Effectively Onceなバッチ処理設計のすすめ
この記事は FOLIO Advent Calendar 2022の25日目です。
12/20の記事4RAPで動いているバッチが300種を超えたお話 - 前編 -の続きです。
はじめに
前編では4RAP(4RAP-IAというコンポーネント)がなぜバッチシステムを採用しているのか、というマクロなアーキテクチャについての設計の経緯(ADR)を紹介しました。
今度はミクロなアーキテクチャとして、バッチ処理設計におけるプラクティスを紹介していきたいと思います。
本稿はあくまで4RAPという特定業界の一つのプロダクトの経験をベースにしたお話です。
記載の方法でうまくいくことを保証するものではありませんが、もし読んだ方の一助になれば幸いです。
4RAPにおけるバッチ処理設計のプラクティス
そもそもバッチ処理でのプラクティスとは何でしょうか?
検索すると色々と出てきますが、皆さん様々なプラクティスを紹介されていますね。(参考 バッチ処理について考える - Qiita バッチ処理の採用と設計を考えてみよう)
なんか既存記事の劣化版になりそうな予感がしてきましたが、 yamrkzさんの記事が観点が網羅されていて説明にちょうど良かったので、こちらに則って4RAPでのバッチ処理のプラクティスを紹介してみたいと思います。
バッチ処理のプラクティス
yamrkzさんの記事では以下の11個の観点が紹介されています。

引用 : バッチ処理 プラクティス
本稿では、このうち以下の6個の観点について述べたいと思います。
- トリガー
- リトライ & 論理設計
- パフォーマンス
- 監視
- ドキュメント
1. トリガー
4RAPのバッチは、ほとんど(8~9割)がパイプラインと社内で呼ばれるワークフローに属しています。
例えば、1日の終わりに行なう日締めの処理と一言で言っても、
- 翌日開始時点の残高を計算・永続化する
- 日付を切り替える
という感じで、まとまっての実行が期待されるコンテキストの異なる処理が存在します。
これを一つのバッチ処理で行なうのは様々な観点で好ましくないため、複数のバッチをまとめたパイプラインという単位で実行を管理しています。

パイプラインもバッチ処理のトリガーと基本的には変わらないのですが、4RAP特有の事情として導入金融機関のシステムとの連携という点があります。
例えば、導入先の金融機関から、毎日夜にファイルを送ってもらって4RAPに取り込むケースを考えましょう。
普段は夜の22時ごろにファイルが送られてくるのですが、月末や処理量が多い日は24時を超えることがしばしばあるとします。
じゃあ4RAP側の受け取り処理を25時に設定すれば良い、、、のですが、出来れば早めにデータを受け取って検証は行なっておきたいところです。[1]
そこで導入金融機関からのファイル取り込みのためのパイプラインは、
- 複数回発火(例で言うと22時 ~ 25時の間)
- ファイルが存在すること
の2つの条件をトリガーとしています。
これにより通常であれば22時ごろ、何らかの理由で遅れた場合は24時ごろという、可能な限り早いタイミングでの検証が実現できます。
なお、最後の発火のタイミングでトリガーの条件を満たさない場合には異常を検知する必要がある点には注意が必要です。(それ以前でファイル不在でトリガー条件を満たさないのは問題ない)
そこで4RAPでは、ファイル不在に関するデッドライン時刻を決め、その時刻以降の実行でトリガー条件を満たさない場合は異常として検知するようにしています。
2. リトライ & 論理設計
4RAPではリトライに関してEffectively Onceを採用しています。
Effectively OnceはApache PULSARが提供する概念で、
- メッセージが100%一意に特定され、[2]
- あらゆる障害でもメッセージは一回以上受信でき、
- 必ず一回のみ処理される
というものです。(オリジナルはこちら)
元はメッセージングミドルウェアにおける概念ですので、4RAPではバッチのコンテキストに合うように、
- 入力データが100%一意に特定され、
- 入力データは一回以上処理対象となり、
- 必ず一回のみ処理される
と読み替えたものをリトライ設計の原則としています。
Effectively Onceが実現できると、例えば誤ってや障害対応の一環としてバッチ処理を複数回実行することがあったとしても、処理されるのは一回のみであることが保証されることになります。
Effectively Onceが保証されていると、前編で紹介した一部の約定データの訂正のような場合でも、何も考えずにバッチを再実行したとしても、正常に処理済みのデータには無影響が確定するので、運用が大変楽になります。
ではEffectively Onceをバッチ処理で実現しようとすると、論理設計においてどういう考慮が必要となるのでしょうか?
まず「入力データが100%一意に特定され」るためには、全ての入力データに何らかのIDが振られている必要があります。
「入力データは一回以上処理対象となる」ことは、バッチ処理の場合はトリガーの項で紹介した複数回発火ような考慮で事足ります。
そして「必ず一回のみ処理される」ためには、入力データが処理されたかどうか判別可能なように、何らかの記録を残す=出力データに入力データのIDが紐付けされている必要があります。
以上が論理設計で保証されていれば、入力データが到着 → 入力データからIDを抽出 → 入力データのIDが紐づく出力データを検索 → 不在なら処理を実施、存在すれば処理をスキップするという判断を行ないます。
これがバッチ処理でEffectively Onceを実現するための、必要十分条件です。

あとは論理設計を進めるだけ、、、ではあるんですが、設計について気をつけるべき点を紹介したいと思います。
A. 分散トランザクションは徹底的に避ける
Effectively Onceを実現する際、出力データを使って処理済みの判定を行なうわけですが、もし分散トランザクションとなっていると、障害発生時に出力が不完全となるケースが発生する可能性があります。

これに真面目に設計で対処しようとするとSagaパターンを実装する必要がありますが、Sagaパターンは複雑な機構ですので運用難易度が高く、少なくともバッチシステムで採用する設計ではないかと思います。
Sagaパターンはやりすぎとして、じゃあ稀な事象だしリスクを承知で運用でカバーという手もありえますが、、、障害時に分散トランザクションがどこで止まったのか、途中状態を正しく把握するのは結構難しく、運用の難易度はかなり上がります。(しかも夜中に発生して寝ぼけ眼だったりすると、、、二次災害不可避ですね)
しかも稀な事象なので発生した時にはローンチから時間が経過してしまって、既に忘却の彼方、もしくは当時を知る人が誰もいない、、、なんてことも起こり得ますよね。(こわい)
長期的な運用を見据えると、分散トランザクションはいいことが本当に何もないので、、、個人的な設計時に避けるべき構成の筆頭に挙げられます。
とは言っても業務要件を素直に紐解くと、分散トランザクションが避けられなさそうなケースも存在しますよね?(人間は優秀だから、そんな複雑な処理もやれてしまう)
次は、分散トランザクションを避けつつEffectively Onceなバッチシステムに設計を変えるにはどうすればいいのか、普段使っているいくつかのパターンがあるので紹介したいと思います。
シンプルにバッチ分割
分散トランザクションの設計が出来たということは、結果整合性までは許容できる状況ということかと思います。
そのため、トランザクション単位で2つのバッチに分割して処理するのが一番シンプルな解決策です。
結果整合性さえあれば出力データの作成順序は気にしないというケースは、これで解決できます。

もしかしたらバッチの数が増えると開発コストや運用コストが増えるのでは、、、?と心配されるかもしれませんね。
開発コストですが、複雑なバッチが一つよりシンプルなバッチが2つの方が、並行して開発が可能だったり、テストやレビュー時の認知コストの負担が抑えられるので、分けても意外とコストの増加はない印象です。
また運用コストも、経験上シンプルなバッチ数と障害数は比例しないので、増えることはほぼありません。(シンプルであればあるほど認知コストが抑えられて失敗が発生しにくいとかがありそう)
経験則で恐縮ですが、分割するデメリットがメリットを上回ったことはありませんでした。(少なくとも顕在化するデメリットはなかった)
ですので、分散トランザクションを持つ複雑なバッチ処理を作るぐらいなら、私はスパッと分割してしまいます。(だから300種にもなる訳ですね)
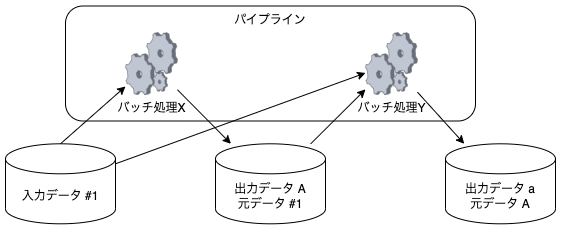
パイプライン
もし出力データ a が出力データ A に依存している場合には、バッチ処理XとYでパイプラインを構成することになります。
その際、バッチ処理Yの入力データをAとする必要がありますが、Aが持つ元データの情報から入力データ #1を辿って参照が可能ですので、パイプラインに変更したとしても情報が不足することはありません。
ストリーム or ポーリング
もし結果整合性は許容出来るけどあまり処理間隔を開けたくない、という場合はどうでしょうか? (実際にあった要件です)
その場合はバッチ処理Xの出力先をキューにしてイベント駆動とするか、キューが難しければバッチ処理Yのポーリング間隔を短くしたりして、対応することになります。

分散トランザクションを許容する
以上の方法でほとんどの分散トランザクションは潰せる(潰した)のですが、稀に分散トランザクションを許容したケースもあります。
どういうケースかというと、
- 入力データは一つ
- ファイルを配布する
- 配布先がN個あり可変
- ファイルに含まれるデータはN個それぞれで異なる
というケースでした。

このケースだけは、
- 可変な複数のシステムへの配布
- トランザクション範囲はファイル単位から変更出来ない
という点がネックになり、分散トランザクションを許容せざるを得ませんでした、、、
このケースは実務上は、
- ファイル上書きの際の冪等性が保証される
- 配布先の後続処理がそれぞれ独立である
の2点が保証出来たため、もし何らかの理由で途中で処理が止まっても何も考えずにバッチ再実行で済み、運用難易度が上がることはありませんでした。(結果オーライ)
ただ、常にそう出来るとも限らないので、もし良い分散トランザクションの回避方法を思いついたら、どこかで記事にしたいと思います。
(2022/12/26追記)
よく考えると、このケースはメッセージングの世界においてはPub/Sub構成で解決される問題ですね。
Pub/Sub構成は、Publishするプロセスはどのシステムが処理するかを問わず送信、Subscribeしているシステム 1~N側で自身が処理すべきメッセージを取捨選択するものです。

バッチ処理の世界に置き直すと、以下のように出力データを1トランザクションで出力、出力データを入力とするシステム1~N側で適切に取捨選択する構成になるかと思います。(以下、「バッチ処理におけるPub/Sub構成」と呼びます)

一方で、4RAPではバッチ処理を持つシステムXとシステム1~Nが、相互にデータのやり取りをする必要があります。
システムXとシステム1~N間の相互依存=密結合を避けるためには、どちらか一方のみの依存とする必要があります。
4RAPではシステムXからシステム1~Nへの依存を前提としています。[3]

この前提でバッチ処理のPub/Sub構成を実現するには、システム1~Nの共通の場所(共通領域)にシステムXからの出力データが配置されることで構成を満たせます。

これで分散トランザクションは解消されましたが、
- 共通領域を通したデータの混同
- 単一データに複数システムが依存することによる運用難易度の向上(システム1のデータで障害発生 → 誤ってシステムNのデータを修正 → システムNで二次障害発生)
など、デメリットもありそうですね。
ここは、設計におけるトレードオフになるポイントかと思います。(2022/12/26追記終わり)
B. 一貫性の後付け
分散トランザクションから少し離れますが、結果整合性ではなくちゃんとした一貫性が欲しいデータもありますよね? (私はありました)
例えば4RAPで1日の終わりに行なう残高に関するパイプラインには、様々な種類のバッチ処理が含まれています。
- バッチ処理X = 翌日開始時点での残高を計算する
- バッチ処理Y = 翌日開始時点での評価損益を計算する
- … (他にも色々と)
単一のバッチ処理で全ての出力に一貫性を持たせようとすると、多様なデータを参照し巨大なトランザクションを張るモンスターバッチが爆誕してしまいます。
基本的にはこれらの計算結果は結果整合性で揃えたいところです。
一方で、顧客には翌日の残高と前日の評価損益のようなチグハグなものではなく、一貫性を持った情報を見せたいですよね?[4]
そこで4RAPでは、一貫性を持たせたい出力データに共通のバージョンを付与して対応しました。
先ほどの4RAPのパイプラインの例では、残高日付という概念をバージョンとして採用します。
日付の切り替えが行なわれるとデータの参照先が前日から翌日に切り替わり、結果整合性でデータは生成されるけれど、バージョンを指定して参照する顧客には、データが一貫性を持って生成されたように見せることが出来ます。

以上が、リトライ設計の原則としてのEffectively Onceと、原則に即したバッチ処理の論理設計のプラクティスのご紹介でした。
3. パフォーマンス
Effectively Onceの原則を設計で実現できていると、設計変更でのパフォーマンス向上は打てる手が多いです。
そもそもEffectively Once自体がメッセージングの世界の概念なので、そのままストリーム処理(からのリアクティブシステム)に変えていくことが可能です。(前編の通り、運用容易性を捨てることになるのでトレードオフはありますが)
もう少しライトな方法としては、バッチ内やバッチ単位での並列処理が考えられます。
全ての入力データにIDが振られているので、バッチ内でマルチスレッド処理することは比較的容易にできます。(処理順の前後問題など、若干設計上気にする点はありますが)
バッチ単位の並列化も同様ですね。
どちらで対応するかは処理内容次第です。(メモリを大量に使う処理ならバッチ単位、そうでなければマルチスレッドとか)
パフォーマンス改善は基本は日々の地道な改善活動が一番大事で、弊社エンジニアはかなりしっかりと取り組んでくれています。(感謝)
ただ、奥の手としてアーキテクチャ変更と親和性が高いということは、Effectively Once原則に従った設計の良い点かなと思います。
4. 監視
前編では、4RAPでは運用容易性を重視しており、障害対応の難易度の振れ幅を最小限にするためには、出来るだけ早い段階での障害の検知が大事だと述べました。
そのため、例えばパイプラインの中に少なくとも一つ以上、エラーモニターと呼ばれる監視のためのバッチ処理を組み込むようにしています。

エラーモニターは、名前の通り異常検知を目的としたバッチです。
パイプラインに組み込む際には、そのパイプラインで行なわれた一連の処理の結果(出力データ)が、あるべき姿になっているかを確認します。
例えば以下のようなバッチ処理を持つパイプラインを考えましょう。
- バッチ処理#1 : システムAからの入力データを、正規化してシステム内に取り込み
- バッチ処理#2 : 正規化されたデータを使って、システムBにへの連携用の加工データを出力

このようなパイプラインでは、エラーモニターは何を検証するのが良いでしょうか?
例えばパイプラインがシステムA, B間の単なるプロトコル変換を行なっているとしましょう。
その場合には、変換漏れがないか、入力データと加工データの件数の一致を確認する観点が考えられます。
例えば入力データが顧客からの商品の受注データで、加工データが卸業者への発注データとしましょう。
この場合には、発注漏れや過大発注がないか、入力データの商品ごとの受注数量の合計と、加工データの商品ごとの発注数量の一致を確認するという観点が考えられます。
このような検証を行なうエラーモニターをパイプラインに組み込んでおくことで、
- バッチ処理単独ではなく、一定の処理単位(パイプラインとか)の観点で検証が可能になる
- バッチ処理の直後に検証することで不具合の発生している範囲が限定される(もし検証に失敗したら直前のバッチがおかしい可能性が高い)
- 後続のバッチ処理で障害が発生した時も調査が容易になる(エラーモニターが成功していればのでこの前提は置いて良い)
- 一度発生した障害の観点での検証も導入可能
というようなメリットが得られます。
特に最後の観点は本番運用に自動テストを組み込むようなものなので、万が一デグレが発生しても被害を最小限にできるため、個人的には強くおすすめします。
5. ドキュメント
ドキュメントの残し方については色々な派閥があるかと思いますが、4RAPでは(今のところは)かなりしっかりと設計をドキュメントに残す形で進めています。
というのも、4RAPは開発がかなり進んで終わりが見えてきたとはいえ、まだMVPを揃えていくフェーズにあります。
SoE(System of Engagement)とSoR(System of Record)というシステムの区分けがありますが、MVPを揃えるフェーズでは圧倒的にSoRに属する開発がほとんどです。(MVPが揃って初めてエンゲージメントのための検証が出来るようになるので)
そして、SoRに求められるのは、「(ドメインの)当たり前」を当たり前に実現することです。
しかしながら、ドメインの当たり前はエンジニアにとっての当たり前ではありません。(2つが一致することの方が稀なレベル)
ですので、コードやテストが正という環境では、SoRの「当たり前」が何かを把握する手段がなくなってしまい、誰も触れないコードになっていくリスクが高くなっていきます。[5]
4RAPは出来るだけ長く安定した運用を目指しており、運用容易性を重視しています。
そのため、SoRの機能=4RAPのこれまでの部分に関しては、ドキュメントは怠らないように心がけてきました。
実際に大量のドキュメントを作りつつメンテナンスも継続していますが、実装者の業務要件の誤解を防いだり障害時の調査時間が短縮されるなど、コストに見合ったリターンはあったかなぁと思います。
おわりに
本稿では4RAPの経験をベースに、Effectively Onceの原則に従ったバッチ処理設計のプラクティスを紹介してきましたが、いかがでしたでしょうか?
ここで紹介したものは、今のところ4RAPではうまくワークしていると思っています。
、、、が、ごくごく特定の領域の話に過ぎません。
もっともっとブラッシュアップしていきたいと考えていますので、
- 自分の業界ではこうしている
- このやり方だとこういうケースに対応できない
- やってみたらうまくいった/いかなかった
などあれば、ぜひ皆様の知見をご教示いただけると幸いです。
では皆様、良いお年を!
-
4RAPは導入金融機関の既存システムにアドオンするプロダクトです。
その性質上、既存システムの夜間処理が終わった後に処理を開始し、翌日に業務に間に合うように処理を完了させる必要があり、あまり時間に余裕があるわけではありません。
この障害対応に使える時間的な余裕が少ないことが、データ不正の検知を前倒しして復旧作業に使える時間を出来るだけ長くする設計の背景にあります。 ↩︎ -
オリジナルの1項目は「Identify and discard duplicated messages with 100% accuracy(重複したメッセージは100%特定、破棄され)」ですが、3項目の「…but effects on the resulting state will be observed only once(必ず一回のみ処理される)」で重複の破棄の意味合いが含まれているため、あえて意訳をしてメッセージの特定のみに絞ってあります。 ↩︎
-
システムXがシステム1~Nに依存している = Xは1~Nの存在を知っている状態
相互依存している = Xは1~Nの存在を、1~NはXの存在を知っている状態 ↩︎ -
例えば更新中に顧客が当日の情報と翌日の情報を混合して見せてしまうと、誤った投資判断を誘発する可能性があるため、表示データは出来るだけ一貫性を持たせなければならないという背景があります。 ↩︎
-
テストがあれば当初の「当たり前」に従った品質を担保出来ますが、外部環境(例えば法令)が変われば、それに伴い「当たり前」が変わっていきます。
テストを新しい「当たり前」に追従させるためにも、(少なくともSoRでは)何かしらのドキュメントは必要じゃないかと考えています。 ↩︎
Discussion