PixelCNNの解説、実装
今回はPixelCNNについて解説します。
原論文: Pixel Recurrent Neural Networks
0. 概論
PixelCNNは画像の分布を学習し、新しい画像を生成するモデルです。
同じ用途のモデルにはGANやVAEがあります。
PixelCNNは次のピクセル、次のピクセルという形で再帰的に次のピクセルの値を予測することで画像の分布を学習します。
この動作は自然言語処理に似ているため、そちらを学んだことのある人は理解しやすいかもしれません。
本記事ではシンプルなPixelCNNを扱います。
1. PixelCNN
1.1 原理
PixelCNNは画像のピクセルに対し、左上から順番に次のピクセルの値を予測するように学習します。
・流れ
左上の
↓
↓
↓
...
これを続けて、
・イメージ
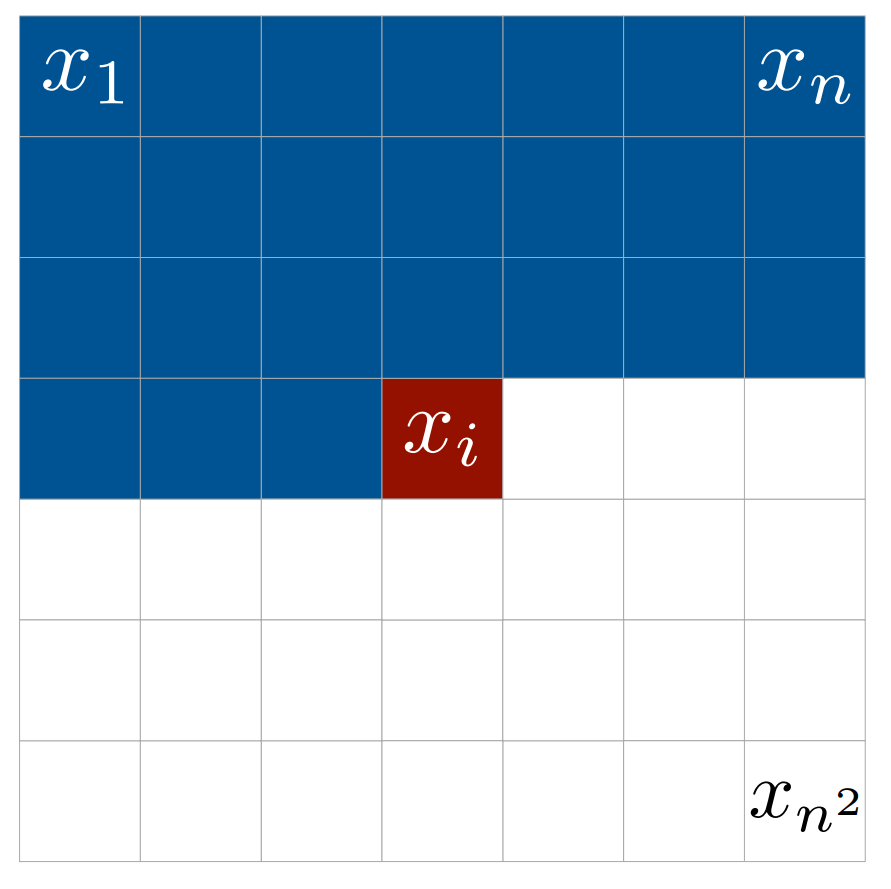
数式で表すと、解像度が
ex. 全ピクセルが黒である確率:
これを条件付き確率の形で書くと
ex. 全ピクセルが黒である確率:
のように条件付き期待値の積で表されます。
PixelCNNでは、教師データ画像の確率分布を学習し、その確率分布に従って画像の生成を行うことで教師データに似た画像を生成します。
1.2 マスク
PixelCNNでは順番に予測を行うため、モデルが
そのため、以下のように畳み込みフィルタをマスクし、以前の情報のみを使用します。
掛けられるマスクは、例えば5×5のフィルタでは以下のようになります。中央が自分自身の位置に対応します。

マスクによって、自分自身とそれ以降の情報を使用しない畳み込み演算が可能になります。過去のデータのみを利用することで、連続性,一貫性のあるデータの生成を可能にしています。
畳み込み演算の数式は以下です。通常の畳み込み演算のフィルタにマスクをかけているだけです。
- 記号
x
i
g
W
mask
1.3 マスクAとマスクB
マスクについて詳しく学ぶために、PixelCNNの大枠と、何を行なっているかを理解する必要があります。
・ 学習の大枠
PixelCNNは以下の構造で学習を行います。
入力画像
↓
畳み込み(繰り返し)
↓
出力画像
↓
正解データと比較
↓
モデルの重み更新
畳み込みの後、教師データに似た画像(の確率分布)を出力します。
PixelCNNでは、「出力画像のピクセル
PixelCNNでは2種類のマスクを使用します。
・ マスクA

・ マスクB

基本的なマスクの役割は、未来の情報を遮断し過去の生成データから生成を行うことで、データの因果関係を学習することです。
一番最初のレイヤではマスクAを使用します。
最初の層での畳み込みは、入力画像のデータ
これにより、出力される特徴マップの各ピクセルは、過去のピクセルのみから推測され、モデルは過去のピクセルから未来のピクセルへの因果関係を学習します。
深層学習の2層目以降では、マスクBを使用します。これは、前の層で得た特徴マップを効率よく利用するためです。
マスクBでは、
これにより各ピクセルは、畳み込みに前層の特徴マップの自分の位置の情報を利用することができます。畳み込みにおいて、「自分の位置の情報」は、自分の位置周辺から畳み込まれたデータの結晶(入力の周辺データの情報が圧縮されている)なので、これが利用できるようになるとモデルの認識能力が大きく向上します。
このように、マスクBを使用する層では「
最終的には256チャネルの画像確率分布が出力され、これが教師データに似た画像を出力するように損失関数を設定しています。従ってこのモデルは、入力画像の因果関係のうち、正解データに含まれる「過去のピクセルから未来のピクセルへの因果関係」を学習します。
ちなみに特徴マップの
・入力画像について
PixelCNNの学習では、入力と正解データに同じ画像を利用します。これにより、正解データに含まれる因果関係を直接的に、効率的に学習することができます。
ここで懸念されることは、入力と出力が恒等写像のため、モデルがが入力をそのまま出力にコピーするような学習をするリスクについてです。
しかし、これはあまり問題になりません。skip connectionを有さないCNNは恒等写像の学習が苦手な上、PixelCNNではモデルが次のピクセルの値を予測するために、以前のピクセルの値から何か有意義な情報を抽出し、学習する必要があります。すなわち、モデルは入力画像を単にコピーするのではなく、畳み込みにより抽出された画像内の特徴と次のピクセル間の複雑な依存関係(大まかに言うと、こういう形状が来たらこういうデータを次に出力すると教師データっぽい画像になるなぁ...という関係)を学習します。
実際には様々な入力画像を畳み込んで(特徴を抽出して)、正解データと似たような画像を生成できる因果関係を学習するため、教師データの量があればモデルはある程度一般化されます。
少し補足
・入力画像と教師画像の関係
入力画像と正解画像を同じ画像にすることで、より効率的に正解画像のピクセル間の因果関係を学習できます。
実際の所、モデルの更新はモデルの出力と正解データにより行われるため、学習時の入力画像には依存しません。しかし、学習されるべき因果関係(教師画像が持つ因果関係)を入力画像が多く保持している方が効率的に学習できます。
入力画像を変更する場合(ノイズを追加するなど)は、生成時にノイズを含む入力画像から、教師データに近い画像を生成したい場合などが考えられます。
しかし一般的に生成時は全て白などの空の画像から生成が行われるため、あまり使うことはなさそうです。
モデルは入力画像に存在する特徴の因果関係のうち、教師画像に含まれる因果関係のみを強く学習し、教師画像に似た画像を生成できるようになります。従って、入力画像には「教師画像に含まれる因果関係」が多く含まれる方が効率的であり、ランダムな画像でも因果関係の学習は可能ですが、「教師画像に含まれない因果関係」は重みの学習に不要であまり使われないため、非効率な学習となってしまいます。効率の面から考えて、入力は教師画像が望ましいと考えられます。
・ 出力と損失関数
pixelcnnの最終的な出力はoutput_channelが256個の1×1畳み込み(各ピクセルに対応する256個の変数を掛ける(ただ重みをかけて確率分布化する。線形変換))による、各ピクセルの256個の確率分布です。
例:
この確率と、教師データのクロスエントロピー誤差を取ることで、確率分布と正解データを比較して、推論が教師データに似るように学習を行なっています。
出力画像の正解は一意ではなく複数存在するため、そのような教師データのピクセル値の確率分布を模倣するために出力を確率分布にしています。(スカラによる平均二乗誤差などではなく、1_1畳み込みを使用して出力を確率分布にして損失を計算しています。スカラにすると、教師データの平均を取ったようなぼやけた画像が出力されることが予想されます)
・マスクB
マスクBは、自分を中心とした入力の特徴を捉えたデータを使用できるため、特徴抽出能力が高いです。例えば学習して鼻検知フィルタができた場合、このフィルタの出力を同じ場所のフィルタが受け取れるため、情報がそのまま伝達します。マスクAでも特徴マップは使用できますが、抽出した特徴情報がずれていきます。
・生成手法
画像の生成時には、各ピクセルに対して得られた確率分布にsoftmaxをかけて、その確率分布に従いピクセルの値を選択します。
- 要約
マスクA,マスクBを利用して未来のデータを利用しないことで、モデルは教師画像に含まれる因果関係を学習することができます
2層目以降は、前層の特徴マップの自信の位置のデータ(x_i
1.4 損失関数
PixelCNNにデータが入力されると、学習した因果関係に従ってデータが構築され、最終的に各ピクセルにおける色値(0~255 : 白=黒)の確率分布を出力します。
出力のデータ形状は(生成枚数, 256, 高さ, 幅)で、2次元目の256個の配列に、各ピクセルが色値としてindexの値をとる確率が格納されます。
・ 出力の例
PixelCNN_output[:,:,0,0] = [0.01, 0.03, ... 0.02]
# この時、左上のピクセルは0.01の確率で白、0.03の確率で一番白に近いグレー、0.02の確率で黒をとる(indexが色値に対応)
# このような確率分布が各ピクセルに対して出力される
この出力の確率分布と、正解画像の各ピクセルの色値との交差エントロピー誤差を損失関数とすることで、教師データ(正解画像)に似た画像を生成するようにモデルが学習されます。
少し補足
交差エントロピー誤差は、分類タスクにおける予測確率分布と正解データとの損失を計算するための損失関数です。「確率分布」と「正解の値」という次元の異なるデータを比較して損失を計算することができます。
この損失に基づいて、教師データのような画像を生成するようにモデルの重み(CNNのフィルタの値)が更新され、類似画像を生成するようになります。
2. 実装
ここからはPyTorchを使用して実際にPixelCNNを実装します。
- インポート
# Please execute in GPU env.
import matplotlib.pyplot as plt
import numpy as np
import torch
import torch.nn.functional as F
from torch import nn, optim
from torch.utils import data
from torchvision import datasets, transforms, utils
各種ライブラリをインポートします。
- マスク付畳み込み層
class MaskedConv2d(nn.Conv2d):
def __init__(self, mask_type, *args, **kwargs):
super().__init__(*args, **kwargs)
assert mask_type in ['A', 'B']
self.register_buffer('mask', self.weight.data.clone())
h = self.weight.size()[2]
w = self.weight.size()[3]
self.mask.fill_(1)
# マスクタイプによる場合分け
if mask_type == 'A': # 自分自身も見ない
self.mask[:, :, h // 2, w // 2:] = 0
self.mask[:, :, h // 2 + 1:] = 0
else: # 自分自身は見る
self.mask[:, :, h // 2, w // 2 + 1:] = 0
self.mask[:, :, h // 2 + 1:] = 0
def forward(self, x):
self.weight.data *= self.mask
return super().forward(x)
- class MaskedConv2d(nn.Conv2d):
pytorchの二次元畳み込みクラスを継承 - super().__init__(*args, **kwargs)
親クラスのinitメソッドを呼び出し - assert mask_type in ['A', 'B']
mask_typeがAもしくはBであることを確認 - self.register_buffer('mask', self.weight.data.clone())
nn.Conv2dが継承しているnn.Moduleのメソッドであるregister_buffer()を使用してbuffur(モジュールの状態の一部だが、学習されるべきではないパラメータ)に、重みと同じ形状のmaskを"mask"という名称で追加します。このデータの勾配は計算されません。また以後は名称を用いてself.maskとして呼び出すことができます。 - h = self.weight.size()[2], w = self.weight.size()[3]
CNNの重み形状は通常、(出力チャネル数(フィルタ数), 入力チャネル数(入力特徴マップのチャネル数。rgbなら3チャネル), フィルタの高さ, フィルタの幅)となります。イメージは、縦横の大きさを持つフィルタ数分のフィルタが、各入力チャネル分用意されている状態です。この形状データから高さと幅のサイズを抜き出します。
※イメージ図 (3, 5, h, w)
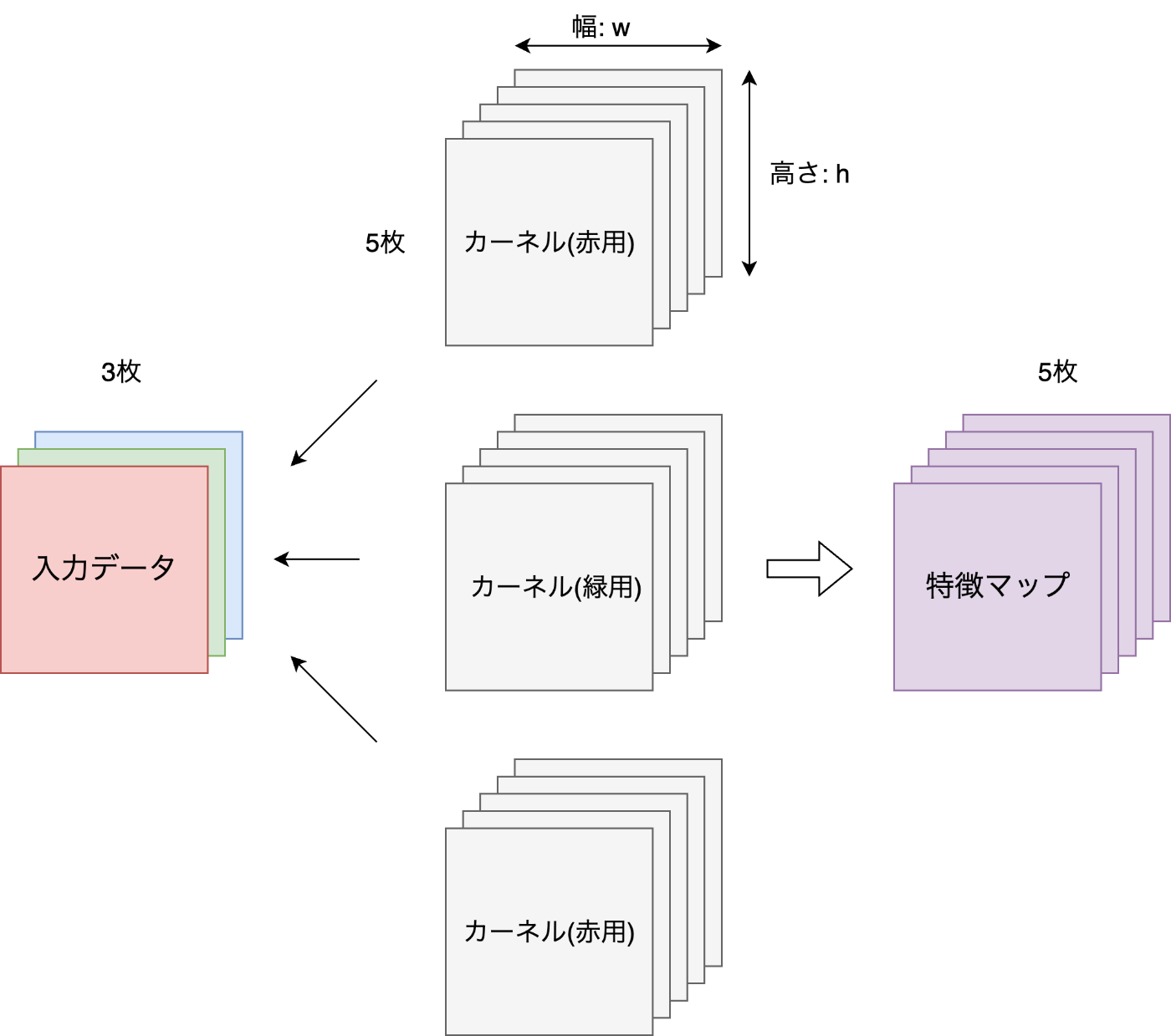
1枚目のカーネルがそれぞれの入力に畳み込みを行い、得られた3枚の特徴マップを合わせて(和や平均)紫の出力(特徴マップ)の1枚目になります。 - self.mask.fill_(1)
マスクを全て1で初期化 - if mask_type == 'A': ...
マスクAとマスクBを選択 - def forward(self, x):
xに対して順伝播を行う関数 - self.weight.data *= self.mask
使用される重みにマスクをかける - return super().forward(x)
継承元の二次元畳み込みを呼び出す
- PixelCNN
class PixelCNN(nn.Module):
def __init__(self, num_of_channels=32, n_layers=7, output_channels=256):
super().__init__()
self.layers = nn.ModuleList()
# 最初のブロック
self.layers.append(MaskedConv2d(mask_type='A',
in_channels=1,
out_channels=num_of_channels,
kernel_size=7,
stride=1,
padding=3,
bias=False))
self.layers.append(nn.BatchNorm2d(num_of_channels))
self.layers.append(nn.ReLU(inplace=True))
# 後続のブロック
for i in range(1, n_layers+1):
self.layers.append(MaskedConv2d(mask_type='B',
in_channels=num_of_channels,
out_channels=num_of_channels,
kernel_size=7,
stride=1,
padding=3,
bias=False))
self.layers.append(nn.BatchNorm2d(num_of_channels))
self.layers.append(nn.ReLU(inplace=True))
self.layers.append(nn.Conv2d(in_channels=num_of_channels,
out_channels=output_channels,
kernel_size=1))
def forward(self, x):
out = x
for layer in self.layers:
out = layer(out)
return out
- class PixelCNN(nn.Module):
pytorchのニューラルネットクラスを継承 - def __init__(self, num_of_channels=32, n_layers=7, output_channels=256):
初期化関数- 引数
num_of_channels: 畳み込みのフィルタ数
n_layers: 中間層の数。畳み込みを何回繰り返すか
output_channels: 出力空間の大きさ。通常は出力画像の枚数を示すが、PixelCNNのようなピクセル単位で生成を行うモデルの場合、ピクセルへの出力値が取りうる範囲を示す。例えば白黒画像の場合、値を256にすれば、0~255(0:白, 255:黒)までの段階のグレーの色が生成範囲となる
- 引数
- self.layers = nn.ModuleList()
pytorchのモジュールリストを定義。このリスト内部のモジュールは自動微分システムに認識される - self.layers.append(MaskedConv2d(mask_type='A', in_channels=1, out_channels=num_of_channels, kernel_size=7, stride=1, padding=3, bias=False))
最初の畳み込み層- 引数
mask_type='A': 一枚目は自分の位置も見ない
in_channels=1: 入力画像の枚数(rgbなら3)
out_channels=num_of_channels: 出力枚数。フィルタ数と同じ
kernel_size=7: 7×7のフィルタを使用
stride=1: 畳み込み計算時にフィルタを動かす量
padding=3: 入力画像を外側に広げる- 出力画像のサイズO (h = wの時):
O = \dfrac{h + 2P - F_h}{S} + 1
h
w
P
F_h
F_w
S
今回はO = \dfrac{h + 2×3 - 7}{1} + 1 → O = h
- 出力画像のサイズO (h = wの時):
- 引数
- self.layers.append(nn.BatchNorm2d(num_of_channels))
バッチ正規化で学習を安定させる。層に入力されたバッチを平均0分散1に正規化(出力:x \gamma, \beta y = \gamma x + \beta - self.layers.append(nn.ReLU(inplace=True))
活性化関数。モデルに非線形性を与え表現力を高める - self.layers.append(MaskedConv2d(mask_type='B', in_channels=num_of_channels, out_channels=num_of_channels, kernel_size=7, stride=1, padding=3, bias=False))
マスクBを使用した畳み込みレイヤを中間層の数だけ定義。 - self.layers.append(nn.Conv2d(in_channels=num_of_channels, out_channels=output_channels, kernel_size=1))
1×1の畳み込み層を最終層として、255個のチャネルの形で各ピクセルに対する色値の確率分布を出力する。最終出力形状は(バッチサイズ, 256, 高さ, 幅)となり、入力画像と同じ形状のチャネルが256枚出力される。 - def forward(self, x):
定義した各レイヤに入力を通す
- データローダー(データセット)定義
trainloader = data.DataLoader(datasets.MNIST('data', train=True,
download=True,
transform=transforms.ToTensor()),
batch_size=128, shuffle=True,
num_workers=1, pin_memory=True)
testloader = data.DataLoader(datasets.MNIST('data', train=False,
download=True,
transform=transforms.ToTensor()),
batch_size=128, shuffle=False,
num_workers=1, pin_memory=True)
pytorchライブラリからMNISTデータセットをdataloaderごとtensorで取得します。
- 引数
num_wokers: メインの処理系から独立して並列処理を行うサブプロセスの数
pin_memory: メモリの固定。ロードが高速化される
- 学習
num_of_layers = 7 # 畳み込み層の数
num_of_channels = 64 # チャネル数
num_of_epochs = 50 # エポック数
X_DIM = 28 # 画像のサイズ(高さ及び幅) 学習に使用するMINST画像データのサイズ、かつ生成画像のサイズ
NUM_OF_VALUES = 255 # とりうる値の幅
device = 'cuda:0' # GPUデバイス
各種設定
pixel_cnn = PixelCNN(num_of_channels, num_of_layers)
optimizer = optim.Adam(list(pixel_cnn.parameters()))
criterion = nn.CrossEntropyLoss()
train_losses, test_losses = [], []
for epoch in range(num_of_epochs):
# 学習
train_errors = []
pixel_cnn.train()
for x, label in trainloader:
target = (x[:,0] * NUM_OF_VALUES).long()
loss = criterion(pixel_cnn(x), target)
train_errors.append(loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 評価
with torch.no_grad():
test_errors = []
pixel_cnn.eval()
for x, label in testloader:
target = (x[:,0] * NUM_OF_VALUES).long()
loss = criterion(pixel_cnn(x), target)
test_errors.append(loss.item())
print(f'epoch: {epoch}/{num_of_epochs} train error: {np.mean(train_errors):0.3f} \
test error {np.mean(test_errors):0.3f}')
train_losses.append(np.mean(train_errors))
test_losses.append(np.mean(test_errors))
ローダーから取得した画像を正解データとして、学習を行います。
- pixel_cnn = PixelCNN(num_of_channels, num_of_layers)
pixelcnnのインスタンス化 - optimizer = optim.Adam(list(pixel_cnn.parameters()))
最適化アルゴリズムに更新すべきパラメータを伝える - criterion = nn.CrossEntropyLoss()
損失関数を定義。分類タスクで一般的な交差エントロピー誤差
以下学習
- for epoch in range(num_of_epochs):
エポック数だけ繰り返す - pixel_cnn.train()
モデルを学習モードに変更 - for x, label in trainloader:
特徴データと正解ラベルを取得。xには[バッチサイズ, チャネル数, 高さ, 幅]のデータが格納されている。今回は白黒画像なのでチャネル数は1。ラベルは今回使用しない。 - target = (x[:,0] * NUM_OF_VALUES).long()
全てのバッチの画像に対して、0~1に正規化されたデータを0~255(白~黒)のデータに戻し、これを正解データとする - loss = criterion(pixel_cnn(x), target)
pixelcnnの出力と正解データの損失を計算 - train_errors.append(loss.item())
計算した、学習時の損失をリストに追加 - optimizer.zero_grad()
勾配情報の初期化 - loss.backward()
誤差逆伝播により勾配を計算 - optimizer.step()
勾配によって重みを更新
以下評価
- with torch.no_grad():
評価時には勾配情報を計算しない - pixel_cnn.eval()
モデルを評価モードに変更 - for x, label in testloader:
評価用データを取得 - target = (x[:,0] * NUM_OF_VALUES).long()
取得したデータを0~255の値に戻す - loss = criterion(pixel_cnn(x), target)
損失を計算 - test_errors.append(loss.item())
損失をリストに追加 - train_losses.append(np.mean(train_errors)), test_losses.append(np.mean(test_errors))
エポックごとの損失をリストに記録
- 画像生成
sample = torch.Tensor(25, 1, X_DIM, X_DIM)
pixel_cnn.eval()
sample.fill_(0)
for i in range(X_DIM):
for j in range(X_DIM):
out = pixel_cnn(sample)
probs = F.softmax(out[:, :, i, j], dim=1)
sample[:, :, i, j] = torch.multinomial(probs, 1).float() / NUM_OF_VALUES
画像の各ピクセルに対してループを実行し、そのピクセルの値を1つずつサンプリングしていきます。
- sample = torch.Tensor(25, 1, X_DIM, X_DIM)
(バッチサイズ(生成画像数), チャネル数, 高さ, 幅)のテンソルを作成。 - pixel_cnn.eval()
cnnを評価モードに変更 - sample.fill_(0)
テンソルを全て0(白)で初期化。この画像をpixelcnnに通し、生成画像を得る
i,jのループを使用して各ピクセルの値を出力
- out = pixel_cnn(sample)
現在のサンプル状態をモデルに入力し、各ピクセル位置における256個の値(確率分布)を出力。pixelcnnは一枚の画像につき256枚の同一形状のチャネルを返すため、形状は(バッチサイズ(25), 256, 高さ, 幅) - probs = F.softmax(out[:, :, i, j], dim=1)
ピクセル位置(i, j)における取りうる色の確率分布を計算します。出力の形状は(バッチサイズ, 値を取る確率)です。 - sample[:, :, i, j] = torch.multinomial(probs, 1).float() / NUM_OF_VALUES
probsの確率分布に従って値を選択する。選択した値のindexを返す。例えばprobs = torch.tensor([0.1, 0.2, 0.3, 0.4])の場合、40%の確率で(index=)3が返される。選ばれた値をNUM_OF_VALUES(255)で割ることで、正規化されたピクセル値(0から1の範囲)に戻す。これがバッチサイズ分だけ行われます。つまりこの一行で、同じprobsによるサンプリングが25回行われ、各バッチの高さi,幅jの位置のピクセルの値が決定されます。
- 可視化
sample_array = sample.cpu().numpy().squeeze()
fig, ax = plt.subplots(nrows=5, ncols=5, figsize=(5, 5))
for i in range(25):
idx = divmod(i, 5)
ax[idx].imshow(sample_array[i]*255, cmap='gray')
ax[idx].axis('off')
fig.show()
得られた25枚の画像(sample)の可視化を行います。
- sample_array = sample.cpu().numpy().squeeze()
得られたデータをcpu環境のnumpy配列に戻し、不要な次元(値が1の次元)を削除。白黒なのでチャネルの次元が落ちて(バッチサイズ(25), 高さ, 幅)の画像データとなる - fig, ax = plt.subplots(nrows=5, ncols=5, figsize=(5, 5))
25枚の画像データ用の場所を定義 - idx = divmod(i, 5)
除算の結果を(整数値, 余り)のタプルで取得。左上から並ぶ座標が手に入る - ax[idx].imshow(sample_array[i]*255, cmap='gray')
画像を定義 - ax[idx].axis('off')
軸を消去 - fig.show()
画像を表示
- 結果

今回は出力に条件を付与できないので、学習したデータ全体から因果関係を学び、確率的に生成を行います。そのため全体的に教師データに類似した画像が生成されます。それらしい出力になっていますね。
精度はまだまだですが、PixelCNNには派生が多くあり、より精度の高いモデルや、生成画像の指定可能なモデルも存在するので、興味がある方は調べてみて下さい。
それでは、今回はここまでになります。長くなってしまいましたが、最後まで読んで頂きありがとうございました。
コード全文
# Please execute in GPU env.
import matplotlib.pyplot as plt
import numpy as np
import torch
import torch.nn.functional as F
from torch import nn, optim
from torch.utils import data
from torchvision import datasets, transforms, utils
class MaskedConv2d(nn.Conv2d):
def __init__(self, mask_type, *args, **kwargs):
super().__init__(*args, **kwargs)
assert mask_type in ['A', 'B']
self.register_buffer('mask', self.weight.data.clone())
h = self.weight.size()[2]
w = self.weight.size()[3]
self.mask.fill_(1)
# マスクタイプによる場合分け
if mask_type == 'A': # 自分自身も見ない
self.mask[:, :, h // 2, w // 2:] = 0
self.mask[:, :, h // 2 + 1:] = 0
else: # 自分自身は見る
self.mask[:, :, h // 2, w // 2 + 1:] = 0
self.mask[:, :, h // 2 + 1:] = 0
def forward(self, x):
self.weight.data *= self.mask
return super().forward(x)
class PixelCNN(nn.Module):
def __init__(self, num_of_channels=32, n_layers=7, output_channels=256):
super().__init__()
self.layers = nn.ModuleList()
# 最初のブロック
self.layers.append(MaskedConv2d(mask_type='A',
in_channels=1,
out_channels=num_of_channels,
kernel_size=7,
stride=1,
padding=3,
bias=False))
self.layers.append(nn.BatchNorm2d(num_of_channels))
self.layers.append(nn.ReLU(inplace=True))
# 後続のブロック
for i in range(1, n_layers+1):
self.layers.append(MaskedConv2d(mask_type='B',
in_channels=num_of_channels,
out_channels=num_of_channels,
kernel_size=7,
stride=1,
padding=3,
bias=False))
self.layers.append(nn.BatchNorm2d(num_of_channels))
self.layers.append(nn.ReLU(inplace=True))
self.layers.append(nn.Conv2d(in_channels=num_of_channels,
out_channels=output_channels,
kernel_size=1))
def forward(self, x):
out = x
for layer in self.layers:
out = layer(out)
return out
trainloader = data.DataLoader(datasets.MNIST('data', train=True,
download=True,
transform=transforms.ToTensor()),
batch_size=128, shuffle=True,
num_workers=1, pin_memory=True)
testloader = data.DataLoader(datasets.MNIST('data', train=False,
download=True,
transform=transforms.ToTensor()),
batch_size=128, shuffle=False,
num_workers=1, pin_memory=True)
num_of_layers = 7 # 畳み込み層の数
num_of_channels = 64 # チャネル数
num_of_epochs = 50 # エポック数
X_DIM = 28
NUM_OF_VALUES = 255
device = 'cuda:0'
pixel_cnn = PixelCNN(num_of_channels, num_of_layers).to(device)
optimizer = optim.Adam(list(pixel_cnn.parameters()))
criterion = nn.CrossEntropyLoss()
train_losses, test_losses = [], []
for epoch in range(num_of_epochs):
# 学習
train_errors = []
pixel_cnn.train()
for x, label in trainloader:
x = x.to(device)
target = (x[:,0] * NUM_OF_VALUES).long()
loss = criterion(pixel_cnn(x), target)
train_errors.append(loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 評価
with torch.no_grad():
test_errors = []
pixel_cnn.eval()
for x, label in testloader:
x = x.to(device)
target = (x[:,0] * NUM_OF_VALUES).long()
loss = criterion(pixel_cnn(x), target)
test_errors.append(loss.item())
print(f'epoch: {epoch}/{num_of_epochs} train error: {np.mean(train_errors):0.3f} \
test error {np.mean(test_errors):0.3f}')
train_losses.append(np.mean(train_errors))
test_losses.append(np.mean(test_errors))
sample = torch.Tensor(25, 1, X_DIM, X_DIM).to(device)
pixel_cnn.eval()
sample.fill_(0)
for i in range(X_DIM):
for j in range(X_DIM):
out = pixel_cnn(sample).to(device)
probs = F.softmax(out[:, :, i, j], dim=1)
sample[:, :, i, j] = torch.multinomial(probs, 1).float() / NUM_OF_VALUES
sample_array = sample.cpu().numpy().squeeze()
fig, ax = plt.subplots(nrows=5, ncols=5, figsize=(5, 5))
for i in range(25):
idx = divmod(i, 5)
ax[idx].imshow(sample_array[i]*255, cmap='gray')
ax[idx].axis('off')
fig.show()
参考
(1) Pixel Recurrent Neural Networks
(2) 【解説+実装】PixelCNNを理解する
Discussion