Kaggleコンペ(LLM Science Exam)の振り返りと上位解法まとめ
コンペURL

どんなコンペ?
LLM(ChatGPT)が作った科学・技術・工学・数学分野の問題をKaggle notebookという限られた環境下(主にメモリ13GBと9時間以内に完了)でどのくらいの精度で解けますか?という自然言語処理系のコンペ。
以下に入出力例を示しています。
・入力
(質問)バタフライエフェクトとは何ですか?
(A)バタフライ効果とは、巨大な球体が不安定な平衡点から...
(B)バタフライ効果は、古典物理学における必要条件...
(C)バタフライ効果は、古典物理学における物理現象の...
(D)バタフライ効果とは、巨大な球体が不安定な平衡点から....
(E)バタフライ効果は、物理学における因果関係の概念の適用と....
・出力
E A B (解答を可能性の高い順番に出力)
評価指標はMAP@3(Mean Average Precision)でした。
ベースライン解法
ChrisさんのNotebookが上位何人かのbaselineになっていました。
図解すると以下のようになります。

LLMなどに背景情報を与えることは 検索拡張生成 (RAG: Retrieval Augmented Generation) といい、質問-解答のペアから、どう関連度の高いcontextを持ってくるか?がこのコンテストにおいて差がつく部分となりました
上位Solutions
KaggleのLBを以下に記載します。
今回、以下の3つが重要であったため、以下の3つに絞って解法をまとめていきます。
- 検索候補文言の正確な前処理
- RAG(検索拡張生成)
- 推論モデル
1. 検索候補文言の正確な前処理
Wikipediaからcontextの候補となる文書を抽出していましたが、公開Notebookには数字の記事などに欠けがあり、これが精度を下げる原因となっていたようです。上位陣はほとんどこのことに気がついています(例:1st, 4thなど)。
また、1stチームはエラー分析をするなかでデータに欠けがあることに気がついたようです。やはり、地道なエラー分析が大事であるということが学ばされます。
他にも、金圏はデータソースごとアンサンブルしているチームが多かったです。
データソースごとアンサンブルしている例1(7th)
データソースごとアンサンブルしている例2(10th)
2. RAG(検索拡張生成)
上位陣に限っても多様でした。①:ベクトル検索、②スパースモデル、③その他モデルに限って話をしていこうと思います。
2.1. ベクトル検索
上位陣の多くがベクトル検索用のリーダーボードのMTEB learderboardを見つけ、ここから上位のものを試したと記載があります。多く使われているのは以下でした。
- e5-base/large
- gte-base/large
- bge-base/large
必ずしもlargeが最終的な精度があがるとも限らないという点が印象的です。自分も実際上に記載のモデルをすべて試し、gte-baseを最終的に使いました。
どの単位でベクトル化するか?についてはあまり記載がありませんが、10thは3〜4文を1つの文章としてスライドさせたようです。
14thはwikipediaページ?の頭(90 words)と最後(3文)を取得していたようです。
2.2. スパースモデル
ここでのスパースモデルはtf-idfなどの(比較的)古典的な手法を指します。以下のブログ(元をたどるとFacebookの論文)などでも紹介されていますが、訓練データとは異なるドメインのデータではBM25などのスパースな手法がニューラル Retriever を上回ることがあると報告されています。
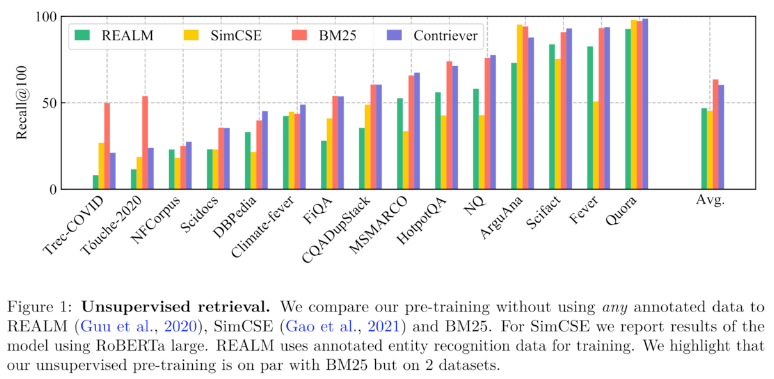
論文は以下から
実装面に関しては5thがpyseriniを使用した実装を紹介してくれていました。
2.3 その他
4thはElasticsearchの2stageを採用しています。
13thはベクトル検索 → tf-idfで並び替えを行っています。
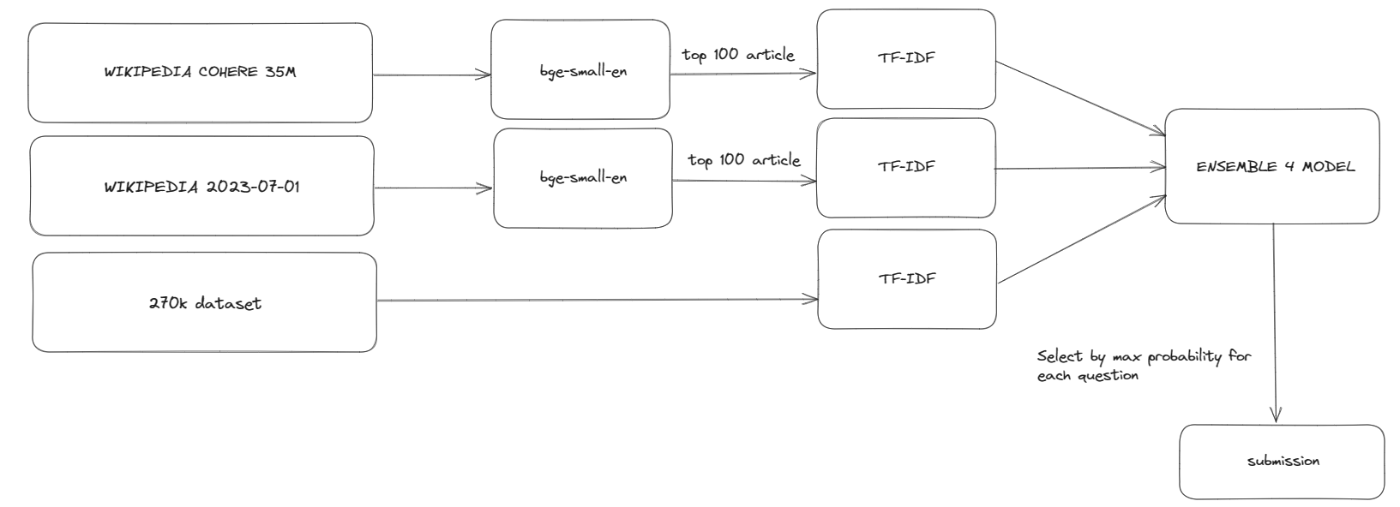
3. 推論モデル
大きくわけると、LLM(7B〜70B)かDeBERTa-v3でした。金圏はDeBERTaでもいけるけど賞金圏はLLMの方がちょっと多い感じ。Kaggle Notebookで回るのか...?という感じですが、コンペの途中で、70BのLLMを動かすNotebookが出てきてました(!)
LLMとしてはLlama-2-7b/13b/70bやMistral-7Bを使用しているチームが多かったです。
一部のチームは予測を多段階に分ける仕組みを使っていました(5th; 7th)。
5thはmistral-7B → llama2-70Bとだんだん重たいモデルを使っていることから、難しい問題には難しいモデルを当てることにより時間の節約にも繋げたと考えられます。
その他
- 下位のRAGを入れ替えることによりTTA(13th)
感想
-
データソースを変えることが思いつかなかった。
- データソースのアンサンブルなんかも思いつかなかったですが、たしかに有効そう。
- 他にも上位解法を眺めると、RAGの出し方の多様性がすごいことがわかります。
- データソース、文章分割単位、ベクトル検索とスパースモデルの組み合わせなど、皆が多様なアプローチで上位を取っていて読んでても楽しいSolutionsでした。
-
RAGや最後の推論共に、2nd-stageで予測しているのが賢いと思った。
- 計算時間がボトルネックになっていたため採用したと思われる
-
実装力が問われるコンペであった
- 上位チームはLLMをKaggle notebook上に実装しているチームが多く、実装力が必要ということを痛感しました。
Discussion