ソースコード & ドキュメントに対応したGraph RAGの実装(Tree-sitter + LightRAG)
追記: 2025/10/8
当記事で解説している内容を基本構造として、簡単に扱えるようにMCPサーバー化したものを作成しました。ご興味あればお試しください。
- 作成したMCPサーバー「Repo GraphRAG MCP Server」
- 以下の記事で説明と使い方を紹介しています。
はじめに
今回は通常の自然言語で記載されたテキスト(設計書など)だけでなく、ソースコードに対してもグラフ化を行ったGraph RAGを試してみましたので記事にしました。
ソースコードに対して単純にRAG(GraphRAG)を行うと通常のトークン数による分割や単純なエンティティ抽出で処理内容が考慮されず、一つのメソッドが複数に分割されたり、元の意味からかけ離れたチャンクやエンティティが抽出されるなどの問題が起こります。
今回はそのような問題に対処するためTree-sitterによるソースコードの構造化を用いてチャンク化、グラフ化を行いました。
この記事内で扱う技術(ライブラリ)は以下です。
- Tree-sitter: ソースファイルの解析に使用
-
LightRAG: Graph RAGに使用
Tree-sitterを用いたグラフ化については以下を参考にしました。
※ 今回行う実装(チャンク化や定義の抽出方法など)とはまた異なるアプローチがされています(READEMEに詳しい構成が記載されていますので一読をお勧めします)。
- advanced-coding-assistant-backend
Tree-sitterについて
Tree-sitterは、プログラミング言語やマークアップ言語などを構文解析するツールです。
解析されたコードは親子関係のあるAST(抽象構文木)ノードというデータ構造で表現します(厳密にはCST(具象構文木)ですが、今回はASTとして扱います)。
ASTノードにはクラスや関数、引数や変数などそれぞれにタイプ名があります。
コードから特定の定義(クラス、関数など)を抽出する際は、このタイプ名を指定することで対応するコード部分を抽出することができます(各言語にはそれぞれ構文規則があり、ASTノードのタイプ名は異なります)。
例として以下のコード(Python)を解析してASTノードから関数名「sample_func」を抽出してみます。
- Pythonコード
def sample_func():
print("Hello World")
sample_func()
- ASTノード
(module
(function_definition
(identifier) # ← ここに関数名「sample_func」が含まれます
(parameters)
(block
(expression_statement
(call
(identifier)
(argument_list
(string))))))
(expression_statement
(call
(identifier)
(argument_list))))
ノードが色々取れましたが、「function_definition」が関数、その子である「identifier」が関数名を表すため、
function_definition == 子ノード ==> identifier となっている箇所を探索すれば抽出できます(関数ではあっても「lambda」など異なる場合もあります)。
今回は上記のようにTree-sitterを用いた解析を行うことでコードの適切な分割と要素の抽出を行います(以下のライブラリを使用)。
LightRAGについて
LightRAGは「チャンクに対しての検索(通常のRAG)」 + 「知識グラフ(エンティティ、リレーションシップ)への検索(Graph RAG)」を組み合わせたハイブリッド設計のRAGフレームワークです。
LightRAGの特徴や使い方などは以下の記事が参考になります。
今回使うLightRAGの主な機能は以下です。
-
通常のナレッジグラフ挿入処理:
LightRAG.ainsert()
テキストなどのドキュメント挿入処理に使います。LightRAGにおいてドキュメントを挿入する際の基本的な機能です。 -
カスタムナレッジグラフの挿入処理:
LightRAG.ainsert_custom_kg()
手動でチャンク、エンティティ、リレーションシップを作成して挿入する機能です。 -
エンティティのマージ処理:
LightRAG.amerge_entities()
複数のエンティティをマージ(連結)して一つにする機能です。エンティティの名前が異なるものを纏め上げる際などに使えます。
主な内容(処理の流れ)
-
まずは、対象のディレクトリ内にある設計書などのドキュメントをチャンク化、グラフ化します。テキストに関しては
LightRAG.ainsert()を使うことで自動的にチャンク化とグラフ化を行うため、どのような種類のエンティティを抽出するかの指定以外、特別な調整は行いません。 -
次にソースコードのチャンク化、グラフ化を行います。ドキュメントとは異なり、Tree-sitterを用いたグラフ化などはLightRAG内の機能にないため、手動でチャンク化、グラフ化を行い
LightRAG.ainsert_custom_kg()を使い挿入します。 -
最後にコードとドキュメントで類似度の高いエンティティを
LightRAG.amerge_entitiesを使いマージします。
コードのエンティティ名はTree-sitterで解析 & 抽出したものなので名前が統一化されていますが、ドキュメントは定義名に「()」がついていたりなど抽出した際の表現方法に微妙な差異があります。今回はそのような微妙な違いもマージすることで、よりドキュメントとコードのつながりを高める狙いでマージ処理を行なっています(抽出プロントの調整でもある程度制御することは可能ですが、今回はLightRAG内のプロントはデフォルトのまま扱いました)。
作業環境
OS: WSL2 Ubuntu22.04
Pythonバージョン: 3.10.12
コーディング
使用したライブラリ
コード内で使用した外部ライブラリとインストールコマンドは以下です(バージョンは自分が動かした時のものです)。
pip install anthropic==0.60.0
pip install langchain-anthropic==0.3.0
pip install lightrag-hku==1.4.5
pip install numpy==1.26.4
pip install PyPDF2==3.0.1
pip install sentence-transformers==3.0.1
pip install textract==1.6.5
pip install tokenizers==0.21.4
pip install torch==2.7.1
pip install transformers==4.54.1
pip install tree-sitter==0.25.0
pip install tree-sitter-cpp==0.23.4
pip install tree-sitter-java==0.23.5
pip install tree-sitter-python==0.23.6
※ 自分の環境では、textractのインストール時に「error: metadata-generation-failed」のエラーが出たため、pipのバージョンを24.0に下げてインストールしました。
全体のコード
import os
import time
import asyncio
import bisect
import textract
import anthropic
import numpy as np
from tree_sitter import Node, Parser, Language
import tree_sitter_python as tspython
import tree_sitter_cpp as tscpp
import tree_sitter_java as tsjava
from lightrag import LightRAG
from transformers import AutoModel, AutoTokenizer
from lightrag.utils import EmbeddingFunc
from lightrag.llm.hf import hf_embed
from lightrag.kg.shared_storage import initialize_pipeline_status
# コード、ドキュメントが格納されている読み取り対象のディレクトリパス
read_dir_path = "./read_dir"
# グラフやチャンクの格納用ストレージパス
storage_dir_path = "./storage_dir"
# 使用するLLM(anthropic)の設定
model_name = "claude-3-5-haiku-20241022" # LLMの名前
llm_max_token_size = 8192 # LLMの最大トークン数
api_key = "APIキー" # anthropicのAPIキー
client = anthropic.AsyncAnthropic(api_key=api_key) # 非同期用anthropicクライアントを取得
# 使用する埋め込みモデルの設定
emb_name = "BAAI/bge-m3" # 埋め込みモデル名
embedding_dim = 1024 # 次元数
emb_max_token_size = 2048 # 埋め込みモデルの最大トークン数
emb_model = AutoModel.from_pretrained(emb_name) # 埋め込みモデルを取得
tokenizer = AutoTokenizer.from_pretrained(emb_name) # 埋め込みモデルのトークナイザーを取得
# チャンクの最大トークン数
chunk_max_tokens = 2048
# 設計書などの(コードファイル以外の)ドキュメントの拡張子を設定
doc_ext_dict = {
"text_file": ["txt", "md"], # "text_file"の値にはテキスト形式で読み取る拡張子のリストを設定
"binary_file": ["pdf", "csv", "doc"] # "binary_file"の値にはバイナリ形式で読み取る拡張子のリストを設定
}
# Tree-sitterで探索するノードの深さ(エンティティ抽出用)を設定
max_depth = 30
# エンティティとして抽出するPythonの定義ノードを設定(キーは定義のタイプ名、値は定義の名前を表すノード)
python_definition_dict = {
"class_definition": "identifier",
"function_definition": "identifier"
}
# Python言語解析用のTree-sitterを設定
py_lang = Language(tspython.language())
# エンティティとして抽出するC++の定義ノードを設定
cpp_definition_dict = {
"class_specifier": "name",
"struct_specifier": "name",
"function_declarator": "identifier"
}
# C++言語解析用のTree-sitterを設定
cpp_lang = Language(tscpp.language())
# エンティティとして抽出するJavaの定義ノードを設定
java_definition_dict = {
"class_declaration": "identifier",
"method_declaration": "identifier",
"interface_declaration": "identifier"
}
# Java言語解析用のTree-sitterを設定
java_lang = Language(tsjava.language())
# コードファイルの拡張子ごとに抽出対象ノードと言語解析用のTree-sitterを設定
code_ext_dict = {
"py": {
"definition": python_definition_dict,
"language": py_lang
},
"cpp": {
"definition": cpp_definition_dict,
"language": cpp_lang
},
"h": {
"definition": cpp_definition_dict,
"language": cpp_lang
},
"java": {
"definition": java_definition_dict,
"language": java_lang
}
}
# ドキュメントから抽出するエンティティの種類を指定
doc_definition_list = ["class_name", "function_name"]
# ドキュメントとコードのチャンク化、グラフ化を行う際の並列処理数
parallel_num = 5
# LLMと埋め込みモデルの並列数には"parallel_num"と同じ値を設定
llm_model_max_async = parallel_num
embedding_func_max_async = parallel_num
# マージするエンティティ同士のコサイン類似度の閾値を設定
merge_score_threshold = 0.9
async def main():
rag: LightRAG = None
try:
# LightRagの初期化処理を実行
rag = await initialize_rag()
# 指定したディレクトリからドキュメントファイルとコードファイルを抽出
doc_dict, code_dict = read_dir(read_dir_path)
# ドキュメントのチャンク化、グラフ化処理を実行
await doc_to_storage(rag, doc_dict)
# コードのチャンク化、グラフ化処理を実行
await code_to_storage(rag, code_dict)
# ドキュメントとコードのエンティティをマージ
await merge_doc_and_code(rag)
except Exception as e:
print(f"エラーが発生しました:\n{e}")
finally:
if rag:
await rag.finalize_storages()
# LightRAGの初期化を行う関数
async def initialize_rag() -> LightRAG:
# LightRAGの初期化(各種パラメータを設定)
rag = LightRAG(
working_dir=storage_dir_path, # ストレージパスを設定
max_parallel_insert=parallel_num, # チャンク化、グラフ化の並列数を設定
llm_model_func=anthropic_complete, # エンティティの抽出や要約などに利用する関数を設定
summary_max_tokens=llm_max_token_size, # 要約生成の最大トークン数を設定
embedding_func=EmbeddingFunc( # 埋め込みに使用する関数を設定
embedding_dim=embedding_dim, # 埋め込みモデルの次元数を設定
max_token_size=emb_max_token_size, # 埋め込みモデルの最大トークン数を設定
func=lambda texts: hf_embed( # lambdaで渡されたテキストをベクトル化する関数を設定
texts,
tokenizer=tokenizer,
embed_model=emb_model,
)
),
llm_model_max_async=llm_model_max_async, # LLMの最大並列処理数を設定
embedding_func_max_async=embedding_func_max_async, # 埋め込みモデルの最大並列処理数を設定
addon_params={
"language": "english", # エンティティの要約などに使用する言語を設定
"entity_types": doc_definition_list, # ドキュメントから抽出するエンティティの種類を設定
}
)
# ストレージの初期化
await rag.initialize_storages()
await initialize_pipeline_status()
return rag
# Anthropicクライアントの実行用関数
async def anthropic_complete(
prompt: str,
system_prompt: str="",
history_messages: list=[],
**kwargs
):
# 会話履歴の設定
messages = []
messages.extend(history_messages)
# メッセージにプロンプトを追加
messages.append(
{
"role": "user",
"content": prompt
}
)
# 最大トークンサイズを設定
max_tokens = kwargs.get('max_tokens', llm_max_token_size)
# LLMの実行
response = await client.messages.create(
system=system_prompt,
model=model_name,
max_tokens=max_tokens,
messages=messages,
)
# 応答の返却
return response.content[0].text
# ノードの行範囲を取得する関数
def get_node_line_range(node: Node, line_offset_list):
# ノードからバイト範囲を取得
start_byte = node.start_byte
end_byte = node.end_byte
# バイト位置をファイル内の行範囲に変換
start_line = bisect.bisect_right(line_offset_list, start_byte) - 1
end_line = bisect.bisect_right(line_offset_list, end_byte) - 1
# ノードの行範囲を返却
return start_line + 1, end_line + 1
# ディレクトリを探索して処理対象のファイルを取得する関数
def read_dir(read_dir_path):
print("=" * 50)
print("処理予定ファイル")
doc_dict = {}
code_dict = {}
# 処理対象とし指定した拡張子のセットを取得
allow_ext_set = set(sum(doc_ext_dict.values(), [])) | set(code_ext_dict.keys())
# フォルダを再帰的に探索
for dir_path, _, file_name_list in os.walk(read_dir_path):
for file_name in file_name_list:
# ファイル名から拡張子を抽出
_, ext = os.path.splitext(file_name)
# 指定された拡張子以外のファイルをスキップ
if ext.lstrip(".") not in allow_ext_set:
continue
# ファイルパスを生成
file_path = os.path.join(dir_path, file_name)
# ファイルパスと中身を設定
if ext.lstrip(".") in code_ext_dict:
with open(file_path, "rb") as file:
code_dict[file_path] = file.read()
print(f"コードファイル: {file_path}")
elif ext.lstrip(".") in doc_ext_dict["text_file"]:
with open(file_path, "r", encoding="utf-8") as file:
doc_dict[file_path] = file.read()
print(f"テキストファイル: {file_path}")
elif ext.lstrip(".") in doc_ext_dict["binary_file"]:
doc_dict[file_path] = textract.process(file_path)
print(f"バイナリファイル: {file_path}")
print("=" * 50 + "\n")
return doc_dict, code_dict
# ドキュメントをチャンク化、グラフ化する関数
async def doc_to_storage(rag: LightRAG, doc_dict: dict):
print("=" * 50)
print("ドキュメントファイルのグラフ化")
# ドキュメントのチャンク化、グラフ化処理
await rag.ainsert(
list(doc_dict.values()),
file_paths=list(doc_dict.keys())
)
for doc_path in doc_dict.keys():
print(f"処理完了:{doc_path}")
print("=" * 50 + "\n")
# コードをチャンク化、グラフ化する関数
async def code_to_storage(rag: LightRAG, code_dict: dict):
print("=" * 50)
print("コードファイルのグラフ化")
# 並列処理用関数
async def process_file(code_path, file_content_bytes):
file_name = os.path.basename(code_path)
# ファイル名から拡張子を抽出
_, ext = os.path.splitext(file_name)
# Tree-sitterのパーサーを準備
language = code_ext_dict[ext.lstrip(".")]["language"]
parser = Parser(language)
# パーサーを使用してコードを構文木に変換
tree = parser.parse(file_content_bytes)
# 構文木からルートノード(コード全体を表すノード)を取得
root_node = tree.root_node
# バイト列をUTF-8に変換
file_content_text = file_content_bytes.decode('utf-8')
line_offset = 0
line_offset_list = []
# 各行の開始位置を取得
line_list = file_content_text.splitlines()
for line in line_list:
line_offset_list.append(line_offset)
line_offset += len(line.encode("utf-8")) + 1
chunks = []
entities = []
relationships = []
# チャンク化対象のノードを抽出
chunk_node_list = await create_code_chunks(root_node, file_content_bytes)
# エンティティとして抽出する定義ノードの辞書を取得
definition_dict = code_ext_dict[ext.lstrip(".")]["definition"]
# チャンク化対象のノードからチャンク化、グラフ化処理を実行
for node, node_text in chunk_node_list:
# 行範囲を取得
start_line, end_line = get_node_line_range(node, line_offset_list)
# チャンクのIDを設定
source_id = f"file:{file_name}_line:{start_line}-{end_line}"
# チャンク化したコードとチャンクのIDをリストに追加
chunks.append(
{
"content": node_text,
"source_id": source_id,
"file_path": code_path
}
)
# グラフ化(エンティティ、リレーションシップ)対象ノードの抽出処理
chunk_entities, chunk_relationships = await create_code_graph(
node=node,
definition_dict=definition_dict,
file_content_bytes=file_content_bytes,
parent_definition_name="",
source_id=source_id,
code_path=code_path,
line_offset_list=line_offset_list
)
# 抽出したノードをエンティティとリレーションシップのリストに追加
entities += chunk_entities
relationships += chunk_relationships
# 作成したリストをカスタムナレッジグラフとして追加
await rag.ainsert_custom_kg(
custom_kg = {
"chunks": chunks,
"entities": entities,
"relationships": relationships
}
)
print(f"処理完了:{code_path}")
file_item_list = list(code_dict.items())
# 同時に処理するバッチサイズを設定
batch_size = parallel_num
# バッチ処理を実行
for batch_index in range(0, len(file_item_list), batch_size):
batch_item_list = file_item_list[batch_index:batch_index+batch_size]
# バッチごとのタスクを作成
batch_task_list = []
for code_path, file_content_bytes in batch_item_list:
task = asyncio.create_task(process_file(code_path, file_content_bytes))
batch_task_list.append(task)
# バッチごとにタスクを実行
await asyncio.gather(*batch_task_list)
print("=" * 50 + "\n")
# チャンク化対象ノードを抽出する関数
async def create_code_chunks(root_node: Node, file_content_bytes: str):
# ノード格納用キューの初期化
task_queue = asyncio.Queue()
# ルートノード直下のノードをキューに追加
for child_node in root_node.children:
await task_queue.put(child_node)
chunk_node_list = []
while not task_queue.empty():
# キューからノードを取得
current_node = await task_queue.get()
# ノードに対応するコード部分を取得
node_text = file_content_bytes[current_node.start_byte:current_node.end_byte].decode("utf-8").strip()
# コードが空の場合はスキップ
if not node_text:
continue
# コードをトークン化
tokens = await asyncio.to_thread(tokenizer.encode, node_text)
# トークンサイズが設定した最大トークンサイズ以下であればチャンクとして追加
if chunk_max_tokens >= len(tokens):
chunk_node_list.append((current_node, node_text))
else:
# 最大トークンサイズより大きい場合は子ノードをキューに追加
for child_node in current_node.children:
await task_queue.put(child_node)
# チャンク対象として抽出されたノードを返却
return chunk_node_list
# グラフ化(エンティティ、リレーションシップ)対象ノードを抽出する関数
async def create_code_graph(
node: Node,
definition_dict: dict,
file_content_bytes: str,
parent_definition_name: str,
source_id: str,
code_path: str,
line_offset_list: list
):
entities = []
relationships = []
file_name = os.path.basename(code_path)
# ノード情報(ノード、親ノードの名前、ネストの深さ)を格納するキューの初期化
task_queue = asyncio.Queue()
# キューの初期化
await task_queue.put((node, parent_definition_name, 0))
while not task_queue.empty():
current_node, parent_definition_name, depth = await task_queue.get()
# ノードから対応するコード部分を取得
node_text = file_content_bytes[current_node.start_byte:current_node.end_byte].decode("utf-8").strip()
# コードが空の場合はスキップ
if not node_text:
continue
# 初期値としてノードの定義名(関数名など)に親ノードの定義名を設定
definition_name = parent_definition_name
# 定義リストに該当するノードタイプだった場合、エンティティを生成
if current_node.type in definition_dict:
start_line, end_line = get_node_line_range(current_node, line_offset_list)
# 子ノード探索用のキューを初期化
search_queue = asyncio.Queue()
for child in current_node.children:
await search_queue.put(child)
entity_name = ""
# 定義名に対応するノードを探索してエンティティ名を設定
while not search_queue.empty():
search_node = await search_queue.get()
if search_node.type == definition_dict[current_node.type]:
definition_name = file_content_bytes[search_node.start_byte:search_node.end_byte].decode('utf-8').strip()
entity_name = f"{file_name}:{definition_name}"
break
else:
for child in search_node.children:
await search_queue.put(child)
# 対応するエンティティ名が存在する場合、エンティティを設定
if entity_name:
# コード要約用のプロンプトを作成
prompt = f"""# Instructions
Extract the important elements and processes from the program and create a brief summary statement described in natural language.
# Rules
- Create a summary statement using natural language, not the program.
- Output only a pure summary without any supplements or questions.
# Program
{node_text}
# Summary statement"""
# コードの要約を実行
description = await anthropic_complete(
prompt=prompt,
max_tokens=llm_max_token_size
)
# エンティティを登録
entities.append(
{
"entity_name": entity_name,
"entity_type": current_node.type,
"description": description,
"source_id": source_id,
"file_path": code_path
}
)
# 親エンティティが存在する場合、リレーションシップを設定
if parent_definition_name:
relationships.append({
"src_id": f"{file_name}:{parent_definition_name}",
"tgt_id": entity_name,
"description": f"The {definition_name} of {parent_definition_name} located in lines {start_line} through {end_line}.",
"keywords": f"{parent_definition_name} {definition_name}",
"weight": 1.0,
"source_id": source_id,
"file_path": code_path
}
)
# ネストの深さが設定した最大値よりも小さい場合、子ノードの探索を実行
if depth < max_depth:
for child_node in current_node.children:
await task_queue.put((child_node, definition_name, depth + 1))
# 作成したエンティティとリレーションシップのリストを返却
return entities, relationships
# ドキュメントとコードのエンティティをマージする関数
async def merge_doc_and_code(rag: LightRAG):
print("=" * 50)
print("エンティティのマージ")
# 全エンティティの名前を取得
all_entity_name = await rag.get_graph_labels()
code_entity_list = []
doc_entity_list = []
code_ext_set = set(code_ext_dict.keys())
doc_ext_set = set(doc_ext_dict["text_file"] + doc_ext_dict["binary_file"])
for entity_name in all_entity_name:
# エンティティ名からエンティティ情報を取得
entity = await rag.chunk_entity_relation_graph.get_node(entity_name)
_, ext = os.path.splitext(entity.get("file_path"))
# コードのエンティティとドキュメントのエンティティを分けてリストに格納
if ext.lstrip(".") in code_ext_set:
code_entity_list.append((entity.get("entity_id"), entity.get("description")))
elif ext.lstrip(".") in doc_ext_set:
doc_entity_list.append((entity.get("entity_id"), entity.get("description")))
if not code_entity_list:
print("コードのエンティティが作成されていません")
if not doc_entity_list:
print("ドキュメントのエンティティが作成されていません")
if not code_entity_list or not doc_entity_list:
print("マージをスキップ")
print("=" * 50 + "\n")
return
# コードのエンティティ(定義名部分)とドキュメントのエンティティをベクトルに変換
embedding_func = rag.embedding_func
code_name_embedding_array = await embedding_func([code_entity_name.split(":", 1)[1] for code_entity_name, _ in code_entity_list])
doc_name_embedding_array = await embedding_func([doc_name for doc_name, _ in doc_entity_list])
# マージ対象の競合を防ぐためのロック
code_list_locks = asyncio.Lock()
# バッチごとに各ドキュメントのエンティティと類似するコードのエンティティ(複数)を検索してマージ
async def process_doc_entity(doc_index, doc_name, doc_description):
doc_name_embedding = doc_name_embedding_array[doc_index]
extract_code_list = []
for code_index, (code_entity_name, code_description) in enumerate(code_entity_list):
code_entity_name_embedding = code_name_embedding_array[code_index]
# エンティティ同士のコサイン類似度を計算
similarity = np.dot(code_entity_name_embedding, doc_name_embedding) / (
np.linalg.norm(code_entity_name_embedding) * np.linalg.norm(doc_name_embedding)
)
# 設定した類似度よりも大きい場合、マージ対象として抽出
if similarity >= merge_score_threshold:
extract_code_list.append((code_entity_name, code_description))
if extract_code_list:
# マージ対象のエンティティの存在チェック(マージ済みの場合は対象外)
exist_code_list = []
async with code_list_locks:
for code_entity_name, code_description in extract_code_list:
exist = await rag.chunk_entity_relation_graph.has_node(code_entity_name)
if exist:
exist_code_list.append((code_entity_name, code_description))
if exist_code_list:
merge_description = ""
print("-" * 50)
print("マージ対象のエンティティ")
print(f"ドキュメントのエンティティ: {doc_name}")
# コードエンティティのdescriptionを連結
for exist_code_index, (exist_code_entity_name, exist_code_description) in enumerate(exist_code_list, 1):
merge_description += f"<SEP>{exist_code_entity_name}\n{exist_code_description}"
print(f"コードのエンティティ_{exist_code_index}: {exist_code_entity_name}")
print("-" * 50 + "\n")
# エンティティのマージを実行
await rag.amerge_entities(
source_entities=[
doc_name,
*[exist_code_entity_name for exist_code_entity_name, _ in exist_code_list]
],
target_entity=doc_name,
target_entity_data={
"description": f"{doc_description}{merge_description}"
}
)
# バッチ処理で並列実行
batch_size = parallel_num
# バッチ処理を実行
for batch_index in range(0, len(doc_entity_list), batch_size):
batch_doc_entity_list = doc_entity_list[batch_index:batch_index+batch_size]
# バッチごとのタスクを作成
batch_task_list = []
for i, (doc_name, doc_description) in enumerate(batch_doc_entity_list):
# 元のインデックスを計算
doc_index = batch_index + i
task = asyncio.create_task(process_doc_entity(doc_index, doc_name, doc_description))
batch_task_list.append(task)
# バッチごとの結果を待機
await asyncio.gather(*batch_task_list)
print("=" * 50 + "\n")
if __name__ == "__main__":
start_time = time.time()
asyncio.run(main())
processing_time = time.time() - start_time
hours, remainder = divmod(processing_time, 3600)
minutes, seconds = divmod(remainder, 60)
# 処理時間を出力
print(f"\n処理時間: {hours:02.0f}h:{minutes:02.0f}m:{seconds:04.1f}s")
上記コード内、以下の部分について説明します。
- パラメータの設定
- ソースコードのチャンク化
- ソースコードのグラフ(エンティティ、リレーションシップ)化
- ドキュメントとコードのエンティティをマージ
パラメータの設定
# コード、ドキュメントが格納されている読み取り対象のディレクトリパス
read_dir_path = "./read_dir"
# グラフやチャンクの格納用ストレージパス
storage_dir_path = "./storage_dir"
# 使用するLLM(anthropic)の設定
model_name = "claude-3-5-haiku-20241022" # LLMの名前
llm_max_token_size = 8192 # LLMの最大トークン数
api_key = "APIキー" # anthropicのAPIキー
client = anthropic.AsyncAnthropic(api_key=api_key) # 非同期用anthropicクライアントを取得
# 使用する埋め込みモデルの設定
emb_name = "BAAI/bge-m3" # 埋め込みモデル名
embedding_dim = 1024 # 次元数
emb_max_token_size = 2048 # 埋め込みモデルの最大トークン数
emb_model = AutoModel.from_pretrained(emb_name) # 埋め込みモデルを取得
tokenizer = AutoTokenizer.from_pretrained(emb_name) # 埋め込みモデルのトークナイザーを取得
# チャンクの最大トークン数
chunk_max_tokens = 2048
# 設計書などの(コードファイル以外の)ドキュメントの拡張子を設定
doc_ext_dict = {
"text_file": ["txt", "md"], # "text_file"の値にはテキスト形式で読み取る拡張子のリストを設定
"binary_file": ["pdf", "csv", "doc"] # "binary_file"の値にはバイナリ形式で読み取る拡張子のリストを設定
}
# Tree-sitterで探索するノードの深さ(エンティティ抽出用)を設定
max_depth = 30
# エンティティとして抽出するPythonの定義ノードを設定(キーは定義のタイプ名、値は定義の名前を表すノード)
python_definition_dict = {
"class_definition": "identifier",
"function_definition": "identifier"
}
# Python言語解析用のTree-sitterを設定
py_lang = Language(tspython.language())
# エンティティとして抽出するC++の定義ノードを設定
cpp_definition_dict = {
"class_specifier": "name",
"struct_specifier": "name",
"function_declarator": "identifier"
}
# C++言語解析用のTree-sitterを設定
cpp_lang = Language(tscpp.language())
# エンティティとして抽出するJavaの定義ノードを設定
java_definition_dict = {
"class_declaration": "identifier",
"method_declaration": "identifier",
"interface_declaration": "identifier"
}
# Java言語解析用のTree-sitterを設定
java_lang = Language(tsjava.language())
# コードファイルの拡張子ごとに抽出対象ノードと言語解析用のTree-sitterを設定
code_ext_dict = {
"py": {
"definition": python_definition_dict,
"language": py_lang
},
"cpp": {
"definition": cpp_definition_dict,
"language": cpp_lang
},
"h": {
"definition": cpp_definition_dict,
"language": cpp_lang
},
"java": {
"definition": java_definition_dict,
"language": java_lang
}
}
# ドキュメントから抽出するエンティティの種類を指定
doc_definition_list = ["class_name", "function_name"]
# ドキュメントとコードのチャンク化、グラフ化を行う際の並列処理数
parallel_num = 5
# LLMと埋め込みモデルの並列数には"parallel_num"と同じ値を設定
llm_model_max_async = parallel_num
embedding_func_max_async = parallel_num
# マージするエンティティ同士のコサイン類似度の閾値を設定
merge_score_threshold = 0.9
上記がパラメータ部分です。
基本的には、read_dir_pathにドキュメントとソースコードを配置後、上記を適宜設定すれば動きます。
※ 今回は実行しやすくするためにグローバル変数部分にまとめましたが、本来は環境変数や設定用ファイルなどを利用した方がよいかと思います。
パラメータの中でも特にドキュメントとソースコードの処理(解析)に関わってくる箇所を以下で解説します。
-
doc_ext_dict: 処理対象とするドキュメント拡張子の辞書
拡張子で処理対象のドキュメント形式を絞ります(ここで設定されていない拡張子は処理対象外です)。
text_fileに設定されている拡張子のファイルは、単純なテキストとして内容を読み取ります。
binary_fileに記載された拡張子のファイルは、textractを使いバイナリ形式で読み取り中身を取得しています。
上記以外でtextractが対応可能な形式については以下を確認してください。
-
max_depth: 探索するノードの深さを設定
エンティティを抽出する際にここで設定した値の分だけ子ノードを再帰的に確認します。
ネストが深すぎて時間がかかる場合などはこの値に適切な最大値を設定して下さい。 -
〇〇_definition_dict: 言語ごとに抽出対象ノードをまとめた辞書を設定
抽出対象のノードをここで絞ります(主にクラスや関数などの定義と定義名を抽出対象とします。
キーには抽出する定義ノード(例: 関数)、値には定義名(例: 関数名)を表すノードを設定します。
ノード名に関しては各言語の文法定義が記載されたgrammar.jsに記載がありますが、以下のように実際に解析して確かめる方法や生成AIに聞く(これが一番早いかと思います)という方法もあります。ノード名確認コード
code_parse_sample.pyfrom tree_sitter import Language, Parser import tree_sitter_python as tspython # Pythonコード解析用のパーサーを設定 PY_LANGUAGE = Language(tspython.language()) parser = Parser(PY_LANGUAGE) # 解析するPythonコード code = bytes(""" def hello(): print("Hello world") hello() """, "utf8") tree = parser.parse(code) # ノードを再帰的に表示する関数 def node_check(node, indent=0, code=None): node_text = node.text.decode('utf8').replace('\n', '\\n') if len(node_text) > 30: node_text = node_text[:30] + "..." print(' ' * indent + f"{node.type} | {node_text}") # 子ノードを再帰的に表示 for child in node.children: node_check(child, indent + 1, code) # ルートノードから表示開始 print("ノード名 | コード") print("-" * 50) node_check(tree.root_node, code=code)実際の処理ではキーに設定したノードから定義(関数などの処理の中身)を抽出して、さらにその中から、値に設定したノード名と一致するものを探索して定義名として抽出します。
キーは対象の処理全体が入っている親ノード、値はその名前が入っている子ノードという形式で要素を追加することで変数名なども取得してエンティティとすることができます。処理コストなど状況に応じて適宜設定してください。 -
〇〇_lang: 文法定義を設定
各言語の文法定義を設定します。
Tree-sitterの解析にはこの文法定義をインポートして渡す必要があります。新たに他言語の解析を追加する場合は、対応するライブラリも合わせてインストール & インポートして下さい。# 例) Python # pip install tree-sitter-python import tree_sitter_python as tspython -
code_ext_dict: 拡張子ごとに抽出対象ノードをまとめた辞書と文法定義を設定
拡張子をキー、値を「〇〇_definition_dict」と「〇〇_lang」として、まとめて設定します。
言語は拡張子で区別しているため、Python言語だったら「py」、Go言語だったら「go」など対応する拡張子を設定してください(一つの言語に複数の拡張子が存在する場合は、拡張子ごとに同じ値を設定してください)。 -
doc_definition_list: ドキュメントから抽出するエンティティを指定
コードのエンティティとマージを行うため、コードから抽出されるエンティティ名と被るような名前を含めて設定します。
今回はシンプルにコードのエンティティ名と被りそうなもの(「クラス名」と「関数名」)だけにしていますが、「ファイル名」などコードのエンティティと被らないものでも自由に追加、変更して問題ありません。 -
parallel_num: ドキュメント、コードの並列処理数とモデルの最大同時実行数を設定
※ 今回、LLMはAnthropicを使用するように設定しています。他サービス(OpenAIやOllma、Geminiなど)を利用する場合はパラメータのモデル設定部分 だけでなく、LightRAGの初期化パラメータllm_model_funcに適切な関数を渡す必要があります。具体的な設定方法に関しては公式のexamplesが参考にな ります。
ソースコードのチャンク化
# チャンク化対象ノードを抽出する関数
async def create_code_chunks(root_node: Node, file_content_bytes: str):
# ノード格納用キューの初期化
task_queue = asyncio.Queue()
# ルートノード直下のノードをキューに追加
for child_node in root_node.children:
await task_queue.put(child_node)
chunk_node_list = []
while not task_queue.empty():
# キューからノードを取得
current_node = await task_queue.get()
# ノードに対応するコード部分を取得
node_text = file_content_bytes[current_node.start_byte:current_node.end_byte].decode("utf-8").strip()
# コードが空の場合はスキップ
if not node_text:
continue
# コードをトークン化
tokens = await asyncio.to_thread(tokenizer.encode, node_text)
# トークンサイズが設定した最大トークンサイズ以下であればチャンクとして追加
if chunk_max_tokens >= len(tokens):
chunk_node_list.append((current_node, node_text))
else:
# 最大トークンサイズより大きい場合は子ノードをキューに追加
for child_node in current_node.children:
await task_queue.put(child_node)
# チャンク対象として抽出されたノードを返却
return chunk_node_list
Tree-sitterでソースコードを解析した際のrootノード直下のノード(rootノードはソースコード全体です。その直下なので各グローバル変数やクラス、関数などのトップレベルの要素が当てはまります)をチャンクとして保存します。もしノードのサイズが指定したトークン数より大きければさらに子ノードを再帰的に抽出してチャンクとします。
このようにしてチャンクにはソースコードのトップレベルの要素(トークン数が大きければさらに子ノード)が収められます(繋ぎなおすと元のソースコードに戻る形になります)。
ソースコードのグラフ(エンティティ、リレーションシップ)化
# グラフ化(エンティティ、リレーションシップ)対象ノードを抽出する関数
async def create_code_graph(
node: Node,
definition_dict: dict,
file_content_bytes: str,
parent_definition_name: str,
source_id: str,
code_path: str,
line_offset_list: list
):
entities = []
relationships = []
file_name = os.path.basename(code_path)
# ノード情報(ノード、親ノードの名前、ネストの深さ)を格納するキューの初期化
task_queue = asyncio.Queue()
# キューの初期化
await task_queue.put((node, parent_definition_name, 0))
while not task_queue.empty():
current_node, parent_definition_name, depth = await task_queue.get()
# ノードから対応するコード部分を取得
node_text = file_content_bytes[current_node.start_byte:current_node.end_byte].decode("utf-8").strip()
# コードが空の場合はスキップ
if not node_text:
continue
# 初期値としてノードの定義名(関数名など)に親ノードの定義名を設定
definition_name = parent_definition_name
# 定義リストに該当するノードタイプだった場合、エンティティを生成
if current_node.type in definition_dict:
start_line, end_line = get_node_line_range(current_node, line_offset_list)
# 子ノード探索用のキューを初期化
search_queue = asyncio.Queue()
for child in current_node.children:
await search_queue.put(child)
entity_name = ""
# 定義名に対応するノードを探索してエンティティ名を設定
while not search_queue.empty():
search_node = await search_queue.get()
if search_node.type == definition_dict[current_node.type]:
definition_name = file_content_bytes[search_node.start_byte:search_node.end_byte].decode('utf-8').strip()
entity_name = f"{file_name}:{definition_name}"
break
else:
for child in search_node.children:
await search_queue.put(child)
# 対応するエンティティ名が存在する場合、エンティティを設定
if entity_name:
# コード要約用のプロンプトを作成
prompt = f"""# Instructions
Extract the important elements and processes from the program and create a brief summary statement described in natural language.
# Rules
- Create a summary statement using natural language, not the program.
- Output only a pure summary without any supplements or questions.
# Program
{node_text}
# Summary statement"""
# コードの要約を実行
description = await anthropic_complete(
prompt=prompt,
max_tokens=llm_max_token_size
)
# エンティティを登録
entities.append(
{
"entity_name": entity_name,
"entity_type": current_node.type,
"description": description,
"source_id": source_id,
"file_path": code_path
}
)
# 親エンティティが存在する場合、リレーションシップを設定
if parent_definition_name:
relationships.append({
"src_id": f"{file_name}:{parent_definition_name}",
"tgt_id": entity_name,
"description": f"The {definition_name} of {parent_definition_name} located in lines {start_line} through {end_line}.",
"keywords": f"{parent_definition_name} {definition_name}",
"weight": 1.0,
"source_id": source_id,
"file_path": code_path
}
)
# ネストの深さが設定した最大値よりも小さい場合、子ノードの探索を実行
if depth < max_depth:
for child_node in current_node.children:
await task_queue.put((child_node, definition_name, depth + 1))
# 作成したエンティティとリレーションシップのリストを返却
return entities, relationships
チャンク化したノードから再帰的に子ノードを探索して指定した定義(クラス定義や関数定義)のノードを抽出します(チャンク配下にエンティティが存在する構造になります)。抽出したノードは以下のようなパラメータを持つエンティティとして設定します。
-
エンティティのパラメータ
- entity_name: {ファイル名} : {ソースコードから抽出したクラス名や関数名などの定義名} を設定。
- entity_type: ノードのタイプを設定(Tree-sitterで抽出したASTノードのタイプをそのまま設定)。
- description: ノードから抽出したソースコード(クラスや関数)の要約文 を設定(要約文はLLMを用いて作成します)。
- source_id: チャンクIDを設定。
- file_path: コードファイルのパスを設定
LigtRAGではエンティティの検索は「entity_name + description」(をベクトル化したもの)に対して類似度検索を行います。そのためdescriptionにはコードではなく要約文を設定して類似度検索に引っ掛かりやすいようにしています。
また、検索されたエンティティに関しては紐づけられたチャンクもコンテキストとして取得されます。そのため、エンティティにはファイル名と定義名、要約文しか入っていませんが、source_id経由で(チャンクから)実際のソースコードの参照も行われます。
リレーションシップに関しては抽出されたエンティティの(ノード間の)親子関係を設定しています。パラメータは以下です。
-
リレーションシップのパラメータ
- src_id: 親ノードのエンティティ名
- tgt_id: 子ノードのエンティティ名
- description: ノード間の親子関係を記述した文章「The {子ノードの名前} of {親ノードの名前} located in lines {ファイル内の開始行番号} through {ファイル内の終了行番号}.」を設定。
- keywords: {親ノードの定義名} {子ノードの定義名} を設定 。
- weight: 固定で1.0を設定
- source_id: 子ノードのチャンクIDを設定
- file_path: コードファイルのパスを設定
ドキュメントとコードのエンティティをマージ
# ドキュメントとコードのエンティティをマージする関数
async def merge_doc_and_code(rag: LightRAG):
print("=" * 50)
print("エンティティのマージ")
# 全エンティティの名前を取得
all_entity_name = await rag.get_graph_labels()
code_entity_list = []
doc_entity_list = []
code_ext_set = set(code_ext_dict.keys())
doc_ext_set = set(doc_ext_dict["text_file"] + doc_ext_dict["binary_file"])
for entity_name in all_entity_name:
# エンティティ名からエンティティ情報を取得
entity = await rag.chunk_entity_relation_graph.get_node(entity_name)
_, ext = os.path.splitext(entity.get("file_path"))
# コードのエンティティとドキュメントのエンティティを分けてリストに格納
if ext.lstrip(".") in code_ext_set:
code_entity_list.append((entity.get("entity_id"), entity.get("description")))
elif ext.lstrip(".") in doc_ext_set:
doc_entity_list.append((entity.get("entity_id"), entity.get("description")))
if not code_entity_list:
print("コードのエンティティが作成されていません")
if not doc_entity_list:
print("ドキュメントのエンティティが作成されていません")
if not code_entity_list or not doc_entity_list:
print("マージをスキップ")
print("=" * 50 + "\n")
return
# コードのエンティティ(定義名部分)とドキュメントのエンティティをベクトルに変換
embedding_func = rag.embedding_func
code_name_embedding_array = await embedding_func([code_entity_name.split(":", 1)[1] for code_entity_name, _ in code_entity_list])
doc_name_embedding_array = await embedding_func([doc_name for doc_name, _ in doc_entity_list])
# マージ対象の競合を防ぐためのロック
code_list_locks = asyncio.Lock()
# バッチごとに各ドキュメントのエンティティと類似するコードのエンティティ(複数)を検索してマージ
async def process_doc_entity(doc_index, doc_name, doc_description):
doc_name_embedding = doc_name_embedding_array[doc_index]
extract_code_list = []
for code_index, (code_entity_name, code_description) in enumerate(code_entity_list):
code_entity_name_embedding = code_name_embedding_array[code_index]
# エンティティ同士のコサイン類似度を計算
similarity = np.dot(code_entity_name_embedding, doc_name_embedding) / (
np.linalg.norm(code_entity_name_embedding) * np.linalg.norm(doc_name_embedding)
)
# 設定した類似度よりも大きい場合、マージ対象として抽出
if similarity >= merge_score_threshold:
extract_code_list.append((code_entity_name, code_description))
if extract_code_list:
# マージ対象のエンティティの存在チェック(マージ済みの場合は対象外)
exist_code_list = []
async with code_list_locks:
for code_entity_name, code_description in extract_code_list:
exist = await rag.chunk_entity_relation_graph.has_node(code_entity_name)
if exist:
exist_code_list.append((code_entity_name, code_description))
if exist_code_list:
merge_description = ""
print("-" * 50)
print("マージ対象のエンティティ")
print(f"ドキュメントのエンティティ: {doc_name}")
# コードエンティティのdescriptionを連結
for exist_code_index, (exist_code_entity_name, exist_code_description) in enumerate(exist_code_list, 1):
merge_description += f"<SEP>{exist_code_entity_name}\n{exist_code_description}"
print(f"コードのエンティティ_{exist_code_index}: {exist_code_entity_name}")
print("-" * 50 + "\n")
# エンティティのマージを実行
await rag.amerge_entities(
source_entities=[
doc_name,
*[exist_code_entity_name for exist_code_entity_name, _ in exist_code_list]
],
target_entity=doc_name,
target_entity_data={
"description": f"{doc_description}{merge_description}"
}
)
# バッチ処理で並列実行
batch_size = parallel_num
# バッチ処理を実行
for batch_index in range(0, len(doc_entity_list), batch_size):
batch_doc_entity_list = doc_entity_list[batch_index:batch_index+batch_size]
# バッチごとのタスクを作成
batch_task_list = []
for i, (doc_name, doc_description) in enumerate(batch_doc_entity_list):
# 元のインデックスを計算
doc_index = batch_index + i
task = asyncio.create_task(process_doc_entity(doc_index, doc_name, doc_description))
batch_task_list.append(task)
# バッチごとの結果を待機
await asyncio.gather(*batch_task_list)
print("=" * 50 + "\n")
マージ処理の大まかな流れは以下です。
- ドキュメントの各エンティティのentity_nameをベクトル化します。
- コードの各エンティティのentity_nameから先頭のファイル名を抜いた定義名を抽出(「ファイル名:定義名」 → 「定義名」)してベクトル化します。
- ベクトル化したドキュメントの各entity_nameとベクトル化したコードのentity_nameの類似度を計算して、設定した類似度よりも高いエンティティをマージ対象として取得します。
-
ドキュメントの各エンティティそれぞれに対して類似度の高かったコードのエンティティ(複数)をマージします。
entity_nameは一意となるため、ドキュメントのentity_nameに統一します。それ以外のsource_idなどのパラメータは「<SEP>」がつけられた状態で連結されます。コードのdescripsionを連結する際は、entity_name(「ファイル名:定義名」)を先頭につけた状態で連結するように処理しています(どのコードファイル内にある定義の説明なのかを明確にするためです)。
実行準備(サンプル)
ドキュメントとソースコードがセットになった適切なサンプルがなかったため、LLMで作成したものを使用しました(今回入れるドキュメントはソースコードに対応する詳細設計書としています)。
サンプル
C++のQtにおける基本的な機能(ボタンやラベル、画面遷移など)を確認するプログラムです。
ソースコード
QT += widgets
TARGET = my_qt
TEMPLATE = app
SOURCES += main.cpp \
MainWindow.cpp \
SubWindow.cpp
HEADERS += MainWindow.h \
SubWindow.h
#include <QApplication>
#include <QStackedWidget>
#include "MainWindow.h"
#include "SubWindow.h"
int main(int argc, char *argv[]) {
QApplication app(argc, argv);
// スタックウィジェット
QStackedWidget stackedWidget;
// メインウィンドウ
MainWindow *mainWindow = new MainWindow(&stackedWidget);
stackedWidget.addWidget(mainWindow);
// サブウィンドウ
SubWindow *subWindow = new SubWindow(&stackedWidget);
stackedWidget.addWidget(subWindow);
// メインウィンドウの設定
stackedWidget.setFixedSize(600, 400);
stackedWidget.show();
return app.exec();
}
#ifndef MAINWINDOW_H
#define MAINWINDOW_H
#include <QWidget>
#include <QLabel>
#include <QLineEdit>
#include <QPushButton>
#include <QCheckBox>
#include <QRadioButton>
#include <QComboBox>
#include <QVBoxLayout>
#include <QHBoxLayout>
#include <QStackedWidget>
class MainWindow : public QWidget {
Q_OBJECT
public:
explicit MainWindow(QStackedWidget *stackedWidget, QWidget *parent = nullptr);
private slots:
void outputMessage();
void goToExample();
private:
QStackedWidget *stackedWidget;
QLabel *label;
QLineEdit *inputField;
QCheckBox *checkbox;
QRadioButton *radio1;
QRadioButton *radio2;
QComboBox *comboBox;
};
#endif
#include "MainWindow.h"
MainWindow::MainWindow(QStackedWidget *stackedWidget, QWidget *parent)
: QWidget(parent), stackedWidget(stackedWidget) {
// ラベル
label = new QLabel("initial_label", this);
// 入力フィールド
inputField = new QLineEdit(this);
inputField->setPlaceholderText("input_name");
// ボタン
QPushButton *button = new QPushButton("button", this);
connect(button, &QPushButton::clicked, this, &MainWindow::outputMessage);
// ラジオボタン
radio1 = new QRadioButton("option_1", this);
radio2 = new QRadioButton("option_2", this);
radio1->setChecked(true);
// コンボボックス
comboBox = new QComboBox(this);
comboBox->addItems({"1", "2", "3"});
// 画面遷移ボタン
QPushButton *exampleButton = new QPushButton("sub_window", this);
connect(exampleButton, &QPushButton::clicked, this, &MainWindow::goToExample);
// レイアウト作成
QVBoxLayout *layout = new QVBoxLayout(this);
// 上部
layout->addWidget(label);
layout->addWidget(inputField);
layout->addWidget(button);
// 中央
QHBoxLayout *optionLayout = new QHBoxLayout();
optionLayout->addWidget(radio1);
optionLayout->addWidget(radio2);
layout->addLayout(optionLayout);
// 下部
layout->addWidget(comboBox);
layout->addWidget(exampleButton);
setLayout(layout);
}
void MainWindow::outputMessage() {
QString name = inputField->text();
QString message = "Hello, " + name + "! ";
message += radio1->isChecked() ? "(option_1)" : "(option_2)";
label->setText(message);
}
void MainWindow::goToExample() {
stackedWidget->setCurrentIndex(1);
}
#ifndef SUBWINDOW_H
#define SUBWINDOW_H
#include <QWidget>
#include <QLabel>
#include <QPushButton>
#include <QVBoxLayout>
#include <QStackedWidget>
class SubWindow : public QWidget {
Q_OBJECT
public:
explicit SubWindow(QStackedWidget *stackedWidget, QWidget *parent = nullptr);
private slots:
void updateExampleMessage();
void goToMain();
private:
QStackedWidget *stackedWidget;
QLabel *localMessageLabel;
QString getExampleMessage();
};
#endif
#include "SubWindow.h"
SubWindow::SubWindow(QStackedWidget *stackedWidget, QWidget *parent)
: QWidget(parent), stackedWidget(stackedWidget) {
// ラベル
QLabel *label = new QLabel("sub_window", this);
// exampleメッセージ用ラベル
localMessageLabel = new QLabel("initial_label", this);
// 戻るボタン
QPushButton *backButton = new QPushButton("back", this);
connect(backButton, &QPushButton::clicked, this, &SubWindow::goToMain);
// 更新ボタン
QPushButton *updateButton = new QPushButton("button", this);
connect(updateButton, &QPushButton::clicked, this, &SubWindow::updateExampleMessage);
// レイアウト
QVBoxLayout *layout = new QVBoxLayout(this);
layout->addWidget(label);
layout->addWidget(localMessageLabel);
layout->addWidget(updateButton);
layout->addWidget(backButton);
setLayout(layout);
}
void SubWindow::updateExampleMessage() {
QString message = getExampleMessage();
localMessageLabel->setText(message);
}
void SubWindow::goToMain() {
stackedWidget->setCurrentIndex(0);
}
QString SubWindow::getExampleMessage() {
return "button_pressed";
}
ドキュメント
# main.cpp 詳細設計書
## 概要
このファイルはQtアプリケーションのエントリポイントとなるmain関数を実装します。メインウィンドウとサブウィンドウを持つスタックウィジェットを作成し、ウィンドウの切り替えが可能なアプリケーションを初期化します。
## インクルードファイル
- `QApplication`: Qtアプリケーションの基本クラス
- `QStackedWidget`: 複数のウィジェットを重ねて管理するクラス
- `MainWindow.h`: メインウィンドウクラスの定義
- `SubWindow.h`: サブウィンドウクラスの定義
## グローバル変数
なし
## 関数
### main関数
**引数**:
- `int argc`: コマンドライン引数の数
- `char *argv[]`: コマンドライン引数の配列
**戻り値**:
- `int`: アプリケーションの終了コード
**処理フロー**:
1. QApplicationインスタンスを作成
2. QStackedWidgetインスタンスを作成
3. MainWindowインスタンスを作成(スタックウィジェットを引数として渡す)
4. MainWindowをスタックウィジェットに追加
5. SubWindowインスタンスを作成(スタックウィジェットを引数として渡す)
6. SubWindowをスタックウィジェットに追加
7. スタックウィジェットのサイズを600x400に固定
8. スタックウィジェットを表示
9. アプリケーションのイベントループを開始し、終了コードを返す
## フローチャート
```mermaid
flowchart TD
A[開始] --> B[QApplicationインスタンスの作成]
B --> C[QStackedWidgetインスタンスの作成]
C --> D[MainWindowインスタンスの作成]
D --> E[MainWindowをスタックウィジェットに追加]
E --> F[SubWindowインスタンスの作成]
F --> G[SubWindowをスタックウィジェットに追加]
G --> H[スタックウィジェットのサイズを600x400に固定]
H --> I[スタックウィジェットを表示]
I --> J[アプリケーションのイベントループを開始]
J --> K[終了]
```
## 注意事項
- MainWindowとSubWindowには、作成したスタックウィジェットへの参照を渡すことで、画面遷移を実現できるようになっています。
- メインウィンドウは最初に表示されるウィンドウ(インデックス0)となります。
- ウィンドウのサイズは600x400ピクセルに固定されます。
# MainWindow.h 詳細設計書
## 概要
このヘッダーファイルはMainWindowクラスの宣言を提供します。MainWindowクラスはアプリケーションのメイン画面を定義し、ユーザーインターフェースの要素とその相互作用を管理します。
## インクルードガード
`MAINWINDOW_H` - 重複インクルードを防止するためのマクロ定義
## インクルードファイル
- `QWidget`: 基本的なGUIコンポーネントの基底クラス
- `QLabel`: テキストやイメージを表示するウィジェット
- `QLineEdit`: 一行のテキスト入力を提供するウィジェット
- `QPushButton`: クリック可能なボタン
- `QCheckBox`: チェックボックス(オン/オフの選択肢)
- `QRadioButton`: ラジオボタン(複数選択肢から一つ選択)
- `QComboBox`: ドロップダウンリスト
- `QVBoxLayout`: ウィジェットを垂直に配置するレイアウト
- `QHBoxLayout`: ウィジェットを水平に配置するレイアウト
- `QStackedWidget`: 複数のウィジェットを重ねて管理するウィジェット
## クラス: MainWindow
QWidgetを継承し、Q_OBJECTマクロを使用してQtのメタオブジェクトシステムを有効化します。
### 公開メンバ
#### コンストラクタ
**宣言**:
```cpp
explicit MainWindow(QStackedWidget *stackedWidget, QWidget *parent = nullptr);
```
**説明**:
- MainWindowクラスのインスタンスを初期化します
- `stackedWidget`: 画面遷移に使用するQStackedWidgetへのポインタ
- `parent`: 親ウィジェット。デフォルトはnullptr
### プライベートスロット
#### outputMessage
**宣言**:
```cpp
void outputMessage();
```
**説明**:
- ボタンクリック時に呼び出されるスロット
- 入力フィールドの内容を読み取り、ラジオボタンの選択状態に基づいてメッセージを生成し、ラベルに表示します
#### goToExample
**宣言**:
```cpp
void goToExample();
```
**説明**:
- 「sub_window」ボタンクリック時に呼び出されるスロット
- スタックウィジェットの現在のインデックスを変更し、サブウィンドウに画面遷移します
### プライベートメンバ変数
#### stackedWidget
**宣言**:
```cpp
QStackedWidget *stackedWidget;
```
**説明**:
- 画面遷移の管理に使用するQStackedWidgetへのポインタ
#### label
**宣言**:
```cpp
QLabel *label;
```
**説明**:
- メッセージを表示するためのQLabelへのポインタ
- 初期テキストは "initial_label"
#### inputField
**宣言**:
```cpp
QLineEdit *inputField;
```
**説明**:
- ユーザー入力を受け付けるQLineEditへのポインタ
- プレースホルダーテキストは "input_name"
#### checkbox
**宣言**:
```cpp
QCheckBox *checkbox;
```
**説明**:
- チェックボックスへのポインタ
- 注: 現在のMainWindow.cppの実装では使用されていません
#### radio1
**宣言**:
```cpp
QRadioButton *radio1;
```
**説明**:
- 「option_1」ラベルのラジオボタンへのポインタ
- 初期状態ではチェックされています
#### radio2
**宣言**:
```cpp
QRadioButton *radio2;
```
**説明**:
- 「option_2」ラベルのラジオボタンへのポインタ
#### comboBox
**宣言**:
```cpp
QComboBox *comboBox;
```
**説明**:
- 3つのアイテム("1", "2", "3")を持つドロップダウンリストへのポインタ
## クラス図
```mermaid
classDiagram
QWidget <|-- MainWindow
MainWindow : +MainWindow(QStackedWidget*, QWidget*)
MainWindow : -outputMessage()
MainWindow : -goToExample()
MainWindow : -QStackedWidget* stackedWidget
MainWindow : -QLabel* label
MainWindow : -QLineEdit* inputField
MainWindow : -QCheckBox* checkbox
MainWindow : -QRadioButton* radio1
MainWindow : -QRadioButton* radio2
MainWindow : -QComboBox* comboBox
```
## 注意事項
- このクラスはQ_OBJECTマクロを使用しているため、Qtのメタオブジェクトコンパイラ(MOC)による処理が必要です。
- `checkbox`メンバー変数は宣言されていますが、現在の実装(MainWindow.cpp)では使用されていません。
- 画面遷移はQStackedWidgetのインデックスを変更することで実現されています。
# MainWindow.cpp 詳細設計書
## 概要
このファイルはメインウィンドウのクラス実装を提供します。ユーザー入力フィールド、ボタン、ラジオボタン、コンボボックスなどのUI要素を配置し、それらの相互作用を管理します。
## インクルードファイル
- `MainWindow.h`: メインウィンドウクラスの定義
## クラス: MainWindow
### コンストラクタ
**引数**:
- `QStackedWidget *stackedWidget`: 画面遷移に使用するスタックウィジェット
- `QWidget *parent`: 親ウィジェット(デフォルト値: nullptr)
**処理**:
1. 親クラスのコンストラクタを呼び出す
2. スタックウィジェットのポインタを保存
3. UIコンポーネントの作成と初期化
- ラベル "initial_label" を作成
- 入力フィールドを作成し、プレースホルダーに "input_name" を設定
- "button" ラベルのボタンを作成し、クリック時に outputMessage スロットに接続
- "option_1" と "option_2" のラジオボタンを作成し、option_1 を初期選択状態に設定
- コンボボックスを作成し、アイテム "1", "2", "3" を追加
- "sub_window" ラベルの画面遷移ボタンを作成し、クリック時に goToExample スロットに接続
4. レイアウトの作成と設定
- メインの垂直レイアウトを作成
- 上部に ラベル、入力フィールド、ボタンを追加
- 中央に ラジオボタンを水平に配置
- 下部に コンボボックスと画面遷移ボタンを追加
5. レイアウトをウィジェットに設定
### outputMessage メソッド
**引数**: なし
**戻り値**: なし
**処理**:
1. 入力フィールドからテキストを取得
2. メッセージ文字列 "Hello, [name]! " を作成
3. ラジオボタンの状態に応じて "(option_1)" または "(option_2)" を追加
4. ラベルのテキストを更新したメッセージに設定
### goToExample メソッド
**引数**: なし
**戻り値**: なし
**処理**:
1. スタックウィジェットの表示インデックスを1に設定(サブウィンドウへ切り替え)
## フローチャート
### コンストラクタ
```mermaid
flowchart TD
A[開始] --> B[親クラスのコンストラクタ呼び出し]
B --> C[スタックウィジェットのポインタ保存]
C --> D[UIコンポーネントの作成]
D --> E[ボタンとスロットの接続]
E --> F[レイアウトの作成]
F --> G[コンポーネントをレイアウトに追加]
G --> H[レイアウトをウィジェットに設定]
H --> I[終了]
```
### outputMessage メソッド
```mermaid
flowchart TD
A[開始] --> B[入力フィールドからテキスト取得]
B --> C[基本メッセージ作成]
C --> D{ラジオボタン1が選択されているか?}
D -->|Yes| E[メッセージに(option_1)を追加]
D -->|No| F[メッセージに(option_2)を追加]
E --> G[ラベルテキストを更新]
F --> G
G --> H[終了]
```
### goToExample メソッド
```mermaid
flowchart TD
A[開始] --> B[スタックウィジェットのインデックスを1に設定]
B --> C[終了]
```
## 注意事項
- ユーザーが名前を入力せずにボタンをクリックした場合、"Hello, ! (option_X)" という形式のメッセージが表示されます。
- ラジオボタンは最初は "option_1" が選択された状態になります。
- コンボボックスの値は現在他の機能と連動していません。
- "sub_window" ボタンをクリックすると、サブウィンドウに画面遷移します。
# SubWindow.h 詳細設計書
## 概要
このヘッダーファイルは`SubWindow`クラスの宣言を提供します。`SubWindow`クラスはアプリケーションのサブ画面を定義し、主にメインウィンドウからの画面遷移先として機能します。ラベル、メッセージ表示用ラベル、更新ボタン、戻るボタンなどのUI要素を含みます。
## インクルードガード
`SUBWINDOW_H` - 重複インクルードを防止するためのマクロ定義
## インクルードファイル
- `QWidget`: 基本的なGUIコンポーネントの基底クラス
- `QLabel`: テキストやイメージを表示するウィジェット
- `QPushButton`: クリック可能なボタン
- `QVBoxLayout`: ウィジェットを垂直に配置するレイアウト
- `QStackedWidget`: 複数のウィジェットを重ねて管理するウィジェット
## クラス: SubWindow
QWidgetを継承し、Q_OBJECTマクロを使用してQtのメタオブジェクトシステムを有効化します。
### 公開メンバ
#### コンストラクタ
**宣言**:
```cpp
explicit SubWindow(QStackedWidget *stackedWidget, QWidget *parent = nullptr);
```
**説明**:
- SubWindowクラスのインスタンスを初期化します
- `stackedWidget`: 画面遷移に使用するQStackedWidgetへのポインタ
- `parent`: 親ウィジェット。デフォルトはnullptr
### プライベートスロット
#### updateExampleMessage
**宣言**:
```cpp
void updateExampleMessage();
```
**説明**:
- 更新ボタンクリック時に呼び出されるスロット
- getExampleMessage関数を呼び出し、返されたメッセージをlocalMessageLabelに設定します
#### goToMain
**宣言**:
```cpp
void goToMain();
```
**説明**:
- 「back」ボタンクリック時に呼び出されるスロット
- スタックウィジェットの現在のインデックスを0に変更し、メインウィンドウに画面遷移します
### プライベートメンバ変数
#### stackedWidget
**宣言**:
```cpp
QStackedWidget *stackedWidget;
```
**説明**:
- 画面遷移の管理に使用するQStackedWidgetへのポインタ
#### localMessageLabel
**宣言**:
```cpp
QLabel *localMessageLabel;
```
**説明**:
- メッセージを表示するためのQLabelへのポインタ
- 初期テキストは "initial_label"
### プライベートメソッド
#### getExampleMessage
**宣言**:
```cpp
QString getExampleMessage();
```
**説明**:
- ボタンが押された時に表示するメッセージを生成するヘルパーメソッド
- "button_pressed" という文字列を返します
## クラス図
```mermaid
classDiagram
QWidget <|-- SubWindow
SubWindow : +SubWindow(QStackedWidget*, QWidget*)
SubWindow : -updateExampleMessage()
SubWindow : -goToMain()
SubWindow : -QStackedWidget* stackedWidget
SubWindow : -QLabel* localMessageLabel
SubWindow : -QString getExampleMessage()
```
## シーケンス図
```mermaid
sequenceDiagram
participant ユーザー
participant SubWindow
participant QStackedWidget
ユーザー->>SubWindow: 更新ボタンをクリック
SubWindow->>SubWindow: updateExampleMessage()
SubWindow->>SubWindow: getExampleMessage()
SubWindow->>SubWindow: localMessageLabel->setText()
ユーザー->>SubWindow: 戻るボタンをクリック
SubWindow->>SubWindow: goToMain()
SubWindow->>QStackedWidget: setCurrentIndex(0)
```
## 注意事項
- このクラスはQ_OBJECTマクロを使用しているため、Qtのメタオブジェクトコンパイラ(MOC)による処理が必要です。
- 画面遷移はQStackedWidgetのインデックスを変更することで実現されています。
- getExampleMessage関数は常に固定文字列("button_pressed")を返すシンプルな実装ですが、将来的に動的なメッセージ生成のために拡張される可能性があります。
# SubWindow.cpp 詳細設計書
## 概要
このファイルはSubWindowクラスの実装を提供します。SubWindowはメインウィンドウから遷移するサブ画面として機能し、シンプルなユーザーインターフェースとメインウィンドウへの戻る機能を提供します。
## インクルードファイル
- `SubWindow.h`: SubWindowクラスの宣言
## クラス: SubWindow
### コンストラクタ
**引数**:
- `QStackedWidget *stackedWidget`: 画面遷移に使用するスタックウィジェット
- `QWidget *parent`: 親ウィジェット(デフォルト値: nullptr)
**処理**:
1. 親クラスのコンストラクタを呼び出す
2. スタックウィジェットのポインタを保存
3. UIコンポーネントの作成と初期化
- "sub_window" テキストのラベルを作成
- "initial_label" テキストのメッセージ用ラベル(localMessageLabel)を作成
- "back" ラベルの戻るボタンを作成し、クリック時に goToMain スロットに接続
- "button" ラベルの更新ボタンを作成し、クリック時に updateExampleMessage スロットに接続
4. 垂直レイアウトの作成と設定
- ラベルを追加
- メッセージ用ラベルを追加
- 更新ボタンを追加
- 戻るボタンを追加
5. レイアウトをウィジェットに設定
### updateExampleMessage メソッド
**引数**: なし
**戻り値**: なし
**処理**:
1. getExampleMessage メソッドを呼び出してメッセージを取得
2. localMessageLabel のテキストを取得したメッセージに更新
### goToMain メソッド
**引数**: なし
**戻り値**: なし
**処理**:
1. スタックウィジェットの表示インデックスを0に設定(メインウィンドウへ切り替え)
### getExampleMessage メソッド
**引数**: なし
**戻り値**:
- `QString`: "button_pressed" という固定文字列
**処理**:
1. "button_pressed" という文字列を返す
## フローチャート
### コンストラクタ
```mermaid
flowchart TD
A[開始] --> B[親クラスのコンストラクタ呼び出し]
B --> C[スタックウィジェットのポインタ保存]
C --> D[UIコンポーネントの作成]
D --> E[ボタンとスロットの接続]
E --> F[レイアウトの作成]
F --> G[コンポーネントをレイアウトに追加]
G --> H[レイアウトをウィジェットに設定]
H --> I[終了]
```
### updateExampleMessage メソッド
```mermaid
flowchart TD
A[開始] --> B[getExampleMessageを呼び出しメッセージを取得]
B --> C[localMessageLabelのテキストを更新]
C --> D[終了]
```
### goToMain メソッド
```mermaid
flowchart TD
A[開始] --> B[スタックウィジェットのインデックスを0に設定]
B --> C[終了]
```
### getExampleMessage メソッド
```mermaid
flowchart TD
A[開始] --> B[文字列"button_pressed"を返す]
B --> C[終了]
```
## 注意事項
- SubWindowは単純な画面で、画面上のラベル、更新ボタン、戻るボタンのみを提供します。
- "button" ボタンをクリックすると、localMessageLabelのテキストが "button_pressed" に更新されます。
- "back" ボタンをクリックすると、メインウィンドウに戻ります。
- getExampleMessage メソッドは現在固定文字列を返すだけですが、将来的に動的なメッセージ生成ロジックに拡張できるよう分離されています。
上記サンプルをread_dir_pathで設定したディレクトリに配置します。
実行結果
パラメータのread_dir_path、storage_dir_path、api_keyを自環境のものに変更して実行してください。
==================================================
処理予定ファイル
コードファイル: /home/yumefuku/llm-code-graphrag/read_dir/MainWindow.cpp
コードファイル: /home/yumefuku/llm-code-graphrag/read_dir/main.cpp
テキストファイル: /home/yumefuku/llm-code-graphrag/read_dir/MainWindow_cpp_設計書.md
テキストファイル: /home/yumefuku/llm-code-graphrag/read_dir/SubWindow_cpp_設計書.md
コードファイル: /home/yumefuku/llm-code-graphrag/read_dir/SubWindow.h
コードファイル: /home/yumefuku/llm-code-graphrag/read_dir/MainWindow.h
テキストファイル: /home/yumefuku/llm-code-graphrag/read_dir/MainWindow_h_設計書.md
テキストファイル: /home/yumefuku/llm-code-graphrag/read_dir/SubWindow_h_設計書.md
コードファイル: /home/yumefuku/llm-code-graphrag/read_dir/SubWindow.cpp
テキストファイル: /home/yumefuku/llm-code-graphrag/read_dir/main_cpp_設計書.md
==================================================
==================================================
ドキュメントファイルのグラフ化
処理完了:/home/yumefuku/llm-code-graphrag/read_dir/MainWindow_cpp_設計書.md
処理完了:/home/yumefuku/llm-code-graphrag/read_dir/SubWindow_cpp_設計書.md
処理完了:/home/yumefuku/llm-code-graphrag/read_dir/MainWindow_h_設計書.md
処理完了:/home/yumefuku/llm-code-graphrag/read_dir/SubWindow_h_設計書.md
処理完了:/home/yumefuku/llm-code-graphrag/read_dir/main_cpp_設計書.md
==================================================
==================================================
コードファイルのグラフ化
処理完了:/home/yumefuku/llm-code-graphrag/read_dir/SubWindow.h
処理完了:/home/yumefuku/llm-code-graphrag/read_dir/MainWindow.h
処理完了:/home/yumefuku/llm-code-graphrag/read_dir/main.cpp
処理完了:/home/yumefuku/llm-code-graphrag/read_dir/SubWindow.cpp
処理完了:/home/yumefuku/llm-code-graphrag/read_dir/MainWindow.cpp
==================================================
==================================================
エンティティのマージ
--------------------------------------------------
マージ対象のエンティティ
MainWindow
1: MainWindow.cpp:MainWindow
--------------------------------------------------
--------------------------------------------------
マージ対象のエンティティ
SubWindow
1: SubWindow.cpp:SubWindow
--------------------------------------------------
--------------------------------------------------
マージ対象のエンティティ
getExampleMessage
1: SubWindow.cpp:getExampleMessage
--------------------------------------------------
--------------------------------------------------
マージ対象のエンティティ
goToExample
1: MainWindow.cpp:goToExample
--------------------------------------------------
--------------------------------------------------
マージ対象のエンティティ
goToMain
1: SubWindow.cpp:goToMain
--------------------------------------------------
--------------------------------------------------
マージ対象のエンティティ
main
1: main.cpp:main
--------------------------------------------------
--------------------------------------------------
マージ対象のエンティティ
outputMessage
1: MainWindow.cpp:outputMessage
--------------------------------------------------
--------------------------------------------------
マージ対象のエンティティ
updateExampleMessage
1: SubWindow.cpp:updateExampleMessage
--------------------------------------------------
==================================================
処理時間: 00h:01m:19.1s
-
処理対象ファイル
ドキュメント: 5ファイル
コード: 5ファイル(my_qt.proは対象外) -
マージ
エンティティ: 8個
(今回、C++の抽出対象ノードとして「変数名」などエンティティ名として被るものを設定していないため、ドキュメントにマージされるコードのエンティティも一個ずつとなっています。) -
処理時間
00h:01m:19.1s
(参考として)実行時にかかったAPIの料金は0.07$ほどでした。
グラフの可視化
LightRAGにはグラフの可視化機能を提供するLightRAG Serverがありますが、以下のようなコードでも(ノードとエッジがあるだけの簡単なものですが)グラフを可視化できます。
graph_pathに生成されたストレージ内の「graph_chunk_entity_relation.graphml」のパスを設定後、実行してください。
ソースコード
import matplotlib.pyplot as plt
import networkx as nx
# フォント設定
plt.rcParams['font.family'] = 'IPAexGothic'
plt.rcParams['axes.unicode_minus'] = False
# グラフのパスを設定
graph_path = "./storage_dir/graph_chunk_entity_relation.graphml"
# GraphMLファイルを読み込む
graph = nx.read_graphml(graph_path)
# レイアウトの設定
pos = nx.spring_layout(graph, k=2.5, iterations=50)
# ノードサイズの設定
node_sizes = [max(500 * graph.degree(n), 300) for n in graph.nodes()]
# グラフを描画
plt.figure(figsize=(15, 10))
# ノード描画
nx.draw_networkx_nodes(
graph,
pos,
node_size=node_sizes,
node_color="lightblue",
alpha=0.8
)
# ノードラベルの設定
labels = {node: node for node in graph.nodes()}
# ラベルの描画
nx.draw_networkx_labels(
graph,
pos,
labels=labels,
font_size=12,
font_family='IPAexGothic',
bbox=dict(facecolor='white', edgecolor='none', alpha=0.7)
)
# エッジの描画
nx.draw_networkx_edges(
graph,
pos,
edge_color="gray",
alpha=0.6
)
# エッジラベルの設定
edge_labels = nx.get_edge_attributes(graph, "label")
# エッジラベルの描画
nx.draw_networkx_edge_labels(
graph,
pos,
edge_labels=edge_labels,
font_size=8,
font_family='IPAexGothic'
)
# グラフの表示
plt.show()
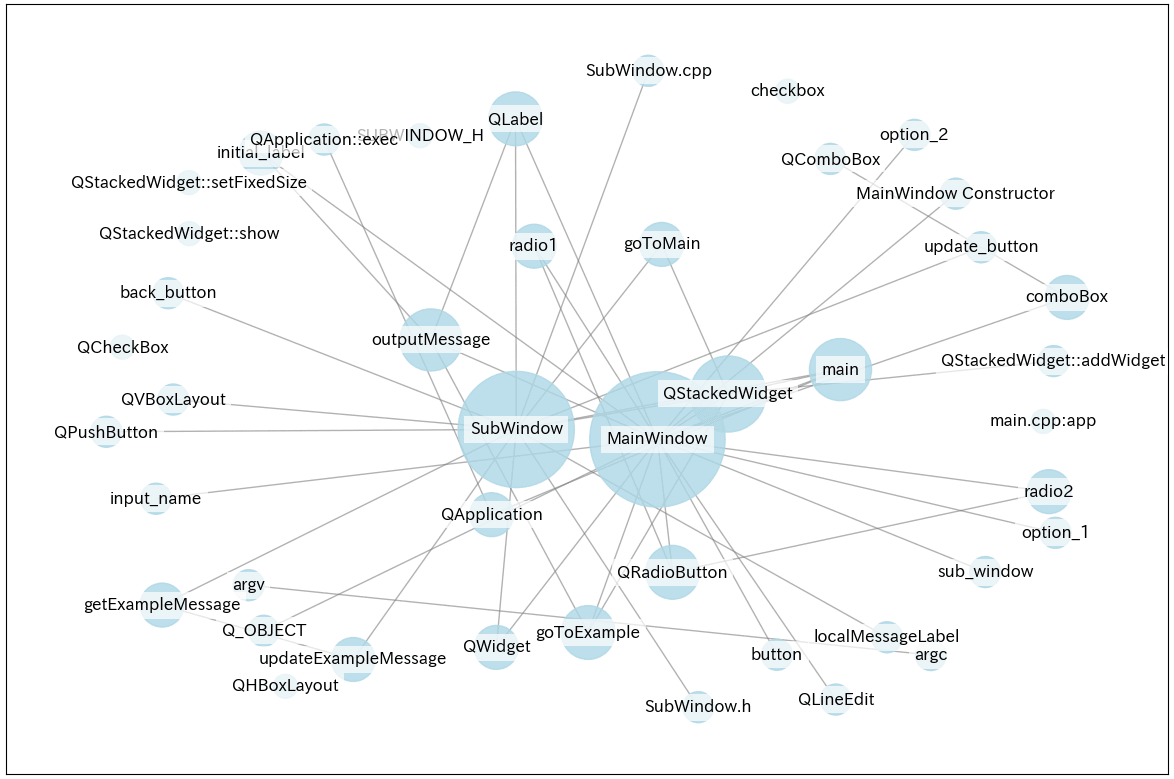
グラフの内容を元に会話
以下のstorage_dir_path、api_keyを自環境のものに変更して実行してください。
ソースコード
import asyncio
import anthropic
from transformers import AutoModel, AutoTokenizer
from lightrag.utils import EmbeddingFunc
from lightrag.llm.hf import hf_embed
from lightrag import LightRAG, QueryParam
from lightrag.kg.shared_storage import initialize_pipeline_status
storage_dir_path = "./storage_dir"
# 使用するLLM(anthropic)の設定
model_name = "claude-sonnet-4-20250514" # LLMの名前
llm_max_token_size = 8192 # LLMの最大トークン数
api_key = "APIキー" # anthropicのAPIキー
client = anthropic.AsyncAnthropic(api_key=api_key) # 非同期用anthropicクライアントを取得
# 使用する埋め込みモデルの設定
emb_name = "BAAI/bge-m3" # 埋め込みモデル名
embedding_dim = 1024 # 次元数
emb_max_token_size = 2048 # 埋め込みモデルの最大トークン数
emb_model = AutoModel.from_pretrained(emb_name) # 埋め込みモデルを取得
tokenizer = AutoTokenizer.from_pretrained(emb_name) # 埋め込みモデルのトークナイザーを取得
async def main():
rag: LightRAG = None
try:
# LightRagの初期化処理を実行
rag = await initialize_rag()
# 会話を実行
await conversation_rag(rag)
except Exception as e:
print(f"エラーが発生しました:\n{e}")
finally:
if rag:
await rag.finalize_storages()
# LightRAGの初期化を行う関数
async def initialize_rag() -> LightRAG:
# LightRAGの初期化(各種パラメータを設定)
rag = LightRAG(
working_dir=storage_dir_path,
llm_model_func=anthropic_complete, # 会話に使用する関数を設定
summary_max_tokens=llm_max_token_size, # 要約生成の最大トークン数を設定
embedding_func=EmbeddingFunc( # 埋め込みに使用する関数を設定
embedding_dim=embedding_dim, # 埋め込みモデルの次元数を設定
max_token_size=emb_max_token_size, # 埋め込みモデルの最大トークン数を設定
func=lambda texts: hf_embed( # lambdaで渡されたテキストをベクトル化する関数を設定
texts,
tokenizer=tokenizer,
embed_model=emb_model,
)
)
)
# ストレージの初期化
await rag.initialize_storages()
await initialize_pipeline_status()
return rag
# Anthropicクライアントの実行用関数
async def anthropic_complete(
prompt: str,
system_prompt: str="",
history_messages: list=[],
**kwargs
):
# 会話履歴の設定
messages = []
messages.extend(history_messages)
# メッセージにプロンプトを追加
messages.append(
{
"role": "user",
"content": prompt
}
)
# 最大トークンサイズを設定
max_tokens = kwargs.get('max_tokens', llm_max_token_size)
# LLMの実行
response = await client.messages.create(
system=system_prompt,
model=model_name,
max_tokens=max_tokens,
messages=messages,
)
# 応答の返却
return response.content[0].text
# 会話の実行用関数
async def conversation_rag(rag: LightRAG):
# 会話履歴を格納するリスト
conversation_history = []
# 最大10ターンの会話を実行
for i in range(1, 11):
# ユーザー入力
user_input = input("\n# ユーザー: ")
# 終了条件("exit"で終了)
if user_input.lower() == 'exit':
print("会話を終了します。")
break
# 質問用のパラメータを作成
query_param = QueryParam(
mode="hybrid", # コンテキストの抽出方法をモードで指定("local", "hybrid", "naive", "mix")
top_k=5, # コンテキストとして使用する上位項目数(エンティティ、リレーションシップなど)
conversation_history=conversation_history, # 会話履歴を設定
history_turns=5 # 考慮する会話のターン数
)
# LLMからの回答を取得
response = await rag.aquery(
query=user_input, # 質問文を設定
param=query_param # 質問用のパラメータを設定
)
# LLMからの回答を表示
print(f"\n{response}")
# 会話履歴にユーザーメッセージを追加
conversation_history.append(
{
"role": "user",
"content": user_input
}
)
# 会話履歴にLLMの回答を追加
conversation_history.append(
{
"role": "assistant",
"content": response
}
)
if __name__ == "__main__":
asyncio.run(main())
※ LLMに関してですが、グラフの作成ではclaude-3-5-haiku-20241022、会話にはclaude-sonnet-4-20250514を使用しています(グラフの作成はエンティティの抽出などで大量の情報を扱うため、コストが低く処理の早いモデルを使用しています。実際に会話を行う際はそこまでコストがかからず速度も気にならないため、精度の高いモデルを使用しました)。
会話の実行結果
# ユーザー: サブウィンドウ内の機能について簡単に教えてください。
# サブウィンドウの機能について
## 概要
サブウィンドウ(SubWindow)は、メインウィンドウから画面遷移できるセカンダリウィンドウとして機能します。QWidgetを継承したクラスで、シンプルなユーザーインターフェースを提供します。
## 主要な機能
### UI要素
サブウィンドウには以下のUI要素が配置されています:
- **ラベル**: "sub_window"というテキストを表示するタイトルラベル
- **メッセージ表示ラベル**: 初期値は"initial_label"で、動的にメッセージを更新できる
- **更新ボタン**: "button"というラベルのボタン
- **戻るボタン**: "back"というラベルのボタン
### 機能的な動作
#### メッセージ更新機能
- 更新ボタンをクリックすると、`updateExampleMessage`メソッドが呼び出されます
- 内部で`getExampleMessage`メソッドを使用して"button_pressed"という固定メッセージを取得
- このメッセージがlocalMessageLabelに表示されます
#### 画面遷移機能
- 戻るボタンをクリックすると、`goToMain`メソッドが実行されます
- QStackedWidgetのインデックスを0に設定することで、メインウィンドウに戻ります
## 技術的特徴
### レイアウト管理
- QVBoxLayoutを使用して、すべてのUI要素を垂直に配置
- 上から順に:ラベル、メッセージラベル、更新ボタン、戻るボタンの順序
### 画面遷移の仕組み
- コンストラクタでQStackedWidgetへのポインタを受け取り保存
- このポインタを使用して画面遷移を制御
- メインウィンドウ(インデックス0)とサブウィンドウ(インデックス1)間の切り替えが可能
サブウィンドウは基本的な相互作用機能を持つシンプルな画面として設計されており、将来的にはgetExampleMessageメソッドを拡張してより動的なメッセージ生成ロジックを実装することも可能です。
## References
[DC] /home/yumefuku/llm-code-graphrag/read_dir/SubWindow_cpp_設計書.md
[DC] /home/yumefuku/llm-code-graphrag/read_dir/SubWindow_h_設計書.md
[KG] /home/yumefuku/llm-code-graphrag/read_dir/SubWindow_cpp_設計書.md
[KG] /home/yumefuku/llm-code-graphrag/read_dir/main_cpp_設計書.md
[KG] /home/yumefuku/llm-code-graphrag/read_dir/SubWindow_h_設計書.md
# ユーザー: メッセージ更新機能についてコードを提示して簡単に説明してください。
# サブウィンドウのメッセージ更新機能
## 概要
サブウィンドウのメッセージ更新機能は、ユーザーが更新ボタンをクリックした際に、表示されているメッセージラベルの内容を動的に変更する機能です。
## 実装コード
### updateExampleMessage メソッド
```cpp
void SubWindow::updateExampleMessage() {
QString message = getExampleMessage();
localMessageLabel->setText(message);
}
```
### getExampleMessage メソッド
```cpp
QString SubWindow::getExampleMessage() {
return "button_pressed";
}
```
## 機能の流れ
### 1. ボタンクリック時の処理
- ユーザーが更新ボタン("button"ラベル)をクリック
- `updateExampleMessage`スロット関数が呼び出される
### 2. メッセージ取得
- `updateExampleMessage`メソッド内で`getExampleMessage`メソッドを呼び出し
- 現在は固定文字列"button_pressed"を返す
### 3. 表示更新
- 取得したメッセージを`localMessageLabel`の`setText`メソッドで設定
- ラベルの表示内容が"initial_label"から"button_pressed"に変更される
## 設計の特徴
### メソッド分離の利点
- `getExampleMessage`メソッドを独立させることで、将来的に動的なメッセージ生成ロジックに拡張可能
- 現在は固定文字列を返すシンプルな実装だが、拡張性を考慮した設計
### UI連携
- コンストラクタでボタンのクリックシグナルと`updateExampleMessage`スロットを接続
- Qtのシグナル・スロット機構を活用したイベント駆動型の実装
この機能により、ユーザーはサブウィンドウ内でボタンをクリックするだけで、表示メッセージをリアルタイムで更新できます。
## References
[DC] /home/yumefuku/llm-code-graphrag/read_dir/SubWindow_cpp_設計書.md
[DC] /home/yumefuku/llm-code-graphrag/read_dir/SubWindow_h_設計書.md
[KG] /home/yumefuku/llm-code-graphrag/read_dir/SubWindow_cpp_設計書.md
[KG] /home/yumefuku/llm-code-graphrag/read_dir/SubWindow_h_設計書.md
# ユーザー: exit
会話を終了します。
回答に誤りは見受けられませんでした。
また、実装コード(updateExampleMessage()、getExampleMessage())を提示した上での回答も問題なく行われています(チャンクからソースコードが取得出来ています)。
おわりに
今回の記事では扱っていませんがLightRAGには「データエクスポート」や「他ストレージ(neo4jやPostgreSQL)の対応」など多くの機能が用意されております。
より、ユースケースに合わせた実装が必要な場合は公式のREADEMEをご確認ください(パラメータに関しても記事内ではあまり触れておりません。グラフの作成やQueryの細かいパラメータ調整が必要な場合もご一読をお勧めします)。
長くなりましたが、ここまで読んでくださった方、ありがとうございました。
また機会があればよろしくお願いします。
Discussion