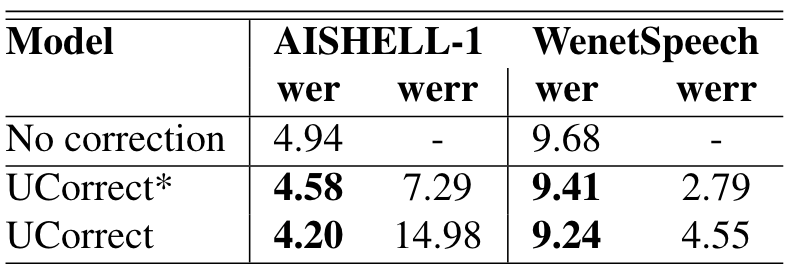
図8: AISHELL-1, WenetSpeechそれぞれのデータセットの音声に対する U2++ ASRモデル(デコード戦略 : ctc greedy search)の出力の訂正精度。* はファインチューニングなしの結果。論文から引用。
データセットによらず、UCorrectは有効であることを確認しています。
以上、ASR誤り訂正システムUcorrectの紹介でした。
アイデアはシンプルながら、競争力のある実験結果になっていると思います。
いくつか気になった点を挙げます。
- いくつかハイパラ(候補生成数など)がありますが、それについて論文中に記載がないためどのような値を設定しているのか(すると良いのか)が気になりました。
- 基本的に1つの音声認識結果に対し、1つの訂正を想定したアーキテクチャになっているように思えますが、実環境だと複数訂正箇所があることは普通にあるため、その辺りの言及もあれば嬉しかったです。
- Generatorにおける類似度計算に利用している部分が中国語特有になっており、その他言語(日本語、英語)ではどうすればよいか(他言語適用)は課題かなと感じました。
ここからは、その他ここ数年のASR誤り訂正研究の論文を9本[4]簡単に紹介したいと思います。
大きく3つのアプローチに分類されるかなと思いました。
- 効率化系
推論速度や学習の効率化系の研究。 - LLM活用系
最近の大規模言語モデル(Large Language Model, LLM)を利用し、LLMの高度な言語知識を活かそうとする研究。 - クロスモーダル系
テキスト情報だけでなく、ASRモデルの入力となっている音声情報も活用し、ASR誤り訂正を行う研究。
それでは、概説していきます。
効率化系の研究
FastCorrect: Fast Error Correction with Edit Alignment for Automatic Speech Recognition [Leng+, NeurIPS2021]
FastCorrectは速度と精度のバランスを追求した非自己回帰型ASR誤り訂正モデルです。
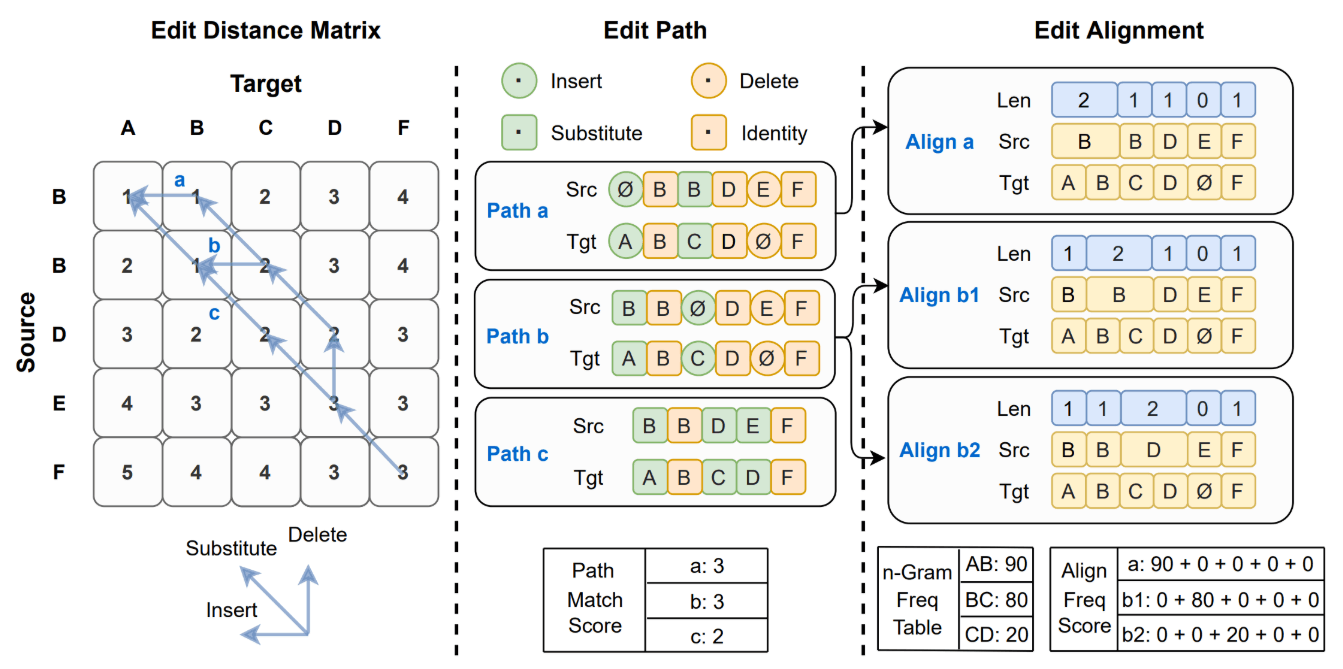
図9: FastCorrectが誤り訂正を行うフロー。ソース(ASRモデル出力系列)とターゲット(誤りのない正解系列)の編集距離行列を構築(図左)し、編集距離最小のパスを選択(図中央)、編集アライメントを得て頻度に基づくスコアリングにより誤り訂正の指針とする(図右)。論文から引用。

図10: FastCorrectのモデル構造。論文から引用。
編集距離に基づいてソース文とターゲット文の各トークン間の編集アラインメント(挿入、削除、置換)を抽出し、エラー訂正の指針とするアプローチです。
実験の結果、FastCorrectは従来の自己回帰型モデルに匹敵する精度を維持しながら、推論速度を6~9倍向上させることを示しました。
また、機械翻訳やテキスト編集用に提案された既存の非自己回帰型モデルよりも優れた性能を示しました。
Mask the Correct Tokens: An Embarrassingly Simple Approach for Error Correction [Shen+, EMNLP2022]
本手法は、元々音声認識の誤り率は低い(入力の10%程度など)傾向にある中で、既存の誤り訂正モデルは限られた誤りトークンに対してしか訂正を学習できず、ほとんどのトークン(正しいトークン)に対しては単純なコピーをするのみとなり、誤り訂正の効果的な学習が阻害される点に注目しています。
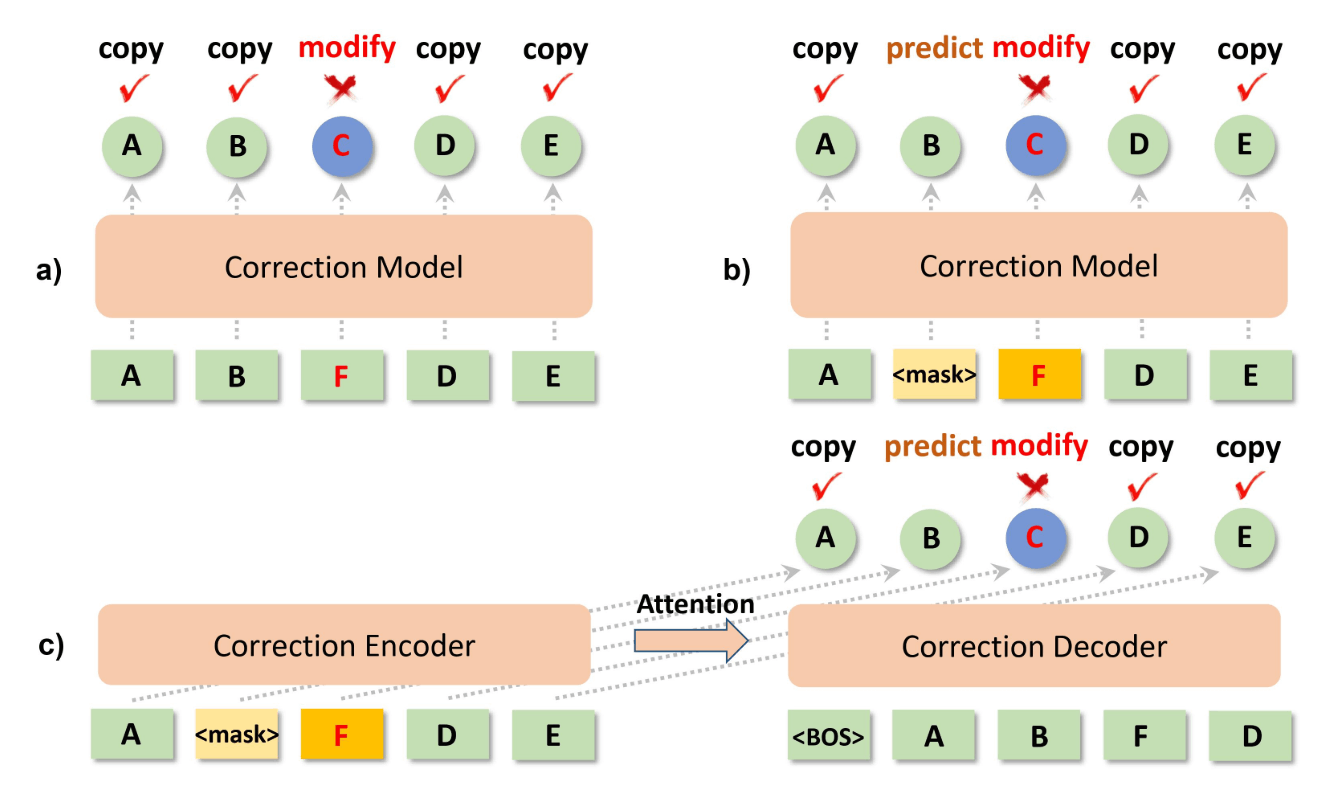
図11: (a):従来の誤り訂正フレームワーク。誤っているトークンを訂正するモデル。誤り箇所は一般的に数が少なく学習効率が悪いという主張。(b)(c):提案手法(自己回帰型と非自己回帰型)。ランダムに正しいトークンをマスクし、その箇所は元のトークンを予測するよう学習することで学習効率を上げる狙い。論文から引用。
誤り訂正の学習を効率化するために、正しいトークンを一部ランダムにマスクし、正しい元のトークンを予測する方法を提案しました。
スペル誤り訂正と音声認識誤り訂正、英語データセットにおける文法誤り訂正において、自己回帰型と非自己回帰型の両方の生成モデルを用いて実験を行った結果、本手法が一貫して訂正精度を向上させたと報告しています。
ASR Error Correction with Constrained Decoding on Operation Prediction [Yang+, Interspeech2022]
本論文は、encoder-decoderアーキテクチャに基づく既存のend-to-endの誤り訂正手法は、デコードフェーズですべてのトークンを処理するため、推論速度が遅いことに着目しています。
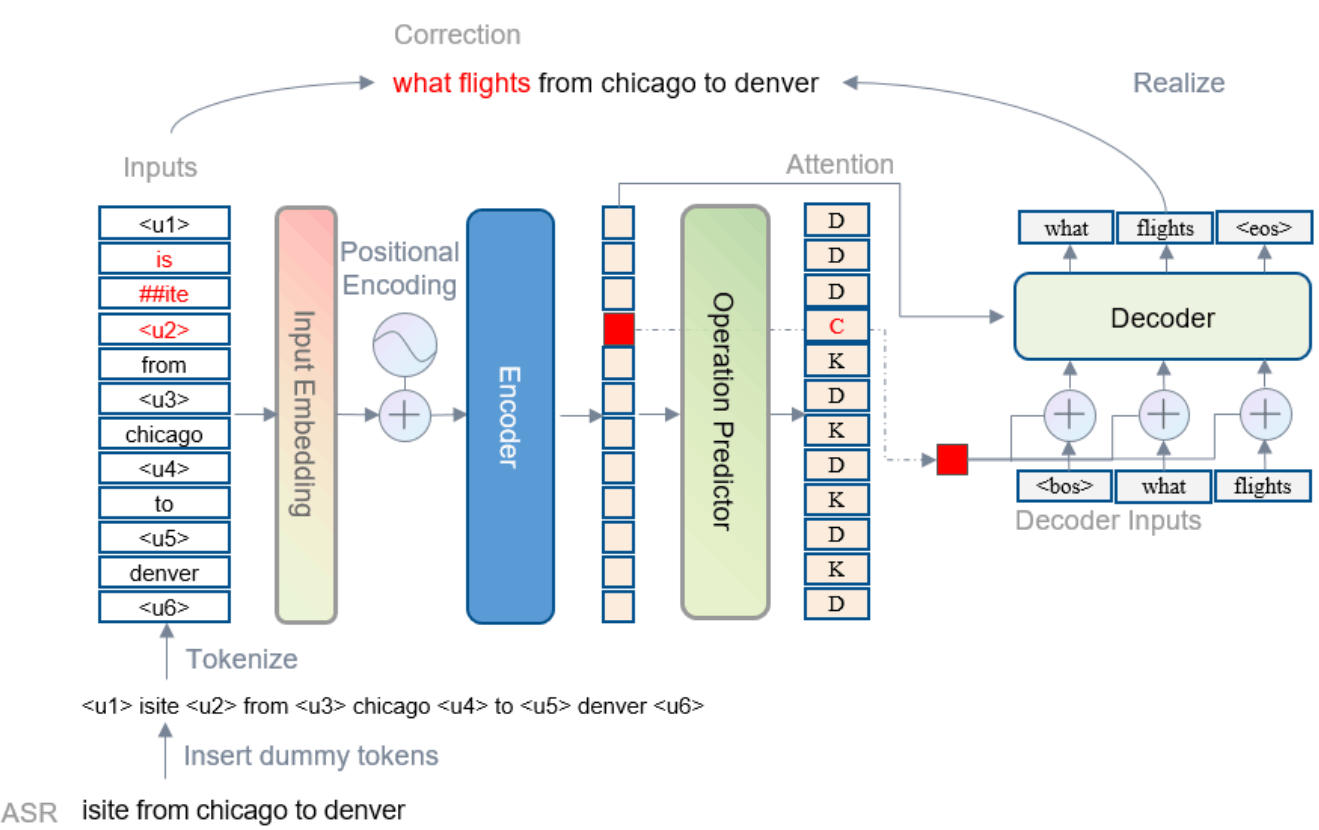
図12: 提案手法のアーキテクチャ。論文から引用。
エンコーダとデコーダの間に、誤り訂正箇所の予測(トークンを保持すべきか(K)、削除すべきか(D)、変更すべきか(C))を分類する予測器を挟み、処理すべきトークンを選別する手法を提案しました。
実験の結果、少なくとも3倍(3.4倍と5.7倍)の推論速度を向上させる一方で同等の精度を維持することを実現できたと報告しています。
LLM活用系
N-best T5: Robust ASR Error Correction using Multiple Input Hypotheses and Constrained Decoding Space [Ma+, Interspeech2023]
ASR誤り訂正において、従来のモデルの多くは1つの候補文しか利用しなかったが、N-best T5はASRシステムの出力するN個の候補文すべてを入力として言語モデルT5を利用することで、より多くの文脈情報を利用する手法として提案されています。

図13: N-best T5のモデル構造。論文から引用。
従来のビームサーチデコーディングでは、生成される文の自由度が高すぎる問題がありましたが、本論文では、ASRシステムの出力する候補文やラティスに基づいて復号空間を制限することで、より正確で制御可能な文生成を実現しました。
N-best T5は従来の音声認識モデルと比較して、誤り率を大幅に低減できることが示されました。
Can Generative Large Language Models Perform ASR Error Correction?
ASR誤り訂正に、ChatGPTのような大規模言語モデル (LLM) を活用する手法の提案です。
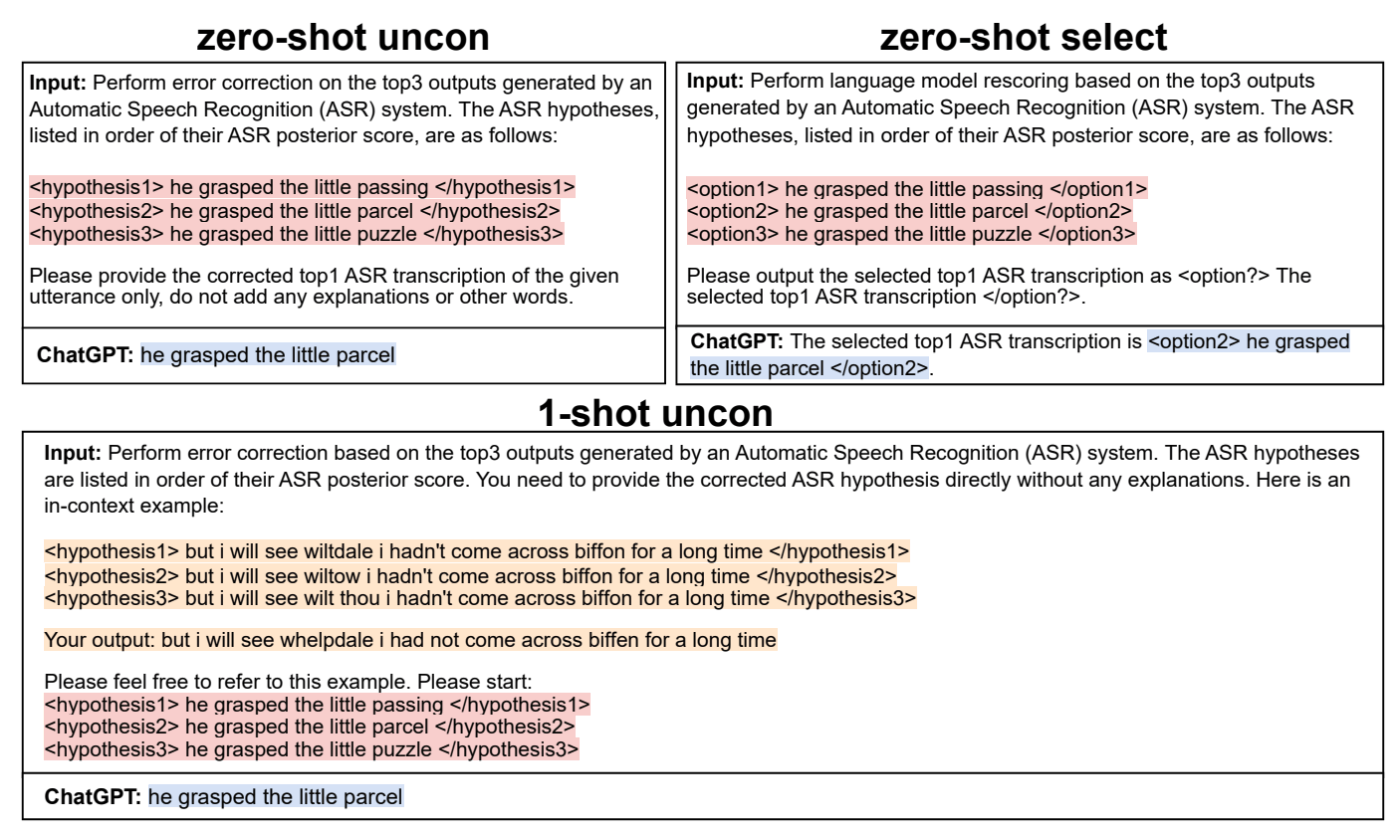
図14: ChatGPTを利用したASR誤り訂正。論文から引用。
従来のASR誤り訂正モデル(教師あり)とは異なり、この手法は事前学習済みのLLMを用いることで、zero-shotまたはfew-shotでの誤り訂正が可能です。
異なるアーキテクチャのASRモデルの出力に対して、N-best T5と同等程度のエラー率の削減を達成したと報告しています。
LLMの豊富な知識を活用することで、従来手法では学習データドメインに依存し困難であったドメイン外のデータセットに対しても高い性能を発揮するとしています。
Multi-stage Large Language Model Correction for Speech Recognition
こちらも、LLMを用いてASRの精度向上を狙う研究です。
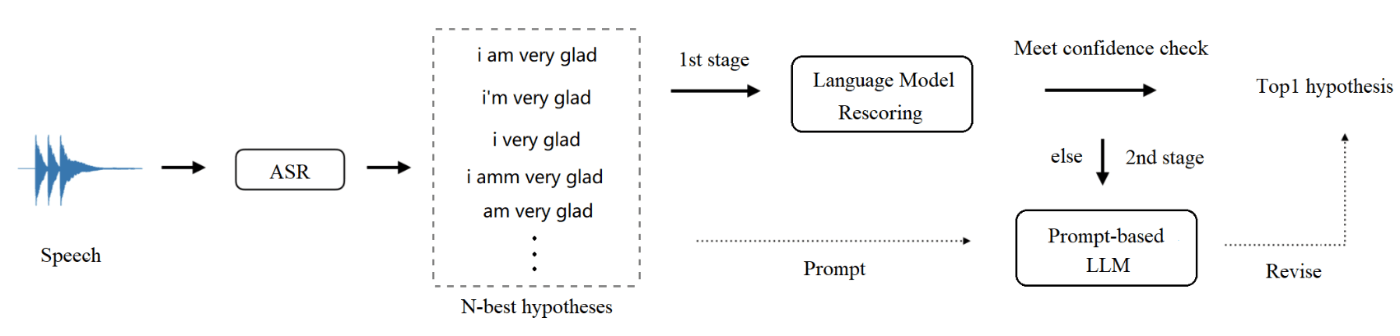
図15: 言語モデルを利用した提案手法の多段階誤り訂正パイプライン。論文から引用。
ASRによる書き起こしn-bestに対し言語モデルによるスコアリングを行い、閾値以上のスコアを獲得する候補があればそれを採用、閾値以上のスコアの候補がなければ、LLMを利用しプロンプトで適切な書き起こしに訂正するよう指示する手法です。
複数のテストドメインにわたって、競合するASRシステムと比較してWERが10%~20%向上することを報告しています。
クロスモーダル系
Non-autoregressive Error Correction for CTC-based ASR with Phone-conditioned Masked LM [Futami+, Interspeech2022]
本論文は、CTC(Connectionist Temporal Classification)ベースのASRモデルは軽量かつ高速な推論が可能である一方、認識時に単語間の依存関係を考慮できないという課題があることに着目しています。
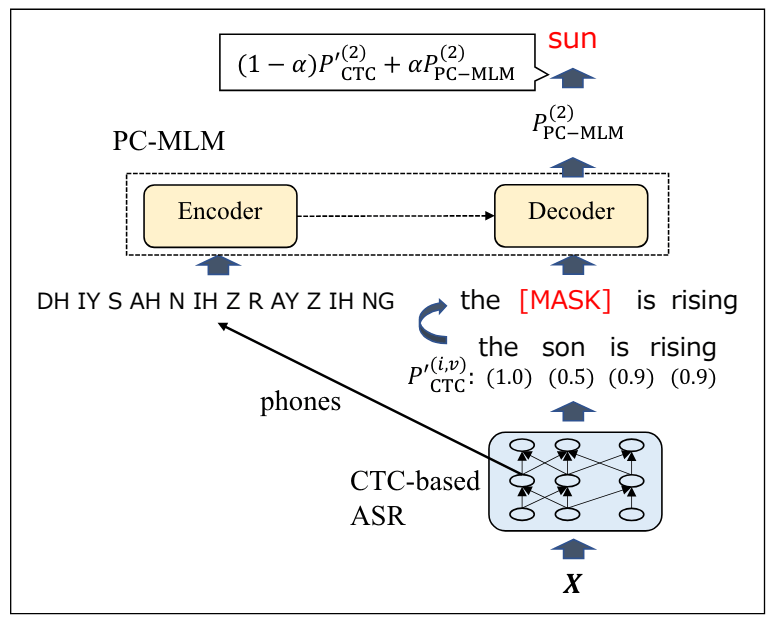
図16: 提案手法の概略図。論文から引用。
音素情報を活用した誤り訂正モデルとして、PC-MLM(phone-conditioned masked LM)を提案しています。
音素列を入力とし、マスクされた単語を予測するように学習します。これにより、音素情報と言語情報を統合して誤り訂正を行うことが可能となります。
日本語コーパス (CSJ) と英語コーパス (TED-LIUM2) を用いた実験の結果、PC-MLMを用いた誤り訂正により、単語誤り率 (WER) が大幅に減少したと報告しています。
Whispering LLaMA: A Cross-Modal Generative Error Correction Framework for Speech Recognition [Radhakrishnan+, EMNLP2023]
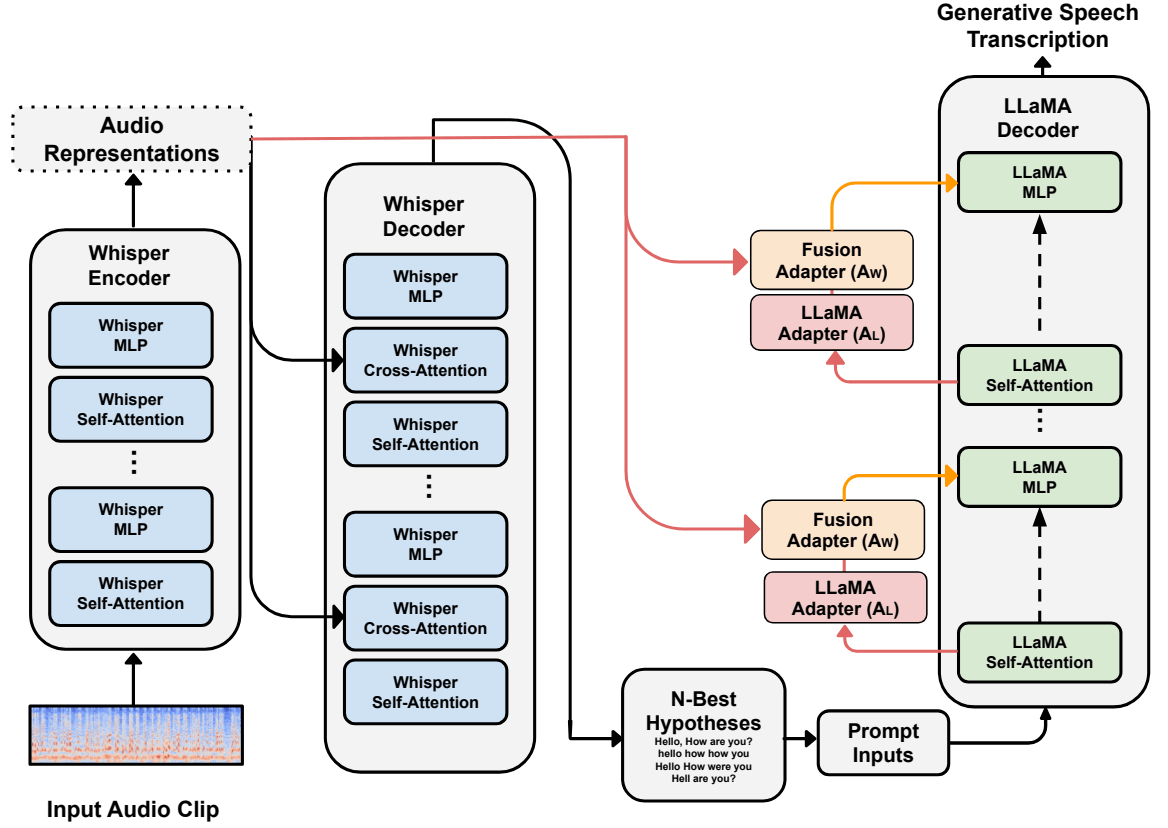
図17: Whispering LLaMAモデルの概略図。論文から引用。
Whisperにより生成した書き起こし候補をLLaMAに入力し、最も正しい書き起こしを選択するよう指示するとともに、LLaMAデコーダにWhisperのEncoder情報をcross-attentionモジュールを通して渡す方法の提案です。
さまざまなASRデータセットで評価され、n-best Oracleと比較して単語誤り率(WER)のパフォーマンスが37.66%向上したことを報告しています。
Crossmodal ASR Error Correction with Discrete Speech Units
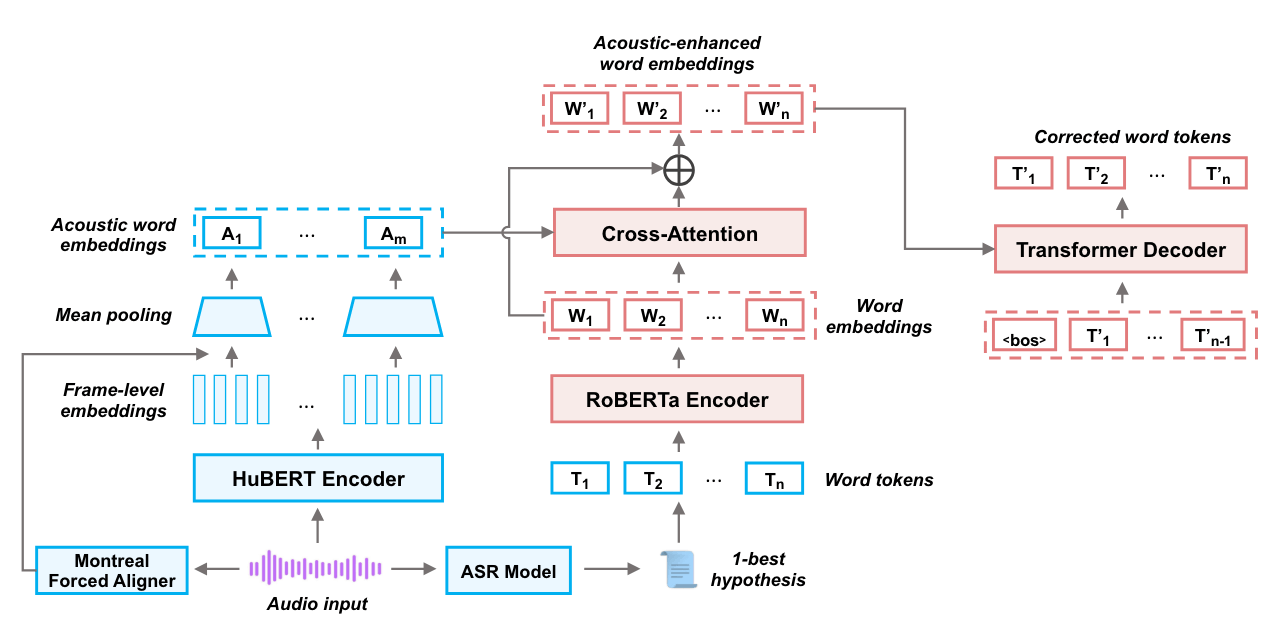
図18: 提案手法の概略図。論文から引用。
低リソースドメイン外(Low-Resource Out-of-Domain, LROOD)の音声に対し、大規模に特定のドメインで学習されたASRモデルは相性が良くなく、LROODに対するASR誤り訂正に取り組んだ研究です。
大規模コーパスで学習されたASR誤り訂正モデルをLROODに適用するために、LROODのDSU(Discrete Speech Units, 離散音声ユニット)を利用しファインチューニングを行うことが有効であることが確認されたと報告しています。
以上、ASR誤り訂正論文の紹介でした。
引き続きASR誤り訂正の調査、研究を進めていきたいと思っています。
お知らせ
少しでも弊社にご興味を持っていただけた方は、お気軽にご連絡頂けますと幸いです。まずはカジュアルにお話を、という形でも、副業を検討したいという形でも歓迎しています。
-
論文中では尤度をトークンスコア関数とし、スコアがもっとも高い系列をマスク位置が音声認識誤りである可能性が高い系列として選択するとし、尤度とパープレキシティが同等のものとされているように読めますが、尤度としては低い(パープレキシティが高い)系列を選択すべきなのでは(誤植では)?と考えています。 ↩︎ ↩︎
-
Visually and Phonologically Similar Characters in Incorrect Simplified Chinese Words [Liu+, COLING2010] ↩︎
-
[1:1]同様誤植なのでは(尤度に基づくスコア計算で最もスコアが高い系列(=最も自然な系列)を選択するのでは)?と考えているのですが、何か誤解しているかもしれません。 ↩︎
-
この分野の研究を網羅できるものではありません。 ↩︎

Discussion