SnowflakeSummit 2022 の激アツ発表をまとめてみた
この記事は何
2022年6月14日から16日にかけてラスベガスで行われたSnowflake Summitでの発表内容をまとめました。
Webサイトによればセッションは313あり、SNSでの発表によると参加者はおよそ1万人とのことで、非常にアツいイベントだったようですね。来年はぜひ行きたい...!
Summitでの発表内容は以下のリンクにておおよそまとめられています。
基調講演では、「TODAY DISRUPT APP DEVELOPMENT」というキーワード掲げられ、アプリケーション開発の領域でのさまざまな革新的な機能が発表されました。
その中でも、
- Unistore
- Snowpark for Python & Streamlit Integration
- Native Applicaton Framework
が今回の発表の目玉になりました。この記事では、これら3つの機能を中心に、Summitでの発表内容をまとめました。
Unistore - OLTPなワークロードをOLAPとシームレスに統合する
Unistoreとは、Snowflake上に構築できる行指向テーブルのことで、オンライントランザクション処理に対応することができるテーブルになります。
Snowfalkeテーブルは列指向の分析向けテーブルであり、MySQLやPostgresQLなどの行指向データベースが得意としていたトランザクション処理に使うことはできませんでした。
また、行指向データベースのデータをSnowflake上で分析できるようにするためには、ETLツールやステージを用いた定期的なロードや、Change Data Captureなどを用いたニアリアルタイムなデータ同期のパイプラインを構築する必要がありました。
今回、Unistoreが登場したことによって、これらのパイプラインの構築が不要になり、トランザクションデータに対するリアルタイムなデータ分析も可能になるとのことです。
この機能は激アツですね・・・! 今作っているいくつかのデータパイプラインやデータアプリケーションの裏側がSnowflakeだけでほとんど構築可能になるので早く使ってみたいですね!
How to Use
以下、Unistoreを使いかたの紹介記事になります。
(記事から抜粋)
CREATE HYBRID TABLE Customers (
CustomerKey number(38,0) PRIMARY KEY,
Customername varchar(50)
);
-- Create order table with foreign key referencing the customer table
CREATE OR REPLACE HYBRID TABLE Orders (
Orderkey number(38,0) PRIMARY KEY,
Customerkey number(38,0),
Orderstatus varchar(20),
Totalprice number(38,0),
Orderdate timestamp_ntz,
Clerk varchar(50),
CONSTRAINT fk_o_customerkey FOREIGN KEY (Customerkey) REFERENCES Customers(Customerkey),
INDEX index_o_orderdate (Orderdate)); -- secondary index to accelerate time-based lookups
UnistoreのテーブルはHybrid Tableと呼ばれ、トランザクションデータを他の分析データと混在させることができます。HTAP(Hybrid Transaction Analytical Processing)と呼ばれる領域に属する機能ですね。
この例を見るとわかるように、プライマリキー制約やインデックスなどを張ることができます! これまではNOT NULLしか有効化できなかったので嬉しいですね。
Unistoreでは、トランザクションデータを即座にSQLで分析できるだけでなく、通常のテーブル(列指向テーブル)とのJOINもできます。当然、データシェアされたテーブルともJOINできるそうです。夢のある話ですね・・・!
パフォーマンスについて明確に記述のある公式ドキュメントは見つけられませんでしたが、Summitでは数千TPS程度というアナウンスがあったようです。ちょっとしたアプリケーションであれば十分な性能になりそうですね。
現地参加していた方のTwitterには、将来的にはタイムトラベルやダイナミックデータマスキングにも対応予定だと書いてあったので、そちらも楽しみですね。
Snowpark for Python & Streamlit - Pythonでのプログラマビリティの向上
二つ目の目玉はPythonサポートを強化し、Snowflake上でPythonアプリケーションの構築を便利にするニュースたちです。
Snowpark for Python
Snowparkは、Snowflakeコネクターの一種ですが、開発者が作成した機械学習ロジックなどをSnowflakeにユーザ定義関数(UDF)などの形でデプロイすることができる機能を備えたツールです。
Snowparkを使うことで、開発者は使い慣れた言語で、Snowflake上のデータをローカルにデータがあるかのように分析ができ、さらに、分析結果や作成したモデルをSnowflakeにデプロイすることができます。
これまで、JavaやScala版が先行して利用可能になっていましたが、今回のSummitで、Python版がついにパブリックプレビューになりました。
去年この動画を見てから半年、、、長いようで短かった。
今回のSummitでは、SnowflakeのWebコンソール(Snowsight)上でPythonが動く様子も紹介されていました(プライベートプレビュー)。早く試してみたいですね〜〜!
また、機械学習向けにメモリサイズの大きいウェアハウスも今後登場予定とのことでした。
パブリックプレビューなので誰でも試すことができます。チュートリアルもありました。
Streamlitとの統合
Snowflakeが買収したStreamlitとの統合機能についても発表がありました。
ちなみに、買収時に出したメッセージでも、Summitでのなんらかの発表を匂わせていましたね。
Streamlitは、Pythonコードだけで、UIを含めたアプリケーションが作成できるライブラリで、現在OSSとして提供されています。そのため、Snowflake connector for Pythonを利用してStreamlitからSnowflakeを利用することはすでに可能です。
今回のSummitでは、Snowsight上でStreamlitのコードを書くことができるようになると発表されました。
デモ動画が上がっていたので、こちらを見ていただくと良いかと思います。
(上記動画から抜粋)
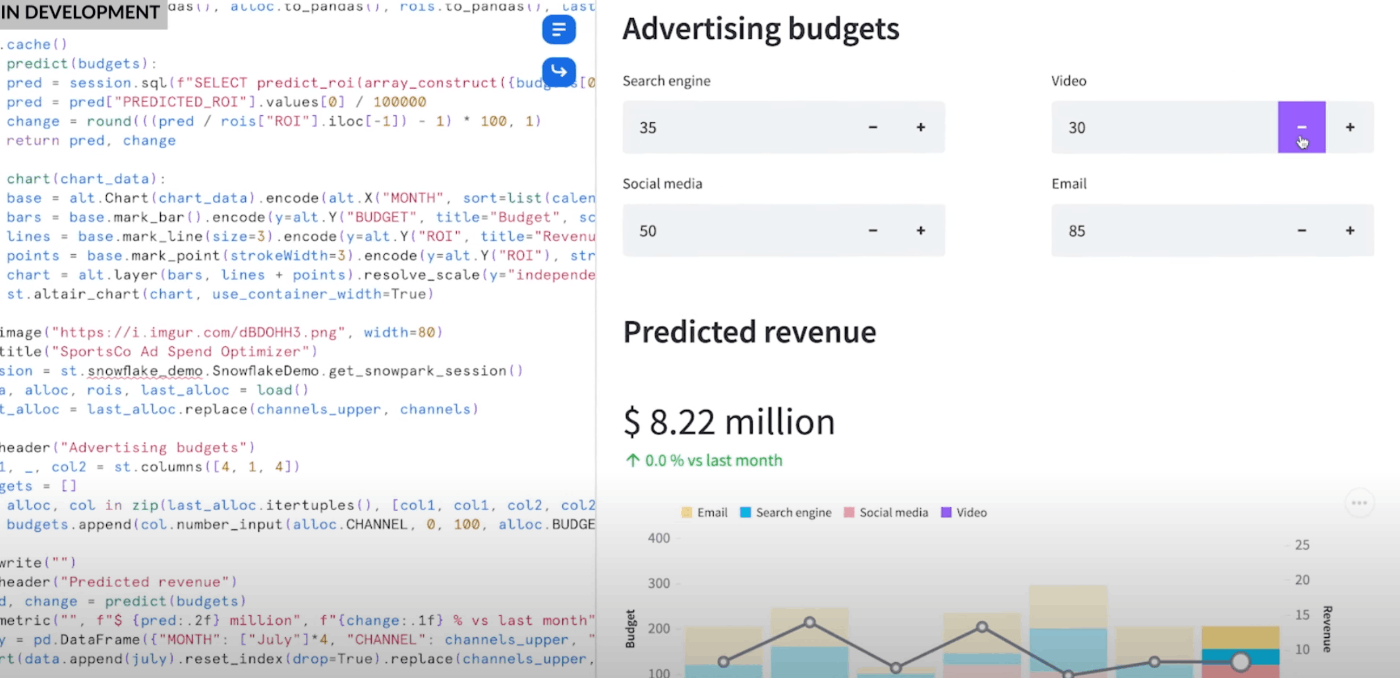
このような形で、スライダーや入力欄を含めたインタラクティブなアプリケーションがSnowsight上で動くようになるそうです。また、将来的にはこのアプリケーションを他のユーザーにシェアすることも可能になるそうです。
Native App Framework - アプリケーションをシェアしよう
そして、3つ目は、 Native Application Frameworkです。
Snowflakeの特徴の一つに、「データシェアリング」という機能がありました。これは、Snowflakeを通じて、他社と安全かつリアルタイムにデータを共有することができるという機能です。
今回、データだけでなく、アプリケーションまでシェアリングすることができるようになりました。これまでもUDFなどを共有することでアルゴリズムを共有することなどができたのですが、それを拡張していった形になります。
Native Application Frameworkでは、UDFやプロシージャに加え、前述したStreamlitのアプリケーションのシェアが可能になります。そして、アプリケーションを販売するためのマーケットプレイスの提供も始まり、マーケットプレイスからアプリをインストールすると、自社のデータを他者に提供することなく、アプリケーションで操作できるようになります。
データシェアリングと同じく、アプリも、提供者にお金が支払われる仕組みになっています。アプリなら個人開発のハードルも低いので、一攫千金も夢じゃないかもしれませんね・・・?
なお、Native Application Frameworkは、Connected Applicationという考え方に基づいたものであり、近年主流となっているManaged Applicationとはやや異なる思想になっています。
以下の記事でより詳細について紹介されています。
これまでに、Goldman Sachs, LiveRamp, Capital One, Habuといった企業がNative Applicationを開発しているそうです。
実例: Capital One - SLINGSHOT
例えば、Capital OneのSlingShotアプリケーションは、Snowflakeの利用料金を安くしてくれるために、色々な提案をしてくれるようです。
アプリケーションの説明欄には、以下のように書かれており、何らかの自動化やクエリパフォーマンスチューニングなどを頑張ってくれるようですね。
Capital One built tools that saved 50K hours of manual effort, reduced spend by 27% and reduced cost per query by 43%.
インストールされたアプリケーションは、Snowflake利用状況が把握できる各種データにアクセスしていろいろと分析してくれるのだと思いますが、データがCapital Oneに送られることはないので、安心してインストールすることができますね。
実際にどうやって開発するのだろう、と思い、デモ動画などを探しましたが、見つけることはできませんでした。もしご存知の方いらっしゃったら是非教えていただきたいです。
その他の発表について
さて、ここまででもうお腹いっぱいなので、残りはサラッと流していきたいと思います。
最初に紹介したこの記事から抜粋していきます。
パフォーマンス改善
AWSにおける10%の計算高速化、ストレージ圧縮率30%効率化、書き込みワークロードの10%効率化、ジオデータに対する検索500%高速化、レプリケーションレイテンシ55%効率化、など。こういう改善が一番嬉しい。
リソースモニターの改善
リソースグループ機能を使って、リソースモニタリングがより柔軟に設定できるようになるそうです。
データガバナンス機能の強化
タグベースマスキングなどの機能の提供が行われるようです。
ストリームデータ処理の強化
ストリーミングの高速化および、Materialized Tableによる高速なストリーミングデータの統合を提供するようです。データエンジニアの身としては嬉しい機能提供ですね。
Materialized Viewはテーブルのjoinが出来なかったので利用用途が限定的でしたが、Materialized Tableはテーブルのjoinにも対応しているとのことで、使えるシーンが多いのではないかと思います。
Apache IceburgのファイルをSnowflakeから操作可能に
IceburgのファイルをSnowflakeから普通のテーブルのように操作できるようになる機能です。意外と反響が大きい機能のようでした。
SQLによる機械学習
BigQueryMLのような、SQL-likeで機械学習ができるようになる機能です。時系列予測から対応予定のようです。
CyberSecurity Workload
Unistoreに先行して、Summitの数日前にアナウンスされていたもう一つの新しいワークロードです。
Unistoreの影に隠れてしまっている気がする...。
SaaSコネクタ
ServiceNOWとGoogleAnalytics4のコネクタが発表されました。Snowflakeに直接データを入れやすくなるので嬉しいですね。
終わりに
基調講演で強調されたテーマである 「TODAY DISRUPT APP DEVELOPMENT」 にふさわしい機能が多く発表され、どの機能も早く使ってみたい気持ちでいっぱいになりました。
ここまで読んでいただき、ありがとうございました!
最近Twitterも始めたので、ぜひ仲良くしてもらえればと思います!
追記: SnowVillageでの報告会
Snowvillageでの報告会動画も上がっていました! とてもわかりやすく、楽しくなれる動画です!
Discussion