RAG Fusion と CRAGの組み合わせを試してみた
はじめに
今回はRAGの手法「RAG Fusion」と「CRAG」の組み合わせを実験的に試してみます。
RAG Fusion
通常のRAGの実装では一つの質問に対してインデックスからドキュメントの検索を行い、検索結果をそのままコンテキストとしてllmに渡します。
RAG Fusionでは、通常のRAGに「類似した質問の生成」と「リランキング(Reciprocal Rank Fusion)」の要素が加わります。類似した質問を使い検索することで、取得するドキュメントの多様性を得られるのが主な利点です。
質問から回答までの流れは以下のようになります。
一つの質問から複数の類似した質問を生成
↓
生成した質問(+ オリジナルの質問)それぞれでインデックスからドキュメントを類似検索
↓
検索結果をリランキング(ドキュメントごとのスコアを算出)して上位のスコアを持つドキュメントを抽出
↓
抽出したドキュメントをコンテキストとしてllmに渡して回答を生成
リランキングに使う(ドキュメントのスコアを算出する)計算式は以下です。
例として以下のドキュメントBのスコアを計算してみます。
| ドキュメント | 質問Aにおける類似度順位 | 質問Bにおける類似度順位 | 質問Cにおける類似度順位 |
|---|---|---|---|
| A | 1位 | 2位 | 3位 |
| B | 1位 | 3位 | 2位 |
| C | 2位 | 3位 | 1位 |
| D | 3位 | 1位 | 2位 |
質問ごとの数値を以下で計算します。
- 質問Aの数値 = 1 / (60 + 1) ≈ 0.01639
- 質問Bの数値 = 1 / (60 + 3) ≈ 0.01587
- 質問Cの数値 = 1 / (60 + 2) ≈ 0.01613
次にそれぞれの数値を足し合わせればスコアが計算できます。
- 0.01639 + 0.01587 + 0.01613 = 0.04839
上記のようにしてドキュメントごとにスコアを算出した後、上位のスコアを持つドキュメントをコンテキストとして使用します。
CRAG(Corrective Retrieval Augmented Generation)
CRAGでは、通常のRAGに「ドキュメントに関連する内容が「ある」「ない」「曖昧」の評価機能」、「関連性がない場合、Web検索を実行する機能」、「知識の洗練」の要素が加わります。関連性のチェックが入るためハルシネーションを減らせるというのが主な利点です。
※今回の実装では以下の2点を省略しています。
- 「ドキュメントに関連する内容が「ある」「ない」「曖昧」の評価機能」において「曖昧」の評価(今回は関連性が「ある」「なし」の二択で評価します)
- 「知識の洗練」
質問から回答までの流れは以下のようになります。
質問文でインデックスからドキュメントを検索して取得
↓
取得したドキュメントに関連する内容があるかないかを評価
↓
関連性がない場合はWeb検索を行いドキュメントに情報を追加
↓
ドキュメント(+ Web検索結果)をコンテキストとしてllmに渡して回答を生成
RAG FusionとCRAGの組み合わせについて
RAG Fusionだけでは、取得した(インデックス内の)ドキュメントでランキング上位だとしても実際には質問との関連性がないこともあります。そこで、CRAGの関連性評価フィルター(+ Web検索)と組み合わせることで関連性のないドキュメントを弾き、足りない場合はWeb検索を行い情報を補強できるようにします。
このようにすることでRAG Fusionによる情報の多様性を持ちながら関係性のないドキュメントによるハルシネーションを防ぐというのが狙いです。
質問から回答までの流れは以下のようになります。
一つの質問から複数の類似した質問を生成
↓
生成した質問(+ オリジナルの質問)それぞれでインデックスからドキュメントを類似検索
↓
検索結果をリランキング(ドキュメントごとのスコアを算出)して上位のスコアを持つドキュメントを抽出
↓
生成した質問(+オリジナルの質問)を一つの質問に統合
↓
統合した質問文とドキュメントの関連性(があるかないか)を評価
↓
関連性がない場合はWeb検索を行いドキュメントに情報を追加
↓
ドキュメント(+ Web検索結果)をコンテキストとしてllmに渡して回答を生成
RAG Fusion × CRAGの実装
実装ではlangGraphを使用しています。
langGraphの使い方については以下で解説しています(今回使用するモデルのClaude 3、検索ツールのTavilyについても紹介しています)。
Nodeと分岐Edgeの定義
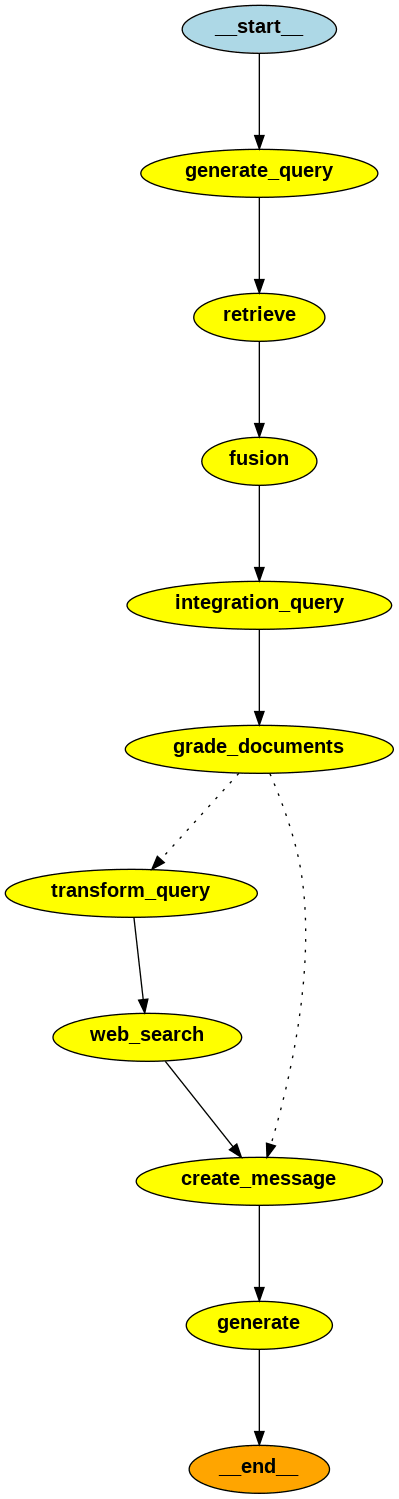
今回の実装におけるNode、分岐Edgeの名前(コード内での関数名)と処理内容は以下となります(サイクルの処理がないため上から下の一方通行です)。
| Node or 分岐Edge | 関数名 | 処理内容 |
|---|---|---|
| Node | generate_query | 元の質問文から類似した質問文を生成 |
| Node | retrieve | 生成した質問(+オリジナルの質問)でインデックスからドキュメントを取得 |
| Node | fusion | ドキュメントのスコアを計算して上位のものを抽出 |
| Node | integration_query | 生成した複数の質問(+オリジナルの質問)を一つの質問に統合 |
| Node | grade_documents | 統合した質問とドキュメントの関連性を評価 |
| 分岐Edge | decide_to_generate | 関連性の評価によってWeb検索の要否を決定 |
| Node | transform_query | 統合した質問をWeb検索クエリに変換 |
| Node | web_search | Web検索を実行して結果を取得 |
| Node | create_message | llmに渡すメッセージを作成 |
| Node | generate | llmからの回答を生成 |
グラフ図にすると以下のようになります。
モデル
モデルにはClaude 3の「Haiku」、「Sonnet」、「Opus」を使用しています。
実装内では(Nodeごとに)以下のようにモデルを使い分けています。
-
Haiku
- grade_documents(統合した質問とドキュメントの関連性を評価)
-
Sonnet
- integration_query(生成した複数の質問(+オリジナルの質問)を一つの質問に統合)
- transform_query(統合した質問をWeb検索クエリに変換)
- generate(llmからの回答を生成)
-
Opus
- generate_query(元の質問文から類似した質問文を生成)
コンテキストの量が多い場合は「Haiku」、コンテキストの量が少なく精度が必要な場合は「Opus」、コンテキストの量、精度が程々な場合は「Sonnet」 という観点で使い分けました。
準備
ライブラリのインストール
# LangChain、LangGraph用ライブラリ
$ pip install langchain
$ pip install langchain-community
$ pip install langgraph
$ pip install langchain_anthropic
# インデックス用ライブラリ
$ pip install unstructured
$ pip install sentence-transformers
$ pip install faiss-gpu
インデックスの準備
今回はWikipediaから情報を取得してインデックスを作成しました。
以下はインデックスの作成に使用したコードです(FAISSを使用しています)。
from langchain_community.vectorstores.faiss import FAISS
from langchain_community.embeddings.huggingface import HuggingFaceEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import DirectoryLoader
# 資料の格納場所(ディレクトリ)
data_dir = "./data"
# ベクトル化したインデックスの保存場所(ディレクトリ)
index_path = "./storage"
# ディレクトリの読み込み
loader = DirectoryLoader(data_dir)
# 埋め込みモデルの読み込み
embedding_model = HuggingFaceEmbeddings(
model_name="intfloat/multilingual-e5-large"
)
# テキストをチャンクに分割
split_texts = loader.load_and_split(
text_splitter=RecursiveCharacterTextSplitter(
chunk_size=300,
chunk_overlap=75
)
)
# インデックスの作成
index = FAISS.from_documents(
documents=split_texts,
embedding=embedding_model,
)
# インデックスの保存
index.save_local(
folder_path=index_path
)
FAISSを使ったindexの作成、読み取りについては以下に記載しています。興味があればご確認ください。
コーディング
RAG Fusion × CRAGの実装コード(全体)は以下となります。
import io
import os
import operator
from typing import List, TypedDict, Sequence, Annotated
from langchain_core.messages import BaseMessage
from langchain.prompts.chat import ChatPromptTemplate
from langchain_anthropic import ChatAnthropic
from langchain_community.retrievers import TavilySearchAPIRetriever
from langchain_community.vectorstores.faiss import FAISS
from langchain.schema import Document
from langchain_community.embeddings.huggingface import HuggingFaceEmbeddings
from langgraph.graph import StateGraph, END
from langchain_core.output_parsers import StrOutputParser
os.environ["TAVILY_API_KEY"] = ""
os.environ["ANTHROPIC_API_KEY"] = ""
class GraphState(TypedDict):
llm_haiku: ChatAnthropic # Claude 3「Haiku」モデル
llm_sonnet: ChatAnthropic # Claude 3「Sonnet」モデル
llm_opus: ChatAnthropic # Claude 3「Opus」モデル
emb_model : HuggingFaceEmbeddings # Embeddingモデル
question: str # 質問文
generate_querys: List[str] # 生成(追加)した質問文
generate_query_num: int # 生成(追加)する質問の数
integration_question: str # 統合した質問文
transform_question: str # Web検索用クエリに変換した質問文
messages: Annotated[Sequence[BaseMessage], operator.add] # メッセージの履歴
fusion_documents : List[List[Document]] # 生成した質問文で検索したドキュメント
documents: List[Document] # 最終的にllmに渡すドキュメント
is_search : bool # web検索の要否
# 元の質問文から類似した質問文を生成
def generate_query(state):
print("\n--- __start__ ---")
print("--- generate_query ---")
llm = state["llm_opus"]
question = state["question"]
generate_query_num = state["generate_query_num"]
system_prompt = "あなたは、1つの入力クエリに基づいて複数の検索クエリを生成するアシスタントです。"
human_prompt = """クエリを作成する際は、元のクエリの意味を大きく変えず一行ずつ出力してください。
入力クエリ: {question}
{generate_query_num}つの出力クエリ:
"""
prompt = ChatPromptTemplate.from_messages(
[
("system", system_prompt),
("human", human_prompt)
]
)
questions_chain = prompt | llm | StrOutputParser() | (lambda x: x.split("\n"))
generate_querys = questions_chain.invoke(
{
"question": question,
"generate_query_num": generate_query_num
}
)
generate_querys.insert(0, "0. " + question)
print("\nオリジナルの質問 + 生成された質問==========================")
for i, query in enumerate(generate_querys):
print(f"\n{query}")
print("\n===========================================================\n")
return {"generate_querys": generate_querys}
# 生成した質問(+オリジナルの質問)でインデックスからドキュメントを取得
def retrieve(state):
print("--- retrieve ---")
emb_model = state['emb_model']
generate_querys = state["generate_querys"]
index = FAISS.load_local(
folder_path= "./storage",
embeddings=emb_model,
allow_dangerous_deserialization=True
)
fusion_documents = []
for question in generate_querys:
docs = index.similarity_search(question, k=3)
fusion_documents.append(docs)
return {"fusion_documents": fusion_documents}
# ドキュメントのスコアを計算して上位のものを抽出
def fusion(state):
print("--- fusion ---")
fusion_documents = state["fusion_documents"]
k = 60
documents = []
fused_scores = {}
for docs in fusion_documents:
for rank, doc in enumerate(docs, start=1):
if doc.page_content not in fused_scores:
fused_scores[doc.page_content] = 0
documents.append(doc)
fused_scores[doc.page_content] += 1 / (rank + k)
reranked_results = {doc_str: score for doc_str, score in sorted(fused_scores.items(), key=lambda x: x[1], reverse=True)[:3]}
print("\n検索上位3つのスコア========================================")
for i, score in enumerate(reranked_results.values(), start=1):
print(f"\nドキュメント{i}: {score}")
print("\n===========================================================\n")
filterd_documents = []
for doc in documents:
if doc.page_content in reranked_results:
filterd_documents.append(doc)
documents = filterd_documents
return {"documents": documents}
# 生成した複数の質問(+オリジナルの質問)を一つの質問に統合
def integration_query(state):
print("--- integration_query ---")
llm = state["llm_sonnet"]
generate_querys = state["generate_querys"]
system_prompt = """あなたは、入力された複数の質問を1つの質問に統合する質問リライターです。"""
human_prompt = """統合した1つの質問のみを出力してください。
複数の質問: {query}
統合した質問: """
prompt = ChatPromptTemplate.from_messages(
[
("system", system_prompt),
("human", human_prompt),
]
)
integration_chain = prompt | llm | StrOutputParser()
questions = "\n".join(generate_querys)
integration_query = integration_chain.invoke({"query": questions})
print(f"\n統合した質問: {integration_query}\n")
return {"integration_question": integration_query}
# 統合した質問とドキュメントの関連性を評価
def grade_documents(state):
print("--- grade_documents ---")
llm = state["llm_haiku"]
integration_question = state["integration_question"]
documents = state["documents"]
system_prompt = """あなたは、検索された文書とユーザーの質問との関連性を評価するアシスタントです。
文書に質問に関連するキーワードまたはセマンティックな内容を含んでいる場合、あなたはそれを関連性があると評価します。
関連性があれば"Yes"、関連性がない場合は"No"とだけ答えてください。"""
human_prompt = """
文書: {context}
質問: {query}
関連性("Yes" or "No"): """
prompt = ChatPromptTemplate.from_messages(
[
("system", system_prompt),
("human", human_prompt),
]
)
filtered_docs = []
is_search = False
grade_chain = prompt | llm | StrOutputParser()
print("\nドキュメントごとの関連性の評価=============================")
for doc in documents:
grade = grade_chain.invoke({"context":doc.page_content, "query": integration_question})
print(f"\n関連性: {grade}")
if "Yes" in grade:
filtered_docs.append(doc)
else:
is_search = True
print("\n===========================================================\n")
return {"documents": filtered_docs, "is_search": is_search}
# 関連性の評価によってWeb検索の要否を決定
def decide_to_generate(state):
print("--- decide_to_generate ---")
is_search = state['is_search']
if is_search == True:
return "transform_query"
else:
return "create_message"
# 統合した質問をWeb検索クエリに変換
def transform_query(state):
print("--- transform_query ---")
llm = state["llm_sonnet"]
integration_question = state["integration_question"]
system_prompt = """あなたは、入力された質問をWeb検索に最適化されたクエリに変換するリライターです。"""
human_prompt = """質問を見て、根本的な意味/意図を推論してWeb検索クエリのみ出力してください。
質問: {query}
Web検索クエリ: """
prompt = ChatPromptTemplate.from_messages(
[
("system", system_prompt),
("human", human_prompt),
]
)
transform_chain = prompt | llm | StrOutputParser()
transform_query = transform_chain.invoke({"query": integration_question})
print(f"\nWeb検索用クエリ: {transform_query}\n")
return {"transform_question": transform_query}
# Web検索を実行して結果を取得
def web_search(state):
print("--- web_search ---")
transform_question = state["transform_question"]
documents = state["documents"]
retriever = TavilySearchAPIRetriever(k=3)
docs = retriever.invoke(transform_question)
documents.extend(docs)
return {"documents": documents}
# llmに渡すメッセージを作成
def create_message(state):
print("--- create_message ---")
documents = state["documents"]
question = state["question"]
system_message = "あなたは常に日本語で回答します。"
human_message ="""次の「=」で区切られたコンテキストを参照して質問に答えてください。
{context}
Question: {query}
"""
prompt = ChatPromptTemplate.from_messages(
[
("system", system_message),
("human", human_message),
]
)
partition = "\n" + "=" * 20 + "\n"
documents_context = partition.join([doc.page_content for doc in documents])
messages = prompt.format_messages(context=documents_context, query=question)
return {"messages": messages}
# llmからの回答を生成
def generate(state):
print("--- generate ---")
llm = state["llm_sonnet"]
messages = state["messages"]
response = llm.invoke(messages)
print("--- end ---\n")
return {"messages": [response]}
# グラフを構成して実行可能な形式にコンパイル
def get_compile_graph():
graph = StateGraph(GraphState)
graph.set_entry_point("generate_query")
graph.add_node("generate_query", generate_query)
graph.add_edge("generate_query", "retrieve")
graph.add_node("retrieve", retrieve)
graph.add_edge("retrieve", "fusion")
graph.add_node("fusion", fusion)
graph.add_edge("fusion", "integration_query")
graph.add_node("integration_query", integration_query)
graph.add_edge("integration_query", "grade_documents")
graph.add_node("grade_documents", grade_documents)
graph.add_conditional_edges(
"grade_documents",
decide_to_generate,
{
"transform_query": "transform_query",
"create_message": "create_message"
},
)
graph.add_node("transform_query", transform_query)
graph.add_edge("transform_query", "web_search")
graph.add_node("web_search", web_search)
graph.add_edge("web_search", "create_message")
graph.add_node("create_message", create_message)
graph.add_edge("create_message", "generate")
graph.add_node("generate", generate)
graph.add_edge("generate", END)
compile_graph = graph.compile()
return compile_graph
if __name__ == "__main__":
llm_haiku = ChatAnthropic(model_name="claude-3-haiku-20240307")
llm_sonnet = ChatAnthropic(model_name="claude-3-sonnet-20240229")
llm_opus = ChatAnthropic(model_name="claude-3-opus-20240229")
emb_model = HuggingFaceEmbeddings(model_name="intfloat/multilingual-e5-large")
compile_graph = get_compile_graph()
# グラフを実行して結果(llmからの回答)を出力
output = compile_graph.invoke(
{
"llm_haiku": llm_haiku,
"llm_sonnet": llm_sonnet,
"llm_opus": llm_opus,
"emb_model": emb_model,
"question": "葬送のフリーレンの勇者パーティーについて教えてください",
"generate_query_num": 2
}
)
print("output:")
print(output["messages"][-1].content)
上記の内、「Node」と「分岐Edge」の処理を確認します。
元の質問文から類似した質問文を生成
def generate_query(state):
print("\n--- __start__ ---")
print("--- generate_query ---")
llm = state["llm_opus"]
question = state["question"]
generate_query_num = state["generate_query_num"]
system_prompt = "あなたは、1つの入力クエリに基づいて複数の検索クエリを生成するアシスタントです。"
human_prompt = """クエリを作成する際は、元のクエリの意味を大きく変えず一行ずつ出力してください。
入力クエリ: {question}
{generate_query_num}つの出力クエリ:
"""
prompt = ChatPromptTemplate.from_messages(
[
("system", system_prompt),
("human", human_prompt)
]
)
questions_chain = prompt | llm | StrOutputParser() | (lambda x: x.split("\n"))
generate_querys = questions_chain.invoke(
{
"question": question,
"generate_query_num": generate_query_num
}
)
generate_querys.insert(0, "0. " + question)
print("\nオリジナルの質問 + 生成された質問==========================")
for i, query in enumerate(generate_querys):
print(f"\n{query}")
print("\n===========================================================\n")
return {"generate_querys": generate_querys}
グラフ実行の際に「generate_query_num」で渡した数値(今回は2)の分だけ類似した質問文を作成します。
以下でLCELのchainを設定しています。
questions_chain = prompt | llm | StrOutputParser() | (lambda x: x.split("\n"))
prompt | llm | StrOutputParser() の部分はllmからの回答を文字列で返し、
(lambda x: x.split("\n")) は改行で区切ることで一行づつリストに格納する処理です。
実行すると生成した質問が一つずつ入れられたリストが返されます。
promptに関しては以下を参考に和訳して少し変更を加えています。今回は(全体的に)わかりやすいので日本語にしていますが、コスト、精度面で考えた際は英語で記載した方が良いかと思います。
生成した質問(+オリジナルの質問)でインデックスからドキュメントを取得
def retrieve(state):
print("--- retrieve ---")
emb_model = state['emb_model']
generate_querys = state["generate_querys"]
index = FAISS.load_local(
folder_path= "./storage",
embeddings=emb_model,
allow_dangerous_deserialization=True
)
fusion_documents = []
for question in generate_querys:
docs = index.similarity_search(question, k=3)
fusion_documents.append(docs)
return {"fusion_documents": fusion_documents}
オリジナルの質問と生成した質問(合計3つ)のそれぞれでインデックスを検索してドキュメントを取得(類似度の高いドキュメントから降順でリストに格納されます)します。
ドキュメントのスコアを計算して上位のものを抽出
def fusion(state):
print("--- fusion ---")
fusion_documents = state["fusion_documents"]
k = 60
documents = []
fused_scores = {}
for docs in fusion_documents:
for rank, doc in enumerate(docs, start=1):
if doc.page_content not in fused_scores:
fused_scores[doc.page_content] = 0
documents.append(doc)
fused_scores[doc.page_content] += 1 / (rank + k)
reranked_results = {doc_str: score for doc_str, score in sorted(fused_scores.items(), key=lambda x: x[1], reverse=True)[:3]}
print("\n検索上位3つのスコア========================================")
for i, score in enumerate(reranked_results.values(), start=1):
print(f"\nドキュメント{i}: {score}")
print("\n===========================================================\n")
filterd_documents = []
for doc in documents:
if doc.page_content in reranked_results:
filterd_documents.append(doc)
documents = filterd_documents
return {"documents": documents}
リランキング(Reciprocal Rank Fusion)を計算してスコアの上位3つを抽出しています。
上記の処理の流れは以下となります。
for docs in fusion_documents:
for rank, doc in enumerate(docs, start=1):
if doc.page_content not in fused_scores:
fused_scores[doc.page_content] = 0
documents.append(doc)
fused_scores[doc.page_content] += 1 / (rank + k)
ドキュメントの文章をキー、それぞれの質問での順位からスコアを計算して足し合わせたものを値として。辞書(fused_scores)を作成しています。
documentsは重複していないドキュメントのリストです(最終的にここから上位スコア3つのドキュメントを抜き出します)。
reranked_results = {doc_str: score for doc_str, score in sorted(fused_scores.items(), key=lambda x: x[1], reverse=True)[:3]}
fused_scoresをスコア順にソートして上位3つを抽出した新しい辞書(reranked_results)を作成します。
filterd_documents = []
for doc in documents:
if doc.page_content in reranked_results:
filterd_documents.append(doc)
documents = filterd_documents
documentsに対してreranked_resultsでフィルターをかけて上位スコア3つのドキュメントのリストとします。
生成した複数の質問(+オリジナルの質問)を一つの質問に統合
def integration_query(state):
print("--- integration_query ---")
llm = state["llm_sonnet"]
generate_querys = state["generate_querys"]
system_prompt = """あなたは、入力された複数の質問を1つの質問に統合する質問リライターです。"""
human_prompt = """統合した1つの質問のみを出力してください。
複数の質問: {query}
統合した質問: """
prompt = ChatPromptTemplate.from_messages(
[
("system", system_prompt),
("human", human_prompt),
]
)
integration_chain = prompt | llm | StrOutputParser()
questions = "\n".join(generate_querys)
integration_query = integration_chain.invoke({"query": questions})
print(f"\n統合した質問: {integration_query}\n")
return {"integration_question": integration_query}
ドキュメントとの関連性を評価するにあたり、複数の質問を一つに統合しています。
このNodeは、RAG FusionとCRAGをつなぐために作りました。統合せずに質問一つずつの関連性を評価するなど他の方法もあるかと思います。
統合した質問とドキュメントの関連性を評価
def grade_documents(state):
print("--- grade_documents ---")
llm = state["llm_haiku"]
integration_question = state["integration_question"]
documents = state["documents"]
system_prompt = """あなたは、検索された文書とユーザーの質問との関連性を評価するアシスタントです。
文書に質問に関連するキーワードまたはセマンティックな内容を含んでいる場合、あなたはそれを関連性があると評価します。
関連性があれば"Yes"、関連性がない場合は"No"とだけ答えてください。"""
human_prompt = """
文書: {context}
質問: {query}
関連性("Yes" or "No"): """
prompt = ChatPromptTemplate.from_messages(
[
("system", system_prompt),
("human", human_prompt),
]
)
filtered_docs = []
is_search = False
grade_chain = prompt | llm | StrOutputParser()
print("\nドキュメントごとの関連性の評価=============================")
for doc in documents:
grade = grade_chain.invoke({"context":doc.page_content, "query": integration_question})
print(f"\n関連性: {grade}")
if "Yes" in grade:
filtered_docs.append(doc)
else:
is_search = True
print("\n===========================================================\n")
return {"documents": filtered_docs, "is_search": is_search}
統合した質問とドキュメントの関連性を"Yes" or "No"の二択で評価します。
一つでも"No"(質問との関連性がない)と評価されたドキュメントが存在した場合、そのドキュメントはコンテキストとして使用せずに「is_search」を"True"として後にWeb検索を行い情報を補完できるようにします。
関連性の評価によってWeb検索の要否を決定
def decide_to_generate(state):
print("--- decide_to_generate ---")
is_search = state['is_search']
if is_search == True:
return "transform_query"
else:
return "create_message"
「is_search」によってWeb検索の準備に進むか、そのままllmに渡すメッセージの作成に移るかを決めます。
統合した質問をWeb検索クエリに変換
def transform_query(state):
print("--- transform_query ---")
llm = state["llm_sonnet"]
integration_question = state["integration_question"]
system_prompt = """あなたは、入力された質問をWeb検索に最適化されたクエリに変換するリライターです。"""
human_prompt = """質問を見て、根本的な意味/意図を推論してWeb検索クエリのみ出力してください。
質問: {query}
Web検索クエリ: """
prompt = ChatPromptTemplate.from_messages(
[
("system", system_prompt),
("human", human_prompt),
]
)
transform_chain = prompt | llm | StrOutputParser()
transform_query = transform_chain.invoke({"query": integration_question})
print(f"\nWeb検索用クエリ: {transform_query}\n")
return {"transform_question": transform_query}
「is_search」が"True"だった場合に呼ばれるNodeです。Web検索に移る前に統合した質問文をWeb検索用のクエリに変換します。
Web検索を実行して結果を取得
def web_search(state):
print("--- web_search ---")
transform_question = state["transform_question"]
documents = state["documents"]
retriever = TavilySearchAPIRetriever(k=3)
docs = retriever.invoke(transform_question)
documents.extend(docs)
return {"documents": documents}
transform_queryで作成したWeb検索クエリを使用してWeb検索を実行後、取得したドキュメントを「documents」に追加します(Web検索には「Tavily」を使用しています)。
llmに渡すメッセージを作成
def create_message(state):
print("--- create_message ---")
documents = state["documents"]
question = state["question"]
system_message = "あなたは常に日本語で回答します。"
human_message ="""次の「=」で区切られたコンテキストを参照して質問に答えてください。
{context}
Question: {query}
"""
prompt = ChatPromptTemplate.from_messages(
[
("system", system_message),
("human", human_message),
]
)
partition = "\n" + "=" * 20 + "\n"
documents_context = partition.join([doc.page_content for doc in documents])
messages = prompt.format_messages(context=documents_context, query=question)
return {"messages": messages}
関連性評価で"Yes"となったドキュメント + Web検索して取得したドキュメント(関連性評価ですべて"Yes"となった場合は取得しない)を使いメッセージを作成します。
llmからの回答を生成
def generate(state):
print("--- generate ---")
llm = state["llm_sonnet"]
messages = state["messages"]
response = llm.invoke(messages)
print("--- end ---\n")
return {"messages": [response]}
作成したメッセージをllmに渡して回答を生成します。
実行結果(インデックス検索結果 + Web検索結果)
質問文: 葬送のフリーレンの勇者パーティーについて教えてください
生成する類似質問の数: 2
--- __start__ ---
--- generate_query ---
オリジナルの質問 + 生成された質問==========================
0. 葬送のフリーレンの勇者パーティーについて教えてください
1. 葬送のフリーレンのストーリーについて詳しく教えてください
2. 葬送のフリーレンに登場する主要キャラクターを紹介してください
===========================================================
--- retrieve ---
--- fusion ---
検索上位3つのスコア========================================
ドキュメント1: 0.04918032786885246
ドキュメント2: 0.03200204813108039
ドキュメント3: 0.016129032258064516
===========================================================
--- integration_query ---
統合した質問: 葬送のフリーレンのストーリーの概要、登場する主要キャラクターとそれぞれの役割、および勇者パーティーの活躍について詳しく教えてください。
--- grade_documents ---
ドキュメントごとの関連性の評価=============================
関連性: Yes
関連性: Yes
関連性: No
===========================================================
--- decide_to_generate ---
--- transform_query ---
Web検索用クエリ: フリーレン 小説 あらすじ キャラクター 勇者パーティー
--- web_search ---
--- create_message ---
--- generate ---
--- end ---
output:
『葬送のフリーレン』の勇者パーティーは以下の4人から構成されています。
- ヒンメル(勇者)
- フリーレン(魔法使い、エルフ族)
- アイゼン(戦士)
- ハイター(僧侶)
彼らは魔王を倒すという偉業を成し遂げた仲間です。しかし、人間とエルフの寿命の違いから、長寿のエルフであるフリーレンは、次第に人間の仲間たちを見送っていかねばならなくなります。
物語は勇者一行が魔王討伐後に王都に凱旋したところから始まり、彼らが50年に一度降る「半世紀(エーラ)流星」を見た後に一旦解散します。その後、フリーレンが仲間たちを追懐しながら旅をするうちに、自分たちの過去に関する新たな謎に気づき、再びパーティーを結成して冒険の旅に出るという展開になります。
途中経過における「類似した質問の生成」、「スコアの計算」、「質問の統合」、「関連度の判定」、「Web検索用クエリの作成」はうまくいってそうです。
outputに関しては(判断が難しいですが)「ストーリー」に関しての類似質問があったためか勇者パーティーが関連したストーリーの紹介がされています(新たな謎って何だろう・・・)。
実行結果(インデックス検索結果のみ)
質問文: 葬送のフリーレンのヒンメルについて教えてください
生成する類似質問の数: 2
--- __start__ ---
--- generate_query ---
オリジナルの質問 + 生成された質問==========================
0. 葬送のフリーレンのヒンメルについて教えてください
1. 葬送のフリーレンに登場するヒンメルの人物像について
2. アニメ『葬送のフリーレン』のキャラクター、ヒンメルの特徴を教えて
===========================================================
--- retrieve ---
--- fusion ---
検索上位3つのスコア========================================
ドキュメント1: 0.03278688524590164
ドキュメント2: 0.032266458495966696
ドキュメント3: 0.03225806451612903
===========================================================
--- integration_query ---
統合した質問: アニメ『葬送のフリーレン』に登場するキャラクター、ヒンメルの人物像や特徴を教えてください。
--- grade_documents ---
ドキュメントごとの関連性の評価=============================
関連性: Yes
関連性: Yes
関連性: Yes
===========================================================
--- decide_to_generate ---
--- create_message ---
--- generate ---
--- end ---
output:
コンテキストからわかることは、以下の通りです。
- 50年後、年老いたヒンメルとフリーレン、そしてパーティーメンバーのハイターやアイゼンが再会し、最後に一緒に流星群を観賞した。
- まもなくヒンメルは亡くなった。
- ヒンメルの葬儀の際、フリーレンはヒンメルのことをほとんど知らず、知ろうともしなかったことに気付き、悲しみの涙を流した。
- フリーレンはヒンメルについてもっと知りたいと思い、人間を理解するため、そして魔法を収集するために旅立った。
つまり、ヒンメルの死後、フリーレンはヒンメルについてほとんど知らなかったことを後悔し、彼のことをもっと知りたいと強く感じたようです。ヒンメルは勇者としてフリーレンを含む仲間に尊敬されていましたが、フリーレンは彼の人となりを十分知らなかったことを悲しんだのです。そのためフリーレンは、ヒンメルを知り、人間理解を深めるため、さらに魔法を集めるため、新たな旅に出たと描かれています。
上記ではインデックス(ローカル資料)のドキュメントだけを参照して回答しています。
実行結果(Web検索結果のみ)
質問文: アニメ「ガールズバンドクライ」の主人公について教えてください
生成する類似質問の数: 2
※アニメ「ガールズバンドクライ」は最近のアニメのためClaude 3は未学習(のはず)です。
--- __start__ ---
--- generate_query ---
オリジナルの質問 + 生成された質問==========================
0. アニメ「ガールズバンドクライ」の主人公について教えてください
1. ガールズバンドクライの主人公の性格や特徴を教えてください
2. アニメ作品「ガールズバンドクライ」の主人公の名前と役割について知りたいです
===========================================================
--- retrieve ---
--- fusion ---
検索上位3つのスコア========================================
ドキュメント1: 0.048915917503966164
ドキュメント2: 0.048651507139079855
ドキュメント3: 0.015873015873015872
===========================================================
--- integration_query ---
統合した質問: アニメ「ガールズバンドクライ」の主人公の名前と役割、および性格や特徴的な面について教えてください。
--- grade_documents ---
ドキュメントごとの関連性の評価=============================
関連性: No
関連性: No
関連性: No
===========================================================
--- decide_to_generate ---
--- transform_query ---
Web検索用クエリ: ガールズバンドクライ 主人公 名前 役割 性格 特徴
--- web_search ---
--- create_message ---
--- generate ---
--- end ---
output:
アニメ「ガールズバンドクライ」の主人公についての詳細な情報は与えられていませんが、コンテキストから以下のことが分かります。
- 「ガールズバンドクライ」は東映アニメーション制作のテレビアニメ作品である。
- 2024年4月6日から放送が開始されている。
- 物語には少なくとも仁菜と桃香というキャラクターが登場し、バンド活動に関わっている。
- 仁菜と桃香の間にはバンドへの思いがすれ違っている様子。
主人公がこの2人のうちどちらなのか具体的には分かりませんが、物語の中心となるのは恐らくこのバンド活動をする女の子たちで、その中でも仁菜と桃香が主要なキャラクターとして描かれていると推測できます。正確な主人公の名前は提示されたコンテキストからは特定できません。
主人公は特定できていませんが説明に誤りはなさそうです(以下で確認できます)。
おわりに
今回、最終的な回答にはClaude 3の「Sonnet」を使っています。コスト面で余裕がある場合は精度の高い「Opus」を使うことをお勧めします(自分はコストを抑えるため「Sonnet」を使用しました・・・)。
実行結果からRAG FusionとCRAGを組み合わせることでの恩恵をはっきりと確認するのは難しいですが、「類似した質問の生成」、「スコアの計算」、「質問の統合」、「関連度の判定」、「Web検索用クエリの作成」の処理は良い感じに動いていそうです。
コードは少し長いですが、RAG FusionとCRAGを連結しただけなので(分岐が一つあるだけでサイクルもないため)実装としては単純なものかと思います。興味があればお試しください。
また機会があればよろしくお願いします。
参考
Discussion