SnowflakeSummit 2023 の激アツ発表をまとめてみた
この記事は何
2023年6月26日から30日にかけてラスベガスで行われた Snowflake Summit での発表内容をまとめました。
昨年も同じような記事を書いたのですが、今回も同じように記載していきたいと思います。
公式サイトによればセッションは433ありました。昨年は313だったので、40%程度拡大したようですね。会場の数も前回より拡大されているとのことで、より激アツになったようです!!
参加者はおよそ1.2万人とのことで、こちらも去年に比べて20%程度増えています。
日本からの参加者はおよそ150人で、昨年よりも大幅に増加しました。国内での Snowflake の広がりを反映していると言えます。なお、著者も今回は現地参加してきました。
Summit での発表内容は以下のブログでおおよそまとまっていると思います。
オープニング基調講演では、「NO LIMITS ON DATA」というテーマが掲げられており、 AI / LLM 、データエンジニアリング、データアプリケーションといった幅広い領域に渡って新機能のアナウンスが行われました。
その中でも、
- Document AI
- Native Application Framework
- Snowpark Container Service
が今回の発表の目玉になりました。
この記事では、これら3つの機能を中心に、 Summit での発表内容を概観していきたいと思います。
Document AI - 非構造データを構造化しよう
ChatGPT をはじめとした LLM(大規模言語モデル) により、AI がついに普及段階になってきました。そんな中、Snowflake は Nvidia とのパートナーシップを発表し、 AI の社会実装を支援する姿勢を打ち出しています。
今回のオープニング基調講演では、 PDF などの非構造化データから情報を抽出し、構造化データに変換できる Document AI という機能がデモンストレーションされました。
世界中のデータの80%を占めるとも言われる非構造化データから効率的にデータを抽出し、活用できるようになるとすれば非常にすごいですね...!
How to Use
以下のYouTubeを参考に、どのように使うのかをご紹介します。
まず、 PDF などの非構造化データに対してチャット形式のように問い合わせを作成し、「モデル」を作成します。
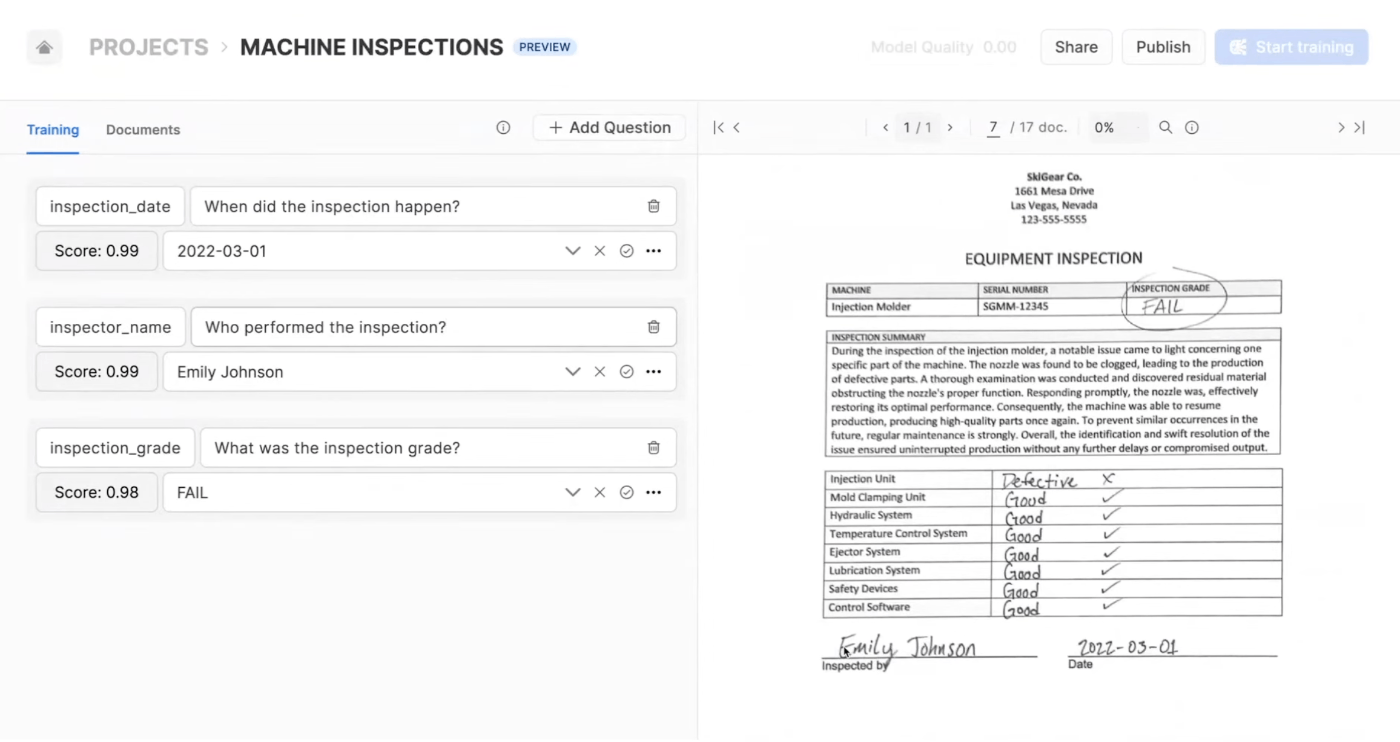
Snowsightからモデルを作成できる
次にこのモデルを公開し、以下のような SQL によって、モデルの出力結果をテーブルに格納します。
CREATE TABLE model_results
AS
SELECT
trained_model!predit(get_presigned_url(@inspections_stage),3) as prediction
FROM directory(@inspections_stage)
;
ここでは、inspections_stageというステージに配置された非構造化ファイルを、先ほど作成していたtrained_modelというモデルにデータを入力し、出力結果をテーブルに格納しています。4行目にある3という数字は、モデル作成時に質問を3つ作っていたので、結果も3つ取得するために記述しています。
質問結果を取得するには、通常のテーブルと同じように、以下のようなクエリを記述すれば OK です。
今回は出力結果をpredictionというカラムに JSON 形式で格納しているので、以下のように取得できます。
SELET
prediction:"inspection_date"[0]::variant::"value"::date as inspection_date
, prediction:"inspection_name"[0]::variant::"value"::string as inspection_name
, prediction:"inspection_grade"[0]::variant::"value"::string as inspection_grade
FROM model_results
つまり、非構造データから、LLM などの機械学習モデルを利用してデータを抽出し、構造化データとしてテーブルに保管することができるという機能になります。シンプルにやばい機能ですね。LLM 関連では他に SQL の自動生成機能なども今後組み込まれていくようですので、期待が大きいです。
Native App Framework - アプリケーションをシェアしよう
二つ目は、昨年の Summit でアナウンスされた Native App Framework が AWS において Public Preview となり、 AWS で Snowflake をホストしている全ユーザーを対象に公開されました。GCP とAzure では引き続き Private Preview になっています。
Native Apps Framework とは、簡単に言えば、 iOS の App Store や Android の Goole Play のように、 Snowflake 上で動作するアプリケーションを作成するフレームワークです。
しかし、この Native App Framework が App Store などと決定的に違う点があります。それは、 Native App Framework はデータを共有することなく、アプリケーションだけを利用することができる点です。
従来型の SaaS アプリケーションにおいて、ユーザーは SaaS 提供元企業のサーバーに自分達のデータを保管しないとアプリケーションを利用することができませんでした。例えば、 SaaS として提供されている営業管理ツールを利用したい企業は、営業管理ツールを提供する企業のサーバー内に、自分達の顧客に関する情報などを保存しています。これはいくつかの問題を引き起こしました。
- 情報ガバナンスとセキュリティの問題。営業管理ツールの提供元企業が、自分達の顧客に関するデータを無断で利用していたり、情報漏洩を引き起こす可能性がある。
- データのサイロ化の問題。 SaaS 提供元企業側にデータが自分達の情報が蓄積されるため、 ETL 処理を行なって自社のデータ基盤に再統合する必要がある。
Snowflake は、このような課題を解消するために Connected Apps という考え方を提唱しました。
Connected Apps では、データを各ユーザーのデータ基盤に留めおいたまま、アプリケーションのロジックのみを SaaS が提供する、という概念です。これは、以下のような技術的な課題が存在していたため、これまで実現が難しく考えられていました。
- アプリケーションのロジックやソースコードを提供先企業に知られることなく提供することが難しい。
- ほとんどの SaaS は、提供元企業のデータと提供先企業のデータの両方を必要とする。そのため、ロジックのみを提供しても実現できない。かと言ってデータごと提供先企業に提供することはビジネス上許容できない。
しかし、 Snowflake のような「信頼できる第三者」が間に入ることで、このような課題が解消できるようになりました。 SaaS 提供元企業は、ロジックとデータを Snowflake 内に配置します。そして、提供先企業も、同様にしてデータを Snowflake 内に配置します。 Snowflake は双方のデータとロジックを受け取りアプリケーションを動かしますが、データの加工過程は SaaS 提供元/提供先双方から見ることが出来ないようになっており、お互いがお互いのデータやロジックを知ることは出来ません。
この仕組みは Snowflake の提供するデータクリーンルームを応用して実現されています。国内では先日 KDDI での取り組みが発表されていましたね。
しかし、 Native App の最大のメリットは、ビジネス上のボトルネックを取り除く点にあります。
一つ目は、 Snowflake というスケーラブルなインフラストラクチャ上で動作するようになっているため、アプリ提供者はインフラストラクチャに関して準備すべきことが圧倒的に少なくて済みます。 AWS や GCP などのパブリックインフラによってハードルは劇的に下がったとは言え、依然として労力はゼロではありません。Snowflake はそれらのインフラの詳細を隠蔽し、開発者はアプリケーションロジックのみを記述すれば良くなりました。いわゆる PaaS の一種として考えることが出来ますね。
二つ目は、アプリ導入検討側の企業は、自分達のデータを提供する必要がなく、 Snowflake のマーケットストアからクリックするだけで導入できるため、導入ハードルが圧倒的に低くなります。結果として、より素早く顧客を獲得できるようになるでしょう。
今回の Summit のオープニング基調講演では、このフレームワークを用いて作成した十個ものアプリケーションが披露されて締めくくられました。これからの SaaS のあり方を大きく変えうるテクノロジーであり、 Snowflake もかなり力を入れているようですね!
App Store などと同様に、 Native App も Snowflake Marketplace で販売可能であり、従量課金や定額課金など、いくつかの課金プランを設定できるようです。
誰でも公開できるので、素晴らしいアイデアを思いついたらすぐに作成してマーケットプレイスで公開しましょう。一攫千金も夢じゃ無いかもしれませんね...?!
既にいくつかのアプリが公開されているので、どんなアプリがあるか知りたい方は以下をご確認ください。
Snowpark Container Service - あらゆるランタイムをSnowflake上で動かそう
そして、3つ目は Snowpark Container Service です。
Container Service を利用することで、以下のようなことがSnowflake上で実現できるようになります。
- GPU を用いた LLM を含む機械学習モデルの学習及び実行
- R, C++, Rust などのあらゆる言語の実行
- API や UI を含むアプリケーションのホスティング
Native Appと統合することで、あらゆるアプリケーションを Snowflake 上でホスティングしてマーケットプレイスで提供できるようになります。
Container Service は Kubernetes ベースのコンテナオーケストレーションを利用していますが、ユーザーは Kubernetes の複雑な設定について考える必要はありません。
Container Service を利用して Hex のアプリケーションがホスティングされている動画も出ていました。既存の Hex とほぼ変わらない機能と UX のまま、マーケットプレイスで公開されています。すごいですね。
Container Service では、Jobs というバッチ処理、Service Functions という AWS Lambda のようなトリガーによって起動する短時間のサーバレス処理、Service という 常時起動するシステム向けの3種類の起動方法が指定できます。
How to Use
まず、コンテナイメージを保存するリポジトリを作成します。
CREATE IMAGE REPOGITORY test_repo;
次に、コンテナを起動する同一のリソースをまとめた概念である Compute Pool を作成します。
CREATE COMUPUTE POOL test_container_services
min_nodes = 1
max_nodes = 2
instance_family = nvidia_A10Gx4 -- 確保するリソースの種類を指定
auto_resume = true
;
次に、Compute Pool の中に Jobs, Service Functions, Services のいずれかを作成します。
今回はJupyter Notebookを Services としてホスティングしてみます。
CREATE SERVICE test_notebook
min_instance = 1
max_instance = 1
compute_pool = test_container_services
spec = '@snowpark_test/notebook/test_notebook_manifest.yaml'
;
specパラメータには、以下のようなコンテナについての定義書の YAML ファイルを指定します。
コンテナのイメージを指定している場所には、先ほど作成したイメージリポジトリにプッシュしているコンテナイメージを指定します。
spec:
container:
- name: test
image: <image_repogitory_url>
volumeMounts:
- name: test
mountPath: /src
env:
GITHUB_TOKEN: xxxxx
volume:
- name: test_vol
source: "@TEST_DB.TEST_SCHEMA.TEST_STAGE"
endpoint:
- name: test_endpoint
port: 8888
public: true
上記のような Service を起動すると コンテナがホストされた URL が発行されるため、その URL にブラウザからアクセスすると、Snowflake へのログインを求められた後に Notebook にアクセスできるようになります。
また、Service Functions はユーザー定義関数と組み合わせることができます。
CREATE FUNCTION test_function(a STRING)
returns array
service = <service_function_name>
endpoint = <endpoint>
max_batch_rows = 1000
;
SELECT
test_function(string_col)
FROM test_table
;
コンテナイメージや、YAML ファイルは SQLを用いてアップロードできますが、今後は Python, CLI, Snowsight 上から行うこともできるようになるそうです。
その他の発表
さて、ここまででもうお腹いっぱいかもしれませんが、今回の Summit では他にも多数の新機能の発表がありました。
全てをフォローすることは難しいため、重要そうなトピックについて紹介します。
Unified Apache Iceberg Table - Apache Iceberg ファイルとの統合を強化
昨年の Summit にて Apache Iceberg への機能対応を発表してから一年が経ち、今回の Summit では、 Iceberg をファイルフォーマットとして用いたテーブルの機能強化がアナウンスされました。
Apache Iceberg とは、オープンソースのファイルフォーマットで、 Snowflake の持つ「タイムトラベル」の機能やACIDを実現可能な列指向フォーマットです。
昨年の Summit では、 ユーザー自身の AWS S3 などのファイルストレージに保管されている Iceberg ファイルを Snowflake からアクセスし、まるでテーブルが存在するかのように SQL を用いてアクセスする External Table という機能と、Snowflakeの管理するストレージ内で Iceberg 形式でデータを保管しクエリすることができる Native Iceberg Table という機能が発表されています。
今回はこのファイル統合についてさらに強化し、Snowflake 内の最適化された独自フォーマットのパフォーマンスに近づけることがアナウンスされました。
大きく分けると、External Table と Native Iceberg Table を Unified Iceberg Table という形式に統合したことと、 Iceberg Table のパフォーマンスを劇的に改善し、通常のテーブルと遜色ないレベルになったことがアナウンスされました。
より詳細な変更点は以下の通りです。
- これまで Snowflake が管理するストレージ内で Iceberg 形式でデータを保存する Native Iceberg Table とユーザー自身のクラウドストレージに保管された Iceberg ファイルを読み書きする External Table という機能に分離していたのを統合し、 Unified Iceberg Table とした
- Native Iceberg Table は Managed Iceberg Table に、 External Table は Unmanaged Iceberg Table に名称が変更された
- Unmanaged Iceberg Table は External Table から2倍以上のパフォーマンス向上を行い、Snowflake の通常テーブルのおよそ2倍程度のパフォーマンスまで改善された
- Managed Iceberg Table は Snowflake の通常テーブルとほぼ遜色ないレベルにまでパフォーマンスするようになった
このアナウンスの重要性は Iceberg を普段利用していないユーザーにとってはぴんと来ないかもしれません。しかし、 Snowflake が Iceberg への対応を強化することにより、ユーザーは Snowflake のエコシステムに依存せずに開発を進めることが出来るようになります。
具体的には、以下のようなユースケースが考えられるでしょう。
- 社内システムが Iceberg 形式のファイルを出力し、クラウドストレージに配置するようにすれば、そのファイルを Snowflake からシームレスにクエリすることが出来るようになる。 ETL ツールが不要になるとともに、社内システムが Snowflake に接続する必要がなくなるため、システム間の依存を排除できる。
- Snowflake 以外のデータウェアハウス・データ分析ツールからも同じ Iceberg ファイルを参照することが出来る。データのシングルソース化[1]が実現できるとともに、ユーザーにとってその時のビジネス要件に最適なソリューションを用いることができる。
このように、データフォーマットのオープンソース化には、ベンダーロックインを防ぎ、システム間の依存関係を防ぐという大きなユーザー利益がある一方、ベンダー側からすると自社のサービスにユーザーを留めにくくなったり、自社のサービスのパフォーマンスに最適化することができなくなる、といった不利益に繋がりかねないでしょう。
しかし、より多くのユーザーがより手軽に Snowflake のエコシステムに参加することが出来るようにするためには、このようなオープンソースフォーマットを取り込むことは非常に重要だと考えられます。そうした意味で、このアナウンスにはインパクトがありました。
私見としては、このようなデータフォーマットにおけるオープンソース化の波はより広がっていくと思っています。例えば、データシェアリングの領域においても、 Delta Sharing のようなプロトコルのオープンソース化が進められ、さまざまなデータウェアハウスプラットフォーム間でのデータシェアリングが実現していくのではないでしょうか。
Iceberg テーブルに関する、 Snowflake の考えについては、以下の記事が参考になると思います。
How to Use
以下、 Unmaged Unified Iceberg Table の作り方になります。
まず、 External Volume と呼ばれる、Iceberg テーブルが置いてあるS3のストレージボリュームを参照するリソースを作成します。
CREATE EXTERNAL VOLUME test_volume
storage_location = ( [
name = 'xxx'
storage_provider = 'S3'
storage_aws_role_arn = 'arn:aws:iam::xxxxxx'
storage_base_s3_url = 's3://xxxxx'
]
);
次に、 Iceberg が利用する「データカタログ」を読み込むリソースを作成します。このデータカタログは Iceberg ファイルを用いて ACID を実現するために必要になる各種メタデータを保管するものです。一般的に呼ばれている「データカタログ」とは違うのでご注意ください。現在さまざまな種類のデータカタログが存在します。ここでは AWS Glue のデータカタログを利用します。
CREATE CATALOG INEGRATION test_catalog
catalog_source = glue
catalog_namespase = 'xxx'
table_format = iceberg
glue_aws_role_arn = 'arn:aws:iam::xxxxxx'
glue_catalog_id = '00000000'
enabled = true
;
外部ボリュームとカタログを利用して Iceberg テーブルを作成します。
// これまでは CREATE EXTERNAL TABLE という構文だった
CREATE ICEBERG TABLE zzzz
catalog_table_name = 'xxxxx'
catalog = 'test_catalog'
external_volume = 'test_volume'
;
Iceberg テーブルに対しては通常の Snowflake テーブルと同様にクエリすることが可能です。
Iceberg を利用することで、 Spark, Hive, Glue, Athena, BigQuery, Databricks などとの連携・相互運用性が向上しますね! いろいろな夢が広がりそうなので楽しみです。
Dynamic Table
昨年の Summit にて Materialized Table としてアナウンスされた機能が Dynamic Table として Public Preview になりました。
Dynamic Table とは、ビューのような特性を併せ持つテーブルです。通常のビューは毎回参照元のテーブルを使って集計を行うため、常に最新のデータを参照できるメリットがある一方、パフォーマンスが悪くなるというデメリットがありました。Dynamic Table は非常に頻繁に集計を行いキャッシュしておくことで、より最新の集計結果を常に得ることができる上、パフォーマンスもテーブルと同等レベルになります。
通常のテーブルは頻繁な更新を行うとコストが非常に増大してしまいますが、Dynamic Table は頻繁に変更が入ることを想定して設計されています。そのため、頻繁に更新が入ったしても、更新にかかるコストを低減し、よりニアリアルタイムにデータを集計していくことが出来るようになります。
How to Use
通常のテーブルと基本的には変わりません。既にドキュメントも公開されています。
CREATE DYNAMIC TABLE test_dynamic
target_lag = '1 minute'
warehouse = <warehouse_name>
as
select * from base_1
left join base_2 on base_1.col1 = base_2.col2
ALTER TABLE文を利用することで、Dynamic Tableのニアリアルタイム処理を即時実行・停止・再開することができます。
ALTER DYNAMIC TABLE test_dynamic REFRESH;
ALTER DYNAMIC TABLE test_dynamic SUSPEND;
ALTER DYNAMIC TABLE test_dynamic RESUME;
これまで、データの同期についてあれこれ考える必要があったものの、Dynamic Table を利用することで悩むことがなくなりそうですね。
なお、Dynamic Tableではユーザー定義関数が利用できないなど、機能制限があるため注意が必要です。
データ変換ツールの dbt でも近々 Dynamic Table が作れるようになりそうです。
なお、Dynamic Table はほとんどの場合、Snowpipe Streaming というニアリアルタイムでのテーブルへのデータ取り込みと組み合わせで使われます。
パフォーマンス改善
オープニングの基調講演では、15%のクエリ速度改善があったそうです。Snowflake はクエリの実行時間に対する課金なので、単純に売上が15%失われるわけです。それでもユーザーのために改善を続けてくれるのは嬉しいですね。
GitOps & DevOps の強化
Snowflake 内の開発体験を向上させるため、以下のような機能がアナウンスされました。
近年。データエンジニアリングにソフトウェアエンジニアリングのプラクティスが持ち込まれてきていますが、その流れを追従していますね。また、Native Appを普及させるためにも、開発体験の向上は必須です。
- Snowflake CLI を強化し、外部ツールから Snowflake リソースを作成・実行などをコントロール可能
- Git を統合し、SQL, Snowpark, Streamlit, Native App を実行・デプロイ可能
- ローカルテスト
- Email 通知
- データ変更をトリガーに Task を実行可能
- Python Task APIs: Task ワークフロー を Python API 経由で実行・スケジューリング
個人的に気になったのはローカルテストですが、デモを見ていた中では、snowflake-vcrpyを利用した pytest のラッパーのようでした。VCRは初回アクセス時の結果をローカルに保管しておき、二度目以降はそちらを利用する、というものです。そのため、完全に Snowflake 環境をローカルで実行できるというわけでは無いかもしれません。
詳細は以下のブログを確認ください。
Snowpark 関連のアップデート
Snowpark 周辺のアップデートもかなり多く来ていました。
- Python 3.10 へのサポート
- 外部ネットワークアクセス
- Snowpark ML API
- UDAF: ユーザー定義集計関数
- Vectorized UDTF
特に、これまで Snowflake のリソース(プロシージャや関数)から外部ネットワークへのアクセスが出来ないことはかなり制約を生み出していました。外部ネットワークアクセスが解禁されたことで、OpenAI API などへアクセスし結果を取得するようなことが実現できるようになりました。
詳細は以下のブログを確認ください。
Stremlit on Snowflake
Snowsight から、Streamlit アプリが作成できる機能が Public Preview になりました。インフラストラクチャを準備する必要なく、Snowflake 内のデータを利用した Streamlit アプリケーションをさっと作成できます。また、同一アカウント内の他ユーザーとのシェアも簡単に出来るようになりました。
これにより、エンジニアがより簡単にデータアプリケーションを作成することが出来るようになります。社内の簡単なアプリケーションや、BI 代わりに Streamlit を使うことが出来るようになりますね。
なお、Streamlit では、最近st.experimental_connectionというコネクター関数が登場して、Snowflake に簡単に接続できるようになりました。そのため、Snowflake 外でホスティングする Streamlit でも利便性が向上しています。
Snowflake Connector
昨年の Summit で、Google Analtics などの SaaS ツールに対する ETL コネクタが発表されました。
今年は MySQL や PostgresQL といったデータベース向けのコネクタの追加が発表されました。
SaaS ツールのコネクタについては、Salesforceとのリアルタイムデータシェアリングでの統合を発表するなど、コネクタの代わりにシェアリングによる提供に方針をシフトしたのかもしれません。
今回特に発表されなかったもの
前回の Summit にてアナウンスがあったものの、今回続報がなかったのが、Unistore です。
特にアプリケーション開発においてほとんどの場合で必須となる OLTP への対応に関わるトピックであり、 Native App の普及に向けて必須となる機能です。ここのアナウンスがなかったのは気になりました。
終わりに
今回の Summit は昨年の Summit にて打ち出された DISRUPT APP DEVELOPMENT をより現実的なものとするような機能群のアナウンスがメインとなりました。Snowflake が AWS, GCP, Azure を統合した次世代のパブリックインフラに姿を変えつつある[2]ことが一層鮮明になってきましたね。
Snowflake が向かう NO LIMIT な未来が一層楽しみになる内容だったかと思います!
来年はサンフランシスコでの開催になりました!
また、7月5日には、SnowflakeSummit を振り返る YouTube ライブも開催されます。ぜひ見てみてくださいね〜!
Twitter でも活動しています。ぜひ交流させてください!
ここまで読んでいただき、ありがとうございました。
-
データを複製して分散させてしまうことなく、常に一箇所に最新の正確なデータが保存されており、それを常に参照することができる状態のこと。この場合、 Snowflake の内部テーブルや各種ツール内にファイルを複製することなく、クラウドストレージ上の同一のファイルを常に参照することで、常に最新で正確なデータが利用可能になります。 ↩︎
-
Snowflake は Single Platform というビジョンを打ち出しており、あらゆるワークロード、データ型、データベースを統一的なプラットフォーム上で扱えることを目指しています。これは従来のパブリッククラウドインフラがユースケースごとに細かくサービスを分割してきたアプローチと逆に向かっています。統一的なプラットフォーム上で統一的な言語体系( SQL )であらゆるリソースとデータを簡単に生成できることにより、学習コストの低下と実装スピードの向上が期待できます。 ↩︎
Discussion