🤖
RAG戦記:llama-indexで複数質問に強いRetrieverを作る
1. モチベーション
- 前回の記事でRAGの概念について導入した.本記事では
llama-indexの応用的な利用方法を学習するためにモジュールを切り出してスクラッチ実装に努める - (今になって)アニメ呪術廻戦にはまったので、呪術高専出身ばりの知識をもったRAGエンジンを構築したい
- シンプルRAGでは、複数の質問に同時に回答させるとベクトルの類似度検索にかかりづらくなるので、複数質問に
オタクのごとくぺらぺらと完答できるシステムが望ましい
2. 概要
2-1. SubQuestionQueryシステム
複数の同時質問に強いSubQuestionQueryでは、以下のステップでQueryを行う
-
Decompose:元の質問User queryを複数のサブ質問に分解
- 例) A会社の2021年から2023年までの売り上げは?
- A会社の2021年の売上を教えてください
- A会社の2022年の売上を教えてください
- A会社の2023年の売上を教えてください
- 例) A会社の2021年から2023年までの売り上げは?
- Vector Search:分解した複数の質問に対して、それぞれについてベクトル検索を行いノード取得
- Synthesize:取得したノードを全て使い回答を合成
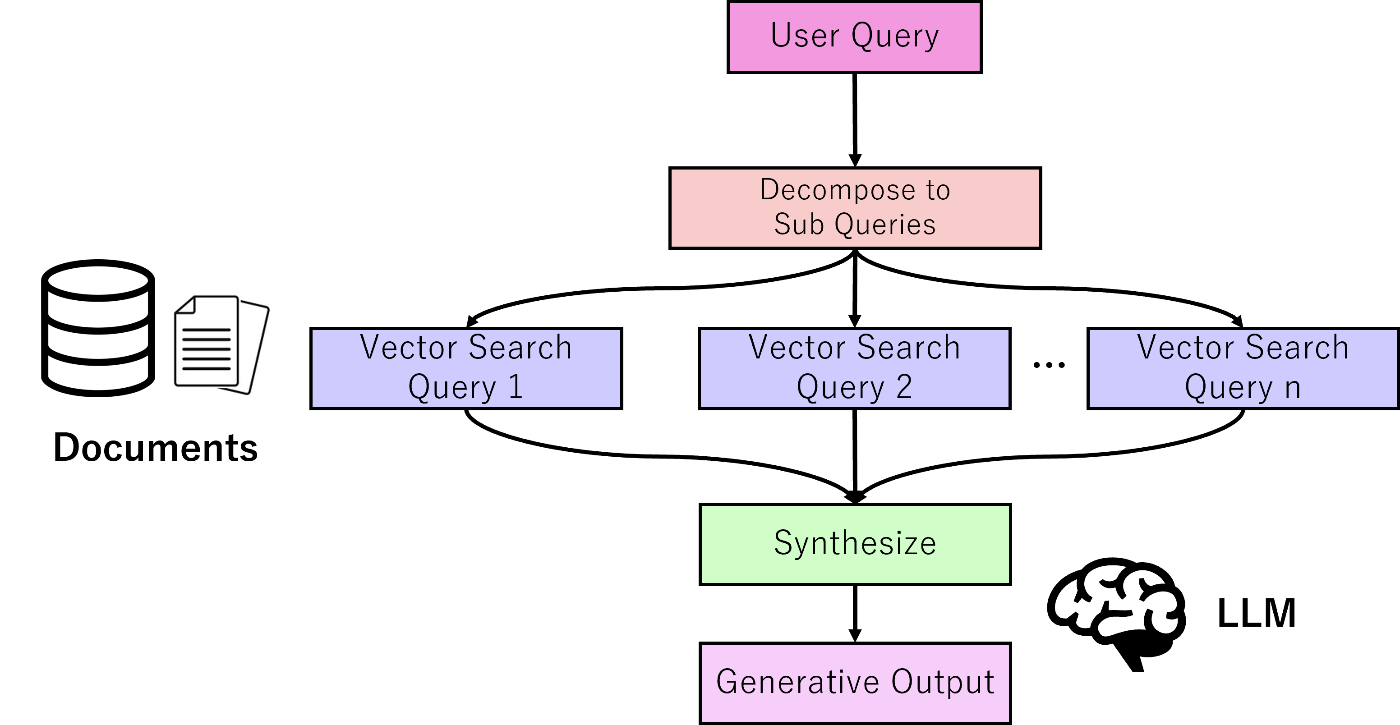
SubQの概要図
2-2. llama-index本家の実装
- 上述した内容を一気通貫で行う
QueryEngineはllama-index本家に既に存在する - 今回は自身の勉強のため、この本家実装を参考にしつつ、①Retrieverと②Synthesizerに分割する
3. 実装
3-1. サブ質問の管理クラス定義
必要なモジュール準備
subq_retriever.py
import asyncio
from typing import List, Optional, Sequence, cast
from llama_index.core.bridge.pydantic import BaseModel, Field
from llama_index.question_gen.openai import OpenAIQuestionGenerator
from llama_index.core.settings import (
Settings,
callback_manager_from_settings_or_context,
llm_from_settings_or_context,
)
from llama_index.core.retrievers import BaseRetriever
from llama_index.core.question_gen.types import BaseQuestionGenerator, SubQuestion
from llama_index.core.tools.query_engine import QueryEngineTool
from llama_index.core.llms.llm import LLM
from llama_index.core.service_context import ServiceContext
from llama_index.core.utils import get_color_mapping, print_text
from llama_index.core.async_utils import run_async_tasks
from llama_index.core.schema import NodeWithScore, QueryBundle, TextNode
- llama-indexで用意されている
BaseRetrieverを継承する形で構築 - まずはサブ質問の内容とその回答を保持するクラスから定義
- subq:分解されたサブ質問
- answer:それに対する回答
- sources:サブ質問に紐づくノード
subq_retriever.py
class SubQuestionAnswerPair(BaseModel):
"""
Pair of the sub question and optionally its answer (if its been answered yet).
"""
sub_q: SubQuestion
answer: Optional[str] = None
sources: List[NodeWithScore] = Field(default_factory=list)
3-2. Retriever構築
構築したクラスの全体プログラムは以下の通り
【SubQuestionRetrieverクラス全体】
subq_retriever.py
class SubQuestionRetriever(BaseRetriever):
def __init__(
self,
question_gen: BaseQuestionGenerator,
query_engine_tools: Sequence[QueryEngineTool],
verbose: bool = True,
) -> None:
self._question_gen = question_gen
self._metadatas = [x.metadata for x in query_engine_tools]
self._engine = query_engine_tools[0].query_engine
self._query_engines = {
tool.metadata.name: tool.query_engine for tool in query_engine_tools
}
self._verbose_subq = verbose
super().__init__()
@classmethod
def from_defaults(
cls,
query_engine_tools: Sequence[QueryEngineTool],
llm: Optional[LLM] = None,
question_gen: Optional[BaseQuestionGenerator] = None,
verbose: bool = True,
service_context: Optional[ServiceContext] = None,
):
llm = llm or llm_from_settings_or_context(Settings, service_context)
if question_gen is None:
question_gen = OpenAIQuestionGenerator.from_defaults(llm=llm)
return cls(
question_gen,
query_engine_tools,
verbose=verbose
)
def _retrieve(self, query_bundle: QueryBundle):
sub_questions = self._question_gen.generate(self._metadatas, query_bundle)
colors = get_color_mapping([str(i) for i in range(len(sub_questions))])
if self._verbose_subq:
print_text(f"Generated {len(sub_questions)} sub questions.\n")
tasks = [
self._aquery_subq(sub_q, color=colors[str(ind)])
for ind, sub_q in enumerate(sub_questions)
]
qa_pairs_all = run_async_tasks(tasks)
qa_pairs_all = cast(List[Optional[SubQuestionAnswerPair]], qa_pairs_all)
# filter out sub questions that failed
qa_pairs: List[SubQuestionAnswerPair] = list(filter(None, qa_pairs_all))
qa_nodes = [self._construct_node(pair) for pair in qa_pairs]
source_nodes = [node for qa_pair in qa_pairs for node in qa_pair.sources]
return qa_nodes + source_nodes
def _construct_node(self, qa_pair: SubQuestionAnswerPair) -> NodeWithScore:
node_text = (
f"Sub question: {qa_pair.sub_q.sub_question}"
f"\nResponse: {qa_pair.answer}"
)
node = NodeWithScore(node=TextNode(text=node_text))
node.metadata.update({"subq": True})
return node
async def _aquery_subq(
self, sub_q: SubQuestion, color: Optional[str] = None
) -> Optional[SubQuestionAnswerPair]:
try:
question = sub_q.sub_question
query_engine = self._query_engines.get(sub_q.tool_name, self._engine)
if self._verbose_subq:
print_text(f"[{sub_q.tool_name}] Q: {question}\n", color=color)
response = await query_engine.aquery(question)
response_text = str(response)
if self._verbose_subq:
print_text(f"[{sub_q.tool_name}] A: {response_text}\n", color=color)
qa_pair = SubQuestionAnswerPair(
sub_q=sub_q, answer=response_text, sources=response.source_nodes
)
return qa_pair
except ValueError:
return None
_retrieveメソッドのポイント
-
Decomposeステップ
- 元質問+メタデータから質問分解を行う
subq_retriever.py
sub_questions = self._question_gen.generate(self._metadatas, query_bundle)
-
Vector-Searchステップ
- 分解した各質問に対して回答とノードのペアを作る
subq_retriever.py
tasks = [
self._aquery_subq(sub_q, color=colors[str(ind)])
for ind, sub_q in enumerate(sub_questions)
]
- ノードの組み分け
-
qa_nodes:各サブ質問Qと一次回答Aのペアから成るノード -
source_nodes:各サブ質問に紐づいたオリジナルノード
-
subq_retriever.py
qa_nodes = [self._construct_node(pair) for pair in qa_pairs]
source_nodes = [node for qa_pair in qa_pairs for node in qa_pair.sources]
3. 実験
- 今回の実験では呪術廻戦Wikiを対象にする
- Wikiの内容に関しての質問を複数一括に投げて、それぞれに対して回答できるか確認
モジュールインポート
from llama_index.readers.wikipedia import WikipediaReader
from llama_index.core import SimpleDirectoryReader
from llama_index.core import VectorStoreIndex
from llama_index.core.tools import QueryEngineTool, ToolMetadata
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core import get_response_synthesizer
from llama_index.core import PromptTemplate
import os
os.environ["OPENAI_API_KEY"] = "<OpenAI_APIのトークン>"
3-1. 【前準備】クエリエンジンの構築
- ドキュメント読み込み + インデクシング
main.py
documents = WikipediaReader().load_data(pages=["呪術廻戦"], lang_prefix="ja")
index = VectorStoreIndex.from_documents(documents)
- QueryEngineの定義
日本語で回答できるようにプロンプトを定義
main.py
prompts = {
"llama_text-qa-ja": PromptTemplate((
"context情報は以下のとおりです。\n"
"---------------------\n"
"{context_str}\n"
"---------------------\n"
"context情報をもとに、事前知識を使わずにQueryに日本語で回答してください。\n"
"Query: {query_str}\n"
"Answer: "
)),
"llama_refine-ja": PromptTemplate((
"元の質問は次のように与えられる: {query_str}\n"
"既存の回答は次のように与えられる: {existing_answer}\n"
"以下のContextを元に、必要に応じて既存の回答を精緻化する機会があります。\n"
"------------\n"
"{context_msg}\n"
"------------\n"
"新しいContextを踏まえて、質問に対してより適切に答えるために元の回答"
"を日本語で精緻化してください。\nContextが役立たない場合は、元の回答を返してください。"
"Refined Answer: "
))
}
main.py
# QueryEngineのオブジェクト化
qengine = index.as_query_engine(
similarity_top_k=3,
text_qa_template=prompts.get( "llama_text-qa-ja"),
refine_tempalte=prompts.get("llama_refine-ja")
)
# metaデータ保持用 (構築したSubQuestionRetrieverで使う)
qengine_tools = [
QueryEngineTool(
query_engine=qengine,
metadata=ToolMetadata(
name="jujutsu-wiki",
description="呪術廻戦に関する情報が載ったwiki",
),
),
]
3-2. 【結果】単純なクエリエンジンでの検索結果
投げかけた質問は次の3つ
| Question | Answer (Ground truth) |
|---|---|
| この物語(呪術廻戦)の主人公は誰? | 虎杖悠仁 |
| 伏黒の領域展開の名前は何? | 嵌合暗翳庭(かんごうあんえいてい) |
| 五条悟の術式は? | 無下限呪術 |
まずはシンプルRAGでの回答を確認する.
main.py
question = """
この物語の主人公は誰?
伏黒の領域展開の名前は何?
五条悟の術式は?
"""
simple_rag_result = qengine.query(question)
print(str(simple_rag_result))
- 回答結果
この物語の主人公は釘崎野薔薇です。
伏黒の領域展開の名前は「嵌合暗翳庭(かんごうあんえいてい)」です。
五条悟の術式は「超人(コメディアン)」です。
釘崎ちゃんが主人公の世界戦...(個人的には見てみたいけど) SimpleRAGでは複数質問への回答は厳しそうです.
複数の質問を埋め込んで検索すると、必要なコンテキストがtop-3には現れてこないことに起因してそうなことを確認.
ノードの表示結果
main.py
from llama_index.core.response.notebook_utils import display_source_node
for node in simple_rag_result.source_nodes[:5]:
display_source_node(node)
Node ID: 18aacc2c-b962-42a7-978c-2ac1ba91de31
Similarity: 0.872646785749746
Text: 死滅回游では、左半身のみの衣服という特徴的なコスチュームで参戦している。 ギャグ漫画のような戦いをする。術式はウケると確信したことを実現させる「超人(コメディアン)」だが、自分の術式のことを何も...
Node ID: bf43f112-d9ed-4159-b5f8-911c16036520
Similarity: 0.8713647349765222
Text: 背後に法陣がついており、適応前に仕留めない限り、後ろの法陣が回ることで負傷を治癒し、それまでに喰らった攻撃への耐性が付与され、よりダメージが通りやすい攻撃をするようになる。また対呪霊に特化した特...
Node ID: ac1303e9-8d3e-4587-8c74-c4c2b3c42749
Similarity: 0.8712296149758573
Text: ==== 東京第1結界 ==== 日車 寛見(ひぐるま ひろみ) 死滅回游の参加者。参加結界は東京第1。 術師として覚醒したタイプ。本業は弁護士。36歳。 ボサボサした頭に三白眼、弁護士バッチを...
3-3. 【結果】SubQueryRetrieverでノード検索+回答
ノード検索
main.py
retriever = SubQuestionRetriever.from_defaults(qengine_tools, verbose=True)
nodes = retriever.retrieve(question)
分解された質問と回答のペアを確認できる

ノードの表示結果
main.py
for node in nodes[:5]:
display_source_node(node)
Node ID: 9a9f0afb-11e2-44e8-8e06-eb9b5e4e77a2
Similarity: None
Text: Sub question: この物語の主人公は誰? Response: 虎杖悠仁
Node ID: 28e6f202-c7e3-466e-a85a-746f3f42f2f2
Similarity: None
Text: Sub question: 伏黒の領域展開の名前は何? Response: 嵌合暗翳庭(かんごうあんえいてい)
Node ID: beee3a69-8468-4eee-9415-7070c98b5afd
Similarity: None
Text: Sub question: 五条悟の術式は? Response: 五条悟の術式は「無下限呪術」と呼ばれる術式です。
LLMによる回答
response_shnthesizerを用いてノードを合成し 回答生成.ノード内に一次回答が存在するので、合成しても答えられるはず...
main.py
synthesizer = get_response_synthesizer(response_mode="compact")
resp = synthesizer.synthesize(
query=question,
nodes=[node for node in nodes if "subq" in node.metadata],
additional_source_nodes=[node for node in nodes if "subq" not in node.metadata],
text_qa_template=prompts.get("llama_text-qa-ja"),
refine_template=prompts.get("llama_refine-ja")
)
print(str(resp))
- 回答結果
虎杖悠仁、嵌合暗翳庭(かんごうあんえいてい)、五条悟の術式は「無下限呪術」と呼ばれる術式です。
お、回答できてる!!!主人公も当てることができてます!
4. サマリ
- llama-indexの
BaseRetrieverを継承して、自分なりのRetrieverを構築できる - 本記事では「SubQuestionRetriever」を構築してみた
- 複数質問の同時回答が必要な場合は、質問を分割するタスクが刺さる
- 単純な質問に対してはSimple-RAGで十分
- ※ 本記事では意図的にSimple-RAGに不利な条件
similarity_top_k=3 (取得するノードの上位個数=3)に設定したが、このパラメータを増やせばContextが増えるためSimple-RAGでも回答可 -
qa_nodesに類似度スコアを割り当てないのは、質問①・質問②...と分割されたSubQuestionに順位をつけない(これらを合わせて一つの質問なので重みは等価)ため
Discussion