DBにおけるインデックス設計入門
こんにちは、@nerusan です。
本日は DB におけるインデックスについて、学んだことをまとめていきたいと思います。
インデックスをどのように貼るべきなのか?悪い使い方は何なのか?を実際に動かしながら述べていこうと思います。
インデックス
データベースにおけるインデックスは、テーブル内のデータの検索やソートを高速化するために使用されるデータ構造です。インデックスは特定の列(または複数の列)に対して作成され、その列の値とそれに対応するデータの物理的な位置情報を持ちます。これにより、データベースエンジンはインデックスを使用して効率的なデータの検索や結合を行うことができます。
よく例えられるのは、本の目次です。
目的のページを、目次なしで探すのと、目次を見てから探すのでは、検索スピードは全く違うことは想像できると思います。
B-tree インデックス
di
B-tree インデックスは、データベースにおいて最も一般的に使用されるインデックスの一つです。B-tree(Balanced Tree)は、データのツリー構造を使用してインデックスを表現するアルゴリズムです。B-tree は、データが順序付けられたツリーとなるようにデータを分割し、効率的な検索を行うことができます。
詳しい原理などは、他にも記事がたくさんあるので、調べてもらえたらと思います。
そのうちの一つの記事を挙げておきます。
B-tree インデックスは以下の特徴を持ちます:
-
バランスが取れている: B-tree はデータの挿入や削除が発生しても、ツリーのバランスを保つために自動的に再構築されます。これにより、インデックスの効率が維持されます。
-
高い検索効率: B-tree は、データを効率的に検索するためにツリーの分割を利用します。ツリーの分割により、検索対象のデータを探すために必要な照会回数が減り、高速な検索が可能となります。
-
ソートされたデータのサポート: B-tree はデータをソート順に保持するため、範囲検索やソート操作にも優れたパフォーマンスを発揮します。
B-tree インデックスは、主に等値検索や範囲検索、ソート操作に使用されます。データベースエンジンは、クエリの実行時に B-tree インデックスを活用し、効率的なデータのアクセスパスを決定します。これにより、データの検索性能が向上し、クエリの実行時間が短縮されます。
インデックスを利用しないフルスキャンと B-tree のデータ量に対する検索・更新の時間を見てみます。
B-tree インデックスでは、データ量が増えても検索にかかる時間が緩やかになっていることがわかります。なので、大量のデータを扱うテーブルにはとても有効的であることがわかります。
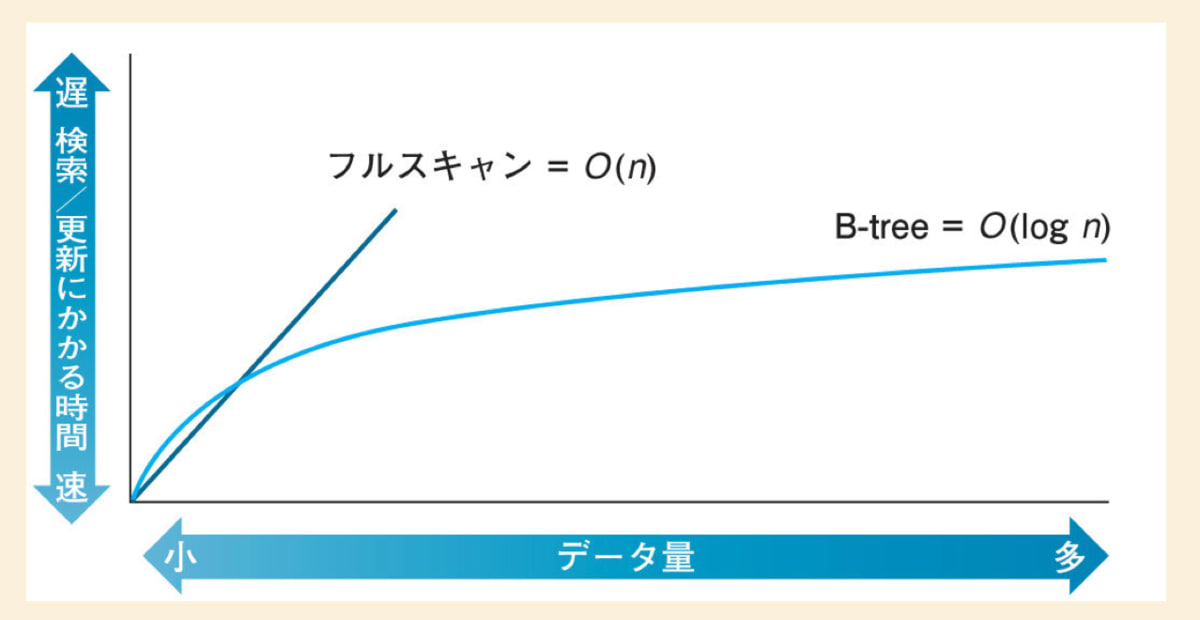
引用:達人に学ぶ DB 設計徹底指南書
カーディナリティ
ここでインデックス設計において重要なカーディナリティについて、述べます。
カーディナリティ(Cardinality)は、データベースのコンテキストで使用される用語で、あるカラム(列)において異なるユニークな値の数を表します。つまり、カーディナリティはカラム内のユニークな値の多様性や重複度を示す指標となります。
例を見ていきましょう。
まず、性別を考えます。性別は、男と女の 2 種類です。
なので、カーディナリティは 2 になります。
日付の場合は、366 日あるので、カーディナリティは 366 になります。
性別と日付を比較すると、日付の方がカーディナリティが高いと言えます。
カーディナリティは、クエリのパフォーマンスやインデックスの効果に影響を与える重要な要素です。一般的に、カーディナリティが高いほど、データの重複が少なく、個々の値がより一意であることを意味します。逆に、カーディナリティが低い場合、データ内の重複が多く、個々の値のバリエーションが少ないことを示します。
設計指針
インデックスは便利ということはわかったと思います。しかし、闇雲にインデックスを利用すると、容量が増えるだけではなく更新、削除、挿入の際、インデックスも更新する必要があるため、かえってパフォーマンスが下がります。
どのようにインデックスを指定すればいいのか?を見ていきます。
- 大きなテーブルに対して作成
- カーディナリティが高い列に作成
- WHERE 句の選択条件、または、結合条件に使用される列に作成
1. 大きなテーブルに対して作成
B-tree インデックスを使ったスキャンとフルスキャンのデータ量・時間の図を再度見てみます。
データ量が少ない場合は、フルスキャンの方が高速です。
実際に大差はありませんが、わざわざインデックスを張る必要はありません。
その閾値としてはだいたい 1 万レコード以下であれば、インデックスを張る意味がありません。
ただ、それは、サーバーの性能などにもよるため一概には言えないため、実際は実測してそこの値を決めることが望ましいです。
引用:達人に学ぶ DB 設計徹底指南書
2. カーディナリティの高い列に作成
絞り込み率が 5% 以下の場合は、有効であると言われています。
つまり、カーディナリティが 20 以上の場合は、インデックスが有効に働く可能性が高いということになります。
ただ、カーディナリティが高いと言って、絶対にインデックスが有効になるとはかぎりません。
例えば、1 から 20 の値を取るうるカラムがあったとします。とりうるカーディナリティは 20 です。ただ、そのうち 19 レコードは 1、後一つは 20 とします、その場合は、インデックスを使って効率よく検索できません。なので、レコードに実際に書き出されるカーディナリティが 20 以上となるカラムにインデックスの適用を考えましょう。
| カラム |
|---|
| 1 |
| 1 |
| ... |
| 1 |
| 1 |
| 29 |
また、複合カラムに対するインデックスをはる場合も注意が必要です。
次の社員テーブルを考えます。
社員テーブル
| 性別(男・女) | 利き手(右・左・両) | 職能(平・係長・課長・部長) |
|---|---|---|
| 男 | 右 | 係長 |
| 女 | 左 | 平 |
それぞれのカーディナリティは 性別:2, 利き手:3, 職能:4 であり、インデックスは必要ありません。
ただ、以下のようなクエリを考えます。
SELECT * FROM `社員テーブル` WHERE 職能給 = `係長` AND 利き手 = `左` AND 性別 = `女`
この場合のカーディナリティは、2✖️3✖️4=24 になり、インデックスは有効になります。
この際、インデックスの貼り方としてはカーディナリティが高い順場にすることでより効率よく検索できます。
-- Good
CREATE INDEX インデックス名 ON 社員テーブル(職能給, 利き手, 性別);
-- Bad
CREATE INDEX インデックス名 ON 社員テーブル(性別,利き手,職能給);
3. WHERE 句の選択条件、または、結合条件に使用される列に作成
以下のテーブルを考えます。
players テーブル
| id | name | uniform_num | country_id |
|---|---|---|---|
| 1 | sakaki | 8 | 1 |
| 2 | john | 9 | 2 |
countries テーブル
| id | name |
|---|---|
| 1 | japan |
| 2 | US |
日本の選手一覧を取得するクエリを考えます。
SELECT *
FROM players
WHERE country_id = 1;
この場合は、country_idカラムにインデックスを貼ると有効になります。ただ、上記のポイントで述べましたが、カーディナリティが 20、総レコード数が1万を超える場合やるべきです。
次に、選手名と国の一覧を取得する以下のクエリを考えます。
SELECT c.name, p.name
FROM players AS p
JOIN countries AS c ON c.id = p.country_id;
上記の SQL では、内部結合を利用しています。この場合、 players テーブルのcountry_idと countries テーブルのidはインデックスをつけるべきです。ただ、上記のポイントで述べましたが、カーディナリティが 20、総レコード数が1万を超える場合やるべきです。今回でいうidは大概プライマリーキー(主キー)を指定します。プライマリキーとユニークキーは、DB 側が自動でインデックスを作ってくれるので、わざわざ 2 個も張る必要がありません。
検索条件や結合条件に利用されないカラムにインデックスを張るのは全くの無意味なので気をつけましょう。
SQL とインデックス
SQL の書き方によっては、インデックスをうまく活用できない場合があります。その例を見ていきましょう
1. インデックス列に演算を行なっている
以下のテーブルを考えます。
users
| id | name | age |
|---|---|---|
| 1 | yuji | 20 |
| 2 | yama | 25 |
age カラムにインデックスを張ります。
年齢+5 が 30 歳以上になる社員一覧を出す以下のクエリを考えます。
SElECT * FROM users WHERE age + 5 > 30;
ただし、このクエリではインデックスを利用しません。
age に対してインデックスを張っており、age+5 に対してはインデックスを張っていないからです。
実際に確認してみましょう。EXPLAINを可惜につけることで、検索の詳細を調べることができます。
mysql> explain select * from users where age + 5 > 30;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | users | NULL | ALL | NULL | NULL | NULL | NULL | 1 | 100.00 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
type が all なので、フルスキャンで探索していることがわかります。
ただこれ以下のクエリで代用することができます。
SElECT * FROM users WHERE age > 25;
mysql> explain select * from users where age > 25;
+----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | users | NULL | range | age_index | age_index | 4 | NULL | 1 | 100.00 | Using index condition |
+----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)
type が range になっているので、インデックスを使った検索ができているのがわかりますね。
インデックスが使われているかどうかを都度EXOLAINで確認すると良さそうです。
2. 索引列に対して SQL を適用している
以下のテーブルを考えます。
users
| id | name | age |
|---|---|---|
| 1 | yuji | 20 |
| 2 | yama | 25 |
SUBSTR(age, 1, 1)に対してもインデックスは聞きません。理由は、先ほどと同じです。
mysql> explain select * from users where substr(name, 1, 1) = 'a';
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | users | NULL | ALL | NULL | NULL | NULL | NULL | 1 | 100.00 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
また、後方一致、中間一致に対しても、インデックスは無効です。
ただし、前方一致の場合は有効です。
-- NG
SELECT * FROM users WHERE name LIKE 'a%';
SELECT * FROM users WHERE name LIKE '%a%';
-- OK
SELECT * FROM users WHERE name LIKE '%a';
検索の時は、FULLTEXT インデックスが利用できそうです。(詳しくは調べられていません。。。)
3. 否定系では利用できない
以下のテーブルを考えます。
users
| id | name | age |
|---|---|---|
| 1 | yuji | 20 |
| 2 | yama | 25 |
否定を利用する以下のクエリにもインデックスは利用されません。
SELECT * FROM users WHERE age != 20;
ただし、DB によっては、インデックスは利用でき、MySQL では利用できます。汎用性があまりないので、あまり利用しない方が良いです。
mysql> explain SELECT * FROM user WHERE age != 20;
+----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | users | NULL | range | age_index | age_index | 5 | NULL | 5 | 100.00 | Using index condition |
+----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)
4. OR による検索
以下のテーブルを考えます。
users
| id | name | age |
|---|---|---|
| 1 | yuji | 20 |
| 2 | yama | 25 |
OR に対してもインデックスは利用されません。
SELECT * FROM users WHERE age = 20 OR age = 30;
この場合は IN 句を利用することで、インデックスを利用することができます。
SELECT * FROM users WHERE age IN (20, 30);
ただし、DB によっては、インデックスは利用でき、MySQL では利用できます。汎用性があまりないので、あまり利用しない方が良いです。
mysql> explain SELECT * FROM user WHERE age = 18 OR age = 20;
+----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | users | NULL | range | age_index | age_index | 4 | NULL | 2 | 100.00 | Using index condition |
+----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)
type が range になっているので、インデックスを使っていますね。
5. null 検索
以下のテーブルを考えます。
users
| id | name | age |
|---|---|---|
| 1 | yuji | 20 |
| 2 | yama | 25 |
IS NULL, IS NOT NULLの利用もインデックスは利用されません。
SELECT * FROM users WHERE age IS NULL;
ただし、DB によっては、インデックスは利用でき、MySQL では利用できます。汎用性があまりないので、あまり利用しない方が良いです。
mysql> explain SELECT * FROM user WHERE age is null;
+----+-------------+-------+------------+------+---------------+-----------+---------+-------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+-----------+---------+-------+------+----------+-----------------------+
| 1 | SIMPLE | users | NULL | ref | age_index | age_index | 5 | const | 1 | 100.00 | Using index condition |
+----+-------------+-------+------------+------+---------------+-----------+---------+-------+------+----------+-----------------------+
6. 暗黙の型変換
以下のテーブルを考えます。
users
| id | name | age |
|---|---|---|
| 1 | yuji | 20 |
| 2 | yama | 25 |
mysql> show columns from users;
+-------+------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+------+------+-----+---------+-------+
| id | int | NO | | NULL | |
| name | text | NO | MUL | NULL | |
| age | int | YES | MUL | NULL | |
+-------+------+------+-----+---------+-------+
暗黙的な検索に対しても、インデックスは利用できません。
age は int で定義されていますが、クエリでは char で指定すると、
SQL は内部的に、型変換して、正しく検索されます。
ただ、この場合は、インデックスは利用されません。
なので、正しい型で指定することが大事です。
-- NG
SELECT * FROM user WHERE age = '25';
-- OK
SELECT * FROM user WHERE age = 25;
ただし、DB によっては、インデックスは利用でき、MySQL では利用できます。汎用性があまりないので、あまり利用しない方が良いです。
mysql> explain SELECT * FROM user WHERE age = '25';
+----+-------------+-------+------------+------+---------------+-----------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+-----------+---------+-------+------+----------+-------+
| 1 | SIMPLE | users | NULL | ref | age_index | age_index | 5 | const | 4 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+-----------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
複合プライマリキーにおけるインデックス
複合プライマリキーについて述べます。
先ほどプライマリキーは自動でインデックスをはってくれると言いました。つまり、複合プライマリキーは、複合インデックスといえます。
よく企業 ID とユーザ ID を複合プライマリキーにすることがあるかなって思います。
users
| company_id * | user_id * |
|---|---|
| 2 | 3 |
| 2 | 4 |
| 3 | 4 |
※*はプライマリキー
ただ、複合キーの使われ方によって、異なる考え方あります。
- 複合プライマリキーを全て WHERE 句に含める場合
- 複合の一部のみを WHERE 句に含める場合
以下詳しく見ていきましょう。
1. 複合プライマリキーを全て where 句に含める場合
複合プライマリキーにおけるインデックスは、複数のカラムからなるインデックスとして作成されます。
複合プライマリキーは、複数のカラムを組み合わせた一意の識別子であり、テーブル内の各レコードを一意に識別するために使用されます。
以下のようなテーブルがあるとします:
CREATE TABLE テーブル名 (
カラム1 データ型,
カラム2 データ型,
...
PRIMARY KEY (カラム1, カラム2, ...)
);
この場合、カラム 1、カラム 2、...からなる複合プライマリキーが定義されています。
これにより、プライマリキーの値に基づいてテーブル内のレコードを高速に識別できます。
複合プライマリキーのインデックスは、テーブル内のデータの整合性を保証し、高速な一意の検索と結合を可能にします。
複合プライマリキーの順序によって、インデックスの効果やクエリの最適化にも影響を与えます。
先ほども述べたように、カーディナリティの高いカラムを先頭に配置することで、検索の効率が向上する場合があります。
それと同時に、クエリの WHERE 句での条件指定の順番も、絞り込み効果を最大化するために重要です。
一般的には、カーディナリティが高い列を優先して WHERE 句に指定することが望ましいです。
つまり、複合プライマリーキーの順番で、WHERE 句を指定することで効率よく検索できます。
これにより、データベースは最初にカーディナリティの高い列を使って絞り込みを行い、その後にカーディナリティの低い列を用いてより具体的な絞り込みを行います。
例えば、以下のようなクエリがあるとします:
SELECT 列1, 列2 FROM テーブル名 WHERE 条件1 AND 条件2;
条件 1 と条件 2 の絞り込み効果が異なる場合、より絞り込み効果の高い条件を先頭に指定すると、データベースがより効果的なプランを選択する可能性が高くなります。
ただし、最適な順序を決定するには、実際のデータの特性やクエリの要件を分析する必要があります。
実際に見てみましょう。
以下のようなusersテーブルを用意します。
mysql> show columns from users;
+-------+-----------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+-----------------+------+-----+---------+----------------+
| cid | bigint unsigned | NO | | NULL | |
| uid | bigint unsigned | NO | | NULL | auto_increment |
| email | varchar(256) | NO | | NULL | |
+-------+-----------------+------+-----+---------+----------------+
ここで、cid(company_id)は会社 ID、uid(user_id)はユーザ ID、email はメールアドレスとします。
ここで、カーディナリティーとして、会社<社員の関係、つまり、cid < uid の関係になります。
なので、インデックスは(uid, cid)の順番でつけることが望ましいです。
CREATE TABLE `users` (
`cid` BIGINT UNSIGNED NOT NULL COMMENT '会社の識別子',
`uid` BIGINT UNSIGNED NOT NULL COMMENT 'ユーザーの識別子',
`email` VARCHAR(256) NOT NULL COMMENT 'メールアドレス',
-- uid, cidの順番
PRIMARY KEY (`uid`, `cid`),
-- メールアドレスも一位に決まるためユニークキー製薬をつける
UNIQUE KEY `uix_email` (`email`) USING BTREE
) Engine=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='ユーザー';
mysql> show columns from users;
+-------+-----------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+-----------------+------+-----+---------+----------------+
| cid | bigint unsigned | NO | PRI | NULL | |
| uid | bigint unsigned | NO | PRI | NULL | auto_increment |
| email | varchar(256) | NO | UNI | NULL | |
+-------+-----------------+------+-----+---------+----------------+
mysql> show index from users;
+-------+------------+-----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression |
+-------+------------+-----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| users | 0 | PRIMARY | 1 | uid | A | 1224310 | NULL | NULL | | BTREE | | | YES | NULL |
| users | 0 | PRIMARY | 2 | cid | A | 2664326 | NULL | NULL | | BTREE | | | YES | NULL |
| users | 0 | uix_email | 1 | email | A | 2278719 | NULL | NULL | | BTREE | | | YES | NULL |
+-------+------------+-----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
3 rows in set (0.00 sec)
メールもユニークかつ、メアドのみでの検索が想定されるので、ユニークキー制約つけています。そうすると、普通のインデックスより高速な検索が可能です。
ユニークが保証かつ、検索対象になるときは、ユニークキー製薬つけることを検討しましょう。
テストデータを 300 万ほど挿入してクエリを叩いてみましょう。
WHERE の指定も同様に uid, cid の順番の方が効率的です。
mysql> select * from users where uid = 99999 and cid = 12;
+-----+-------+---------------------------+
| cid | uid | email |
+-----+-------+---------------------------+
| 12 | 99999 | email99999_12@example.com |
+-----+-------+---------------------------+
1 row in set (0.00 sec)
時刻を見ても 0.00sec なので、高速で動いていますね。
念のため、INDEX が利用されているか確認しましょう。
EXPLAINを先頭につけることで確認することができます。
mysql> explain select * from users where uid = 99999 and cid = 12;
+----+-------------+-------+------------+-------+---------------+---------+---------+-------------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------------+------+----------+-------+
| 1 | SIMPLE | users | NULL | const | PRIMARY | PRIMARY | 16 | const,const | 1 | 100.00 | NULL |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
type を見るとconstになっています。
これは、PRIMARY KEY または UNIQUE インデックスのルックアップによるアクセスを表しており、インデックスがしっかり使われていることが確認できます。
ただ、複合プライマリキーの片方のみで検索をかける場合は注意が必要です。
例えば、会社ごとの従業員数一覧を出したい次のクエリを考えます。
mysql> SELECT * FROM users WHERE cid = 12;
+-----+--------+----------------------------+
| cid | uid | email |
+-----+--------+----------------------------+
| 12 | 1 | email1_12@example.com |
...
| 12 | 99998 | email99998_12@example.com |
| 12 | 99999 | email99999_12@example.com |
+-----+--------+----------------------------+
177592 rows in set (0.70 sec)
時間も 0.7s かかっていますね。
このクエリはがインデックスが利用されているかみましょう。
mysql> explain select * from users where cid = 12;
+----+-------------+-------+------------+-------+---------------+-----------+---------+------+---------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+-----------+---------+------+---------+----------+--------------------------+
| 1 | SIMPLE | users | NULL | index | NULL | uix_email | 1026 | NULL | 2664326 | 10.00 | Using where; Using index |
+----+-------------+-------+------------+-------+---------------+-----------+---------+------+---------+----------+--------------------------+
type が index になっています。これは、フルインデックススキャンとなっており、インデックス全体をスキャンする必要があるのでとても遅いです。
これを解決するための方法を見てみましょう。
2. 複合の一部のみを WHERE 句に含める場合
複合プライマリキーの一部のみを WHERE 句に指定する場合、プライマリキーの順番は効果的なインデックスの使用を促すために重要です。
複合プライマリキーの順番によって、インデックスの効果が変わる可能性があります。
同様に以下の例を考えましょう。
次のようなテーブルがあり、カラム 1 とカラム 2 からなる複合プライマリキーが定義されています:
CREATE TABLE テーブル名 (
カラム1 データ型,
カラム2 データ型,
PRIMARY KEY (カラム1, カラム2)
);
場合によっては、カラム 1 のみを WHERE 句に指定したクエリを実行したいかもしれません。
具体的には、以下のようなクエリが考えられます:
SELECT * FROM テーブル名 WHERE カラム1 = 値;
このクエリでは、WHERE 句でカラム 1 の条件を指定しています。
複合プライマリキーが (カラム 1, カラム 2) の順番で定義されている場合、クエリの WHERE 句でカラム 1 の条件を指定することで、インデックスが効果的に使用されます。
インデックスはカラム 1 を先頭としているため、カラム 1 の値に基づいて効率的にレコードが検索されます。
一方、複合プライマリキーが (カラム 2, カラム 1) の順番で定義されている場合、クエリの WHERE 句でカラム 1 の条件を指定しても、インデックスの効果は低くなります。
インデックスはカラム 2 を先頭としているため、カラム 1 の条件に基づく絞り込みが効果的に行われません。
したがって、複合プライマリキーの一部を WHERE 句に指定する場合は、複合プライマリキーの順番はインデックスの効果を最大化するために考慮する必要があります。
一般的には、クエリで頻繁に絞り込まれるカラムを複合プライマリキーの先頭に配置すると効果的です。
通常、データベースは、最初の(一番左の)列で検索を行う時に複合インデックスを使うことができます。
3 列に対する複合インデックスを作った時は、1 番目の列だけで検索する場合、1 番目と 2 番目の列で検索する場合、全ての列で検索する場合に、そのインデックスが使えます。
CREATE TABLE テーブル名 (
カラム1 データ型,
カラム2 データ型,
カラム3 データ型,
PRIMARY KEY (カラム1, カラム2, カラム3)
);
-- OK(インデックスを使って効率的に検索できる)
SELECT * FROM テーブル名 WHERE カラム1 = 値;
SELECT * FROM テーブル名 WHERE カラム1 = 値 AND カラム2 = 値;
SELECT * FROM テーブル名 WHERE カラム1 = 値 AND カラム2 = 値 AND カラム3 = 値;
-- NG(インデックスを効率よく使うことができない)
SELECT * FROM テーブル名 WHERE カラム2 = 値 AND カラム3 = 値;
SELECT * FROM テーブル名 WHERE カラム3 = 値;
usersテーブルの場合で考えてみましょう。
今回は、会社ごとの従業員数一覧を出したい次のクエリが考えられるので、(cid, uid)の順番でプライマリキーを登録します。
SELECT * FROM users WHERE cid = 12;
CREATE TABLE `users` (
`cid` BIGINT UNSIGNED NOT NULL COMMENT '会社の識別子',
`uid` BIGINT UNSIGNED NOT NULL COMMENT 'ユーザーの識別子',
`email` VARCHAR(256) NOT NULL COMMENT 'メールアドレス',
-- cid, uidの順番
PRIMARY KEY (`cid`, `uid`),
UNIQUE KEY `uix_email` (`email`) USING BTREE
) Engine=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='ユーザー';
mysql> SELECT * FROM users WHERE cid = 12;
+-----+--------+----------------------------+
| cid | uid | email |
+-----+--------+----------------------------+
| 12 | 1 | email1_12@example.com |
...
| 12 | 177591 | email177591_12@example.com |
| 12 | 177592 | email177592_12@example.com |
+-----+--------+----------------------------+
177592 rows in set (0.08 sec)
mysql> explain select * from users where cid = 12;
+----+-------------+-------+------------+------+---------------+---------+---------+-------+--------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+---------+---------+-------+--------+----------+-------+
| 1 | SIMPLE | users | NULL | ref | PRIMARY | PRIMARY | 8 | const | 358628 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+---------+---------+-------+--------+----------+-------+
type が ref になっており、時間も 0.7s から 0.08s と早くなっていることが伺えますね。
ref は、PRIMARY KEY、UNIQUE KEY でないインデックス(ユニークでないインデックス)を使って等価検索(WHERE key = value)を行うことを表しています。
別で新たにインデックスを張ることも 1 つの案ですが、あまりいい方法とは言えません。
2 つインデックスを作ると、select の パフォーマンスはよくなります。
しかし、インデックスが多く設定するほど、ストレージ領域の増大に繋がり、2 番目のインデックスのメンテナンスの オーバーヘッドが増えます。
つまり、テーブルに対するインデックスの数が多いほど、insert や delete、update に時間が要することになります。
CREATE TABLE テーブル名 (
カラム 1 データ型,
カラム 2 データ型,
...
PRIMARY KEY (カラム2, カラム1, ...),
INDEX インデックス名 (カラム1)
);
絶対ダメというわけではなく、アプリケーションに応じて実際のデータの特性や要件を分析し、実際に計測して判断することが大事になってくるかなって思います。
また、先ほど複合インデックスは、カーディナリティは高い順番が良いとされました。
cid, uid の順番だとカーディナリティが低い順番だから言ってることが違う!と思われた人もいると思います。
しかし、インデックスを減らす方がより効率が良いため、cid、uid の順番にして、インデックスは一つにしているというわけです。
複合プライマリキー(インデックス)のまとめ
ここまで複合インデックスについてまとめると、基本的に、複合カラムのプライマリキーは、カーディナリティが高い順につけるのが良いと言われていますが、上記のように必ずしもそれに従っていれば最適であるというわけではありません。
アプリケーションで実際にどのように使われる想定なのか、それらによって柔軟に順番を決めていけるとよりアプリケーションのパフォーマンスを向上させていくことができるでしょう。
まとめ
インデックスについて、述べていきました。
間違って解釈している部分もあると思います。
なので、ご指摘いただけるとありがたいです:)
Discussion