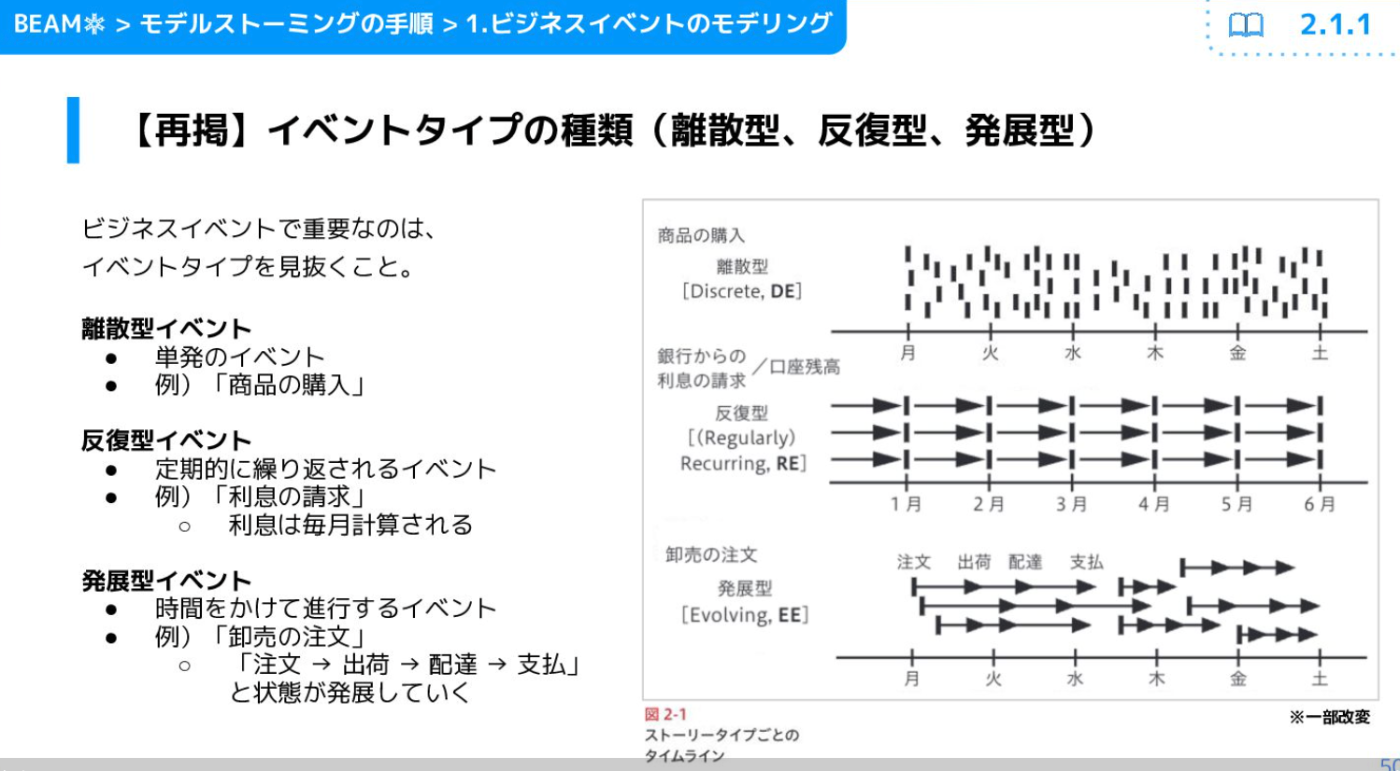
【ディメンショナルモデリング】
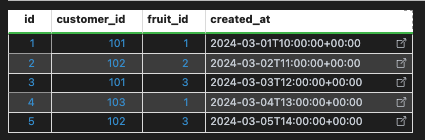
CUSTOMER_FRUITSでディメンションテーブルを作成するサンプル
前提条件

customer_fruits
with
customer_fruits as (
select *
from
unnest(
array<
struct<
id int64,
customer_id int64,
fruit_id int64,
created_at timestamp
>
>[
(1, 101, 1, timestamp('2024-03-01 10:00:00')),
(2, 102, 2, timestamp('2024-03-02 11:00:00')),
(3, 101, 3, timestamp('2024-03-03 12:00:00')),
(4, 103, 1, timestamp('2024-03-04 13:00:00')),
(5, 102, 3, timestamp('2024-03-05 14:00:00'))
]
)
)
select *
from customer_fruits
mst_fruit
with
mst_fruit as (
select *
from
unnest(
array<struct<id int64, name string, deleted_at timestamp>>[
(1, 'りんご', null), (2, 'バナナ', null), (3, 'メロン', null)
]
)
)
select *
from mst_fruit

customer_fruitsをdbt snapshotで実行した場合
- 生成カラムは説明に必要なものだけにしています
- id = 2 のレコードを物理削除が発生している
今回は、created_atしかないテーブルで物理削除されている想定ですが、created_atとdeleted_atがあれば、dbt_valid_from→created_at、dbt_valid_to→deleted_atの置き換えで同じことができます
with
customer_fruits_snapshot as (
select *
from
unnest(
array<
struct<
id int64,
customer_id int64,
fruit_id int64,
created_at timestamp,
dbt_valid_from timestamp,
dbt_valid_to timestamp
>
>[
(
1,
101,
1,
timestamp("2024-03-01 10:00:00"),
timestamp("2024-03-01 10:00:00"),
null
),
(
2,
102,
2,
timestamp("2024-03-02 11:00:00"),
timestamp("2024-03-02 11:00:00"),
timestamp("2025-03-06 16:00:00")
),
(
3,
101,
3,
timestamp("2024-03-03 12:00:00"),
timestamp("2024-03-03 12:00:00"),
null
),
(
4,
103,
1,
timestamp("2024-03-04 13:00:00"),
timestamp("2024-03-04 13:00:00"),
null
),
(
5,
102,
3,
timestamp("2024-03-05 14:00:00"),
timestamp("2024-03-05 14:00:00"),
null
)
]
)
)
select *
from customer_fruits_snapshot

Date type
Name Range
DATE 0001-01-01 to 9999-12-31.
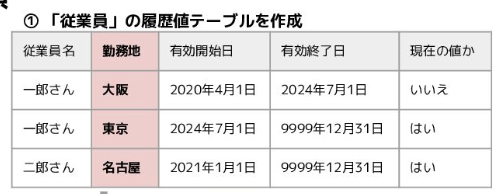
開始日=前レコード終了日ではない方が
従業員.従業員ID =経費ファクト.従業員ID AND
経費ファクト.発生日
BETWEEN 従業員.開始日AND 従業員.終了日
でとれるから便利
with
mst_fruit as (
select *
from
unnest(
array<struct<id int64, name string, deleted_at timestamp>>[
(1, 'りんご', null), (2, 'バナナ', null), (3, 'メロン', null)
]
)
),
customer_fruits_snapshot as (
select *
from
unnest(
array<
struct<
id int64,
customer_id int64,
fruit_id int64,
created_at timestamp,
dbt_valid_from timestamp,
dbt_valid_to timestamp
>
>[
(
1,
101,
1,
timestamp("2024-03-01 10:00:00"),
timestamp("2024-03-01 10:00:00"),
null
),
(
2,
102,
2,
timestamp("2024-03-02 11:00:00"),
timestamp("2024-03-02 11:00:00"),
timestamp("2025-03-06 16:00:00")
),
(
3,
101,
3,
timestamp("2024-03-03 12:00:00"),
timestamp("2024-03-03 12:00:00"),
null
),
(
4,
103,
1,
timestamp("2024-03-04 13:00:00"),
timestamp("2024-03-04 13:00:00"),
null
),
(
5,
102,
3,
timestamp("2024-03-05 14:00:00"),
timestamp("2024-03-05 14:00:00"),
null
)
]
)
),
mst_fruit_string as (
select
id as fruit_id,
concat(lpad(cast(id as string), 2, '0'), "_", name) as fruit_name,
deleted_at
from mst_fruit
),
customer_fruit_period as (
select
customer_fruits_snapshot.customer_id,
customer_fruits_snapshot.fruit_id,
date(
datetime(customer_fruits_snapshot.dbt_valid_from, 'Asia/Tokyo')
) as valid_from,
date(
coalesce(
datetime(customer_fruits_snapshot.dbt_valid_to, 'Asia/Tokyo'),
'9999-12-31'
)
) as valid_to
from customer_fruits_snapshot
),
calendar as (
select create_date
from
unnest(
generate_date_array(
(select min(valid_from) from customer_fruit_period),
date_add(current_date('Asia/Tokyo'), interval 1 month),
interval 1 day
)
) as create_date
),
fruit_calendar_mapping as (
select
calendar.create_date,
customer_fruit_period.customer_id,
customer_fruit_period.fruit_id,
mst_fruit_string.fruit_name
from customer_fruit_period
left join mst_fruit_string using (fruit_id)
left join
calendar
on calendar.create_date
between customer_fruit_period.valid_from and customer_fruit_period.valid_to
),
daily_fruit_aggregation as (
select
customer_id,
create_date,
array_agg(distinct fruit_id order by fruit_id asc) as fruit_ids,
array_agg(distinct fruit_name order by fruit_name asc) as fruit_names,
from fruit_calendar_mapping
group by 1, 2
),
final as (
select
customer_id,
fruit_ids,
array_to_string(
array(select cast(x as string) from unnest(fruit_ids) as x), ','
) as fruit_id_strings,
array(
select regexp_replace(y, '.._', '') from unnest(fruit_names) as y
) as fruit_names,
regexp_replace(
array_to_string(fruit_names, ','), '.._', ''
) as fruit_names_string,
min(create_date) as valid_from,
if(
max(create_date)
= date_add(current_date('Asia/Tokyo'), interval 1 month),
date('9999-12-31'),
max(create_date)
) as valid_to,
max(create_date)
= date_add(current_date('Asia/Tokyo'), interval 1 month) as is_current
from daily_fruit_aggregation
group by 1, 2, 3, 4, 5
)
select *
from final
order by 1, 6





JSON文字列にしてSTRINGカラムに押し込める、とかもありそうですね

代理キー
- 本書では、列名に「_key」という接尾辞を付けることで、代理キーを簡単に識別できます。顧客ディメンションの代理キーはcustomer_key、営業担当ディメンションの代理キーはsalesperson_keyというように呼ばれています。ディメンションテーブルの代理キーは常に最初の属性として示されています。
- 代理キーと自然キーを分離することで、元の運用システムが変更を追跡できない場合でも、データ ウェアハウスで変更を追跡できます。
さらに読む
- 業務システムの設計に関する詳細な情報については、Chris Date著『データベースシステム入門 第8版』(Addison Wesley、2003年)に勝る優れた参考文献はありません。本書は、リレーショナルデータベース管理システムにおけるトランザクション処理をサポートするために用いられる正規化の原則を詳細に解説しています。
- 業務システムと分析システムの違いについては、豊富な情報が公開されています。
- まずは、Ralph KimballとMargy Ross共著の『The Data Warehouse Toolkit, Second Edition』 (Wiley、2002年)の第1章
- Inmon、Imhoff、Sousa共著の『The Corporate Information Factory, Second Edition』(Wiley、2000年)の解説から始めるのが良いでしょう。
- ファクトとディメンションの分離に関する詳細については、ディメンション設計に関する書籍を参照してください。
- 『Data Warehouse Design Solutions』(Adamson and Venerable、Wiley、1995年)と
- 『Mastering Data Warehouse Aggregates』(Adamson、Wiley、2006年)はどちらも冒頭でこのトピックを取り上げており、
- KimballとRossの『The Data Warehouse Toolkit』も同様です。これらの書籍では、スタースキーマの典型的なクエリパターンについても取り上げています。
- ブラウズクエリについては、『The Data Warehouse Toolkit』で解説されています。
データウェアハウスアーキテクチャ
- WH Inmonのアーキテクチャ
- コーポレート・インフォメーション・ファクトリー・アーキテクチャ
- Kimballのアーキテクチャ
- 本書では、Kimballのアーキテクチャをディメンション・データウェアハウス・アーキテクチャと呼びます。
- スタンドアロン・データマート
- エンタープライズ・コンテキストで設計されていない分析データストア
- 短期的な節約は、長期的なコストの増加につながります
- 将来の潜在的なコストについて共通の理解がある限り、特定の分野に特化することは理にかなっているかも
データウェアハウスアーキテクチャの比較(日本語要約)
| アーキテクチャ名 | 提唱者 | 別名 | 説明 | ディメンショナル設計の役割 |
|---|---|---|---|---|
| Corporate Information Factory (コーポレート情報ファクトリー) | Bill Inmon | ・アトミックデータウェアハウス ・エンタープライズデータウェアハウス | ・エンタープライズDWHはアトミック(詳細レベル)データの統合リポジトリ ・直接アクセスされない ・部門ごとの利用・分析のためにデータマートへ再編成 | データマートにのみディメンショナル設計を使用 |
| Dimensional Data Warehouse (ディメンショナルDWH) | Ralph Kimball | ・エンタープライズデータウェアハウス ・バスアーキテクチャ ・設計されたデータマート ・仮想データマート | ・ディメンショナルDWHはアトミックデータの統合リポジトリ ・直接アクセス可能 ・サブジェクトエリア(テーマ別領域)は“データマート”と呼ばれることがあるが分離されたDBである必要はない | 全てのデータがディメンショナルに整理される |
| Stand-Alone Data Marts (スタンドアローン・データマート) | 提唱者なし(よくあるが推奨されない) | ・データマート ・サイロ ・ストーブパイプ ・アイランド | ・エンタープライズ全体の文脈を持たないサブジェクトエリア単位の実装 | ディメンショナル設計が使われることもある |
| アーキテクチャ | 企業レベル | サブジェクトエリア(部門)レベル | ||||
|---|---|---|---|---|---|---|
| 統合リポジトリの有無 | 形式 | 直接アクセス | データマート | 形式 | 直接アクセス | |
| Corporate Information Factory (インモン型) | ✅ | 3NF | ❌ | 物理的 | ディメンショナル(※) | ✅ |
| Dimensional Data Warehouse (キンボール型) | ✅ | ディメンショナル | ✅(※) | 論理的(※) | ディメンショナル | ✅ |
| Stand-Alone Data Marts (スタンドアローン型) | ❌ | n/a | n/a | 物理的 | ディメンショナル(※) | ✅ |
※: オプション
repository = データを一元的に集約・保管する場所(データベース)
用語
データウェアハウス
- スタンドアロンのデータマートを含む分析データベースを含むあらゆるソリューションを指します。この用語は、中央リポジトリや統合リポジトリを意味するものではありません。
エンタープライズ・データウェアハウス
- コーポレート・インフォメーション・ファクトリーの中央リポジトリを指します。この用語の使用は、他のデータウェアハウス・アーキテクチャがエンタープライズ志向に欠けていることを意味するものではありません。
データマート
- あらゆるアーキテクチャにおける特定の領域を指します。この用語の使用は、特定の部門に焦点を絞ったり、企業全体のコンテキストが欠如していることを意味するものではありません。
ETL
- 構造化データストア間で情報を移動するあらゆるアクティビティを指します。この用語を一般的な意味で使用することは、より具体的な定義を持つCorporate Information Factoryを軽視する意図はありません。
ソースシステム
- スタースキーマがデータを取得するコンピュータシステムを指します。企業情報ファクトリーのデータマートの場合、ソースシステムはエンタープライズデータウェアハウスです。ディメンション型データウェアハウスまたはスタンドアロンデータマートのスタースキーマの場合、ソースシステムはオペレーショナルシステムです。
ビジネスインテリジェンス
- エンドユーザー向けのレポートやその他の情報製品を作成するために使用されるあらゆるソフトウェア製品を指すために使用されます。これは、独立した分析データストアや、特定の形式のパッケージソフトウェアの使用を意味するものではありません。
ディメンション
ディメンションとその値はさまざまな方法で意味を追加します。
- クエリやレポートをフィルタリングするために使用されます。
- ファクトの集約範囲を制御するために使用されます。
- 情報を整理したり並べ替えたりするために使用されます。
- レポートの背景情報を提供するために事実を添えます。
- マスター詳細構成、グループ化、小計、および要約を定義するために使用されます。
ファクト
ファクトテーブルには単価(unit_price)ではなく、数量×単価である金額(order_dollars)を格納すべき。
その理由は以下の通り:
- クエリ時の計算が不要でパフォーマンスが向上
- 単価変更による影響を避け一貫性を確保
- 金額は完全加算可能で、柔軟な集計が可能
- 単価はディメンションとして使い、金額はファクトとして保持する
単位量は分析において重要なディメンション。単位量を格納できる明確なディメンションテーブルがない場合は、ファクトテーブルに縮退ディメンションとして配置することができます。
「完全加算可能(fully additive)」とは、どんな切り口(ディメンション)で集計しても合計できる指標のことです。
🔁 具体例:
たとえば order_dollars(売上金額) が完全加算可能な場合:
- 日別に合計:OK
- 商品別に合計:OK
- 店舗別に合計:OK
- これらを組み合わせても合計可能(例:店舗×日別売上)
⚠️ 対して、非加算可能なものの例:
- 単価(unit_price) → 平均は出せるけど、足しても意味がない
- 在庫残数(inventory_balance) → 時点ごとの値なので、合計するとおかしくなる
つまり、「完全加算可能」=どんな集計軸でも素直に足し算できる指標という意味です。データモデリングではとても重要な性質
加算可能な値を保存する
比率そのものはファクトテーブルに保存せず、その構成要素である「利益額(margin_dollars)」と「売上額(order_dollars)」を格納します。これらはどちらも**完全加算可能(fully additive)**なので、どんなディメンション(商品別・日別など)で集計しても正しい合計値が得られます。
- 比率はファクトテーブルに直接格納しない。
- 加算可能な構成要素を格納し、必要に応じて比率を計算する。
「ファクトテーブルの粒度は、可能な限り細かく設定せよ」
例外: 別途、詳細データを保存したリポジトリ(例:データレイクや履歴テーブル)がある場合は、
→ ファクトテーブルは集計済み(粗い粒度)でもよい場合がある。
🧩 縮退ディメンションとは?
通常はディメンション(属性)は別テーブルに分離されますが、
どうしても分けにくい属性をファクトテーブルに直接持たせた場合、
それを「縮退ディメンション」と呼びます。
✅ 特徴
-
ファクトテーブルに含まれるが、役割はディメンション
- フィルター、グルーピング、並び替えなどに使える。
- 例:注文番号、伝票番号、トランザクションIDなど
- ディメンションテーブルと違って、参照テーブルが存在しない
🧱 なぜ使うのか?
- 一部の属性は他と共有されず、独自の値しか持たない(例:トランザクションID)
- わざわざディメンションテーブルを作っても意味がないか、正規化しにくい
⚠️ 注意点
- 文字列のような情報を多く含む場合、ファクトテーブルが重くなる
- むやみに使うと、パフォーマンスや保守性に悪影響が出る
- 多くの場合は、**ジャンクディメンション(複数の小さい属性をまとめたテーブル)**の方が適切
💡 実務での使いどころ
- **トランザクション識別子(例:order_id, invoice_number)**など、
それ自体で分析には使わないが、詳細のトレースやマスター・ディテールの関係構築に使える属性に限って使うのが一般的。
**スローチェンジングディメンション(SCD)**の Type 1 と Type 2 の違い
分析の整合性を保ちたい場合はType 2、最新情報だけが必要な場合はType 1を選ぶのが一般的です。
🔁 Type 1
- Action(操作): ディメンションを上書き更新(Update Dimension)
- Effect on Facts(ファクトへの影響): 履歴が上書きされる(Restates History)
→ 過去のファクトが最新のディメンション値と結びついてしまう。
🧱 Type 2
- Action(操作): ディメンションに新しい行を追加(Insert New Row in Dimension Table)
- Effect on Facts(ファクトへの影響): 履歴が保持される(Preserves History)
→ 過去のファクトは当時の属性値に紐付いたまま残る。
🌟 スター・スキーマの基本まとめ
🧭 ディメンションテーブル
- **自然キーと代替キー(サロゲートキー)**を持ち、履歴管理が可能。
- 列数は多く(ワイドに)、分析に有用な属性を豊富に持たせる。
- 数値型のディメンションも存在し、使用方法でファクトと区別される。
- 正規化はせず、第3正規形にはしない。
- ジャンクディメンションは無関係な属性をまとめたもの。
- 行動ディメンションはファクトから導出される属性群。
📊 ファクトテーブル
- ディメンションへの外部キー+ファクト値で構成される。
- すべての関連ファクトを含める(派生可能なものも含める)。
- 加算できない値(比率など)は、加算可能な構成要素に分解し、レポート時に計算。
- 疎な構造(イベント発生時のみ行が存在)。
- **粒度(グレイン)**は明確に定義する。
- 縮退ディメンションはファクトテーブル内にあるディメンション(例:トランザクションID)。
🐢 スローリー・チェンジング・ディメンション(SCD)
- タイプ1:属性の変更を上書きし、履歴は保持されない(過去のファクトの文脈が変わる)。
- タイプ2:変更時に新しい行を挿入、履歴が保持される(ファクトの履歴文脈が保たれる)。
🧊 キューブ(OLAP)
- 多次元データベースでの実装形態、OLAP分析が可能。
- SQLでは表現しづらい柔軟な分析ができる。
- 属性や取引数の増加でストレージ使用量が増加。
- スケーラビリティは限定的だが、スター・スキーマを補完する強力な手段となる。
ドリル・アクロスとは?
- 異なるファクトテーブル間の情報を結合して分析する手法。
- たとえば「受注ファクト」と「出荷ファクト」を連携し、「受注に対してどれだけ出荷されたか」を分析する。
✅ ファクトを組み合わせてよいか判断する2つの質問
-
これらのファクトは同時に発生するか?
→(例:受注日と出荷日が同じか) -
これらのファクトは同じ粒度(グレイン)で記録されているか?
→(例:どちらも「注文単位」での記録か)
🛑 どちらかが「いいえ」の場合
- 異なるプロセスを表すファクトなので、直接結合してはいけない。
- たとえば、「注文」と「出荷」は発生時点が異なり、処理単位(粒度)も異なることが多いため、**別々に集計し、あとから結合(ドリル・アクロス)**する必要がある。
Sparsity(スパース性): ファクトテーブルに記録されているデータの「まばらさ」を表す概念です。
この特性は粒度の記述から論理的に導き出されます。行は、ディメンション値のすべての可能な組み合わせではなく、発生したアクティビティについてのみ記録されます。
🔍 Sparsityの意味
- ファクトテーブルには、実際にビジネス活動が発生したときだけ行が記録される。
- つまり、すべてのディメンションの組み合わせが揃っているわけではない。
- 実際に存在する組み合わせは、理論上のすべての組み合わせに比べて非常に少ない。
📊 例
たとえば、以下の3つのディメンションがあるとします:
- 商品:1,000種
- 店舗:100店舗
- 日付:365日
理論上の組み合わせ数は 1,000 × 100 × 365 = 36,500,000行
しかし、実際に売上が発生した組み合わせはそのごく一部(例えば数百万行)しか存在しない。
→ このように、全体に対して実データがまばらに存在している状態が「スパース(sparse)」と呼ばれます。
⚠️ 実務での注意点
- JOIN時の結合漏れやNULL処理に注意が必要。
- BIツールやクエリで**「存在しないデータ」をどう扱うか**を意識する。
- データ圧縮やパフォーマンスチューニングの観点でも重要。
要するに、「ファクトテーブルには必要なデータしか存在しない、そしてそれは全体の可能性に対してごく一部である」というのがSparsityの本質です。
🐸 茹でガエルのたとえ話(boiling the frog)
- カエルをぬるま湯に入れて、少しずつ温度を上げていくと、カエルは変化に気づかずにそのまま茹で上がってしまう(という寓話)。
- これは、「小さな問題の積み重ねが、やがて大きな問題になる」という警鐘を鳴らす話です。
💡 ここでの教訓
- 異なるプロセス(例:注文と出荷)に関するファクトを1つのファクトテーブルに入れてしまうと、クエリで必ず条件を追加しなければならないようになります(
HAVING句など)。
SELECT product_key, SUM(quantity_shipped) FROM sales_facts
GROUP BY product_key
HAVING SUM(quantity_shipped) > 0
- その追加作業は最初は小さく感じても、あらゆる分析で同じ対応が必要になり、最終的には大きな負担になります。
- つまり、設計時の手抜きが、将来の分析作業の重荷になるということです。
📌 メッセージ
「クエリで何とかする」のではなく、最初のスキーマ設計で正しくプロセスを分けるべき。
そうすれば後で「茹でガエル」にならずに済む。
✅ 設計時にすべきこと
- プロセスごとに別々のファクトテーブルを作る。
- クエリで余計なフィルタ条件を入れずに済むようにする。
- 将来のメンテナンス性・分析の自由度を高める。
Schema design time, as my friend used to say, is your chance to “un-boil” the frog.
スキーマ設計は、私の友人がよく言っていたように、カエルを「煮る前に冷ます」チャンスです。
ドリルアクロス (drill across)
- 2つのファクトテーブルを直接結合したり、共通のディメンションを介して結合したりしないでください。不正確な結果が生じる可能性があります。
- 2つのプロセスを比較する適切な方法は、「ドリルアクロス」と呼ばれます。
- ファクトを共通の次元レベルでクエリし、要約したら、中間結果セットをマージできます。SQL用語で言えば、完全外部結合が必要です。
「スパース性(sparsity)の不足」
不必要なデータがファクトテーブルに存在してしまうことによって、分析の精度や使いやすさが損なわれるという問題を指しています。
🔍 スパース性とは?
データウェアハウス設計における「スパース性」とは、必要なときにだけ行(レコード)を持つという性質です。逆に言えば、「不要なときはレコードを持たない」ことが重要です。
- 「スパース(sparse)」= まばらな、必要な部分だけが埋まっている状態
- 「密な(dense)」= すべての組み合わせにレコードがある状態(非効率)
💥 スパース性の欠如による問題
✏️ ケース:注文と出荷を1つのファクトテーブルに混在させた場合
例えば:
| customer_id | product_id | order_date | quantity_ordered | quantity_shipped |
|---|---|---|---|---|
| 100 | 333 | 2024-01-01 | 5 | 0 |
上記のようなレコードは「注文はあったが、出荷はなかった」ことを表します。しかし、ユーザーが 「出荷データだけを分析したい」 と思ってレポートを見た場合、このようなレコードが含まれていると非常に混乱します。
- ユーザー:「なんで quantity_shipped が 0 のレコードがあるの?キャンセル?トラブル?」
- 開発者:「それは '注文があったけど出荷がなかった' という事実を記録するために……(略)」
- ユーザー:「いや、出荷だけ見せてよ!」
📉 問題点:
- クエリが複雑になる(HAVING 条件や NULL チェックが常に必要)
- 分析結果が誤解されやすくなる(例:ゼロを欠損と解釈する)
- BIツールでの可視化にも悪影響(不要なバー、空行など)
✅ 解決策:スパース性を保つスキーマ設計
-
プロセスごとにファクトテーブルを分離する
-
order_facts:注文データだけ -
shipment_facts:出荷データだけ
-
-
不要な行を生成しない設計をする
- 注文だけあった日には
shipment_factsにレコードを作らない
- 注文だけあった日には
-
比較が必要な場合は Drill Across を使う
- 必要なときにだけ結合し、分析目的に応じて柔軟に対応できる
🔁 NULL vs 0 の話
「NULL にしても意味ない。結局出てくる。」
これはその通りです。
-
NULLにしても、レコード自体が存在していれば レポートに登場します。 - 表示上
0でもNULLでも、**「そこに何かある」**という事実がレポートに現れてしまう。 - 本来は「出荷されていないのだから、その行自体が存在しないべき」というのが理想です(=スパース性の維持)。
📌 まとめ
| 概念 | 内容 |
|---|---|
| スパース性の欠如 | 本来存在しなくてよい行まで記録されてしまうこと |
| 問題 | 不要なデータが混ざることで、分析の精度・使いやすさが下がる |
| 解決策 | プロセスごとのファクトテーブル設計+Drill Acrossでの比較 |
| NULL vs 0 | レコードがある限り表示されるため、NULLでも回避不能 |
Conformed Dimensionsとは、
複数のファクトテーブル間で共通して使えるディメンションのこと。これにより、異なるビジネスプロセスを横断して一貫した分析(=ドリルアクロス)が可能になります。
**Types of Dimensional Conformance(ディメンション整合のタイプ)**について
✅ 1. Shared Dimensions(共有ディメンション)
- 同一のディメンションテーブルを複数のファクトテーブルで使うケース。
- 最も明確な整合の形。
- 例:
date_dimやproduct_dimを売上・在庫など複数の事実テーブルで共有。
✅ 2. Conformed Rollups(整合ロールアップ)
- 異なる粒度のディメンションだが、上位レベルで整合性が取れている状態。
- 例:
store_dim(店舗)とregion_dim(地域)は構造が異なるが、共通の地域コードで結合できる。
✅ 3. Degenerate Dimensions(縮退ディメンション)
- ファクトテーブル内に直接格納されたディメンション(例:注文番号など)も、他のプロセスと共通で使える場合は整合していると見なせる。
✅ 4. Overlapping Dimensions(重複ディメンション)※議論あり
- 異なるディメンションテーブルだが、一部の値や意味が重複しているケース。
- 例:
customer_dim_onlineとcustomer_dim_storeに一部同じ顧客が存在する場合。 - 整合と認めるかどうかは設計者や組織の判断に依存。
適合マトリクス(conformance matrix)
適合マトリクスは実装の青写真として機能します。

マトリックス図を使用して、ファクト テーブルまたはサブジェクト領域全体のディメンションの適合性を文書化
適合バス(Conformance Bus)
ディメンションモデルにおける適合フレームワーク(conformance framework)は、ディメンション・データウェアハウス設計における最上位レベルの重要項目です。
KimballとRossはこの適合フレームワークを「適合バス(Conformance Bus)」と呼んでいます。
適合バスは、
- 各サブジェクトエリア(業務領域)の個別ニーズに対応しながら
- 領域間の比較や統合的な分析も可能にします。
その結果、エンタープライズ全体を対象とした分析基盤を実現し、**ミクロレベル(個別プロセス)とマクロレベル(全体プロセス)**の両方で比較・分析を行えるようになります。
適合ディメンションは設計の中心的な機能
ディメンション設計と適合性フレームワークが完成したら、実装プロジェクトを本格的に開始できます。
入門には『Data Warehouse Lifecycle Toolkit』、モデリングには『Data Warehouse Toolkit』、ETLには『ETL Toolkit』、Microsoft向けには『Microsoft Toolkit』、記事集には『Kimball Group Reader』がおすすめです。
✅ Kimball Groupの代表的な書籍まとめ
| 書籍タイトル | 主な内容・特徴 |
|---|---|
| The Data Warehouse Toolkit, Third Edition (Kimball and Ross) | ディメンショナルモデリングの決定版ガイド。スタースキーマ設計を中心に、モデルパターンを体系的に解説。 |
| The Data Warehouse Lifecycle Toolkit, Second Edition (Kimball, Ross, Thornthwaite, Mundy and Becker) | データウェアハウスプロジェクト全体の進め方(要件定義→設計→開発→運用)を網羅した実践ガイド。 |
| The Kimball Group Reader, Second Edition – Remastered Collection (Kimball and Ross) | Kimball Groupが発表した記事、デザインTips、ホワイトペーパーを再編集したベストセレクション。 |
| The Microsoft Data Warehouse Toolkit, Second Edition (Mundy and Thornthwaite) | SQL Server 2008 R2とMicrosoft BIツールを使って、Kimball方式でDWHを構築するためのガイド。 |
| The Data Warehouse ETL Toolkit (Kimball and Caserta) | ETLプロセスにフォーカス。データ抽出・クレンジング・整合・配信に関する技術を体系的に紹介。 |
| Kimball's Toolkit Classics | 「Data Warehouse Toolkit(第2版)」「Lifecycle Toolkit(第2版)」「ETL Toolkit」をセットにしたクラシックコレクション。 |
| The Microsoft Data Warehouse Toolkit (Mundy and Thornthwaite) | SQL Server 2005版。Microsoft製品によるDWH構築方法を解説。(※こちらは少し古め) |
✅ 選び方ガイド
- 📘 モデリングを極めたい → 「The Data Warehouse Toolkit」
- 📗 プロジェクト全体の流れを学びたい → 「The Data Warehouse Lifecycle Toolkit」
- 📙 ETL設計に特化したノウハウが欲しい → 「The Data Warehouse ETL Toolkit」
- 📕 Microsoft環境(SQL Server)でやりたい → 「The Microsoft Data Warehouse Toolkit」
- 📓 短時間でKimballのエッセンスを広く知りたい → 「The Kimball Group Reader」
Star Schema: The Complete Reference
スタースキーマ、スノーフレーク、キューブを扱うすべての方のために書かれた、次元モデリングの包括的なガイドです。その広範かつ奥深い解説は、初心者から上級者まで、あらゆる方にとって最適なリファレンスとなっています。
Data Warehouse Design Solutions
スタースキーマ設計の原則を徹底的に解説しています。
Mastering Data Warehouse Aggregates
スター スキーマ データ ウェアハウスのパフォーマンスを向上させる最も効果的なツールであるディメンション集計について詳細に説明した初めての書籍です。
ディメンションが肥大化することに対する対処
サブタイプ化(subtyping)
サブタイプ固有の属性が関係する状況では、共通属性のみを含むコアディメンションを構築し、サブタイプごとにカスタムディメンションを個別に作成することで、ディメンション行のサイズを制御できます。
ミニディメンション
より頻繁に変更される属性を分離するためにミニディメンションを作成できます。
ロール
ディメンションテーブルは、ファクトテーブルと複数の関係を持つことができます。それぞれの関係はロールと呼ばれます。
外部キー列には各ロールを暗示する名前を付ける必要があり
従業員への3つの外部キー参照で、従業員表のキー名に、employee_key_official、employee_key_processor、employee_key_underwriterというロール記述子が追加されています。
これにより、ファクト表の列名を調べる際に、各ロールを容易に識別できます。
ディメンションテーブルにNULLを保存せず
ディメンションテーブルにNULLを保存せず、代わりに「N/A」(テキスト)、「0」(数値)、「未来の日付」(日付型)などの既定値を使います。
場合によっては「Unknown」「Invalid」など理由を表す値を使うこともあり、さらに専用のステータス列を追加する設計も推奨されます。
ディメンション情報がまだ提供されていない
オプションの関係に加えて、ディメンション情報がまだ提供されていないトランザクション、運用システムが無効な情報を記録しているトランザクション、あるいはディメンションがまだ発生していない事象を表しているトランザクションが存在する可能性があります。
SALESREP テーブル
| salesrep_key | row_type | salesrep_type | salesrep_name |
|---|---|---|---|
| 0 | No Salesrep | n/a | n/a |
| 100 | Salesrep | Associate | Paul Cook |
| 101 | Salesrep | Associate | Steve Jones |
| 102 | Salesrep | Manager | Glen Matlock |
Special-case row
salesrep_key = 0は特別な行(営業担当者が不明またはいない場合を表す)
SALES_FACTS テーブル
| day_key | product_key | salesrep_key | quantity_sold |
|---|---|---|---|
| 2991 | 201 | 100 | 10 |
| 2991 | 201 | 101 | 10 |
| 2991 | 201 | 102 | 10 |
| 2991 | 201 | 0 | 10 |
A reference to the special row
salesrep_key = 0を参照して、担当者不在の売上を記録
PRODUCT テーブル
| product_key | row_type | product_code | product_name |
|---|---|---|---|
| 0 | Invalid | n/a | n/a |
| 1 | Unknown | n/a | n/a |
| 101 | Product | B57330-1 | Cardboard Box |
| 102 | Product | B47770-2 | Bubble Envelope |
Used when a fact is supplied with an invalid product_code
product_key = 0は不正なプロダクトコードに対応
Used when a fact arrives prior to dimensional context
product_key = 1はディメンション情報が未確定な時に対応
属性階層を文書化することによるその他の利点
ディメンションテーブル内の属性間の階層関係を理解することは、他の理由でも役立ちます。BIのドリルダウン機能の設定に役立つだけでなく、属性階層に関する情報は、適合ディメンション、キューブ、集計テーブルの設計にも役立ちます
スノーフレークスキーマ
ERモデリングの訓練を受けた人にとって、スノーフレークは運用システムで培われたベストプラクティスを反映したものですが、分析データベースでは、スペースを節約する以外にはあまり役に立ちません。
Snowflake(スノーフレーク設計)を受け入れる場面
通常は避けるべきとされるスノーフレーク設計ですが、例外的に適用が推奨されるケースが2つあります。
-
技術的な理由
使用するツールやアーキテクチャの都合上、スノーフレーク構造のほうが性能や機能面で有利な場合。 -
モデリング上の必要性
特定の要件を満たすために、ディメンションを複数のテーブルに分解(正規化)する必要がある場合。
Outrigger(アウトリガー)とは
定義
データウェアハウス設計で、ディメンションテーブル内に繰り返し現れる属性セットを別のテーブルに分離し、主キー/外部キー関係でリンクする方法を指します。
使う理由
- 同じ属性が複数の場所で繰り返され、一貫性を保つ必要があるとき。
- 属性数が多く、ディメンションテーブルが横に広がりすぎるのを防ぎたいとき。
メリット
- ETL処理が一元化されるため、データの整合性を確保できる。
- 属性の重複や不整合を防ぎ、管理がしやすくなる。
デメリット
- テーブル結合が必要になるため、クエリのパフォーマンスが低下する可能性がある。
- 分かりやすさ・使いやすさが犠牲になる場合がある。
注意点
基本的には星型スキーマ(スタースキーマ)を守るべきだが、やむを得ない場合にのみアウトリガーを導入する。
policy_change_facts は、ポリシー(契約)変更を記録するテーブル。
グレイン(粒度) は「ポリシーごとの変更1件につき1行」。
各行には、
- policy_key(変更対象のポリシーを表すキー)
- transaction_type_dimension(変更理由。新規契約・変更・キャンセルの区別)
- day_key_effective(この変更が有効になった日付)
- day_key_expired(次の変更により失効する日付) が含まれている。
Time-Stamped Dimension(タイムスタンプ付きディメンション)
ポリシーディメンション(policy dimension)**の**タイムスタンプ版を示している。
通常のディメンションテーブルに含まれるもの:
- サロゲートキー(内部管理用の一意ID)
- ナチュラルキー(現実世界のキー、例:ポリシー番号など)
- その他のディメンション属性(例えば、契約者名、プランタイプなど)
加えて、4つの追加カラムがある:
- transaction_type(このバージョンの変更理由)
- effective_date(このバージョンが有効になった日)
- expiration_date(このバージョンが失効する日)
- most_recent_version(これが最新バージョンかどうかを示すフラグ)
most_recent_version
- Expired
- Current
フラグはブール値から説明テキストに変換され、複数の要素で構成されるフィールドは保持されると同時に、構成要素に分解されます。ディメンションとして使用できる数値属性を見落とさないことも重要です。
KimballとRossは、有効日と有効期限を追跡するディメンションテーブルを「トランザクション追跡ディメンション」と呼んでいます。
ハイブリッド属性とは?
ハイブリッド属性とは、
**ディメンション(属性)にもファクト(数値集計対象)**にも使える列のこと。
たとえば:
-
covered_parties(被保険者数)というディメンション列を - 日付条件で絞り込んで
- SUM集計すると、まるでファクトのように使える。
これは、タイムスタンプ付きディメンション(履歴管理するディメンション)でよく起こる現象です。
Unified Star Schema




ファクトレス・ファクトテーブルの2種類
-
イベント型:活動の発生を記録(例:処理件数、問い合わせ数、広告表示回数)
→ カウントでプロセス指標を得る -
状態型:特定時点の条件や関係を記録(例:プログラムの適格性、担当者割当、実施中のキャンペーン、天候)
→ 活動と比較することで洞察を得る
ファクトの追加
ファクトのないファクト・テーブルがイベントを追跡する場合、特別なファクト(contact)を追加することで、標準的なフ ァクト・ テーブルに類似させることができます。このファクトには常に値 1 が含まれます
| day_key | time_key | customer_key | contact_type_key | contact |
|---|---|---|---|---|
| 27221 | 121 | 4622 | 101 | 1 |
| 27221 | 121 | 3722 | 101 | 1 |
| 27221 | 121 | 2828 | 102 | 1 |
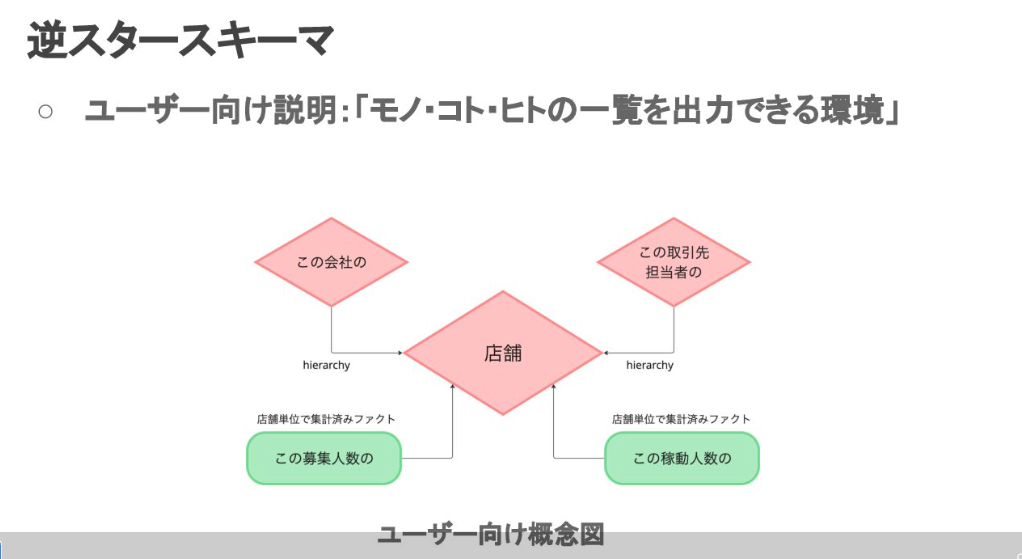
階層が明示されていれば、集計の粒度は階層の一部を丸で囲むだけで定義できる
ダッシュボードや集計の要件定義に使えそうな図ではある
とはいえ、綺麗に階層を分類できるとは限らないので、全てのケースで使えるわけではなさそう

📊Dimensional design activities
| フェーズ | 活動内容 |
|---|---|
| Plan | - プロジェクトチームの特定 - リソースの特定とスケジュール設定 - 計画の策定 - キックオフミーティングの実施 - ドキュメントの依頼 |
| Interview | - ビジネスユーザーへのインタビュー - ソースシステムの専門家へのインタビュー |
| Design | - 次元モデルの開発 - 設計レビューの実施 |
| Prioritize* | - 候補プロジェクトの特定 - プロジェクトの優先順位付けと戦略の文書化 (※単一のサブジェクトエリアに焦点を当てたプロジェクトでは省略可能) |
| Document | - 次元モデルのドキュメントを完成させる |
📋 Developing a Plan(計画の策定)
| 項目 | 内容 |
|---|---|
| 目的 | 設計を場当たり的に進めず、関係者の協力を得ながら効率的に進めるために、正式な計画を策定する。 |
| 計画の形態 | 数ページのテキストとスケジュール表で十分だが、希望があればより詳細にすることも可能。 |
| 計画に含める要素 | - スコープの明記 - 責任を持つスポンサー - プロジェクトメンバー - インタビュー対象者 - 設計レビュー参加者 - プロジェクトプランナー - 戦略的意思決定者 - スケジュール - 主要成果物 |
| キックオフミーティング | プレゼン形式で上記項目を共有し、関係者の参加意義と期待値を明確に伝える。 |
| 期待値の設定 | 設計が「解決策」ではなく「設計図とスケジュール」を生み出すものであると周知することが重要。 |
非公式なスケッチや即興のホワイトボードへの落書きを、より大きな グループによるレビューのための正式なデザインに統合する必要があります。
Developing the Dimensional Model(次元モデルの開発)
初心者や体系的に整理したい場合には、KimballとRossが提唱する以下の4ステップに従うと効果的です。
-
プロセスを記述する
設計対象となるビジネスプロセス(例:注文、出荷など)を明確にする。 -
ファクトテーブルの粒度を決める
ファクトテーブルの1行が何を表すか(例:注文の明細1件)を定義する。 -
ファクトを列挙する
分析対象となる定量的データ(例:金額、数量など)を洗い出す。 -
ディメンションを特定する
ファクトを説明・分割するための視点(例:日付、製品、顧客など)を決める。
個々のスター・スキーマを設計した後に考慮すべき追加ステップ:
-
整合性(Conformance)フレームワークの構築
全体設計の中核となる。ファクトテーブルと次元テーブルの整合性を保つため、どのテーブルが共通で使われるかを整理する。
→ これはKimball流でもInmon流でも、スタンドアロンのデータマートでも共通して重要。 -
ディメンションの「ゆっくり変化する特性(SCD)」の特定
ディメンションの属性が時間とともにどのように変化するかを把握し、SCDの適用方法(Type 1/2/3など)を決める。 -
各プロセスに対する代替モデルの検討
異なる視点や粒度でのモデリング、ファクトの分割や統合など、柔軟な設計を検討する。
ファクト間の親和性はプロセスの手がかり
マトリックスの行は、インタビュー・メモ から特定された事実を表します。列は次元の候補を表す。チェックマークは、各事実が利用可能な次元の詳細レ ベルを示します。
| 指標 | 訪問日 | 提案日 | 注文日 | 出荷日 | 返品日 | 製品 | 営業担当 | 顧客 |
|---|---|---|---|---|---|---|---|---|
| 商談回数 | ✓ | ✓ | ✓ | |||||
| 提案数量 | ✓ | ✓ | ✓ | ✓ | ||||
| 提案金額 | ✓ | ✓ | ✓ | ✓ | ||||
| 注文数量 | ✓ | ✓ | ✓ | ✓ | ||||
| 注文金額 | ✓ | ✓ | ✓ | ✓ | ||||
| 原価金額 | ✓ | ✓ | ✓ | ✓ | ||||
| 粗利金額 | ✓ | ✓ | ✓ | ✓ | ||||
| 売上金額 | ✓ | ✓ | ✓ | ✓ | ✓ | |||
| 出荷数量 | ✓ | ✓ | ✓ | ✓ | ||||
| 返品数量 | ✓ | ✓ | ✓ | ✓ | ||||
| 返品金額 | ✓ | ✓ | ✓ | ✓ |
要件クロスリファレンス
| 日 | 製品 | 営業担当者 | - | - | - | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 日 | 四半期 | 製品 | カテゴリ | 営業担当者 | 担当地域 | 地域 | 顧客 | 倉庫 | 注文行 | ||
| 営業 | 営業電話 | ✓ | ✓ | ✓ | ✓ | ✓ | |||||
| 営業訪問 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||
| 提案 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||
| 受注 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| 出荷 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| 返品 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| 在庫 | 在庫 | ✓ | ✓ | ✓ | ✓ | ✓ | |||||
| 需要予測 | ✓ | ✓ | ✓ | ✓ | |||||||
| 財務 | 売掛金 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| 売上目標 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||||
| コミッション支払 | ✓ | ✓ | ✓ | ✓ | ✓ |
✅ ファクトの加算性(Additivity)による分類
| 種類 | 定義 | 例 | 集計可能な軸 |
|---|---|---|---|
| 🔢 加算可能(Additive) | すべての軸(ディメンション)で合計できる | 売上金額、数量、コスト | 日付・商品・店舗などすべて |
| ➕ 半加算可能(Semi-Additive) | 一部の軸では合計可能だが、他ではNG | 在庫残高、口座残高、スナップショット値 | 店舗・商品ではOK、日付ではNG(時点ごとの値) |
| 🚫 非加算(Non-Additive) | どの軸でも合計できない | 単価、利益率、ROAS、平均値、比率 | 集計は平均・中央値などを使う |
🔍 各例の補足:
✅ 加算可能
-
数量(quantity)
→ 商品や日付、顧客で自由に合計できる。 -
売上金額(sales_amount)
→ 同様に、どのディメンションでも足し算できる。
➕ 半加算可能
-
在庫残高(inventory_balance)
→ 店舗別や商品別に「ある時点の値」は意味があるが、複数日付を足すと意味がない。 -
残高(account_balance)
→ スナップショットで取得した値であり、日付をまたいだ合計は無意味。
🚫 非加算
-
単価(unit_price)
→ 合計しても意味がない。平均単価として扱う。 -
利益率(profit_margin)
→ 平均や加重平均で扱うべき。単純合計は不可。 -
クリック率(CTR)やCVR
→ 合計値にはできない。計算式に基づく比率なので、全体で再計算する必要がある。
💡 実務での使い分けポイント
- ダッシュボード設計やメトリクス定義のときに「この数値は日付で集計できるか?」を考える。
- 半加算の指標は、分析時に「最新日付だけ」や「スナップショット」で扱う。
- 非加算の指標は、集計前の状態で計算するか、平均値/比率の再計算が必要。
データ・AIエンジニアBooks#52 - 30分でわかる「アジャイルデータモデリング 組織にデータ分析を広めるためのテーブル設計ガイド」