API Gatewayのresponse streamingでAPI Gatewayのサイズ上限を超えてダウンロードが行えるか試してみた
はじめに
みなさん、AWS re:Inventの時期ですね!
AWSをお使いの皆様はこの時期はAWSのアップデート情報を追うのに忙しいかなと思います。
もしくはre:Inventの現地で発表とセッションを追うのに忙しい方もいらっしゃるかもしれません。
自分は現地参加は無理なので公式ブログと現地参加の皆さんの情報を頼りにアップデート情報を追っています。
さて、re:Inventの時期にはAWSのアップデートが大量にリリースされるのが恒例 [2]ですが、今回は11月にアップデートのあったAPI GatewayのResponse Streamingに注目します。
これによりレスポンスの制限を一部乗り越えられるのではないかと思ったのが動機です。
既に触れられているユースケースでよくあるのは、Bedrock[3]のレスポンスをLambdaがそのままストリームでAPI Gatewayから返す、というものです。
例えば以下など
この記事ではそれらではなく、Lambdaのresponse streamingと組み合わせて10MBを超えるファイルをAPI Gatewayから返せるか、ということを検証してみます。
前提
まず、なぜこのような検証をしようと思ったかというと、API Gatewayを使ったサーバレスアーキテクチャにおいて、API Gatewayを介したファイルダウンロードを行わせたいケースがあったからです。
最初に軽く触れましたが、API Gatewayのレスポンスには制限が存在しました。
ペイロードサイズが10MB(上限緩和不可)だったり、タイムアウトが最大29秒(HTTP APIだと30秒っぽい)だったり…。
※参考
これまでは、このようなケースでは一旦S3バケットにファイルを配置し、S3のPreSigned URLを発行してそこからダウンロードさせるなどがよくある手法でした。
※S3のPreSigned URLについては以下
署名付き URL を使用したオブジェクトの共有
API Gateway + Lambda で S3 署名付き URL (ダウンロード用) を発行する構成を AWS CDK で実装する
ざっくりいうと一時URLを期限付きで発行してそこからダウンロードさせるという形です。
動画や重い画像などをやりとりさせるなら、API Gateway経由よりもS3から直接ダウンロードしたほうがやや料金効率も良いですし、Lambdaを経由させるとLamdbaの実行時間分課金が入るのでその分も省けます。
ただし、たとえば以下のようなケースではAPI Gatewayから直接返したいということが想定されます。
- Presigned URLをむやみに発行したくない
- バケットポリシーでIP制限などかけることはできるものの、基本的には発行したURLが漏れたらURLが期限切れになるまでは誰でも使えてしまう
- APIの仕様としてファイルを直接返させるようにしたい
- クライアント側で発行したURLに即時アクセスさせる挙動を保証させられるなら良いですが、APIだけ実装して使い方はクライアント任せ、みたいな感じだとそうもいかないことがあります
- 一時的にでも、ユーザーに渡すファイルをS3に配置したくない
- S3バケットにもともとあるものでなければファイルの原本がどこかにあるはずで、そうなるとファイルのコピーがS3に置かれることになり、それを嫌がるというケースは考えられます
- もちろん、S3バケットのライフサイクルポリシーを使って短い時間でバケットから削除するという方法も考えられるのでそこは作る人や組織のポリシーや考え方次第です
- S3バケットにもともとあるものでなければファイルの原本がどこかにあるはずで、そうなるとファイルのコピーがS3に置かれることになり、それを嫌がるというケースは考えられます
また、たとえばPDFなどをダウンロードさせたい場合、10MBという制限が微妙で、これに抵触するかどうかを考えなければいけなくなったりします。
そこで、API GatewayのResponse Streamingを使って、この10MBの制限を超えてファイルを返せるかどうかを試してみよう、というのが今回の記事を書こうと思った発端です。
今回は以下のような構成を想定します。
- ランタイム
- Lambda
- PythonとNode.js
- Lambda
- API種別
- API Gateway REST APIを想定
- Response Streaming対応は執筆時点ではREST APIのみ
- API Gateway REST APIを想定
- 取得ファイル
- S3上に配置したファイル
- S3のAPI経由ではなく、公開したS3から直接ダウンロード
- S3上に配置したファイル
- 目的
- API Gatewayのレスポンスとしてそのまま10MBを超えるファイルを返せかどうかを確認する。
注意点として、Lambdaのレスポンスストリーミングはランタイムによって対応状況が異なります。Node.jsはランタイムネイティブでの対応が案内されています。一方、他言語では AWS Lambda Web Adapter(awslabs/aws-lambda-web-adapter)を組み合わせることでHTTPフレームワークのストリーミングをLambdaに橋渡しできます。
本記事ではPython で Web Adapterを使用した手法も触れます。(自分がPythonでLambdaを実装する要件があり検証したいため。)
※API GatewayやらLambdaやらってなんぞや、という方は以下などをご参照ください。
- API Gateway
- Amazon API Gateway とは何ですか?
- APIをサクッと構築できるサービス。構築したAPIを別のところに流したり、AWSのサービスに流して処理させたりできる。
- Lambda
- AWS Lambda とは
- ざっくり言うと、サーバを意識せずにプログラムを実行できるサービス。今回のような構成ではAPI Gatewayが受けたリクエストをLambdaに送って、そのLambdaが処理を行う。
- サーバレスアーキテクチャ
※追記
実はAPI GatewayのLambda関数プロキシ統合ではなく、Lambda Function URLを発行してそれをAPI GatewayのHTTP Proxy統合でエンドポイントURLに設定することで、ペイロードサイズ上限を回避する方法が既に記事化されています。
ただし、この方法ではLambda Function URLに対するアクセス制限をどうするかが課題になってきます。
未検証ですが、HTTP Proxy統合のリクエストではおそらくLambda Function URLのIAM認証のリクエスト要件を満たせない(SigV4 署名付きリクエストが必要)ので、実質リソースベースポリシーによる制御が必要になるかと思います。
API GatewayのARNを設定すればもしかしたらAPI Gatewayからのみ呼び出せるようにできるかもしれませんが、ちょっとそこまでは未検証です…。
また、何も設定しないとパブリックにアクセス可能なURLとなってしまうため注意が必要です。
また、イベントの受け取り方が変わるため、Lambdaの実装もLambdaプロキシ統合のLambdaとは異なってくるはずです。
検証構成(概略)
- クライアント(ブラウザや
curl) - API Gateway(REST API)
-
レスポンス転送モードを"ストリーム"に設定する
- 今回のアップデートでできるようになったことです
- Lambda統合でLambdaにレスポンスを返させる
-
レスポンス転送モードを"ストリーム"に設定する
- Lambda(ストリーミングで応答を返す)
- S3バケット
- 今回はS3のAPI経由ではなく、バケットを公開してそこからダウンロードする形で試します。
セットアップ手順(概要)
- API Gateway REST API を作成
- Response Streamingを実装したLambdaを作成
- 統合に Lambda を指定(Lambdaプロキシ統合)
- 必要に応じてステージ/ルート/オーソリゼーションを設定
-
curlやブラウザからダウンロード挙動を確認(CloudWatch Logs でエラーやタイムアウトも併せて確認)
ローカルでの簡易動作確認やパッケージングには、普段のビルド/デプロイ手段(SAM/Serverless Framework/Terraform/手動アップロードなど)を適用してください。ここでは最小例に留めます。
Lambdaの実装
API Gatewayにレスポンスを返させるLambdaを先に作成します。
先述の通り、執筆時点ではNodeだけがLambdaのResponse Streamingのみに対応しています。
Lambdaはランタイム設定とタイムアウト値以外はデフォルトで作成します。
タイムアウトについては短すぎるとダウンロード中にタイムアウトしてしまうため、ここでは適当に1分と設定します。
サンプルでS3に上げたファイルがあんまり大きい場合はメモリを増やしたほうがいいかもしれません。
ランタイム設定については実装する言語のものを設定してください。

Node.js(ネイティブ)— S3中継の最小例
Node.js ランタイムでは Lambda がResponse Streamingをネイティブにサポートします。公開S3のオブジェクトをhttps.getで取得し、そのままストリーム転送します。
import https from 'node:https';
import { pipeline } from 'node:stream/promises';
// グローバルの awslambda ヘルパを使用
export const handler = awslambda.streamifyResponse(async (event, responseStream, context) => {
const httpResp = awslambda.HttpResponseStream.from(responseStream, {
statusCode: 200,
headers: {
'Content-Type': 'application/octet-stream',
// 任意: ダウンロード時のファイル名を指定
'Content-Disposition': 'attachment; filename="file.bin"'
}
});
const url = 'https://<bucket>.s3.<region>.amazonaws.com/path/to/object';
await new Promise((resolve, reject) => {
https.get(url, (res) => {
if (res.statusCode !== 200) {
// 上流エラーを簡易的に通知
httpResp.write(Buffer.from(`Upstream error: ${res.statusCode}\n`));
httpResp.end();
reject(new Error(`S3 GET failed: ${res.statusCode}`));
return;
}
pipeline(res, httpResp).then(resolve).catch(reject);
}).on('error', reject);
});
});
REST API は Lambda プロキシ統合で、該当リソース/メソッドに上記ハンドラを紐づけます。
ファイル名付与の補足(取得元から動的に反映)
ダウンロード時の名前と拡張子を保持したい場合、取得元(S3キー名やContent-Disposition/Content-Type)からファイル名を導出し、レスポンスヘッダに付与します。
- 例(Node): S3のURLやキーから名前を抽出
const key = 'path/to/file/report_2025.pdf';
const filename = key.split('/').pop(); // report_2025.pdf
const headers = {
'Content-Type': 'application/pdf',
'Content-Disposition': `attachment; filename="${filename}"; filename*=UTF-8''${encodeURIComponent(filename)}`
};
const httpResp = awslambda.HttpResponseStream.from(responseStream, { statusCode: 200, headers });
- 例(Python/FastAPI): 事前に
HEADでS3メタ(Content-Type/Content-Disposition)を取得して反映する設計も有用
from urllib.parse import quote
from fastapi import FastAPI
from starlette.responses import StreamingResponse
app = FastAPI()
async def stream_s3():
... # S3からチャンク取得する非同期ジェネレータ
@app.get("/download")
async def download():
filename = 'report_2025.pdf'
headers = {
'Content-Type': 'application/pdf',
'Content-Disposition': f'attachment; filename="{filename}"; filename*=UTF-8''{quote(filename)}'
}
return StreamingResponse(stream_s3(), headers=headers)
注意:
-
filename*(RFC 5987)を併記すると非ASCII名でも安全に提示できます - 中継(Lambda→API Gateway)では最終的なヘッダはLambda側の指定が採用されるため、Lambdaで付与してください
Python(Web Adapter)— FastAPIでのS3中継(標準的手法)
Pythonでは AWS Lambda Web Adapter とFastAPIのStreamingResponseを組み合わせるのが標準的で扱いやすいです。公開S3から取得したバイナリをそのまま転送します。
※今回の仕様確認をしたいだけであれば、後述の標準ライブラリ版で十分です。
コード例(main.py):
import httpx
from fastapi import FastAPI
from starlette.responses import StreamingResponse
app = FastAPI()
S3_URL = "https://<bucket>.s3.<region>.amazonaws.com/path/to/object"
CHUNK_SIZE = 1024 * 1024
async def stream_s3():
async with httpx.AsyncClient() as client:
async with client.stream("GET", S3_URL) as r:
r.raise_for_status()
async for chunk in r.aiter_bytes(CHUNK_SIZE):
if chunk:
yield chunk
@app.get("/download")
async def download():
headers = {
"Content-Type": "application/octet-stream",
"Content-Disposition": "attachment; filename=\"file.bin\""
}
return StreamingResponse(stream_s3(), headers=headers)
Web Adapter の利用(Layerをアタッチして実行ラッパを有効化)が必要です。公式リポジトリの手順に沿って設定してください。
Web Adapter 導入ポイント(Python)
- Layer: 公式のLambda Adapter Layerを関数にアタッチ(リージョン/アーキ別の最新ARNはREADME参照)
- 執筆時点では以下
- 執筆時点では以下
- 環境変数(必須):
AWS_LAMBDA_EXEC_WRAPPER=/opt/bootstrapAWS_LWA_INVOKE_MODE=response_stream-
PORT=8080(またはAWS_LWA_PORT)
- 環境変数(任意):
-
AWS_LWA_ENABLE_COMPRESSION=true(圧縮を有効化) -
RUST_LOG=info(デバッグ用)
-
- フレームワーク: Flaskのジェネレータ/ FastAPIの
StreamingResponseでストリーム返却 - テスト: バイナリ取得は
curl -L --silent --show-error -o /tmp/test.binを推奨。ヘッダ確認はcurl -IでTransfer-Encoding: chunkedなどを確認。CloudWatch Logsで例外/タイムアウトも監視 - 重要(ハンドラ設定): Web AdapterをZip+マネージドランタイムで使う場合、Lambdaの「ハンドラ」は“起動スクリプト”を指します。例:
run.sh。lambda_function.lambda_handlerのようなモジュール.関数形式を指定すると、/opt/bootstrap: ... /var/task/lambda_function.lambda_handler: No such file or directoryのようなエラーになります。必ず起動スクリプト(後述)を用意し、ハンドラをそのファイル名(例:run.sh)に設定してください。- 重要(Pythonバージョン互換性): FastAPI(pydantic/pydantic-core を含む)は、LambdaのPython 3.14 では未対応のバイナリがあり、
ModuleNotFoundError: No module named 'pydantic_core._pydantic_core'が発生します。Lambda のランタイムは Python 3.12(または3.11)を選択してください。依存のビルドは使用ランタイムと同じメジャーバージョンで行う必要があります。 - 重要(CloudShellでのバージョン/アーキ整合): CloudShell は初期状態で Pythonが古い場合があります。
uvを導入して Python 3.12 を取得し、uv run -p 3.12でビルド・検証するとランタイムと整合が取れます。また、CloudShell(x86_64)と Lambda 関数・Web Adapter Layer のアーキテクチャ(x86_64/arm64)を一致させてください。macOS(arm64)でビルドした依存は Linux(x86_64/arm64)とABIが異なり失敗します。
- 重要(Pythonバージョン互換性): FastAPI(pydantic/pydantic-core を含む)は、LambdaのPython 3.14 では未対応のバイナリがあり、

テストではランタイム、レイヤーは以下のように設定しました。
重要なのはハンドラとレイヤーの設定です。
ランタイムは使いたいバージョンを選択(ローカルでビルドする場合はビルドしたバージョンに合わせる)
アーキテクチャは、コンソール上でコードを編集するだけなら任意、ローカルでビルドしてzipにして上げる場合はローカルのアーキテクチャと合わせる(Apple siliconのMacを使っている人は恐らくMacでビルドしたものはコケるので、面倒ですがEC2やCloudShell上でやるなどしましょう…。SAMを使えば多分うまくいきますが、SAMの説明が大変なのでここでは割愛します。)
レイヤーはちゃんと選んだアーキテクチャと互換のある方を設定しましょう。

デプロイ方法(uv利用、zipパッケージ想定):
pythonプロジェクトを既に扱ったことのある人向けです。
依存解決・パッケージングはローカルで uv を使います(Lambda 実行環境では uv は使いません)。
参考
余談ですが、Pythonの環境構築周りでuvは非常に便利なので使ったことがない方はこれを機にぜひ使ってみてください。
# CloudShell で uv を導入し、Python 3.12 を取得して使用する
curl -LsSf https://astral.sh/uv/install.sh | sh
uv python install 3.12
# 依存取得とベンドリング(uv + 3.12指定)
# dist/ 配下に依存を展開し、同ディレクトリにアプリ本体を配置してZip化します。
rm -rf dist
uv -p 3.12 pip install --target ./dist fastapi "httpx>=0.24" "starlette>=0.27" uvicorn
# 起動スクリプト(run.sh)を作成(ハンドラでこのファイル名を指定)
printf '%s\n' '#!/usr/bin/env sh' \
'export PYTHONPATH="/var/task/dist:${PYTHONPATH}"' \
'exec python3 -m uvicorn main:app --host 0.0.0.0 --port "${PORT:-8080}"' \
> run.sh
chmod +x run.sh
# パッケージング(Zipの“ルート”にファイルを配置すること)
# 注意: Lambda のハンドラはZipのルートにある実行ファイル名を参照します。
# dist/ 配下に run.sh を入れたまま Zip 化すると、ハンドラ `run.sh` が見つからず失敗します。
# そのため Zip のルートに `run.sh` と `main.py` を置いて圧縮してください。
cp main.py ./
cp run.sh ./
zip -r dist.zip main.py run.sh dist
# Lambda へアップロード(AWS CLI)
aws lambda update-function-code --function-name <your-func> --zip-file fileb://dist.zip
CloudShellでのmain.py配置方法(アップロード/作成時の注意)
- CloudShell のエディタで新規作成した場合は、保存先を
~/lambda-fastapi/main.pyにしてください(作業ディレクトリ直下)。 - ローカルから「アップロード」機能で転送した場合、既定ではホームディレクトリ直下(
~/)に保存されます。作業ディレクトリへ移動するには次を実行します。
# 作業ディレクトリへ移動(なければ作成)
mkdir -p ~/lambda-fastapi && cd ~/lambda-fastapi
# ホーム直下にアップロードされた main.py を作業ディレクトリへ移動
mv ~/main.py .
# 以降、run.sh作成→依存ベンドリング→Zip化の手順を続けます
printf '%s\n' '#!/usr/bin/env sh' \
'export PYTHONPATH="/var/task/dist:${PYTHONPATH}"' \
'exec python3 -m uvicorn main:app --host 0.0.0.0 --port "${PORT:-8080}"' \
> run.sh
chmod +x run.sh
Lambda 側の設定:
- ハンドラ:
run.sh(Zipのルート直下に配置したファイル名。サブディレクトリを含めない) - レイヤー: Lambda Web Adapter Layer をアタッチ
- 環境変数:
AWS_LAMBDA_EXEC_WRAPPER=/opt/bootstrap,AWS_LWA_INVOKE_MODE=response_stream,PORT=8080- 備考: 依存を
dist/にベンドリングしたため、run.sh内でPYTHONPATH=/var/task/distを設定してからuvicornを起動しています。 - ランタイム: Python 3.12(推奨)。3.14 を選ぶと pydantic-core のネイティブ拡張が見つからず起動に失敗します。
- アーキテクチャ: CloudShell(通常は x86_64)と Lambda のアーキ、Web Adapter Layer(X86/Arm64)を一致させること。異なるアーキでビルドした依存は読み込めません。
- 備考: 依存を
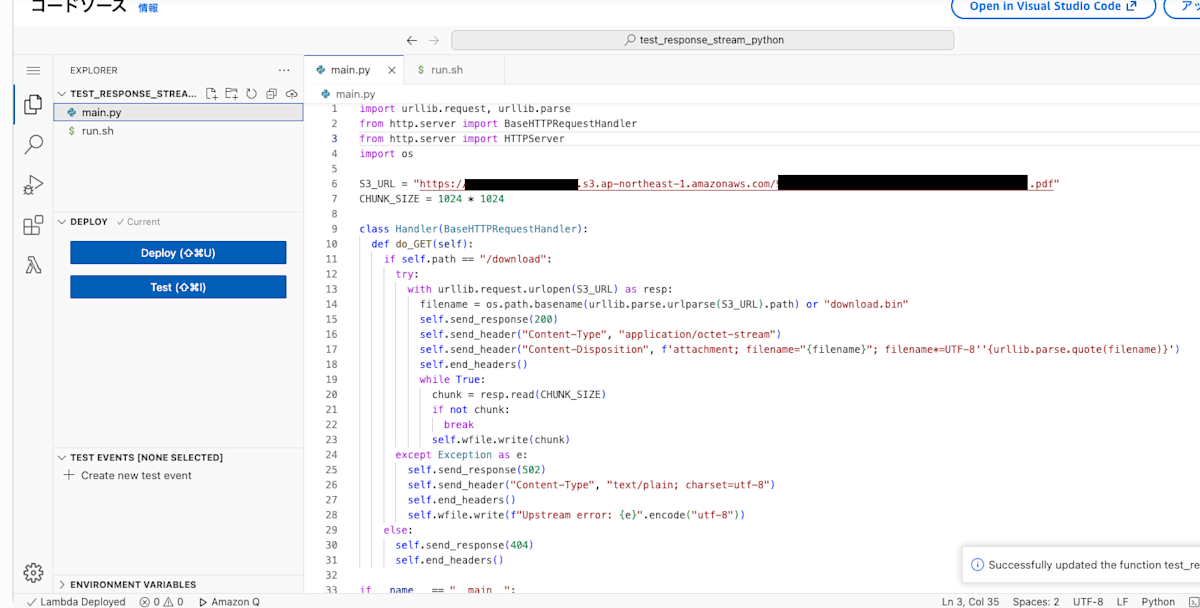
補足(コンソールのみで完結させたい場合の標準ライブラリ版):
外部依存を入れず、urllib.request と簡易HTTPハンドラでストリーミング転送も可能です(Layer/環境変数は同様)。ソースは1ファイルをコンソールに貼り付けるだけで動作します。
今回はダウンロードの確認をしたいだけなのでこちらで十分です。
# 標準ライブラリのみの簡易版
import urllib.request, urllib.parse
from http.server import BaseHTTPRequestHandler
from http.server import HTTPServer
import os
S3_URL = "https://<bucket>.s3.<region>.amazonaws.com/path/to/object"
CHUNK_SIZE = 1024 * 1024
class Handler(BaseHTTPRequestHandler):
def do_GET(self):
if self.path == "/download":
try:
with urllib.request.urlopen(S3_URL) as resp:
filename = os.path.basename(urllib.parse.urlparse(S3_URL).path) or "download.bin"
self.send_response(200)
self.send_header("Content-Type", "application/octet-stream")
self.send_header("Content-Disposition", f'attachment; filename="{filename}"; filename*=UTF-8''{urllib.parse.quote(filename)}')
self.end_headers()
while True:
chunk = resp.read(CHUNK_SIZE)
if not chunk:
break
self.wfile.write(chunk)
except Exception as e:
self.send_response(502)
self.send_header("Content-Type", "text/plain; charset=utf-8")
self.end_headers()
self.wfile.write(f"Upstream error: {e}".encode("utf-8"))
else:
self.send_response(404)
self.end_headers()
if __name__ == "__main__":
# Web Adapter はこのHTTPサーバ(:8080)にプロキシします
port = int(os.environ.get("PORT", "8080"))
server = HTTPServer(("0.0.0.0", port), Handler)
server.serve_forever()
起動スクリプト(ハンドラに指定):
#!/usr/bin/env sh
exec python3 -u main.py
デプロイのポイント:
-
ハンドラ:
run.sh(上記の起動スクリプト名) -
Zip で
main.pyとrun.shを含める(chmod +x run.sh済み)- また、zipにしなくても、自分の手元ではLambdaのコンソールからファイルを作るだけでも確認できました。main.pyとrun.shを下記の要領で作ってあげればよいです。
- また、zipにしなくても、自分の手元ではLambdaのコンソールからファイルを作るだけでも確認できました。main.pyとrun.shを下記の要領で作ってあげればよいです。
-
レイヤー/環境変数は FastAPI 例と同様

API Gateway(REST API)のリソース/メソッドを /download に向ければ、チャンクでダウンロードされるはずです。クライアント側の確認例(冗長出力を抑制):
curl -L --silent --show-error -o big.bin "https://<api-id>.execute-api.<region>.amazonaws.com/download"
wc -c big.bin
curl -I "https://<api-id>.execute-api.<region>.amazonaws.com/download"
期待できる効果と観点
- 大きいコンテンツの送出: 従来の固定上限(単一レスポンスボディサイズ)を避けつつ配信可能
- メモリ消費の平準化: 生成・読み取りしたチャンクを逐次送出
- ユーザー体験の改善: 早期にダウンロードが開始され、全量完了を待たずに受信が進む
制約・注意点(実務での落とし穴)
- ランタイム対応差: Node.jsはネイティブ、Python等はWeb Adapterの導入が必要
- タイムアウト: Lambda実行時間上限内で送出完了が必要(長時間配信は注意)
- ネットワーク途中経路: 一部のプロキシ/CDN/クライアントがチャンク転送に制約を持つことあり
- VPC接続: 関数をVPCに接続するとデフォルトでインターネットへ出られないため、公開S3へ到達するにはNAT構成、またはS3向けVPCエンドポイントの利用が必要
- ヘッダ/圧縮: 事前に
Content-Lengthを確定しづらい。圧縮やContent-Encodingの扱いは検証必須 - ダウンロードヘッダ:
Content-Disposition: attachment; filename="..."を付与するとブラウザ保存時の名称を制御可能 - 事前メタ取得: サイズやタイプが必要な場合はS3に対して
HEADで取得→ヘッダとして返す設計も有用 - キャッシュ戦略: ストリーミングとキャッシュ制御の組み合わせは要検討(CloudFront経由の場合など)
- エラーハンドリング: 途中失敗時の再開や整合性(部分取得)をどう扱うか
REST API作成手順
検証用なので簡素な設定でコンソールから作ります。
- APIを作成: API Gateway コンソールで「REST API」を新規作成
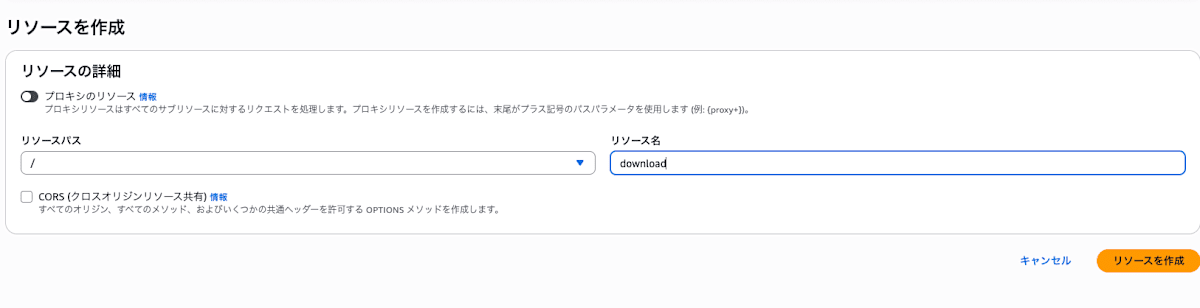
- リソース追加: 例として
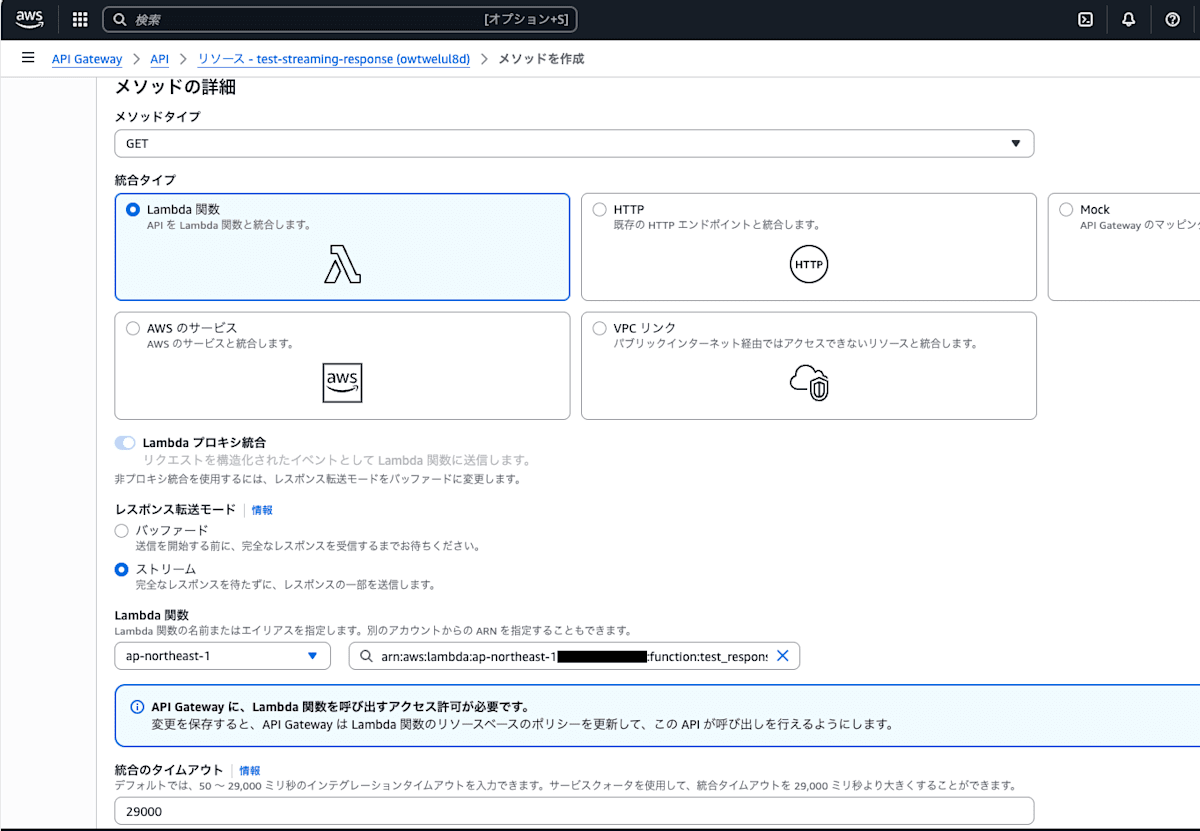
/downloadリソースを作成 - メソッド追加:
GETメソッドを作成し、統合タイプをLambda プロキシに設定、対象のLambda関数を指定 - 統合リクエスト: 「Response transfer mode」を
Streamに設定(コンソールのIntegration設定画面) - 統合レスポンス: 必要に応じてヘッダ(
Content-Type等)をパススルー、チャンク転送を阻害する設定がないことを確認 - デプロイ: 新規または既存ステージへデプロイして、Invoke URLを取得
- 動作確認:
curl -Iでヘッダ確認、実体はcurl -L --silent --show-error -o /tmp/test.binで取得(後述の確認例)。またはブラウザでURLにアクセス。
デプロイ手順(具体例)
コンソールでの手順:
※初回想定です。
- 作成したAPIを選択して、「リソース」→「APIをデプロイ」→
新しいステージでステージを作成(test、など)してデプロイ
- 2回目以降はここで作成したステージを選択すればOK
- 「ステージ」からURLをコピー(例:
https://<api-id>.execute-api.<region>.amazonaws.com/test) - テスト:
https://.../test/downloadに対してcurl -Iでヘッダ確認、実体取得はcurl -L --silent --show-error -o /tmp/test.binを利用

CLIでの手順(bash、既存APIにGET /downloadを追加済みの前提):
# API IDとステージ名を設定
API_ID=<your-api-id>
STAGE=prod
# ステージ作成(初回のみ)
aws apigateway create-deployment --rest-api-id "$API_ID" --stage-name "$STAGE" --description "Initial streaming deployment"
# 変更反映時の再デプロイ(統合やメソッド変更後)
aws apigateway create-deployment --rest-api-id "$API_ID" --stage-name "$STAGE" --description "Update streaming integration"
# 動作確認
curl -I "https://$API_ID.execute-api.<region>.amazonaws.com/$STAGE/download"
curl -L --silent --show-error -o /tmp/test.bin "https://$API_ID.execute-api.<region>.amazonaws.com/$STAGE/download"
補足:
- 「Response transfer mode: Stream」の設定はメソッド統合の「Integration Request」で変更→保存後に必ず再デプロイが必要
- ステージ変数は本構成では不要(Lambdaプロキシ統合+直指定のため)。環境差分を切り替える場合は活用可
検証結果
実際にS3に10MBを超えるサイズのファイルを上げて、そのパスのファイルをダウンロードできるか確認したところ、これら全ての方法でブラウザ、コマンド両方でダウンロードできることを確認しました。
実際にこの方法でAPI Gatewayの制限を上回るサイズのファイルをダウンロードできそうです。
また、未検証ですがLambdaのタイムアウト上限を上げておけば、API Gatewayのこれまでの制限だった29秒を超えるダウンロード時間のファイルも恐らくダウンロードできるかと思います。
もっともお手軽なのはNodeですね。ただ、LWAを使えばPythonでも標準ライブラリのみで完結させることも可能なのはちょっと驚きました。
まとめ
API GatewayのStreaming Response対応によって、これまでネックだったレスポンスの制限を回避する方法が一つ見えてきました。
巷ではLLMの回答を受けるユースケースばかり見ますが、単純に大きなファイルをAPI Gatewayを経由して扱う必要がある場合の考えうる方法が増えたということもきっとどなたかの役に立つことでしょう。
一応注意事項としては、これはあくまでもレスポンスのストリーミングなので、ダウンロードでは制限を回避できてもアップロード(POSTやPUT)では制限を回避できません。
API Gatewayを介したファイルアップロードは10MBのままなのでご注意ください。
余談
この記事はCopilot Chatの助けを存分に得ながら作成しました。
他にもいくつかZennに記事を書いてリポジトリ管理しているので、口調や考え方などは他記事を参考にしてもらっています。
もちろん丸投げじゃなくて、ある程度内容を整備してもらって自分で検証した結果を記載しています。
記事を書くのは単純に文章を作るのが大変なので、労力がかかる部分をうまく助けてもらいつつ、記事作成のハードルを下げて新しい記事を書きやすくなるといいなと思っています。
-
みすてむず いず みすきーしすてむず とは、オープンソースのプラットフォームMisskeyのインスタンスのひとつで、主にITに関わる人が参加しています。最近はXよりもそちらに入り浸っています。 ↩︎
-
いわゆる「予選落ち」とか「pre:invent」とか言われているやつです。 ↩︎
-
いろんなAIモデルをAWSの統合APIを通じて利用できるようにしているサービス。AWSがAnthropicに出資していることもあり、Claudeの新バージョンの追加が早い。執筆時点ではGPTやGeminiはOSS版しかなさそう。 ↩︎
Discussion