kaggle HMSコンペ WaveNet Starter - [LB 0.52] 解説


0. 概要
WaveNetを使用した脳波分類タスクのソリューション
0.1 コンペ説明
患者の脳波が示す活動の種類を分類する。専門家の評価を正解として予測を行うコンペ
このコンペでは、生の脳波波形(eeg)とスペクトログラム(spectrogram)の両方が提供されており、スペクトログラムは10分、脳波波形は50秒です、またこれらのデータの中央の50秒は同じデータであり、この期間は同じデータを二つの表現方法で提示しています。
eeg: 一般に想像する波形データ(株価など)
spectrogram: 一般的にスペクトログラムとは、電極から得られた電気信号に対して、短い時間窓で区切ったうえで短時間フーリエ変換(STFT: Short-Time Fourier Transform)を適用して得られる三次元(時間、周波数、パワースペクトル密度)の情報を持ったデータのことである。つまり、datasetのspectrogramファイルはすべてeegデータのフーリエ変換後の情報である。下図の色で囲まれた枠内の電極からのデータで、計4つのスペクトログラム(LL、LP、RP、RR)の作成ができる。

より詳しく知りたい方は、コンペの概要と以下のデータ説明を読むと分かりやすいと思います。
1. WaveNetとは
因果関係を持った一次元の畳み込みを使用した深層モデルで、一次元波データ(信号)の生成や分類に使用されます。
以前に解説していますのでご覧ください。
2. Notebook解説
2.0 概要
4種のスペクトログラムデータをWaveNetを使用した4層のWaveBlockに入力し、プーリング層を通した後結合します。最終的に全て全結合してsoftmaxで確率に変換しています。
直接的に脳波を使用するのではなく、脳波を利用して4つの系列のデータを作成し、それを学習させます。
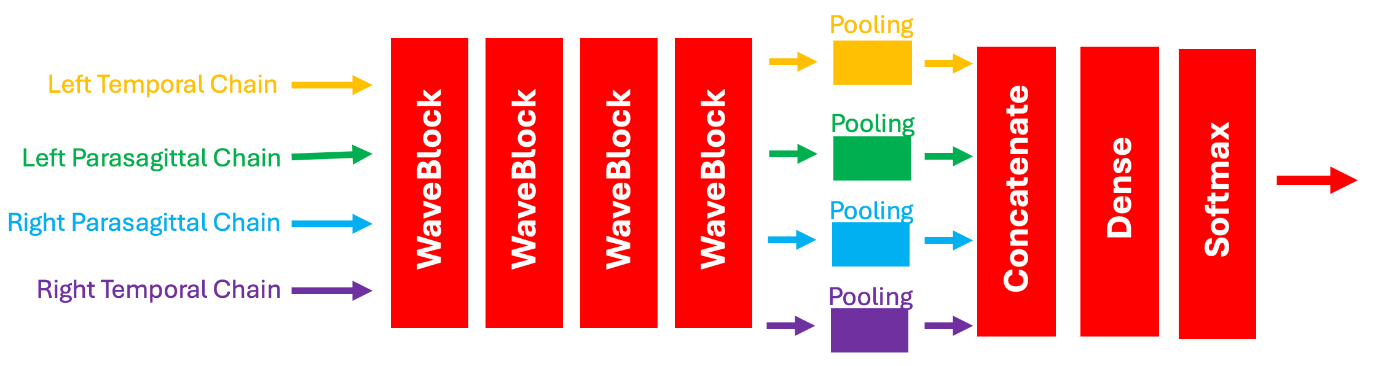
本Notebookはversion8です。
2.1 データ取得/前処理
・ライブラリのインポートとデータ取得
下2行でeegデータを作成するか、version1から取得するか決定します。
import pandas as pd, numpy as np, os
import matplotlib.pyplot as plt
train = pd.read_csv('/kaggle/input/hms-harmful-brain-activity-classification/train.csv')
print( train.shape )
display( train.head() )
# CHOICE TO CREATE OR LOAD EEGS FROM NOTEBOOK VERSION 1
CREATE_EEGS = False
TRAIN_MODEL = False
# output
# (106800, 15)
# eeg_id eeg_sub_id eeg_label_offset_seconds spectrogram_id spectrogram_sub_id spectrogram_label_offset_seconds label_id patient_id expert_consensus seizure_vote lpd_vote gpd_vote lrda_vote grda_vote other_vote
# 0 1628180742 0 0.0 353733 0 0.0 127492639 42516 Seizure 3 0 0 0 0 0
# 1 1628180742 1 6.0 353733 1 6.0 3887563113 42516 Seizure 3 0 0 0 0 0
# 2 1628180742 2 8.0 353733 2 8.0 1142670488 42516 Seizure 3 0 0 0 0 0
# 3 1628180742 3 18.0 353733 3 18.0 2718991173 42516 Seizure 3 0 0 0 0 0
# 4 1628180742 4 24.0 353733 4 24.0 3080632009 42516 Seizure 3 0 0 0 0 0
・生のEEGデータを取得します。
df = pd.read_parquet('/kaggle/input/hms-harmful-brain-activity-classification/train_eegs/1000913311.parquet')
FEATS = df.columns
print(f'There are {len(FEATS)} raw eeg features')
print( list(FEATS) )
# output
# There are 20 raw eeg features
# ['Fp1', 'F3', 'C3', 'P3', 'F7', 'T3', 'T5', 'O1', 'Fz', 'Cz', 'Pz', 'Fp2', 'F4', 'C4', 'P4', 'F8', 'T4', 'T6', 'O2', 'EKG']
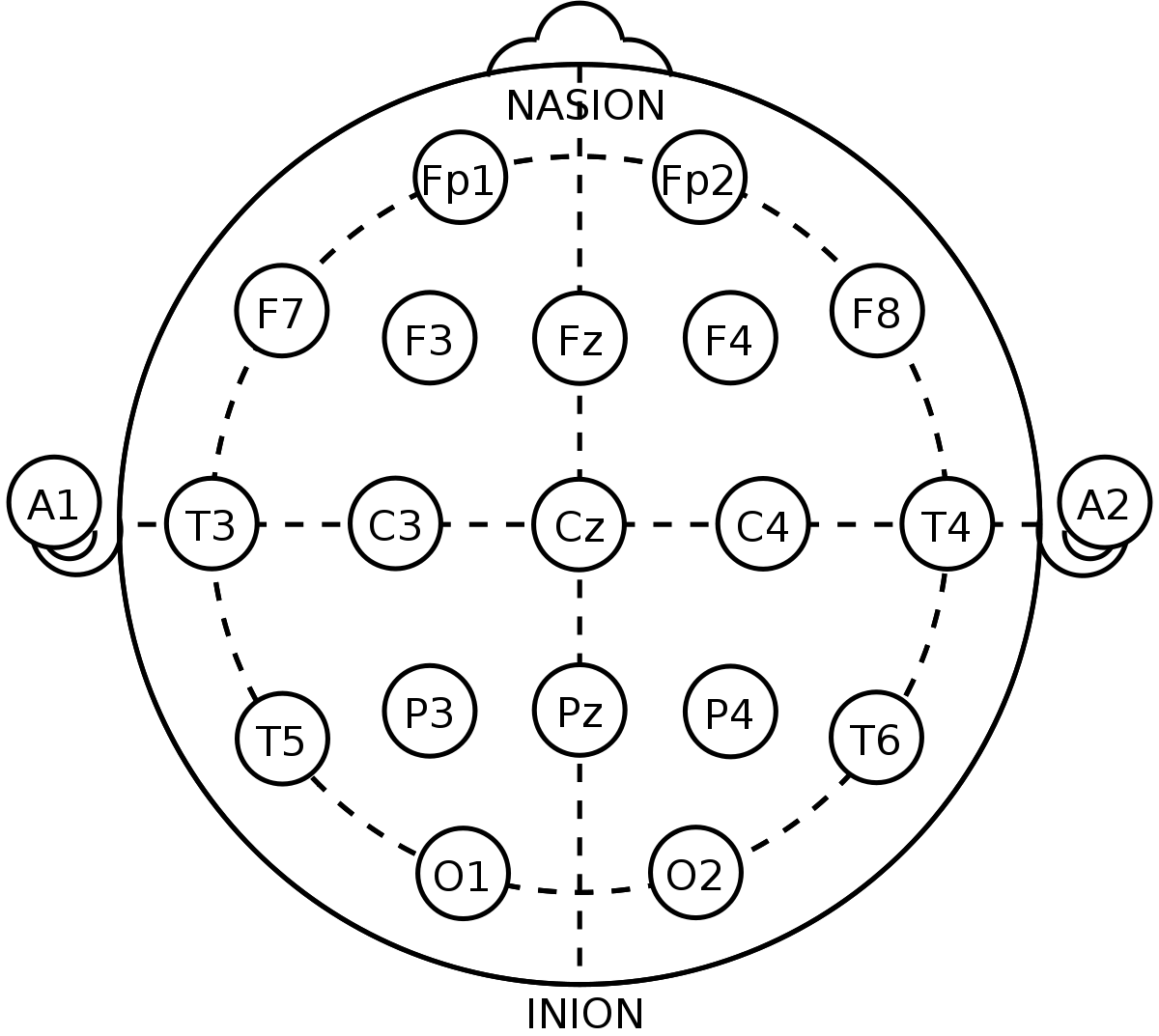
eegデータと、列名を取得しています。
ここで取得できた列名データは、それぞれ頭の各所に取り付けられた電極から得た波形です。
※A1とA2は除きます。EKGは心臓から取得した波形データです。
・この中から一部のeegデータのみを使用します。
print('We will use the following subset of raw EEG features:')
FEATS = ['Fp1','T3','C3','O1','Fp2','C4','T4','O2']
FEAT2IDX = {x:y for x,y in zip(FEATS,range(len(FEATS)))}
print( list(FEATS) )
# output
# We will use the following subset of raw EEG features:
# ['Fp1', 'T3', 'C3', 'O1', 'Fp2', 'C4', 'T4', 'O2']
・parquet形式のデータをeegデータに変換する関数を定義
def eeg_from_parquet(parquet_path, display=False):
# EXTRACT MIDDLE 50 SECONDS
eeg = pd.read_parquet(parquet_path, columns=FEATS)
rows = len(eeg)
offset = (rows-10_000)//2
eeg = eeg.iloc[offset:offset+10_000]
if display:
plt.figure(figsize=(10,5))
offset = 0
# CONVERT TO NUMPY
data = np.zeros((10_000,len(FEATS)))
for j,col in enumerate(FEATS):
# FILL NAN
x = eeg[col].values.astype('float32')
m = np.nanmean(x)
if np.isnan(x).mean()<1: x = np.nan_to_num(x,nan=m)
else: x[:] = 0
data[:,j] = x
if display:
if j!=0: offset += x.max()
plt.plot(range(10_000),x-offset,label=col)
offset -= x.min()
if display:
plt.legend()
name = parquet_path.split('/')[-1]
name = name.split('.')[0]
plt.title(f'EEG {name}',size=16)
plt.show()
return data
- def eeg_from_parquet(parquet_path, display=False):
parquetファイルのパスを取得 - eeg = pd.read_parquet(parquet_path, columns=FEATS)
列名を指定してpd.DataFrameで読み出す - rows = len(eeg)
行数を取得 - offset = (rows-10_000)//2
10000行を除いた残りの行数を取得し、1/2倍 - eeg = eeg.iloc[offset:offset+10_000]
DataFrameの中央10000行を取得 - if display: \ plt.figure(figsize=(10,5)) \ offset = 0
図の大きさを定義 - data = np.zeros((10_000,len(FEATS)))
DataFrameと同じ形状のndarrayを作成 - for j,col in enumerate(FEATS):
列数だけ繰り返し - x = eeg[col].values.astype('float32')
指定の列をnumpy配列に変換し、float32に変更 - m = np.nanmean(x)
欠損値を無視して配列xの平均値を計算 - if np.isnan(x).mean()<1: x = np.nan_to_num(x,nan=m)
np.isnan(x).mean(): 配列xが全てNaNの時に1を返す。1つでも有効な値がある場合はif文がTrueになる。この時、配列xの欠損値を値mに変更 - else: x[:] = 0
全てのデータがNaNの時、配列xを0で初期化 - data[:,j] = x
配列xをdataのj番目の列に割り当て - if j!=0: offset += x.max()
初回を除いて、offsetに配列xの一番大きい値を追加 - plt.plot(range(10_000),x-offset,label=col)
配列xの値をy軸にしてグラフを描画。列名を名前に設定 - offset -= x.min()
offsetからxの最小値を引く(マイナスの最大値を足す) - plt.legend()
凡例を表示 - name = parquet_path.split('/')[-1] \ name = name.split('.')[0] \ plt.title(f'EEG {name}',size=16)
ファイルパスからファイル名を抜き出し、拡張子を除いてグラフタイトルに設定 - return data
(データ、列名)のnumpy配列を返す
・paequetファイルをnumpy配列に変換、保存
%%time
all_eegs = {}
DISPLAY = 4
EEG_IDS = train.eeg_id.unique()
PATH = '/kaggle/input/hms-harmful-brain-activity-classification/train_eegs/'
for i,eeg_id in enumerate(EEG_IDS):
if (i%100==0)&(i!=0): print(i,', ',end='')
# SAVE EEG TO PYTHON DICTIONARY OF NUMPY ARRAYS
data = eeg_from_parquet(f'{PATH}{eeg_id}.parquet', display=i<DISPLAY)
all_eegs[eeg_id] = data
if i==DISPLAY:
if CREATE_EEGS:
print(f'Processing {train.eeg_id.nunique()} eeg parquets... ',end='')
else:
print(f'Reading {len(EEG_IDS)} eeg NumPys from disk.')
break
if CREATE_EEGS:
np.save('eegs',all_eegs)
else:
all_eegs = np.load('/kaggle/input/brain-eegs/eegs.npy',allow_pickle=True).item()
- all_eegs = {}
読み出したnumpy配列を保存するための辞書を定義 - DISPLAY = 4
表示グラフ数 - EEG_IDS = train.eeg_id.unique()
trainのeed_id列(Series)から一意のeeg_idを取得(numpy array)。 - PATH = '/kaggle/input/hms-harmful-brain-activity-classification/train_eegs/'
parquetファイルの保存ディレクトリ - if (i%100==0)&(i!=0): print(i,', ',end='')
100ファイルごとに進捗を表示 - data = eeg_from_parquet(f'{PATH}{eeg_id}.parquet', display=i<DISPLAY) \ all_eegs[eeg_id] = data
parquetファイルを(データ、列名)のnumpy配列で取得。eeg_idをkeyとして辞書に格納 - if i==DISPLAY: ...
グラフの出力が終わった後一度だけ、処理するファイル数を出力 - if CREATE_EEGS: \ np.save('eegs',all_eegs) \ else: \ all_eegs = np.load('/kaggle/input/brain-eegs/eegs.npy',allow_pickle=True).item()
{eeg_id:numpy array}とする辞書をnpy形式で保存、もしくは取得
出力例
・
# LOAD TRAIN
df = pd.read_csv('/kaggle/input/hms-harmful-brain-activity-classification/train.csv')
TARGETS = df.columns[-6:]
TARS = {'Seizure':0, 'LPD':1, 'GPD':2, 'LRDA':3, 'GRDA':4, 'Other':5}
TARS2 = {x:y for y,x in TARS.items()}
train = df.groupby('eeg_id')[['patient_id']].agg('first')
tmp = df.groupby('eeg_id')[TARGETS].agg('sum')
for t in TARGETS:
train[t] = tmp[t].values
y_data = train[TARGETS].values
y_data = y_data / y_data.sum(axis=1,keepdims=True)
train[TARGETS] = y_data
tmp = df.groupby('eeg_id')[['expert_consensus']].agg('first')
train['target'] = tmp
train = train.reset_index()
train = train.loc[train.eeg_id.isin(EEG_IDS)]
print('Train Data with unique eeg_id shape:', train.shape )
train.head()
- df = pd.read_csv('/kaggle/input/hms-harmful-brain-activity-classification/train.csv')
"df"としてtrainデータを読み込む - TARGETS = df.columns[-6:]
予測ターゲットを取得 - TARS = {'Seizure':0, 'LPD':1, 'GPD':2, 'LRDA':3, 'GRDA':4, 'Other':5}
予測ターゲット辞書を定義 - TARS2 = {x:y for y,x in TARS.items()}
逆引き辞書を定義 - train = df.groupby('eeg_id')[['patient_id']].agg('first')
一意のeeg_idを基準としてpatientidの最初の値を取得 - tmp = df.groupby('eeg_id')[TARGETS].agg('sum')
特定のeeg_idに対する専門家の投票結果を総計して取得 - for t in TARGETS: \ train[t] = tmp[t].values
trainに"病名_vote"の各列を定義し、値としてeeg_idに対する専門家の投票の総計を取得 - y_data = train[TARGETS].values
専門家の同eeg_id内の各波形に対する投票の総計をy_dataとして取得 - y_data = y_data / y_data.sum(axis=1,keepdims=True)
合計で割って投票割合を取得 - train[TARGETS] = y_data
trainデータも投票割合に変更 - tmp = df.groupby('eeg_id')[['expert_consensus']].agg('first') \ train['target'] = tmp
trainの'target'列に専門家の - train = train.reset_index()
インデックスを初期化 - train = train.loc[train.eeg_id.isin(EEG_IDS)]
EEG_IDSに含まれる行のみ取得。※.eed_idでSeriesを取得し、isin(x)でSeriesの各行の値がxに含まれる場合はTrue、そうでない時はFalseのSeries配列を取得
2.2 ローパスフィルター
・Butterローパスフィルターの定義
from scipy.signal import butter, lfilter
def butter_lowpass_filter(data, cutoff_freq=20, sampling_rate=200, order=4):
nyquist = 0.5 * sampling_rate
normal_cutoff = cutoff_freq / nyquist
b, a = butter(order, normal_cutoff, btype='low', analog=False)
filtered_data = lfilter(b, a, data, axis=0)
return filtered_data
- def butter_lowpass_filter(data, cutoff_freq=20, sampling_rate=200, order=4):
ローパスフィルタ関数の定義- 引数
data: フィルタリングされる信号。1次元または多次元のNumPy配列
cutoff_freq: ローパスフィルターのカットオフ周波数(Hz)。この周波数より高い周波数の信号が減衰される
sampling_rate: 信号のサンプリングレート(Hz)。信号がどのくらいの頻度でサンプリングされたかを提示
order: フィルターの次数。この値が大きいほど、カットオフ周波数近辺で急激に減衰するが、フィルターの設計が複雑になり、計算コストが高くなる。
- 引数
- nyquist = 0.5 * sampling_rate
ナイキスト周波数の計算。サンプリング周波数の半分で、この値が信号に含まれる周波数の最大値。逆に計測対象の信号がナイキスト周波数を超えた場合、異なる周波数で同じ波形が現れることがあるためサンプリング周期が不適切とわかる - normal_cutoff = cutoff_freq / nyquist
カットオフ周波数をナイキスト周波数で割ることで正規化する。正規化により、カットオフ周波数は0から1の範囲の値(0は0Hz、1はナイキスト周波数)で表され、butter関数はこれを受け取ることで、任意のサンプリングレートに対して容易に適用できるように設計されている。 - b, a = butter(order, normal_cutoff, btype='low', analog=False)
butter関数を使用してフィルター係数を計算する。この関数は、指定された次数と正規化されたカットオフ周波数に基づいて、Butterworthローパスフィルターの分子(b)と分母(a)の係数を返す。- 引数
btype='low': ローパスフィルター
analog=False: デジタルフィルターの設計を指示
- 引数
- filtered_data = lfilter(b, a, data, axis=0)
lfilter関数を使用して、計算されたフィルター係数(bとa)をデータに適用し、フィルタリングされた信号を生成する。axis=0パラメータでフィルタリングを適用する軸を指定。これにより入力データが多次元配列の場合にも対応できる。
・カットオフ周波数の異なるローパスフィルターの可視化
FREQS = [1,2,4,8,16][::-1]
x = [all_eegs[EEG_IDS[0]][:,0]]
for k in FREQS:
x.append( butter_lowpass_filter(x[0], cutoff_freq=k) )
plt.figure(figsize=(20,20))
plt.plot(range(10_000),x[0], label='without filter')
for k in range(1,len(x)):
plt.plot(range(10_000),x[k]-k*(x[0].max()-x[0].min()), label=f'with filter {FREQS[k-1]}Hz')
plt.legend()
plt.title('Butter Low-Pass Filter Examples',size=18)
plt.show()
- FREQS = [1,2,4,8,16][::-1]
カットオフ周波数のリスト(反転される) - x = [all_eegs[EEG_IDS[0]][:,0]]
辞書all_eegsから最初のeeg_idのデータの最初の列を抜き出す(二重リスト)。1つの電極から得た系列データ。 - x.append(butter_lowpass_filter(x[0], cutoff_freq=k))
x[0]にローパスフィルタを通した結果をxに格納。[[元データ], [ローパス1データ], ...] - plt ...
ローパスフィルタを通した結果を図示
出力
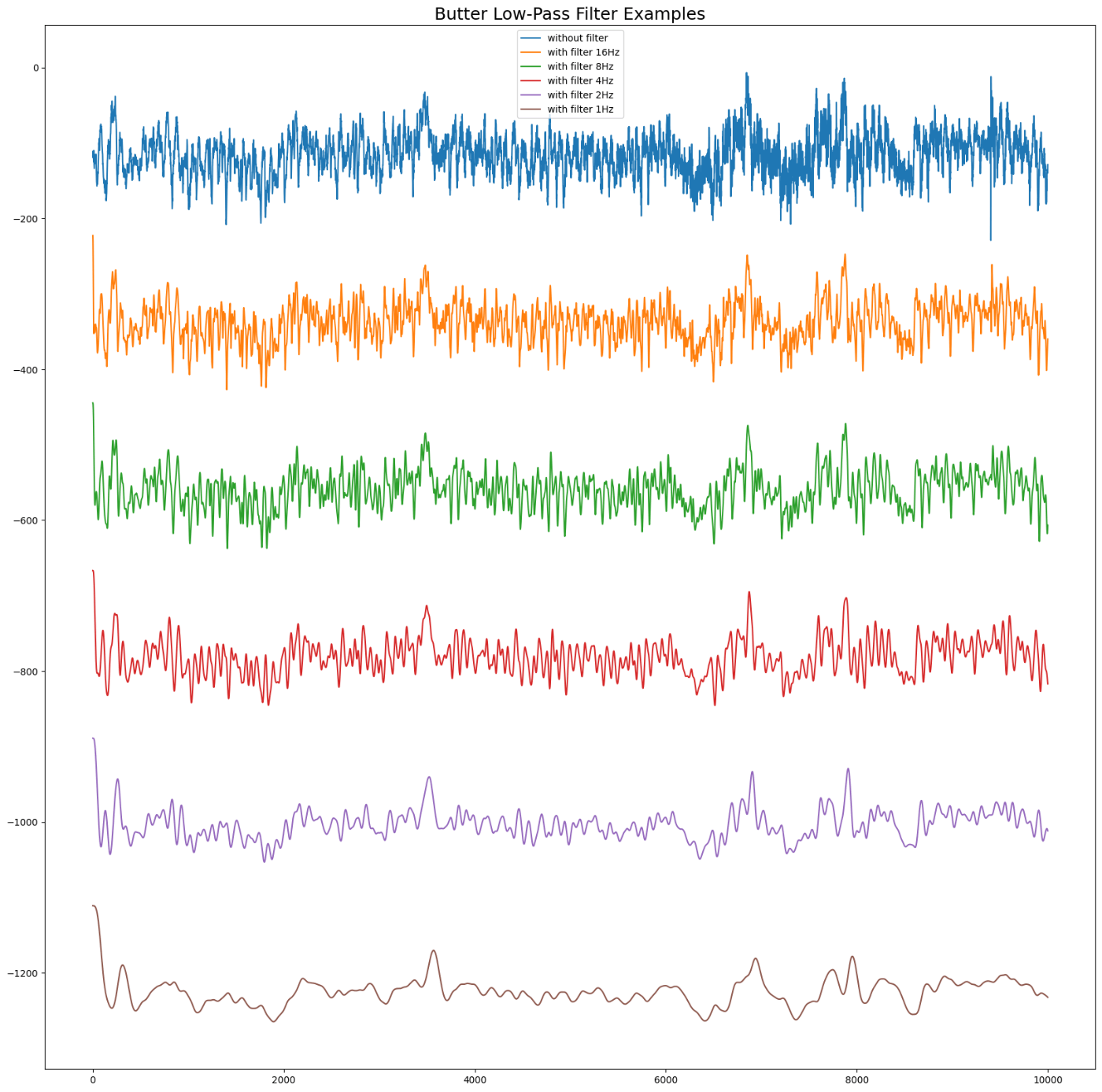
2.3 データローダー
・データローダー定義
前処理を得てモデルへデータを供給します。
import tensorflow as tf
class DataGenerator(tf.keras.utils.Sequence):
'Generates data for Keras'
def __init__(self, data, batch_size=32, shuffle=False, eegs=all_eegs, mode='train',
downsample=5):
self.data = data
self.batch_size = batch_size
self.shuffle = shuffle
self.eegs = eegs
self.mode = mode
self.downsample = downsample
self.on_epoch_end()
def __len__(self):
'Denotes the number of batches per epoch'
ct = int( np.ceil( len(self.data) / self.batch_size ) )
return ct
def __getitem__(self, index):
'Generate one batch of data'
indexes = self.indexes[index*self.batch_size:(index+1)*self.batch_size]
X, y = self.__data_generation(indexes)
return X[:,::self.downsample,:], y
def on_epoch_end(self):
'Updates indexes after each epoch'
self.indexes = np.arange( len(self.data) )
if self.shuffle: np.random.shuffle(self.indexes)
def __data_generation(self, indexes):
'Generates data containing batch_size samples'
X = np.zeros((len(indexes),10_000,8),dtype='float32')
y = np.zeros((len(indexes),6),dtype='float32')
sample = np.zeros((10_000,X.shape[-1]))
for j,i in enumerate(indexes):
row = self.data.iloc[i]
data = self.eegs[row.eeg_id]
# FEATURE ENGINEER
sample[:,0] = data[:,FEAT2IDX['Fp1']] - data[:,FEAT2IDX['T3']]
sample[:,1] = data[:,FEAT2IDX['T3']] - data[:,FEAT2IDX['O1']]
sample[:,2] = data[:,FEAT2IDX['Fp1']] - data[:,FEAT2IDX['C3']]
sample[:,3] = data[:,FEAT2IDX['C3']] - data[:,FEAT2IDX['O1']]
sample[:,4] = data[:,FEAT2IDX['Fp2']] - data[:,FEAT2IDX['C4']]
sample[:,5] = data[:,FEAT2IDX['C4']] - data[:,FEAT2IDX['O2']]
sample[:,6] = data[:,FEAT2IDX['Fp2']] - data[:,FEAT2IDX['T4']]
sample[:,7] = data[:,FEAT2IDX['T4']] - data[:,FEAT2IDX['O2']]
# STANDARDIZE
sample = np.clip(sample,-1024,1024)
sample = np.nan_to_num(sample, nan=0) / 32.0
# BUTTER LOW-PASS FILTER
sample = butter_lowpass_filter(sample)
X[j,] = sample
if self.mode!='test':
y[j] = row[TARGETS]
return X,y
- __init__()
ジェネレータの初期化に使用される。主なパラメータは、入力データ(data)、バッチサイズ(batch_size)、シャッフルの有無(shuffle)、EEGデータ(eegs)、モード(mode)、何分の一倍にダウンサンプリングされるか(downsample) - def __len__(self):
エポック毎のバッチサイズ数を返す。全データをバッチサイズで割り、np.ceilで小数点切り上げ - def __getitem__(self, index):
指定されたインデックスのバッチデータを返す。ここでself.downsample毎にデータを取得し、ダウンサンプリングも行う。 - def on_epoch_end(self):
各エポックの終了時に呼ばれ、データのインデックスを更新(suffleオン時にはシャッフル)する。 - __data_generation(self, indexes):
配列でインデックスの範囲を取得し、その範囲に対応するデータと正解ラベルを返す - X = np.zeros((len(indexes),10_000,8),dtype='float32')
次元数(バッチサイズ)indexes, 行数(データポイント)10000, 列数(電極由来)8の空データを作成 - y = np.zeros((len(indexes),6),dtype='float32')
行数(バッチサイズ)indexes, 列数(正解ラベル数)6の空データを作成 - sample = np.zeros((10_000,X.shape[-1]))
行数10000、列数(電極由来)8の空データを作成 - for j,i in enumerate(indexes):
繰り返し回数をj, 取得するデータのindexをiとしてindexes数だけ繰り返し - row = self.data.iloc[i]
index = iの行データを取得。入力配列(data)はこの行のeeg_idを取得するためだけに使用される。 - data = self.eegs[row.eeg_id]
辞書self.eegsからrow.eeg_idの指定するnumpyデータを取得。形状は(10000, 8)で、列名は['Fp1','T3','C3','O1','Fp2','C4','T4','O2'] - sample[:,0] = data[:,FEAT2IDX['Fp1']] - data[:,FEAT2IDX['T3']] ...
特徴量エンジニアリング。それぞれの電極データの差分を計算して波形とし、特定の脳領域間の活動さを捉える。算出波形をsampleの各列に割り当て - sample = np.clip(sample,-1024,1024) \ sample = np.nan_to_num(sample, nan=0) / 32.0
取得データの大きさを-1024~1024に丸める。欠損値を0に置換して32で割って正規化 - sample = butter_lowpass_filter(sample)
ローパスフィルターを通す - X[j,] = sample
取得した波形を繰り返し回数jの列に割り当て - if self.mode!='test': \ y[j] = row[TARGETS]
評価時でない場合、yのj行目にTRAGET列のデータを格納。(専門家の投票結果) - return X,y
形状(indexes(バッチサイズ), 電極間の差分データ, 電極数)のXと、形状(indexes(バッチサイズ), 各種症状に対する専門家の投票結果)のyをタプルで返す
・データローダーが取得するデータの可視化
gen = DataGenerator(train, shuffle=False)
for x,y in gen:
for k in range(4):
plt.figure(figsize=(20,4))
offset = 0
for j in range(x.shape[-1]):
if j!=0: offset -= x[k,:,j].min()
plt.plot(range(2_000),x[k,:,j]+offset,label=f'feature {j+1}')
offset += x[k,:,j].max()
tt = f'{y[k][0]:0.1f}'
for t in y[k][1:]:
tt += f', {t:0.1f}'
plt.title(f'EEG_Id = {EEG_IDS[k]}\nTarget = {tt}',size=14)
plt.legend()
plt.show()
break
2.4 GPU設定
・GPUの初期設定
import os
os.environ["CUDA_VISIBLE_DEVICES"]="0,1"
import tensorflow as tf
print('TensorFlow version =',tf.__version__)
# USE MULTIPLE GPUS
gpus = tf.config.list_physical_devices('GPU')
if len(gpus)<=1:
strategy = tf.distribute.OneDeviceStrategy(device="/gpu:0")
print(f'Using {len(gpus)} GPU')
else:
strategy = tf.distribute.MirroredStrategy()
print(f'Using {len(gpus)} GPUs')
使用可能なGPUデバイスを取得し、1つの場合と複数の場合分けてtensorflowの設定を行います。
・混合浮動小数点の使用可否
# USE MIXED PRECISION
MIX = True
if MIX:
tf.config.optimizer.set_experimental_options({"auto_mixed_precision": True})
print('Mixed precision enabled')
else:
print('Using full precision')
混合浮動小数点を使用するか否か。使用する場合、精度を下げない部分の計算で小数点が切り捨てられ、計算が高速化します。
2.5 モデル構築
・学習率推移の設定
# TRAIN SCHEDULE
def lrfn(epoch):
return [1e-3,1e-3,1e-4,1e-4,1e-5][epoch]
LR = tf.keras.callbacks.LearningRateScheduler(lrfn, verbose = True)
EPOCHS = 5
エポック毎に学習率を変更するスケジューラーを定義
・WaveBlock関数を定義
from tensorflow.keras.layers import Input, Dense, Multiply, Add, Conv1D, Concatenate
def wave_block(x, filters, kernel_size, n):
dilation_rates = [2**i for i in range(n)]
x = Conv1D(filters = filters,
kernel_size = 1,
padding = 'same')(x)
res_x = x
for dilation_rate in dilation_rates:
tanh_out = Conv1D(filters = filters,
kernel_size = kernel_size,
padding = 'same',
activation = 'tanh',
dilation_rate = dilation_rate)(x)
sigm_out = Conv1D(filters = filters,
kernel_size = kernel_size,
padding = 'same',
activation = 'sigmoid',
dilation_rate = dilation_rate)(x)
x = Multiply()([tanh_out, sigm_out])
x = Conv1D(filters = filters,
kernel_size = 1,
padding = 'same')(x)
res_x = Add()([res_x, x])
return res_x
- def wave_block(x, filters, kernel_size, n):
wave_blockの定義。- 引数
x: 入力
filters: フィルター数
kernel_size: カーネルサイズ
n: 拡張因果畳み込みの拡張数=畳み込み回数
- 引数
- dilation_rates = [2**i for i in range(n)]
拡張因果畳み込みの拡張率をリストで設定。n=4の時、dilation_rates=[1,2,4,8]。拡張率1で通常の畳み込みと同じ。 - x = Conv1D(filters = filters, kernel_size = 1, padding = 'same')(x)
一次元畳み込み。入力xのチャネル数をfiltersの数に揃えるために使用される。padding='same'で入出力の形状が同じになるように0埋めされる。 - res_x = x
residual connection(残差接続)用にxを保持 - for dilation_rate in dilation_rates:
拡張率ごとに繰り返し - tanh_out = Conv1D(filters = filters, kernel_size = kernel_size, padding = 'same', activation = 'tanh', dilation_rate = dilation_rate)(x)
一次元畳み込み層を定義。活性化関数はtnah、dilation_rateで拡張率を指定 - sigm_out = Conv1D(filters = filters, kernel_size = kernel_size, padding = 'same', activation = 'sigmoid', dilation_rate = dilation_rate)(x)
一次元畳み込み層を定義。活性化関数はsigmoid、dilation_rateで拡張率を指定 - x = Multiply()([tanh_out, sigm_out])
tanhの畳み込み結果とsigmoidの畳み込み結果を乗算 - x = Conv1D(filters = filters, kernel_size = 1, padding = 'same')(x)
WaveNet論文による1次元畳み込み。おそらく乗算結果を(意味のある)別の表現空間に変換する役割を担う - res_x = Add()([res_x, x])
残差接続。入力を加算する - return res_x
結果を返す。形状は(batch_size, datapoint_num(時間。10000), filters(チャネル数))
・モデル構造を定義
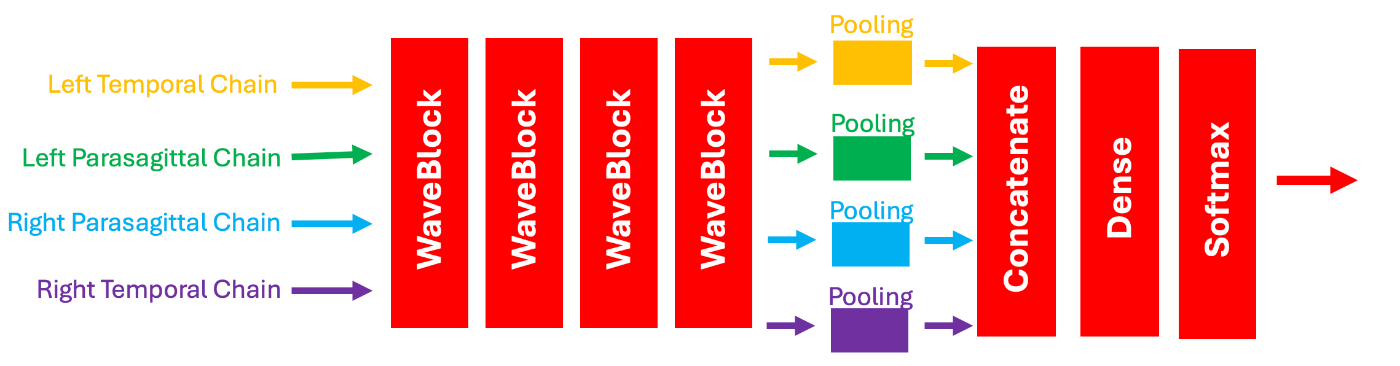
def build_model():
# INPUT
inp = tf.keras.Input(shape=(2_000,8))
############
# FEATURE EXTRACTION SUB MODEL
inp2 = tf.keras.Input(shape=(2_000,1))
x = wave_block(inp2, 8, 3, 12)
x = wave_block(x, 16, 3, 8)
x = wave_block(x, 32, 3, 4)
x = wave_block(x, 64, 3, 1)
model2 = tf.keras.Model(inputs=inp2, outputs=x)
###########
# LEFT TEMPORAL CHAIN
x1 = model2(inp[:,:,0:1])
x1 = tf.keras.layers.GlobalAveragePooling1D()(x1)
x2 = model2(inp[:,:,1:2])
x2 = tf.keras.layers.GlobalAveragePooling1D()(x2)
z1 = tf.keras.layers.Average()([x1,x2])
# LEFT PARASAGITTAL CHAIN
x1 = model2(inp[:,:,2:3])
x1 = tf.keras.layers.GlobalAveragePooling1D()(x1)
x2 = model2(inp[:,:,3:4])
x2 = tf.keras.layers.GlobalAveragePooling1D()(x2)
z2 = tf.keras.layers.Average()([x1,x2])
# RIGHT PARASAGITTAL CHAIN
x1 = model2(inp[:,:,4:5])
x1 = tf.keras.layers.GlobalAveragePooling1D()(x1)
x2 = model2(inp[:,:,5:6])
x2 = tf.keras.layers.GlobalAveragePooling1D()(x2)
z3 = tf.keras.layers.Average()([x1,x2])
# RIGHT TEMPORAL CHAIN
x1 = model2(inp[:,:,6:7])
x1 = tf.keras.layers.GlobalAveragePooling1D()(x1)
x2 = model2(inp[:,:,7:8])
x2 = tf.keras.layers.GlobalAveragePooling1D()(x2)
z4 = tf.keras.layers.Average()([x1,x2])
# COMBINE CHAINS
y = tf.keras.layers.Concatenate()([z1,z2,z3,z4])
y = tf.keras.layers.Dense(64, activation='relu')(y)
y = tf.keras.layers.Dense(6,activation='softmax', dtype='float32')(y)
# COMPILE MODEL
model = tf.keras.Model(inputs=inp, outputs=y)
opt = tf.keras.optimizers.Adam(learning_rate = 1e-3)
loss = tf.keras.losses.KLDivergence()
model.compile(loss=loss, optimizer = opt)
return model
- inp = tf.keras.Input(shape=(2_000,8))
入力形状を定義。(batch_size, time_stpes(2000), 電極数(8)) - inp2 = tf.keras.Input(shape=(2_000,1)) ... model2 = tf.keras.Model(inputs=inp2, outputs=x)
WaveBlockを重ねたモデルを定義(model2) - x1 = model2(inp[:,:,0:1])
inpの最初の電極間データをWaveBlockに入力。スライスなので入力の次元数は保たれる。model2は(batch_size, 2000, 1)の3次元形状を期待 - x1 = tf.keras.layers.GlobalAveragePooling1D()(x1)
WaveBlockの出力を平均プーリングする - x2 = model2(inp[:,:,1:2])
inpの次の電極間データをWaveBlockに入力 - z1 = tf.keras.layers.Average()([x1,x2])
x1とx2の出力結果の平均をとる。これにより、LL部分の電極間データの特徴マップが得られる
以下同様 - y = tf.keras.layers.Concatenate()([z1,z2,z3,z4])
出力された特徴マップを縦方向に結合 - y = tf.keras.layers.Dense(64, activation='relu')(y)
出力が64次元の全結合層を定義 - y = tf.keras.layers.Dense(6,activation='softmax', dtype='float32')(y)
出力が6次元で活性化関数がsoftmaxの、分類タスクにおける最終レイヤを定義 - model = tf.keras.Model(inputs=inp, outputs=y)
inpからyまでの流れをモデルとして定義 - opt = tf.keras.optimizers.Adam(learning_rate = 1e-3)
最適化関数(adam)と学習率を設定 - loss = tf.keras.losses.KLDivergence()
損失関数(KLダイバージェンス)を定義。2つの分布間の異なりを表す - model.compile(loss=loss, optimizer = opt)
モデルに損失関数と最適化関数を設定してコンパイル(setup) - return model
コンパイルしたモデルを返す
2.6 学習/評価
・学習して、グループK-Foldで評価
VERBOSE = 1
FOLDS_TO_TRAIN = 5
if not os.path.exists('WaveNet_Model'):
os.makedirs('WaveNet_Model')
from sklearn.model_selection import KFold, GroupKFold
import tensorflow.keras.backend as K, gc
all_oof = []; all_oof2 = []; all_true = []
gkf = GroupKFold(n_splits=5)
for i, (train_index, valid_index) in enumerate(gkf.split(train, train.target, train.patient_id)):
print('#'*25)
print(f'### Fold {i+1}')
train_gen = DataGenerator(train.iloc[train_index], shuffle=True, batch_size=32)
valid_gen = DataGenerator(train.iloc[valid_index], shuffle=False, batch_size=64, mode='valid')
print(f'### train size {len(train_index)}, valid size {len(valid_index)}')
print('#'*25)
# TRAIN MODEL
K.clear_session()
with strategy.scope():
model = build_model()
if TRAIN_MODEL:
model.fit(train_gen, verbose=VERBOSE,
validation_data = valid_gen,
epochs=EPOCHS, callbacks = [LR])
model.save_weights(f'WaveNet_Model/WaveNet_fold{i}.h5')
else:
model.load_weights(f'/kaggle/input/brain-eegs/WaveNet_Model/WaveNet_fold{i}.h5')
# WAVENET OOF
oof = model.predict(valid_gen, verbose=VERBOSE)
all_oof.append(oof)
all_true.append(train.iloc[valid_index][TARGETS].values)
# TRAIN MEAN OOF
y_train = train.iloc[train_index][TARGETS].values
y_valid = train.iloc[valid_index][TARGETS].values
oof = y_valid.copy()
for j in range(6):
oof[:,j] = y_train[:,j].mean()
oof = oof / oof.sum(axis=1,keepdims=True)
all_oof2.append(oof)
del model, oof, y_train, y_valid
gc.collect()
if i==FOLDS_TO_TRAIN-1: break
all_oof = np.concatenate(all_oof)
all_oof2 = np.concatenate(all_oof2)
all_true = np.concatenate(all_true)
- VERBOSE = 1
verbose(冗長)。どの程度まで学習状況を出力するか決定する - FOLDS_TO_TRAIN = 5
交差検証を行う回数。一般的には分割数と同じだけ行われるが、分割数より少なくても問題ない - if not os.path.exists('WaveNet_Model'):
モデルの保存先を作成 - all_oof = []; all_oof2 = []; all_true = []
oof結果格納先の初期化 - gkf = GroupKFold(n_splits=5)
sklearnのGroupKFlodオブジェクトを定義。分割数は5 - for i, (train_index, valid_index) in enumerate(gkf.split(train, train.target, train.patient_id)):
gkfにより、train_indexには学習用データのインデックスを含む配列、vaild_indexには評価用データのインデックスを含む配列が得られる(iは繰り返し回数)。同じpatient_idを持つデータは同じ側にのみ存在する。 - train_gen = DataGenerator(train.iloc[train_index], shuffle=True, batch_size=32)
データローダーから指定のインデックスのデータ(バッチサイズ, 電極間の差分データ, 電極数)を取得 - train_gen = DataGenerator(train.iloc[train_index], shuffle=True, batch_size=32)
学習用DataGeneratorの定義。trainから学習用データのインデックスの行のみをgeneratorに渡す - valid_gen = DataGenerator(train.iloc[valid_index], shuffle=False, batch_size=64, mode='valid')
評価用DataGeneratorの定義。trainから評価用データのインデックスの行のみをgeneratorに渡す - K.clear_session()
初期化。kerasによって生成された全ての状態をリセットする。効率的なメモリ活用のために使われる - with strategy.scope():
スコープ内では(事前に設定した)適切なGPU環境を使用 - model = build_model()
モデルの定義 - model.fit(train_gen, verbose=VERBOSE, validation_data = valid_gen, epochs=EPOCHS, callbacks = [LR])
モデルの学習。- 引数
tarin_gen: 使用する学習データジェネレータ
valid_gen: 評価に使用するデータジェネレータ
epochs: 学習回数(全データが使用されると1回)
callbacks: epoch毎に呼ばれる。今回は学習率を変更する
- 引数
- model.save_weights(f'WaveNet_Model/WaveNet_fold{i}.h5')
fold毎にモデルを保存 - model.load_weights(f'/kaggle/input/brain-eegs/WaveNet_Model/WaveNet_fold{i}.h5')
学習済みの場合、重みをロード - oof = model.predict(valid_gen, verbose=VERBOSE)
varid_genを使用して予測を行う。予測結果をoofに格納 - all_oof.append(oof)
fold毎に結果を追加 - all_true.append(train.iloc[valid_index][TARGETS].values)
予測に使用したデータの正解ラベルをall_trueに追加。これにより、全学習/評価終了後に、all_oofとall_trueで答え合わせができる - y_train = train.iloc[train_index][TARGETS].values
trainデータの正解ラベル(vote)を取得。6列のnumpy配列 - y_valid = train.iloc[valid_index][TARGETS].values
validデータの正解ラベル(vote)を取得。6列のnumpy配列 - oof = y_valid.copy()
y_validをoofにコピー - for j in range(6): \ oof[:,j] = y_train[:,j].mean()
oofの各列の値を、(y_trainの)その列の平均値に設定。計算した平均値(スカラ)をoof各列の全行に代入。目的は列毎の平均値を代入したoofをベースラインにすること - oof = oof / oof.sum(axis=1,keepdims=True)
各列の全データを行の合計値で割る。これにより、行方向の総和が1の確率分布になる - all_oof2.append(oof)
fold毎にoofデータをall_oof2に追加する。oofは評価用データのインデックスしか持たないので、全fold完了時に、all_oof2はモデルの予測結果と比較するための平均ベースラインとして完成する - del model, oof, y_train, y_valid \ gc.collect()
メモリ、ガベージコレクションの開放 - if i==FOLDS_TO_TRAIN-1: break
繰り返し回数がFOLDS_TO_TRAINと同値になった時、ループを抜ける - all_oof = np.concatenate(all_oof) \ all_oof2 = np.concatenate(all_oof2) \ all_true = np.concatenate(all_true)
追加していたデータを全て列方向に結合。全てのインデックスが含まれるようになる。
・予測結果のクロスバリデーションスコアの計算
import sys
sys.path.append('/kaggle/input/kaggle-kl-div')
from kaggle_kl_div import score
oof = pd.DataFrame(all_oof.copy())
oof['id'] = np.arange(len(oof))
true = pd.DataFrame(all_true.copy())
true['id'] = np.arange(len(true))
cv = score(solution=true, submission=oof, row_id_column_name='id')
print('CV Score with WaveNet Raw EEG =',cv)
予測結果と、正しいデータをDataFrameに変換し、同一の"id"列を追加。データの順番は同じなので、idは上から順番に付ければ大丈夫です。
- cv = score(solution=true, submission=oof, row_id_column_name='id')
予測結果(oof)と正解分布(true)の"id"が同じ列に対して、KLダイバージェンスを計算。
・学習データの平均値におけるクロスバリデーションスコアの計算
oof = pd.DataFrame(all_oof2.copy())
oof['id'] = np.arange(len(oof))
true = pd.DataFrame(all_true.copy())
true['id'] = np.arange(len(true))
cv = score(solution=true, submission=oof, row_id_column_name='id')
print('CV Score with Train Means =',cv)
同様の計算を、学習データの平均をとったベースラインで行います。このデータより予測データのスコアが高ければ(数値としては低ければ)学習が上手くいっていると考えられます。
2.7 提出
・予測するデータの確認
del all_eegs, train; gc.collect()
test = pd.read_csv('/kaggle/input/hms-harmful-brain-activity-classification/test.csv')
print('Test shape:',test.shape)
test.head()
# output
# Test shape: (1, 3)
# spectrogram_id eeg_id patient_id
# 0 853520 3911565283 6885
予測するべきデータが一行しかありませんが、このcsvファイルは提出時に正しいものに置き換えられます。
・paquetデータをnumpy配列として取得
all_eegs2 = {}
DISPLAY = 1
EEG_IDS2 = test.eeg_id.unique()
PATH2 = '/kaggle/input/hms-harmful-brain-activity-classification/test_eegs/'
print('Processing Test EEG parquets...'); print()
for i,eeg_id in enumerate(EEG_IDS2):
# SAVE EEG TO PYTHON DICTIONARY OF NUMPY ARRAYS
data = eeg_from_parquet(f'{PATH2}{eeg_id}.parquet', i<DISPLAY)
all_eegs2[eeg_id] = data
予測用データに含まれる一意のeeg_idをkeyとして、numpy配列データをvalueとする辞書all_eeg2を作成
・学習したモデルを使用して予測を行う
# INFER MLP ON TEST
preds = []
model = build_model()
test_gen = DataGenerator(test, shuffle=False, batch_size=64, eegs=all_eegs2, mode='test')
print('Inferring test... ',end='')
for i in range(FOLDS_TO_TRAIN):
print(f'fold {i+1}, ',end='')
if TRAIN_MODEL:
model.load_weights(f'WaveNet_Model/WaveNet_fold{i}.h5')
else:
model.load_weights(f'/kaggle/input/brain-eegs/WaveNet_Model/WaveNet_fold{i}.h5')
pred = model.predict(test_gen, verbose=0)
preds.append(pred)
pred = np.mean(preds,axis=0)
print()
print('Test preds shape',pred.shape)
- preds = []
予測結果を格納するリスト - model = build_model()
モデル定義 - test_gen = DataGenerator(test, shuffle=False, batch_size=64, eegs=all_eegs2, mode='test')
予測用データを提供するデータローダーを定義 - for i in range(FOLDS_TO_TRAIN):
学習したfoldの数だけ繰り返し - pred = model.predict(test_gen, verbose=0)
モデルを使用して予測 - preds.append(pred)
予測結果をリストに格納 - pred = np.mean(preds,axis=0)
リストに格納された予測結果(二次元配列)を、次元方向、リスト方向に平均化して1つの予測結果predを作成する。各foldの予測結果を平均するイメージ
・提出用csvファイルの作成
# CREATE SUBMISSION.CSV
from IPython.display import display
sub = pd.DataFrame({'eeg_id':test.eeg_id.values})
sub[TARGETS] = pred
sub.to_csv('submission.csv',index=False)
print('Submission shape',sub.shape)
display( sub.head() )
# SANITY CHECK TO CONFIRM PREDICTIONS SUM TO ONE
print('Sub row 0 sums to:',sub.iloc[0,-6:].sum())
# output
# Submission shape (1, 7)
# eeg_id seizure_vote lpd_vote gpd_vote lrda_vote grda_vote other_vote
# 0 3911565283 0.047582 0.032299 0.001257 0.112705 0.105959 0.700198
# Sub row 0 sums to: 0.9999999820720404
- sub = pd.DataFrame({'eeg_id':test.eeg_id.values})
'eeg_id'列に予測用データのeeg_id列の値が格納されているDataFrame、subを作成 - sub[TARGETS] = pred
subの[TARGET]列に予測結果を格納。予測用データジェネレータでシャッフルしていないため、そのまま追加してもidが合致する - sub.to_csv('submission.csv',index=False)
DataFrameをcsvに変換。indexは不要。これが提出用ファイルとなる。
まとめ
今回は以上です。長くなりましたが、興味がある方はぜひ原文を確認してみて下さい。
Discussion