DeepSpeedはなぜ速いのか〜推論編〜
はじめに
昨今、ChatGPTに代表されるように、LLM(大規模言語モデル)が大きな盛り上がりを見せています。
本記事では、LLMの学習や推論を高速化するためのライブラリであるDeepSpeedが、どのようにしてその高速化を達成しているのかを解説します。
DeepSpeedの理論部分、特に推論について日本語で解説している記事があまりなかったため、今回執筆することにしました。
この記事を読んで欲しい人
- DeepSpeedでなぜ推論が速くなるのかを知りたい人
- DeepSpeedを使って手元の推論時間を短縮したい人
DeepSpeedとは
DeepSpeedは、Microsoftから発表されている学習や推論の高速化、圧縮などを扱うライブラリです。本記事では、特に推論の高速化について解説します。推論高速化のためのサービスとしては、他にもvLLMやTGI、Together Inference Engineやgroqなどがあります。
DeepSpeedからはさまざまなサービスが提供されているため、本章で各サービスを簡単に整理したいと思います。技術の詳細については次章のDeepSpeedで用いられている技術に記載しました。
DeepSpeed Inference
2021年5月24日に投稿された上記の記事には、様々な手法が記載されています。arxivの論文と合わせて、以下のように整理してみました。
- DeepSpeed Transformer
- 単一GPU上のtransformerカーネルを工夫する
- DeepFusion
- SBI-GeMM
- 複数GPU上で密なtransformerを効率よく動かす
- Tensor Parallelism
- Pipeline Parallelism
- 大規模なGPU上で疎なtransformer(MoEなど)を効率よく動かす
- Orchestration of Tensor, Data, &Expert Parallelism for MoE
- PCC: Parallelism Coordinated Communication for MoE
- Highly Optimized Computation Kernels for MoE
- 単一GPU上のtransformerカーネルを工夫する
- DeepSpeed Quantization Tookit
- 量子化を用いて推論コストを削減する
- Mixture of Quantization (MoQ)
- High-performance INT8 inference kernels
- 量子化を用いて推論コストを削減する
- ZeRO-Inference
- GPUのメモリに乗り切らないモデルでも、CPUのメモリを使って推論を動かせるようにする
DeepSpeed MII (Model Implementations for Inference)
DeepSpeed MIIは、上記のDeepSpeed Inferenceをより簡単に使うためのライブラリです。
上述したDeep-Fusion, Tensor Parallelisim, ZeRO-Inference, コンパイラの最適化, 量子化(ZeroQuant)などをサポートしています。
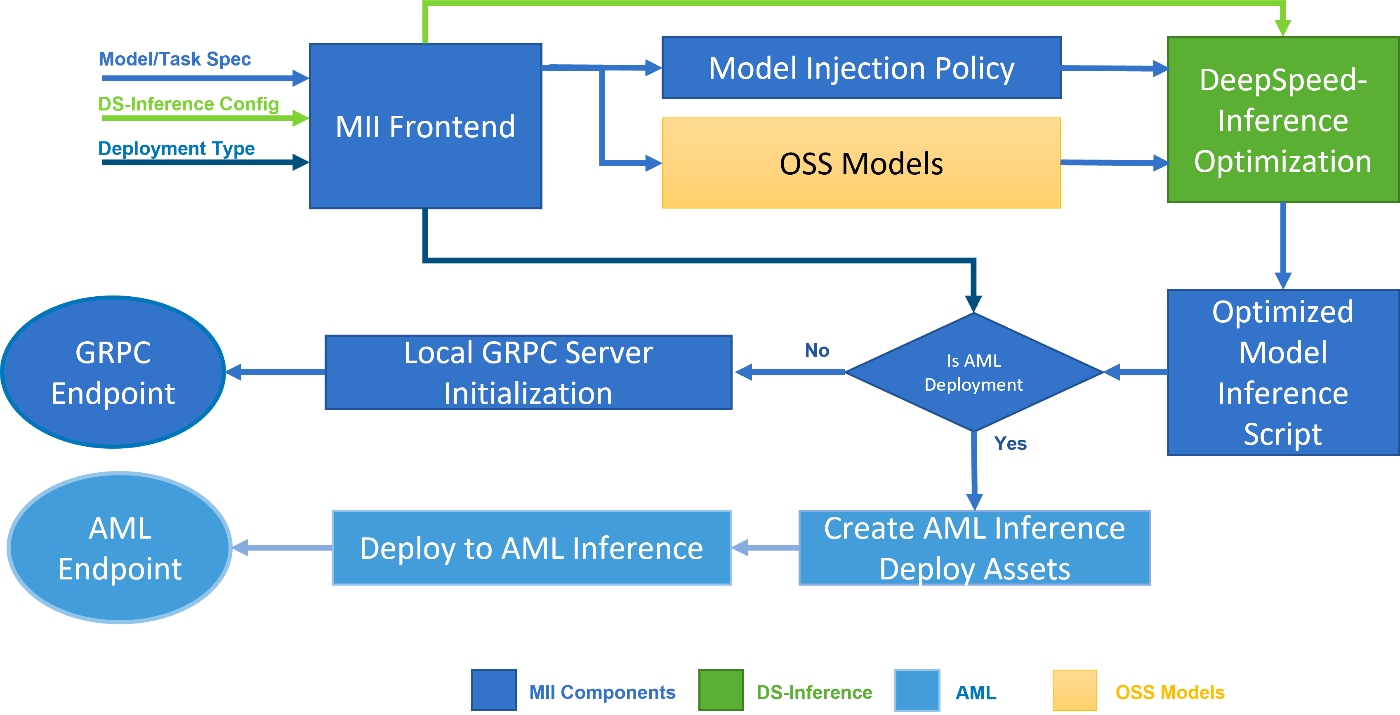
Fig.1. MIIのアーキテクチャ。公式ブログより引用。
DeepSpeed-FastGen (DeepSpeed Inference v2)
DeepSpeed Inferenceのバージョン2として、2023年11月にDeepSpeed-FastGenがリリースされました。下図のように、DeepSpeed MIIのアーキテクチャもこのDeepSpeed-FastGenを用いてアップデートされています。
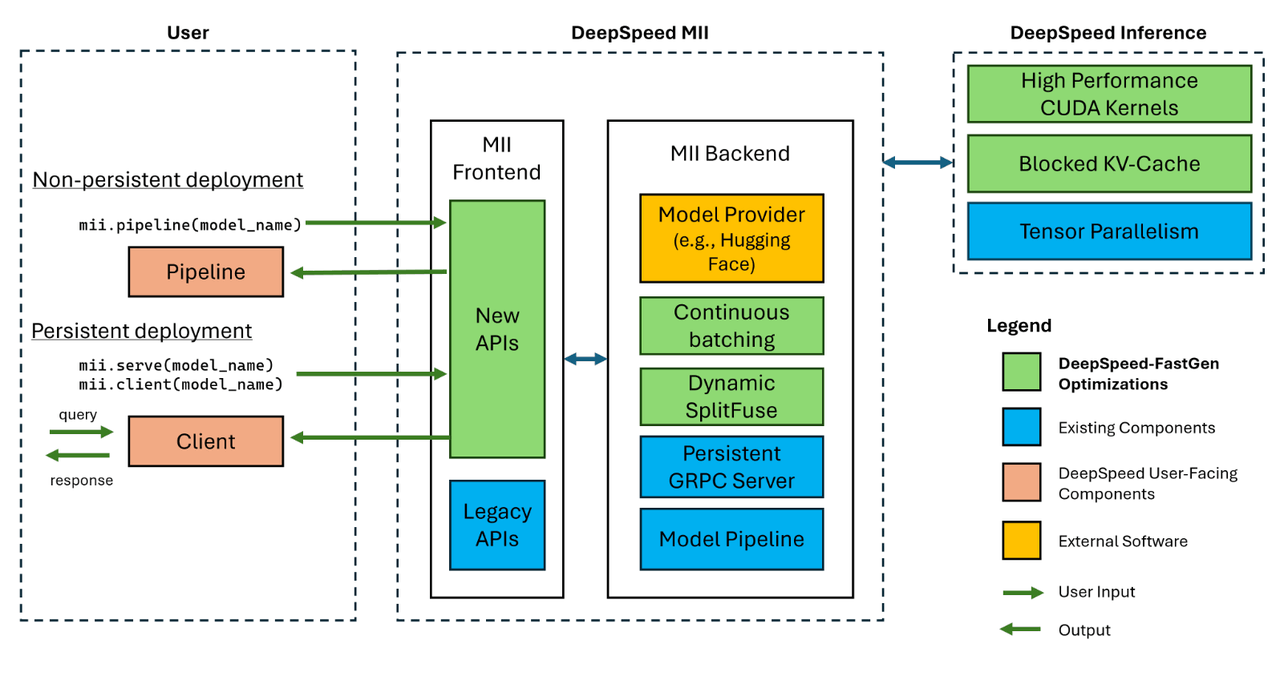
Fig.2. DeepSpeed-FastGenを用いたMIIのアーキテクチャ。リポジトリより引用。
DeepSpeed-FastGenでは、DeepSpeed Inferenceの機能に加えて(もしくは代わって??)、以下の機能が実装されています。
- Blocked KV Caching
- Continuous Batching
- Dynamic SplitFuse
- High Performance CUDA Kernels
DeepSpeedで用いられている技術
それではいよいよ、DeepSpeedの中身の部分を解説していきます。推論の際には、学習とはまた違った高速化が必要になります。特に推論は少ないバッチサイズで行われることが多く、低いレイテンシー(通信の遅延時間)や高いスループット(単位時間あたりのデータ処理量)が求められます。なお、MoEモデルの高速化については時間の都合から一旦省略しました。
DeepFusion
LLMの学習や推論には、多くの場合高速化や並列計算のためGPUが用いられます。GPUを使用するプログラムは、ホストCPUで実行されるホストプログラムと、GPUで実行されるカーネル/カーネルプログラムで構成されるのが特徴です。GPUを使用した計算を行いたい場合、カーネルを起動して、計算終了後にホストに復帰します。GPU内で動作するカーネルからカーネルを呼び出すこと(NVIDIAのダイナミックパラレリズム)も可能です。NVIDIAのCUDAでカーネルやカーネルを呼び出すコードを記述できますが、カーネルを使用するプログラムがたくさんあると、カーネルを起動する時間がオーバーヘッドとなります。DeepFusionの基本的な考え方は、組み合わせられるカーネルを組み合わせて、カーネルを起動する回数を減らそう、というものです。
DeepFusionには2段階あり、1段階目ではTransformer内のLayerNormやSoftmax、bias-addといったPyTorchの演算子を、DeepSpeed版に置き換えます。2段階目では、下図のように複数のマクロ演算子を組み合わせます。
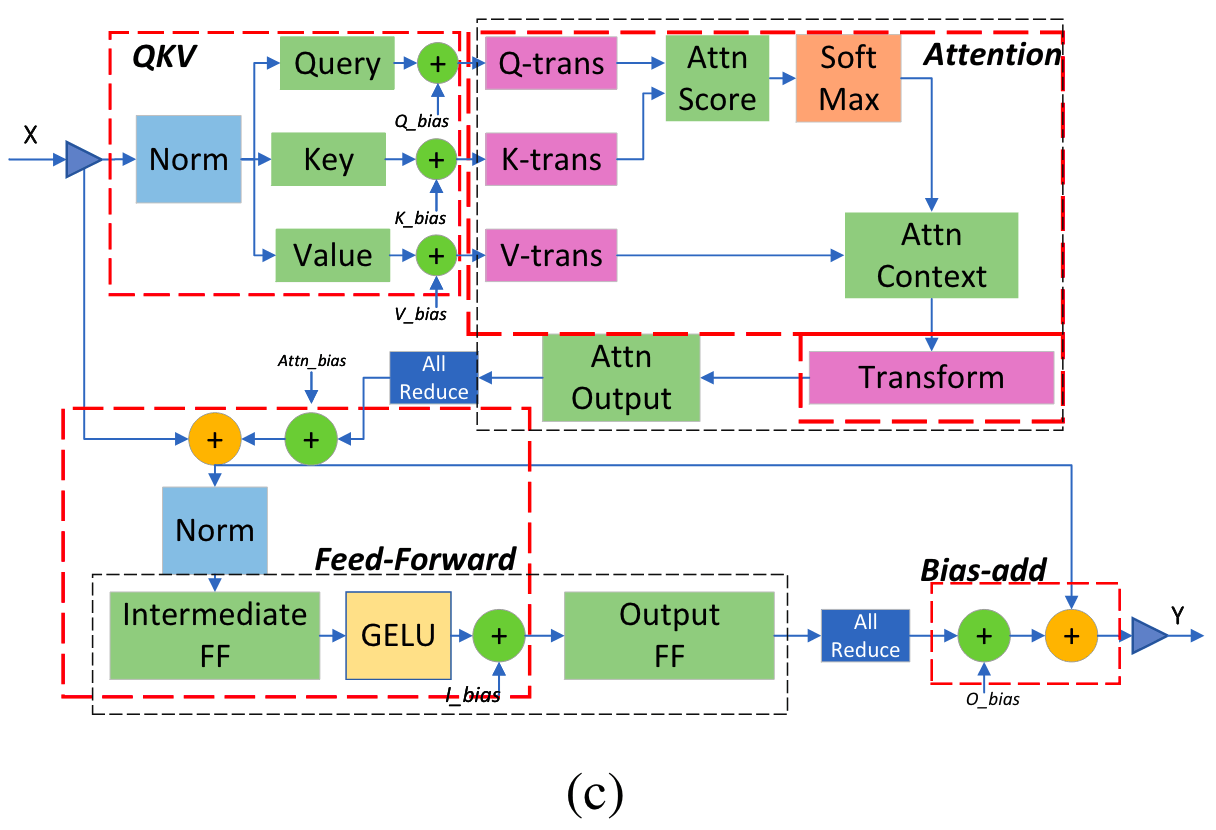
Fig.3. DeepFusionで組み合わせる演算子。DeepSpeed Inferenceより引用。
- インプットのLayer Normalizationと、Query, Key, ValueのGeMM(行列の掛け算)部分を組み合わせる。
- Q, K, V行列の転置とアテンションの計算部分を組み合わせる。
- アテンション後のLayer Normalizationと中間のFFにおけるGeMMを組み合わせる。
- バイアスと残差の加算を組み合わせる。
DeepFusionの一部は、オープンソースになっているコードとして実際に見ることができます。
ただし、2段階目のDeepFusionの一部は、一般には公開されていないようです(参照)。
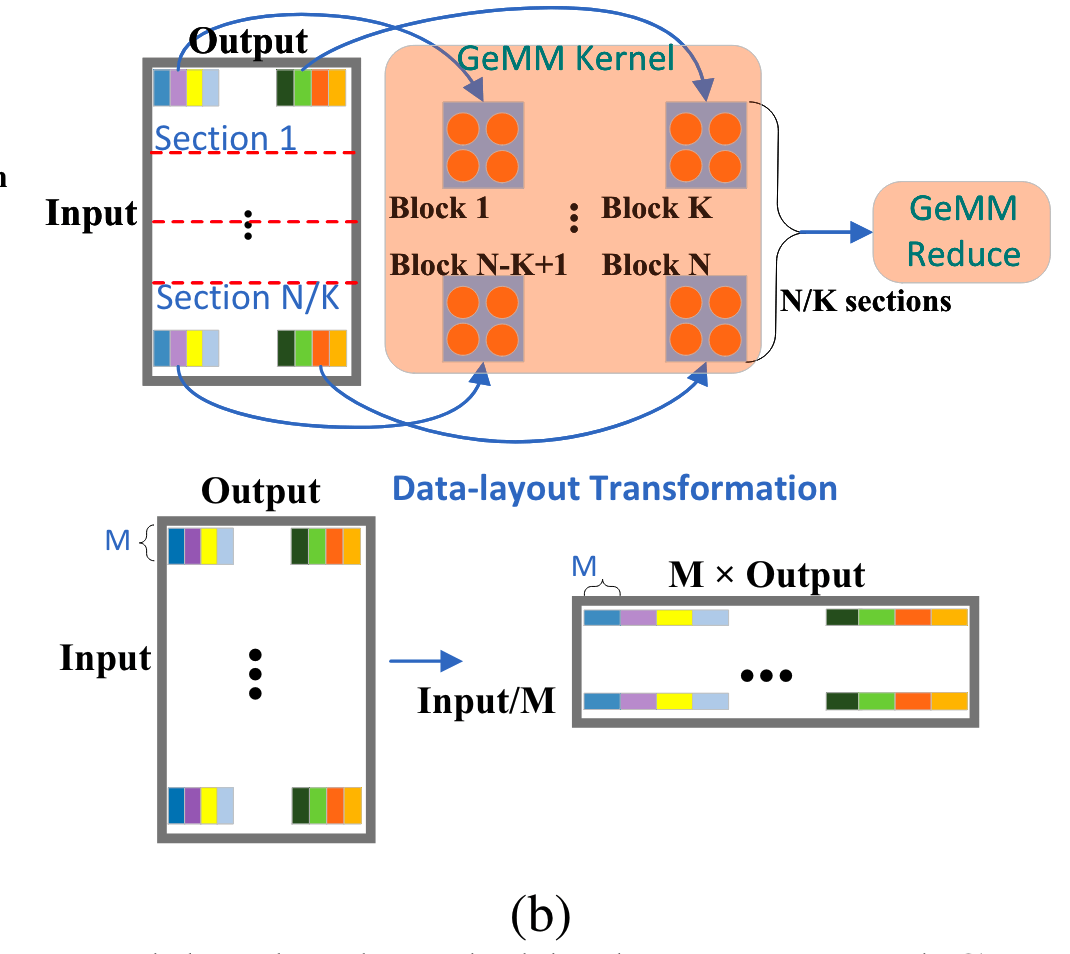
SBI-GeMM
GeMM(汎用行列-行列乗算)のためのライブラリーとして、cuBLASやCUTLASSが存在しますが、これらは推論時における小さいバッチサイズに最適化されていません。バッチサイズが小さい場合、計算速度自体ではなく、メモリからパラメータを読み取る時間が高速化のために重要になってきます。SBI-GeMMを用いたカーネルでは、パラメーターをロードするためのメモリ帯域幅の使用率を最大化するように微調整されています。SBI-GeMMの設計は以下の3つから成り立っています。
-
タイリング戦略
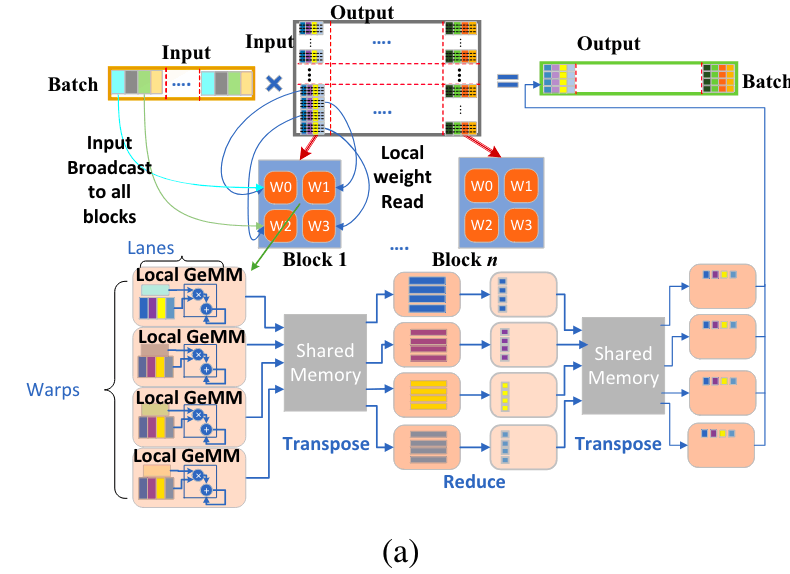
行列乗算のためのタイリング戦略。DeepSpeed Inferenceより引用。
上記の図においては、Batchが生成する文章の数、Inputは例えば生成中のtokenのembedding vectorであるとします。アテンションにおけるQ,K,V等を求めるためには、Input×Outputの行列を乗算して、OutputのQ,K,VベクトルをBatch個数分求める必要があります(図右上)。
ここでは、Outputの次元に沿って乗算する行列を分割し、それぞれのセグメントを個別に処理します。このようなタイリング手法を用いることで、データの局所性を高め、メモリアクセスの効率を高めることができます。Outputの次元が十分に大きくない時は、Inputの次元に沿っても分割されることがあります(図上中央)。分割されたセグメントごとに、CUDAのブロックにパラメータを渡し、ブロック内の各ワープ(スレッドの集まり)がセグメント内の各行を担当します。 -
協調グループリダクション
前述のタイリング戦略では、各ブロック内のワープで分割して計算を行いましたが、最終的なOutput×Batchの行列ではそれらをまとめる必要があります。通常これには、複数のワープレベルの同期が必要であり、パフォーマンスのボトルネックを生じさせます。
そこで、部分結果がメモリ内で同じ出力要素に連続して配置されるように共有メモリで単一のデータレイアウト転置を行い、単一のワープがレジスタ内で直接協調グループコレクティブを使用してリダクションを行うことができるようにします。
- フルキャッシュラインの活用
GPUアーキテクチャにおいて、各L1キャッシュラインは128バイトですが、ワープ内のスレッドごとに1つのFP16またはINT8要素を使用した連結メモリアクセスではフルキャッシュラインを完全に消費することはできません。この問題に対処するために、出力次元に沿ってスレッドごとに複数の要素を読み取ることで、並列タイルの数が減少し、これがメモリ帯域幅に悪影響を及ぼします。したがって、私たちの解決策は初期化中に重み行列を転置して、各列に対してM行がメモリ内で連続して配置されるようにすることです。これにより、各スレッドが入力次元に沿ってM要素を読み取ることが可能になります(図1(b)参照)。128バイトのキャッシュラインを考慮して、Mを半精度の場合は2、INT8データタイプの場合は4と設定しています。
Tensor Parallelism
複数のGPUを利用できるときに、それぞれのGPUに別々の仕事をやらせて、あとで組み合わせることで高速化を図ることができます。その一つがTensor Parallelismです。DeepSpeedは自動で並列度などを決定し、このTensor Parallelismをサポートしています。
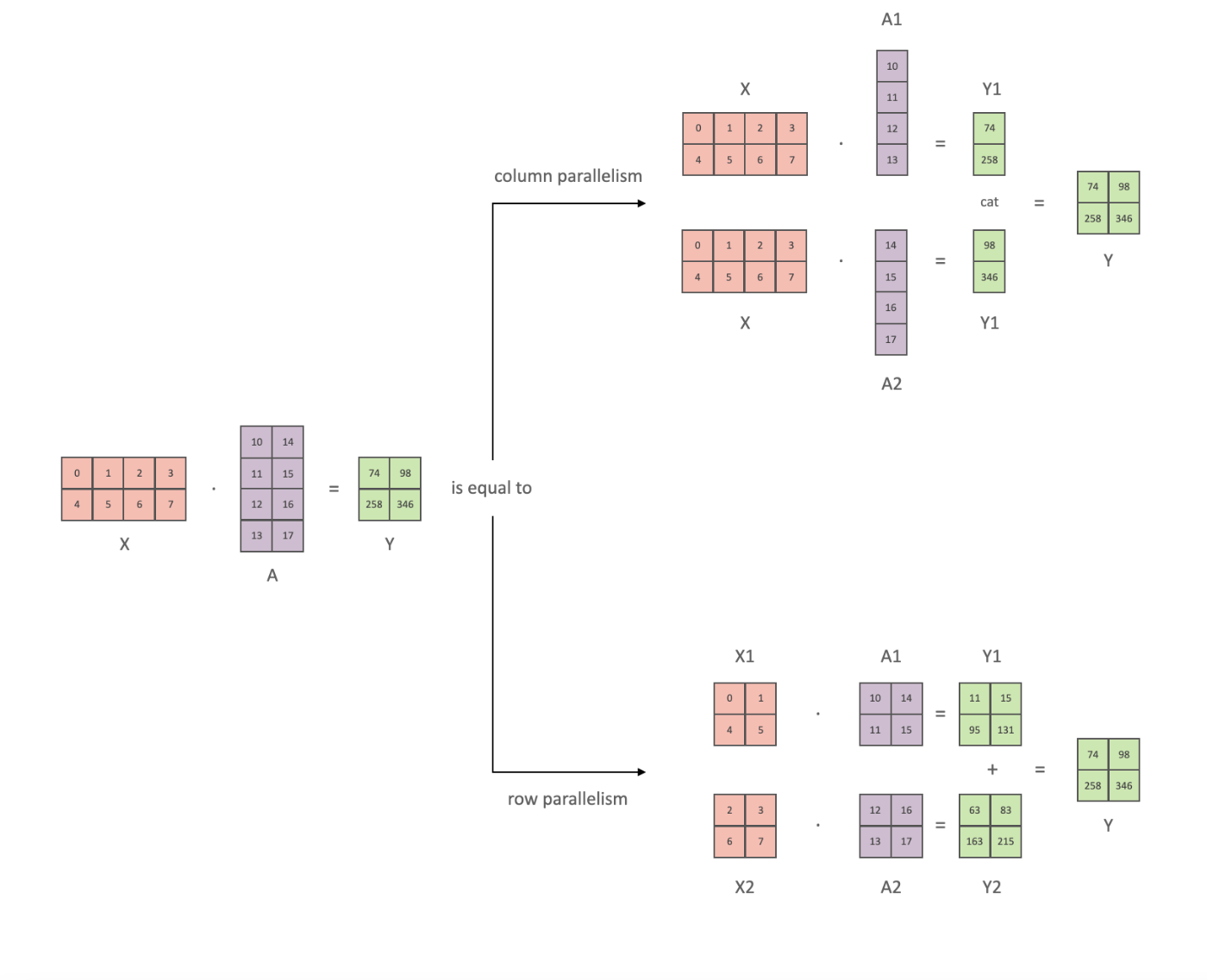
行列計算分割の例。huggingface公式ドキュメントより引用。
たとえば、上記のような
と書くことや、row parallelismのように
と書くことで、行列計算を分解することが可能です。例えば上記の例でGPUが2つであれば、それぞれのGPUで別々に分割した行列計算を行い、最後に統合することで、
詳しい内容については、Zennに非常にわかりやすい記事がありますので、そちらも参照してください。次節で説明するPipeline Parallelismについても解説が載っています。
Pipeline Parallelism
Pipeline Parallelismでは、モデルのレイヤーを複数のGPUに分割し、GPU間で次のレイヤーに順番に結果を渡すことで、推論を行います。これにより、一つのGPUではメモリが足りなくなってしまうモデルでも、複数のGPUを用いることで推論が可能になります。
Pipeline Parallelでは、ミニバッチをさらに小さいマイクロバッチに分けることで、bubble(GPUがidle状態になっている部分)を減らすことができます。Fig.4は、縦軸が4つのPipeline Stage、横軸が時間を表す、Pipeline Parallelを図示したものです。ここでは、S0,S1,S2,S3がそれぞれマイクロバッチ、つまり文章1,2,3,4を表しています。また、青、紫、緑は、それぞれの文章における生成されたtoken1,token2,token3を示します。S0は時間が経つにつれて次のステージに流れていき、最後のステージまで到達したら、その生成されたtokenの結果を元にまたステージ1から計算を始めます。transformerのような自己回帰モデルでは、一つ前で生成したtokenの結果を利用して次のtokenを生成するため、図の赤いS0にはそれぞれ依存関係があります。
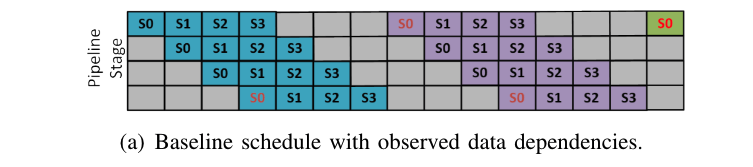
Fig.4. Pipeline Parallelの例(baseline)。DeepSpeed Inferenceより引用。
この方法では、図の青いtokenと紫のtokenの生成の間にグレーの部分、すなわちidle状態があることが分かります。DeepSpeedでは、この部分に対応するために、以下の手法を提案しています。
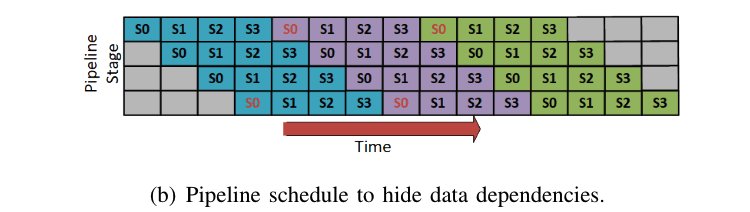
Fig.5. Pipeline Parallelの例(hide data dependencies)。DeepSpeed Inferenceより引用。
すなわち、S0について青色のtokenの生成が終わった段階で、紫色のtokenの第一段階をスタートします。こうすることで、bubbleを最小限に減らし、赤いS0の依存関係も保つことができます。
推論にはプロンプトの処理とトークン生成の二段階があり、かかる時間も異なるため、同じバッチサイズを使うことは少し効率が悪いです。プロンプト処理とは、最初に入力したプロンプトを処理して、KV cache(後述)を求める過程です。マイクロバッチへの分割数を増やすことで、bubbleを隠すことができるようになります。トークン生成では、生成したトークンを次のトークン生成の入力として、自己回帰的に計算を行います。ここでは、マイクロバッチ内でのトークン数は少なく、カーネルの実行時間は完全にメモリ帯域幅に依存します。これは、モデルパラメータの取得の方がトークン計算よりもボトルネックになるためで、マイクロバッチの数を変更しても計算時間はあまり変わりません。全体としては、マイクロバッチの数は少ない方が、モデルパラメータの取得を何度も行わなくて済むため効率的です。
これらの関係を表したものがFig.6です。ここでは、縦軸をステージ1と2、横軸を時間として、マイクロバッチの数が2のSmall micro-batch count, マイクロバッチの数が4のLarge micro-batch count, プロンプト処理ではマイクロバッチの数が4で、トークン生成では2のHybrid micro-batch countの3種類を比較しています。

Fig.6. Batch SizeのScheduling。DeepSpeed Inferenceより引用。
マイクロバッチの数が常に少ないと(Small micro-batch count)、プロンプト処理の段階でbubbleが大きくなってしまいます。一方で、マイクロバッチの数を増やすと(Lareg micro-batch count)、プロンプト処理の段階でbubbleを隠すことはできますが、トークン生成に長い時間がかかってしまいます。Hybrid micro-batch countではこれらの良いとこどりを試み、プロンプト処理の段階ではbubbleを隠すために比較的多いマイクロバッチ数、トークン生成の段階では少ないバッチ数をSchedulingします。上図を比較すると、Hybrid micro-batch, Small micro-batch, Large micro-batchの順に生成が完了していることが読み取れます。
加えて、各ステージのKV cacheは次にその文章のトークンを生成するまで使用しないため、CPUにオフロードしたり、GPUとレイヤーの偶奇で割り当てを決定し、通信が競合しないようにしたりなど、さまざまな工夫が行われています。
Mixture of Quantization (MoQ)
バッチサイズが小さい大規模なTransformerベースのモデルの推論時間は、主にメインメモリからのパラメータロード時間がボトルネックになります。MoQでは、シンプルにFP32の精度のパラメータを低精度(INT4やINT8)に変換した後、FP16のパラメータとして保存します。実際の計算はINT4やINT8の精度までしか出ませんが、FP16で保存しておく理由は、元々存在するDeepSpeedのmixed-precision training pipelineを再利用してシームレスな統合を目指したためのようです。また、INT8でトレーニングされたパラメータに合わせて最適化された、INT8推論カーネルも存在します。このカーネルは、INT8としてパラメータを読み込んで、推論計算を行う前にFP16に変換してから計算を行います。
ZeRO-Inference
ZeRO-Inferenceは高速化の文脈とは少し異なり、レイテンシーを犠牲にしても良いので少ないGPUメモリで大規模なモデルを動かしたい時に用いられます。具体的には、普段はCPUのDRAMやNVMeにパラメータを保存しておいて、必要な時に必要なレイヤーのみGPUのメモリに移動させて計算を行います。
加えて、以下の2つの方法でパフォーマンスの最適化を図ります。
- Prefetching
- 現在のレイヤーの計算と同時に、設定可能な数のレイヤーを、使用する前にprefetch(あらかじめパラメータをGPUメモリに移しておくこと)を行います。こうすることで、GPUメモリの消費量は増えますが、計算時間の裏でprefetchを行い、スループットが向上します。
- Multi-GPU PCI-e bandwidth utilization
- 複数のGPUが存在する状況では、CPUのメモリから各GPUにデータを持ってきた後、必要な場合はGPU間でデータを交換します。こうすることで、より高速なGPU-GPU間の通信を利用することが可能になります。

Fig.. ZeRO-Inferenceを用いた1GPUで推論できる最大のモデルサイズ。ZeRO-Inference: Democratizing massive model inferenceより引用。
- 複数のGPUが存在する状況では、CPUのメモリから各GPUにデータを持ってきた後、必要な場合はGPU間でデータを交換します。こうすることで、より高速なGPU-GPU間の通信を利用することが可能になります。
Blocked KV Caching
KV cachingとは、KeyとValueをキャッシュしておくことで再計算を不要にし、計算を高速化する手法です。transformerでは、Query, Key, Valueの値からAttention Scoreを求めます。この際、新しく入ってきたQueryの値と、それまでのKey, Valueの値が必要になります。ここで、Fig.7を参照すると、それまでのKeyやValueの値をcacheしておくことで、毎回再計算しなくて済むことが分かります(図中で紫色になっている部分)。

Fig.7.KV Cachingのgif画像。Transformers KV Caching Explainedより引用。
計算を高速化できるKV cachingですが、その分cacheが必要であるため、メモリを消費します。また、vLLMの報告では、60~80%のメモリが無駄に消費されてしまっているそうです。
無駄になっている理由としては、
- Internal Fragmentation:最終的なアウトプットの長さがわからないため、余分に確保してしまったメモリ。
- Reservation:後で生成した際に使用するものの、現段階では使用していないメモリ。
- External Fragmentation:文章Aと文章Bの生成の間で生まれてしまうメモリの無駄。
が挙げられます。
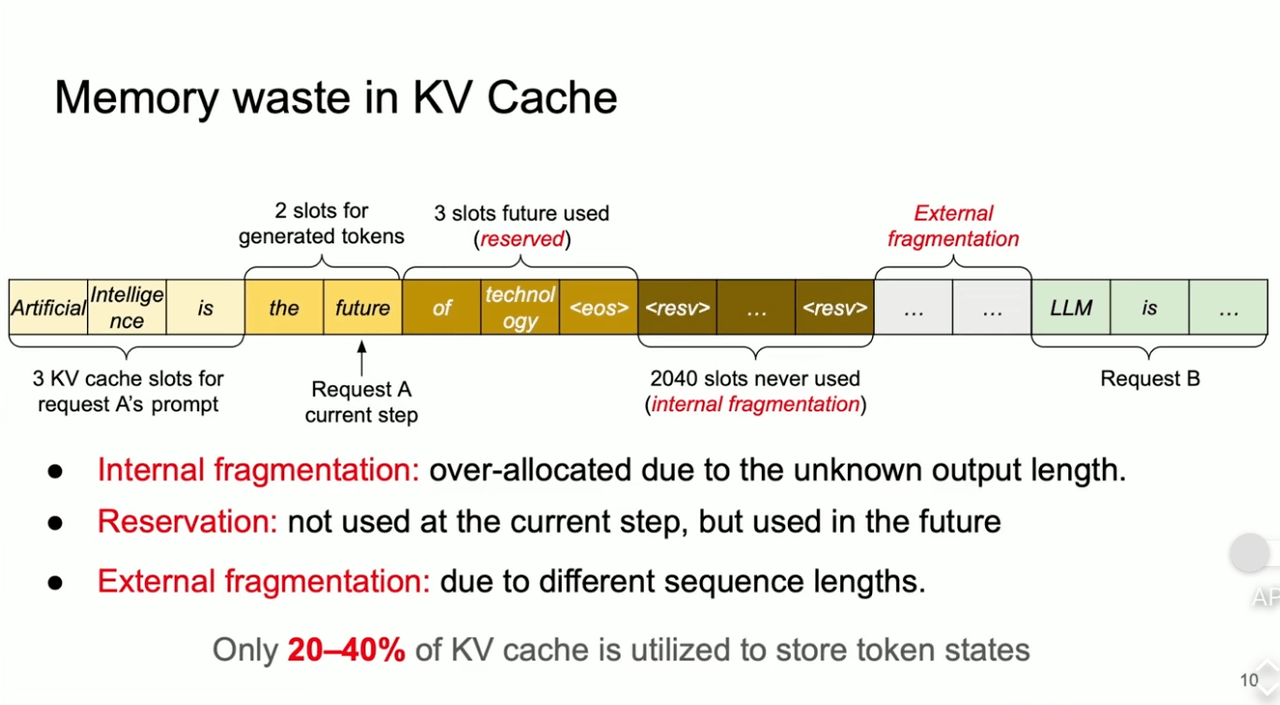
Fig.8.KV Cacheのメモリの無駄。Fast LLM Serving with vLLM and PagedAttentionより引用。
これを解消するために、DeepSpeedではBlocked KV Caching(またの名をPaged Attention)をサポートしています。Blocked KV CachingではOSの仮想記憶管理とページング方式に着想を得て、KV cacheをブロックに分割して保存します。KV cacheが物理メモリ上で連続している必要がなくなり、Fragmentationといったメモリの無駄が削減されます。
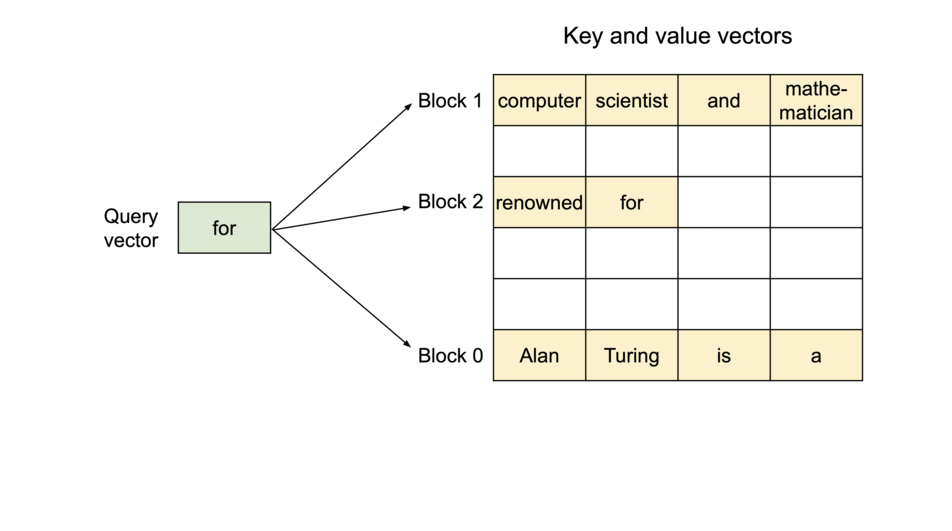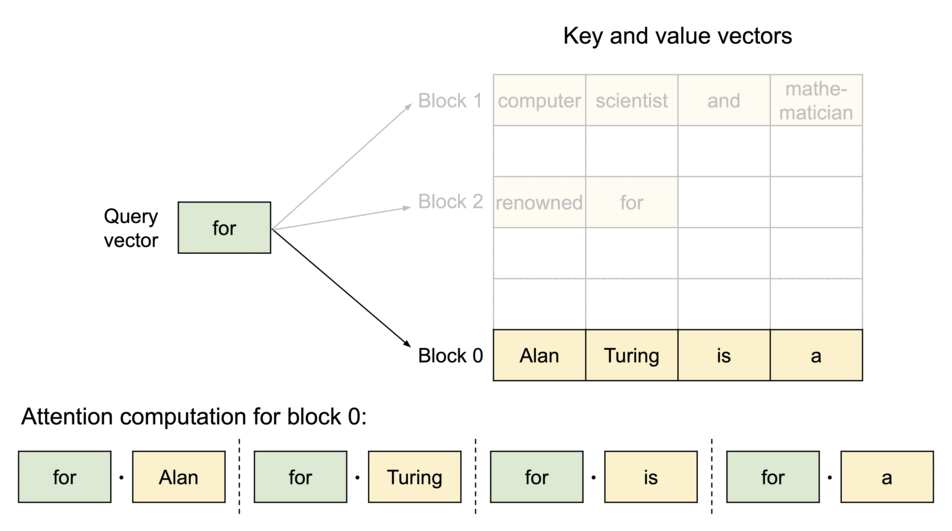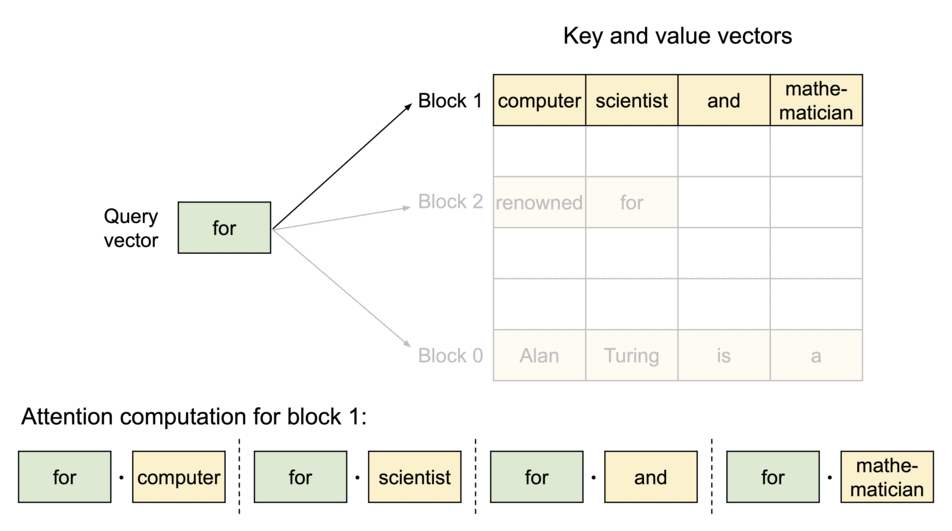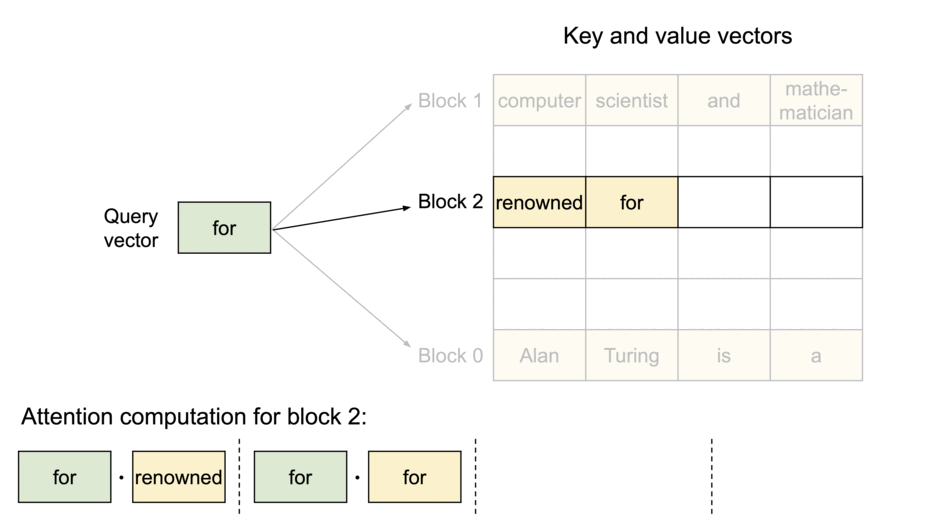
Fig.9.KV cacheのブロック分割の例。vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttentionより引用
生成を行う場合は、Block tableのマッピングで仮想メモリと物理メモリの割り当てを管理し、新しくtokenを生成した場合に動的にメモリを確保します。こうすることで、メモリの無駄は最後のブロックのみで発生するようになります。

Fig.10.Blocked KV cacheを利用した生成の例。vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttentionより引用
メモリの無駄を減らすことができれば、より多くのバッチを読み込んで推論を高速化することが可能になります。
Continuous Batching
通常のナイーブなBatchingを表したものがFig.11です。図では、4つの文章を同時に生成するバッチ処理を行なっており、黄色い部分がPipeline Parallelismの節で説明したプロンプト処理(prefill)、青色の部分がトークン生成(decode)となっています。

Fig.11. Naive batching / static batching。anyscale)より引用。
Naive batchingの問題は、例えば上図のS1やS3において、T6やT7、T8で活用されていないGPUが生まれてしまっている点が挙げられます。その文章が早めに生成が終わったとしても、バッチ内の全ての文章の生成が終わるまで待たなければいけません。これでは無駄が生じてしまいます。
Continuous Batchingでは、以下のような改善を施します。すなわち、生成が終わった部分については次の文章の生成を開始することで、無駄を省くことができます。
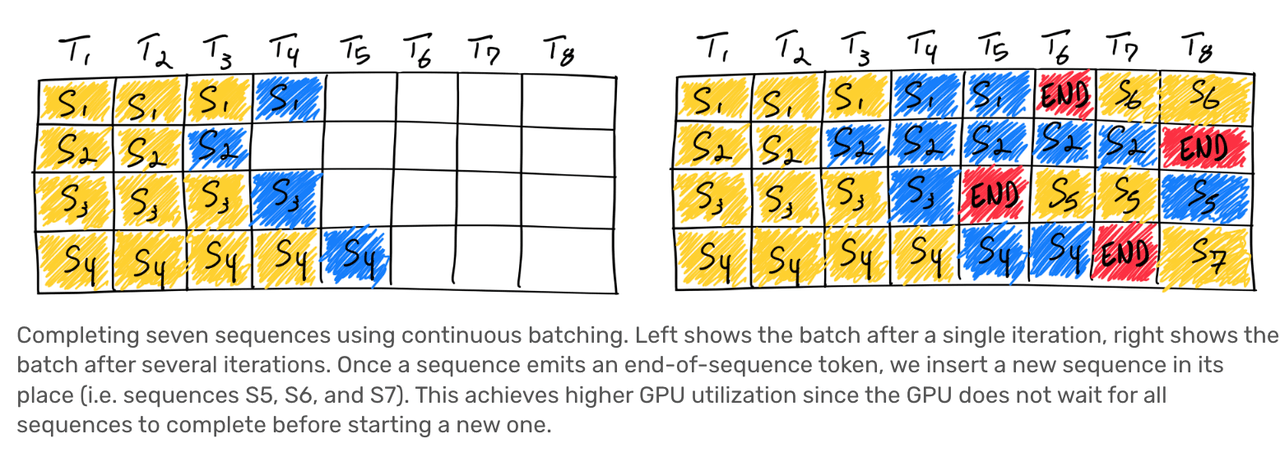
Fig.12. Continuous Batching。anyscale)より引用。
なぜこんなことが可能なのかというと、Iteration-Level Schedulingを採用しているためです。同様の技術を採用しているOrcaの以下の動画が分かりやすいのですが(7:07~)、毎回トークンを一つ生成するごとにRequest Poolに戻すことで、生成が終わった場合には新たな文章の生成を開始することができます。例えば上のFig.12のT5において[S1,S2,END,S4]を受け取ったら、T6には[S1,S2,S5,S4]の情報を渡して新たにもう1トークンだけ生成します。T6では[END,S2,S5,S4]を受け取るため、次のイテレーションでは新たにS6の処理を始めることができます。
ただ、黄色のprefillと青のdecodeを同時に行なったり、それまでに処理されたtoken数が異なる文章を同時に計算することで、行列計算をバッチにまとめられないという問題が発生します(動画:8:58~)。これに対応するために、処理の系列長を考慮する必要のあるAttention LayerについてSelective Batchingを導入し、tensorを合算→Attention部分のみ分割して計算→tensorを再び合算、という処理を辿ることで、解決を図っています。
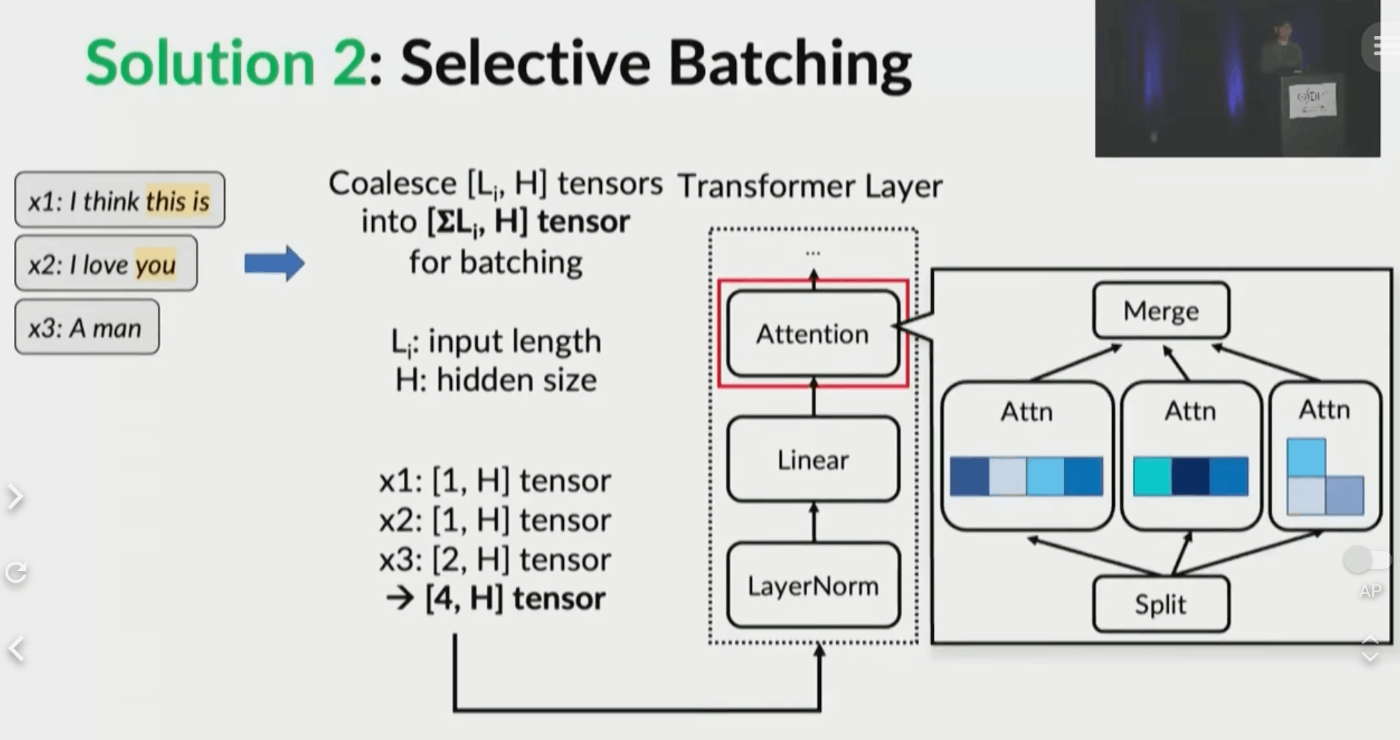
Fig.13. Selective Batchingの様子。OSDI '22 - Orca: A Distributed Serving System for Transformer-Based Generative Modelsより引用。
Dynamic SplitFuse
Continuous Batchingでは、トークン生成が終わった場合に、すぐに次の文章の生成処理を始められることを示しました。
Fig.12. Continuous Batching。anyscale)より引用。
ただ、例えばT6を見てみると、文章を生成しているS2とS4(正確には終了tokenを生成しているS1も)と、新たにprefillが行われているS5が同時に計算されていることが分かります。KV cacheの部分でも少し触れましたが、新たにtokenを生成するdecodeフェーズでは、KV cacheを用いて計算を高速化することができます。一方で、prefillの段階でははじめてKeyやValueを計算するため、この計算を避けることはできません。したがって、S1,S2,S4はS5のK,Vの計算処理を待たなければいけない、という状態が発生します。
Dynamic SplitFuseでは、prefillを行う場合は他のtoken生成を一旦中断して、prefillだけまとめてやってしまおう、という考え方(だと思います)。つまり、T6において一旦S2やS4の生成を中断し、S6やS7のprefillをS5と同時に行います。そうすることで、時間のかかるprefill段階のQ,K,V計算を並列で行うことができます。Dynamic SplitFuseは、このトークン生成中断とprefill処理の割合を動的に調整するものです。
DeepSpeedの使い方
DeepSpeed MIIを用いることで、難しいパラメータを色々と設定しなくても、たった5行程度でDeepSpeed Inferenceを使うことができます。
import mii
pipe = mii.pipeline("meta-llama/Llama-2-7b-hf")
responses = pipe("The reason why DeepSpeed is fast is", max_new_tokens=128, return_full_text=True)
if pipe.is_rank_0:
print(responses[0])
おわりに
今回はDeepSpeedがどのように推論の高速化を達成しているか、論文や公式サイトをもとに解説しました。いくつか明らかになっていない部分があるため、コメント欄でご意見承れますと幸いです。
Discussion