ウォーターフォールとの共存 (前編) ~ 複雑さを紐解く ~
これはなに?
アドベントカレンダーのネタになるものがないかなぁと今年一年を振り返っていた中で、こんな投稿があったのを見つけました。

弊社では金融機関向けのプロダクトである4RAPを提供しています。
これまでSBI証券や愛媛銀行という複数の金融機関の導入を行なってきましたが、どちらも金融機関向けの開発はウォーターフォールを採用してきました。
どちらのプロジェクトもスケジュールの遅延や大規模障害を回避し、プロジェクトの規模の割には比較的安定して終えられたかなぁと思います。
一般にウォーターフォールのプロジェクトを成功裏に導くことは難しいとされています。
実際、ソフトウェア開発の歴史の中で、アジャイルを含む探索的な開発プロセスが提案され、実践による知見の蓄積と改善により、段々とウォーターフォールからの置き換えが進んできました。
率直に言って、条件が整うならば探索的手法を採用する方が合理的だと言えるでしょう。
とはいえ、様々な事情によりウォーターフォールを採用する(せざるを得ない)こともまだまだ多いのが現実ではないでしょうか?
例えば4RAPでは、金融機関のシステムとのデータのやり取りを必要とするプロダクトであるため、導入に当たっては連携するシステムとのデリバリーのタイミングを合わせなければなりません。
こういうプロジェクトではいつ終わるかを明示できない探索的手法は使えず、必然的にウォーターフォール一択となってしまいます。
うちはウォーターフォールなんてやってないよ、という方は多いかもしれません。
が、トップダウンで期限付きプロジェクトが降ってくる、、、理由は様々だと思いますが、そういうシチュエーションって結構あるんじゃないでしょうか?
期限付きのプロジェクトはその完了タイミングを制御するために計画・予測を行なう必要があり、結局のところ本質はウォーターフォールと変わらないケースが多いです。
そう考えると、ウォーターフォールに接する機会のある方は、実は意外と多いのではないかと思っています。
一方で、ウォーターフォールについて言及されている記事はほとんどないようです。(Zennで検索すると7件だけ)
こういう状況であれば、これまで得られた知見を還元することは一定の社会的な意義があるのかなぁと思い、記事を書いてみることにしました。
この記事で解決したいこと
本稿は、「現在、ウォーターフォールを採用している・せざるを得ないチームや企業」を読者として想定し、ウォーターフォールがなぜうまく回らないのか、うまく回すためには何が大事なのかについての個人的な考察と施策を紹介したいと思います。
この記事が、ウォーターフォールモデルの採用における失敗や不確実性の制御の課題を抱える読者、または開発プロセスの改善アイデアを探している読者に役立てば幸いです
ウォーターフォールとは?
本稿では議論のために、ウォーターフォールを以下の条件を満たすようなシステム開発に関わる一連のプロセスと再定義します。
1. 変更が難しい制約が存在する
期限や予算といった変更が難しい強い制約が存在することは、開発プロセスがウォーターフォールであると言える重要な特徴です。
それらの制約は、課題が解決可能かどうかの予測のために事前に計画を立てる強い動機となり、アジャイルなどの探索的プロセスを採用しないインセンティブに繋がりやすいです。
2. 期間初期に、満たすべき要求・要件をコミットする必要がある
期間の初期に要求・要件を確定するなどのコミットメントが求められることが、ウォーターフォールの2つ目の特徴です。
単に制約が存在するだけであれば、探索的手法を選択するケースもありえますが、初期にコミットメントが必要となると時間的な制約から、探索的手法を採用することが難しくなります。
3. 要求・要件の検証(テスト)が期間終盤に実施される
ウォーターフォールの最後の特徴は、要求・要件を満たしているかどうかの検証が、開発期間の終盤にしか行なわれない点にあります。
探索的手法には、目的地との現在地の乖離を測るため、フィードバックループが必要となります。
前段2つを満たしただけであれば、探索的手法の適用は難しいながらも可能かもしれません。
しかしながら、リソースや体制不備などの理由により検証が終盤にしか行なわれない状況では、フィードバックループが(少なくとも限定的にしか)働かず、たとえ探索的手法のやり方を導入しても形骸化してしまいます。
つまり、ウォーターフォールが非探索的=計画的手法であるという性質は、この特徴をもって決定づけられると考えられます。
なぜウォーターフォールは難しいのか?
前段ではウォーターフォールを定義しましたが、ではなぜウォーターフォールは難しいのか掘り下げてみましょう。
正しいシステムとは?
ウォーターフォールの複雑さを理解するために、まずはソフトウェア開発における「正しさ」という概念に焦点を当てましょう。ここで重要なのは、L-真(Logic-真)とF-真(Fact-真)という二つの次元です。
L-真は論理的な正しさを指し、ソフトウェアが技術的に正しいこと、例えば問題なくコンパイルできることを意味します。
F-真は事実としての正しさを指し、ソフトウェアが実際の業務要件を適切に満たしていることを意味します。
これらの概念は、佐藤正美氏によるTM(Theory of Modeling)で使われており、通常、データモデル(およびその成果物としてのシステム)が、これらをtrue/falseの二値で満たす必要があるとされています。
しかし、一般的なソフトウェア開発では、これらは単純な二値ではなく、より複雑なグラデーションを持っています。
例えば4RAPでは、より処理性能の高いストリーム処理ではなく、バッチパイプライン処理を採用しています。これは、現状の運用者数であれば、必要なL-真を満たすために十分な性能を、バッチパイプラインでも提供可能という判断に基づいています。
同様に、F-真の観点から見ると、新しいファンドラップやロボアドバイザーといった運用サービスの開始に伴うデータ入稿作業も注目すべき例です。
4RAPは運用サービスの同時運用をサポートするプラットフォームですが、運用サービスのローンチの頻度は必ずしも高くありません。
理想的には運用サービスのライフサイクルは導入金融機関がコントロールすべきですが、このような稀な作業のための開発は成果に見合わないため、エンジニア作業を許容するという妥協を行ないました。
このように、L-真とF-真は単なる二値ではなく、より幅広いグラデーションを持っています。
そこで本稿では、以下のように再定義します。
- L-真 : システムに対する非機能的な要求
- F-真 : システムに対する機能的な要求
- システムがL-真を満たす度合いを「L-真値 L (0<=L<=1)」、F-真を満たす度合いを「F-真値 F (0<=F<=1)」とする
- L=1, F=1の場合、システムは理想の状態である
- システムは許容可能なL-真値, F-真値のしきい値 L*, F*を持つ
- L*, F*は未知である
この再定義を通じて、ウォーターフォールの複雑さとその背後にある概念をより深く掘り下げたいと思います。
ウォータフォールの複雑さとは?
再定義したL-真, F-真をベースとすると、システムは以下の4つの領域のいずれかに存在するものと言えます。
- 領域 A (L < L*, F < F*) : 機能要求も非機能要求も満たさない
- 領域 B (L >= L*, F < F*) : 非機能要求は満たすが、機能要求は満たさない
- 領域 C (L < L*, F >= F*) : 機能要求は満たすが、非機能要求は満たさない
- 領域 D (L >= L*, F >= F*) : 機能要求も非機能要求も満たす

領域 A は、開発途中のシステムの他、開発は完了したが業務が回らないどころかうまく動かないなど、本番運用には不十分なシステムが該当します。
たまに開発を中止した大型プロジェクトの話が聞こえてきますが、これは領域 A を脱することが出来なかった例かと思います。 (恐ろしい)
領域 B は、動くシステムではあるが、まだ業務を行なうには機能が不足しているようなシステムが該当します。
領域 C は、機能要求は満たすが本番運用に耐えないシステム、例えばモックアップやデモなどが該当します。
領域 D は、機能要件・非機能要件を満たす、まさに作りたいシステムです。
開発プロセスとは、この領域Dに属する機能・非機能に関する要求を満たすシステムを顕現させる手続きと言えます。
では、開発プロセスの一つであるウォーターフォールの複雑さとはなんなのでしょうか?
比較対象として、まずは探索的手法の一つであるアジャイルを考えてみましょう。
アジャイルソフトウェア開発宣言にある通り、アジャイルでは「動くソフトウェア」を提供しつづけることが重要な特徴です。
これは例えば、顧客から「移動手段としての車」を求められれば、まずはスケートボードや自転車、バイク、オープンカーなどのより簡易な移動手段(= L*を満たすもの)を提供することを表します。
そういった複数の移動手段の提供を通して機能要求に対する不足を検証し、機能要求を満たす必要十分な移動手段(ここではオープンカー)にたどり着くことを目指します。
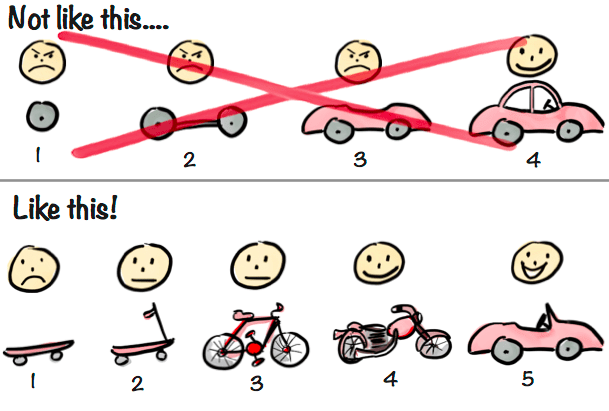
これは領域 B から領域 D を目指して、探索活動を行なうことを表します。

一方で、ウォーターフォールは、事前のコミットメントを求める手法です。
これはつまり領域 C から領域 D を目指すことを表します。
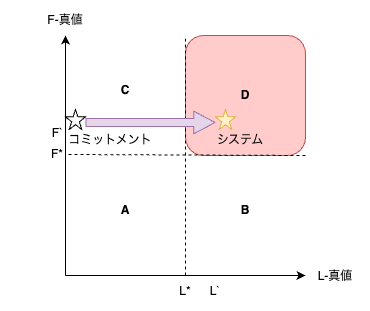
どちらも領域 D に属するシステムを顕現させることを目的とした開発プロセスである点は一緒です。
ではどこがウォーターフォールの複雑さの原因となっているのでしょうか?
ソフトウェア開発の歴史において、数学的・科学的なバックグラウンドが醸成され、開発をサポートする様々なソフトウェアやフレームワーク・クラウドサービスなどが開発されてきました。
そういった支援ツールを利用することで、L-真を満たしたシステムを作ることは極めて容易になっています。
これは、L-真 = 非機能要求を満たす領域 B のシステムを作ることが容易である = 不確実性が少ないことを表します。
一方、F-真 = 機能要件は業界や会社・法律のようなコンテキストによって変わりうるものです。
例えば、個人情報保護法は3年ごとに改定されますが、(当たり前ですが)その改定内容は毎回異なります。
また、同じ改定であっても金融機関と個人商店のECサイトでは対応が異なりますし、金融機関のなかでも会社ごとに対応内容が異なるなどのバリエーションが発生します。
このように、歴史的な蓄積のあるL-真とは異なり、F-真を満たす機能要求 F* を明らかにする(予測する)ことは、コンテキストを理解することを要するため、相対的に難しい課題です。
さらに、機能要求が明らかになった(予測できた)としても、同時に L-真 を満たすシステムの導出は自明ではありません。
以下は「顧客が本当に必要だったもの」で有名な画像(の一部)です。
この絵は「ブランコ(Tree Swing)」という機能要求は満たしていますが、おそらく誰も乗れません(し、木もそのうち枯れてしまう)ので、非機能要件は満たしていない(本番運用は不可能)といえます。

そして、動くシステム(=L-真を満たす)システムを探索した結果として、いつのまにか「ブランコ」という機能要求がすっぽり抜け落ちてしまった、、、
ここまで極端かどうかはともかく、よくある話なのではないでしょうか。

つまり、ウォータフォールで取り組む領域 C から領域 D を目指すことは、
- コミットメントが真の機能要求を下回る
- L-真の探索の結果、コミットメントを満たさないシステムとなる
という2つのリスクをはらんでいる訳です。
このことが、ウォーターフォールを成功裏に導くことの難しさの原因と考えられます。
まとめ
前編では、ウォーターフォール開発プロセスの複雑さを深く理解するために、以下の重要な概念とポイントを取り上げました。
- L-真とF-真の概念:ウォーターフォールの挑戦を理解するために、L-真(論理的な正しさ)とF-真(事実としての正しさ)という二つの次元を導入しました。これらは、ソフトウェアが技術的に妥当であると同時に、実際の業務要件を満たしていることを意味します。
- 開発プロセスにおけるL-真とF-真の応用:実際のソフトウェア開発では、L-真とF-真は単純な二値ではなく、複雑なグラデーションを持ちます。グラデーションを表現可能なようL-真とF-真の概念を拡張・再定義しました。
- ウォーターフォールの複雑さの探求:拡張されたL-真とF-真に基づき開発プロセスを再定義し、ウォーターフォールにおける開発プロセスの複雑さを分析しました。特に、機能要求と非機能要求を同時に満たすことの難しさと、予測の不確実性がウォーターフォールの複雑さの根本的な原因であることを示しました。
この前編では、ウォーターフォール開発の本質的な課題と複雑さを理解するための基礎を築きました。後編では、これらの課題にどのように対処するか、さらにウォーターフォールと他の開発手法との比較を深掘りする予定です。
Discussion