【dbt】dbt snapshot
公式
delete処理:宛先テーブルに存在するレコードがソーステーブルでdeleteされていた場合
update処理:宛先テーブルと比較してソーステーブルのレコードがupdateされていた場合
insert処理:宛先テーブルに無いレコードがソーステーブル側に新規で作成されていた場合
細かく挙動が説明されていた
Slowly Changing Dimension の Type 0~7 が何を意味しているのかわかる
わかりやすい
{% snapshot daily_data_snapshot %}
{{
config(
target_database=[BigQueryで言うところのプロジェクト名]
target_schema=[データセット],
unique_key=[主キー],
strategy='timestamp',
updated_at=[date型のカラム。ここに指定した列を最終更新日時として、既存テーブルと比較して更新された行をINSERTする],
)
}}
select
*
from
{{ source([データセット名], [テーブル名]) }}
{% endsnapshot %}
snapshotに関するベストプラクティス
snapshotはとても便利な機能なのですが、使い方を誤ると、全く活用されない大量のデータを保持してしまうなど、リスクに繋がる可能性があります。
以下は公式Docからの引用ですが、snapshotに関するベストプラクティスを、私なりに解釈してまとめておきます。
-
Strategyはできる限り「timestamp」を使用する
- 差分を効率的に検知し、最適なデータ更新を行うためです。
-
unique_keyが本当にユニークであることを確認する-
unique_keyはスナップショットを正確に機能させるために重要です。unique_keyの一意性を保証するためにschema testを設定することも推奨されます。
-
-
Snapshot用に別のスキーマを定義する
- 分析用データとスナップショットを別スキーマにすることで、意図しない削除からデータを保護できます。Snowflakeなどでは、スナップショット生成時に別のロールを使用して削除を防ぐといった運用も可能です。
-
Sourceに対してSnapshotを行う
- クレンジング処理を行う前の生データをスナップショットすることが理想です。元データをそのまま保存することで、将来のデータ追跡に役立ちます。
-
Sourceを参照する際は
source関数を使う-
source関数を使うことで、データリネージが追跡可能になり、データの出所を明確にすることができます。
-
-
Snapshotには、できるだけ多くのカラムを選択する
- 可能であれば
select *を使用し、将来的に利用する可能性があるカラムをすべてスナップショットするのが理想です。
- 可能であれば
-
SnapshotのSELECT文でJOINを避ける
- JOINを含むクエリは、timestampの信頼性を損なう可能性があります。JOINが必要な場合は、各元テーブルごとにスナップショットを取ることを検討してください。
-
SnapshotのSELECT文でデータのクレンジングやロジックの実装を避ける
- クレンジング処理やロジックは将来的に変更が必要になる可能性があるため、シンプルなクエリでスナップショットを取ることが推奨されます。ただし、JSONのカラムを展開する場合などは例外です。
これらのポイントを守ることで、スナップショットの効果的な活用とデータの管理がスムーズになります。
--store-failures フラグ
dbt test を実行したときに失敗したテストによって条件を満たさなかった行を保存する事が出来ます。
それが --store-failures フラグです。
dbt test --select ./models/sources --store-failures
ソースのみでテストを実行する $ dbt test --select source:jaffle_shop
dbt snapshot は、「列名は変わるが値のupdated_atはそのまま」という場合を除いて、データソースの変更に追従できることがわかりました。
増分更新テーブルをスナップショットに切り替え
updated_atで増分更新テーブルしている
create or replace table `スナップショットテーブル`
partition by date_trunc(updated_at, day)
cluster by ~, ~,~,~ as (
with
base_data as (select * from `増分更新テーブル`),
data_with_row_number as (
select *, row_number() over (partition by id order by updated_at) as row_number
from base_data
),
previous_records as (
select id, updated_at as dbt_valid_to, row_number - 1 as row_number
from data_with_row_number
where row_number >= 2
),
final as (
select
data_with_row_number.* except (row_number),
to_hex(
md5(
concat(
coalesce(cast(data_with_row_number.id as string), ''),
'|',
coalesce(cast(data_with_row_number.updated_at as string), '')
)
)
) as dbt_scd_id,
data_with_row_number.updated_at as dbt_updated_at,
data_with_row_number.updated_at as dbt_valid_from,
previous_records.dbt_valid_to
from data_with_row_number
left join
previous_records
on data_with_row_number.id = previous_records.id
and data_with_row_number.row_number = previous_records.row_number
),
test as ( -- 確認用
select id, updated_at, dbt_scd_id, dbt_updated_at, dbt_valid_from, dbt_valid_to
from final
where id in (1945, 1813)
order by id asc, updated_at asc
),
test2 as ( -- 確認用
select id, count(*) as cnt
from base_data
group by 1
having cnt > 1
)
select *
from final
)
dbt snapshotの対象の見極め
SELECT *
FROM INFORMATION_SCHEMA.REFERENTIAL_CONSTRAINTS
DELETE_RULE の値
- CASCADE: 参照元の行が削除されたとき、参照先の行も削除される
- SET NULL: 参照元の行が削除されたとき、参照先の外部キーが NULL になる
- RESTRICT / NO ACTION: 参照元の行が削除されるとエラーになる
SELECT
REFERENCED_TABLE_NAME,TABLE_NAME,DELETE_RULE,CONSTRAINT_NAME
FROM INFORMATION_SCHEMA.REFERENTIAL_CONSTRAINTS
WHERE REFERENCED_TABLE_NAME in (
"〜",
"〜",
"〜"
)
CASCADEが設定されているカラム一覧を取得 用例:データを更新・削除する際に他のテーブルのデータに影響を与えてしまわないかを確認する
SELECT `TABLE_SCHEMA`,
`KEY_COLUMN_USAGE`.`TABLE_NAME`,
`COLUMN_NAME`,
`KEY_COLUMN_USAGE`.`REFERENCED_TABLE_NAME`,
`REFERENCED_COLUMN_NAME`,
`UPDATE_RULE`,
`DELETE_RULE`
FROM `INFORMATION_SCHEMA`.`KEY_COLUMN_USAGE`
JOIN `INFORMATION_SCHEMA`.`REFERENTIAL_CONSTRAINTS`
ON `INFORMATION_SCHEMA`.`KEY_COLUMN_USAGE`.`TABLE_SCHEMA` =
`INFORMATION_SCHEMA`.`REFERENTIAL_CONSTRAINTS`.`CONSTRAINT_SCHEMA`
AND
`INFORMATION_SCHEMA`.`KEY_COLUMN_USAGE`.`TABLE_NAME` =
`INFORMATION_SCHEMA`.`REFERENTIAL_CONSTRAINTS`.`TABLE_NAME`
AND
`INFORMATION_SCHEMA`.`KEY_COLUMN_USAGE`.`CONSTRAINT_NAME` =
`INFORMATION_SCHEMA`.`REFERENTIAL_CONSTRAINTS`.`CONSTRAINT_NAME`
WHERE `DELETE_RULE` = 'CASCADE'
OR `UPDATE_RULE` = 'CASCADE';
- CASCADE:
- 親テーブルから行を削除または更新し、子テーブル内の一致する行を自動的に削除または更新します。 ON DELETE CASCADE と ON UPDATE CASCADE の両方がサポートされています。 2 つのテーブル間で、親テーブルまたは子テーブル内の同じカラムに対して機能する複数の ON UPDATE CASCADE 句を定義しないでください。
- SET NULL:
- 親テーブルから行を削除または更新し、子テーブルの外部キーカラムを NULL に設定します。 ON DELETE SET NULL 句と ON UPDATE SET NULL 句の両方がサポートされています。
- SET NULL アクションを指定する場合は、子テーブル内のカラムを NOT NULL として宣言していないことを確認してください。
- RESTRICT:
- 親テーブルに対する削除または更新操作を拒否します。 RESTRICT (または NO ACTION) を指定することは、ON DELETE または ON UPDATE 句を省略することと同じです。
- NO ACTION:
- 標準 SQL のキーワード。 MySQL では、RESTRICT と同等です。 MySQL Server は、参照されるテーブル内に関連する外部キー値が存在する場合、親テーブルに対する削除または更新操作を拒否します。 一部のデータベースシステムは遅延チェックを備えており、その場合、NO ACTION は遅延チェックです。 MySQL では、外部キー制約はただちにチェックされるため、NO ACTION は RESTRICT と同じです。
- SET DEFAULT:
- このアクションは MySQL パーサーによって認識されますが、InnoDB と NDB はどちらも、ON DELETE SET DEFAULT または ON UPDATE SET DEFAULT 句を含むテーブル定義を拒否します。
{% test validity_period_validation(model, column_name) %}
{# スナップショットの有効期間に隙間や重複がないか
https://qiita.com/hanon52_/items/6b1ed1a5247d0cac759f
#}
with ordered_periods as (
select
{{ column_name }},
dbt_valid_from,
dbt_valid_to,
lead(dbt_valid_from) over (partition by {{ column_name }} order by dbt_valid_from) as next_valid_from
from
{{ model }}
)
select *
from ordered_periods
where
dbt_valid_to != next_valid_from
{% endtest %}
異常が発生したタイムスタンプ(2024-12-08 16:25:52.849929 UTC)の前まで履歴をロールバックさせます。
-- 異常発生後に挿入された行を削除
delete from `ucchi_test_snapshot`
where dbt_valid_from >= timestamp("2024-12-08 16:25:52.849929 UTC");
-- 異常発生後に無効となった行を有効化
update `ucchi_test_snapshot`
set
dbt_valid_to = null
where dbt_valid_to >= timestamp("2024-12-08 16:25:52.849929 UTC");
is_current
dbt_valid_toがnullであれば、is_currentなのか?
dbt v1.8のinvalidate_hard_deletes=True,v1.9のhard_deletes='invalidate'では、削除されるとdbt_valid_toが入る。つまり物理削除されたレコードは、下記の条件で除外される。
if(dbt_valid_to is null, true, false) as is_current
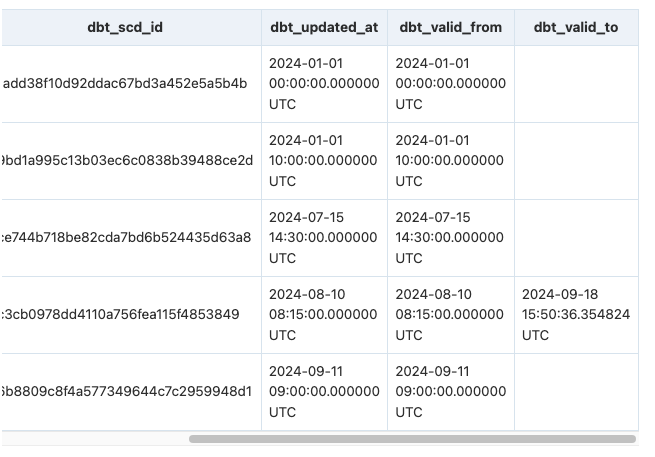
物理削除されたレコードも含めたis_currentを定義するのであれば
下記の条件で、is_currentを定義する。
dbt snapshotでis_currentがない理由がわかった。何をis_currentとしたいかは変わる
WITH your_table AS (
SELECT 1 AS id, DATE '2024-01-01' AS dbt_updated_at UNION ALL
SELECT 2, DATE '2024-01-02' UNION ALL
SELECT 3, DATE '2024-01-03' UNION ALL
SELECT 3, DATE '2024-01-04' UNION ALL
SELECT 3, DATE '2024-01-05' UNION ALL
SELECT 4, DATE '2024-01-06'
)
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY id ORDER BY dbt_updated_at DESC) = 1 AS is_current
FROM
your_table
ORDER BY
id, dbt_updated_at
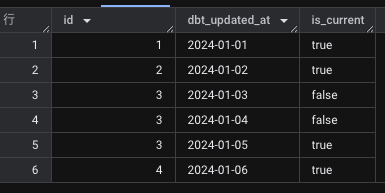
多分これ(検証中)
PARTITION BY dbt_valid_to
CLUSTER BY dbt_unique_key, dbt_scd_id, dbt_valid_from
1. 前提
- SCD2 履歴管理のスナップショットテーブル
- MERGE で毎日更新(insert / update / delete)
- 履歴復元や時系列分析で参照される可能性あり
テーブルの主な列:
-
dbt_unique_key… 主キー / MERGE join に使用 -
dbt_scd_id… SCD2 一意ID / MERGE join に使用 -
dbt_valid_from,dbt_valid_to… 履歴期間管理 -
created_at,updated_at… 作成/更新タイミング
https://tech.timee.co.jp/entry/2024/06/11/151948
2. パーティション設計の考え方
更新最適化重視
-
PARTITION BY dbt_valid_to
- 更新時に
WHERE dbt_valid_to IS NULLのみスキャンできる - 古い履歴をスキャンせず MERGE が効率化
- 更新時に
参照最適化重視
- 参照クエリで時系列復元が多い場合は
- PARTITION BY dbt_valid_from に変更すると良い
- ただし更新が毎日走る場合は更新効率を優先するのが無難
3. クラスタリング設計の考え方
更新効率重視
-
CLUSTER BY dbt_unique_key, dbt_scd_id, dbt_valid_from が妥当
-
dbt_unique_key→ MERGE join に効く -
dbt_scd_id→ SCD2 一意行の効率化 -
dbt_valid_from→ 時系列差分抽出の効率化
-
補足
- 同じ列を PARTITION と CLUSTER に入れる必要は基本ない
- 日単位パーティションであれば、クラスタに同じ列は不要
- 月単位パーティションで日付条件を絞る場合のみクラスタに入れる意味がある
- 書き込みコストを抑えるため、クラスタ列は 3〜4 列までに収める
4. 参照クエリ向け最適化
- snapshot を直接分析で使う場合は、別 mart テーブルを作って
PARTITION BY dbt_valid_from
CLUSTER BY dbt_unique_key, dbt_valid_to
- 更新効率と分析効率を分離すると安定
5. まとめの推奨設定
PARTITION BY dbt_valid_to
CLUSTER BY dbt_unique_key, dbt_scd_id, dbt_valid_from
- 毎日 MERGE が走る更新処理に最適化
- 時系列抽出や履歴参照もある程度カバー
- 書き込みコストとパフォーマンスのバランスが良い
💡 ポイント
- 更新が毎日走るテーブルは、更新効率優先でクラスタ列を絞る
- 分析向けのクエリは downstream mart やマテビューで最適化する
- 同じ列を PARTITION と CLUSTER に入れる必要は基本なし