歌え!GPT。text LMによるアドリブ生成手法(弁財天アプローチ解説1)


この記事は何?誰向け?
- 弁財天というAIによるアドリブ生成コンテストの自分のベースラインモデルの手法を共有している
- GPT-3とabc記法によるコードからのアドリブ生成。
- 割とベースラインとしてはそこそこのものができた。
- ただしお金がかかりすぎるので、結局イテレーションを回すのに向かなかった。
基本的には音楽生成に興味がある方や弁財天に参加したい方向けです。
ちなみにこちらのChatGPT meetupでのLTの前半部分の行間を解説したものになります。こっちはLLMやGPT系に興味ある方向けです。
(LTなので結構砕けたスタイルにしていますが・・・)
また最終的なモデルが生成したアドリブはこちらにまとめています。
https://zenn.dev/yatszhash/articles/35045e02b748b9
手法Summary
- GPT-3とabc記法によるコードからのアドリブ生成。
- GPT-3をコード8小節とメロディー8小節のペアでfine-tuningする。
- 楽譜(musicXML)を以下の手順でtextのデータセットに変換する。
- 楽譜を8小節ごとに分割。
- メロディーとコードに分割。
- コードは構成音と長さに対応する音符に変換。
- abc形式へ変換。
- 前処理でキーを統一するなどしてタスクの難易度を下げる。
Introduction
本当に今更ですが、2月に弁財天というAIによるアドリブ生成コンテストに参加していました。
自分がそこで行ったLMを使ったアドリブ生成手法を公開していきます。
なぜこの旬もとっくに過ぎたタイミングに、winner’sでもない解法をくどくど書いて公開するのかというと、以下の理由からです。
- ChatGPTやGPT-4などLLMによるコンテンツ生成が非常に盛り上がっており、 手法を共有しとくと誰かの役に立ちそうだから。
あとやってみたブログのネタ潰し - あと第2回が10月にあるので、参考にして次回の参加者にもっとブラッシュアップした手法を提案してほしいとの想いがあるため。
あと絶対受けを狙ってLLMでやりたい勢が出るだろうからもう似たような手法は既出だよと牽制 - 完全に個人的な思いですが、テキスト縛りで音楽生成でここまでいけるんだっていうのを共有したかった。(今回のすごく限定されたルールでは、ベースラインのmagentaのimmprovisation RNNよりもよかったかもしれない。)
弁財天とは?
Music x Analytics Meetupというコミュニティが主催する
“AIミュージックバトル!『弁財天』は「伴奏」から
「アドリブメロディ」をAIで生成し
「どれだけイケてるメロディか」を競うAI自動作曲コンテストです。”
(公式サイトより引用/改変)
その場で運営からお題のコード進行と伴奏が与えられ、
メロディー部分をAIに生成させます。
複数のメロディー候補を生成させて、人の耳で選ぶことも許されています。
(ただし制限時間が数分と短いので、大量に生成して選ぶといったアプローチは難しい。)

例えば
予選で使われた伴奏音源の一つは
(コード進行は画像の通り)
で自分がモデルによって生成したメロディーを付与した音源がこちらになります。(GPT-3ではなく別のLMを使ったもの。)
textのLMで音楽をやる難しさ
GPT-3やChatGPT、あるいはそれ類する自然言語textのLMは、inputをtextにさえすれば、比較的幅広いタスクをこなすことができます。
しかし、音楽の生成をやる上で結構な弱点があります。
例えば
- 四則演算など数値・量の扱いが苦手。([Dyer et.al., 2022], [Schick et.al., 2023])
- 4/4なのに、1小節に4拍子分の音符や休符をいれてくれるとは限らない。
- (実際1小節に4拍子分未満/より多い音符が入ることはよくあった。)
- tokenおよびそのembeddingが音楽用ではない。
- subtokenが一般ドメイン用であるため、分かれ方が音楽的にナンセンスな可能性がある。
- 例えばABC(ラシド)とあったときに、音楽的に意味がある音符単位で
- ”A” “B” “C”
- と分かれるとは限らず、
- ”AB” “C”とか
- ”ABC”
- みたいな分かれ方になる可能性がある。
- 例えばABC(ラシド)とあったときに、音楽的に意味がある音符単位で
- token間の音楽的な関係がうまくembeddingに反映されるとは限らない。
- 例えばA(ラ)とB(シ)が全音違うといったことや、コードのAmの構成音を学習できるかが怪しい。
- subtokenが一般ドメイン用であるため、分かれ方が音楽的にナンセンスな可能性がある。
- 決まったルールがあるフォーマットを出力するのもLMだと保証されない。
- 楽譜などはルールがある。
- ルール化された出力を確実に出力させるのが難しい。
- (実際今回も最後まで苦しんだ。不正な形式しか出ないinputがあったり。)
- (とはいえプログラミングのコード生成は割とうまくいくことが多いので、学習量次第で改善する気もしなくもない。)
- そもそも事前学習のコーパスに歌詞以外の音楽のデータがそんなに入ってなさそう。
と言った点が挙げられます。
まあコンテストに勝つことを考えれば、手法として選ばないでしょう。
textのLMのアプローチをとった理由
それではなぜLLMのアプローチをとったか?
「話題性のあるLMとテキストで縛って、割とイケてるメロディーを生成してどやりってみたかった。」
半分ネタづくりのために途中まではやっていた
(なお、全く賭けだったわけではなく、弁財天のルール的にかなり制約を設けて自由度を落としていたところを考慮にいれています。例えば
- キーがCかAm固定
- 音楽生成にしては短い8小節のみの生成
と言った点です。
)
今回作成したアドリブ生成AI
今回作成したシステムの概要図です。

このシステムの以下のようなポイントを解説していきます。
- 入出力形式
- 学習用データセットの作り方
- モデル(GPTのケースのみ今回)
- 後処理(次回)
- 評価(次回)
入出力形式
形式
プログラムが音楽を入出力するための表現として、さまざまな形式があります。
例
- 波形
- ピアノロール
- midi
- 楽譜(今回利用)
今回は楽譜を入出力にすることにしました。
入手できるデータセットの量は圧倒的に波形(mp3含む)やmidi(やそれらを変換して得られるピアノロール)の形式が多いです。
しかし、実際の演奏データのmidiやmp3などの音源を利用すると、人の演奏による揺らぎやズレまで学習してしまい、リズムとのずれが大きくなるかなーと思ったためです。
(後でも触れていますが、リズムを抽出してモデルに入力するのが難しい。)
加えてたとえ波形を出力しても、提出用にクリーンなmidiにするのが難しいです。
(”music transcription”というタスクとして、研究はあるので試しましたが、厳しかったです。例えば)
“楽譜”をテキストで表す
楽譜をtextで表現する方法はいくつかあります。
電子楽譜のデータ構造として一番普及しているのはmusic XMLでしょう。
とはいえ、XMLは構造が複雑で短い曲でもテキスト長が大きくなってしまいます。モデルが整合性をたもったまま何小節分も生成できる気がしません。そもそもLMのinputの長さ制限をオーバーしてしまう可能性があります。
よりシンプルな方法があればそちらの方がLMも学習/生成しやすそうです。
幸いなことに、楽譜をアルファベット、数字、記号で表す方法として、ABC記譜法という既に確立された表現方法があります。特に伝統音楽、民族音楽などオープンな音楽ソースはこの形式でメロディーがweb上で配布されていることがあります。
簡単にいうと、abc記譜法ではアルファベットが音符の音程を表していて、その後の数字が音符の長さを表しています。zは休符です。
(ABCDEFGはラシドレミファソに対応します。)
日本語wikiから引用すると例えばソーラン節なら
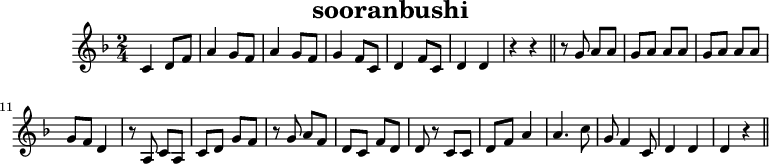
X:1
T:sooranbushi
M:2/4
L:1/8
K:F
C2 DF | A2 GF | A2 GF | G2 FC | D2 FC | D2 D2 | z2 z2 ||
zG AA | GA AA | GA AA | GF D2 | zA, CA, | CD GF | zG AF | DC FD | D z CC |
DF A2| A3 c | G F2 C | D2 D2 | D2 z2||
のように表現されます。
ちなみにこれをmusicXMLで表すと
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE score-partwise PUBLIC "-//Recordare//DTD MusicXML 3.1 Partwise//EN" "http://www.musicxml.org/dtds/partwise.dtd">
<score-partwise version="3.1">
<work>
<work-title>sooranbushi</work-title>
</work>
<movement-title>sooranbushi</movement-title>
<identification>
<creator type="composer">Music21</creator>
<encoding>
<encoding-date>2023-03-11</encoding-date>
<software>music21 v.8.1.0</software>
</encoding>
<miscellaneous>
<miscellaneous-field name="humdrum:ONM">1</miscellaneous-field>
</miscellaneous>
</identification>
<defaults>
<scaling>
<millimeters>7</millimeters>
<tenths>40</tenths>
</scaling>
</defaults>
<part-list>
<score-part id="P6fc8c7e41cf93a14ac7ecb9c23626c42">
<part-name />
</score-part>
</part-list>
<!--=========================== Part 1 ===========================-->
<part id="P6fc8c7e41cf93a14ac7ecb9c23626c42">
<!--========================= Measure 0 ==========================-->
<measure number="0">
<attributes>
<divisions>10080</divisions>
<key>
<fifths>-1</fifths>
<mode>major</mode>
</key>
<time>
<beats>2</beats>
<beat-type>4</beat-type>
</time>
<clef>
<sign>G</sign>
<line>2</line>
</clef>
</attributes>
<note>
<pitch>
<step>C</step>
<octave>4</octave>
</pitch>
<duration>10080</duration>
<type>quarter</type>
</note>
<note>
<pitch>
<step>D</step>
<octave>4</octave>
</pitch>
<duration>5040</duration>
<type>eighth</type>
<stem>up</stem>
<beam number="1">begin</beam>
</note>
<note>
<pitch>
<step>F</step>
<octave>4</octave>
</pitch>
<duration>5040</duration>
<type>eighth</type>
<stem>up</stem>
<beam number="1">end</beam>
</note>
</measure>
<!-- 18小節分省略 -->
<!--========================= Measure 20 =========================-->
<measure number="20">
<note>
<pitch>
<step>D</step>
<octave>4</octave>
</pitch>
<duration>10080</duration>
<type>quarter</type>
</note>
<note>
<rest />
<duration>10080</duration>
<type>quarter</type>
</note>
<barline location="right">
<bar-style>light-light</bar-style>
</barline>
</measure>
</part>
</score-partwise>
というふうに改行があるとはいえなかなかな長さになります。もちろんその分リッチな情報は表せるのですが、今回のコンテストではそこまで表現力が必要がありません。
そのシンプル性とデータの入手しやすさから、textによる音楽生成の先行研究や記事ではabc記譜法が使われていることがよくありますので今回もabc記譜法を採用しました。
(とはいえ振り返れば、XMLそのものはLLMの学習データに入っている気がするので、一度ぐらいは試してもよかったですね。)
学習用データセットの作り方
作成手順
今回モデルは
- input(prompt) コード進行
から
- ラベル(completion) メロディー
を生成できるように学習させます。
そのために、学習用のデータセットのコードとメロディーのペアは以下のように作成しました。
- ソース楽譜を前処理
- 8小節に分割
- メロディーとコードに変換する。
- コードを構成音に変換
- musicXMLからabcに変換
ソースのコーパス
今回のコンテストで重要なポイントの一つは、データセットが指定されていない点です。
参考データセットとして、ジャズのアドリブのデータセット Charlie Parker's Omnibook は与えられているものの、
残念ながら50曲分でしかもjazzかつ一人のプレイヤー(チャーリー・パーカー)のものしかありません。
いくらGPT-3が賢い(?)といえど、モデルを学習させるにはサイズ、バリエーションともに心もとないです。
追加のアドリブメロディーとコードのデータセットを自分で探してくる必要がありますが、
残念ながら今回のコンテストに合う”アドリブ(インプロビゼーション)”のデータセットはすぐには見つけられませんでした。
代わりに利用したのは、一般的な歌曲や器楽曲の楽譜です(ジャズならアレンジ前のテーマ部分)。
音楽生成系の先行研究をたどると、
- OpenEWLD (musicXML) (Wikifoniaのサブセット)
という著作権フリーな歌曲や器楽曲のmusicXMLがよく使われているので、そちらをCharlie Parker's Omnibook に加えて利用することとしました。
8小節単位に抽出
弁財天のルールではアドリブ生成は
- 8小節分のコード
から
- 8小節分のメロディ
を生成するタスクと解釈できます。(ただしending(outro)も生成OKであり、その部分まで含むと、9~10小節分)
(これに加えて、伴奏の演奏が入ったmidiも与えられます。この複数の楽器が入ったの活用は先行研究を見てもかなり難しそうなため今回は無視しました。実際他の本選出場者の中でも一部リズムを利用している方がいるだけでした。)
8小節しか必要ないなら9小節以上ある曲を学習させても時間がかかる上難易度が上がるだけで意味がなさそうです。
とはいえ、都合よく8小節分しかない曲はほとんど存在しません。
そのため、1曲から8小節分を4小節ずつスライドさせながら切り出し、擬似的に8小節分の曲を作成するようにしました。
スライドさせるのが4小節単位なのは、だいたい4/4なら4小節ずつぐらいでメロディーがまとまり区切れることが多いためです。もっといえば8小節ずつのほうがメロディーのまとまりが良いのですが、データを増やしたかったため4小節ずつずらしていっています。
アウフタクトがあるとずれてしまうのですが、今回そこの処理はさぼっています。
Gershweinの‘S Wonderfulの例(CY00ライセンス)

コード進行の与え方
コード情報を削除してメロディだけを抽出するのは簡単です。
- コードの並びだけ (例えばAm C | A D | G7 C )だと、コードが変わるタイミングが正確にわからない。(というかabcとして不正)
- メロディーは削除されるので、メロディーの音符の上にコードをつけたりできない。
- (今回本番ではコードは短くとも2拍ごとにしか変わらないという制約があったので推論時に限るともっとラフに表現することはできます。とはいえ、学習データには2拍より短いコードチェンジも含まれているので、結局細かな表現が必要になります。)
一方コード進行の与え方には、色々な方法があります。
与え方の主なポイントは以下の2点です。
- コードをどのように表現するか?
- コードの長さ(変わるタイミング)をどのように表現するか?
コードをどのように表現するか?
通常楽譜ではコードはコードネームとして、小節の上に記号が付与されることで
コードネームは楽譜上(musicXML)では

のように与えられています。(Gershweinの‘S Wonderfulから引用。転調済み)
abc 記譜法でも同様にコードネームは表現することができます。(””の部分)
"C" G3/2 G/ E2- | E4 |"C#dim" G3/2 G/ E2- | E4
しかしCがC,E,G(ドミソ)、C#dimが^C,E,Gという3つの音から成るという知識はGPT-3は持っていないと思われます。
メロディーの音とコードの構成音の対応を学習してほしいなら、暗黙的にコードの構成音の学習を頑張らせるより、明示的に構成音を与えてしまって学習させた方が良さそうです。
もう一つコードネームで学習してしまうと、学習データにないコードネームが現れたときの挙動に不安があります。例えば、"Caug"というのが学習データに含まれていないのにも関わらず出てきたとき、”aug”部分をどのように解釈するのかわからないためです。構成音を与えた場合も未知の音の組み合わせにどう対処するかわからない部分はありますが、若干マシかと考えました。
そこで構成音に置き換えることにしました。 ちなみに実際コードネームで与えるのも試しましたが、結果が悪かったです。
(余談ですが、ChatGPTはCやC#dimの構成音を知っているので、GPT-3も知っているかもしれません。)

コードの長さ(変わるタイミング)をどのように表現するか?
コードの並びだけ (例えばAm C | A D | G7 C )だと、コードが変わるタイミングが正確にわかりません。今回本番ではコードは多くとも2拍ごとにしか変わらないという制約があったものの、学習データには2拍分より短いコードも含まれており、細かな表現が必要になります。
幸い今回はすでにコードは構成音で置き換えるので、コードが続く長さは構成音の音符の長さで表現できます。
最終的にコードとメロディーは

コードのabc
X:1
L:1/4
M:4/4
K:C
V:1
[D,F,A,=C]4 | [D,F,A,=C]2 [G,,B,,D,F,]2 | [C,E,G,]4 | [D,,^F,,A,,C,E,]3 [G,,B,,_D,=F,] |$ %4
[G,,B,,_D,=F,]4 | [G,,B,,_D,=F,]4 | [^C,E,G,]4 | [^C,E,G,]4 | %8
メロディーのabc
X:1
L:1/4
M:4/4
K:C
V:1
G3/2 G/ E2- | E2 G2 | =C4- | C3 z | G3/2 G/ E2- | E4 | G3/2 G/ E2- | E4 | %8
のように表現されます。
前処理
前述したようにtextのLMで音楽をやるのはLMの性質上難しいです。そのため、タスクの難易度を少しでも下げるため、以下の前処理を行いました。
- 曲のキーをCまたはAmにすべて移調する。
- ルール上与えられる曲はCまたはAm
- モデルが暗にキーの判定をする必要がなくなる。
- キーを条件としてinputに与える手もあるが、12種類のキーに対して、コードとキーの関係をモデルが学習する難しい。
- 本番のデータと同じキーの学習データの量もかせげる。
- 4/4のものだけ残す
- ルール上4/4しか与えられない。
- こちらも固定しておかないと、
- 拍子記号によって小節に入る拍子分が変わるので、モデルがそこを暗に計算する必要がでてくる。
- abcにおける音の流さの表現も変わってしまう。(ベースの音符の長さによって4/4ならAは4分音符の一方、1/3なら)
- 不正なmusicXMLが入っているため、そのようなものは除外。
- musicXMLからmusic21読み込む際やabcに変換される際にエラーが出るためほぼ半自動的に除外。
- 当然タイトル、歌手、コメントや歌詞といった余計な条件付けにつながりそうな情報はinput/target双方から削除。
- (逆に例えば曲名などでtextで音楽の生成を条件付けに使うこともできるが、コントロールが難しそうなので除外。)
モデル
元々のモチベーションからして、 モデルはGPT-3を選択します。
GPT-3の学習方法
GPT-3を利用する際、
- in-context learning(パラメータの更新を行わない)
- fine-tuning (パラメータの更新を行う)
の2つの選択肢があります。
in-context learning + few-shot learningは以下の理由から難しそうでした。
- abcにしたとしても1曲あたりのテキストが長い。
- 単純に8小節のパートを数例入れたぐらいではパターンを抽出出来なさそう。
- 少なくとも例と推論したいコード進行が似ている例を抽出するなど別のロジックが必要になりそう。
- そもそもLMの学習データにabcがそんなに入ってなさそう。
そのため、今回はfine-tuningしか行っていません。
fine-tuningの設定は
- モデルはcurie
- 4~5 epochs
- ハイパーパラメータは一旦デフォルトのまま。
で行いました。
GPT-3のapiで使ったjsonlはこんな感じになりました。
{"prompt": "[C,E,G,]4 | z2 [F,_A,CD]2 | [C,E,G,]4 | [G,,B,,D,F,]4 | [C,E,G,]2 [A,,,D,,E,,^G,]2 [E,A,C] | $ [D=GB]3 [D,^F,A,C] | [G,,B,,D,=F,]2 [C,E,G,A,]2 [C,E,G,A,] | [G,B,D]3 [C,E,G,] | $ z2 [G,,B,,D,F,A,]2 | [C,E,G,]4 | $ <song>", "completion": " e3 d/>c/ | B d f a | g e d c | B d B A | G (3A/A/A/ B (3A/A/A/ | B g g e/>f/ | g e a f | $ g e2 c/d/ | $ <end>"}
{"prompt": "[C,E,G,_B,]4 | [G,,=B,,D,F,]4 | [G,,B,,D,F,]4 | [C,E,G,_B,]4 | [C,E,G,_B,]4 | [G,,=B,,D,F,]4 | $ [G,,B,,D,F,]2 [E,^G,B,D]2 | [A,,C,E,]4 | [D,^F,A,C]4 | [G,,B,,D,=F,]4 | $ <song>", "completion": " z4 | z z/ d/ g/d/4c/4 _B/G/- | G g/d/4c/4 _B/E/- E | z z/ ^F/ (3G/B/d/ ^f/e/- | $ e (3d/4e/4d/4c/ B/A/^G/B/ | A/e/ (3c/4d/4c/4A/ ^G/E/C/A,/ | =G/=F/^F/d/ z z/ c/ | $ B/d/d/d/ c/B/G/D/ | $ <end>"}
(以下省略)
GPT-3での生成結果
一部の学習データを使って、試しにtrainしたモデルの生成結果です。
temperature=0.75で生成しています。
生成例1
生成例2
単調なものの、ベースラインとしては悪くなさそうです。
致命的な欠点
GPT-3でのアプローチを続けたかったのですが、
このアプローチ致命的な欠点がありました。
それはイテレーション毎に結構なお金がかかるということです。

さらに、性能がよくて有望そうなDavinchiはこれの10倍かかります。(だれかリッチな人やって欲しい。)
Colab Pro(現在1,179円/月)やPro+(現在5,767円/月)の比ではありません。
マネーの力を持たない貧弱な自分はここで暗礁に乗り上げてしまいます。
結び
せっかくGPT-3で良さげなベースラインモデルができたのに、マネーパワーが足りずこのままではイテレーションが回せません。では代わりにどのように暗礁から脱出したのか。第2回に続く・・・・
第2回では、加えて後処理の方法
- 不正なフォーマットが出た時の対応
- 全音符や2分音符などが出がちだが、音をアドリブっぽく細かく動かす方法
- 音が伴奏に埋もれて目立たない問題。
など他の弱点への対策も併せて触れる予定です。
(参考)text出力による音楽生成の先行研究
アドリブ生成だabcやtextの出力を使った研究を今の所見つけられていません。
しかし、textから音楽を生成する”TextToMusic”というタスクがあります。
(最近話題になった研究だとfacebookのMusicGenやGoogleのMusicLMなど)
そのタスクでは、abcを出力に利用した先行研究は査読有無かかわらず結構あります。
例
- GPT-2を使ったもの
- BARTやGPT-2を使ったもの
中でもmediumにGPT-3で作曲を試みた記事があり、今回の手法はこちらをかなり参考にしています。
https://towardsdatascience.com/ai-tunes-creating-new-songs-with-artificial-intelligence-4fb383218146
https://github.com/robgon-art/ai-tunes
これはバンドの名前と曲名をpromptとして与えて、音楽のメロディーとコードをテキストで生成するシステムです。

(https://towardsdatascience.com/ai-tunes-creating-new-songs-with-artificial-intelligence-4fb383218146 より引用)
Discussion