【機械学習】CVスコアを理解する
1. CVスコアとは
CVスコアは、機械学習モデルの性能を測るための CV(Cross validation) という検証の結果のことです。
イメージ: データを分割してモデルの性能を評価する
CVでは全データを使用して一般化能力を測るため信頼度が高く、KaggleではTrust CV(公開されているLBのスコアと連動するCVのスコアを信じろ)と言う言葉もあります。
こうして、CVスコアが上がれば、パブリックリーダーボードのスコアが上がるという状況ができれば、特徴選択やモデルの選択などが、サブミットすることなくCVスコアのみで判断することができ、パブリックリーダーボードのスコアは目安程度となります。
トラストCV」とkaggleでは、格言のようにCVスコアを信じることの大切さが言われますが、信じるのはパブリックリーダーボーと相関する状況になった、CVスコアのことであり、適当に作った検証セットのCVスコアではないということを気をつけましょう。
(コンペによっては、相関させるのが不可能だったり、CVスコアを信じる、パブリックリーダーボードを信じる必要があるなど、特殊なものもありますが、その時には、統計学だったりドメイン知識だったり幅広い知見が求められると思っています)信頼できる検証セットを作成できた後は、実験を数多くするのみです。
引用: カレーちゃん
2. 手法
CVスコアは、クロスバリデーションを行ったモデルが、それぞれのFoldでTestデータとして使用したデータに対して、そのFoldで学習したモデルによる予測を行い、それを全てのFoldに対して行った推論値を、正解データと共に損失関数に入れて算出された値のことです。
言葉では難しくて分かりませんね。イメージを見ていきましょう。
・イメージ

上図の構成要素それぞれについて以下で解説していきます。
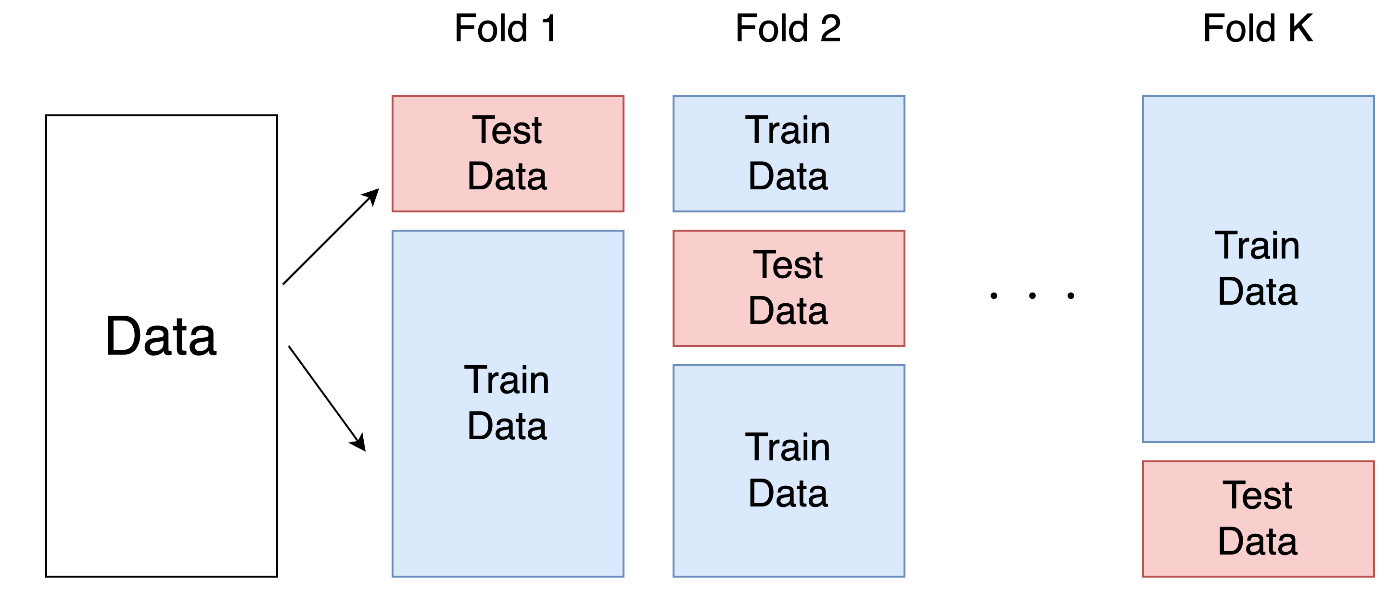
1. Fold分割
データセットを、いくつかのFold(一般的に5つ)に分割します。
この時、それぞれのFoldも学習用のTrain Dataと、評価用のTest Dataに分割されます。
この時、各FoldのTestデータに重複は存在しません。
具体的な分割のやり方については記事を書いています。
2. Train
foldに分割したそれぞれのTrain Dataを使用して、複数の同じモデルの学習を行います。この時、各モデル性能の評価にはそれぞれのTest Dataを使用します。
学習の過程で、最も性能が良かったモデルを選び、最終的にK個のモデルが出来上がります。

3. Inference
作成したK個のモデルを使用し、各foldのTest Dataに対して再度推論を行います。
これにより、各foldのTest Dataに対応する推論がK個出来上がります。

これらの推論結果をConcatで結合することでにより、元々のデータセットの全てのデータに対する推論が完成します。

4. CV Score
完成した推論とTarget(正解データ)を損失関数(Loss)に渡し、得られた結果がCV Scoreです。
この値が低いほど、より良いモデルであることが分かります。
※外部データに対するScoreとCV Scoreが連動していることが前提

5. モデルをまとめる
これまで、K個のモデルを作ってきましたが、最終推論時には一つの結果にする必要があります。
これには様々な手法がありますが、シンプルな解決策は、K個のモデルで全データに対して推論し、得られたK個の出力を平均することです。
まとめ
今回はCV Scoreについて解説しました。
より良いモデル構築の助けとなる手法でした。
Discussion