K-Fold交差検証についてのまとめ
sklearnのK-Fold Cross Validation(K-分割交差検証)についてまとめます。
概要
K-Foldはモデルの評価に利用されます。
目的はモデルの汎化性能を確認し、過学習を防ぐことです。
まず全てのデータを訓練用(Train data)とテスト用(Test data)に分割します。
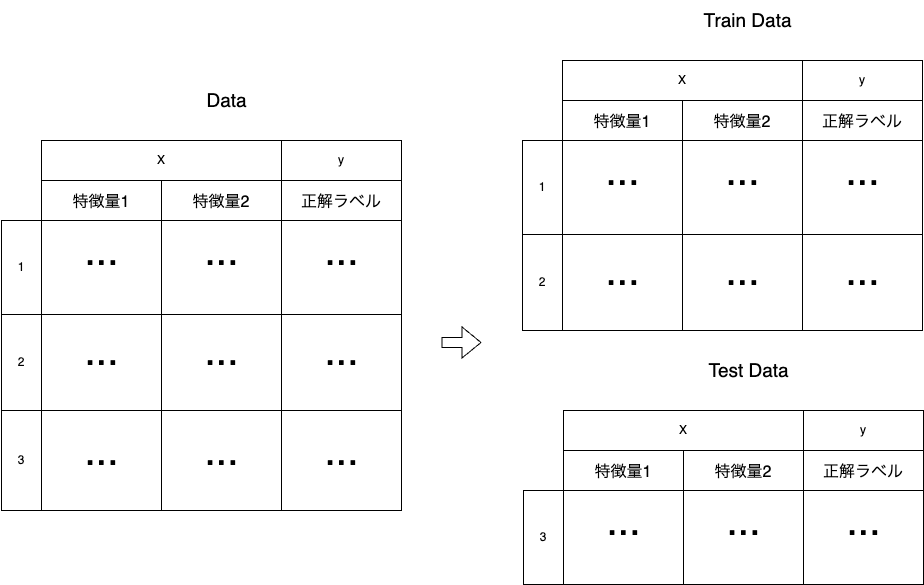
そして分割した「Train dataのXとy」を使用して学習を行ったモデルで、「Test dataのXだけ」から予測を行い、Test dataのyと比較して精度を評価します。
これをCross Validation(交差検証)、略してCVと呼びます。
K-FoldはこのCVの分割を行う手法です。
K-Fold
KFold(n_splits, shuffle, random_state)
- データをk個に分割し、n個を訓練用、k-n個をテスト用として使う
- 分けられたk個のデータがテスト用として必ず一度だけ使われるようにk回検証する
- 引数
n_split(option):データの分割数、つまりk。検証はここで指定した数値の回数行われる
shuffle(option):Trueならランダムにデータを選択する
random_state(option):乱数のシードを指定できる。ランダム性を持つ手法で再現性を保ちたいときに利用
KFold.split(X, y, groups)
- 訓練用、テスト用に分割したインデックスの配列を返す
- 引数
X: 特徴量など含むデータフレーム。この長さに基づいて分割される
y(option): データのターゲットや正解ラベルを含む配列。Stratified K-Foldなど正解ラベルを使用する手法で利用
groups(option): データポイントのグループを指定する配列。GroupKFoldなどグループ情報を使用する手法で利用
K-Fold
import numpy as np
from sklearn.model_selection import KFold
X = np.array([[1, 2], [3, 4], [1, 2], [3, 4]])
y = np.array([1, 2, 3, 4])
kf = KFold(n_splits=4)
for i, (train_index, test_index) in enumerate(kf.split(X)):
print(f"Fold {i}:")
print(f" Train: index={train_index}")
print(f" Test: index={test_index}")
# output
# Fold 0:
# Train: index=[1 2 3]
# Test: index=[0]
# Fold 1:
# Train: index=[0 2 3]
# Test: index=[1]
# Fold 2:
# Train: index=[0 1 3]
# Test: index=[2]
# Fold 3:
# Train: index=[0 1 2]
# Test: index=[3]
データのインデックスが、訓練用とテスト用に分割されます。これらを使用してモデルの精度を確認します。
※ 基本的に分割の割合は等しくなりますが、データ総数がn_splitsで割り切れない場合には、「全てのデータが一度だけTest dataとして使用される」ことを条件に変則的に分割されます。
変則分割の例
n_splits=3
# Fold 0:
# Train: index=[2 3]
# Test: index=[0 1]
# Fold 1:
# Train: index=[0 1 3]
# Test: index=[2]
# Fold 2:
# Train: index=[0 1 2]
# Test: index=[3]
Group K-Fold
GroupKFold(n_splits)
- データの分割に、「group番号が同じものは同じ側(訓練用orテスト用)のデータになる」という制限が追加されます。
- 引数
n_split(option):データの分割数。デフォルトは5
Group K-Fold
import numpy as np
from sklearn.model_selection import GroupKFold
X = np.array([[1, 2], [3, 4], [5, 6], [7, 8], [9, 10], [11, 12]])
y = np.array([1, 2, 3, 4, 5, 6])
groups = np.array([0, 0, 2, 2, 3, 3])
group_kfold = GroupKFold(n_splits=2)
for i, (train_index, test_index) in enumerate(group_kfold.split(X, y, groups)):
print(f"Fold {i}:")
print(f" Train: index={train_index}, group={groups[train_index]}")
print(f" Test: index={test_index}, group={groups[test_index]}")
# output
# Fold 0:
# Train: index=[0 1 2 3], group=[0 0 2 2]
# Test: index=[4 5], group=[3 3]
# Fold 1:
# Train: index=[0 1 4 5], group=[0 0 3 3]
# Test: index=[2 3], group=[2 2]
# Fold 2:
# Train: index=[2 3 4 5], group=[2 2 3 3]
# Test: index=[0 1], group=[0 0]
グループ番号を任意の配列で指定し、同じグループ番号を持つデータは同じ側のデータ(TrainもしくはTest)に割り当てられます。
Stratified K-Fold
StratifiedKFold(n_splits, shuffle, random_state)
- 特に分類問題で、Train data及びTest dataの各クラス(正解ラベル)の分布が等しくなるように分割を行う
- 引数
n_split(option):データの分割数、つまりk。検証はここで指定した数値の回数行われる
shuffle(option):ランダムにデータを選択
random_state(option):乱数のシードを指定できる
StratifiedKFold.split(X, y, groups)
- 引数
X: 特徴量などを含むデータ。分割のために長さのみが必要
y: 正解ラベルを含むデータ。このクラスによって分割が決定されるため、本手法では必須
groups(option): 不要。互換性のために存在
Stratified K-Fold
import numpy as np
from sklearn.model_selection import StratifiedKFold
X = np.array([[1, 2], [3, 4], [1, 2], [3, 4], [1, 2], [3, 4], [1, 2], [3, 4]])
y = np.array([0, 0, 0, 0, 1, 1, 2, 2])
skf = StratifiedKFold(n_splits=2)
for i, (train_index, test_index) in enumerate(skf.split(X, y)):
print(f"Fold {i}:")
print(f" Train: index={train_index}")
print(f" Test: index={test_index}")
# output
# Fold 0:
# Train: index=[2 3 5 7]
# Test: index=[0 1 4 6]
# Fold 1:
# Train: index=[0 1 4 6]
# Test: index=[2 3 5 7]
上記では、Train,Test共に正解ラベルが「0」のデータが2つ、「1」のデータが1つ、「2」のデータが1つ均等に存在します。
このように、正解ラベルの割合が同じになるようにデータを分割するのがStratified K-Foldです。正解ラベルが不均一なデータでは、例えばTrain dataに正解が「2」のデータが偏り、Testデータで「2」が正解となる予測を試すことができない、ということが起こり得ます。
これを解決するために使用されます。
StratifiedGroupKFold
StratifiedGroupKFold(n_splits, shuffle, random_state)
- Group K-Fold と StratifiedKFoldの複合
- 同グループのデータが同じ側に割り当てられ、クラス(正解ラベル)の分布はTrainとTestで等しくなるように分割される
- 優先度はGroup K-Foldの方が上のため、分布にばらつきが出ることがある
StratifiedGroupKFold
import numpy as np
from sklearn.model_selection import StratifiedGroupKFold
X = np.ones((17, 2))
y = np.array([0, 0, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0])
groups = np.array([1, 1, 2, 2, 3, 3, 3, 4, 5, 5, 5, 5, 6, 6, 7, 8, 8])
sgkf = StratifiedGroupKFold(n_splits=3)
for i, (train_index, test_index) in enumerate(sgkf.split(X, y, groups)):
print(f"Fold {i}:")
print(f" Train: index={train_index}")
print(f" group={groups[train_index]}")
print(f" Test: index={test_index}")
print(f" group={groups[test_index]}")
# output
# Fold 0:
# Train: index=[ 0 1 2 3 7 8 9 10 11 15 16]
# group=[1 1 2 2 4 5 5 5 5 8 8]
# Test: index=[ 4 5 6 12 13 14]
# group=[3 3 3 6 6 7]
# Fold 1:
# Train: index=[ 4 5 6 7 8 9 10 11 12 13 14]
# group=[3 3 3 4 5 5 5 5 6 6 7]
# Test: index=[ 0 1 2 3 15 16]
# group=[1 1 2 2 8 8]
# Fold 2:
# Train: index=[ 0 1 2 3 4 5 6 12 13 14 15 16]
# group=[1 1 2 2 3 3 3 6 6 7 8 8]
# Test: index=[ 7 8 9 10 11]
# group=[4 5 5 5 5]
同グループのデータが同じ側に割り当てられた上で、TrainとTestに含まれる分類クラス(正解ラベル)の分布が等しくなるように分割されます。
他の分割手法
ここからはK-Foldとは異なる手法で、代表的なものを紹介します。
これらはK-Foldの「データがテスト用として一度だけ使用される」という制限がなくなるため、同じインデックスが何度もTest dataに出現する可能性があります。
Shuffle Split
ShuffleSplit(n_splits, test_size, train_size, random_state)
- ランダムにデータを選択してTrain dataとTest dataを作成する
- Train data, Test dataのサイズを割合もしくは絶対値で指定できる
- 何回分割を繰り返すか指定できる(kfoldは 繰り返し回数=分割回数 で固定)
- 引数
n_splits(option): 分割を何回行うか
test_size(option): Test dataのサイズ
train_size(option): Train dataのサイズ
random_state(option): ランダムのシード値
Shuffle Split
import numpy as np
from sklearn.model_selection import ShuffleSplit
X = np.array([[1, 2], [3, 4], [5, 6], [7, 8], [3, 4], [5, 6]])
y = np.array([1, 2, 1, 2, 1, 2])
rs = ShuffleSplit(n_splits=5, test_size=.25, random_state=0)
for i, (train_index, test_index) in enumerate(rs.split(X)):
print(f"Fold {i}:")
print(f" Train: index={train_index}")
print(f" Test: index={test_index}")
# output
# Fold 0:
# Train: index=[1 3 0 4]
# Test: index=[5 2]
# Fold 1:
# Train: index=[4 0 2 5]
# Test: index=[1 3]
# Fold 2:
# Train: index=[1 2 4 0]
# Test: index=[3 5]
# Fold 3:
# Train: index=[3 4 1 0]
# Test: index=[5 2]
# Fold 4:
# Train: index=[3 5 1 0]
# Test: index=[2 4]
# train と test のサイズを指定
rs = ShuffleSplit(n_splits=5, train_size=0.5, test_size=.25,
random_state=0)
for i, (train_index, test_index) in enumerate(rs.split(X)):
print(f"Fold {i}:")
print(f" Train: index={train_index}")
print(f" Test: index={test_index}")
# output2
# Fold 0:
# Train: index=[1 3 0]
# Test: index=[5 2]
# Fold 1:
# Train: index=[4 0 2]
# Test: index=[1 3]
# Fold 2:
# Train: index=[1 2 4]
# Test: index=[3 5]
# Fold 3:
# Train: index=[3 4 1]
# Test: index=[5 2]
上の例はTest dataのサイズを25%に指定しており、下の例はTrain dataのサイズを50%, Test dataのサイズを25%に指定しています。分割の回数は上が5回、下が4回です。
K-Foldのような制限がないため、このように柔軟に分割方法を指定することができます。
Stratified Shuffle Split
上記の手法の複合
※追記予定
Time Series Split
時系列データに対するデータ分割
※追記予定
参考:
(1) sklearn公式ドキュメント
(2) sklearnの交差検証の種類とその動作
Discussion