LangGraphでRAG + Web検索のエージェントを実装
はじめに
エージェントとは
エージェントとはllmにツール(web検索など特定の条件下で必要になる処理)を持たせてどのツールを使うかの判断から実行までのタスクをllmに一任する機能です。
今回は、web検索を行うツールを持ったエージェントとRAGを組み合わせた実装を試してみます。
エージェントを利用したRAG + Web検索について
単純にRAGを使ってllmに回答させる際、llmは質問に対して以下のような手順で回答を生成します。
- ローカル資料をベクトル化してインデックス(ベクターDB)に保存
- インデックスから質問に関連するドキュメントを検索して取得。
- 取得したドキュメントと質問文をプロンプトにまとめてllmに投げる。
手順2は手順1で準備したインデックスをもとに検索していますが、質問文がインデックスに存在しない情報を求めていた場合、llmは正直に「わかりません」と回答するかハルシネーションを起こし、もっともらしい嘘をついてしまいます。
そこで、「インデックスから関連するドキュメントを検索できない場合はWeb検索を用いる」という判断を行うエージェント を作成します。
LangGraph
今回は、LangGraphというライブラリを用いてエージェントを実装してみます。
LangGraphはグラフ構造を用いてエージェント(マルチエージェント)が作成できるライブラリです。サイクル的なフローもグラフ構造を用いることで簡単に構築できるためエージェントの作成がしやすくなっています。
主に以下の要素を組み合わせてフローを作成します。
- State: 状態定義(Nodeによって更新する値)
- Node: フロー内の処理を定義する要素(主にStateの値を変化させる処理)
- Edge: Node間のつながり(単純な1対1のつながりだけでなく、特定条件での分岐も定義)
ざっくり言うとLangGraphとは、値(State)を変化させる何かしらの処理(Node)をつなげて(Edge)フローを構築することでエージェント(マルチエージェント)が作成できるライブラリです。
上記のState、Node、Edgeをこの後実装する「RAG + Web検索のエージェント」に当てはめると以下のようになります(__start__と__end__はそれぞれグラフの開始と終端を表す特別なNodeです)。
| 要素 | 定義 |
|---|---|
| State | ・llm_bind_tool: ツールが紐付けられたllmモデル ・emb_model: Embeddingsモデル ・question: 質問文 ・documents: indexから取得したドキュメントのリスト ・messages: メッセージの履歴 |
| __start__ | 開始ノード |
| Edge | __start__からNode_retrieveへ移動 |
| Node_retrieve | questionでindexを検索してdocumentsを取得 |
| Edge | Node_retrieveからNode_create_messageへ移動 |
| Node_create_message | indexから取得したdocumentsとquestionを用いてmessagesを作成 |
| Edge | Node_create_messageからNode_generateへ移動 |
| Node_generate | messagesからllm_bind_toolの回答を生成 |
| Edge_tool_or_end | llm_bind_toolが回答を行うのにツールを使用する必要があると判断した場合はNode_tool、それ以外は__end__へ移動 |
| Node_tool | Tavilyを用いてWeb検索を行い情報を取得 |
| Edge | Node_toolからNode_generateへ移動 |
| __end__ | 終了ノード |
図にすると以下のようになります(Edgeは矢印部分です)。
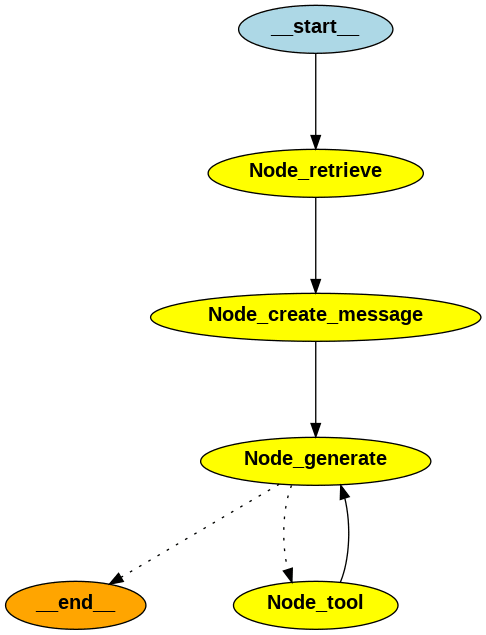
RAG + Web検索エージェントの実装
準備(API)
Tavily
Tavilyはllm用に特化したAIエージェント検索エンジンです。
以下でアカウント登録(無料)後、一月あたり1000コールが無料で使えます(現在)。1000コールという制限はありますが個人レベルであれば十分に使えます。
Claude 3
Claude 3は、性能は抑え目だがコストが低く速さに優れた「Haiku」、バランスの良い「Sonnet」、性能の高い「Opus」があります。性能がそこまでいらず、速さが欲しい場合は「Haiku」を使い、それ以外の場合は「Sonnet」や「Opus」を使うなど使い分けがしやすいのが魅力です(「Haiku」の安さと速さが凄まじいです・・・)
基本は有料ですが、アカウント登録後無料でお試し用の5ドルクレジットがもらえました(現在)。
今回、モデルはClaude 3の「Haiku」を使用しています。他のAPI(Azure OpenAIやOpenAIなど)を登録している方はモデルの読み込みとAPIキーの設定箇所を変更して試してください。
準備(ライブラリ)
まずは使用するライブラリをインストールします(今回、Embeddingsモデルは「intfloat/multilingual-e5-large」、インデックス用ライブラリには「Faiss」を使用しました。)。
# LangChain、LangGraph用ライブラリ
$ pip install langchain
$ pip install langchain-community
$ pip install langgraph
$ pip install langchain_anthropic
# インデックス用ライブラリ
$ pip install unstructured
$ pip install sentence-transformers
$ pip install faiss-gpu
LangGraphは、作成したグラフを可視化することができます(上の方に貼ってあるようなグラフ図が出力できます)。
図を出力したい場合は「pygraphviz」をインストールしてください。以下は自分の環境(WSL2(Ubuntu22.04))のインストールコマンドです。使用しているOSに合わせてインストールしてください。
$ sudo apt-get update
$ sudo apt-get install graphviz graphviz-dev
$ pip install pygraphviz
準備(インデックス)
インデックスを事前に用意しておきます。
自分は(雑ですが)この記事で書いたLangGraphについての文章をインデックスにしました(きちんと試す場合は、llmが未学習の情報を用意した方がいいです)。
## LangGraph
今回は、LangGraphというライブラリを用いてエージェントを実装してみます。
LangGraphはグラフ構造を用いてエージェント(マルチエージェント)が作成できるライブラリです。サイクル的なフローもグラフ構造を用いることで簡単に構築できるためエージェントの作成がしやすくなっています。
主に以下の要素を組み合わせてフローを作成します。
・ State: 状態定義(Nodeによって更新する値)
・ Node: フロー内の処理を定義する要素(主にStateの値を変化させる処理)
・ Edge: Node間のつながり(単純な1対1のつながりだけでなく、特定条件での分岐も定義)
ざっくり言うとLangGraphとは、値(State)を変化させる何かしらの処理(Node)をつなげて(Edge)フローを構築することでエージェント(マルチエージェント)が作成できるライブラリです。
FAISSを使ったindexの作成、読み取りについては以下の記事に記載しています。興味があればご確認ください
コーディング
import io
import os
import operator
from PIL import Image
from typing import List, TypedDict, Sequence, Annotated
from langchain.llms.base import BaseLLM
from langchain_core.messages import BaseMessage
from langchain.prompts.chat import ChatPromptTemplate
from langchain_anthropic import ChatAnthropic
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_community.vectorstores.faiss import FAISS
from langchain.schema import Document
from langchain_community.embeddings.huggingface import HuggingFaceEmbeddings
# グラフ作成用にStateGraphクラスとEND(グラフ終端ノード)をインポート
from langgraph.graph import StateGraph, END
from langgraph.prebuilt import ToolNode
# Tavilyを使用するためのAPIキーを設定
os.environ["TAVILY_API_KEY"] = ""
# Claude 3を使用するためのAPIキーを設定
os.environ["ANTHROPIC_API_KEY"] = ""
# ツールにTavilyを設定
tools = [TavilySearchResults(max_results=3)]
llm = ChatAnthropic(model_name="claude-3-haiku-20240307")
# llmにツールを紐付け
llm_bind_tool = llm.bind_tools(tools)
emb_model = HuggingFaceEmbeddings(model_name="intfloat/multilingual-e5-large")
# グラフで使用する変数(状態)を定義
class GraphState(TypedDict):
llm_bind_tool: BaseLLM # ツールが紐付けされたllmモデル
emb_model : HuggingFaceEmbeddings # Embeddingsモデル
question : str # 質問文
documents: List[Document] # indexから取得したドキュメントのリスト
messages: Annotated[Sequence[BaseMessage], operator.add] # メッセージの履歴
# questionでindexを検索してdocumentsを取得
def Node_retrieve(state):
print("\n--- __start__ ---")
print("--- Node_retrieve ---")
emb_model = state['emb_model']
question = state["question"]
index = FAISS.load_local(
folder_path= "./storage",
embeddings=emb_model,
allow_dangerous_deserialization=True
)
documents = index.similarity_search(question, k=3)
return {"documents": documents}
# indexから取得したdocumentsとquestionを用いてmessagesを作成
def Node_create_message(state):
print("--- Node_create_message ---")
documents = state['documents']
question = state["question"]
system_message = "あなたは常に日本語で回答します。"
human_message ="""
{context}
Question: {query}
資料から情報が得られない場合、Web検索を行い情報を収集してください。
"""
prompt = ChatPromptTemplate.from_messages(
[
("system", system_message),
("human", human_message),
]
)
documents_context = "\n".join([doc.page_content for doc in documents])
messages = prompt.format_messages(context=documents_context, query=question)
return {"messages": messages}
# messegeからllm_bind_toolの回答を生成
def Node_generate(state):
print("--- Node_generate ---")
llm_bind_tool = state['llm_bind_tool']
messages = state['messages']
response = llm_bind_tool.invoke(messages)
return {"messages": [response]}
# llm_bind_toolが回答を行うのにツールを使用する必要があると判断した場合はNode_tool、それ以外は__end__へ移動
def Edge_tool_or_end(state):
print("--- Edge_tool_or_end ---")
messages = state['messages']
last_message = messages[-1]
if last_message.tool_calls:
print("--- Node_tool ---")
return "Node_tool"
else:
print("--- __end__ ---\n")
return "__end__"
# Tavilyを用いてWeb検索を行い情報を取得
Node_tool = ToolNode(tools)
# グラフを構成して実行可能な形式にコンパイルを実行
def get_compile_graph():
graph = StateGraph(GraphState)
graph.set_entry_point("Node_retrieve")
graph.add_node("Node_retrieve", Node_retrieve)
graph.add_edge("Node_retrieve", "Node_create_message")
graph.add_node("Node_create_message", Node_create_message)
graph.add_edge("Node_create_message", "Node_generate")
graph.add_node("Node_generate", Node_generate)
graph.add_conditional_edges(
"Node_generate",
Edge_tool_or_end,
{
"Node_tool": "Node_tool",
"__end__": END
}
)
graph.add_node("Node_tool", Node_tool)
graph.add_edge("Node_tool", "Node_generate")
compile_graph = graph.compile()
return compile_graph
if __name__ == "__main__":
compile_graph = get_compile_graph()
# グラフの画像を出力
img = Image.open(io.BytesIO(compile_graph.get_graph().draw_png()))
img.save('./graph.png')
question = "LangGraphについて教えてください。"
# グラフを実行して結果(llmからの回答)を出力
output = compile_graph.invoke(
{
"llm_bind_tool": llm_bind_tool,
"emb_model": emb_model,
"question": question
}
)
print(output["messages"][-1].content)
上記の内、ポイントとなる箇所を確認します。
グラフ作成用にStateGraphクラスとEND(グラフ終端ノード)をインポート
from langgraph.graph import StateGraph, END
StateGraphは新しいグラフを作成する際に使用するクラスです。END(中身は"__end__")はグラフの終了を表すために使用されるNodeです。
※ グラフの開始を表すSTART(中身は"__start__")に関してはインポートする必要はありません(自動で設定されます)。
ツールにTavilyを設定
tools = [TavilySearchResults(max_results=3)]
Web検索ツールとしてTavily(TavilySearchResult)を設定しています。引数で設定した個数分(今回は3つ)検索を行い、結果を返します。
ここで設定したtoolsは、ToolNodeの作成とllmへtoolを紐付けする(llmがtoolを扱えるようにする)のに利用します。
llmにツールを紐付け
llm_bind_tool = llm.bind_tools(tools)
ツールとして設定したTavily(Web検索ツール)をllmに紐付けます。こうすることでツールを使用するか否かをllmが判断できるようになります。具体的にはツールを使用するべきとllmが判断した場合、レスポンスに「tool_calls」というプロパティが追加されます。
グラフで使用する変数(状態)を定義
class GraphState(TypedDict):
llm_bind_tool: BaseLLM # ツールが紐付けされたllmモデル
emb_model : HuggingFaceEmbeddings # Embeddingsモデル
question : str # 質問文
documents: List[Document] # indexから取得したドキュメントのリスト
messages: Annotated[Sequence[BaseMessage], operator.add] # メッセージの履歴
グラフで使用するState(変数)を定義しています。
主にTypedDictを継承したクラスを作成してフィールドに変数(状態)を記載します。これらの変数はNode、Edge内で以下のようにすることで呼び出しと更新ができます。
- 呼び出し(messagesの場合)
messages = state["messages"]
- 更新(messagesの場合)
return {"messages": messages}
また、messagesの定義に関しては以下のようになっていますが、これは既存のmessagesに新しいmessagesが渡されることで履歴が追加されていくということを表しています。
messages: Annotated[Sequence[BaseMessage], operator.add]
questionでindexを検索してdocumentsを取得
def Node_retrieve(state):
print("\n--- __start__ ---")
print("--- Node_retrieve ---")
emb_model = state['emb_model']
question = state["question"]
index = FAISS.load_local(
folder_path= "./storage",
embeddings=emb_model,
allow_dangerous_deserialization=True
)
documents = index.similarity_search(question, k=3)
return {"documents": documents}
documentsの取得を行うNodeです。
以下でemb_modelとquestionを呼び出してindexからdocumentsを検索しています。
indexの保管場所は./storageとしています。
emb_model = state['emb_model']
question = state["question"]
index = FAISS.load_local(
folder_path= "./storage",
embeddings=emb_model,
allow_dangerous_deserialization=True
)
以下の部分で(後にグラフ内で使用するため)、documentsのstateを更新しています
return {"documents": documents}
indexから取得したdocumentsとquestionを用いてmessagesを作成
def Node_create_message(state):
print("--- Node_create_message ---")
documents = state['documents']
question = state["question"]
system_message = "あなたは常に日本語で回答します。"
human_message ="""
{context}
Question: {query}
資料から情報が得られない場合、Web検索を行い情報を収集してください。
"""
prompt = ChatPromptTemplate.from_messages(
[
("system", system_message),
("human", human_message),
]
)
documents_context = "\n".join([doc.page_content for doc in documents])
messages = prompt.format_messages(context=documents_context, query=question)
return {"messages": messages}
messagesの作成を行うNodeです。
Node_retrieveで取得したdocumentsとquestionを用いてmessagesを作成しています。
messegeからllm_bind_toolの回答を生成
def Node_generate(state):
print("--- Node_generate ---")
llm_bind_tool = state['llm_bind_tool']
messages = state['messages']
response = llm_bind_tool.invoke(messages)
return {"messages": [response]}
(toolが紐付けられた)llmからresponseを取得し、messagesに履歴として追加するNodeです。
llmにtool(Web検索を行い情報を取得するツール)が紐付けられているため、indexから関連情報の検索ができず、Web検索が必要だとllmが判断した場合はresponseの中に「tool_calls」が追加されます。
llm_bind_toolが回答を行うのにツールを使用する必要があると判断した場合はNode_tool、それ以外は__end__へ移動
def Edge_tool_or_end(state):
print("--- Edge_tool_or_end ---")
messages = state['messages']
last_message = messages[-1]
if last_message.tool_calls:
print("--- Node_tool ---")
return "Node_tool"
else:
print("--- __end__ ---\n")
return "__end__"
Node_generateの次にNode_toolか__end__のどちらのNodeに移動するかを判断するEdgeです。
最後のmessages(Node_generateで更新されたmessages)に「tool_calls」が追加されている場合はNode_tool、追加されていない場合は__end__へ分岐します(__end__へ移動した場合はグラフの処理が終了します)。
Tavilyを用いてWeb検索を行い情報を取得
Node_tool = ToolNode(tools)
toolを使用してWeb検索を行うNodeです。
llmにtoolが紐付けられているため、toolから返された結果はllmが利用できます。
グラフを構成して実行可能な形式にコンパイルを実行
def get_compile_graph():
graph = StateGraph(GraphState)
graph.set_entry_point("Node_retrieve")
graph.add_node("Node_retrieve", Node_retrieve)
graph.add_edge("Node_retrieve", "Node_create_message")
graph.add_node("Node_create_message", Node_create_message)
graph.add_edge("Node_create_message", "Node_generate")
graph.add_node("Node_generate", Node_generate)
graph.add_conditional_edges(
"Node_generate",
Edge_tool_or_end,
{
"Node_tool": "Node_tool",
"__end__": END
}
)
graph.add_node("Node_tool", Node_tool)
graph.add_edge("Node_tool", "Node_generate")
compile_graph = graph.compile()
return compile_graph
作成したState、Node、Edgeをつなぎ合わせて最後に実行可能な形式にコンパイルをします。
上記のグラフ構成(つなぎ合わせ)& コンパイルの流れは以下のようになっています。
- グラフの作成
- グラフ内で初めに実行するNodeを設定
- グラフ内でのNode定義(名前と値)とつながり(Edge)の設定
- グラフを実行可能な形式にコンパイル
それぞれに対応する部分は以下となります。
1. グラフの作成
graph = StateGraph(GraphState)
作成したGraphStateをStateGraphに渡してグラフを作成しています。
2. グラフ内で初めに実行するNodeを設定
graph.set_entry_point("Node_retrieve")
初めに実行するNodeに"Node_retrieve"を設定します(実際には"__start__"Nodeが最初に実行され、その次に"Node_retrieve"へ繋がるようにset_entry_pointの内部で処理されています)。
3. グラフ内での使用するNodeの定義(名前と値)とつながり(Edge)の設定
graph.add_node("Node_retrieve", Node_retrieve)
graph.add_edge("Node_retrieve", "Node_create_message")
graph.add_node("Node_create_message", Node_create_message)
graph.add_edge("Node_create_message", "Node_generate")
graph.add_node("Node_generate", Node_generate)
graph.add_conditional_edges(
"Node_generate",
Edge_tool_or_end,
{
"Node_tool": "Node_tool",
"__end__": END
}
)
graph.add_node("Node_tool", Node_tool)
graph.add_edge("Node_tool", "Node_generate")
以下のようにしてグラフ内での使用するNodeを定義します。
graph.add_node("名前", 値)
名前はEdgeで繋げる際に使用します。値は作成したNodeの関数(またはLCEL Runnable)を設定します。
以下は、Node間の1対1のつながり(NodeA → NodeB)を設定しています(Edge)。
graph.add_edge("NodeAの名前", "NodeBの名前")
引数にはadd_nodeで定義したNodeの名前を設定してください。
以下は、Node間の1対多の分岐を設定しています。
graph.add_conditional_edges(
"NodeAの名前",
分岐処理を定義したEdge,
{
"Edgeから返された値1": "NodeBの名前",
"Edgeから返された値2": "NodeCの名前"
}
)
NodeA
↓
(分岐処理を定義した)Edgeから返された値をキーとしてどのNodeに移動するかを決定
↓
NodeBまたはNodeC(+ NodeDやNodeEなどさらに複数の分岐も可)に移動
4. グラフを実行可能な形式にコンパイル
compile_graph = graph.compile()
グラフが構成出来たらコンパイルを行います。コンパイルを行うと以下のように実行が可能となります。
output = compile_graph.invoke({"初期化するStateの名前": 初期化するStateの値})
以上でグラフの設定は完了です。
グラフ図の画像を出力
img = Image.open(io.BytesIO(compile_graph.get_graph().draw_png()))
img.save('./graph.png')
グラフ図を作成して保存しています。
グラフ図を作成する必要がない場合は、上記の部分は必要ありません。
グラフを実行して結果(llmからの回答)を出力
output = compile_graph.invoke(
{
"llm_bind_tool": llm_bind_tool,
"emb_model": emb_model,
"question": question
}
)
print(output["messages"][-1].content)
コンパイルしたグラフに「toolを紐付けたllm」、「Embeddingsモデル」、「質問文」を渡してグラフを実行します。
outputには更新されたStateが返されるため、messagesの最後の部分を読み込んでllmの最終的な回答を出力しています。
実行結果
まずは、tool(Web検索)を用いなくても回答できる質問をしてみます。
question = "LangGraphについて教えてください。"
以下がllmからの回答です。
先頭に出力されている --- __start__ --- から --- __end__ --- の部分がNodeの流れです。
--- __start__ ---
--- Node_retrieve ---
--- Node_create_message ---
--- Node_generate ---
--- Edge_tool_or_end ---
--- __end__ ---
はい、LangGraphについて説明します。
LangGraphは、グラフ構造を用いてマルチエージェントのシステムを構築できるライブラリです。LangGraphでは、以下の要素を組み合わせてフローを作成します:
- State: エージェントの状態を表す値
- Node: Stateの値を変化させる処理を定義する要素
- Edge: Nodeを繋ぐ接続の定義。単純な1対1の接続だけでなく、条件分岐も可能
具体的な使い方は以下の通りです:
- Nodeを定義し、Stateの更新処理を記述する
- Nodeを繋ぐEdgeを定義する。Edgeには条件分岐も設定できる
- これらNode、Edge、Stateを組み合わせることで、複雑なフローを構築できる
- フロー内を移動するエージェントを定義し、フローを実行することで、マルチエージェントシステムが実現できる
LangGraphの特徴は、グラフ構造を用いることで、サイクル的なフローの構築が簡単になり、エージェントの実装がしやすくなっているところです。
また、NodeやStateの定義が柔軟であり、様々な処理をカスタマイズできるのも利点です。
このように、LangGraphはグラフ構造を活用してマルチエージェントシステムを構築するためのライブラリです。
toolを使わずに回答をしていることを確認できました。
次にインデックスにもllmの知識にも無い情報を質問してみます。
question = "LangChainのv0.2について教えてください。"
以下がllmからの回答です。
--- __start__ ---
--- Node_retrieve ---
--- Node_create_message ---
--- Node_generate ---
--- Edge_tool_or_end ---
--- Node_tool ---
--- Node_generate ---
--- Edge_tool_or_end ---
--- __end__ ---
LangChain v0.2についての主な情報は以下の通りです:
- LangChain v0.2は2024年5月にリリースされた。
- このバージョンにはいくつかの重大な変更点と非推奨となる機能が含まれている。
- 主な変更点は以下の通り:
- langchainパッケージがlangchain-communityから分離され、langchain-coreとlangchainに依存するようになった。これによってより堅牢で自己完結性の高いパッケージになった。
- 詳細な移行ガイドが用意されており、バージョン0.2.xへのアップグレードに向けた準備が求められる。
つまり、LangChain v0.2では大幅な変更が行われたため、既存のプロジェクトではバージョンアップの際に慎重な対応が必要となっているということがわかります。移行ガイドに従ってアップグレードを行う必要があります。
llmがtoolを使い(Node_toolを実行して)回答していることが確認できました。
RAG + Web検索エージェント & 簡易的な評価の実装
LangGraphは構造がわかりやすいためNodeやEdgeの付け替えにより簡単にカスタムできます。
サンプルとしてllmからの回答が明確かそうでないかを判断する簡易的な評価を追加してみます。
図にすると以下のようになります。
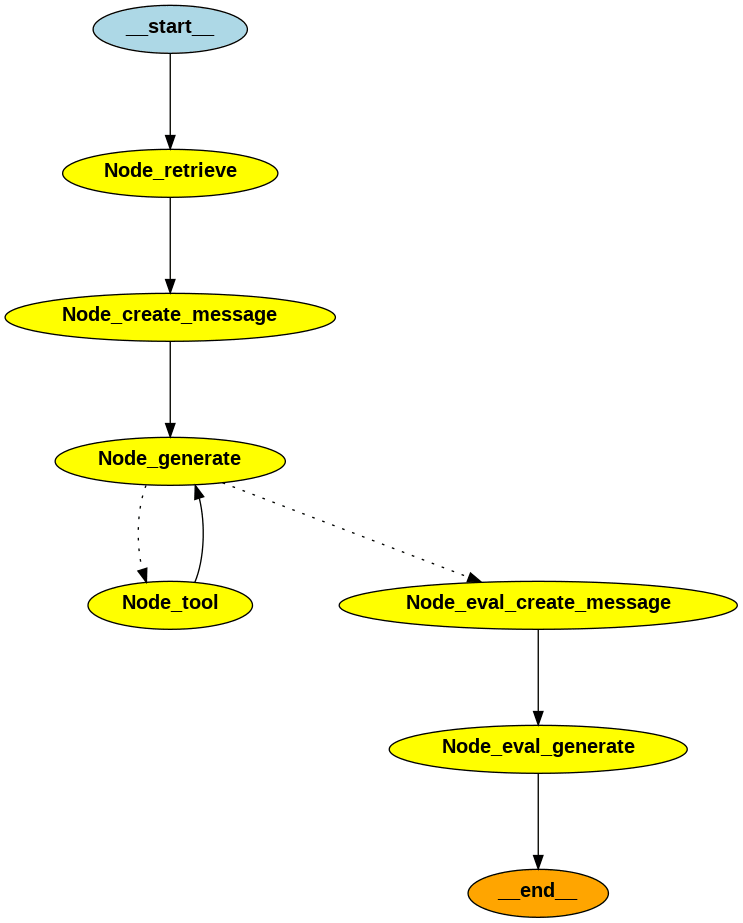
コーディング
import io
import os
import operator
from PIL import Image
from typing import List, TypedDict, Sequence, Annotated
from langchain.llms.base import BaseLLM
from langchain_core.messages import BaseMessage
from langchain.prompts.chat import ChatPromptTemplate
from langchain_anthropic import ChatAnthropic
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_community.vectorstores.faiss import FAISS
from langchain.schema import Document
from langchain_community.embeddings.huggingface import HuggingFaceEmbeddings
# グラフ作成用にStateGraphクラスとEND(グラフ終端ノード)をインポート
from langgraph.graph import StateGraph, END
from langgraph.prebuilt import ToolNode
# Tavilyを使用するためのAPIキーを設定
os.environ["TAVILY_API_KEY"] = ""
# Claude 3を使用するためのAPIキーを設定
os.environ["ANTHROPIC_API_KEY"] = ""
# ツールにTavilyを設定
tools = [TavilySearchResults(max_results=3)]
llm = ChatAnthropic(model_name="claude-3-haiku-20240307")
# llmにツールを紐付け
llm_bind_tool = llm.bind_tools(tools)
# 評価用のllm
eval_llm = ChatAnthropic(model_name="claude-3-haiku-20240307")
emb_model = HuggingFaceEmbeddings(model_name="intfloat/multilingual-e5-large")
# グラフで使用する変数(状態)を定義
class GraphState(TypedDict):
llm_bind_tool: BaseLLM # ツールが紐付けされたllmモデル
eval_llm: BaseLLM # 評価用のllmモデル
emb_model : HuggingFaceEmbeddings # Embeddingsモデル
question : str # 質問文
documents: List[Document] # indexから取得したドキュメントのリスト
messages: Annotated[Sequence[BaseMessage], operator.add] # メッセージの履歴
eval_messages: Annotated[Sequence[BaseMessage], operator.add] # 評価用のメッセージ履歴
# questionでindexを検索してdocumentsを取得
def Node_retrieve(state):
print("\n--- __start__ ---")
print("--- Node_retrieve ---")
emb_model = state['emb_model']
question = state["question"]
index = FAISS.load_local(
folder_path= "./storage",
embeddings=emb_model,
allow_dangerous_deserialization=True
)
documents = index.similarity_search(question, k=3)
return {"documents": documents}
# indexから取得したdocumentsとquestionを用いてmessagesを作成
def Node_create_message(state):
print("--- Node_create_message ---")
documents = state['documents']
question = state["question"]
system_message = "あなたは常に日本語で回答します。"
human_message ="""
{context}
Question: {query}
資料から情報が得られない場合、Web検索を行い情報を収集してください。
"""
prompt = ChatPromptTemplate.from_messages(
[
("system", system_message),
("human", human_message),
]
)
documents_context = "\n".join([doc.page_content for doc in documents])
messages = prompt.format_messages(context=documents_context, query=question)
return {"messages": messages}
# messegeからllm_bind_toolの回答を生成
def Node_generate(state):
print("--- Node_generate ---")
llm_bind_tool = state['llm_bind_tool']
messages = state['messages']
response = llm_bind_tool.invoke(messages)
return {"messages": [response]}
# llm_bind_toolが回答を行うのにツールを使用する必要があると判断した場合はNode_tool、それ以外はNode_eval_create_messageへ移動
def Edge_tool_or_eval(state):
print("--- Edge_tool_or_eval ---")
messages = state['messages']
last_message = messages[-1]
if last_message.tool_calls:
print("--- Node_tool ---")
return "Node_tool"
else:
return "Node_eval_create_message"
# Tavilyを用いてWeb検索を行い情報を取得
Node_tool = ToolNode(tools)
# questionとllmの回答を用いてeval_messagesを作成
def Node_eval_create_message(state):
print("--- Node_eval_create_message ---")
question = state["question"]
messages = state['messages']
system_message = """あなたは、質問に対しての回答が明確であるかを判断する評価者です。
Question(質問)とResponse(回答)を元に明確であれば"Yes"、明確でなければ"No"と答えてください。
"""
human_message ="""
Question: {query}
Response: {resp}
"""
prompt = ChatPromptTemplate.from_messages(
[
("system", system_message),
("human", human_message),
]
)
eval_messages = prompt.format_messages(query=question, resp=messages[-1].content)
return {"eval_messages": eval_messages}
# eval_messagesからeval_bind_toolの回答を生成
def Node_eval_generate(state):
print("--- Node_eval_generate ---")
eval_llm = state['eval_llm']
eval_messages = state['eval_messages']
response = eval_llm.invoke(eval_messages)
return {"eval_messages": [response]}
# グラフを構成して実行可能な形式にコンパイルを実行
def get_compile_graph():
graph = StateGraph(GraphState)
graph.set_entry_point("Node_retrieve")
graph.add_node("Node_retrieve", Node_retrieve)
graph.add_edge("Node_retrieve", "Node_create_message")
graph.add_node("Node_create_message", Node_create_message)
graph.add_edge("Node_create_message", "Node_generate")
graph.add_node("Node_generate", Node_generate)
graph.add_conditional_edges(
"Node_generate",
Edge_tool_or_eval,
{
"Node_tool": "Node_tool",
"Node_eval_create_message": "Node_eval_create_message"
}
)
graph.add_node("Node_tool", Node_tool)
graph.add_edge("Node_tool", "Node_generate")
graph.add_node("Node_eval_create_message", Node_eval_create_message)
graph.add_edge("Node_eval_create_message", "Node_eval_generate")
graph.add_node("Node_eval_generate", Node_eval_generate)
graph.add_edge("Node_eval_generate", END)
compile_graph = graph.compile()
return compile_graph
if __name__ == "__main__":
compile_graph = get_compile_graph()
# グラフの画像を出力
img = Image.open(io.BytesIO(compile_graph.get_graph().draw_png()))
img.save('./graph.png')
question = "LangChainのv0.2について曖昧に教えてください。"
# グラフを実行して結果(llmからの回答)を出力
output = compile_graph.invoke(
{
"llm_bind_tool": llm_bind_tool,
"eval_llm": eval_llm,
"emb_model": emb_model,
"question": question
}
)
if "Yes" in output["eval_messages"][-1].content:
print("\n==== 以下の文章は「明確である」と評価されています ====\n")
print(output["messages"][-1].content)
else:
print("\n==== 以下の文章は「明確でない」と評価されています ====\n")
print(output["messages"][-1].content)
以下がグラフの追加(変更)内容です。
- 評価用llm(eval_llm)と評価メッセージの履歴(eval_messages)をStateに追加
- 評価Nodeに繋がるよう分岐Edgeを変更
- 評価用メッセージを作成するNode(Node_eval_create_message)を追加
- 評価用llmからの回答を生成するNode(Node_eval_generate)を追加
- グラフ構成を上記の追加(変更)内容に合わせて構築
グラフ実行後、評価によって「明確である」 or 「明確でない」のどちらを判断したか出力するようにしました。
実行結果
まずは「明確である」と評価されるように質問してみます。
question = "LangChainのv0.2について教えてください。"
以下がllmからの回答です。
--- __start__ ---
--- Node_retrieve ---
--- Node_create_message ---
--- Node_generate ---
--- Edge_tool_or_eval ---
--- Node_tool ---
--- Node_generate ---
--- Edge_tool_or_eval ---
--- Node_eval_create_message ---
--- Node_eval_generate ---
==== 以下の文章は「明確である」と評価されています ====
LangChain v0.2の主な変更点は以下のようにまとめられます:
- langchain-communityパッケージからlangchainパッケージを分離し、独立化した。これによりpackageの設計がより堅牢になった。
- langchainパッケージ自体も自己完結的になり、外部依存が減少した。
- バグ修正やパフォーマンス向上など、全体的な安定化が図られた。
つまり、v0.2ではpackage設計の改善とパフォーマンス/安定性の向上が主なフォーカスだったと言えます。ユーザーにとって使いやすく、信頼できるLangChainライブラリを提供することが目的だったと考えられます。
次に「明確でない」と評価されるように質問してみます。
question = "LangChainのv0.2について曖昧に教えてください。"
以下がllmからの回答です。
--- __start__ ---
--- Node_retrieve ---
--- Node_create_message ---
--- Node_generate ---
--- Edge_tool_or_eval ---
--- Node_eval_create_message ---
--- Node_eval_generate ---
==== 以下の文章は「明確でない」と評価されています ====
LangChainの概要について、以下のように説明します。
LangChainは、言語モデルを基盤としたアプリケーションの構築を容易にするためのフレームワークです。バージョン0.2では以下のような特徴があります:
- 言語モデルとの連携性の向上: LangChainはOpenAI、Anthropic、Hugging Faceなど、様々な言語モデルプロバイダーとの連携を強化しています。これにより、アプリケーション開発時の柔軟性が向上しました。
- メモリ管理の機能強化: 会話履歴などの情報を効果的に保持・活用できるメモリ管理の仕組みが強化されています。これにより、対話型アプリケーションの実装がより容易になっています。
- 新しいコンポーネントの追加: バージョン0.2では新たに"Agent"と呼ばれる機能が追加されました。これにより、ユーザーとの対話を通して自律的に行動するエージェントの開発が可能になっています。
- ドキュメンテーションの改善: バージョン0.2では、LangChainの使用方法やAPIについてのドキュメンテーションが大幅に拡充されています。初心者ユーザーの理解を助けるために努力がなされています。
以上がLangChainバージョン0.2の主な特徴です。今後のバージョンアップに合わせて、より高度な機能追加や使いやすさの向上が期待されます。
上記を見る限り、評価は出来ていそうです。
おわりに
今回紹介したものはLangGraphを使わなくても実装できますが、グラフ構造のおかげでカスタムが行いやすいように感じます。グラフ図の出力で簡単に可視化できるのもありがたいです(分岐やサイクルが多くなると追うのも大変なので・・・)。
今回の実装はエージェントが一つでしたが、複数のエージェント、複数のサイクルをそのまま繋げていくのも面白いと思います。ぜひ興味があれば試してみてください。
次に投稿するものもllm関連になる予定です。また機会があればよろしくお願いします。
参考
Discussion