Scaled Dot-Product Attentionとは (Transformerその1)
今回はTransformerに使用されている、Scaled Dot-Product Attentionについて解説します。
この記事を参考にして書いているため、先にこちらを見ることをお勧めします。
また、ある程度モデルについて知識のある方を対象にしています。
Transformer
初めに、Transformerのアーキテクチャは次のようになっています。

そしてこの中のMulti-head Attentionのアーキテクチャは次のようになっています。

今回はさらにこの中のScaled Dot-Product Attentionについて解説していきます。
Scaled Dot-Product Attention
Scaled Dot-Product Attentionのアーキテクチャは次のようになっています。
- Scaled Dot-Product Attention

数式
Scaled Dot-Product Attentionは、基本的に次の数式で表されます。これは、上の図の操作を数式で表現したものです。
出力(output) =
- Q: query(入力)
- K: key(入力)
- V: value(入力)
-
d_k - softmax: 正規化関数
初めに、この数式を理解するところから始めます。
Matmul(QK^T
- 行列
Q K^T
MatMulレイヤでは行列積演算を行なっています。ここでは、
次の図を見て下さい。

のような、「
そして、これが(ベクトルでなく)
イメージとしては、
のように、
つまり、
Scaled
- 正規化
\dfrac{QK^T}{\sqrt{d_k}}
Scaledレイヤでは、正規化を行なっています。
ですが、行列積はベクトルの次元数が多いほど、(当然ですが)出力結果が大きくなる特性を持ちます。これによって類似度計算後のsoftmaxの出力が極端(1要素以外ほぼ0)になってしまったり、勾配情報が消失するといった問題が発生します。
そこで、
Mask(opt.)
- マスク(オプション)
Maskではマスクをおこなっています。
これは主に出力生成時の推測(prediction)および訓練(train)時に行われる操作で、一般的には下三角行列と内積を取ることで未来の情報を利用できなくします。
- 下三角行列(要素を全て1としている)
[[1, 0, 0, 0, 0],
[1, 1, 0, 0, 0],
[1, 1, 1, 0, 0],
[1, 1, 1, 1, 0],
[1, 1, 1, 1, 1]]
例えば、[i have a pen .] という時系列データがあった場合、[i]の次の単語を予測するタスクでは、[have a pen .]という情報は答えにあたるため、提供されてはいけないはずです。
そこで、予測時には下三角行列を使用して次のような行列を入力とします。
[['i', '0', '0', '0', '0'],
['i', 'have', '0', '0', '0'],
['i', 'have', 'a', '0', '0'],
['i', 'have', 'a', 'pen', '0'],
['i', 'have', 'a', 'pen', '.']]
これを上から順に入力することで、未来の情報を知ることなく、適切に予測を行えるようになります。
また、異なる長さのデータについて、長さを揃えるためにマスクを使用したり、訓練時にも未来の情報を使用して推論を行うモデルになることを避けるためにマスクを行うことがあります。
softmax
- 正規化
softmaxレイヤでは、正規化を行なっています。
上記で求めた
- softmax
↓softmax(正規化)
Matmul(softmax(\dfrac{QK^T}{\sqrt{d_k}})V
- 行列積
これまでに作ってきた
ここでも初めはベクトルで考えましょう。
例えば
とすると、これは
(分からない人は最初のMatMulの説明を確認してみて下さい)
これと
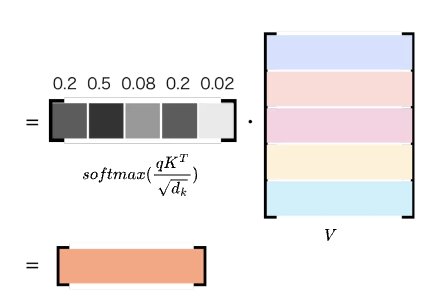
図を見ると、
これはつまり、
これがScaled Dot-Product Attentionの最終出力です。(本来は
具体例
具体的に翻訳タスクで考えます。
Transformerではself-Attentionが使用されるため、
初めに
そして、例えば
その重みを使用して、関連度の高い情報を
擬似コードでも流れを確認して見ましょう。(本来はembeddingによって単語はベクトル化されていますが、視認性向上のためそのまま記述しています)
# 擬似コード
Q = [[I,
am,
fine,
.,
And,
you]
q = [I]
K = [[I, am, fine, ., And, you]]
V = [[I,
am,
fine,
.,
And,
you]
# 類似度を計算
weight = q・K # =[0.7, 0.11 , 0.03, 0.03, 0.03, 0.1]
# Vから、[I]に似た情報を抜き出す
output = weight・V # I, am, youの単語ベクトルの情報を多く含む
結論
Scaled Dot-Product Attentionは、スケーリングや行列積を利用して、
これによって、時系列データ同士の関連度を取得したり、予測する際に関連度の高い情報を利用できるようになります。
また、
Tarnsformerは6年前に発表された技術ですが、最近のモデルもTransformerを利用しているものが多く、現在でもとても重要な技術です。
それでは、今回は以上です。最後まで読んでいただきありがとうございました。
参考
[1]https://arxiv.org/pdf/1706.03762.pdf
[2]https://developers.agirobots.com/jp/multi-head-attention/
Discussion