🧠
RAG(検索拡張生成)について
1. RAGってなぁに?
1-1. 概要
- GPTなどのLLMは事前知識が固定されており、学習した時点での情報しか持っていない
- LLMに外部データベースを接続させて、特定の専門知識に特化した回答をさせるシステムをRAG(検索拡張生成:Retrieval-Augmented Generation)と呼ぶ
- LLMを再学習させることなく、システムを構築させるだけで永続化できるためコスパ良
- 基本的には「独自の知識を持ったQA対応bot」を作成する代物

Userからの質問に外部DBを接続してLLMに回答させる概要図
1-2. メリット
- 外部DBを「プロダクトの仕様書」のように対応させれば、プロダクトに関しての知識を含有したChatBotが簡単に作成できる
- カスタマーサポートなどで、過去のQAをデータベース化しておけばオペレータからの回答時間を短縮できる
- 外部DBの情報を根拠に回答を生成するので、ハルシネーションを減らせる
2. RAGの詳細
2-1. 基本概念
- RAGは大きく分けて次の2つのステップから成る

ピンク矢印:Retrieval, 水色矢印:Generative
具体的には以下のステップを踏むことになる.
- ユーザーから投げられた質問をもとに、データストア(DB)に文書検索を行う.
- DBから関連したデータを取得して、ユーザーの質問と合体させてLLMに投げる
- 最後に投げられたプロンプトからLLMは回答を生成.
2-2. 【Retrieval】検索対象となるデータストアの事前準備
検索フェーズでは、事前に用意された対象のドキュメントから、ユーザーからの質問に関連する部分を抽出する.ただし、対象のドキュメントはデータ形式が様々(pdf, docx,...)であることが多いので、事前準備としてそれらのデータを検索可能な形式に変換する必要がある.
検索手法
前捌きとして、ひとえに「検索」といっても手法はいくつか存在するので、まずはその手法から紹介する.
A) ベクトル検索
- 元の質問をベクトル(数値の羅列)化して、数値的にどれくらい近いかの距離で検索する手法
- 事前に検索対象の文書と質問をEmbedding(検索空間へ数値列として埋め込み)を行う必要がある

埋め込みモデルを用いてテキストをベクトル化

GCPより引用
B) キーワード検索
- サイト内の検索と同様に、与えられたキーワードの出現頻度やレア度を元に検索を行う手法
- Web検索などはおおよそこの手法が使われる
- 通常BM25手法やTF-IDFスコアを基準にした検索手法が用いられる

ベクトル検索:データストアの構築手続き
上で紹介したベクトル検索手法では、事前に対象の文書を検索可能なベクトルの数値列に変換する必要がある。その手順はさらに細分化され、以下のようになる.
- Loading:対象のドキュメントファイル(pdf, html, docxなど)からテキストを抽出
-
Indexing:抽出したテキスト情報をLLMでも解釈できる文字数に分割し ベクトル化
- 分割したテキスト(Contextと呼ぶ) + メタ情報(ファイル名など)を合わせた構造化データの塊を
\textcolor{red}{ノード}
- 分割したテキスト(Contextと呼ぶ) + メタ情報(ファイル名など)を合わせた構造化データの塊を
- Storing:Indexingして構造化したデータを保存する
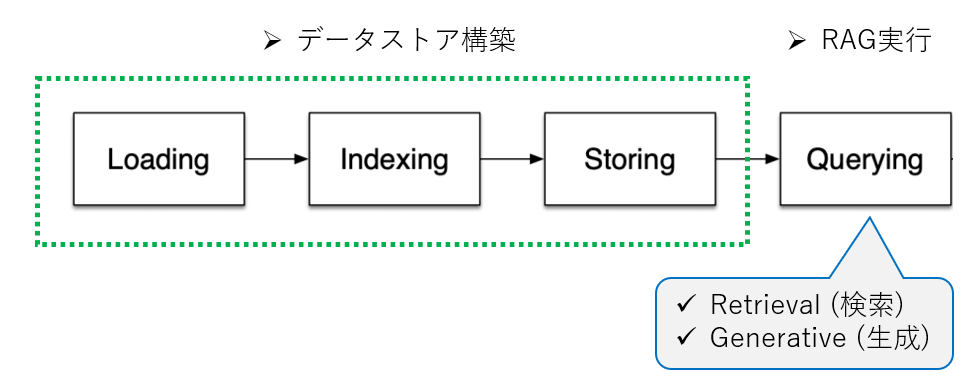
Llamaindexより引用.本家ではRAGのステップの最後に評価フェーズがあるがここでは割愛
2-3. 【Generative】検索された情報を元に回答を生成する手法
前節でベクトルDBから質問Qに関連するノードを取得する手順について説明した.Generativeステップでは、取得したノード情報を元にLLMで回答を生成する.一般に、全ノードを回答根拠にして一括にLLMに入力すると、文字数(正確にはトークン数)の制限により、LLMは回答できない。そこで、ノードに含まれるContext情報を一つ一つLLMにチェックさせ、質問に関連する文書だけを回答に反映させる手法が用いられる.
この節では簡単にその回答生成のアルゴリズムを紹介する.
Refine
- このアルゴリズムでは、LLMを繰り返し呼び出す.
- 1回目「QAプロンプト」:一つ目のノードから質問(図でいうQuery)に対する一次回答を得る
- 2回目以降「Refineプロンプト」:前回の回答・質問・ノード(Context)を用いて回答を改善
- 次点のノードが質問の回答根拠として役立つ場合 ⇒ 回答を更新・改善
- 次点のノードが質問の回答根拠として役立たない場合 ⇒ 元の回答を保持

Compact
- refineと同じだが、Contextを事前に連結しLLM呼び出しを少なくする
3. Llama-indexとの対応・実装
3-1. 文書の埋め込み
-
llama-index==0.10.17を用いた. - 事前にopenAIのAPIキーは発行しているものとする
前準備
import os
os.environ["OPENAI_API_KEY"] = "<OpenAI_APIのトークン>"
- Loading:文書からテキストを抽出して解析
from llama_index.core import SimpleDirectoryReader
# ドキュメント解析 (data/以下のテキストファイルを解析)
documents = SimpleDirectoryReader("data").load_data()
- Indexing:対象のドキュメントをインデックス化
from llama_index.core import VectorStoreIndex
# インデックス生成
index = VectorStoreIndex.from_documents(documents)
- Storing:インデックス化したノードをローカルに保存
# 保存
index.storage_context.persist(persist_dir="./storage_context")
# 次回以降読み出す場合
from llama_index.core import StorageContext, load_index_from_storage
storage_context = StorageContext.from_defaults(persist_dir="./storage_context")
index = load_index_from_storage(storage_context)
3-2. RAGの実行
- Retrieval(検索):保存したノードから質問Qに関連するノードを抽出
question = "このプロダクトの使い方は?"
retriever = index.as_retriever()
nodes = retriever.retrieve(question)
- Generative(生成):抽出したノードを元に回答を生成
from llama_index.core import get_response_synthesizer
# 回答の生成手法を指定
synthesizer = get_response_synthesizer(response_mode="refine")
# LLMを用いて取得したノードを合成 → 回答を生成
response = synthesizer.synthesize(query=question, nodes=nodes)
print(str(response))
(おまけ) Queryingを一括に行う
engine = index.as_query_engine()
response = engine.query("このプロダクトの使い方は?")
Discussion