【強化学習】Hindsight Experience Replay (HER)
0. はじめに
強化学習のExperience Replayに興味がありZennで論文調査などの記事を書いたり、Replay Bufferライブラリ cpprb を開発したりしています。
今回、前々から取り組もうと思いつつそのままになっていた論文の紹介と実装してみましたの記事です。
(cpprbのサイトのページの日本語焼き直しです。)
1. [論文紹介] Hindsight Experience Replay (HER)
M. Andrychowicz et al., "Hindsight Experience Replay", NeurIPS (2017) (arXiv:1707.01495)
1.1 前提
強化学習(のoff-policyな手法)では、遷移 (一般には
ゴール状態を目指すタイプの (goal orientedな) 環境の場合、最も単純な報酬設計はゴールに到達したら報酬、到達しなければ無報酬 (or 罰則) という2値報酬 (binary reward) が考えられると思います。もしゴールに到達するまでに多くのステップを踏む必要があるとすると、得られる遷移の殆どは一定の罰則しか持たず意味のある報酬を持つ遷移が稀になってしまい (sparse reward) 学習が困難になることが知られています。
勿論ゴールまでの距離など、意味のある情報を利用して報酬を設計するとより効率的に学習をすすめることができますが、環境によっては報酬設計が難しい場合もあるため、人為的な報酬設計を必要としない学習手法が待ち望まれていました。
1.2 提案手法
そこで著者らは、ゴールに到達していない『失敗した』エピソードからもうまく学習する Hindsight Experience Replay (HER)を提案しました。
コンセプトは簡単で、もしゴール
元の遷移:
追加遷移:
更に著者らは、各遷移に付け替えるゴールの選び方(strategy)として、以下のようなパターンを提案しました。(final以外はハイパーパラメータ
- final: エピソードの最終状態を利用
- future: 同一エピソードのより未来の状態から
k - episode: 同一エピソード内の状態から
k - random: 既に保存されているすべての状態から
k
またHERは遷移の水増しであり、既存のPER[1]と組み合わせて利用することもできることが言及されています。
1.3 実験
著者らは、物理シミュレータMuJoCoを利用して3種類のロボットアーム環境で実験をしています。以下に引用している図のとおり、いずれの環境でも (random strategy 以外の) HERを採用することで、タスクの成功率を向上させています。これらの環境では、future strategy の
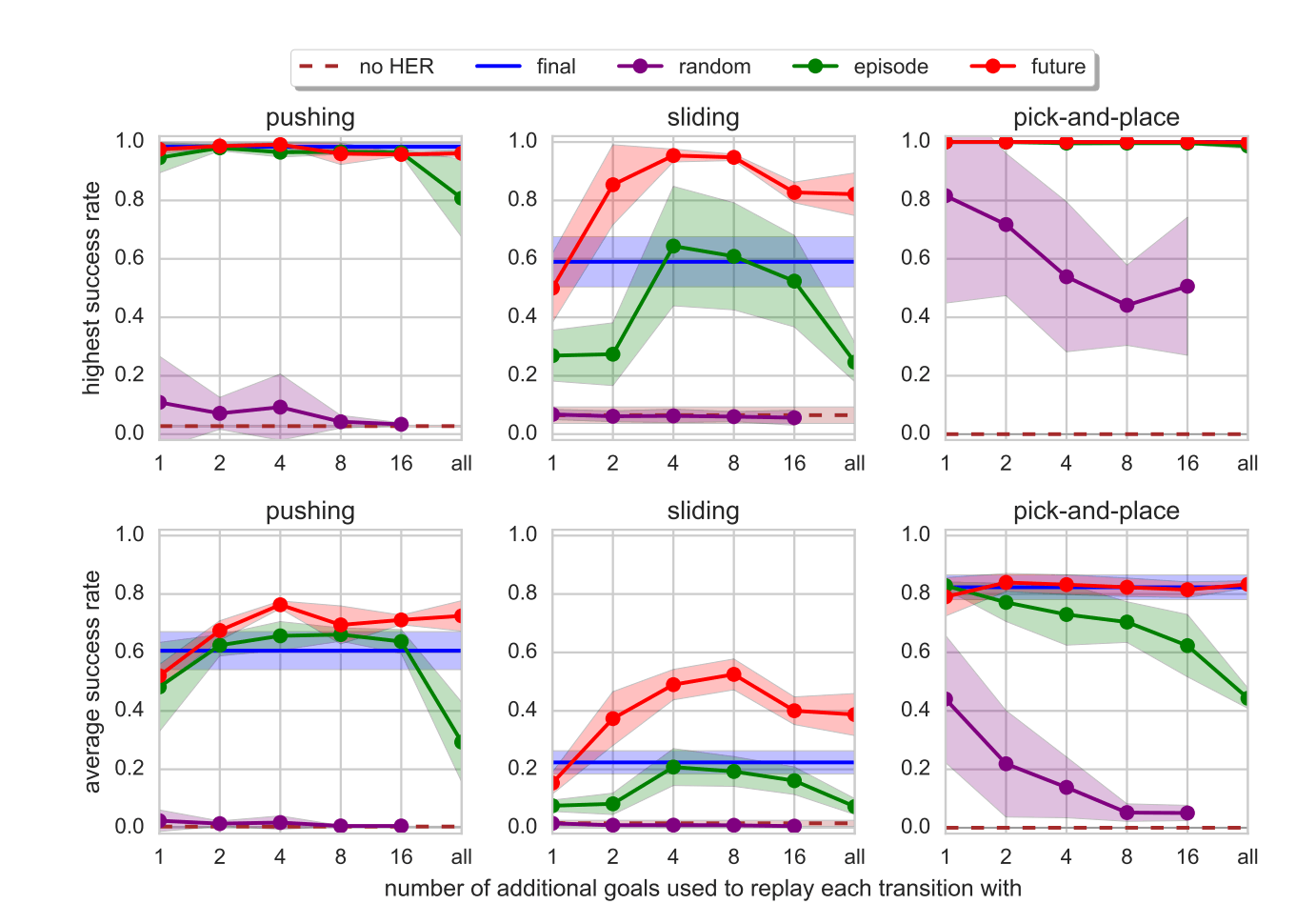
MuJoCoを利用した3つのロボットアーム環境でのstrategy比較(原論文より引用)
また、詳しくは原論文を見ていただきたいのですが、あえて人為的に報酬設計をするとHERでは性能が劣化しました。「成功か失敗かの判断と報酬関数の間に乖離がある」「下手な行動に対して罰則を与えるため探索を阻害する」等が理由ではないだろうかと推測しています。
1.4 まとめ
Hindsight Experience Replayによりゴールを付け替えた遷移を追加することで、疎な2値報酬からでも効率的に学習をできることがわかりました。
2. cpprbでの実装と利用方法
cpprbでは、HindsightReplayBufferクラスを新規に実装しました。(詳細)
簡単な利用方法は以下のようになります。
import cpprb
# Bufferの作成
# - ゴール付替後にrewardを計算し直す必要があるので、rewardを計算する関数(SxAxG -> R)を渡す
buffer_size = int(1e6)
her = cpprb.HindsightReplayBuffer(buffer_size,
{"obs": {}, "act": {}, "next_obs": {}},
max_episode_len = 100,
reward_func=lambda s,a,g: -1*(s!=g).any(axis=1),
state="obs", # 内部で報酬関数に渡すためにキーを指定
action="act", # 同上
next_state="next_obs", # 同上
strategy="future", # "future" or "episode" or "random" or "final"
additional_goals=4, # "final" strategyの際は無視される
prioritized=True) # PERを採用するかどうか
# Bufferへの追加 (他のReplay Bufferクラスと同様)
# - メインのReplay Bufferには反映されず、一旦現在のエピソード用のローカルバッファに入る
# - 最大エピソード長 (max_episode_len) 以上を追加しようとするとエラーになる
her.add(obs=0, act=1, next_obs=1)
# エピソード終端
# - 元々のゴールを渡す
# - エピソードがメインのReplay Bufferに反映される
# - strategy に従ってゴールを付け替え報酬を再計算した遷移も追加される
her.on_episode_end(goal)
# サンプル (他のReplay Bufferクラスと同様)
# - env_dict に指定したものに加え、"rew"、"goal" が追加される
batch_size = 32
sample = her.sample(batch_size)
obs = sample["obs"]
act = sample["act"]
next_obs = sample["next_obs"]
rew = sample["rew"]
goal = sample["goal"]
# PERが有効 (prioritized=True) の時
indexes = sample["indexes"]
weights = sample["weights"]
new_priorities = # |TD error|
her.update_priorities(indexes, new_priorities)
3. サンプルコード
単純で動作が分かりやすい環境として、上記論文のToy問題であるbit-flippingを実装してテストしました。
Nビットの状態があり、初期状態とゴールが無作為に選ばれ、1アクション毎に1ビットを反転させることで、ゴール状態を目指す環境です。Nが大きくなるほど、ゴールに到達して報酬を得られる確率が低くなり、HERを採用しないと学習が非効率的になることが指摘されています。
import os
import datetime
import numpy as np
import gym
from gym.spaces import Box, Discrete
import tensorflow as tf
from tensorflow.keras.models import Sequential, clone_model
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam
from tensorflow.summary import create_file_writer
from cpprb import HindsightReplayBuffer
class BitFlippingEnv(gym.Env):
"""
bit-flipping environment: https://arxiv.org/abs/1707.01495
* Environment has n-bit state.
* Initial state and goal state are randomly selected.
* Action is one of the 0, ..., n-1, which flips single bit
* Reward is 0 if state == goal, otherwise reward is -1. (Sparse Binary Reward)
Simple RL algorithms tend to fail for large ``n`` like ``n > 40``
"""
def __init__(self, n):
seeds = np.random.SeedSequence().spawn(3)
self.np_random = np.random.default_rng(seeds[0])
self.observation_space = Box(low=0, high=1, shape=(n,), dtype=int)
self.action_space = Discrete(n)
self.observation_space.seed(seeds[1].entropy)
self.action_space.seed(seeds[2].entropy)
def step(self, action):
action = int(action)
self.bit[action] = 1 - self.bit[action]
done = (self.bit == self.goal).all()
rew = 0 if done else -1
return self.bit.copy(), rew, done, {}
def reset(self):
self.bit = self.np_random.integers(low=0, high=1, size=self.action_space.n,
endpoint=True, dtype=int)
self.goal = self.np_random.integers(low=0, high=1, size=self.action_space.n,
endpoint=True, dtype=int)
return self.bit.copy()
gamma = 0.99
batch_size = 64
N_iteration = int(1.5e+4)
nwarmup = 100
target_update_freq = 1000
eval_freq = 100
egreedy = 0.1
max_episode_len = 100
nbit = 10
# Log
dir_name = datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
logdir = os.path.join("logs", dir_name)
writer = create_file_writer(logdir + "/metrics")
writer.set_as_default()
# Env
env = BitFlippingEnv(nbit)
eval_env = BitFlippingEnv(nbit)
model = Sequential([Dense(64,activation='relu',
input_shape=(env.observation_space.shape[0] * 2,)),
Dense(64,activation='relu'),
Dense(env.action_space.n)])
target_model = clone_model(model)
# Loss Function
@tf.function
def Huber_loss(absTD):
return tf.where(absTD > 1.0, absTD, tf.math.square(absTD))
@tf.function
def MSE(absTD):
return tf.math.square(absTD)
loss_func = Huber_loss
optimizer = Adam()
buffer_size = 1e+6
env_dict = {"obs":{"shape": env.observation_space.shape},
"act":{"shape": 1,"dtype": np.ubyte},
"next_obs": {"shape": env.observation_space.shape}}
discount = tf.constant(gamma)
# Prioritized Experience Replay: https://arxiv.org/abs/1511.05952
# See https://ymd_h.gitlab.io/cpprb/features/per/
prioritized = True
def reward_func(s, a, g):
r = -1*((s!=g).any(axis=1))
return r
# Hindsigh Experience Replay : https://arxiv.org/abs/1707.01495
# See https://ymd_h.gitlab.io/cpprb/features/her/
rb = HindsightReplayBuffer(buffer_size, env_dict,
max_episode_len = max_episode_len,
reward_func = reward_func,
prioritized = prioritized)
if prioritized:
# Beta linear annealing
beta = 0.4
beta_step = (1 - beta)/N_iteration
def sg(state, goal):
state = state.reshape((state.shape[0], -1))
goal = goal.reshape((goal.shape[0], -1))
return tf.constant(np.concatenate((state, goal), axis=1), dtype=tf.float32)
@tf.function
def Q_func(model,obs,act,act_shape):
return tf.reduce_sum(model(obs) * tf.one_hot(act,depth=act_shape), axis=1)
@tf.function
def DQN_target_func(model,target,next_obs,rew,done,gamma,act_shape):
return gamma*tf.reduce_max(target(next_obs),axis=1)*(1.0-done) + rew
@tf.function
def Double_DQN_target_func(model,target,next_obs,rew,done,gamma,act_shape):
"""
Double DQN: https://arxiv.org/abs/1509.06461
"""
act = tf.math.argmax(model(next_obs),axis=1)
return gamma*tf.reduce_sum(target(next_obs)*tf.one_hot(act,depth=act_shape), axis=1)*(1.0-done) + rew
target_func = Double_DQN_target_func
def evaluate(model,env):
obs = env.reset()
goal = env.goal.copy().reshape((1, -1))
n_episode = 20
i_episode = 0
success = 0
ep = 0
while i_episode < n_episode:
Q = tf.squeeze(model(sg(obs.reshape((1, -1)), goal)))
act = np.argmax(Q)
obs, _, done, _ = env.step(act)
ep += 1
if done or (ep >= max_episode_len):
if done:
success += 1
obs = env.reset()
goal = env.goal.copy().reshape((1, -1))
i_episode += 1
ep = 0
return success / n_episode
# Start Experiment
n_episode = 0
obs = env.reset()
goal = env.goal.copy().reshape((1, -1))
ep = 0
for n_step in range(N_iteration):
if np.random.rand() < egreedy:
act = env.action_space.sample()
else:
Q = tf.squeeze(model(sg(obs.reshape(1, -1), goal)))
act = np.argmax(Q)
next_obs, _, done, info = env.step(act)
ep += 1
rb.add(obs=obs,
act=act,
next_obs=next_obs)
if done or (ep >= max_episode_len):
obs = env.reset()
goal = env.goal.copy().reshape((1, -1))
rb.on_episode_end(goal)
n_episode += 1
ep = 0
else:
obs = next_obs
if rb.get_stored_size() < nwarmup:
continue
if prioritized:
sample = rb.sample(batch_size, beta=beta)
beta += beta_step
else:
sample = rb.sample(batch_size)
weights = sample["weights"].ravel() if prioritized else tf.constant(1.0)
with tf.GradientTape() as tape:
tape.watch(model.trainable_weights)
Q = Q_func(model,
sg(sample["obs"], sample["goal"]),
tf.constant(sample["act"].ravel()),
tf.constant(env.action_space.n))
sample_rew = tf.constant(sample["rew"].ravel())
sample_done = (1.0 + sample_rew) # rew = 0 -> done = 1, rew = -1 -> done = 0
target_Q = tf.stop_gradient(target_func(model,target_model,
sg(sample["next_obs"],sample["goal"]),
sample_rew,
sample_done,
discount,
tf.constant(env.action_space.n)))
absTD = tf.math.abs(target_Q - Q)
loss = tf.reduce_mean(loss_func(absTD)*weights)
grad = tape.gradient(loss, model.trainable_weights)
optimizer.apply_gradients(zip(grad, model.trainable_weights))
tf.summary.scalar("Loss vs training step", data=loss, step=n_step)
if prioritized:
Q = Q_func(model,
sg(sample["obs"], sample["goal"]),
tf.constant(sample["act"].ravel()),
tf.constant(env.action_space.n))
absTD = tf.math.abs(target_Q - Q)
rb.update_priorities(sample["indexes"], absTD)
if n_step % target_update_freq == 0:
target_model.set_weights(model.get_weights())
if n_step % eval_freq == eval_freq-1:
eval_rew = evaluate(model, eval_env)
tf.summary.scalar("success rate vs training step",
data=eval_rew, step=n_step)

100ステップ毎の成功率(20回中の成功率)の推移。学習自体を5回実施
(ここでは割と簡単なN=10でテストしたので、HERがなくても学習できたかもしれませんが、) 5回学習させいずれの試行でもゴールに到達した比率が1に収束しました。
※ 余談ですが、OpenAI Gym からもHER向けの(MuJoCoを利用した)環境が提供されています。使い方が少し特殊で分からなかったので避けましたが、以下に説明のページがあることを後から見つけました。(goal はobsの中に入っていたのですね。)
4. おわりに
ゴールを目指す疎な2値報酬の環境において効率的に学習を行うHindsight Experience Replay (HER)論文を読んで、自作のReplay Bufferライブラリcpprbに実装をし紹介記事を書きました。
興味を持ってくれた人がいれば、cpprbを使ってもらえると私が喜びます。
また、質問・要望・バグ報告などがあればGitHub Discussionsにいつでも書き込んでいただいて構いません。
Discussion