SCDやめるってよ
伝えたいこと
データ特性、要件に応じて必ずしもひとつのデータモデリング、アプローチで解決できるとは限らずその都度データ特性、要件にフィットするデータモデリングをするのが結果的に良い方法だと考えています
なので、ここで話す内容はあくまで一例に対してSCDをやめたデータモデリングを採用したら上手くデータ特性と要件を満たせたという話なので参考程度に読んでもらえると幸いです
ここで話すこと
- dbtを使ってSCDに準じた開発・運用
- SCDをやめるアプローチについて
ここで話さないこと
- SCDの説明
- 基礎的なデータモデリングの概要
- ソースデータの収集・管理
忙しい方向け
SCDやめてみたを読んでいただければと思います
前提
以下のデータ特性とモデリング要件を前提に話を進めます
- イベントログの各レコードに既にディメンションとなる情報とファクトがまとめられている
- モデリング要件
- 日毎のKPI集計をしたい
- 以下の情報でセグメントが切られる
- ユーザー
- 所属地域
これらを満たすデータとしてgoogleが提供するGA4の公開データ(以降、パブリックデータと呼びます)を例に説明を進めます
以上を元に以下を採用して話を進めます
| content | name |
|---|---|
| source data | bigquery-public-data.ga4_obfuscated_sample_ecommerce |
| data modeling | Star Schema |
サンプルのデータモデリング
このパブリックデータはECサイトにGA4入れて得られたデータになります
1レコードに以下のような様々なデータを含みます
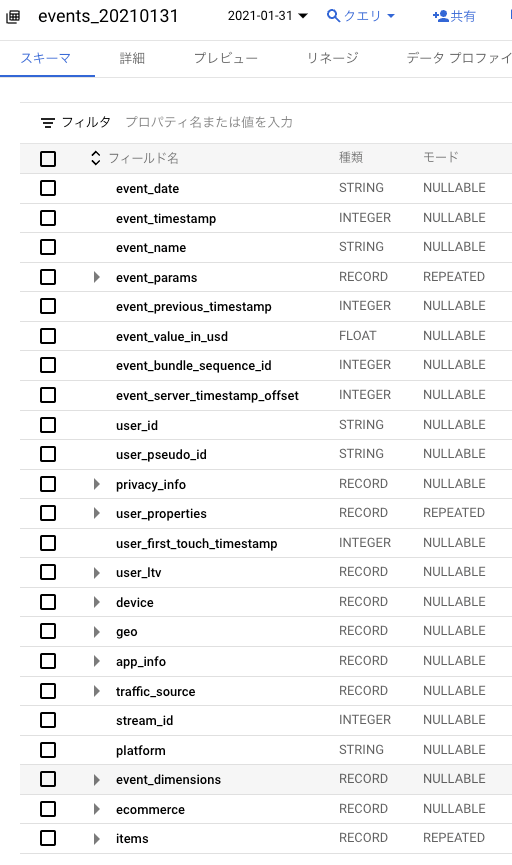
テーブルの要約
- イベントのタイムスタンプ
- ページメタデータ
- アクセスユーザー情報
- デバイス情報
- 地域情報
- トラフィックデータ
- ECサイトのアイテム情報
上記のデータの中から今回は、ユーザーアクセスからDAUを以下のセグメントに切ったデータモデリングしていきます
- ユーザー
- 所属地域
下図が例として作成したデータモデリングになります
このデータモデリングから例えば以下のようなメトリクスの計算ができます
- DAU/WAU/MAU
- RR
etc..
更にそれらメトリクスからディメンションに上げたセグメントで切った分析を行なえます
dbtによるStar Schema + SCDの実装
dbtでStar SchemaとSCDを実装する際にファーストチョイスとして上がるのがdbtの標準機能で搭載されているsnapshotというSCD Type2に準じた実装をサポートする機能があります
このsnapshotは、他のdbtのモデルと同じようなコードを記述してそのモデルのconfigにsnapshotに必要な項目を入れるだけでSCD Type2の処理を実現する機能です
具体的な例を挙げるとユーザー情報のディメンションを作りたい際は以下の様に記述すると実装することができます
{% snapshot dim_scd__users %}
{{
config(
target_schema=target.schema,
target_database=target.project,
unique_key="user_key",
strategy="timestamp",
updated_at="updated_at"
)
}}
select
{{ dbt_utils.generate_surrogate_key(['user_id', 'created_at']) }} as user_key,
user_id,
created_at,
platform,
device.category,
device.mobile_brand_name,
device.mobile_model_name,
device.operating_system,
device.operating_system_version,
device.language as device_language,
max(event_timestamp) as updated_at
from
{{ ref('stg__events') }}
where
date(event_timestamp) = "{{ var('date') }}"
group by 1, 2, 3, 4, 5, 6, 7, 8, 9, 10
{% endsnapshot %}
これで dbt snapshotもしくは dbt buildでdbtが内部でSCD Type2に沿った処理が行われます
ディメンションテーブルと結合できるようにファクトテーブルを実装すればStar Schemaの実装は完了します
with
import_stg as (
select * from {{ ref('stg__events') }} where date(event_timestamp) = "{{ var('date') }}"
),
import_dim_users as (
select * from {{ ref('dim_scd__users') }} where date(dbt_valid_to) is null
)
select
import_dim_users.user_key,
import_stg.event_timestamp as access_timestamp,
import_stg.event_timestamp
from
import_stg
inner join
import_dim_users
on
import_stg.user_id = import_dim_users.user_id
and import_stg.created_at = import_dim_users.created_at
また、ファクトテーブルのmaterializedにincrementalを採用することで細かいアクセス粒度に沿ったデータをストアすることが出来ます
version: 2
models:
- name: fct__access
config:
materialized: incremental
incremental_strategy: insert_overwrite
on_schema_change: fail
partition_by:
field: event_timestamp
data_type: timestamp
granularity: day
snapshotを使って実装をする上での考慮事項
上述したようにsnapshotを使うと簡単にディメンションテーブルの実装を実現出来ます
snapshotは、内部の処理で一部のカラムの差分を見ることでデータ追記の処理が行われその処理は2つのモード(snapshot内では、strategyと呼びます)で実装されています
- timestamp: updated atなどのデータの更新を表すカラムを元にデータ追記をします
- check: 複数のカラムの値を結合して差分があればそのデータを追記します
(データ更新日は自動で現実で処理した日時が入るため意図しない更新日が入ることがあります)
データの変更を表現できるような値を持つソースであれば気にせずそのままsnapshotを使っても問題なく実装することが出来ます
下図のように扱うソースのレイヤーで担保する機能が変わります
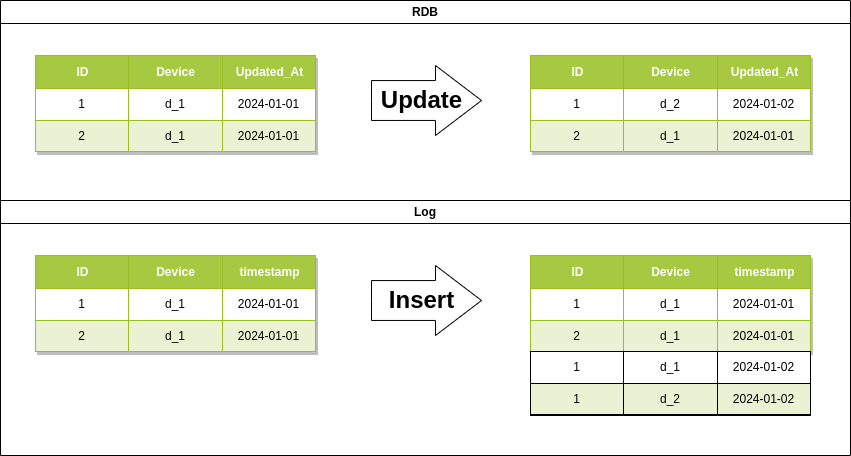
- RDBをソースとする場合、RDB側でデータ更新の担保します
- ログの場合は、データ追記するのみなので処理する時点でどのデータで更新された正しいものなのかを正とすることが難しいです
このことより、RDBをソースとしたディメンションには問題なくsnapshotを導入できますがログをソースとする場合はsnapshotの処理の前にRDBで担保していたような処理を前段追加する必要があります
追加する処理の一例として、ディメンションテーブルを自己参照して差分チェックをするような処理があります
このようにデータ特性によっては、snapshotの機能だけではサポートできない場合があります
SCDを取り入れた開発・運用
snapshot以外にもSCD自体を取り入れた開発・運用では様々な考慮事項があります
考慮事項
開発
- 差分を取るカラムが必要十分か
- 再処理した場合でもデータ更新日時の冪等性を保つ処理
- ディメンションと結合するファクトで処理日付の整合性をとる
- 運用中で既存のディメンションテーブルへのカラムを追加するときに一意性への影響を考慮する
運用
- 開発で更新日時の冪等性を保っても再処理した日時から最新日付まですべて再処理しないとディメンションテーブルの時系列の整合性が取れなくなる
- ディメンションテーブルを一意に表現するキーが更新されたらファクトも合わせて更新処理が必要になる
開発・運用例
一例として、パブリックデータを使った具体的な開発・運用を説明します
- パブリックデータのカラムをディメンションとファクトの要素分解します
↑ソースに当たるのでここから以下の様に分解します
-
分解したディメンションとファクトが結合できるようにキーを定義します
- キーの定義は、ディメンションで持つデータが一意であることを表現できるようにします
- 例えば、dim_usersであれば
user_idとcreated_atをdbt_utils.generate_surrogate_key関数を使ったサロゲートキーを作ります - a.b.の手順を行ったデータモデリングを作ります
-
ディメンションで差分をチェックする処理を実装します
-
ファクトテーブルの生成はディメンションテーブルのサロゲートキーの作成に使ったカラムとディメンションテーブルを結合することでサロゲートキーを取得できます
- サンプルコード
- 最後にファクトに必要な値をデータから取得してファクトテーブルにストアします
上記の手順でパブリックデータからディメンションとファクトの開発を行うことができます
運用中も同様の手順でディメンションテーブルの追加やカラムの追加が可能です
SCDをやめてみた
上述していることをまとめるとSCDを導入した開発・運用は総じて不定期に発生するデータ更新を考慮した実装、オペレーションが無いとディメンションテーブルの整合性を担保できなくなります
SCDを用いると以下のような効率的なデータリソースの使用を提供することが出来ます
- ディメンションに更新が合ったものと新規のみ追加されるため保持するデータ量を圧縮することができる
- 保持するデータ量に起因してクエリのスキャンコストを抑えることができる
提供できるメリットは、効率的な使用にフォーカスしているため開発、運用オペレーションのコストはあまり考慮されていないと考えることもできます
つまり開発、運用オペレーションコストが効率的な使用と比較して上回っていると考えられる場合SCDを採用しないモデリングを採用するもの一つです
SCDを導入しないStar Schemaでは以下のような開発、オペレーション上のメリットが得られると考えられます
- ディメンションテーブルの実装で差分をチェックする処理を省ける
- ファクトテーブルとディメンションテーブルの更新粒度を合わせることで整合性を保ちやすい
- バックフィルなどの再処理でディメンションの時系列性が壊れることが無くなる
SCDをやめた実装
SCDを採用しないStar Schemaの実装はどのようなことを考慮すればよいかまとめました
- ディメンションとファクトの更新粒度を合わせる
- 具体的には、日次更新バッチであればファクトは必ず日次更新されていましたがそれをディメンションでも同じようにする
- ディメンションのデータは同日のものだけみるようにして過去データとの差分は考慮しない
- ファクトが参照するディメンションは処理をした同じ日付を参照して結合する
上記の考慮事項は実装のみで上述したデータモデリングはSCDに関係なく形は変わりません
dbtの機能として以下のように変えることが出来ます
-
dbt snapshotを使った処理を撤廃- →
dbt runですべてのモデルを実行できる
- →
- ディメンションの自己参照から差分チェックする処理は不要になります
- →日付の粒度で処理する場合はその中でデータだけでディメンションを表現します
- ディメンションもincremental modelに変更することができる
- →incremental modelの機能としてパーティションテーブルとしてデータをストアできるようになる
- →カラム追加はincremental modelの機能で
on_schema_changeを用いることができる
- ファクトは同日のディメンションのみ参照して結合できればよい
- →ディメンションを全スキャンしないためディメンションのストアする量は増えてもスキャン量をそこまで増えない
これらをまとめて実際に実装したものが以下のコードになります
上述したユーザーのディメンションテーブルやファクトテーブルと比較してもかなり実装コードが少なくなったことがわかります
サンプルコードで比較すると以下の様にコード削減することが出来ました
| file name | scd | not scd | diff |
|---|---|---|---|
| dim__users | 48 | 33 | 15 |
| dim__countries | 40 | 29 | 11 |
| fct__access | 71 | 50 | 21 |
3つのファイルだけでも合計で47行のコードを削減できています
また、単純な数の比較だけでなく内部のロジックもスッキリしています
例えば、dim__usersを並べてみます
SCDを無くしたコードでは以下のような変更されています
- 自己参照からの差分チェックが無い
- ソースの日付から時系列に沿った逐次処理が省かれている
- サロゲートキーは同じuser_id, created_atでも日付が変われば別のキーとしてストアされる
- パーティションへのwhereを無くしてバックフィルの処理が可能
主に
サロゲートキーは同じuser_id, created_atでも日付が変われば別のキーとしてストアされる
の変更を加えたため他の実装を実現出来ています
また、カラム追加に伴うキーの変更も変更日以降のみディメンションテーブルとファクトを更新することが出来ます
以上のことより、例に上げたパブリックデータのようなデータ特性にはSCDの無いデータモデリングを導入すると開発、運用オペレーションコストを下げることができます
細かいyamlファイルの記述やディレクトリ構成はgithubを参照ください
まとめ
SCDは、データ特性によっては効率的なリソース管理を促すものの考慮事項に沿った開発・運用オペレーションを構築しないとデータの整合性が崩れることがあります
dbtのsnapshotという機能を用いるだけでSCDを実装するのに必要な処理を省くことができるがソース側でデータ更新を担保する機能が無い場合はELT処理内で追加の実装が発生します
リソース管理よりも開発、運用オペレーションコストを重視する場合は、SCDを採用しないデータモデリングを導入するとSCDで必要な考慮事項を省きつつデータの整合性を保ちやすい実装を実現しやすくなります
また、dbtなどの新しいツールはこれらの開発の速度と正確性の向上をサポートするものでデータモデリングのスクラップ&ビルドを効率的に実現できるツールの側面もあると考えています
冒頭でも話しましたがデータ特性と要件に応じて適合するデータモデリングを検討して導入するのがより良いデータパイプラインの実装につながると考えています
以上、ここまで読んでいただきありがとうございました
Discussion