Redshift + Laravel でお安くBIツールを作る
株式会社Fusicのおかべです。
Fusicアドベントカレンダー8日目として、BIツールを使わずにデータを可視化する方法で記事を書きます。
数万人規模のユーザーに対してデータを可視化した画面を見せたいけども費用は抑えたい、という方などに参考にしてほしいです。
内容まとめ
- 大量ユーザーに見せる画面の場合、BIツールは高くつくよ
- RedshiftとLaravelを使えばある程度データの可視化はできるので、費用を抑えたいときには選択肢の一つになるよ
Quicksightとは
AWSのBIツールといえばQuicksightです。Quicksightを使うと比較的容易にデータの可視化が実現できます。
Quicksihgtのチャート例↓
また、表示だけであればQuicksightでチャートを作って、それをiframeでアプリケーションに組み込むこともできます。また、セレクトボックスで動的に値を変更してチャートを表示することもできますし、認証したユーザーに対して個別のチャートを表示することもできます。
iframeを利用したアプリケーションの例↓
お金があるなら大人しくQuicksightを使うのが吉です。
Quicksightは大量ユーザーが使用すると料金がすごいことになる
Quicksightは「ユーザーそれぞれにアカウントを発行して作成者/閲覧者の権限を与える」パターンと、「ユーザーをプロビジョニングせずに不特定多数に公開する」パターンで料金が異なります。
数万人規模となるとユーザーを管理するのは容易ではないので今回は後者のユーザーをプロビジョニングしないパターンを考えます。
この場合、リーダーセッションキャパシティーというやつになり、料金体系は以下のようになります。
| タイプ | 容量 (セッションの数) | 料金 | 超過料金/追加セッション |
|---|---|---|---|
| 1 か月あたりのプラン | 500/月 | 250 USD/月 | 0.50 USD |
| 年間プラン | 50,000/年 | 20,000 USD/年 | 0.40 USD |
| 年間プラン | 200,000/年 | 57,600 USD/年 | 0.28 USD |
| 年間プラン | 400,000/年 | 96,000 USD/年 | 0.24 USD |
| 年間プラン | 800,000/年 | 162,000 USD/年 | 0.20 USD |
| 年間プラン | 1,600,000/年 | 258,000 USD/年 | 0.16 USD |
| 年間プラン | 3,000,000+/年 | お問い合わせ |
セッションの定義は公式のFAQページに詳しく書いてあります。簡単にまとめると、1セッションは30分で30分経ったら自動的に更新(新しいセッションが始まる)。バックグラウンドで開きっぱなしにしている場合などはセッションにはカウントされない、みたいな感じです。
ちょっと試算してみましょう。
例えば、一人のユーザーが1週間に2回、1回30分以内でチャートを表示する場合を考えます。
このとき、1年間(52週)だと一人のユーザーの年間あたりのセッション数は 52*2=104 セッションになります。
試算1. ユーザーが2000人の場合
合計セッションは 104*2000=208000 セッション/年 です。200,000/年のプランで契約して追加セッション分は超過料金で払うとすると、
57,600 USD + 8000*0.28 USD = 59840USD/年 ≒ 897万円/年 (1USD=150円で計算)
2000人が閲覧するチャートは年間900万円くらいかかることになります。
試算2. ユーザーが20万人の場合
合計セッションは 104*200000=20800000 セッション/年 です。一番上のプランである3,000,000+/年を軽く超えてしまうので問い合わせをしないといけない内容になりますw
料金がボリュームディスカウントである程度安くなったとしても、2000万セッションだと2,000,000USD/年 ≒ 2億円/年 くらいはしそうですね…
BIは少数の人間がデータ分析をするのには適していますが、それを外部に公開する、ましては不特定多数に公開しようとすると結構お金がかかります。
データの可視化を安く済ませる方法
これを安く済ませる方法は少なくとも2つはあると思っています。
- Quicksightで図を作成し、PDF化して配布する
- Quicksightを使わない
2番目は元も子もない話ですが、Quicksightを使うにしてもデータウェアハウスとしてS3やRedshiftなどは準備をしているはずなので、それに対して自分でアプリケーションを作ってクエリを投げてチャートで表示したらいいやん、という話です。
今回はそれを実現できるのか検証したいと思います。
AWSコンソールからRedshiftをたてる
とりあえずRedshiftを立ててみます。
検証用なので冗長性などは考えず、セキュリティもガバガバです。またサーバレスではなくクラスターを立てる形で行きます。
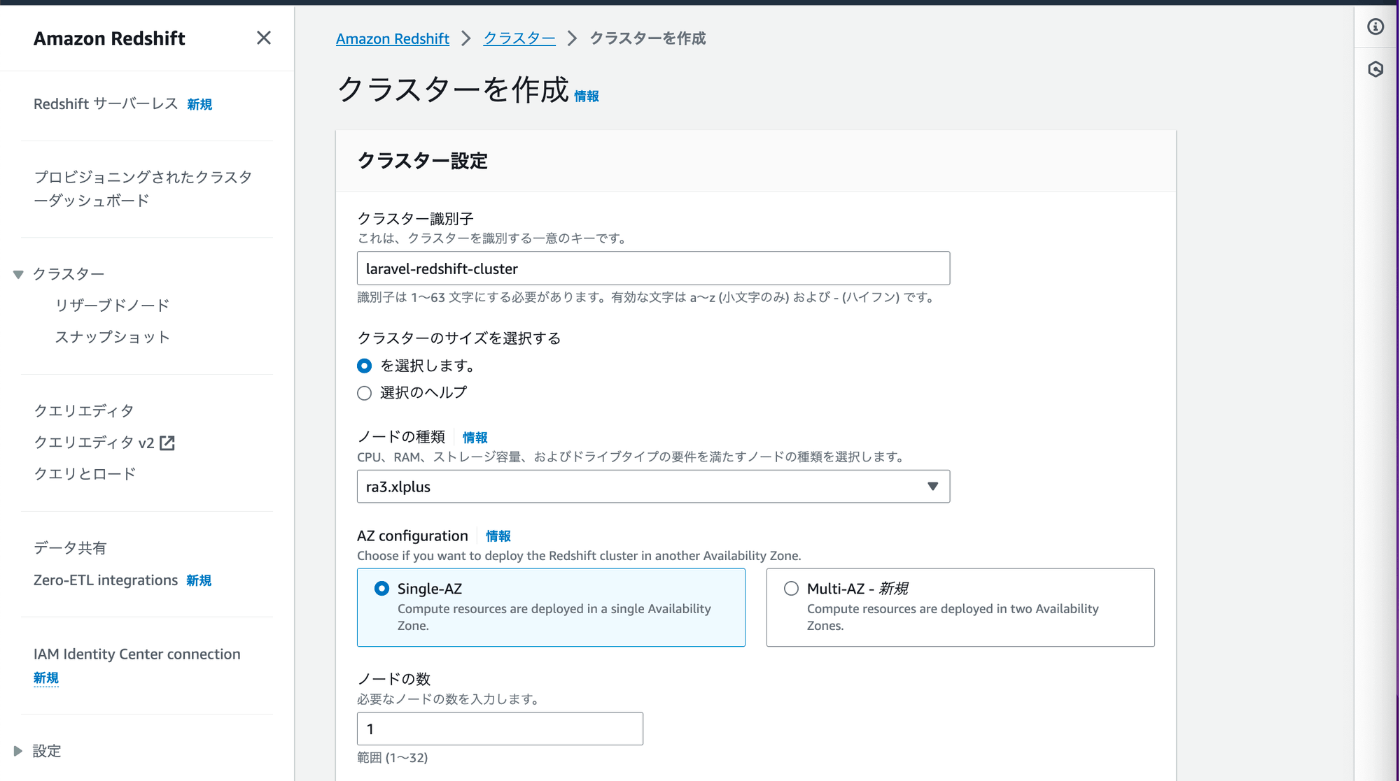
設定したパラメータは以下になります。
| クラスター識別子 | laravel-redshift |
|---|---|
| ノードの種類 | ra3.xlplus |
| AZ configuration | Single-AZ |
| ノードの数 | 1 |
| サンプルデータ | ロードしない |
| 管理者ユーザー名 | 任意 |
| 管理者ユーザーパスワード | 任意 |
| 関連付けられた IAM ロール | IAMロールの管理 > IAMロールを作成 > 任意のS3バケット で作成したロール |
| 追加設定 > ネットワークとセキュリティ | [パブリックにアクセス可能] をオンにする をチェック |
| 追加設定 > データベース設定 > データベース名 | dev |
| 追加設定 > データベース設定 > データベースポート | 5439 |
これでRedshiftが立ちました。
外部に公開している状態なので、ID/PWとエンドポイントがバレたら良くないです。セキュリティは適宜調整してください。
コンソールからテーブルまで作っておきましょう。
クエリエディタv2に入ります。

先ほど作成したクラスター名が表示されているのでクリックします。
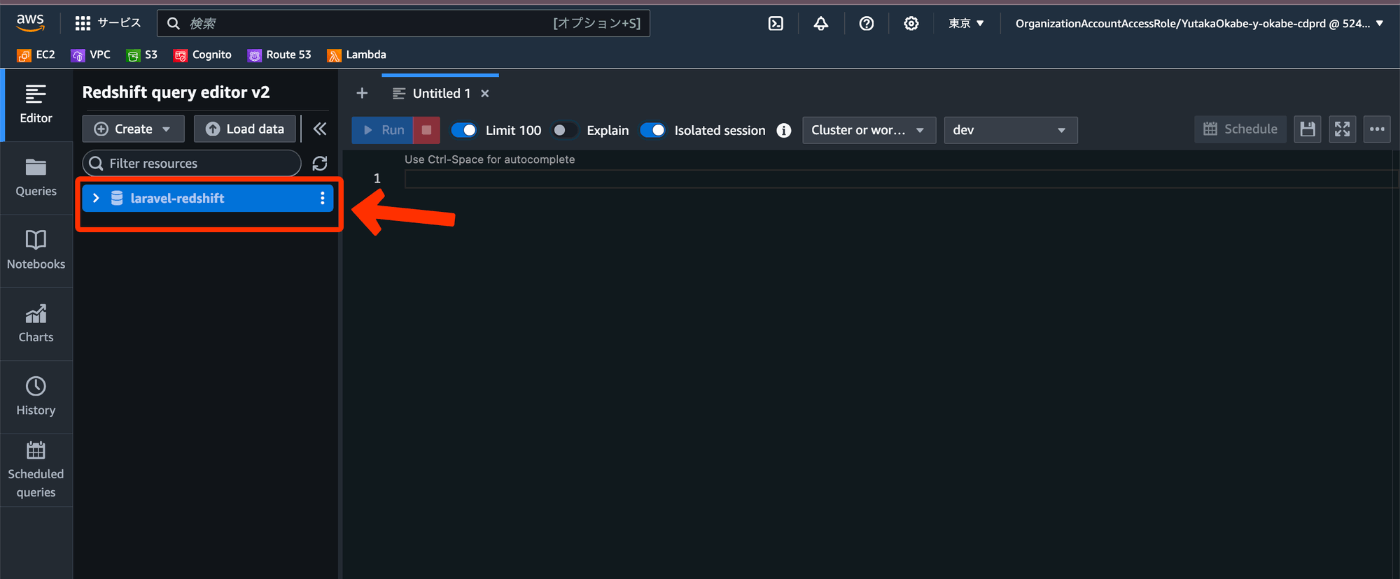
接続を作成する必要があるので、 Database user name and password を選択して、先ほど設定した管理者ユーザー名と管理者ユーザーパスワードでdevデータベースに入れるようにしてください。
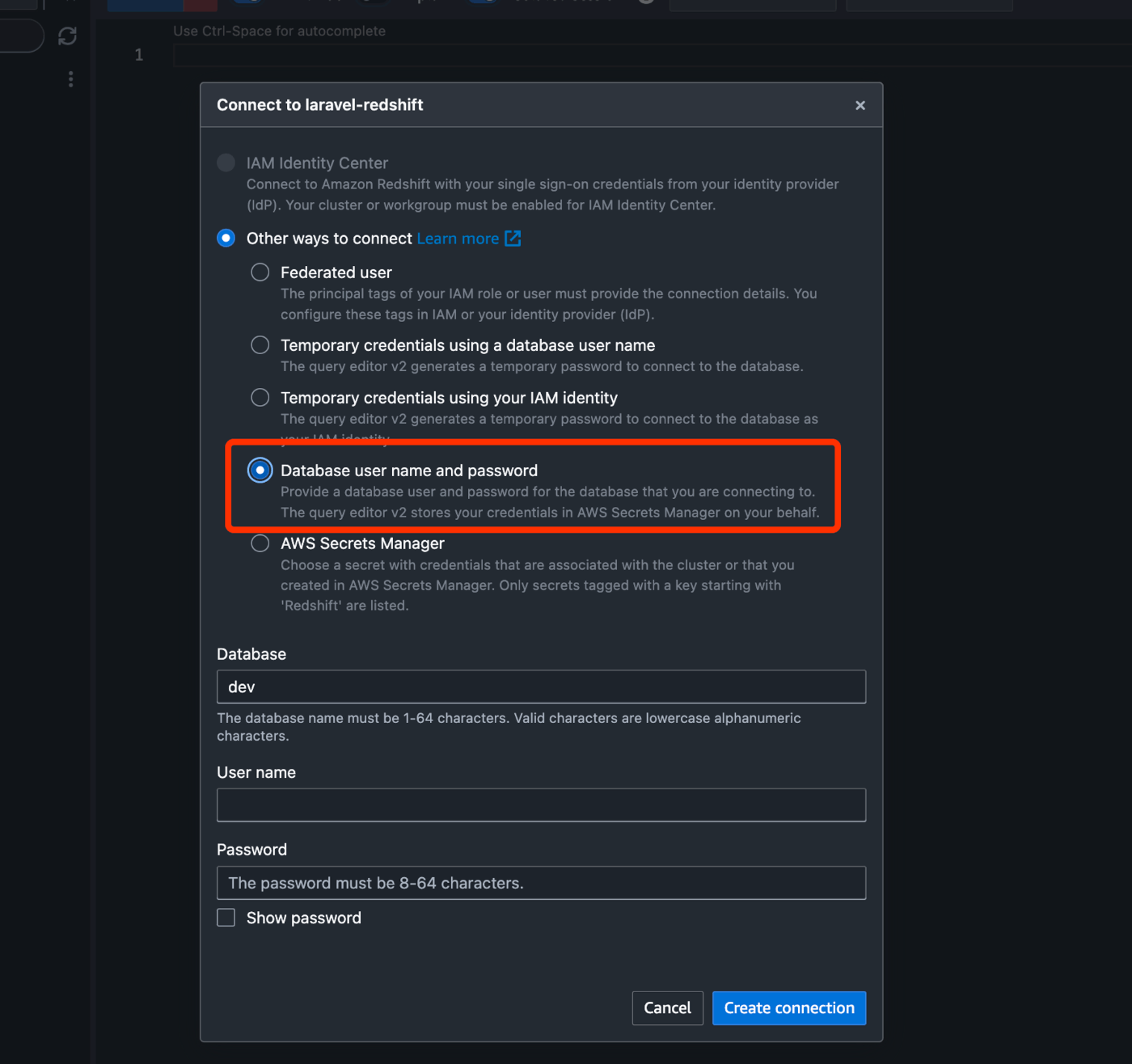
うまくいくとdevデータベースに入れます。現状テーブルは何もありません。
usersテーブルを作成しておきましょう。
右上の接続がdevになっていることを確認してテーブル作成のSQL入れるとテーブルが作成できます。
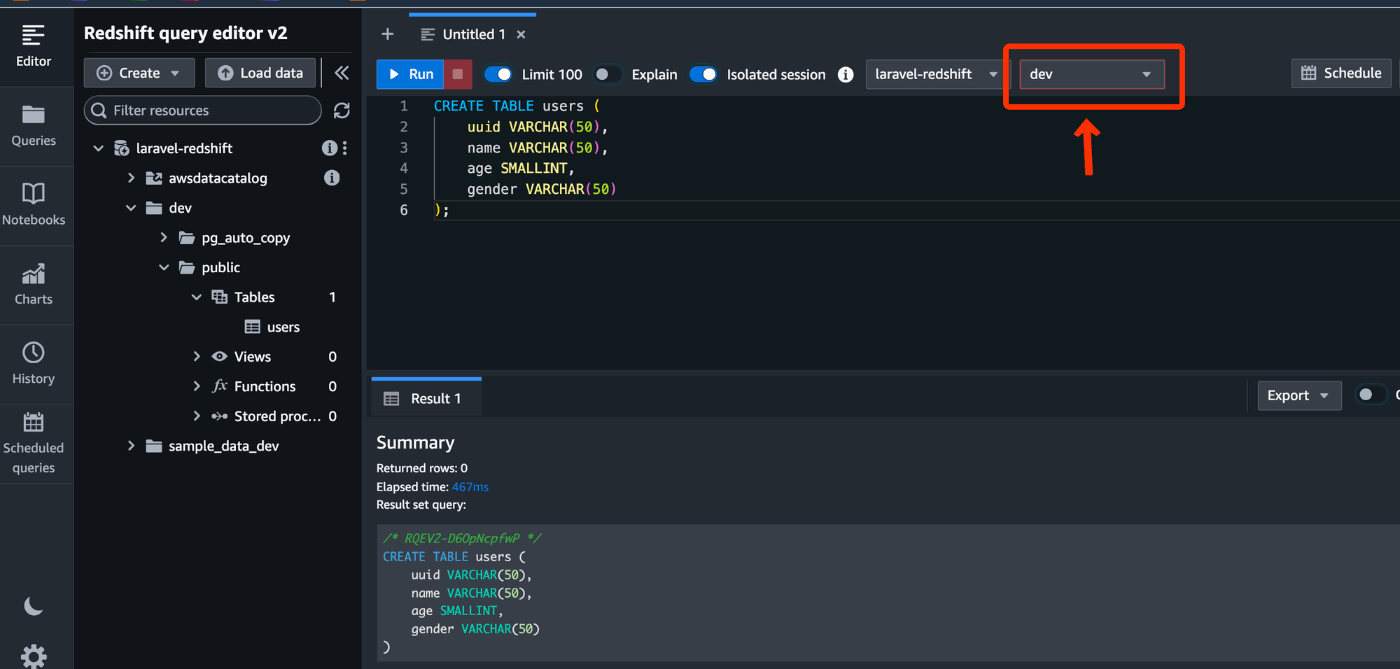
CREATE TABLE users (
uuid VARCHAR(50),
name VARCHAR(50),
age SMALLINT,
gender VARCHAR(50)
);
ここにデータを投入していきますが、集計用ということでとりあえず100万レコードくらいのデータを突っ込んでみます。
データ投入の方法はいろいろありますが、今回はせっかくLaravelを使うので、Laravelのコマンドで100万レコードあるcsvファイルを作成してS3にアップロード → RedshiftでS3Copyコマンドでデータ投入 という形にしたいと思います。記事の本筋と外れるのでやり方はおまけに置いておきます。
LaravelとRedshiftを繋ぐ
Laravelを手元で準備します。この時のバージョンは10で、welcomeページが見えてる状態までは作ってあるとします。
またDB接続用のドライバー、特にRedshiftはPostgresqlベースなので pdo pgsql pdo_pgsql らへんは入れておいてください。
まずはenvに設定を追加します。
DB_CONNECTION=redshift
REDSHIFT_HOST=laravel-redshift.cvjtnlesspr8.ap-northeast-1.redshift.amazonaws.com
REDSHIFT_PORT=5439
REDSHIFT_DATABASE=dev
REDSHIFT_USERNAME={先ほど設定した管理者ユーザー名}
REDSHIFT_PASSWORD={先ほど設定した管理者ユーザーパスワード}
REDSHIFT_HOST には先ほどのRedshiftコンソールのエンドポイントからポートとDB名を除いた値を設定してください。
次に config/database.php にRedshfitに繋ぐための設定を追記します。
'connections' => [
'redshift' => [
'driver' => 'pgsql',
'host' => env('REDSHIFT_HOST'),
'port' => env('REDSHIFT_PORT'),
'database' => env('REDSHIFT_DATABASE'),
'username' => env('REDSHIFT_USERNAME'),
'password' => env('REDSHIFT_PASSWORD'),
'charset' => 'utf8',
'prefix' => '',
'search_path' => 'public',
'sslmode' => 'prefer',
],
それではさっそくクエリを投げてみましょう。めんどくさいのでweb.phpに全部書きます。良い子は真似しないでね。
Route::get('/', function () {
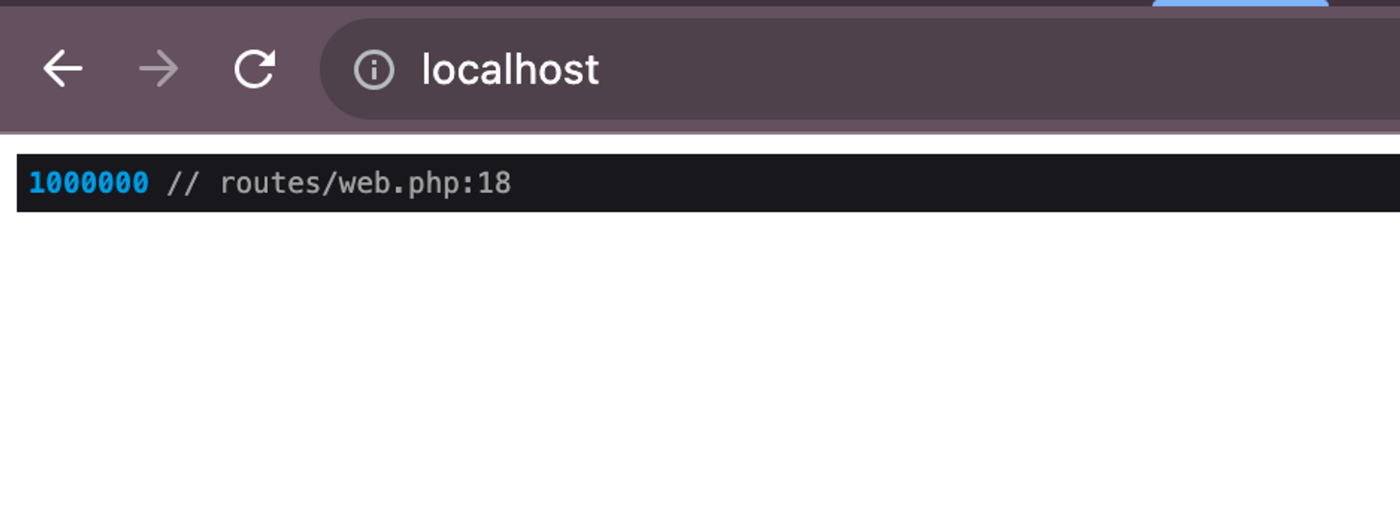
dd(User::query()->count());
return view('welcome');
});
取れてそうです。Eloquentがそのまま使えるのがありがたいですね。
チャートで表示
さて、あとはフロントの話になるのでさくっと終わらせましょう。クエリの結果をChart.jsでグラフにしてみます。
今回はユーザーの男女比率と年齢層のヒストグラムを作ってみます。
考え方としてはRedshift側に集計処理を持たせてフロントエンドはそれをライブラリで表示するだけです。
Route::get('/', function () {
$genderCounts = User::selectRaw('gender, COUNT(*) as count')
->groupBy('gender')
->get();
$ageCounts = User::selectRaw('age, COUNT(*) as count')
->groupBy('age')
->orderBy('age')
->get();
return view('welcome', compact('genderCounts', 'ageCounts'));
});
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Laravel Redshift</title>
<script src="https://cdn.jsdelivr.net/npm/chart.js"></script>
</head>
<body>
<div style="max-width: 600px; display: flex;">
<canvas id="genderChart"></canvas>
<canvas id="ageHistogram"></canvas>
</div>
<script>
var genderCounts = @json($genderCounts);
var ageCounts = @json($ageCounts);
// 性別比率の円グラフ
var genderCtx = document.getElementById('genderChart').getContext('2d');
var genderChart = new Chart(genderCtx, {
type: 'pie',
data: {
labels: genderCounts.map(g => g.gender),
datasets: [{
label: 'Gender Ratio',
data: genderCounts.map(g => g.count),
backgroundColor: ['blue', 'pink', 'green'],
}]
}
});
// 年齢層のヒストグラム
var ageCtx = document.getElementById('ageHistogram').getContext('2d');
var ageHistogram = new Chart(ageCtx, {
type: 'bar',
data: {
labels: ageCounts.map(a => a.age),
datasets: [{
label: 'Age Distribution',
data: ageCounts.map(a => a.count),
backgroundColor: 'rgba(0, 123, 255, 0.5)',
}]
},
options: {
scales: {
y: {
beginAtZero: true
}
}
}
});
</script>
</body>
</html>
実行してみます。
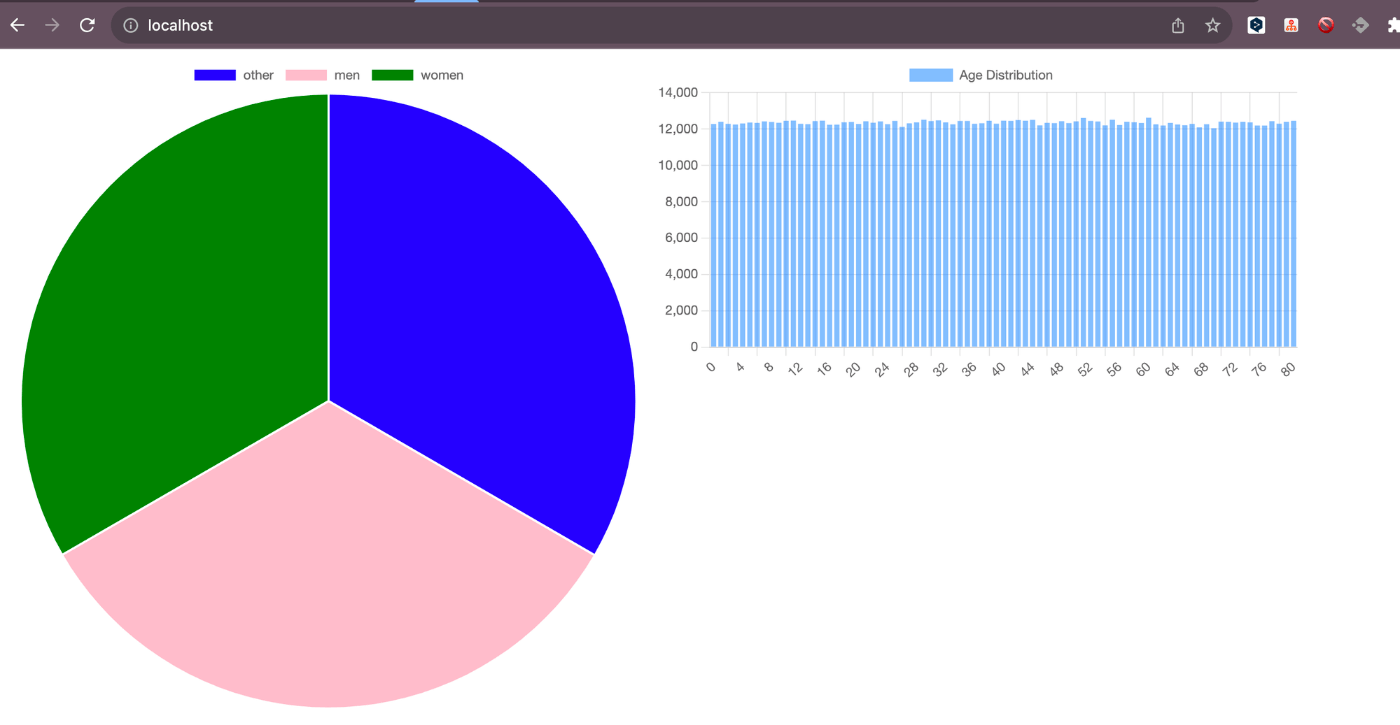
表示できました。性別は綺麗に3等分くらいになってるし、ヒストグラムは0~80歳までの各年齢1.2万件くらいなのでfakerがちゃんとランダムにデータ作ってくれてそうですね。
ちなみにですが、Redshiftのクエリは初回実行は結構重く、2回目からはキャッシュが効くので速くなります。
手元の環境だと100万件に対するチャートの表示スピードは2回目以降は2秒くらいでした。
もちろんネットワーク速度やマシンスペック、Redshfitのチューニング次第でもっとスピードを出すことは可能だと思いますが、まぁ実用もできるスピードではないでしょうか。
まとめ
今回はLaravelとRedshiftでお安くBIツールっぽいものを作ってみました。
もちろんエンジニアじゃないと触れない点でBIツールよりかは圧倒的に劣りはするんですが、金額がユーザー数に比例して増えていくBIツールに比べて、今回の場合は基本的にデータ可視化部分はアプリケーションのホスト代だけです。なんと家計に優しい。
Fusicアドベントカレンダーまだまだ続くのでお楽しみに!
おまけ
① 開発環境どうする問題
開発環境からAWSに対してクエリを投げるのは大変だしお金もかかるのでローカルの環境を作りたいと思いますよね。
僕もそう思ってとりあえずLocalstackをみるとRedshiftあるじゃん!と思って導入してみました。
しかし、、、LocalstackのRedshfitは無料版だとクラスターとDBまでは作れますが、テーブルを作ることができないのです。。
以下のExecuteStatementの部分になります。Oh,,商売上手,,
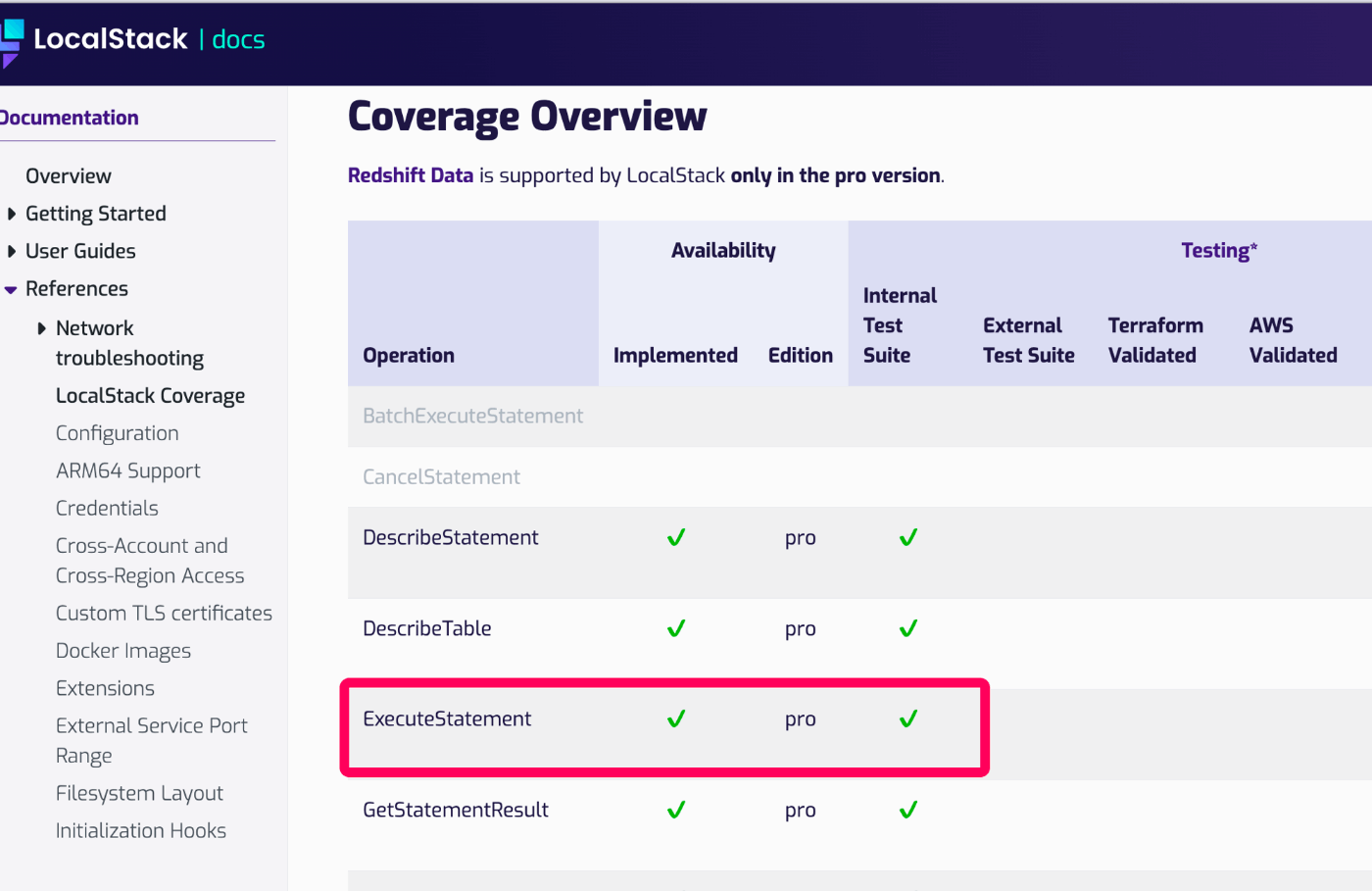
データを投入ができないので無料だと開発環境では使えないですね。
他にコンテナとしてRedshift互換のものを提供してるライブラリ等もめぼしいのがないので、とれる選択肢としてはLocalstackに課金するか、開発環境でもAWS使うかになります。
結局、僕はAWSを使う方を選択しました。理由は以下です。
- Localstack有料版が月額$35で結構お高い
- Localstackはある程度の確認はできるけど、AWS Redshiftの完全互換ではないので最終的にはAWS上で動作確認する必要はある
- パフォーマンスのチューニングなどはAWS上で結局行う必要がある
- AWS RedshfitはVPC内に設置するので、セキュリティーグループで自分のIPなどに接続を制限すれば最低限のセキュリティは保てる
RedshiftはPostgres互換と聞いていたので開発環境はいっそPostgresだけにしてしまおうかとも思いましたが、Postgresでは動作するけどRedshiftで動作しないクエリが結構あるみたいなのでやめました。
一方でRedshiftで動作するクエリは基本的にはPostgresでも実行できるので、テストはPostgresコンテナを立てれば良いという考えです。
もしこの辺の開発環境でいい方法があったら教えてもらえると嬉しいです。
② Redshiftに大量データを投入
Laravelのコマンドで100万件のcsvを作成してS3にアップロード → RedshiftでS3Copyコマンドでデータ投入 までを作ります。
aws/aws-sdk-php を入れておいてください。
まずはS3にバケットを用意するのと、SDKが使えるようにS3にアップロードする権限を持ったIAMユーザーを発行しておいてください。
それではPHP側の作業に移ります。
100万件の適当なデータを作るのが面倒なので、そんな時はfakerにお任せしましょう。Factoryを以下のように作成します。
<?php
namespace Database\Factories;
use Illuminate\Database\Eloquent\Factories\Factory;
class UserFactory extends Factory
{
public function definition(): array
{
return [
'uuid' => $this->faker->uuid(),
'name' => $this->faker->name(),
'age' => $this->faker->numberBetween(0, 80),
'gender' => $this->faker->randomElement(['men', 'women', 'other']),
];
}
}
モデルから使用するので忘れずにモデルも作成しましょう。
<?php
namespace App\Models;
use Illuminate\Database\Eloquent\Factories\HasFactory;
use Illuminate\Database\Eloquent\Model;
class User extends Model
{
use HasFactory;
}
これで準備が整ったので100万行のcsvを作成するコマンドを作ります。
ローカルにデータを保持しなくていいように factory()->make() で作成します。
<?php
namespace App\Console\Commands;
use App\Models\User;
use Aws\S3\S3Client;
use Illuminate\Console\Command;
class ExportUsersToS3 extends Command
{
private S3Client $s3client;
protected $signature = 'export:users';
protected $description = 'Create and Export Users to S3 as CSV';
public function __construct()
{
parent::__construct();
$this->s3client = $this->client();
}
public function handle()
{
$this->info('export_user_csv_to_s3 start');
ini_set('memory_limit', '-1');
ini_set('max_execution_time', '0');
for ($i = 0; $i < 1000000; $i++) {
$users[] = array_values(User::factory()->make()->toArray());
}
$headers = array_keys(User::factory()->make()->getAttributes());
// csv作成
$file = fopen(storage_path('app/tmp/users.csv'), 'w');
fputcsv($file, $headers);
foreach ($users as $row) {
fputcsv($file, $row);
}
fclose($file);
// S3にアップロード
try {
$this->s3client->putObject([
'Bucket' => 'redshift-data-csv',
'Key' => 'users.csv',
'Body' => fopen(storage_path('app/tmp/users.csv'), 'r')
]);
$this->info('finish successfully');
return Command::SUCCESS;
} catch (\Exception $e) {
$this->error($e->getMessage());
return Command::FAILURE;
}
}
private function client(): S3Client
{
return new S3Client([
'region' => 'ap-northeast-1',
'credentials' => [
'key' => 'xxx',
'secret' => 'yyy',
],
]);
}
}
アップロードできました。カラム数が少ないので100万レコードでも61MBしかないんですね。
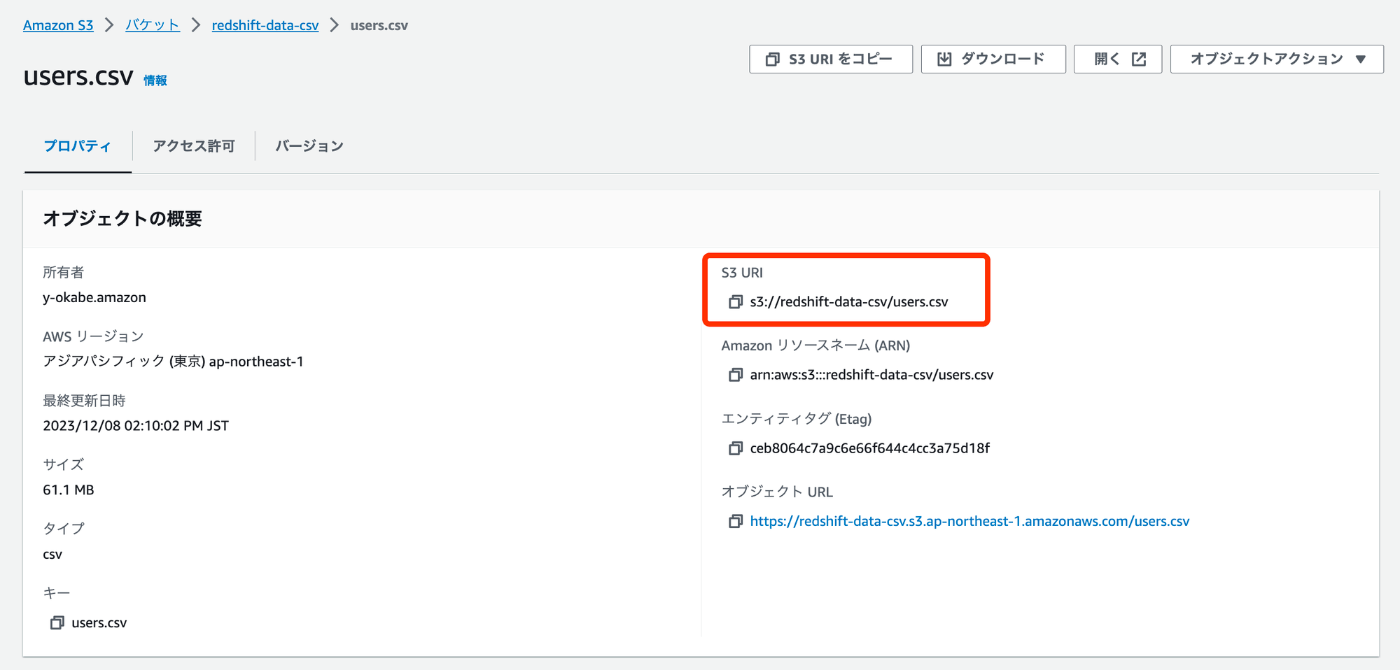
S3URIをコピーしておきます。
Redshiftのクエリエディタv2に行きます。
左上のLoadDataをクリックするとS3からデータをロードするための設定をするポップアップが出てきます。
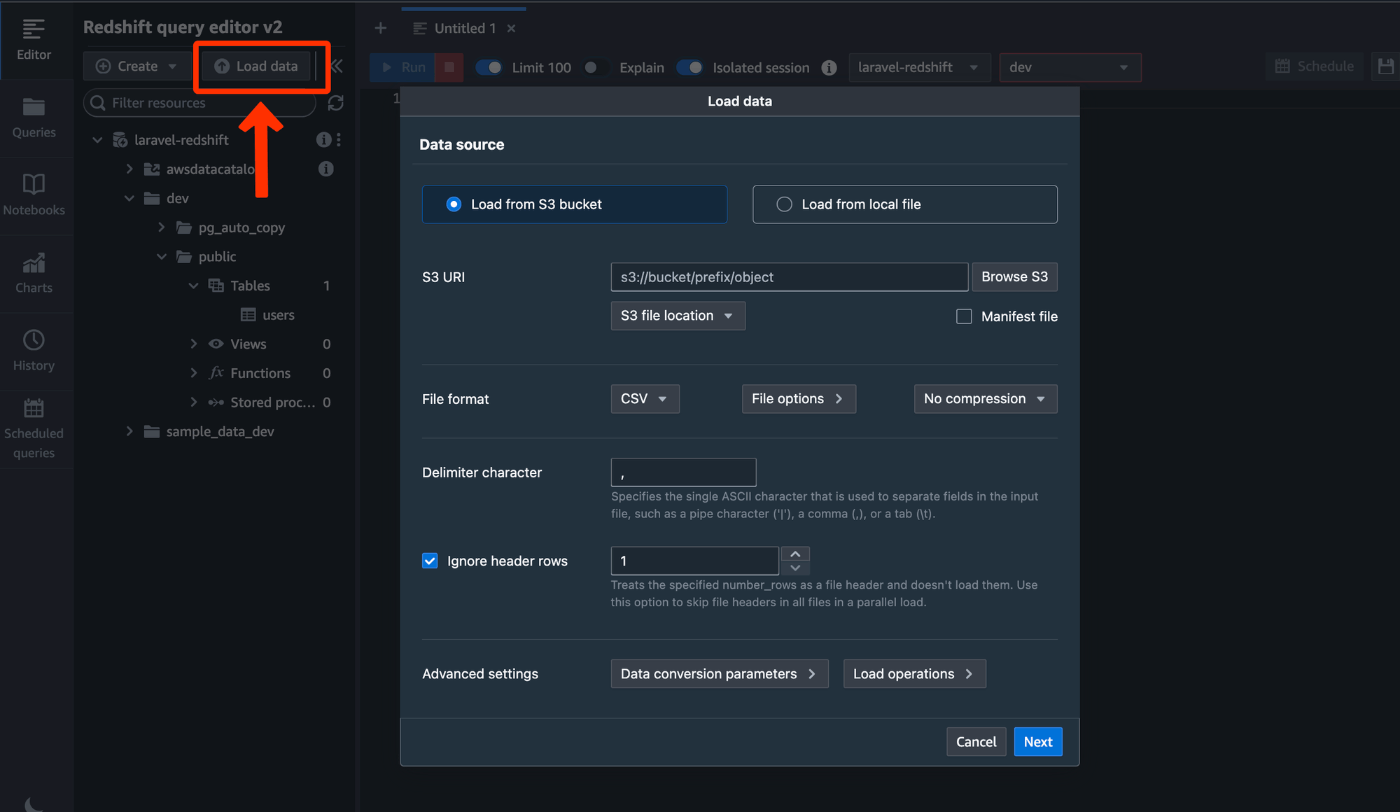
ここに先ほどのS3URIを貼り付け、リージョンを選択します。それ以外はデフォルトのままでNextをクリック。

ロードするテーブルを選択します。IAM roleはクラスターを作成する時に作成したIAMロールで構いませんので選択してLoadをクリックします。
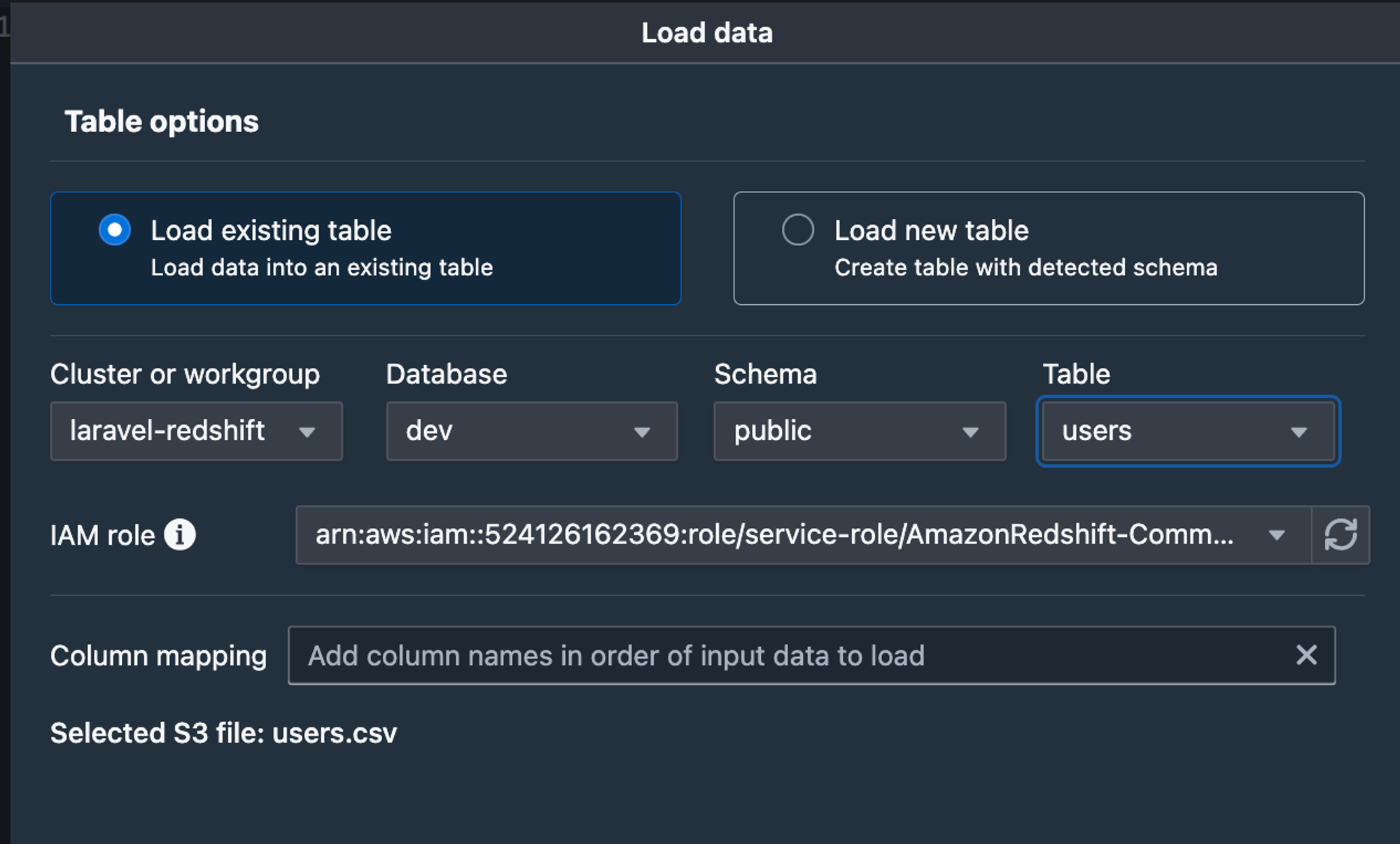
Loadをクリックするとコマンドが作成され自動的に実行されます。設定に問題がなければ20sほどでロードが完了しました。
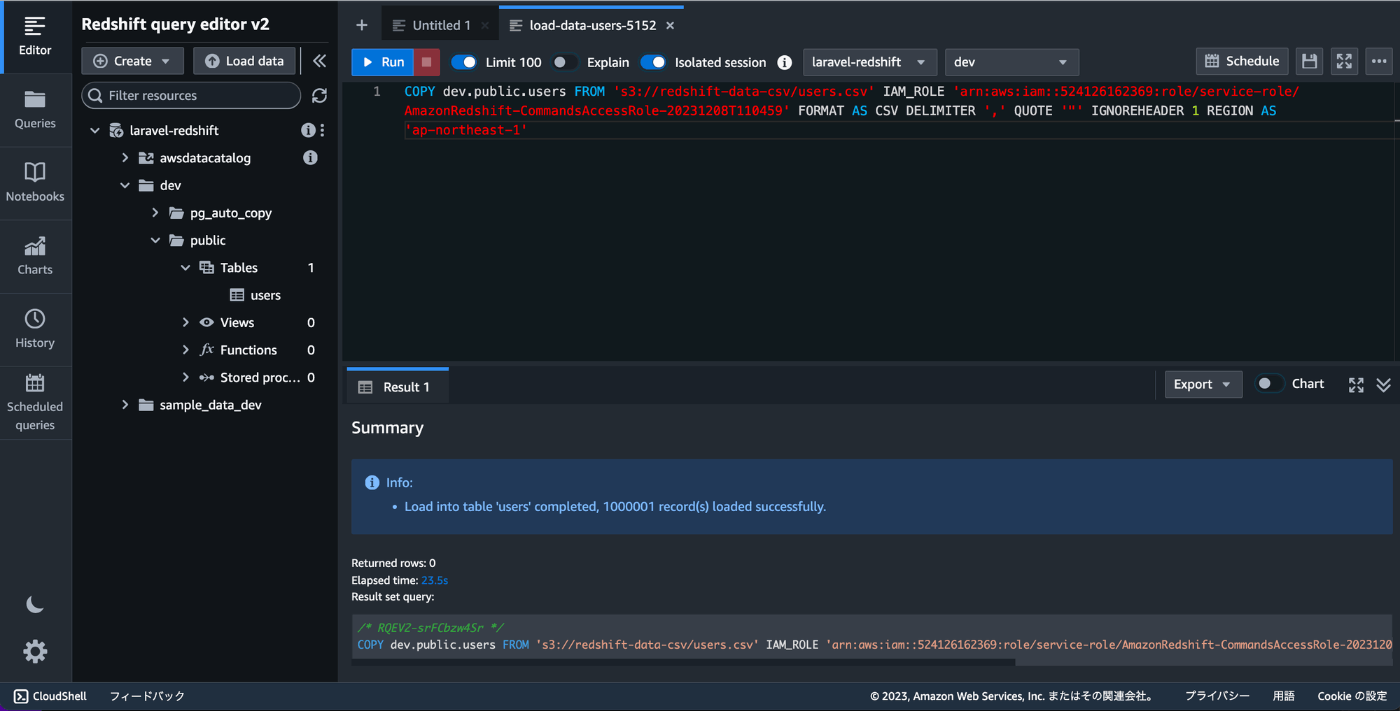
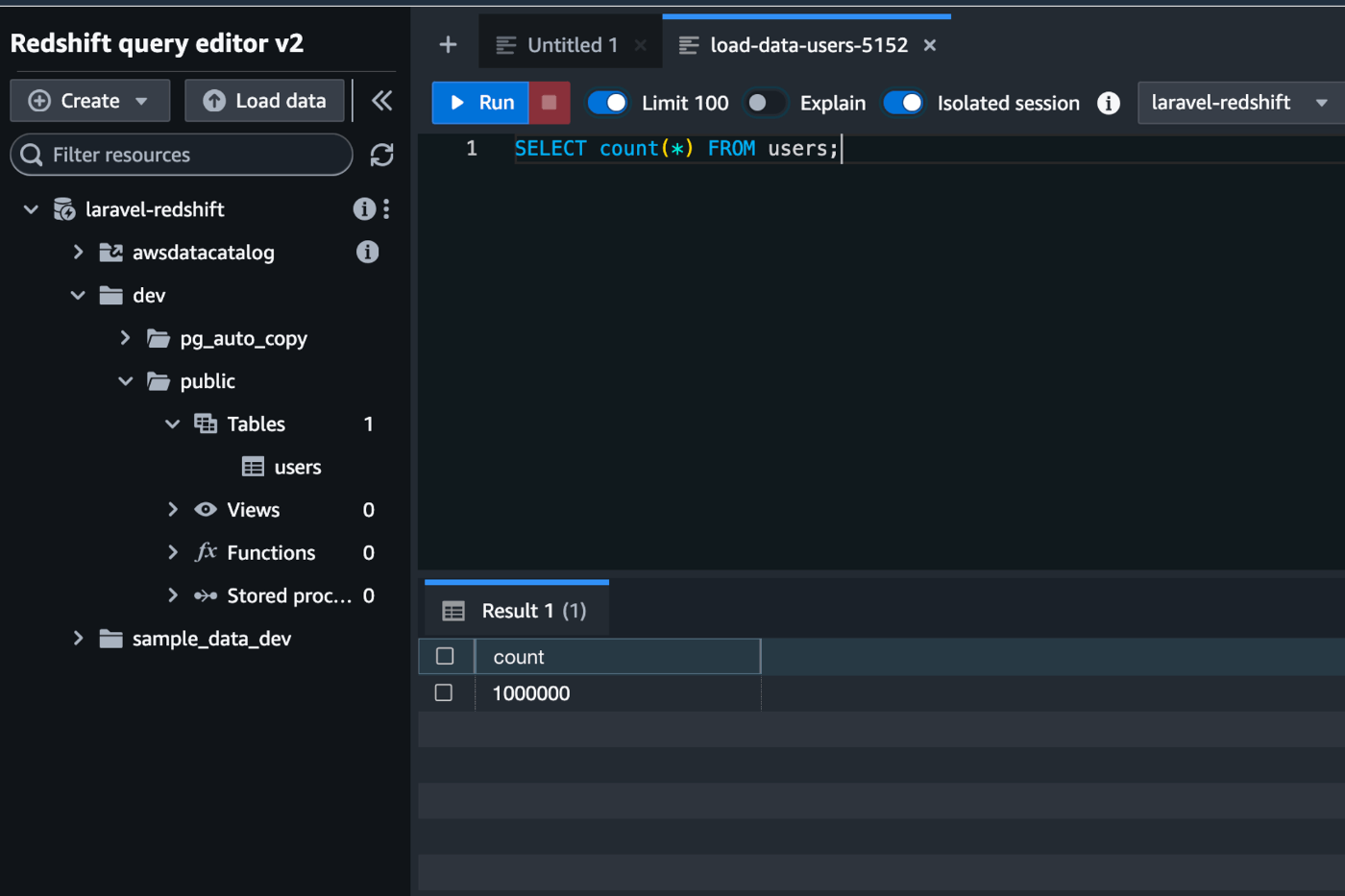
100万件入ってることが確認できます。
Discussion