はじめに
こんにちは。ZENKIGENデータサイエンスチーム所属のredteaです。原籍はオムロンソーシアルソリューションズ株式会社 技術創造センタですが、社外出向でZENKIGENに所属しており、数理最適化や機械学習を用いたデータの分析業務、それらの結果に基づいた顧客への提案をしております[1]。所属チームでXを運用しており、AIに関する情報を発信していますのでご興味あれば覗いてみてください。
本記事の取り組み
先日(2024年末)とても便利そうな optimizer RAdamScheduleFree が公開されました。この optimizer は名前の通り、warmup を含む全ての学習率スケジューリングの調整が一切不要なのが特徴です。この optimizer は実装者によって『全ての学習率スケジューリングを過去にするOptimizer』という記事で紹介されています。この記事を見ずに先に本記事を見る方はほとんどいらっしゃらないかと思いますが、もしまだ見ていない方は先に紹介元記事をお読みください。とりあえず RAdamScheduleFree を使いたい人にはその説明が簡潔に、中身まで詳しく知りたい玄人向けにはこれでもかというほど丁寧に解説されています。
この記事の中で、筆者は RAdamScheduleFree を以下のように説明しています。
新規に網羅的な性能実験などはおこなっていません。つまり、皆さんにとっては依然として「どこの馬の骨ともわからないoptimizer」の類ではあるわけですが、それをあなたにとっての新しい「これ使っときゃOK」にするかどうかは、あなたの好奇心次第です。
そして公開から月日が流れ、既に好奇心旺盛な方々がいろんな条件で実験[2]しています。私もその好奇心旺盛な1人として、GNNs (Graph Neural Networks) を対象に、RAdamScheduleFree を試し、その結果を共有します。結論はタイトルの通り、RAdamScheduleFree は GNNs でも健在でした。
GNNsとは
本記事の本題からは外れるので、説明は割愛します。概要を知りたい方はこちらの記事、詳しく知りたい方はこちらの書籍がおすすめです。本を紹介しておいてアレですが、私はまだ読破できておりません...
評価実験
実験概要
今回は、以下2つのデータセットで実験を行います。
- PyTorch Geometricで用意されている Node Classification[3] 用のサンプルデータセット
- 以前私が Zenn に投稿した GNNs の Auto-Encoder(station2vec)のデータセット
それぞれの実験において、 RAdamScheduleFree と、ベースラインとして Scheduler を用いた Adam で学習曲線を比較します。
実験に用いたソースコードは GitHub にて公開していますので、詳細が気になる方はご覧ください。なお、ニューラルネットワークの実験ですが、データセットもモデルもかなり小さいので、CPU でも十分実験できます。
1. Node Classification
データセット
PyTorch Geometric の Node Classification には、以下3種類のデータセットが用意されています。
| Name | ノードの数 | エッジの数 | 特徴量次元数 | 分類するクラス数 |
|---|---|---|---|---|
| Cora | 2,708 | 10,556 | 1,433 | 7 |
| CiteSeer | 3,327 | 9,104 | 3,703 | 6 |
| PubMed | 19,717 | 88,648 | 500 | 3 |
データセットはこちらの論文で使われたものです。いずれもノードは文献を、エッジは文献間の引用関係を表したグラフ構造を持ち、ノードに付随する特徴量として文献内のテキストから抽出した bag-of-words を持ちます。すなわち、文献内の bag-of-words と、その引用関係から、文献のラベル[4]を予測するタスクです。データセットはあらかじめ training, validation, test 用に分かれており、そのまま使用します。
学習設定
RAdamScheduleFreeと、ベースラインとして Scheduler を用いた Adam で比較します。また、RAdamScheduleFree は学習率の初期値は設定が必要なので、学習率の初期値と収束の関係性を調べるべく、学習率の初期値も動かして実験しました[5]。モデルの設定は以下の通りです。
| 項目 | 値 |
|---|---|
| モデル | GCNConv |
| 隠れ層の数 | 3 |
| 各層の次元数 | 64 |
| ドロップアウト率 | 0.5 |
結果と感想
Cora Dataset
まずは Cora Dataset に対する学習曲線です。

Cora Dataset における Test Loss と Test Accuracy。実線が scheduler を用いた結果で、点線が scheduleFree。色が赤濃い方が学習率の初期値が高いことを表します。
最も早く Test Loss が落ちきったのは、以下3種の設定でした。
- scheduler の学習率初期値が0.01の橙実線
- scheduler の学習率初期値が0.008の緑実線
- scheduleFree の学習率初期値が0.1の茶点線
scheduler(実線)の方は、学習率の初期値が高すぎると(0.1や0.05の濃赤線) Test Loss が落ちきらなかったり、Test Accuracy が高まりきらなかったりしますが、scheduleFree の方は高めの学習率初期値が良さそうです。
CiteSeer Dataset
次に CiteSeer Dataset に対する学習曲線です。

CiteSeer Dataset における Test Loss と Test Accuracy。実線が scheduler を用いた結果で、点線が scheduleFree。色が赤濃い方が学習率の初期値が高いことを表します。
最も早く Test Loss が落ちきったのは、以下3種の設定でした。
- scheduler の学習率初期値が0.01の橙実線
- scheduler の学習率初期値が0.008の緑実線
- scheduleFree の学習率初期値が0.1の茶点線
こちらも概ね Cora Dataset の実験結果と同じ傾向と言えるでしょう。
PubMed Dataset
最後に PubMed Dataset に対する学習曲線です。

PubMed Dataset における Test Loss と Test Accuracy。実線が scheduler を用いた結果で、点線が scheduleFree。色が赤濃い方が学習率の初期値が高いことを表します。
最も早く Test Loss が落ちきったのは、以下4種の設定でした。
- scheduler の学習率初期値が0.1の茶実線
- scheduler の学習率初期値が0.05の赤実線
- scheduler の学習率初期値が0.01の緑実線
- scheduler の学習率初期値が0.008の緑実線
PubMed Dataset に対しては、scheduler の方が早く収束し、やや scheduleFree (RAdamScheduleFree) が不利な結果でしたが、やはり scheduleFree でも収束が早いのは学習率初期値が高い傾向にあることは変わりません。
2. Variational Graph Auto-Encoders
データセットと学習設定
①Node Classification と同様、RAdamScheduleFree と、ベースラインとして Scheduler を用いた Adam で比較します。学習率の初期値は①Node Classificationと同じ組み合わせですが、RAdamScheduleFree の方はより大きな初期学習率があっても良いと考え、0.2, 0.4, 0.8 を追加しています。なお、簡単のため学習データに対する誤差を評価している点をご注意ください。
詳しくはこちらの記事をご覧ください。以下、簡単に要点だけ書きます。
データセット
独自に収集したオープンデータによって、駅同士をエッジで結んだグラフを構成しています。ノード特徴量には昼夜人口などの駅に関する情報が、エッジ特徴量には駅間の距離などが付与されています。詳細は元記事をご参照ください。
モデル
モデルは VGAE (Variational Graph Auto-Encoders) ですが駅の埋め込みを目的としているので少々オリジナルからいじっています。具体的には、Encoder によって、各ノードが持つ生データである特徴量ベクトルを潜在変数

モデルアーキテクチャ(元記事より)。
損失関数
Reconstruction Loss(再構成誤差を二乗誤差で定義)と、Edge Prediction Loss (交差エントロピー誤差で定義)を算出します。また、
結果と感想
まずは学習曲線の全体像を見てみます。図中の色や線の種類(実線/点線)の使い方は①Node Classificationと同じです。一部の設定では誤差が大きくなりすぎていますね。

station2vec学習曲線の全体像。実線が scheduler を用いた結果で、点線が scheduleFree。色が赤濃い方が学習率の初期値が高いことを表します。RAdamScheduleFree の方はより大きな初期学習率があっても良いと考え、0.2, 0.4, 0.8 を追加しています。
このままでは収束速度に関する部分がわかりにくいので拡大します。
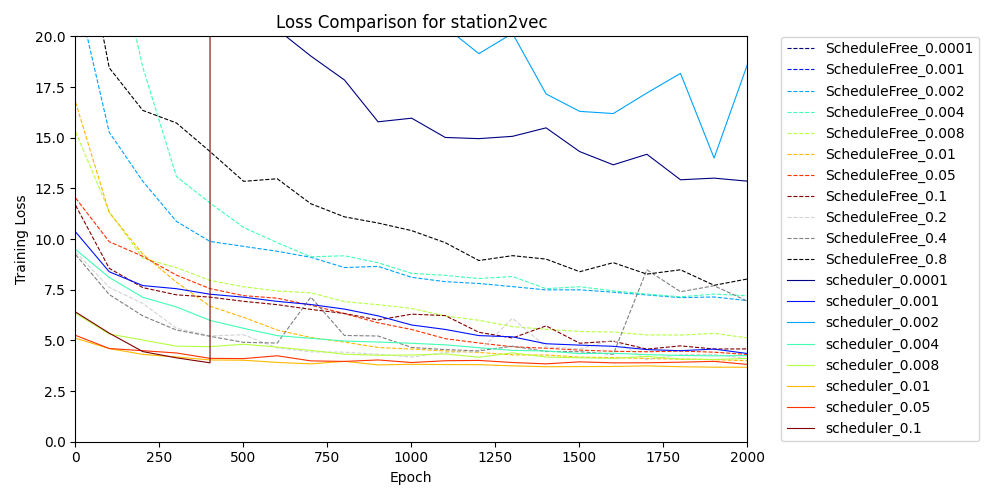
station2vec学習曲線の拡大版。実線が scheduler を用いた結果で、点線が scheduleFree。色が赤濃い方が学習率の初期値が高いことを表します。RAdamScheduleFree の方はより大きな初期学習率があっても良いと考え、0.2, 0.4, 0.8 を追加しています。
学習誤差が早く落ちきったのは以下の通り全て scheduler 条件でした。
- scheduler の学習率初期値が0.1の茶実線
- scheduler の学習率初期値が0.05の赤実線
- scheduler の学習率初期値が0.01の橙実線
グラフのサイズが小さいことや、学習データに対する誤差を評価してることなど、特殊な設定ではあるものの、今回の実験では scheduler を用いた方法が有利という結果になりました。ただ、RAdamScheduleFree の方は少し待てばどの学習率の初期値を選んでもしっかり収束していますし、学習の安定感は申し分ないと考えます。タスク次第な部分がありますが、本記事では「初手 RAdamScheduleFree」は健在であると結論づけます[6]。
結び
CPUでも計算できるくらい小さな規模の簡単なGNNs実験でしたが、GNNsでも概ね「初手 RAdamScheduleFree」に支障がなさそうです。もちろん実験設定によっては従来の scheduler を用いる方法が有利な場合もあり得ますが、私は今後も実務の中でも試していくつもりです。素晴らしい optimizer の開発に心からの敬意と感謝を。
参考文献
- Revisiting Semi-Supervised Learning with Graph Embeddings, Zhilin Yang, et. al., 2016.
- Variational Graph Auto-Encoders Thomas N. Kipf, Max Welling, 2016.
お知らせ
少しでも弊社にご興味を持っていただけた方は、お気軽にご連絡頂けますと幸いです。まずはカジュアルにお話を、という形でも、副業を検討したいという形でも歓迎しています。

Discussion