【ML Basic Method】VIT解説
今回はVIT(Vision Transformer)について解説します。
原論文: An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
1. VIT
1.1 VITとは
VIT(Vision Transformer)は、元々言語処理タスクのために開発されたTransformerを、画像認識タスクに適用する手法です。
Transformerの持つAttentionメカニズムにより、CNNよりも柔軟に入力の特徴を結びつける事ができます。
特にデータ数が多いタスクに有用であり、Kaggleでも利用される事がありますが、その分学習時間やモデルサイズは増加してしまいます。
画像認識関連のSOTAにおいて、上位手法をVITが占有しているものもあり、その注目度はますます上昇しています。
1.2 アーキテクチャ
VITは、主にInputLayer、Encoder、MLPHeadの三つの部品で構成されています。
・VIT
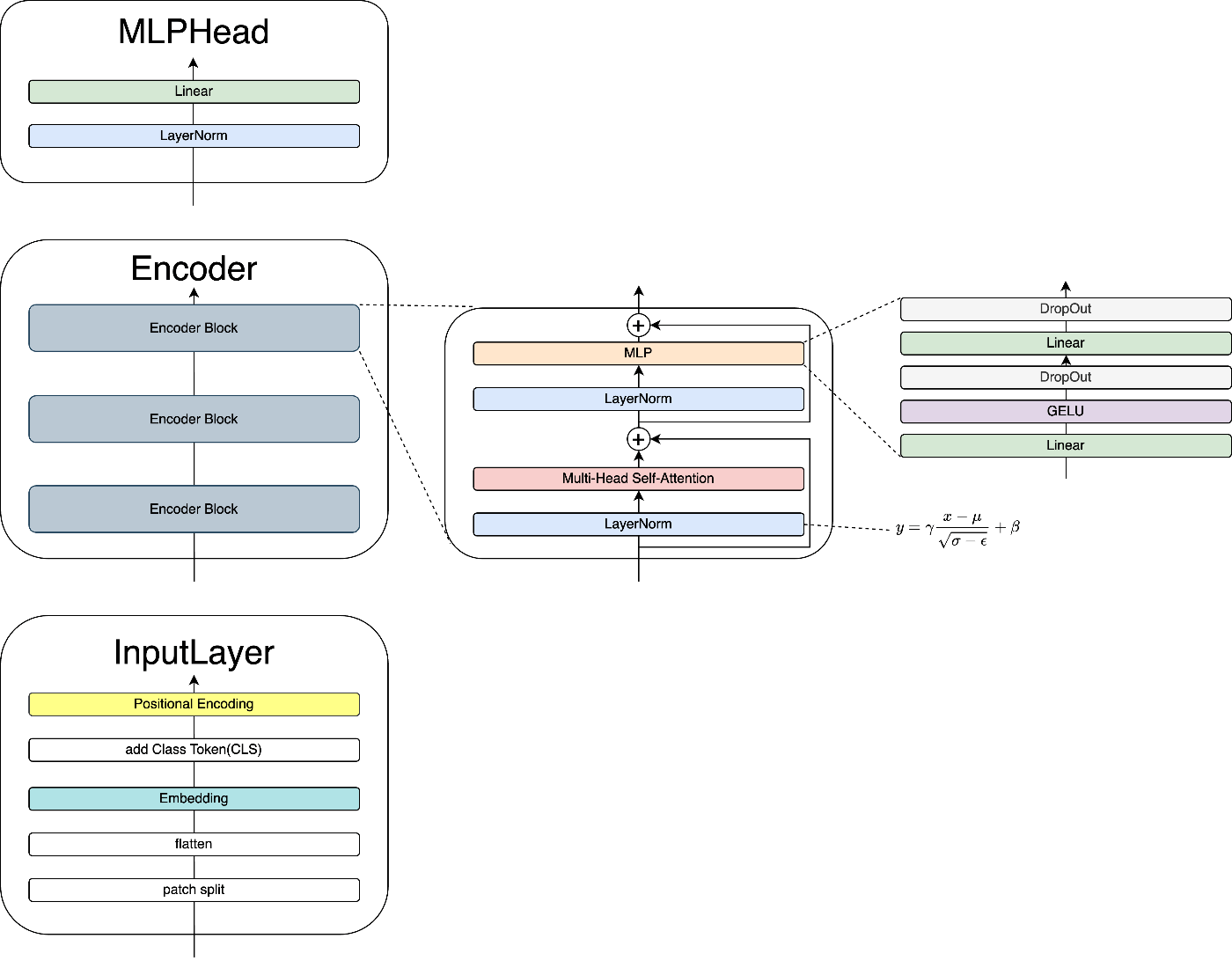
2. InputLayer
この章では、最初に画像を入力するInputLayerについて解説します。
ここでは、画像の埋め込みを行います。画像をトークンに変換し、トークンをベクトルに変換して並べます。
・InputLayer
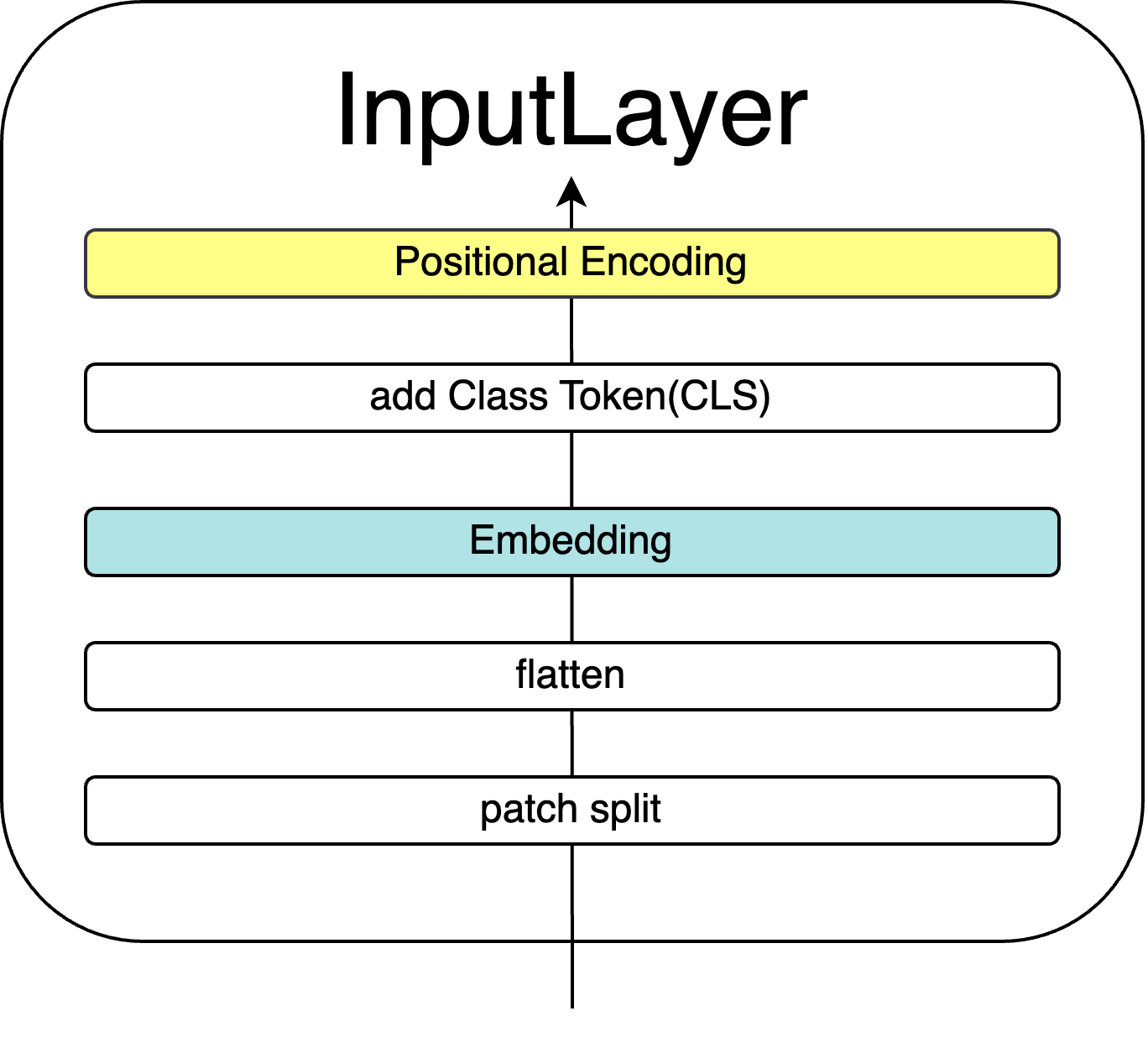
2.1 パッチ分割 (Patch Split)
エンコーダデコーダ系モデルにおける自然言語処理のタスクでは、Embedding(埋め込み)と呼ばれる、入力を単語に分割してトークン化する工程が最初に行われる事が多いです。
VITでは、画像をトークン化するために、画像を均等に分割してそれらをパッチ(トークン)として扱います。
例えば32×32の画像を2×2(=4)個のパッチに分解すると、それぞれ上下左右を切り取った16×16の画像(パッチ)が4つ入手できます。
原論文では、224×224の画像を16×16(=256)個や14×14(196)個のパッチに分解しています。
・2×2パッチ化の例

↓ パッチ化


2.2 flatten
画像をパッチに分割した後、flatten処理でデータを一次元化し、1層の線形層による線形変換を行います。
Transformerは元々一次元の系列データを扱うためのモデルであるため、このflattenでフォーマットを合わせています。
2.3 Embedding
一次元に変換したデータの各要素を、ベクトルに変換します。これにより一次元データ二次元配列になります。
これはword2vecと同じ原理で、トークンが柔軟な意味を持てるようにベクトルに変換します。
2.4 クラストークン(CLS)
次に、上記処理によって埋め込みを終えたデータの先頭に、クラストークンを結合します。
クラストークンはSelf Attentionによって得られる、画像全体のデータの関係性を捉えたベクトルです。
その長さはEmbedding後の各ベクトル長と同じで、ベクトルの全データは学習可能なパラメータになっています。
一次元ベクトルの先頭にクラストークンが追加されて、入力のデータ長が「ベクトル長」分だけ増加するイメージです。
2.5 位置埋め込み(Positional Encoding)
最後に、これまでのデータに位置埋め込みを行います。
これは、各トークンに自分の位置を知らせる情報を追加することを意味します。
例えば、画像の左上に飛行機がある場合と、右下に飛行機がある場合では、画像の意味が異なると考えられます。
得られたトークンが同じでも、その位置によって画像の意味は変化します。この変化をとられるための情報が位置埋め込みによって追加されるのです。
以上でInputLayerは終了です。
3. Encoder
Encoderの前に、前知識としてVITにおけるSelf Attentionについて以下で軽く解説しています。
VITにおけるSelf Attention
0. Self Attention
VITにおけるSelf Attentionは、通常のTransformerのSelf Attentionと同じ役割を果たします。つまり、一次元化された画像トークンを並べた二次元配列をQKVとして扱い、似ている部分の情報に重みをつけたデータを抽出して、次の層に渡します。
-
Attention
出力(output) =softmax(\dfrac{QK^T}{\sqrt{d_k}})V -
Q: query(入力)
-
K: key(入力)
-
V: value(入力)
-
d_k -
softmax: 正規化関数
※Self Attentionの詳細はこちらで解説しています。
0.1 Multi-Head Self-Attention
VITもTransformer同様にMulti-Head Self-Attention(MHSA)を持ちます。
これはSelf Attentionを並列に接続したものです。
特にVITではMHSAのヘッド数に応じてQKVが分割され、それぞれの分割したデータに対してSelf Atentionを行い、その結果を結合します。
Encoderは、主に計算処理を行う部分です。複数のEncoder Blockの積み重ねで構成されています。
全体像は次のようになっています。
・Encoder
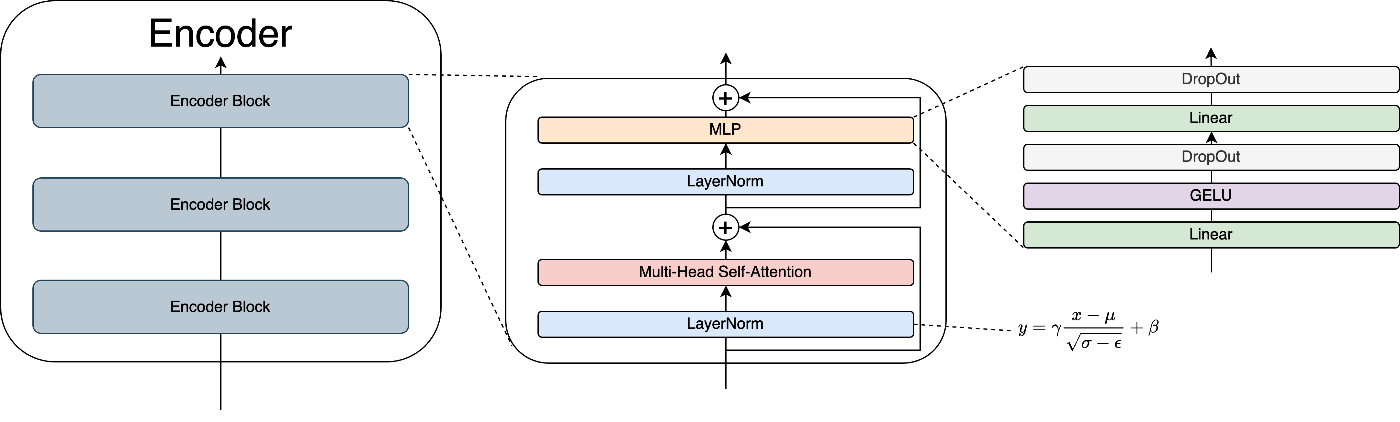
ではEncoder Blockの中身について見ていきましょう。
3.1 Encoder Block
Encoder Blockは次のようなアーキテクチャです。
・Encoder Block
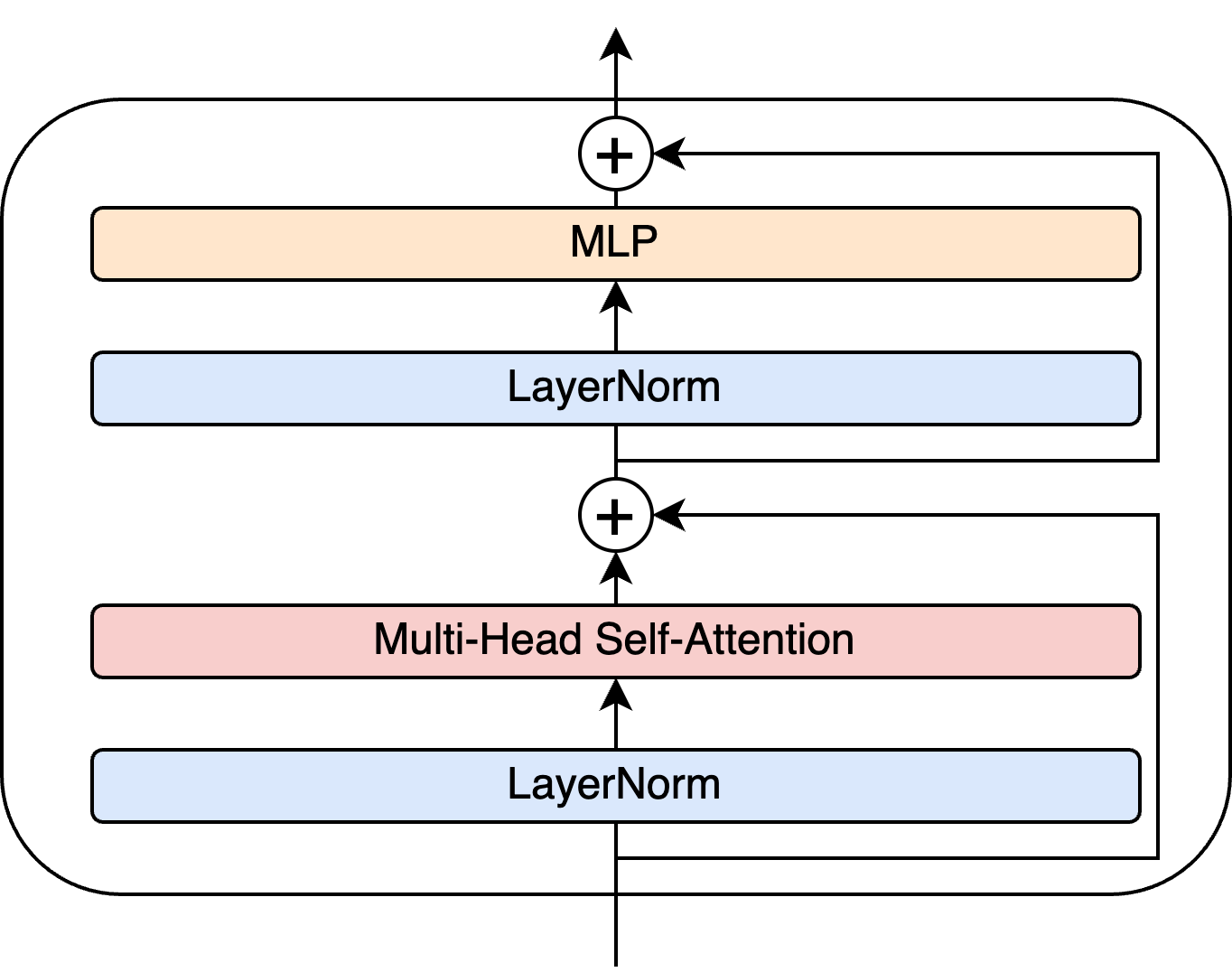
MHSAとMLPのSkip Connectionと、それらの前にLayerNorm層が入力されたもので、これがVITの本体といえるでしょう。
これを積み重ねることで、複数のAttentionによる特徴の抽出が繰り返し行われ最適化され、必要な情報がMLPに渡るようになります。
次はEncoder Blockの構成要素について解説します。
3.1.1 LayerNorm
最初はLayerNormalizationです。
よく利用される正規化にBtachNormalizationがありますが、この手法はバッチ全体を正規化するため、データごとにトークン数が異なるデータ(一文の単語数など)には適切ではありませんでした。
これを解決するために提案された正規化手法がLayerNormalizationです。
この正規化は入力
- 平均と分散
\mu = \dfrac{1}{N}\sum\limits^N_{i=1}x_i
\sigma^2 = \dfrac{1}{N}\sum\limits^N_{i=1}(x_i-\mu)^2 - 正規化後の
x_i(=\hat{x}_i)
各特徴x_i \mu \sigma
\hat{x}_i = \dfrac{x_i - \mu}{\sqrt{\sigma^2 + \epsilon}} - LayerNromの出力
y_i
LayerNromの出力y_i \hat{x}_i \gamma \beta
y_i = \gamma \hat{x}_i \beta
= \gamma \dfrac{x - \mu}{\sqrt{\sigma - \epsilon}} + \beta
LayerNormでは入力系列データ以外を考慮しないため、入力データ長にばらつきがあっても対応できます。VITでは系列長が揃っていることが一般的だと思いますが、元々のTransformerの名残なのかLayerNromを使用しています。
またBatchNormやLayerNromなどの正規化は、手法は異なれど目的は同じで、モデル内部の分布が学習時と訓練時で異なること(内部の共変量シフト)に起因する精度の低下を防ぐことです。
3.3 MLP
次にMLP(多層パーセプトロン)を解説します。
VITのMLPは以下のようなアーキテクチャを持ちます。
・MLP
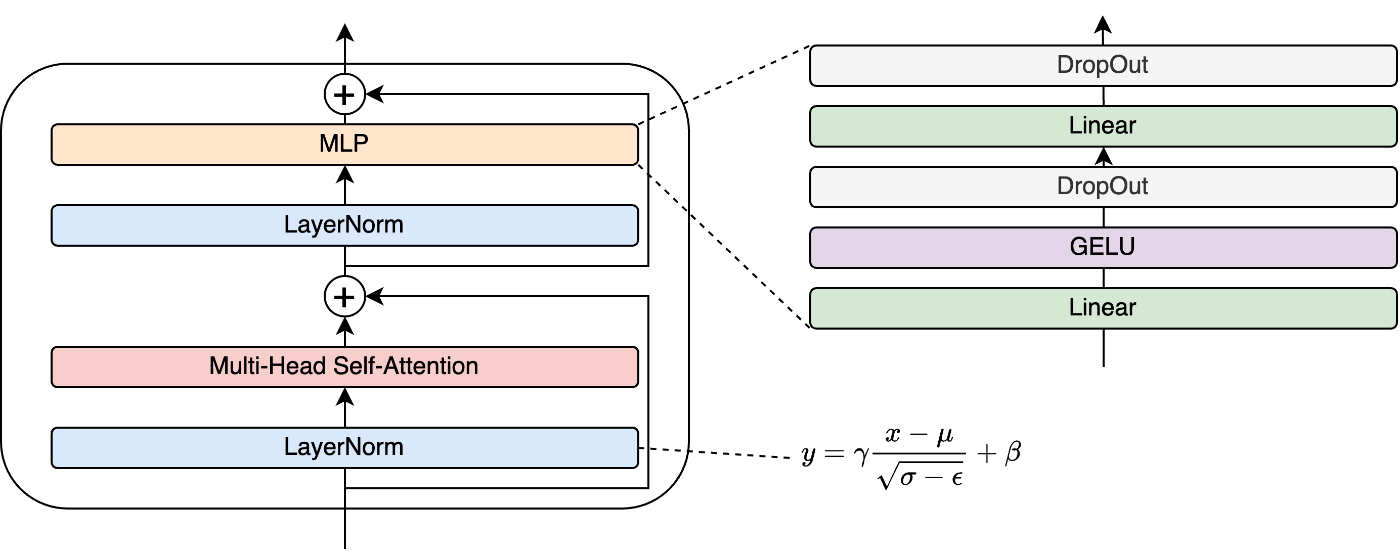
- Liner
線形結合層。出力は重み付き線形和の配列 - GELU
Transformer系統モデルでよく利用される活性化関数。負の値でも完全に0にならないためReLUより情報の損失が少ないと言われている

- DropOut
一部のニューロンを無視する層
VITのMLPは、線型結合を利用した、二層のニューラルネットワークです。
改めて、Encoder Blockは
・MHSA
・LayerNorm
・MLP
によってEncoder Blockは構成されています。
Encoder Blockの機能としては、埋め込みによってベクトル化された画像の関連性を学習し、類似した情報をMLPに渡すことで、入力の特徴がよりよく表現された空間に転写しています。
この転写されたベクトルが次のMLPHeadに渡されるのです。
3. まとめ
上記のEncoder Blockを積み重ねたものが、VITのEncoder部分になります。積み重ねることで、より深く柔軟に画像の要素同士の関係性を学習する事ができます。
最後にアーキテクチャをもう一度示します。
・Encoder
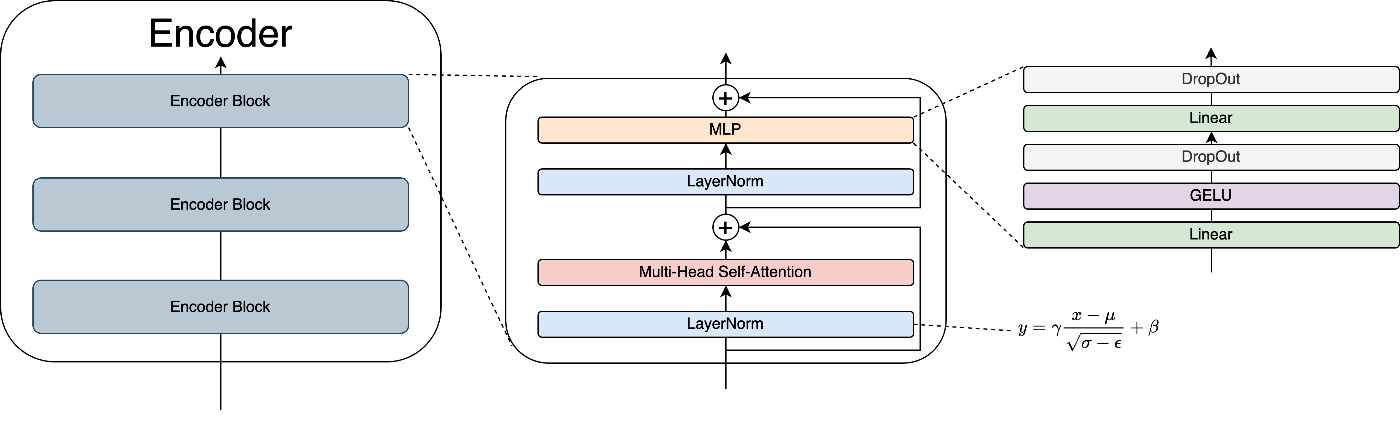
4. MLPHead
MLPHeadはクラス分類を行う分類機です。
アーキテクチャは以下のようになっています。
・MLPHead

単MLPHeadは、単純なLinearとLayerNormによる一層の線型結合層です。
- Liner
線形結合層。出力は重み付き線形和の配列 - LayerNorm
前回解説しています。
主な役割は、Encoderで得られたベクトル空間を特定のクラス数に整える事です。
MLPHeadには活性化関数が含まれていないため、主としての学習の部分はEncoder部分が担っている事が分かります。
5. まとめ
以上でVITの各部品についての解説は終了です。
では、改めてVITの概要を確認しましょう。
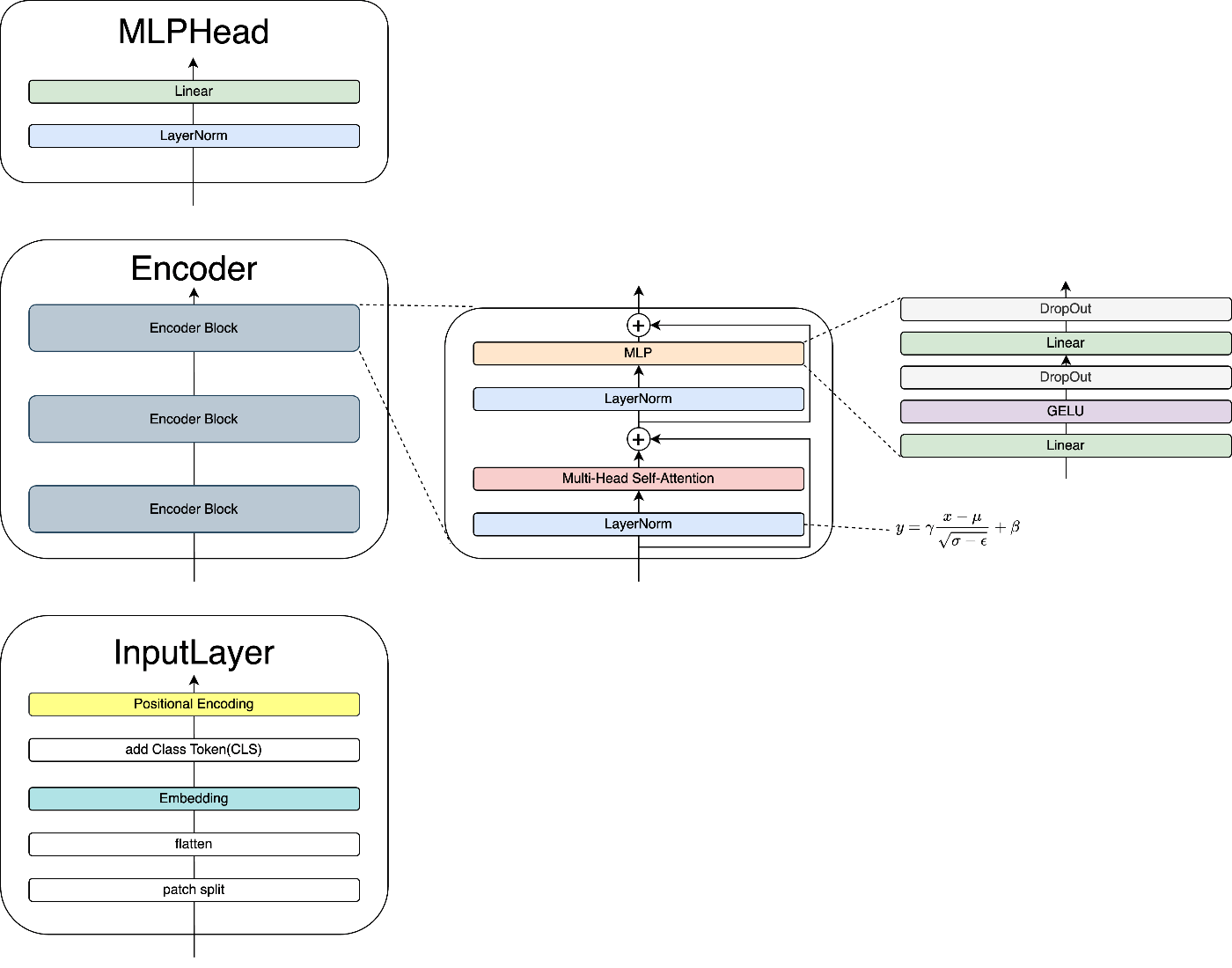
5.1 InputLayer
InputLayerは以下の流れで処理を行います。
- 画像をパッチに分割 (patch split)
- 一次元化 (flatten)
- ベクトル化 (Embedding)
- クラストークン追加 (add Class Token)
- 位置埋め込み (Positional Encoding)
この処理によって画像は機械が扱えるような、意味のある二次元配列に変換されます。
5.2 Encoder
Encoderは以下の流れで処理を行います。
※Encoder Blockの処理
- 入力をLayerで正規化 (LayerNorm)
- MHSAで、各トークンと周囲トークンの類似度を特徴量として複数空間で取得 (MHSA)
- Skip Conecctionで線形変換の要素を追加 (+)
- Layerで正規化 (LayerNorm)
- 線形変換とGELUで必要な特徴量の取捨選択 (MLP)
- DropOutで過学習抑制 (MLP)
Encoderは、これを積み重ねてより深い特徴を学習します。
5.3 MLPHead
MLPHeadは以下の流れで処理を行います。
- 入力をLayerで正規化 (LayerNorm)
- 線形結合層で出力の数を分類先クラス数に合わせる (Linear)
5.4 概略
おおまかに
InputLayerで学習可能な形に変換、
Encoderで特定の画像トークンと周囲の画像トークンの類似度を学習、
MLPHeadで出力形状を整えます。
VITで注目すべきはAttention機構による特徴の抽出と、Multi-Headによる特徴空間の多様化です。これによってVITは柔軟な表現力を獲得する事ができています。
VITの解説は以上になります。
最後まで読んでいただきありがとうございました。
参考
(1)原論文 An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
(2)Vision Transformer 入門 株式会社技術評論社 2022/9/30 山本晋太郎,徳永匡臣,箕浦大晃,QIU YUE,品川政太郎
Discussion