プログラムの計算量とは?オーダー記法など基本的なことまとめ
はじめに
この記事は ミライトデザイン Advent Calendar 2021 の 15 日目の記事となっています。
前回は「競技プログラミングをしなくても知っておきたい計算量のはなし」という記事を書いてくれた ほげさん でした。
今回の記事はそれに続いて、そもそも計算量とはなんですか? といった人向けに、というより自分の整理用にざっくりとまとめてみようと書き始めた記事となっています。
計算量についてあまりわからないという人は、この記事を読んだ後にもう一度ほげさんの記事を読んでみると面白いと思います。
計算量とは?
そもそも、計算量とは何?って人はいないでしょうか。
正直アドカレで計算量について書こうと決まるまで、自分はよく分かってなかったです。
で、計算量とは何かをざっくり説明すると、プログラムの計算効率はどのぐらいなのかを測る指標のようなものです。
プログラムの処理には計算や、繰り返し、比較などの様々な処理がありますが、これらの処理はデータ(要素)がどれぐらい増えたらどれぐらいの割合で実行時間が増えていくのかを表したりします。
計算量には大きく
プログラムが処理を実行する際にどれぐらいの「手順」を必要とするのかを指標とするもの と、
プログラムが処理を実行する際にどれぐらいの「メモリ」を必要とするのかを指標とするもの の 2 種類があります。
これらの指標を使って、より効率的なアルゴリズムを測ったりします。
時間計算量
時間計算量は先述の通り「プログラムが処理を実行する際にどのぐらいの手順を必要とするのか」を表す指標です。
1 万回の処理を実行するより、1 回の処理を実行する方が短い時間で実行できますよね。
そういった処理の手順回数(ステップ数)を比較して、より短い時間で実行できる効率のよいアルゴリズムを測ることができます。
空間計算量
空間計算量も先述の通り「プログラムが処理を実行する際にどのぐらいのメモリを必要とするのか」を表す指標です。
時間計算量の手順回数とは違い、空間計算量はプログラムの実行に必要なメモリを表します。
最近ではパソコンのメモリは大幅に増えていることから、空間計算量を気にするよりは時間計算量を気にすることの方が効率的なアルゴリズムを求めることができます。
そのため、単に計算量というと時間計算量を指すことが多いでしょう。
( この記事でも以下「計算量」を「時間計算量」と指す )
オーダー記法を使おう
さて、ここまでの解説で計算量という指標を使用し、より効率的なアルゴリズムを測ることができるということはわかりましたが、具体的にはどうやって測るのでしょうか。
計算量は一般に、オーダー記法(
ただし、プログラムの処理は実行マシンやメモリ容量、プログラミング言語などによって影響されるため、厳密な計算量は計れません。
ですので、オーダー記法というのは大雑把にこれぐらい早くなるよとか、こっちの処理の方が効率はいいよなどを評価するものと思ってください。
そして、オーダー記法は
詳細はこの後説明しますが、「この処理は
よくある代表的なものだけでも覚えておくと良いと思います。
オーダー記法の考え方
オーダーは先述でもある通り
例えば
例として、100 万件の csv を繰り返して何かしらの処理を実行するとしたら、100 万に比例した回数の処理が実行されるということになります。
// $csvは100万件なので100万回のループとなる
foreach ($csv as $cols) {
echo $cols[0] // 何かしらの処理1
echo $cols[1] // 何かしらの処理2
}
この場合はループの中で 2 回処理が実行されるので、**100万件 × 何かしらの処理2回 = 200万** で 200 万回の処理が実行されることになります。
// $csvは100万件なので100万回のループとなる
foreach ($csv as $cols) {
// csvの項目は100項目なので100回のループとなる
foreach ($cols as $cal) {
echo $cal // 何かしらの処理1
}
}
1 行に 100 項目のデータがあるとしたら 100万件 × 100項目 × 何かしらの処理1回 = 1億 になるので、1 億回の処理が実行されることになります。
ですので、大雑把に
小さい数値は無視する
大雑把に処理の評価はできますが、実際のプログラムでは
オーダー記法はデータ(要素)の数を数百件や数千件のものではなく、0 または ∞ に近い数値で評価します。
最初の例の場合は何かしらの処理が 2 回あったので
何かしらの処理が 3 つとなり
さらに、ある処理の中で複数のステップがある場合は
以上のことから、ある処理を
このように「大体
代表的なオーダー記法の種類
ここでは概要だけ紹介します。
詳細の方は ほげさんの記事 や参考にした こちら の記事をみてください。
O(1)
一番計算量が少ないもので、定数時間と呼びます。
データ量にかかわらず、定数の回数だけで処理回数が完了するものです。
配列のインデックスアクセスや、(線形)リストの先頭への要素追加や先頭要素の削除などが当てはまります。
O(N)
データの数に比例して処理時間がかかります。線形時間と呼びます。
配列などのループ。
O(N^2)
線形時間より遅い 2 重ループなどが当てはまります。二乗時間と呼びます。
O(log N)
二分探索などで処理を減らすアルゴリズムで、対数時間と呼びます。
これ以上は改善する必要がないもので、ソート済み配列の二分探索などで使用されます。
計算量の大小
ここまで読んで、計算量の大小が分かったのではないでしょうか。
今回例であげた代表的なものを比較すると以下のような関係になります。
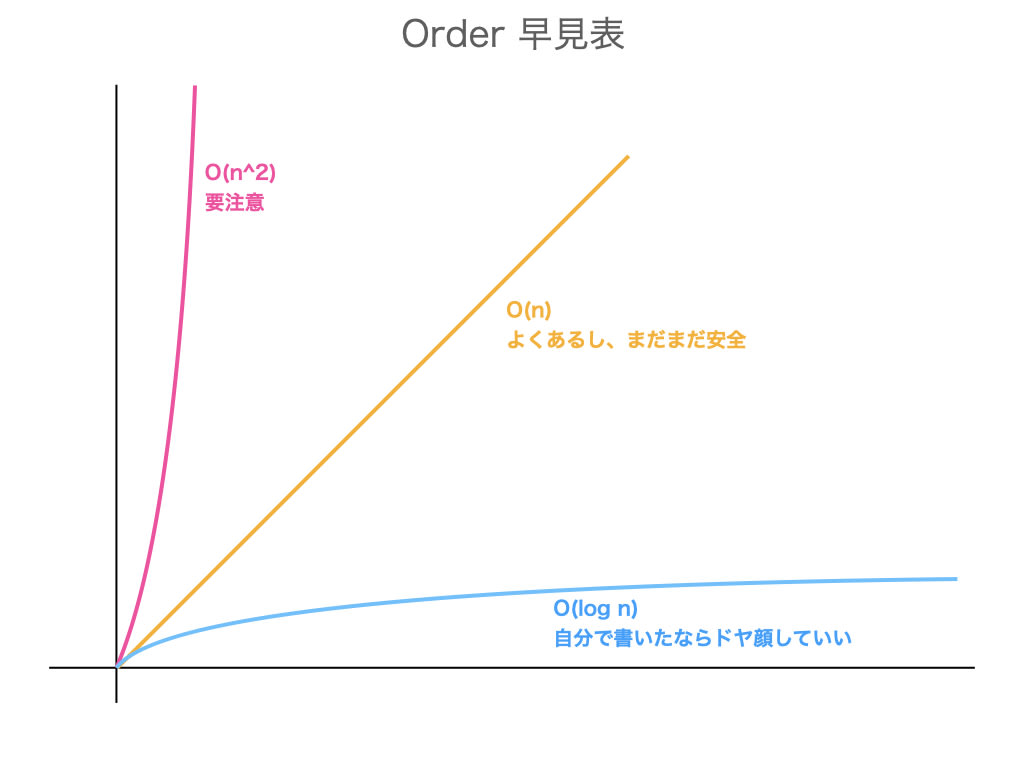
競技プログラミングをしなくても知っておきたい計算量のはなし より引用
ここを意識して実装できるようになるとまた初心者から一歩成長できると思います。
おわりに
これで「計算量ってなに?」って状態からは脱却できたのではないでしょうか。
計算量を求めるには具体的に処理を見て判断したりするので、サンプルのコードを見ながらの方がわかりやすいのですが、この記事では導入ということで具体的な求め方は省きました。
最初にも言ったように、この記事を読んで「そもそも計算量とは?」って状態から脱却できたら、ほげさんの記事 を読み返してみると面白いと思います。
そして、今後は「動く機能を作れる」から「パフォーマンスを考えた上で機能を作れる」って状態を目指していきたいなと思います。
さて、次回の記事はアドカレ初登場のミライト代表 hiroさん の記事です。
どんな記事が書かれるか楽しみですね。
Discussion