PDFの検索(ColPali)→ 画像からキャプションの生成とバウンディングボックスの配置(Florence-2-large)を試してみた
はじめに
今回は、画像(写真や絵、グラフなど)の多いPDFの資料からでも知りたい情報を手っ取り早く検索したいと思い試したものになります。
通常、PDFを検索する際はOCRで文字情報を抜き出して検索をすることが多いかと思います。
ですが、写真や絵の中に文章があるなどテキスト抽出が難しいがあります。また、画像が多かったりその画像が主題となっているページでは文字情報だけで全容を把握できません。
今回はその対処法としてColPaliモデルというものを使い、PDFページを画像情報として扱った検索を試してみます。
また、検索結果のページ情報として(ページ内にある)画像のキャプション生成とテキストの抽出 & バウンディングボックス(対象のオブジェクトを囲んだ枠線)の配置を行います。
具体的には以下のことを行います。
- PDFのページを画像として扱い埋め込みに変換(ColPaliを使用)。
- 埋め込みを使い検索クエリから類似度の高いページを抽出(ColPaliを使用)
- ページのキャプションを生成して出力(Florence-2-largeを使用)
- ページからテキストを抽出して出力
- ページにバウンディングボックスを配置(Florence-2-largeを使用)
- バウンディングボックスが配置されたページを画像として保存
また、今回は英文のPDFを扱うため、日本語で扱うための翻訳機能(ON_OFF切り替え可能)を付けました。
検索クエリを日本語 → 英語、キャプションとテキストを英語 → 日本語、に内部で翻訳して出力するようにしています(日本語で検索して日本語でキャプションとテキストが返ってきます)。
日本語の翻訳にはBorea-Phi-3.5-mini-Instruct-Jpを使用しました。
以下は入力と出力の例です。
入力例)
- PDF: 10ページ
- 検索クエリ: 「鳥」
出力例)
- 検索結果ページ: 5ページ目
- 画像のキャプション: ページ内にある画像の説明
- 抽出したテキスト: ページ内から抽出したテキスト
- ページの保存: 鳥が関連する画像にバウンディングボックスが配置された状態のページ
※ キャプションに関しては、ページ全体を画像として読み込ませるため、複数の画像がページ内にあっても読み取ります。また、ある程度単語や文章も認識して説明が行われます。
※ ページ内のテキスト抽出処理に関しては本題ではないため、前処理、後処理などは行わず単純な方法で行っています。RAGなどを実装する際はより高度な実装が必要かと思います。
以上が実装するものの概要です。
PDFの処理は色々ありますが、今回は「ローカルLLMで」、「小さいモデルで」をコンセプトに試しました。
使用モデルについて
ColPali
ColPaliは、テキストと画像に対してColBERTスタイルでベクトル化を行う、PaliGemma-3Bをベースにしたモデルです。
ColPaliではドキュメントを画像として扱います。事前にOCRによるテキストの抽出をしておく必要ありません。
この手法によるメリットは、(ざっくりいうと)画像として扱っているため、テキストの抽出が難しい場合でも視覚情報から単語をとらえて検索できることです。
参考記事:
Florence-2-large
Florence-2-large(0.77B)は、Microsoft社がリリースした軽量の視覚言語モデルです。画像からキャプションの生成やオブジェクトの検出が行えます。
入力には、画像に加えて"<CAPTION>"(キャプション)や"<OD>"(物体検出)などのタスクプロンプト + 入力テキストを渡します(入力テキストは、キャプションからオブジェクトを検出する"<CAPTION_TO_PHRASE_GROUNDING>"タスクに使用します)。
出力は、キャプションタスクの場合は画像を説明するテキスト、オブジェクト検出タスクの場合はオブジェクトの座標が返されます。
参考記事:
Borea-Phi-3.5-mini-Instruct-Jp
Borea-Phi-3.5-mini-Instruct-Jpは、phi-3.5-mini-Instruct(3.8B)に対してAxcxept社がチューニングを行ったモデルです。 Japanese MT Bench(日本語評価)、ElyzaTasks100(日本語性能)そしてMTBench(英語評価)においてもベースモデルより高いスコアを記録しており、汎用的なタスクに対応できるようになっています。
以下の3つがリリースされていますが、今回は「Borea-Phi-3.5-mini-Instruct-Jp」を利用しました。
- Borea-Phi-3.5-mini-Instruct-Jp: 汎用性と日本語性能の向上が特徴的なモデル
- Borea-Phi-3.5-mini-Instruct-Common: 汎用的に能力向上を行ったモデル
- Phi-3.5-mini-instruct-Borea-Coding: コーディング能力と日本語力を高めたモデル
参考記事:
使用するPDF
今回読み込ませる資料は、「政府広報オンライン(Government Public Relations Online)」が出している以下のPDF(英文)を使用しました。
- 政府広報オンライン(Government Public Relations Online)
出典:政府広報オンライン(https://www.gov-online.go.jp/hlj/en/may_2024/)
PDF内では、主に日本の代表的な森や森林浴について紹介されています(落語や和菓子なども紹介されています)。
写真や図、画像上のテキストなどが程よくあるため、ColPaliによる検索 & Florence-2-largeによるキャプションの生成を試すのに適していそうです(海外向けかと思いますが、日本にある森や落語の魅力が写真や図によりわかりやすく解説されているため読み物としても面白かったです)。
作業環境
OS: WSL2 Ubuntu22.04
GPU: GeForce RTX 2080 SUPER(8GB)
CPU: Corei9-9900KF
ライブラリの準備
まずはPDFファイルのテキスト、画像の抽出などの操作に使用するため「poppler-utils」、「tesseract-ocr」、「libtesseract-dev」のインストールが必要です。
自分の環境(WSL2 Ubuntu22.04)では以下のコマンドでインストールしました。
$ sudo apt install poppler-utils
$ sudo apt install tesseract-ocr
$ sudo apt install libtesseract-dev
次にコード内で使用する、以下のライブラリをインストールします。
$ pip install pytesseract
$ pip install pdf2image
$ pip install colpali-engine==0.2.0
$ pip install torch
$ pip install typer
$ pip install tqdm
$ pip install transformers
$ pip install Pillow
$ pip install flash_attn
$ pip install timm
コーディング(全体)
全体のコードは以下となります(長いため折りたたんでいます)。
コーディング(全体)
import os
import re
import time
import glob
import torch
from tqdm import tqdm
import pytesseract
from PIL import (
Image,
ImageDraw,
ImageFont
)
from transformers import (
AutoProcessor,
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig
)
from torch.utils.data import DataLoader
from colpali_engine.trainer.retrieval_evaluator import CustomEvaluator
from colpali_engine.models.paligemma_colbert_architecture import ColPali
from colpali_engine.utils.colpali_processing_utils import process_images, process_queries
from colpali_engine.utils.image_from_page_utils import load_from_pdf
# huggingfaceトークンの設定
os.environ["HF_TOKEN"] = ""
# デバイス
device = "cuda"
# 作業フォルダ
work_path = "./"
# PDF(作業フォルダ直下に配置)
pdf = "HIGHLIGHTING_Japan_May2024.pdf"
# 検索クエリ(「translate=False」の場合は英語を使用)
query = "Recommended forests"
# 英文の翻訳を行うかどうか
translate = False
# 埋め込み作成時のバッチ数
batch_size = 2
# 上位2件の検索結果を出力
top_k = 2
# 画像のバウンディングボックスの色
bboxes_color = (50, 205, 50) # ライムグリーン
# 画像のラベルの色
label_color = "white"
def main():
pdf_path = os.path.join(work_path, pdf)
pdf_name = os.path.splitext(pdf)[0]
image_dir_path = os.path.join(work_path, f"{pdf_name}_pages")
# 画像の保存ディレクトリを作成
os.makedirs(image_dir_path, exist_ok=True)
# フォルダ内の画像を削除
image_path_list = glob.glob(os.path.join(image_dir_path, "*.png"))
for file in image_path_list:
os.remove(file)
emb_dir_path = os.path.join(work_path, "embeddings")
emb_name = f"{pdf_name}_embedding.pt"
emb_path = os.path.join(emb_dir_path, emb_name)
# 埋め込みの保存ディレクトリを作成
os.makedirs(emb_dir_path, exist_ok=True)
# colpaliのモデルとプロセッサを取得
colpali_model, colpali_processor = load_colpali()
# PDFを画像に変換
images = load_from_pdf(pdf_path)
# 埋め込みが存在する場合は取得、存在しない場合は作成して保存
if os.path.isfile(emb_path):
embedding = torch.load(emb_path, weights_only=True)
else:
embedding = create_embdding(colpali_model, colpali_processor, images)
torch.save(embedding, emb_path)
print(f"\n埋め込みを保存: {emb_name}\n")
# Borea-Phi-3.5-mini-Instruct-Jpモデルとトークナイザーの取得
borea_phi_model, borea_phi_tokenizer = load_borea_phi()
# 「translate=True」の場合、検索クエリを英語に翻訳
if translate:
translate_query = translation(
borea_phi_model,
borea_phi_tokenizer,
text=query,
translate_switch="ja_to_en"
).strip()
else:
translate_query = query
# ページ検索の開始時間を取得
start_time = time.time()
# PDFのページごとに検索スコアを取得
scores = page_scores(
colpali_model,
colpali_processor,
embedding,
translate_query
)
# ページ検索の処理時間を取得
processing_time = time.time() - start_time
hours, remainder = divmod(processing_time, 3600)
minutes, seconds = divmod(remainder, 60)
# 処理時間を出力
page_seach_time = f"{hours:02.0f}h:{minutes:02.0f}m:{seconds:04.1f}s"
# ColPaliモデルとプロセッサをメモリから削除
del colpali_model
del colpali_processor
torch.cuda.empty_cache()
# 上位スコアのページを取得
top_scores = scores.argsort()[-top_k:][::-1]
# Florence-2-largeモデルとトークナイザーの取得
florence_model, florence_processor = load_florence()
page_score_list = []
page_caption_list = []
page_text_list = []
# キャプションの生成、テキストの抽出、バウンディングボックス付き画像の保存を実行
for index in top_scores:
page_image = images[index]
page_score = f"ページ: {index+1} スコア: {scores[index]}"
page_score_list.append(page_score)
# キャプションの生成
page_caption = run_florence(
florence_model,
florence_processor,
page_image,
"<MORE_DETAILED_CAPTION>"
)
page_caption_list.append(page_caption)
# PDFのページからテキストを抽出
page_text = pytesseract.image_to_string(page_image)
# 2行以上の空白行を一行に置換
page_text = re.sub(r'\n\s*\n', '\n\n', page_text).strip()
page_text_list.append(page_text)
# バウンディングボックスの座標を生成
bboxes_labels = run_florence(
florence_model,
florence_processor,
page_image,
"<CAPTION_TO_PHRASE_GROUNDING>",
translate_query
)
# バウンディングボックスを画像に配置
image = draw_bboxes(page_image, bboxes_labels)
# 画像を保存
img_name = f"page_{index+1}_score_{scores[index]}.png"
image_path = os.path.join(image_dir_path, img_name)
image.save(image_path)
# Florence-2-largeモデルとプロセッサをメモリから削除
del florence_model
del florence_processor
torch.cuda.empty_cache()
# キャプション、抽出したテキストの翻訳と結果の出力
for page_and_score, page_caption, page_text in zip(page_score_list, page_caption_list, page_text_list):
# 上位スコアのページとスコアを出力
print(f"\n\n{page_and_score}")
print("===================================================================")
# 「translate=True」の場合、ページのキャプションを日本語に翻訳
if translate:
translate_page_caption = translation(
borea_phi_model,
borea_phi_tokenizer,
text=page_caption["<MORE_DETAILED_CAPTION>"],
translate_switch="en_to_ja"
).strip()
else:
translate_page_caption = page_caption["<MORE_DETAILED_CAPTION>"]
print("画像のキャプション-------------------------------------------------")
print(translate_page_caption)
print("-------------------------------------------------------------------")
# 「translate=True」の場合、ページのテキストを日本語に翻訳
if translate:
translate_page_text = translation(
borea_phi_model,
borea_phi_tokenizer,
text=page_text,
translate_switch="en_to_ja"
).strip()
else:
translate_page_text = page_text
print("\n抽出したテキスト-------------------------------------------------")
print(translate_page_text)
print("-------------------------------------------------------------------")
print("===================================================================")
print(f"\nColPaliによるページ検索の処理時間: {page_seach_time}")
# ColPaliのモデルとプロセッサを読み込む関数
def load_colpali():
# モデルの読み込み
model = ColPali.from_pretrained(
"google/paligemma-3b-mix-448",
torch_dtype=torch.bfloat16,
device_map=device
).eval()
model.load_adapter("vidore/colpali")
# プロセッサの読み込み
processor = AutoProcessor.from_pretrained("vidore/colpali")
return model, processor
# 埋め込みを作成する関数
def create_embdding(colpali_model, colpali_processor, images):
# データローダーの作成
dataloader = DataLoader(
images,
batch_size=batch_size,
shuffle=False,
collate_fn=lambda x: process_images(colpali_processor, x)
)
# 埋め込みの作成
embedding = []
for batch_doc in tqdm(dataloader):
with torch.no_grad():
batch_doc = {k: v.to(device) for k, v in batch_doc.items()}
embeddings_doc = colpali_model(**batch_doc)
embedding.extend(list(torch.unbind(embeddings_doc.to(device))))
return embedding
# 全ページのスコアを取得する関数
def page_scores(colpali_model, colpali_processor, embedding, query):
mock_image = Image.new("RGB", (448, 448), (255, 255, 255))
# クエリの埋め込みを生成
with torch.no_grad():
processed_query = process_queries(
colpali_processor,
[query],
mock_image
)
processed_query = {k: v.to(device) for k, v in processed_query.items()}
query_embedding = colpali_model(**processed_query)
# クエリの埋め込みとPDFの埋め込みで類似度を計算
evaluator = CustomEvaluator(is_multi_vector=True)
scores = evaluator.evaluate(query_embedding, embedding)[0]
return scores
# Florence-2-largeのモデルとプロセッサを読み込む関数
def load_florence():
repo_id = "microsoft/Florence-2-large"
# モデルの読み込み
model = AutoModelForCausalLM.from_pretrained(
repo_id,
torch_dtype=torch.float16,
device_map=device,
trust_remote_code=True
)
# プロセッサの読み込み
processor = AutoProcessor.from_pretrained(
repo_id,
trust_remote_code=True
)
return model, processor
# タスクによって画像を処理する関数
def run_florence(florence_model, florence_processor, image, task_prompt, query=None):
if query is None:
prompt = task_prompt
else:
prompt = task_prompt + query
# 画像とテキストをテンソルに変換
inputs = florence_processor(
text=prompt,
images=image,
return_tensors="pt"
).to(device, torch.float16)
# 入力テンソルから出力を生成
generated_ids = florence_model.generate(
input_ids=inputs["input_ids"],
pixel_values=inputs["pixel_values"],
max_new_tokens=2048,
num_beams=3,
do_sample=False
)
# 出力テンソルをテキストにデコード
generated_text = florence_processor.batch_decode(generated_ids, skip_special_tokens=False)[0]
# 生成されたテキストから結果を取得
response = florence_processor.post_process_generation(
generated_text,
task=task_prompt,
image_size=(image.width, image.height)
)
return response
# バウンディングボックスを配置する関数
def draw_bboxes(image, bboxes_labels):
draw = ImageDraw.Draw(image)
# バウンディングボックスの位置を取得
bboxes = bboxes_labels['<CAPTION_TO_PHRASE_GROUNDING>']['bboxes']
# ラベルのテキストを取得
labels = bboxes_labels['<CAPTION_TO_PHRASE_GROUNDING>']['labels']
# 画像にバウンディングボックスとラベルを描画
for bbox, label in zip(bboxes, labels):
# バウンディングボックスを描画
draw.rectangle(bbox, outline=bboxes_color, width=10)
# ラベルのフォントサイズを設定
font = ImageFont.load_default().font_variant(size=50)
# ラベルの位置を設定
label_position = (bbox[0]+10, bbox[1]-50)
# ラベルのサイズを取得
label_bbox = font.getbbox(label)
label_width = label_bbox[2] - label_bbox[0]
label_height = label_bbox[3] - label_bbox[1]
# ラベル背景の矩形を設定
background_bbox = [
label_position[0]-10,
label_position[1]+label_bbox[1]-10,
label_position[0]+label_width+10,
label_position[1]+label_height+label_bbox[1]
]
# ラベル背景を描画
draw.rectangle(background_bbox, fill=bboxes_color)
# ラベルを描画
draw.text(
label_position,
text=label,
font=font,
fill=label_color
)
return image
# Borea-Phi-3.5-mini-Instruct-Jpのモデルとトークナイザーを読み込む関数
def load_borea_phi():
repo_id = "HODACHI/Borea-Phi-3.5-mini-Instruct-Jp"
# 量子化のConfigを設定
quantization_config = BitsAndBytesConfig(
load_in_8bit=True
)
# モデルの読み込み
model = AutoModelForCausalLM.from_pretrained(
pretrained_model_name_or_path=repo_id,
torch_dtype=torch.float16,
quantization_config=quantization_config,
device_map=device
)
# トークナイザーの読み込み
tokenizer = AutoTokenizer.from_pretrained(
pretrained_model_name_or_path=repo_id
)
return model, tokenizer
# 翻訳を行う関数
def translation(model, tokenizer, text, translate_switch=""):
# translate_switchによって英語 or 日本語のどちらに翻訳するか判断
if translate_switch == "en_to_ja":
content = """あなたは英語の文章を**的確な**日本語に翻訳する優秀なな翻訳家です。
**翻訳した文章のみ**を出力してください。
翻訳する文章は以下です。
{text}
"""
elif translate_switch == "ja_to_en":
content = """You are an excellent translator who translates Japanese texts into **accurate** English.
**Only output the translated text**.
The text to be translated is as follows.
{text}
"""
else:
return text
messages = [
{"role": "user", "content": content.format(text=text)}
]
# トークナイザーのチャットテンプレートを適用
prompt = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
# プロンプトをトークン化してテンソルに変換
inputs = tokenizer([prompt], return_tensors="pt").to(device)
# 入力テンソルから出力を生成
generated_ids = model.generate(
inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=4096
)
# 生成された回答を抽出
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(inputs.input_ids, generated_ids)
]
# トークンIDを文字列に変換
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
return response
if __name__ == "__main__":
# 開始時間を取得
start_time = time.time()
main()
# 処理時間を取得
processing_time = time.time() - start_time
hours, remainder = divmod(processing_time, 3600)
minutes, seconds = divmod(remainder, 60)
# 処理時間を出力
print(f"全体の処理時間(モデルの読み込み時間を含む): {hours:02.0f}h:{minutes:02.0f}m:{seconds:04.1f}s")
主なパラメータ(作業フォルダのパスや検索クエリなど)はグローバル変数で設定しています。作業フォルダにPDFを配置してパラメータを適宜変更すれば動作(するはず・・・)します。日本語で検索して日本語で結果を出力する場合は「translate = True」を設定してください。
初回のみPDFから埋め込みの作成を行います(embeddingsフォルダが作成されそこに配置されます。2回目以降の実行では作成済みの埋め込みを使用して検索を行います)。
上記コードの内、主な機能(main関数以外の関数部分)を確認してみます。
コーディング(関数部分の確認)
ColPaliのモデルとプロセッサを読み込む関数(load_colpali)
# ColPaliのモデルとプロセッサを読み込む関数
def load_colpali():
# モデルの読み込み
model = ColPali.from_pretrained(
"google/paligemma-3b-mix-448",
torch_dtype=torch.bfloat16,
device_map=device
).eval()
model.load_adapter("vidore/colpali")
# プロセッサの読み込み
processor = AutoProcessor.from_pretrained("vidore/colpali")
return model, processor
ColPaliのモデルとプロセッサの読み込みを行います。
ベースモデルとして"paligemma-3b-mix-448"を読み込み、アダプターをセットすることでColPaliを準備します。
埋め込みを作成する関数(create_embdding)
# 埋め込みを作成する関数
def create_embdding(colpali_model, colpali_processor, images):
# データローダーの作成
dataloader = DataLoader(
images,
batch_size=batch_size,
shuffle=False,
collate_fn=lambda x: process_images(colpali_processor, x)
)
# 埋め込みの作成
embedding = []
for batch_doc in tqdm(dataloader):
with torch.no_grad():
batch_doc = {k: v.to(device) for k, v in batch_doc.items()}
embeddings_doc = colpali_model(**batch_doc)
embedding.extend(list(torch.unbind(embeddings_doc.to(device))))
return embedding
初回実行時、新しくPDFの埋め込みを作成する際に使用する関数です。
ColPaliのモデル(colpali_model)とプロセッサ(colpali_processor)、そしてPDFの各ページを画像として読み込んだリスト(images)を引数として渡します。
埋め込みを作成する際には、グローバル変数で設定した「batch_size」ごとに画像を読み込んで埋め込み(ベクトルのリスト)を作成します。
全ページのスコアを取得する関数(page_scores)
# 全ページのスコアを取得する関数
def page_scores(colpali_model, colpali_processor, embedding, query):
mock_image = Image.new("RGB", (448, 448), (255, 255, 255))
# クエリの埋め込みを生成
with torch.no_grad():
processed_query = process_queries(
colpali_processor,
[query],
mock_image
)
processed_query = {k: v.to(device) for k, v in processed_query.items()}
query_embedding = colpali_model(**processed_query)
# クエリの埋め込みとPDFの埋め込みで類似度を計算
evaluator = CustomEvaluator(is_multi_vector=True)
scores = evaluator.evaluate(query_embedding, embedding)[0]
return scores
ColPaliのモデル(colpali_model)とプロセッサ(colpali_processor)、PDFの埋め込み(embedding)、検索クエリ(query)を引数として渡します。
検索クエリを埋め込みに変換後、PDFの埋め込みとの類似度をスコアのリストとして返却します。リストはPDFのページ順となっています。
Florence-2-largeのモデルとプロセッサを読み込む関数(load_florence)
# Florence-2-largeのモデルとプロセッサを読み込む関数
def load_florence():
repo_id = "microsoft/Florence-2-large"
# モデルの読み込み
model = AutoModelForCausalLM.from_pretrained(
repo_id,
torch_dtype=torch.float16,
device_map=device,
trust_remote_code=True
)
# プロセッサの読み込み
processor = AutoProcessor.from_pretrained(
repo_id,
trust_remote_code=True
)
return model, processor
Florence-2-largeのモデルとプロセッサの読み込みを行います。
タスクによって画像を処理する関数(run_florence)
# タスクによって画像を処理する関数
def run_florence(florence_model, florence_processor, image, task_prompt, query=None):
if query is None:
prompt = task_prompt
else:
prompt = task_prompt + query
# 画像とテキストをテンソルに変換
inputs = florence_processor(
text=prompt,
images=image,
return_tensors="pt"
).to(device, torch.float16)
# 入力テンソルから出力を生成
generated_ids = florence_model.generate(
input_ids=inputs["input_ids"],
pixel_values=inputs["pixel_values"],
max_new_tokens=2048,
num_beams=3,
do_sample=False
)
# 出力テンソルをテキストにデコード
generated_text = florence_processor.batch_decode(generated_ids, skip_special_tokens=False)[0]
# 生成されたテキストから結果を取得
response = florence_processor.post_process_generation(
generated_text,
task=task_prompt,
image_size=(image.width, image.height)
)
return response
Florence-2-largeのモデル(florence_model)とプロセッサ(florence_processor)、画像(image)、タスク(task_prompt)、検索クエリ(query)を引数として渡します(queryは"<CAPTION_TO_PHRASE_GROUNDING>"タスクにのみ使用します)。
今回使用するタスク(task_prompt)とそのレスポンス(response)は以下の二つです
- task_prompt: "<MORE_DETAILED_CAPTION>"(キャプションの生成)
- response: 画像のキャプション(説明文)
- task_prompt: "<CAPTION_TO_PHRASE_GROUNDING>"(オブジェクトの座標とラベルの取得)
- response: 検索クエリ(query)で指定したオブジェクトの座標とラベル
バウンディングボックスを配置する関数(draw_bboxes)
# バウンディングボックスを配置する関数
def draw_bboxes(image, bboxes_labels):
draw = ImageDraw.Draw(image)
# バウンディングボックスの位置を取得
bboxes = bboxes_labels['<CAPTION_TO_PHRASE_GROUNDING>']['bboxes']
# ラベルのテキストを取得
labels = bboxes_labels['<CAPTION_TO_PHRASE_GROUNDING>']['labels']
# 画像にバウンディングボックスとラベルを描画
for bbox, label in zip(bboxes, labels):
# バウンディングボックスを描画
draw.rectangle(bbox, outline=bboxes_color, width=10)
# ラベルのフォントサイズを設定
font = ImageFont.load_default().font_variant(size=50)
# ラベルの位置を設定
label_position = (bbox[0]+10, bbox[1]-50)
# ラベルのサイズを取得
label_bbox = font.getbbox(label)
label_width = label_bbox[2] - label_bbox[0]
label_height = label_bbox[3] - label_bbox[1]
# ラベル背景の矩形を設定
background_bbox = [
label_position[0]-10,
label_position[1]+label_bbox[1]-10,
label_position[0]+label_width+10,
label_position[1]+label_height+label_bbox[1]
]
# ラベル背景を描画
draw.rectangle(background_bbox, fill=bboxes_color)
# ラベルを描画
draw.text(
label_position,
text=label,
font=font,
fill=label_color
)
return image
画像(image)、オブジェクトの座標とラベル(bboxes_labels)を引数として渡します。
「bboxes_labels」はrun_florence関数(<CAPTION_TO_PHRASE_GROUNDING>タスク)で取得したオブジェクトの座標とラベルです。
この関数は、引数で渡した画像にラベル付きのバウンディングボックスを配置して返します。
Borea-Phi-3.5-mini-Instruct-Jpのモデルとトークナイザーを読み込む関数(load_borea_phi)
# Borea-Phi-3.5-mini-Instruct-Jpのモデルとトークナイザーを読み込む関数
def load_borea_phi():
repo_id = "HODACHI/Borea-Phi-3.5-mini-Instruct-Jp"
# 量子化のConfigを設定
quantization_config = BitsAndBytesConfig(
load_in_8bit=True
)
# モデルの読み込み
model = AutoModelForCausalLM.from_pretrained(
pretrained_model_name_or_path=repo_id,
torch_dtype=torch.float16,
quantization_config=quantization_config,
device_map=device
)
# トークナイザーの読み込み
tokenizer = AutoTokenizer.from_pretrained(
pretrained_model_name_or_path=repo_id
)
return model, tokenizer
Borea-Phi-3.5-mini-Instruct-Jpのモデルとトークナイザーの読み込みを行います。
翻訳を行う関数(translation)
# 翻訳を行う関数
def translation(model, tokenizer, text, translate_switch=""):
# translate_switchによって英語 or 日本語のどちらに翻訳するか判断
if translate_switch == "en_to_ja":
content = """あなたは英語の文章を**的確な**日本語に翻訳する優秀なな翻訳家です。
**翻訳した文章のみ**を出力してください。
翻訳する文章は以下です。
{text}
"""
elif translate_switch == "ja_to_en":
content = """You are an excellent translator who translates Japanese texts into **accurate** English.
**Only output the translated text**.
The text to be translated is as follows.
{text}
"""
else:
return text
messages = [
{"role": "user", "content": content.format(text=text)}
]
# トークナイザーのチャットテンプレートを適用
prompt = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
# プロンプトをトークン化してテンソルに変換
inputs = tokenizer([prompt], return_tensors="pt").to(device)
# 入力テンソルから出力を生成
generated_ids = model.generate(
inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=4096
)
# 生成された回答を抽出
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(inputs.input_ids, generated_ids)
]
# トークンIDを文字列に変換
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
return response
グローバル変数で「translate = True」を指定した際に使用する関数です。
Borea-Phi-3.5-mini-Instruct-Jpのモデル(model)とトークナイザー(tokenizer)、翻訳するテキスト(text)、英訳 or 和訳のモード設定(translate_switch)を引数として渡します。
translate_switchには"en_to_ja"(英語 → 日本語)または "ja_to_en"(日本語 → 英語)を指定して翻訳を切り替えるようにしています。
実行結果_1
翻訳なし
まずは翻訳なし(translate = False)で実行してみます。
検索クエリ(query)は「Recommended forests」、検索するページ数(top_k)は上位スコア2ページに設定しました。
ページとスコア、画像キャプション、抽出したテキストの出力は以下となります(長いため折りたたんでいます)。
出力(英語)
ページ: 5 スコア: 9.5625
===================================================================
画像のキャプション-------------------------------------------------
The image is a map of Japan, showing the locations of the most beautiful forests in the country. The map is in an orange color and is divided into different sections, each representing a different type of forest.
The top left section of the map has the letter "J" in the center, which is likely the name of the forest. Below that, there is a list of the names of the forests, including "Kikuchi Gorge", "Bijinbayashi", "Honshu", "Akashima Natural Forest", and "Kumano Kodo". The map also includes a legend that explains the different colors used in the map.
On the right side of the image, there are several smaller circles that represent the different types of forests in Japan. These circles are labeled with their names and are arranged in a grid-like pattern. The background of the infographic is white, and the text is black.
-------------------------------------------------------------------
抽出したテキスト-------------------------------------------------
JAPAN’S HEALING FORESTS <partT1>
apan is one of the most forested coun-
tries in the world, with approximately 70
percent of its land area covered by forest.
BUCO ee bey meu Caee DCO MODAL ou tos (OKIE
LUE MCMC OTOL PM APPR eMC ur CIT LOMO
time. In Japan, the practice of relaxing in such
a forest, away from the busy daily life, is called
“shinrin-yoku” (forest bathing)*, and overseas it AKAN-MASHU
is also known as “shinrin-yoku” as the Japanese Velie
term implies. Actually, forest bathing has scien- Eastern Hokkaido
tifically proven the relaxing effects. This issue
of Highlighting Japan introduces readers to forest
bathing based on scientific knowledge and some
of Japan’s most famous forests, including the
Akasawa Natural Recreation Forest in Nagano
Prefecture, the birthplace of forest bathing, the Hokkaido
Shirakami Sanchi Mountain Range, and the
ancient pilgrimage routes of Kumano Kodo, as
well as various initiatives that utilize forests.
* The Japanese term for “shinrin-yoku” is for-
est bathing. Shinrin means ‘forest’ and Yoku =
means ‘bath.’ Shinrin-Yoku literally means Ss La l RAKAM |
forest bathing, or ‘taking in the forest atmo- SAN Cc H |
PNT n as gy
PT Mag
sphere’ for therapeutic results. 12) iB | N BAYAS H |
Me Tar on Rel 5 2
Nile Maat ie)
$
KIKUCHI GORGE
Parse A AKASAWA NATURAL
- Kumamoto Prefecture Pad RECREATION
y FOREST
NEL nL
Nagano Prefecture
y
KUMANO KODO
Nara Prefecture
We clccrotg
MEIN aCe
SHIKOKU KARST TENGU
HIGHLAND NATURAL
RECREATIONAL FOREST
Tsuno Town, Kochi Prefecture
Vol.192 HIGHLIGHTING JAPAN 5
-------------------------------------------------------------------
===================================================================
ページ: 11 スコア: 9.5
===================================================================
画像のキャプション-------------------------------------------------
The image is a page from a book titled "Japan's Healing Forests". It is divided into two sections.
The top section is a photograph of a forest with tall trees and a clear blue sky. The trees are tall and green, and the sky is a bright blue. The forest appears to be in a wooded area, as there are no other trees visible in the image.
In the bottom section, there is a photo of a black bird perched on a tree trunk. The bird is facing towards the right side of the page, and its beak is open as if it is about to take flight. The tree trunk is covered in white flowers, and there are a few small white flowers scattered around it. The background is blurred, but it seems to be a forested area with more trees and shrubs. The text on the page is written in black font and is in a smaller font size than the rest of the text.
-------------------------------------------------------------------
抽出したテキスト-------------------------------------------------
You can enjoy forest bathing in the Japanese Spruce (Sakhalin spruce)*
forest that spreads out from right behind the Kawayu Visitor Center.
the other lakes and marshes in the area. The other is
the ‘Mashu area,’ where you get a feel of the moisture
and circulation of the water, with Lake Kussharo,
which fills the western half of Japan’s largest caldera—
Kussharo Caldera—and Lake Mashu, one of the clear-
est lakes in the world.”
Suehiro told us how to enjoy
the forests in the Mashu and Akan
areas.
“The Tsutsujigahara Nature
Trail from the Kawayu Visitor
Center in the Kawayu Onsen hot
spring area of Mashu to Atusanu-
puri (also known as Mt. Io) is a flat
trail that can be traversed by foot
in about one hour. It is a precious
place with a unique ecosystem of
Photo: Akan-Mashu National Park
JAPAN’S HEALING FORESTS <PartT1>
Iso-azalea flowers extend through the forest along the Tsutsujigahara
Nature Trail
production.
However, Maeda Masana, the initial head of the
park, believed that “this mountain should be changed
from one to be logged into one to be viewed,” and
based on his principle of not opposing the power of
nature but maximizing it, long-
term efforts have been made to
keep the forests in their original
state and pass them down to the
future generations. You can enter
the Hikari no Mori (Mystical For-
est) and Kohoku no Mori (North
of the Lake Forest) with a qualified
Ippoen Forest Guide. The many
interesting spots include a giant
katsura (Cercidiphyllum japonicum)
tree said to be 800 years old and
Photo: PIXTA
The black woodpecker, which also inhabits the area,
is designated as a natural treasure.
alpine plants that can withstand
the volcanic gases and acidic soil
discharged from Mt. Io. You can stroll through the
forests and observe the plants living in this special
environment-—the trail starts with a Coniferous Forest
Zone, and also has a Broadleaf Forest Zone and an Iso-
azalea’ Zone, all within a short distance of about 2.5
kilometers. The sight of 100 hectares of pure white iso-
azaleas in the forest in early summer (around June) is
especially stunning.”
In the Akan area, we recommend a guided tour
that explores the forests by the Maeda Ippoen Founda-
tion*, which has been working for over 90 years to pre-
serve sustainable forests. According to Hibino Akihiro
of the Lake Akan National Park Ranger Station, “In the
early 1900s, a great number of trees in the Akan area
forests administered by the Maeda Ippoen Foundation
were cut down to clear space for ranching and timber
Tezukanuma Swamp with its hot
springs, so we recommend that
you have the experience of forest bathing in a prime-
val forest preserved by the people of Akan.”
The Akan-Mashu National Park is currently part of
the Project to Fully Enjoy National Parks.
Suehiro said, “In order to make the park more
accessible to overseas visitors, we are working on a
variety of projects, including the renovation of over-
night accommodations and observatory facilities. We
hope that many people will visit the unique, majestic
forests of Akan-Mashu.”
A depression formed by volcanic activity.
2. Asmall evergreen shrub native to Hokkaido that is 30-70 cm tall. It is sometimes seen in gravelly
alpine areas, and also grows in some volcanic ash areas and marshlands.
3. Found in Hokkaido and on Mount Hayachine in Honshu. It is designated as a Tree of Hokkaido
along with the Ezo spruce.
4. A foundation set up to carry on the wishes of Maeda Masana, who developed the expansive
mountain forests along the lakeside of Lake Akan in Hokkaido in early 1900, and to contribute to
the preservation of its natural environment and appropriate use.
Vol.192 HIGHLIGHTING JAPAN
Photo: Akan-Mashu National Park
ii
-------------------------------------------------------------------
===================================================================
ColPaliによるページ検索の処理時間: 00h:00m:00.7s
全体の処理時間(モデルの読み込み時間を含む): 00h:01m:52.9s
出力の(5ページ目の)画像のキャプション部分を確認すると、以下の部分で森林地帯の名前が確認できます。
The top left section of the map has the letter "J" in the center, which is likely the name of the forest. Below that, there is a list of the names of the forests, including "Kikuchi Gorge", "Bijinbayashi", "Honshu", "Akashima Natural Forest", and "Kumano Kodo". The map also includes a legend that explains the different colors used in the map.
抽出したテキストからも森林地帯の名前を確認できますが、抽出しずらいページだったためか、ノイズや脱字の多い文章になっています。
画像が主体としてあるページの場合、キャプションから見た方が概要を素早く把握することが出来そうです。
ただ、キャプションはほとんどが画像についての説明なので、文字が主体のページでは抽出したテキストから内容を確認する必要があります(次点で高いスコアである11ページでは、キャプションだけでページの概要を把握することができません)。RAGのコンテキストとして使用する場合は、画像のキャプションと抽出したテキストを同時に入れるのがよさそうです。
出力の最後には、以下のように処理時間が返されています。
ColPaliによるページ検索の処理時間: 00h:00m:00.7s
全体の処理時間(モデルの読み込み時間を含む): 00h:01m:52.9s
上記は、埋め込み作成後(2回目以降)の実行時間です。初回実行には埋め込み作成時間(約1分)が追加でかかります。
ColPaliによるページ検索(32ページ)の処理は0.7秒で完了しており高速です。
全体の処理時間については、キャプションの生成とバウンディングボックスの生成をそれぞれ2回ずつ + モデルの読み込みや他処理を考慮するとそこまで遅くはないように思えます。
以下は、コード実行時に作成される検索結果のページ(画像)です(作業ディレクトリ内の"<PDF名>_pages"フォルダに保存されます)。
- 5ページ目 スコア 9.5625
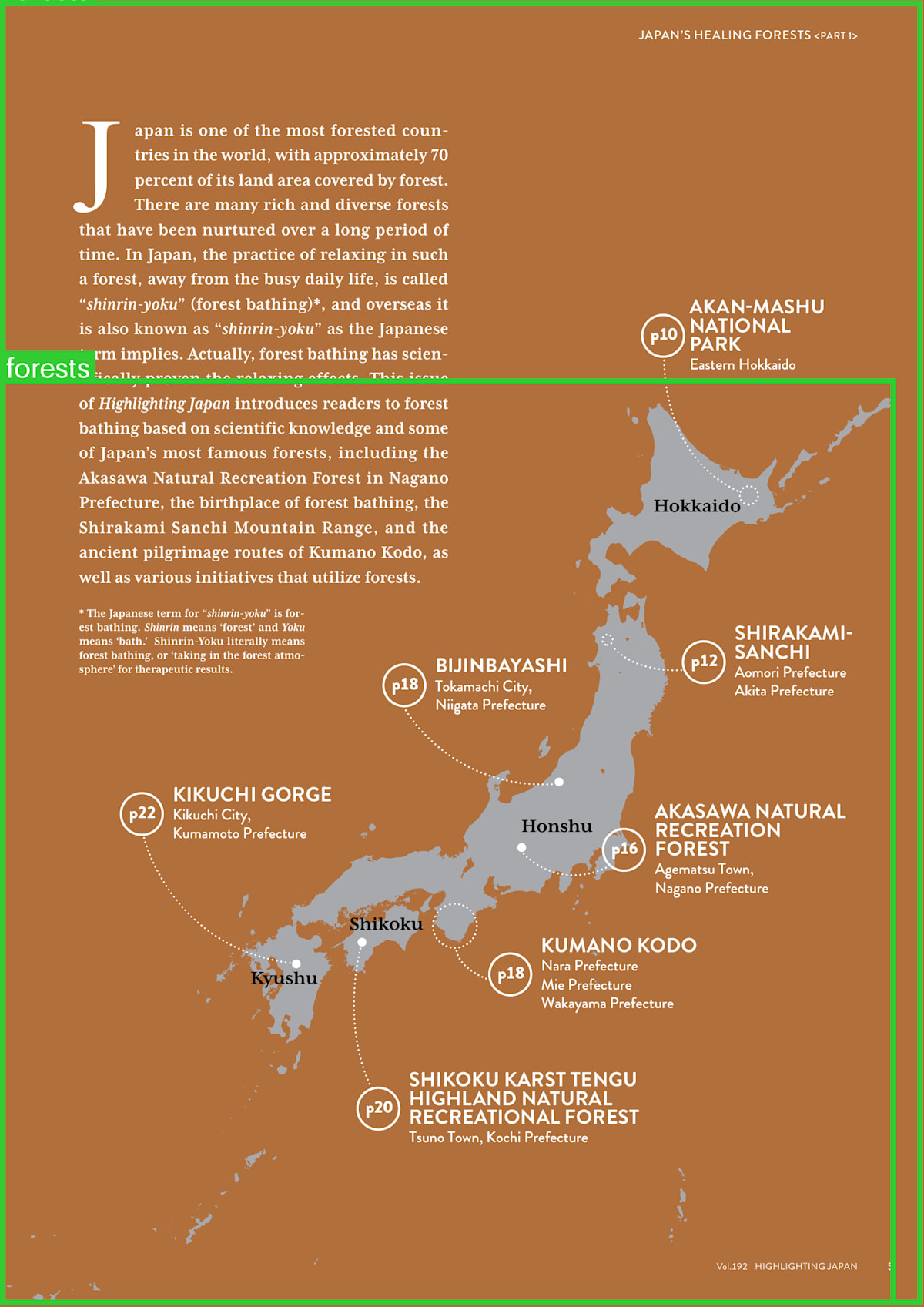
- 11ページ目 スコア 9.5

検索でスコアが一番高かった5ページ目の画像を確認すると、日本の地図と代表的な森林を表すマップが確認できます。検索クエリで指定した「Recommended forests」の検索結果としてうまくいってそうです。
画像には、「forests」のラベルが付けられたバウンディングボックスが配置されています。
翻訳あり
次は翻訳あり(translate = True)で実行してみます。
検索クエリ(query)は「おすすめの森」、出力する検索結果のページ数(top_k)は上位スコア2ページに設定しました。
ページとスコア、画像キャプション、抽出したテキストの出力は以下となります(長いため折りたたんでいます)。
出力(日本語)
ページ: 5 スコア: 9.5625
===================================================================
画像のキャプション-------------------------------------------------
地図は日本の美しい森林の位置を示しており、オレンジの色で分割されています。各部分は異なるタイプの森林を表しています。
左上の地図の頂点には「J」の文字が中央に配置されており、これが森林の名前の可能性があります。その下には、「キクチガード」、「ビジンバヤシ」、「ホンスホ」、「アカシマ自然林」、「クマノコド」という森林の名前のリストがあります。地図には、使用されている色の説明を含む階層もあります。
地図の右側には、日本の森林の異なるタイプを表す小さな円が配置されています。これらの円は名前がラベル付けされており、グリッド状の配置になっています。インフォグラフィックの背景は白色で、テキストは黒色です。
-------------------------------------------------------------------
抽出したテキスト-------------------------------------------------
日本の治癒の森は世界で最も森林豊かな国の一つで、約70%の陸地が森に覆われています。
日本では、このような森でリラックスすることを「森林浴(しんrin-よく)」と呼び、海外でも「森林浴」として知られています。実際に、森林浴は科学的にも癒し効果が証明されています。この号「高輝く日本」では、科学的な知識に基づいて、日本の有名な森林、例えば、長野県のアカサワ自然温泉公園、北海道の白神山脈、古のカムイオードの旅のルート、そして森を活用したさまざまな取り組みなどを紹介しています。
* 「森林浴」という日本語の用語は、「森」を意味する「しんrin」と「入る」を意味する「よく」を組み合わせたもので、「森を浴びる」という意味を持ちます。これは、森の空間を満喫して癒しを得ることを指しています。
(注:文章には不正確な文字が含まれているため、正しい日本語の翻訳には修正が加えられています。)
-------------------------------------------------------------------
===================================================================
ページ: 11 スコア: 9.5
===================================================================
画像のキャプション-------------------------------------------------
画像は「日本の癒しの森」と題された本の一コマです。上部は森林の写真で、高い木々と明るい青空が映し出されています。木は緑で高く、空は明るい青です。画像は木が主体で、他の木は見えません。
下部には、右側に向かって立つ黒い鳥の写真があります。鳥の嘴が開いて飛び立つ準備を示しています。樹冠は白い花で覆われ、少数の小さな白い花も周囲に点在しています。背景はぼやけていますが、森林と低木が見えるようです。ページの文字は黒で小さなフォントで書かれています。
-------------------------------------------------------------------
抽出したテキスト-------------------------------------------------
森林浴を楽しむことができる日本の樫栗杉(さかくりすぎ)*森が右側の堅平観光センターから広がる
他の湖と湿地帯にもあります。他のものは『マシュー地域』と呼ばれ、水の湿気と流れを感じることができる、カルデラ湖(カストラロデラカルデラ)とマシュー湖の一つである
スエヒロには、マシューとアカン地域の森林を楽しむ方法を教えてもらいました。
マシューから始まる『ツツジガハラ自然トレイル』は、カンゾウ温泉の熱泥地域のKawayu観光センターから約1時間の歩ける平坦な道で、珍しい生態系を持つ貴重な場所です。
写真:アカンマシュー国立公園
日本の癒しの森林 <部1>
イソアザレアの花が森に広がる
しかし、前身のマエダ・マサナは、「この山は伐採されるべきではなく、見るべきものに変えるべきだ」と考え、自然の力を尊重しつつ最大限に活用する原則に基づき、長期的な努力で、森林を元の状態に保ち、将来の世代に伝えることに努めてきました。
入場可能な『ハイキリノモリ(神秘の森)』と『コホクノモリ(湖の森)』を兼ね差し出す資格のあるイポエン森林ガイドによるガイド付きの森林散策をお勧めします。多彩な興味深いポイントには、800年以上の古木として知られる大きなカツヤ(カツヤ)の木も含まれます。
黒漆鳥、マエダ・イポエン基金の保護された自然宝石としても知られています。
火山ガスと酸性土壌を生き延ばすアルプス植物も見られる、約2.5キロメートルの短距離の森林を歩くことができる。トレイルは、淡水林区、広葉林区、イソアザレア区を含む短距離内に広がり、早春(約6月)には100ヘクタールの純白のイソアザレアの森が幻想的な美しさを放つ
アカン地域では、マエダ・イポエン基金*によって管理されている森林を探索するガイド付きツアーをお勧めします。
1900年代初頭に、アカン地域の森林に大量に木を伐採して牧場と木材のために開けたことから、熱泥湖の森林浴体験を提案しています。
アカンマシュー国立公園は、全国の国立公園を楽しむプロジェクトに参加しています。
スエヒロは、海外の訪問者に公園をよりアクセスしやすくするための多様なプロジェクトに取り組んでおり、独特で壮大なアカンマシューの森林を楽しむことを願っています。
噴火による溝。
2. 小さな冷涼な広葉樹、北海道原産のもので、30-70cmの高さ。石灰岩のアルプス地域や火山灰地帯に見られ、一部の火山灰地帯にも生えています。
3. 北海道と本州の山のマエダ・スプリングスと共に、北海道の木として指定されています。
4. マエダ・イポエン基金*を設立し、マエダ・マサナの夢で広がる山の森林を保護し、適切な利用を支援するための基金です。
Vol.192 HIGHLIGHTING JAPAN
写真:アカンマシュー国立公園
ii
-------------------------------------------------------------------
===================================================================
ColPaliによるページ検索の処理時間: 00h:00m:00.3s
全体の処理時間(モデルの読み込み時間を含む): 00h:08m:16.5s
固有名詞がカタカナで多少わかりにくいところはありますが、日本語として一目で内容が理解できるのはありがたいです。
処理時間は以下です。
ColPaliによるページ検索の処理時間: 00h:00m:00.3s
全体の処理時間(モデルの読み込み時間を含む): 00h:08m:16.5s
ColPaliによるページ検索(32ページ)の処理は0.3秒で完了しています。
全体の処理時間については、翻訳処理が追加されたため数倍(00h:01m:52.9s → 00h:08m:16.5s)に伸びています・・・。
処理時間に関しては環境にも大きく依存しますが、時間が気になる場合、4bit量子化や翻訳に使うモデルをより小さいモデル(EZO-Common-T2-2B-gemma-2-itやQwen2-1.5B-Instructなど)に変更するのもありかと思います。
(保存されるページ画像については、先ほど(翻訳なし)と同じ結果のため省略します。)
次は、別のページが検索結果として出てくるように検索クエリを変えて試してみます。
実行結果_2
翻訳なし
検索クエリ(query)を「What is "Wagashi"?」、出力する検索結果のページ数(top_k)は上位スコア1ページに設定しました。
ページとスコア、画像キャプション、抽出したテキストの出力は以下となります(長いため折りたたんでいます)。
出力(英語)
ページ: 28 スコア: 13.1875
===================================================================
画像のキャプション-------------------------------------------------
The image is an advertisement for a Japanese dish called "Art Inspired by the Seasons: Wagashi". The dish is displayed on a white plate with a pair of chopsticks resting on top of it. The dish appears to be a type of Japanese dumpling, with a white base and a dark brown filling on top. The filling is made up of small pieces of meat and vegetables, and is drizzled with a dark sauce. The plate is garnished with a sprig of green leaves. The background is a light pink color, and there is text on the right side of the image that reads "Series: Discovering Japan through the eyes of Japanese food".
-------------------------------------------------------------------
抽出したテキスト-------------------------------------------------
28
n spring, there are many light-
colored sweets that evoke the
image of budding plants. Sakura
mochi, a typical example of
spring wagashi, comes in two styles:
Kansai style and Kanto style.? Kan-
sai-style sakura mochi are light pink
mochi glutinous rice cakes filled with
azuki bean paste (with some beans
left whole) and wrapped in pickled
sakura cherry leaves. In the Kanto
region, the azuki bean paste is rolled
in a crepe-like dough, which is then
wrapped in a pickled sakura cherry
HIGHLIGHTING JAPAN MAY 2024
» -.Minazuki, a type of wagashi that embodies wishes for
good health and happiness
leaf. Sakura mochi is so popular, it can
even be found in convenience stores
and supermarkets outside of the
spring season.
uring the hot and humid
Japanese summer, cool-
looking smooth sweets
made with agar or kuzu
are especially popular. Minazuki is a
wagashi made with a jelly-like base
made to resemble a small piece of
ice and topped with azuki beans. In
Japan, the color red is traditionally
—
believed to keep evil spirits away, so
this wagashi, with the hope that the
red beans on top will do just that,
symbolizes wishes for good health
and happiness.
s the season of chest-
nuts and sweet potatoes,
autumn is known for
wagashi such as kuri-kinton
(candied chestnuts and sweet pota-
toes) and imo-yokan (sweet potato
jelly). Besides, there is also a genre
of Japanese confectionery called
—
Photo: PITA
-------------------------------------------------------------------
===================================================================
ColPaliによるページ検索の処理時間: 00h:00m:00.6s
全体の処理時間(モデルの読み込み時間を含む): 00h:01m:37.1s
キャプションの説明では、和菓子が肉と野菜の料理として説明されているなど若干怪しい部分はありますが、検索では問題なく和菓子のページを取得出来ています。
処理時間は以下です。
ColPaliによるページ検索の処理時間: 00h:00m:00.6s
全体の処理時間(モデルの読み込み時間を含む): 00h:01m:37.1s
以下は、コード実行時に作成される検索結果のページ(画像)です。
- 28ページ目 スコア 13.1875

バウンディングボックスのラベルには「wagashi」と記載されており座標もきちんと取れています。
翻訳あり
検索クエリ(query)を「「和菓子」とは何ですか?」、出力する検索結果のページ数(top_k)は上位スコア1ページに設定しました。
ページとスコア、画像キャプション、抽出したテキストの出力は以下となります(長いため折りたたんでいます)。
出力(日本語)
ページ: 28 スコア: 12.9375
===================================================================
画像のキャプション-------------------------------------------------
画像は日本料理「四季にインスピレーションを受けたアート:わがし - 日本食を見る目」の広告です。料理は白い皿に置かれ、上には箸が置かれています。料理は日本の皮箱蒸しのようなもので、白い基盤と上に黒褐色の具材で埋められたダークトップがあります。具材は小さな肉と野菜で構成され、暗いドレッシングで漬けられています。皿は緑の葉で飾られており、背景は薄いピンク色です。画像右側には「日本を食べる目を発見」という文字が記されています。
-------------------------------------------------------------------
抽出したテキスト-------------------------------------------------
春には、桜のような色の甘いスナックが多く、桜の花びらを思わせるものが多い。関西風の桜餅は、桜の葉に包まれた小麦粉のあずき餡とともに、一部のあずきが残っているもので、辛子桜の葉で包まれている。東京地方では、あずき餡がクレープのような皮で巻かれ、それを辛子桜の葉で包んでいる。
2024年5月の高評価
- ミナズキ、健康と幸福を象徴する願望のある団子
桜餅は夏の熱気と湿度の厳しい日本でも人気があり、コンビニやスーパーでも見かけることができる。
夏の暑い日本の季節には、アガやクズを使った見た目の涼しげなスナックが人気を集める。ミナズキは、アガやクズで作られたジェル状のベースを持ち、あずきをのせ、伝統的には悪霊を遠ざけるために赤いあずきが象徴する健康と幸福の願いを表している。
秋には、栗きんとん(焼き栗と甘ねぎ)やいもよかん(甘ねぎジェル)などの団子が有名で、さらには日本の甘味料である団子のジャンルがある。
(注: 翻訳は文章の内容に基づいており、日本語の流暢さと文法に焦点を当てています。)
-------------------------------------------------------------------
===================================================================
ColPaliによるページ検索の処理時間: 00h:00m:00.2s
全体の処理時間(モデルの読み込み時間を含む): 00h:04m:03.4s
処理時間は以下です。
ColPaliによるページ検索の処理時間: 00h:00m:00.2s
全体の処理時間(モデルの読み込み時間を含む): 00h:04m:03.4s
(保存されるページ画像については、先ほど(翻訳なし)と同じ結果のため省略します。)
実行結果_3
翻訳なし
検索クエリ(query)を「Map of the "Kumano Kodo"」、出力する検索結果のページ数(top_k)は上位スコア1ページに設定しました。
ページとスコア、画像キャプション、抽出したテキストの出力は以下となります(長いため折りたたんでいます)。
出力(英語)
ページ: 18 スコア: 15.5
===================================================================
画像のキャプション-------------------------------------------------
The image is a page from a magazine article titled "Exploring 'Kumano Kodo', a Forest-Enveloped World Cultural Heritage Site". The page is divided into two sections. The top section is titled "Features" and has a map of the world on the right side. Below the map, there is text that explains the features of the article.
The bottom section has a photo of a forest with tall trees and a person walking through it. The person is wearing a traditional Japanese outfit and is walking on a path that winds through the trees. The trees are tall and lush, and the sunlight is shining through the branches, creating a warm glow on the scene. The background is white, and there is a small illustration of a mountain range in the top right corner.
-------------------------------------------------------------------
抽出したテキスト-------------------------------------------------
18
FEATURES
Exploring
‘Kumano Kodo, a
Forest-Enveloped
World Cultural
Heritage Site
The Kii Peninsula, Japan’s largest, lies
slightly west from the central area of Honshu,
extending into the Pacific Ocean. Within the
Kii Peninsula, trails known as the ‘Kumano
Kodo’ have been preserved since ancient
times. A section of these routes has been des-
ignated as a UNESCO World Cultural Her-
itage Site,’ making it one of the rare trails
worldwide to receive such recognition. This
year, 2024, marks the 20th anniversary of
the listing of the ‘Sacred Sites and Pilgrimage
Routes in the Kii Mountain Range,’ which
includes the Kumano Kodo routes. Here, we
take a look at Kumano Kodo, situated amid
the forests of the Kii Mountains.
(Text: Morohashi Kumiko)
he majority of the Kii Peninsula is occupied by
mountainous terrain, known as the Kii Moun-
tain Range, which spans the three prefectures
Apilgrimage route leading to three sacred sites known as Kumano Sanzan.
The model in the photograph is wearing attire typical of upper-class ladies
during the medieval period, often worn while traveling.
HIGHLIGHTING JAPAN MAY 2024
‘Mount Koya
Kumano
Hongu Taisha
Kumano.
Hayatama
Taisha
== Nakahechi
=== Kohechi === Ohechi
of Mie, Nara, and Wakayama. The mountain range
with elevations ranging from 1,000 to 2,000 meters
runs from East to West and from North to South and is
characterized by a warm and extremely rainy climate,
nurturing rich forests over the years.
To the southeast lies a sacred site known as
‘Kumano Sanzan,’ primarily comprising three shrines
and two temples. This site has been a center of faith
for centuries and is recognized as a vital component of
the World Cultural Heritage Site. Near one of the three
grand shrines, Kumano Hongu Taisha (located in
Tanabe City, Wakayama Prefecture), sits the Kumano
Hongu Heritage Center, dedicated to the dissemina-
tion of tourist information and local information. We
spoke with Sugawa Aki who works at the center.
“The region centered around Kumano Sanzan,
enveloped by the natural beauty of the Kii Mountain
Range and known as ‘Kumano,’ has been revered as
a sacred place dedicated to the gods since ancient
times. Furthermore, from the 10th to the lth cen-
tury onwards, former emperors and monk emper-
ors as well as nobles, frequently visited this sacred
area on journeys known as Kumano pilgrimages. I
believe that’s why the trails were so well maintained,”
explains Sugawa.
“Kumano Kodo is a collective term referring to
Amountain forest along the Kumano Kodo, which includes numerous
subsidiary shrines called “Oji,” meaning “prince,” dedicated to the divine
offspring of Kumano Sanzan.
Photo: Kumano Hongu Heritage Center
-------------------------------------------------------------------
===================================================================
ColPaliによるページ検索の処理時間: 00h:00m:00.9s
全体の処理時間(モデルの読み込み時間を含む): 00h:01m:38.7s
処理時間は以下です。
ColPaliによるページ検索の処理時間: 00h:00m:00.9s
全体の処理時間(モデルの読み込み時間を含む): 00h:01m:38.7s
- 18ページ目 スコア 15.5

右上のマップ部分をしっかりと囲ってくれています。
翻訳あり
検索クエリ(query)を「熊野古道のマップ」、出力する検索結果のページ数(top_k)は上位スコア1ページに設定しました。
ページとスコア、画像キャプション、抽出したテキストの出力は以下となります(長いため折りたたんでいます)。
出力(日本語)
ページ: 18 スコア: 13.0
===================================================================
画像のキャプション-------------------------------------------------
画像は「熊野古道」と題された世界文化遺産の記事の一面です。ページは2つの部分に分かれています。上部は「特徴」と題され、右側に世界地図が配置されています。地図の下には、記事の特徴を説明するテキストがあります。
下部には、高く茂った木々の中を歩く人物の写真があります。その人物は伝統的な日本の衣装を着用し、木々の間を緩やかに進む道を歩いています。木々は豊かで高く、枝からの光が木々の間を通して柔らかな光沢を放ち、シーンに温かい雰囲気を与えています。背景は白色で、上部右上には小さな山脈のイラストが描かれています。
-------------------------------------------------------------------
抽出したテキスト-------------------------------------------------
大阪桃子が主催する、日本の山岳地帯、紀伊半島の森林覆いに包まれた世界文化遺産地区「キマノ」についての見識を探る。
紀伊半島は日本の最大の半島で、中部の中心からわずかに西に位置し、太平洋に臨む。この紀伊半島には、古代から保存されている「キマノ・コード」と呼ばれるトレイルが存在する。2024年は、これらのルートが世界遺産に認定されて20年目を迎える。これは世界でも稀なトレイルの一つである。
「キマノ」は、紀伊山地の森林に囲まれた場所に位置し、この地区の中心として歴史的に信仰されてきた。
紀伊山地は東西に伸び、南北にも延び、1,000~2,000メートルの高度差を持つ。温暖で激しい雨量により、この地域には豊かな森林が育まれてきた。
東南に位置する「キマノ・サンサン」という聖地は、主に三つの神社と二つの寺院から構成されている。この聖地は、長い歴史の中で信仰の中心として崇敬されてきた。この地区は、世界遺産の一部として認められている。
「キマノ・サンサン」の一つ、「キマノ・ホウグ・タイシ」(田辺市、和歌山県)には、「キマノ・コード」の案内と地域情報を提供する「キマノ・ホウグ・タイシ・ハーベスト・センター」が立地している。ここでは、桃子さんという方が勤務しており、話を聞いた。
「紀伊半島、特に『キマノ』は、古代から神聖なる場所として崇敬されてきた。また、10世紀から10世紀の間に、元上皇や仏皇帝、貴族がこの聖地を訪れることが多く、これが『キマノ・コード』のようなトレイルが良好に保存されている理由だと思う。」と桃子さんは説明してくれた。
「『キマノ・コード』とは、この地区に広がる森林の中に点在する「オジ」と呼ばれる尊崇される子孫神社の集合を指す。」
(注: 「オジ」は「王子」の意味で、これらの神社は「キマノ・サンサン」の子孫として崇敬されている。)
-------------------------------------------------------------------
===================================================================
ColPaliによるページ検索の処理時間: 00h:00m:00.4s
全体の処理時間(モデルの読み込み時間を含む): 00h:05m:16.6s
処理時間は以下です。
ColPaliによるページ検索の処理時間: 00h:00m:00.4s
全体の処理時間(モデルの読み込み時間を含む): 00h:05m:16.6s
(保存されるページ画像については、先ほど(翻訳なし)と同じ結果のため省略します。)
おわりに
今回は気になっていた3つのモデルを使いPDF(画像 + テキスト)を処理してみました。どれも軽量なため試しやすかったです。
-
ColPali
画像からでもいい感じに検索できるということで気になっていましたが、精度 & 速度が想定以上でした。テキストの抽出が必要ないため(画像から埋め込みを作成するため)使い勝手もよく、PDFだけでなく様々なユースケースで扱えそうです。 -
Florence-2-large
今回は画像が多い、または主題のページでも全体の意味が把握できるように視覚言語モデルとしてこちらのモデルを使ってみました。写真や絵の説明だけでなく文章が散らばっていてもある程度認識して説明してくれるのはありがたいです。 -
Borea-Phi-3.5-mini-Instruct-Jp
翻訳用としてのモデルではないのですが、全体的な性能(特に日本語)が高く気になっていたので使ってみました。
固有名詞の翻訳が難しいことと、画像からテキスト抽出したものを翻訳しているためうまくいかない部分はありましたが、文章としては自然に近い形で翻訳してくれました。
今回は行いませんでしたが、出力したテキストをRAGのコンテキストとして利用する場合はそのまま、このモデルで処理するなどもありかと思います。
また機会があればよろしくお願いします。
※ 記事を書いている間にQwenから「Qwen2-VL(2B, 7B, 72B)」がリリースされました。多言語に対応(日本語でも可)しています。
こちらのモデルを視覚言語モデルとして採用してみるのもありかと思います(「Qwen2-VL-2B-Instruct」あたりは小さいため試しやすそうです)。
参考記事:
参考記事
Discussion