WaveNet解説 / 音声生成、音声分析モデル
0. 概論
Wavenetとは、PixelCNNをベースにした音声波形を生成するための機械学習モデルです。
原論文(2016)
Wavenetは非常に流暢かつ自然な音声を生成することができ、また音声認識のタスクでもSOTAを達成しました。
1. Wavenet
1.1 全容
WaveNetは、オーディオ波形の生のサンプルを直接モデリングする深層ニューラルネットワークです。
過去の音声サンプルの確率的分布を学習し、その分布に基づいて新しいサンプルを一つずつ生成します。
- Wavenet

1.2 CAUSAL CONVOLUTIONS
WaveNetは因果関係を保つために、causal(因果) convolutionを使用します。
PixelCNNと同様に、WaveNetは過去のデータに依存せずデータの予測を行います。
音声データは1次元なので、一次元の畳み込みを活用してデータを畳み込みます。この時、データ総数-1分だけ入力データをパディングすることで、入力→モデル→出力で、モデルが予測を行う際に、自身の位置のデータポイント以前のデータを利用しなくなります。
・causal convolutions
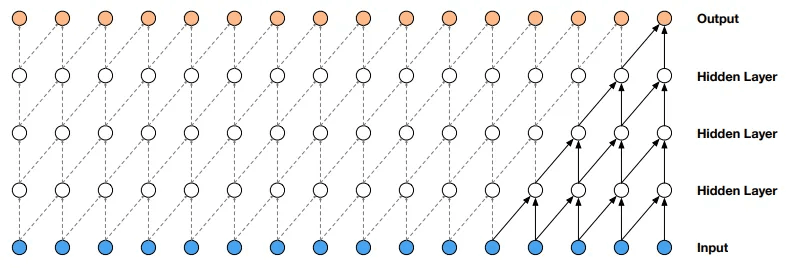
※outputの一番左上が最初の出力であり、この出力には(一番左下の)最初の入力の情報しか含まれていないことを理解できます。
causal convolutionの主な利点は、RNNと比べて、再帰接続がないため計算が早いことです。
※RNNも因果関係を尊重します
対して問題点は受容野が少ないことです。
「受容野」とは、ネットワークのある層の出力が依存する入力データの範囲を指します。例えば上記のイメージ図ではカーネルサイズ5、ストライド1で畳み込みを行なっていますが、隠れ層が3層の場合1つの出力に対して5つの入力情報しか利用できず、長期的な因果関係を学習することが出来ません。
これを解決するには、カーネルサイズを増やすか層数を増やす必要があります。
しかし、この手法にも問題があります。
これを解決するのがDILATED CAUSAL CONVOLUTIONS(拡張因果畳み込み)です。
1.3 DILATED CAUSAL CONVOLUTIONS
上記のcausal convlutionにdilated(拡張)が追加された畳み込みです。
dilated causal convlutionでは特定の間隔で入力値をスキップすることによって、フィルタ(カーネル)の幅よりも大きな領域にわたってフィルタが適用されます。
・dilated causal convlution(概要)
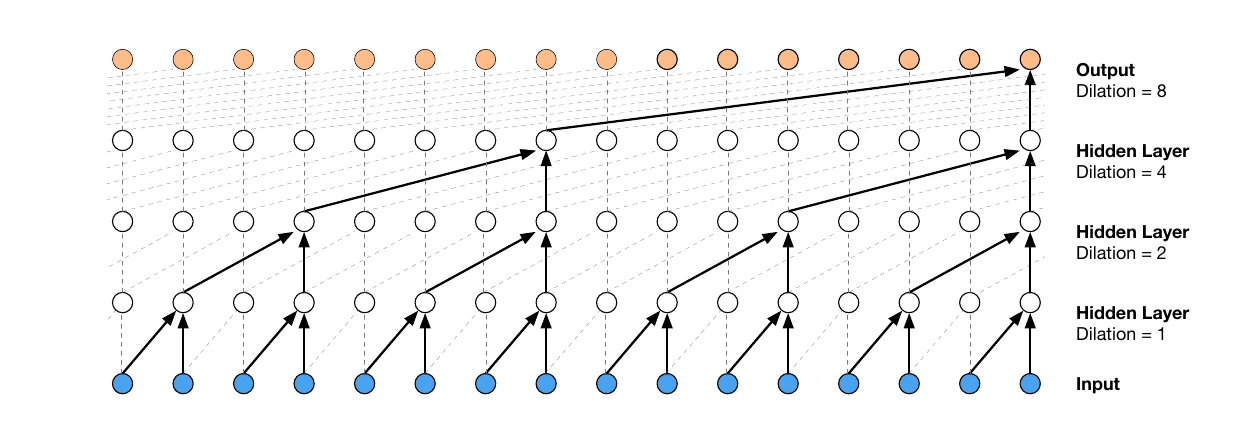
※ある位置のニューロンは、前の層のいくつかのニューロンだけに依存し、次の層のニューロンに影響を与えるニューロンの数は指数関数的に減少します。
通常のcausal convolutionと比較してみると、直接的に各ニューロンに影響を与えるニューロンの数は同じですが、各出力値は下の行の入力全てから影響を受けます。
これによりcausal convolutionと同じ計算量で、より大きな受容野を達成できます。また受容野は層数と共に指数関数的に増加することも非常に嬉しいポイントです。受容野の増加に非常に効率よく対応できるようになりました。
これを利用した信号生成のイメージを以下に示します。
・dilated causal convlution(生成の流れ)

上図はdilated causal convlutionを用いた生成のイメージです。input→hiddenlayer→outputという学習の流れを考えた時、生成されたoutputはこれまでの時系列につながる生成データとなります(入力データインデックス[1,2,3]の場合、[4]が予測、出力される)。従って、これを新しい入力データとして追加することで、次の出力が可能になります([1,2,3,4]→[5])。
1.4 SOFTMAX DISTRIBUTIONS
ここでは、1.4.1で音声データの基礎を、1.4.2でsoftmaxレイヤを理解します。
1.4.1 音声データの形式
オーディオデータは通常、時間に沿った一連のデータとして記録されます。
各データの値は音の振幅(大きさ)を表し、16ビットの整数で表されます。これによってオーディオデータの振幅は-32768から32767、合計65536の値を取ることが出来ます。
1.4.2 softmaxレイヤ(標準化)
オーディオデータの値は大きな範囲を取るため、softmaxで範囲を制限する必要があります。WaveNetではこのためにμ-lawコンパンド変換を使用します。
μ-lawコンパンド変換は、オーディオデータのダイナミックレンジ(最小値と最大値の範囲)を圧縮するために使用される非線形変換です。
これにより合計65536範囲のオーディオデータが256の範囲に変換され、計算コストが減少します。
最終的には、聴覚可能な形式に戻すために逆μ-lawコンパンド変換が行われます。
・μ-law変換
- option
sign
f(x_t)
x_t
μ
これは、データの前処理として畳み込みの前に行われます。
1.5 GATED ACTIVATION UNITS
WaveNetでは、PixelCNNと同じゲート付き活性化関数を使用しています。
- option
z
x
*
\odot
\delta
tanh
k
W_{k,f}
W_{k,g}
活性化関数を通した後にゲートを乗算することで、伝達する情報の取捨選択ができるようになります。
1.6 RESIDUAL AND SKIP CONNECTIONS
残差接続(residual connection)とスキップ接続(skip connection)の両方がネットワーク全体で使用され、高速かつ深いモデルの学習を可能にします。
1.7 CONDITIONAL WAVENETS
WaveNetは、特定の条件(例えば異なる話者)を持つ音声を生成するために、追加入力による条件付けが可能です。
これにはGlobal conditioning(グローバル条件)とLocal conditioning(ローカル条件)があります。
例えばTTS(Text to Speech)の場合、以下のようになります。
1.7.1 Global Conditioning(全体条件付け)
グローバル条件とは生成される音声全体に対して特性を与えます。これは、話者のアイデンティティ(性別、年齢等)や感情などが考えられます。
グローバル条件付き生成を行う場合、活性化関数は以下のように変更されます。
- option
^T
\textbf{h}
1.7.2 Local Conditioning(一部条件付け)
ローカル条件は、より細かい制御を行います。例えば、音声のピッチや音量の変動など、時間に応じて変化する特性を与えることが出来ます。
ローカル条件付き生成を行う場合、活性化関数は以下のように変更されます。
-option
ローカル条件付けベクトル
つまり、条件を付与するベクトルを時系列の感覚に合わせて追加することで、音声の各時点における特性を付与します。
これらの条件(global,local)は同時に付与することもできます。
1.8 CONTEXT STACKS
context stacks(コンテキストスタック:文脈に応じた積み重ね)は、WaveNetの受容野のサイズを増加させるための補完的なアプローチです。
コンテキストスタックとは、拡張因果畳み込みや残差接続、スキップ接続などを取り入れた別個の小さなモデルまたはネットワークを指します。
この小さなモデルは次の流れで利用されます。
-
コンテキストスタックの利用
まず、コンテキストスタックはオーディオ信号の比較的長い部分を処理します。これは、信号の長期的な特徴やパターンを捉えることを目的としています。コンテキストスタックによる処理を通じて、信号の長期間にわたる依存関係やコンテキストが要約され、エンコードされた形で情報が得られます。 -
情報の条件付けへの利用
次に、このコンテキストスタックによって得られた情報を、別のWaveNetモデル(主モデル)がオーディオ信号のより短い部分を処理する際のガイドとして利用します。具体的には、この情報を主モデルに入力として提供し、モデルが生成するオーディオの特定の部分が、より広いオーディオ信号の文脈に適合するようにします。
これにより、モデルは長期的な依存性を向上させることが出来ます。(話題や音楽テーマの一貫性を保つ)
補足:コンテキストスタックの特徴
コンテキストスタックの特徴
-
コンテキストスタックの多様性
長さや隠れユニット数の異なる複数のコンテキストスタックを使用することができます。これにより、モデルはさまざまな時間スケールでの情報を捉えることができます。 -
受容野とユニット数の関係
大きな受容野を持つコンテキストスタックは、層ごとのユニット数が少なくなるように設定されます。
これは、長期的な時間的相関をモデル化するために、必ずしも大量の計算能力が必要ではないという直感に基づいています。 -
プーリング層
コンテキストスタックによる情報の取得が、より低頻度で実行されるようにプーリング層を含むこともできます。
これにより計算コストを抑えながら、長期的な情報を効率的に処理できます。
2. 評価
実際のWaveNetはどの程度の性能を持つのでしょうか?
ここではそれぞれのタスクについて軽く紹介します。
2.1 複数話者の音声生成
単一のWaveNetは、話者109人のone-hot encodingベクトルを生成条件とすることで、
全ての話者の音声をモデル化することが出来ました。
これは、データセットの109人全ての話者の特徴を1つのモデルで捉えられることを示しています。
また、話者のデータが1人の場合と、複数人の場合を比較したときに、検証セットにおける性能が向上することが確認されました。これは、WaveNetの内部表現の学習が複数の話者の間で共有されていることを示唆しています。
2.2 言語的特徴による条件付け
WaveNetは、言語的特徴を条件とした場合、自然なリズムやアクセントを持つ音声サンプルを生成することが出来ました。時々不自然なリズムやアクセントが見受けられましたが、これはWaveNetの受容野が240ミリ秒であり、基本周波数の長期依存性を捉えるには短すぎたことが原因とされ、「低周波数の外部のモデルによって学習された入力の長期依存性の情報」を条件としてWaveNetを学習することで解決されました。
これは、WaveNetの拡張性や対応性と、高品質な音声データ生成が可能であることを示しています。
2.3 音楽
著者らによる主観的な評価をまとめます。
・生成された音楽は心地良かったが、長期的な一貫性には欠けていた
・良い結果を得るためには広い受容野が必要
・音楽ジャンルや楽器による条件付けも有望な結果が得られた
2.4 音声認識
WaveNetはTIMITデータセットの「音声から音素を導出する」というタスクでSOTA(18.8%の音素誤認)を達成しました。
著者らは、モデルを音声認識という新しいタスクに適合させるために以下の処理を追加しました。
・因果畳み込みの後にプーリング層を追加(データ次元削減)
・その後に、幾つかの通常の畳み込み層を追加(音素の特徴抽出)
・損失関数のハイブリット。損失関数を、従来の音声の振幅などを予測するものと、ある区画の音素の分類を行うものの2つを採用することで、モデルは入力全体の構造やコンテキストと、音声の微細な部分の詳細の両方を捉えられるようになります。
ここで行なった変更は、「音素を分類する」というタスクに焦点を当てているため、他のタスクでは使用できないかもしれませんが、上記のような拡張性が許されていることは、このモデルが様々なタスクに非常に応用しやすいことを示しています。
またSOTA達成の背景には、モデルの大元の部分である「WaveNetが拡張畳み込みのレイヤーを重ねることで受容野を長くすることができる」という特性から、LSTMユニットを使うよりもはるかに効率よく長期的な入力を受け取れるようになったことも影響していると考えられます。
3. まとめ
今回は以上になります。音声生成や信号分析の分野で現在も幅広く使われているモデルで、非序に汎用性が高いと考えられます。興味がある方はぜひ原論文を読んでみて下さい。
参考
(1) WaveNet: A Generative Model for Raw Audio (Link)
(2) Day 3: WaveNet: A Generative Model for Raw Audio (Link)
(3) tensorflow-wavenet (Link)
(4) [WaveNet: A generative model for raw audio] (Link)
Discussion
図2のカーナルサイゼが2じゃないですか?