kaggle LLMコンペ 上位解法まとめ
はじめに
科学分野の5択問題を解くLLMの精度を競うKaggle - LLM Science Exam というkaggleコンペが2023/10/11まで開催されていました。
コンペ終了後に公開された上位チームの解法からたくさん学びがあったので、備忘録も兼ねてまとめていきたいと思います。
コンペ概要
- 問題文(prompt)とA~Eの選択肢(option)が与えられ、それを解くモデルの精度を競うコンペでした。
- テストデータはSTEM分野のWikipedia記事からGPT3.5に作成させたことがDataタブで明言されていました。

上位チーム解法まとめ
1. Approach
- 全てのチームが、問題の生成元となった記事をwikiテキストデータセットから検索(Retrieval)し、関連するテキスト(context)もモデルに入力するRAGと呼ばれるアプローチを採用していました。
- RAGを行わないとモデルは事前学習で得られた知識のみに依存するため、一定のスコアで精度が頭打ちになります。そのため、このコンペではRetrievalの精度を上げて正解情報を含むcontextをいかに取ってこれるかがスコアアップの大きなキーになっていました。
- RAGアプローチの詳細はこちらのdiscussionで詳しく説明されています。(60k Dataset Achieves LB 0.830+)
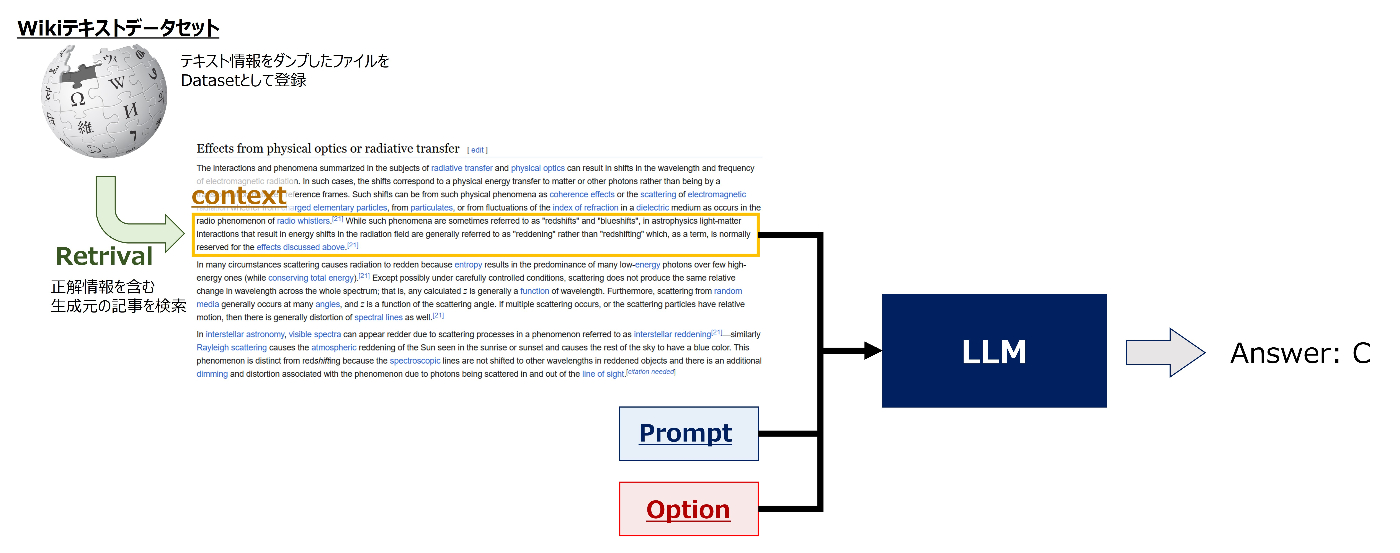
2. Retrieval
Wikiテキストデータセット
- ベースラインNotebookで使用されていたwikiテキストデータセットは記事やセクションに欠損があるという課題がありました。
- 上位チームはこの課題に対応するため、"欠損の無いwikiテキストデータセットを使用する" or "複数のwikiテキストデータセットを組み合わせる"のいずれかの方法を取っていました。
- 以下のwikiテキストデータセットが上位チームではよく使用されていた印象です。
-
cirrussearch wiki dump(引用:1st, 4th, 10th, etc...)
- 欠損がほぼ無い。ただし、改行文字が含まれていないためセクションに分割することができない。
-
MB 270K(引用:7th, 10th, 12th, etc...)
- コンペ終盤に公開されたWikiAPIを使って収集された欠損の無いwikiテキストデータセット。コンペで提供された学習データ200サンプルをベースにクラスタリングでSTEM関連記事を270K収集している。
-
独自データセット(引用:3rd, 5th, 6th, etc...)
- 主にパーサーを変更したりカスタマイズすることで欠損の無いテキストデータセットを生成していた印象。
-
sentence transformer
-
検索は主にsentence transformerベースの手法が主流で、モデルはbge, gte, e5がよく使用されていました。モデルはHuggingFaceのmtebリーダーボードを参考に実験的に選定していたようです。(引用:1st, etc...)
-
ほとんどのチームが記事をある程度の長さで分割して全文を検索対象としていました。分割単位は、「パラグラフや一文単位で分割」しているパターンと「一定トークン数で区切って分割」しているパターンのいずれかが多く、後者の分割トークン数は大体100〜1000の範囲で各チームごとに特色がありました。
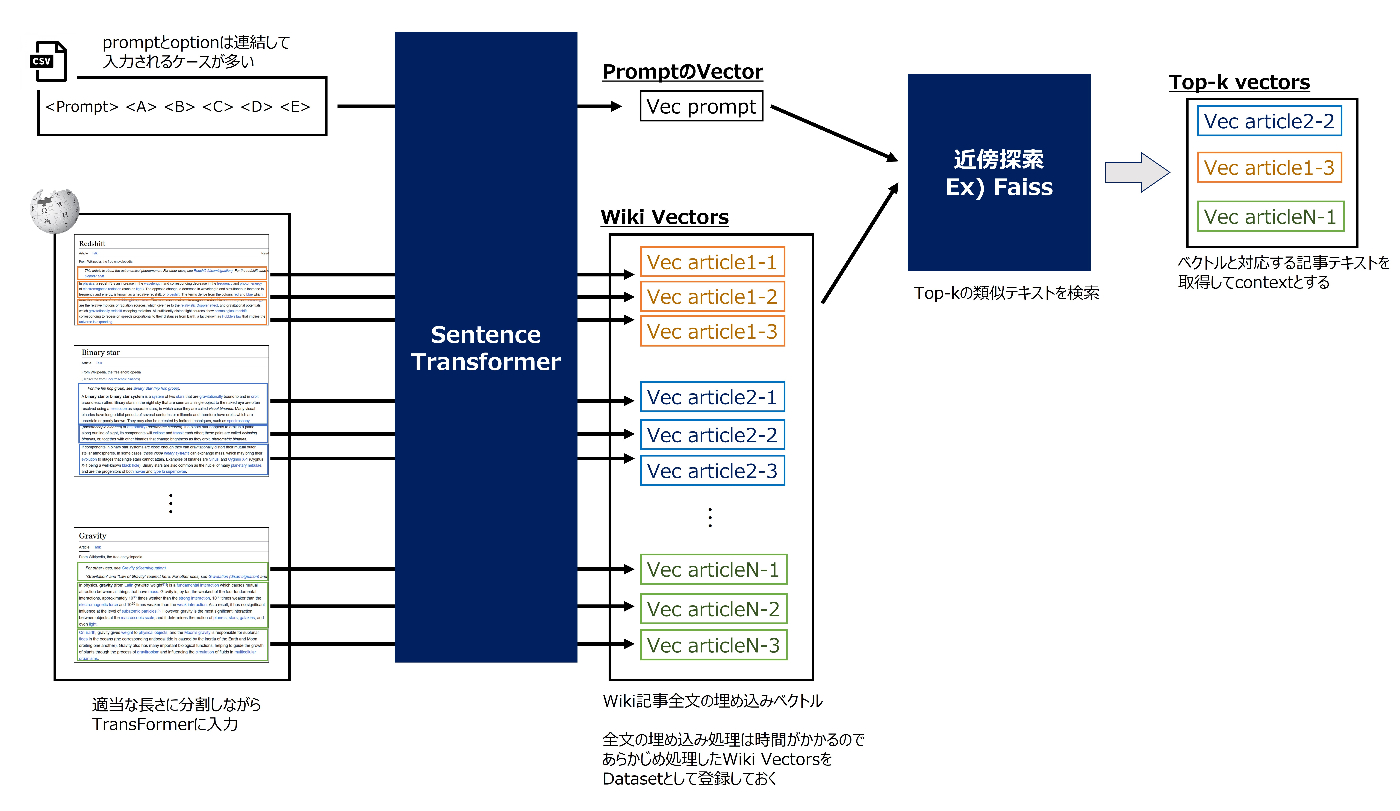
- 単純に記事全文のベクトルを検索しようとするとメモリ不足でエラーになるので、上位チームはメモリ節約の工夫をして検索をしていました。
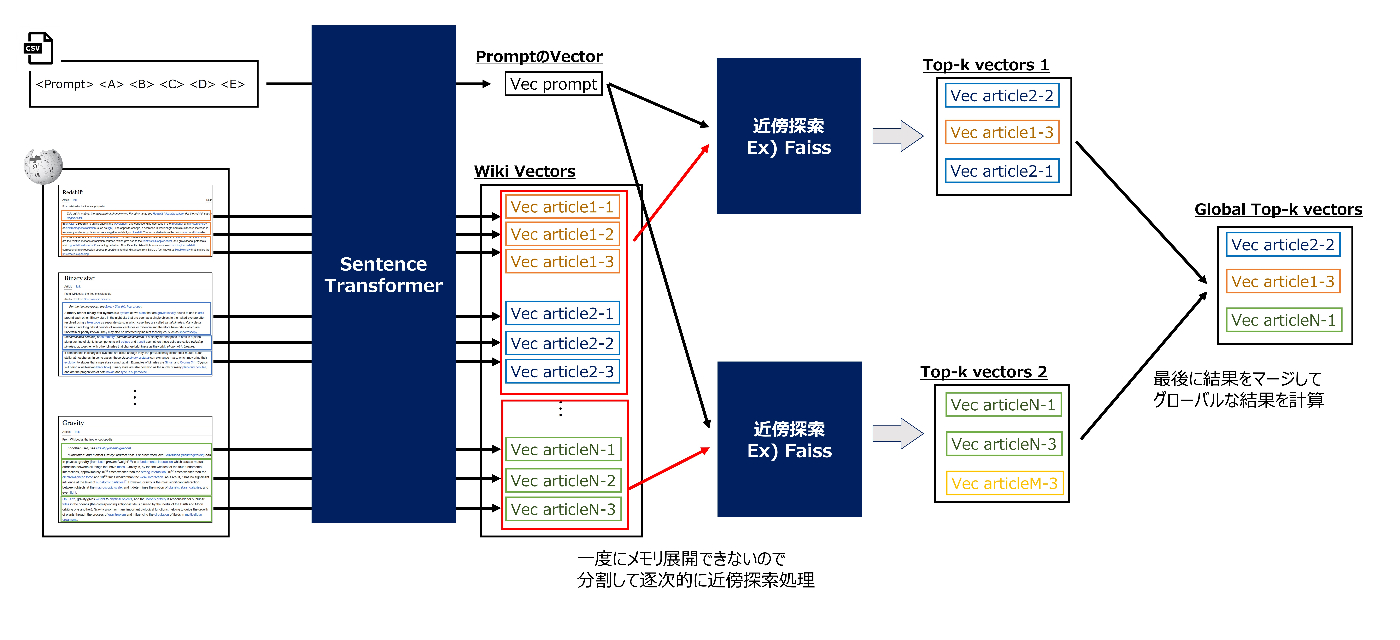
TF-IDF
- 様々な検索手法を組み合わせることでcontextの多様性が上がるため、古典的な手法を組み合わせているチームも多くありました。(引用:7th, 10th)
- 公開ノートブックで採用されていたこともありTF-IDFを使用しているチームが多かったですが、BM25など別な手法を採用していたチームもいました。(引用:5th)
Rerankerモデル
- 最初にある程度多くの候補記事を検索してから、Rerankerモデルで再ランク付けして上位記事を絞り込む手法で検索精度を上げているチームもいました。(引用:2nd, 3rd, 6th)
- 3rdチームはRerankerモデルを上手くファインチューニングしており、学習のtipsがいくつか紹介されています。
Validation
- コンペから提供されたデータには生成元のwiki記事情報が含まれていないため、検索モデルの性能を評価することが難しかったのですが、いくつかの上位チームはそれぞれ独自のスキームで検証を行っていたようです。
3. Model
アーキテクチャ
- BERT系の軽量モデル(Deberta-v3-large)、GPT系のLLMモデルが多く使用されていました。
- 金圏上位はLLMモデルを上手くソリューションに組み込んでいた印象です。
| Model Configuration | Teams |
|---|---|
| Deberta-v3(BERT)メイン | 4th, 10th, 11th, 12th, 13th, 14th |
| LLM(GPT)メイン | 1st, 5th |
| ハイブリッド | 2nd, 3rd, 6th, 7th |
- LLMモデルを組み込んだソリューションにもいくつかパターンがあり、7Bや13Bくらいの小さめのLLMを複数使用しているチーム(1st, 7th, etc...)や70Bの大きなLLMを組み込んでいるチーム(3rd, 5th, etc..)がありました。
- LLMモデルはMistral、llama2(およびその派生)がよく使用されていました。
バイナリモデル vs クロスオプションモデル
-
多肢選択問題を扱うには、「一度に1つの選択肢のみを入力して、その選択肢が正解か不正解かを予測する2値分類」として扱うバイナリモデル方式(
MultipleChoiceやReward Modelingなど)と、「一度にすべての選択肢を入力して、正解の選択肢を予測する多値分類」として扱うクロスオプションモデル方式(span-classificationやCausalLMなど)の2パターンの方式があります。 ※正確には分類タスクとは限らないが、便宜上"分類タスク"と表現 -
公開ノートブックではDeberta-v3をMultipleChoiceタスクとして扱うバイナリモデル方式が採用されており、上位チームの多くも同様の方式を採用していました。
-
ただし、それぞれ対照的なメリット・デメリットがあり、金圏上位チームはそれぞれを組み合わせる、もしくはそれぞれの方式のデメリットをカバーするような工夫を上手く組み込んでスコアを上げていたように思います。
- 1stチームはLLMに二値分類用のヘッドを追加してバイナリモデル方式を採用していましたが、推論時に他選択肢のロジットの平均を分類ヘッドに追加入力することでクロスオプション情報を反映させていました。(引用:1st)
- 5thチームは
{context} {prompt} {A} {B} {C} {D} {E} Answer:のようなプロンプトをLLMに入力して、_A~_Eトークンが次に来る確率で正解の予測を行うクロスオプションモデル方式を採用していました。クロスオプションの場合、入力時の選択肢の並び順に影響を受けやすい(位置バイアス)という課題がありますが、選択肢の順番を並び替えるTTAで位置バイアスの影響を軽減していたとのことです。ちなみに70B LLMでTTAを5回やると通常はタイムアウトしますが、全通りの並べ方パターンを連結してAttention Maskを適切に設定して共通部分の推論を1回に抑える工夫で制限時間内での実行を可能にしていました。(引用:5th)
| Method | メリット | デメリット |
|---|---|---|
| バイナリモデル | ・位置バイアスの影響を受けない ・inputのcontextを長く取れる |
・他選択肢の情報を予測に使えない ・複数回の推論が必要なので処理時間がかかる |
| クロスオプションモデル | ・予測に全選択肢の情報を使うことができる ・1回の推論で全選択肢の予測ができるので高速 |
・位置バイアス(選択肢の並び順)の影響を受けやすい |
4. Train
LoRA / QLoRA
- LLMの学習にはLoRAやQLoRAが使用されていました。
- trlライブラリを用いることで簡単に実装でき、7Bや13BのLLMであれば24GB程度のGPUでも学習できるので、今後もLLMを使うコンペではLoRAがスタンダードな方法になりそうです。
- 70Bレベルになると要求されるハードウェアスペックも高くなるため、ゼロショット学習で使用しているチームが多かったですが、5thチームはA100 80GBのマシンを使ってQLoRAでモデル学習を行なっていたようです。(引用:5th)
5. Predict
マルチステージ推論
- まずDeberta-v3などのパラメータ数の少ない軽いモデルで全サンプルを推論し、予測信頼度が低いサンプルのみをさらに大きなモデルで推論する多段階推論を採用しているチームも多かったです。(引用:5th, 7th, etc...)
- パラメータ数の大きいLLMモデルは処理時間がかかるので、推論対象を難しいサンプルに絞ることで時間節約する方法が今回のコンペでは効果的だったようです。
キャッシュを用いた高速化
- バイナリモデル方式の場合、1サンプルの予測にoptionの数だけモデル推論する必要があるので処理時間がかかるデメリットがありますが、GPT系統のモデルであれば共通部分の処理結果をキャッシュしておくことで推論時間を短縮を行なうことが可能になります。1stチームはこの方法で多くのLLMモデルをアンサンブルに組み込んでいました。
-
<context> <prompt> <option>のような入力フォーマットの場合、前半の<context> <prompt>の部分は全てのoption共通なので、その時点までの処理結果をキャッシュして使い回すことで処理時間を短縮できるイメージ。 - 具体的な実装方法は1stチームが推論ノートブックを公開してくれています。HFで比較的シンプルに実現することができるようです。(1st place. Single model inference)
LLM-70Bモデルのカーネル上での実行
- 計算資源が限られたkaggleカーネルで70Bレベルの大規模モデルを単純にロードしようとするとメモリに乗り切らないので、量子化した重みをレイヤーごとにロードして推論するといった工夫が必要になります。
- かなりテクニカルな方法ですが、実装方法を解説してくれているDiscussionやNotebookが公開されていて、こちらが参考になります。
6. Ensemble
XGB Ranker
- 2ndチームは、Retrivalモデルのスコア、Deberta/LLMの予測logit、"None of avobe"という選択肢が含まれるかどうかのフラグ、を特徴量としてXGBでスタッキングを行い、最終アンサンブルに組み込んでいました。(引用:2nd)
- コンペで提供された学習データの中には"None of avobe"(「正解の選択肢は存在しない」)という選択肢が含まれるサンプルが存在していました。2nd solutionによると、実験的にすべてのサンプルの正解選択肢を"None of avobe"に置換して推論したところ精度が大幅に下がった(MAP@3 0.9 → 0.3)ことから、private testにこのようなサンプルが多く含まれているとshakeの危険性があると判断して、"None of avobe"の特徴も含めたスタッキングを採用していたとのことです。
- 今回はそのようなサンプルがtestデータにもあまり含まれていなかったらしく、アブレーション実験の結果を見てもあまりスコアに寄与していなかったようですが、このようなshake対策の考え方はとても参考になりました。
Reference
コンペ終了後に色んな方がDiscussionやまとめ記事を公開してくれていました。どれも読みやすく、それぞれどういうところに着目してるか分かってとても面白かったです。
- Kaggleコンペ(LLM Science Exam)の振り返りと上位解法まとめ
- I learned a lot through the competition!
- What is the difference between a good and a great solution?
まとめ
今回のコンペで上位に行くにはRetrievalが最もキーだったように思います。やはり正解情報を直接参照できるので、contextをより良くすることが重要だったのではないかと思います。
その上で、更に上位のチームはLLMをはじめとしたモデル部分の工夫も様々おこなっており、限られた時間の中でアイデアを実現するエンジニアリング力や実験管理能力みたいなものもやっぱり大事なんだなぁと改めて感じました。
また、このコンペではLoRAのようなLLM学習方法をはじめ、最近流行りのLLMについて多くのことを学べた良いコンペだったと思います。
それと同時にkaggleカーネル上で70B LLMを動かしたり、9hという制限時間で複数のLLMを実行する方法なども共有されて、今後のコンペでも少しずつLLMを使ったソリューションが出てくるのかなと感じました。
これをきっかけに継続的にキャッチアップを続けて、取り残されないように頑張りたいです。
Discussion