今まで貯めたBigQueryのスナップショットをdbt snapshotの世界に持っていく
概要
- データ基盤の中で変わりうるマスターデータ(メンバーのステータスなど)のスナップショットを置いておくために毎日メンバー数分のデータを取り込んで保存していました
- しかしこれを続けるとデータ量が膨大になってきてしまいまいます
- dbtを導入するにあたりdbt snaphshotで、変更したレコードのみを取り込むようにしたくなりました
- 今まで撮り続けたレコードもなんとかdbt snapshotのデータの初期のデータとして取り込みたいと思い格闘した記録をここに記そうと思います
ちなみに
いつからスナップショットを撮り始めるといいの?という質問に対してこのブログではこのように述べてます
The best time to start snapshotting your data was twenty years ago.
The second best time is today.
早く撮り始めないとこの記事で述べていくように一手間加えないといけなくなってしまいます。
扱うデータを作る
データセットを作る
lakeというデータセットを作ってそこにデータソースを作ろうと思います。
create schema lake
options(
location="asia-northeast1"
)
既存のスナップショットを作る
old_snapshotという名前にして既存のスナップショットを作ります。
メンバーのidとstatusといつのスナップショットかを表すだけのシンプルなテーブルにします。
create or replace table lake.old_snapshot
as
with snapshot_20220101 as (
select
member_id,
member_status,
member_type,
date(2022, 1, 1) snapshot_date
from
(
select "hoge" as member_id, "active" member_status, "premium" member_type union all
select "fuga" as member_id, "active" member_status, string(null) member_type
)
),
snapshot_20220102 as (
select
member_id,
member_status,
member_type,
date(2022, 1, 2) snapshot_date
from
(
select "hoge" as member_id, "active" member_status, "premium" member_type union all
select "fuga" as member_id, "active" member_status, string(null) member_type
)
),
snapshot_20220103 as (
select
member_id,
member_status,
member_type,
date(2022, 1, 3) snapshot_date
from
(
select "hoge" as member_id, "deactive" member_status, "premium" member_type union all
select "fuga" as member_id, "active" member_status, string(null) member_type
)
),
final as (
select * from snapshot_20220101 union all
select * from snapshot_20220102 union all
select * from snapshot_20220103
)
select * from final
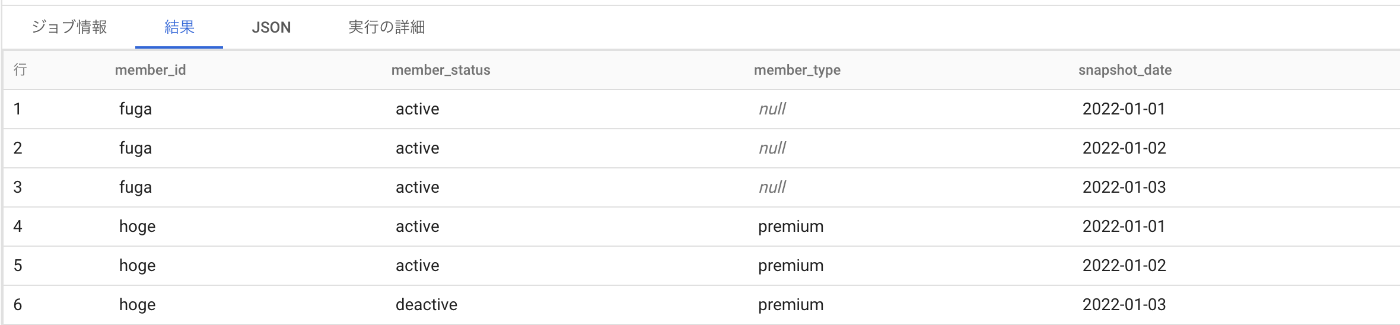
hogeさんとfugaさんがいて、1月2日には何も変更が起きておらず1月3日にhogeさんがdeactivateになっているテーブルです。
また、member_typeというnullableなカラムがあり、hogeさんには値が入っていて変わっていないですが、fugaさんはずっとnullが入っています。
データソースを作る
データソースとなるマスターデータは今の状態のみを表すものにします。
create or replace table lake.member
as
select
member_id,
member_status,
member_type
from
(
select "hoge" as member_id, "deactive" member_status, "premium" member_type union all
select "fuga" as member_id, "deactive" member_status, string(null) member_type
)

最新の状態ではどちらもdeactivateになっています。
dbt snapshotの準備をする
dbtのプロジェクトを作成してsnapshotsディレクトリ配下にmember.sqlとしてスナップショットのためのクエリを用意します。
{% snapshot member %}
{{
config(
target_schema="snapshots",
unique_key="member_id",
strategy="check",
check_cols=[
"member_status",
"member_type",
]
)
}}
select
member_id,
member_status,
member_type
from lake.member
{% endsnapshot %}
dbt snapshotを実行すると

最新の情報が保存されています。
モチベーションとしてはスナップショット撮ってある分もここに追加したい!というものになります。
マイグレーションクエリについて
前日との比較
今回変わりうるのはmember_statusです。
前日のmember_statusをカラムに追加します。
一番初めの日付のところにはnullが入ります。
select
*,
row_number() over(partition by member_id order by snapshot_date) row_number,
lag(member_status, 1) over(partition by member_id order by snapshot_date) lag_member_status,
lag(member_type, 1) over(partition by member_id order by snapshot_date) lag_member_type,
from member_master
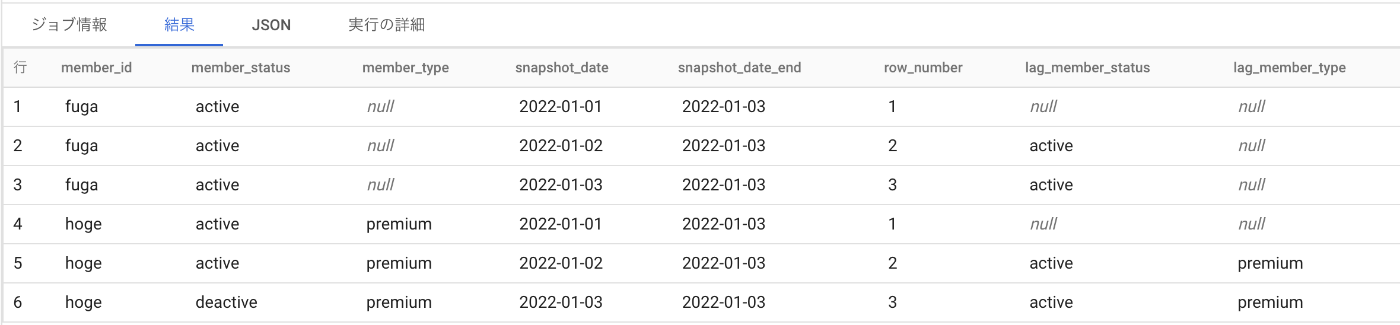
変更があった部分にflagをつける
最古のデータ(row_numberが1のところ)と変更があった部分にflagをつけます。
select
*,
if(
row_number = 1 or
member_status != lag_member_status or
member_type != lag_member_type,
1, 0
) modified_flag
from member_with_lag
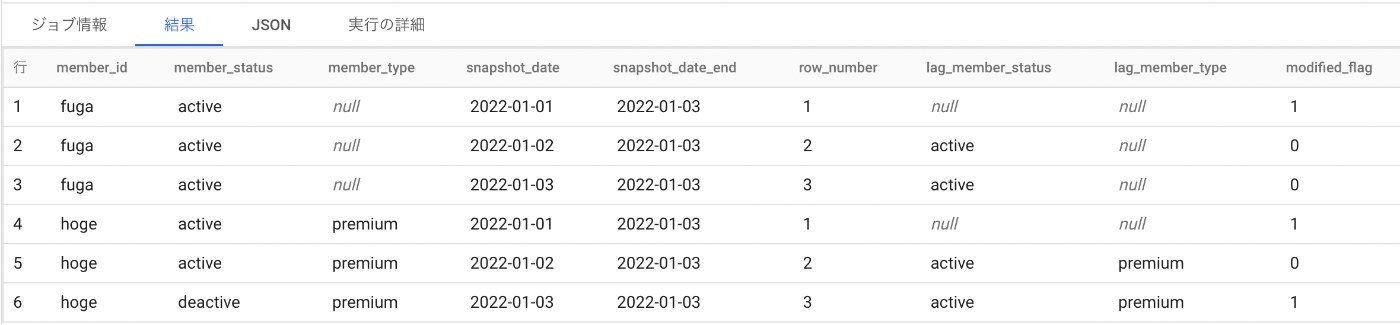
変更が起きてから次に起きるまでをひとまとまりにする
言語化するのが難しいのですがdbt_valid_fromとdbt_valid_toを作るための作業です。
まとまりをrankという言葉を使って表しています。
select
*,
sum(modified_flag) over(partition by member_id order by snapshot_date) rank,
from member_with_flag
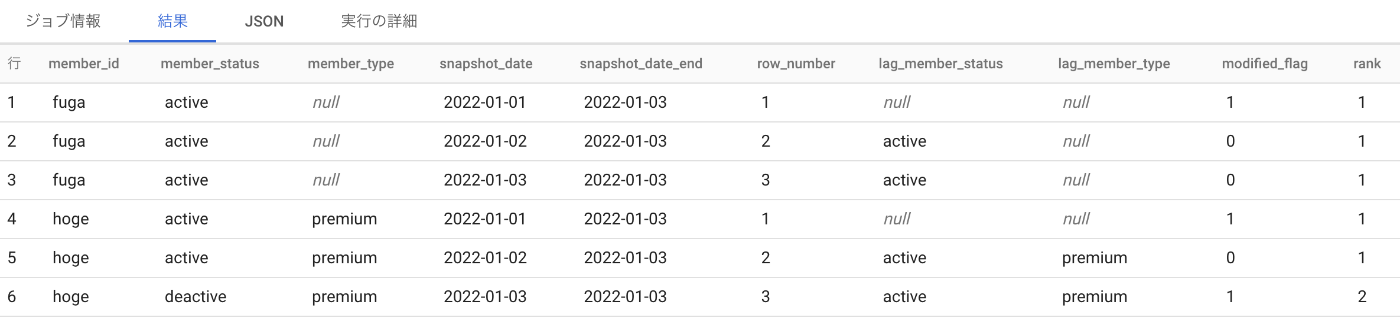
最終的なクエリ
ここまでできたらrankごとにsnapshot_dateのminとmaxをとってdbt snapshot用にちょっと整えてあげます。
DDLでテーブルを作るところも併せた最終的なクエリはこちらになります
create table if not exists snapshots.member
(
member_id string not null,
member_status string not null,
member_type string,
dbt_scd_id string not null,
dbt_updated_at timestamp not null,
dbt_valid_from timestamp not null,
dbt_valid_to timestamp
)
partition by date(dbt_updated_at)
as
with param as (
select
date(2022, 01, 03) snapshot_date_end
),
member_master as (
select
*
from `lake.old_snapshot`,
param
where
snapshot_date <= param.snapshot_date_end
),
member_with_lag as (
select
*,
row_number() over(partition by member_id order by snapshot_date) row_number,
lag(member_status, 1) over(partition by member_id order by snapshot_date) lag_member_status,
lag(member_type, 1) over(partition by member_id order by snapshot_date) lag_member_type,
from member_master
),
member_with_flag as (
select
*,
if(
row_number = 1 or
member_status != lag_member_status or
member_type != lag_member_type,
1, 0
) modified_flag
from member_with_lag
),
member_with_rank as (
select
*,
sum(modified_flag) over(partition by member_id order by snapshot_date) rank,
from member_with_flag
),
member_history as (
select
member_id,
rank,
min(snapshot_date) dbt_valid_from,
max(snapshot_date) dbt_valid_to,
from member_with_rank
group by 1, 2
),
final as (
select
member_history.member_id,
member_master.member_status,
member_master.member_type,
generate_uuid() dbt_scd_id,
timestamp(member_history.dbt_valid_from) dbt_updated_at,
timestamp(member_history.dbt_valid_from) dbt_valid_from,
timestamp(if(dbt_valid_to = param.snapshot_date_end, null, date_add(dbt_valid_to, interval 1 day))) dbt_valid_to
from member_history, param
left join member_master
on member_history.member_id = member_master.member_id
and member_history.dbt_valid_from = member_master.snapshot_date
)
select * from final
結果はこちらです

実はちょっとdbt_scd_idが残念な感じではあります...
dbt snapshotを実行する
最後にdbt snapshotを実行して自分で用意したテーブルと世界線を融合させます。
結果がこちらになります
dbt_scd_idが少し残念ですね。

しかしほしいものは手に入りました。
これでdbtでスナップショットを撮っていく世界線に踏み出せますね。
Discussion
ああ、前のコメントは本質じゃなかったすね😅(混乱避けるため削除)
この方法は今まで撮り溜めたsnapshotをまとめてマージしようとする力作っすね。
1つづつ遡りながらマージしようとするのは大変なのかな🤔
タイムトラベルみたいな機能があればそれでいけるんですかね?
うちの環境だとそれがなかったので、お手製マイグレーションクエリで乗り切ることにしました!
なるほど🤔
後半の力作部分は、
snapshotデータを1日づつ分割できない(↓のような形)で固まってるデータに対して
dbtのsnapshotの仕組み:type-2 Slowly Changing Dimensionsを機能させる実装て感じすかね。いやあ、力作です🙏
同じようなbq運用されてる方は助かるんじゃないかな😇
Snowflakeの場合は、タイムトラベル機能でピンポイントな時間指定でデータ参照できるんで比較的シンプルに実装できそうっすね〜
(ただし期限内のみ)