音声認識技術を全く知らないWebエンジニアが、E2E解説文論を頑張って読み解く(後半:E2Eをつかってみる)
はじめに
音声認識ど素人がE2Eを学習した記録です。
本記事は前半のE2Eの概要と後半の実践に分かれています。
前半はこちら
本記事では、「3. E2E 音声処理の実践」に書かれたESPnet2の実践を読み解きます。また、実際にGoogle Colaboratory でデモを実装します。
なお、本記事では筆者が知らなかった単語をいちいち解説しますが、知っていたら読み飛ばしてください。
Google Colaboratoryの完成版ノートブックはこちら
ESPnet2_ASRとTTSのデモ.ipynb
なお、「3.4 レシピを利用したモデル構築」以降は内容が高度すぎてついていけなかったため、省略します。
m(_ _)m
この記事でやること
- ESPnet2の概要
- ASR,TTSのデモ
3.1 ESPnet2
ESPnetは、エンドツーエンドの音声認識、テキスト読み上げ、音声翻訳など、音声に関する処理をカバーするエンドツーエンドの音声処理ツールキットです。
ESPnet2の実装要件
ESPnet2は、Linux環境での利用を想定しており、必要動作要件は以下の通りです。
実装要件
- Python 3.7+
- gcc 4.9+ for PyTorch1.10.2+
OS要件
- ubuntu(Linuxの兄弟1)
- centos(Linuxの兄弟2)
- debian(Linuxの兄弟3)
ちなみに、Google ColabはUbuntuで動いています。
3.2 環境構築
デモコードは解説文論ではなく、ESPnet2公式サイトを参考にしています。これは解説文論が2020年記載のため、現在のESPNet2バージョンだとうまく動かなかったためです。
次のESPnet2を含む、次のパッケージをインストールします。
!pip install -q espnet==v202301
!pip install -q espnet_model_zoo
# ASRで使うパッケージ
!pip install librosa pysndfile
# TTSで使うパッケージ
!pip install typeguard==2.13.3
Google Colabではコマンド実行時に「!」をつけます。
パッケージの概要は以下です。
- espnet...E2E方式の音声処理ツール
- espnet_model_zoo..ESPnetで作成された、事前トレーニング済みモデル一覧
- librosa...オーディオ分析用のPythonパッケージ
- pysndfile..音声ファイルの読み書きができるパッケージ
- typeguard...型ガード、バージョンを変えると動かなくなったので注意
ESPnet2では、研究データ共有リポジトリであるZenodo(espnet_model_zoo)と連携していて、様々な事前学習モデルを簡単に試すことができます。
3.3 事前学習モデルを利用した推論 TTS(音声合成)
ESPnet2でのTTS(音声合成)の流れは、2STEPのみです。
- STEP1.事前学習されたモデルから、Text2Speechインスタンスを構築
- STEP2.インスタンスに音声合成したいテキストを渡す
STEP1.事前学習されたモデルから、Text2Speechインスタンスを構築
インスタンス構築のためのコードを載せます。
from espnet2.bin.tts_inference import Text2Speech
from espnet2.utils.types import str_or_none
text2speech = Text2Speech.from_pretrained(
model_tag=str_or_none('kan-bayashi/ljspeech_vits'),# 英語の音声合成モデル
device="cuda",
# Only for Tacotron 2 & Transformer
threshold=0.5,
# Only for Tacotron 2
minlenratio=0.0,
maxlenratio=10.0,
use_att_constraint=False,
backward_window=1,
forward_window=3,
# Only for FastSpeech & FastSpeech2 & VITS
speed_control_alpha=1.0,
# Only for VITS
noise_scale=0.333,
noise_scale_dur=0.333,
)
from_pretrained()メソッドより、音声合成のためのインスタンスを構築します。
引数model_tagはespnet_model_zooパッケージのタグがサポートされており、使用するモデルを指定します。
今回使用するモデルはkan-bayashi/ljspeech_vitsで、英語の音声合成用モデルです。
また、引数deviceは推論に使用するデバイスを指定します。cudaかcpuを指定してください。
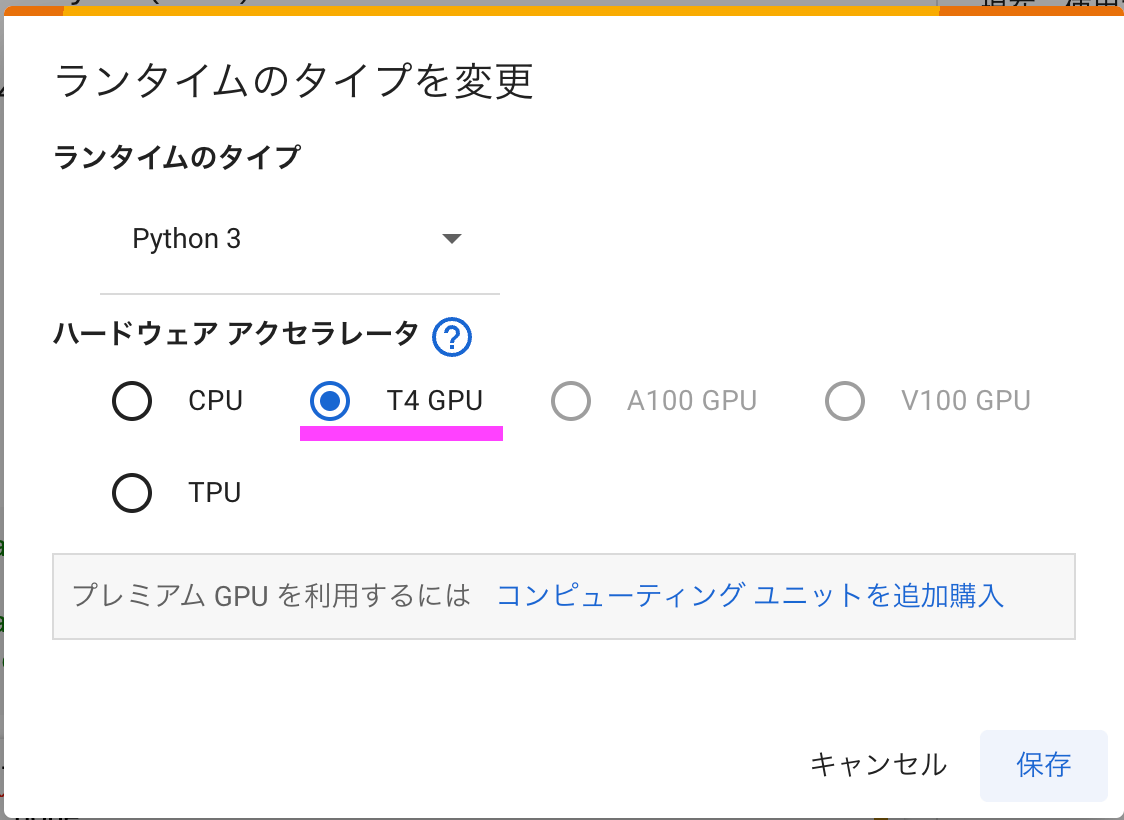
無料版のGoogle Colabでも、ランタイプが「T4 GPU」の場合、cudaを使用することができます。
Google Colabの利用者が多いとき、自動で「CPU」になっている場合があります。その時はcudaを使用できないため、device="cup"としてください。
CUDAとは?
CUDA(クーダ)は、GPU上で並列処理を実行するためのソフトウェア開発環境です。Compute Unified Device Architectureの略です。
GPUは、画像処理やコンピューターグラフィックスなどの、大量の計算を並列処理するための演算装置です。Graphics Processing Unitの略です。
近年、GPUは単純なタスクを大量にこなすことに向いている特性から、画像処理だけでなく、画像認識や音声認識など機械学習の分野でも使われるようになりました。
GPUに似た演算装置にCPUがあります。CPUはコンピューターの頭脳として幅広い処理を行います。個々のタスクを集中して処理する、連続的な演算処理能力に長けているのが特徴です。
CPUとGPUの違いについて、CPUはコンピュータの処理全般に関する計算を担当しますが、GPUは画像処理などの特定のタスクを高速に計算することに特化しています。また、「コア」とよばれる、命令を処理する装置の数がCPUは数個に対し、GPUは数千個のコアを持つことが違いとして挙げられます。

CUDAとCPUの違いまとめ
| 特徴 | CUDA (GPU) | CPU |
|---|---|---|
| 定義 | NVIDIA社のGPUに並列実行させるための開発環境 | コンピューターの主要な処理計算 |
| 用途 | 複雑な計算処理や大規模なデータ処理、機械学習 | 一般的なプログラミング、データ処理、システム操作 |
| アーキテクチャ | 数千の小さなコアを持つ | 数個から数十個のコアを持つ |
| 処理能力 | 大量のデータや単純な計算を大量に行う作業に向いている | 一般的な計算タスクや複雑なアルゴリズムに向いている。多様なタスクをこなせる。 |
その他の引数
他の引数のthresholdやminlenratioは公式のサンプルをそのまま設定しています。これらのオプションを外すとRTFが0.05から0.4に一気に上がったため、いい感じに調整してくれているのかと思います。
RTFって?
RTF(Real Time Factor)は、音声認識処理の速度を表す指標です。RTFが小さいほど、リアルタイムに近い処理速度が得られます。
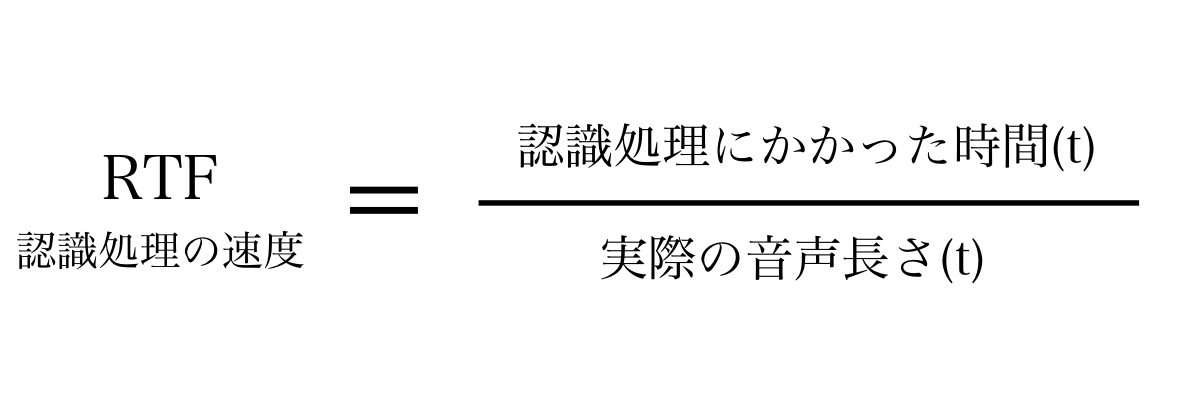
RTFは、音声認識処理にかかった時間を、実際の音声長さで割った値です。例えば、10秒の音声を5秒で処理できた場合、RTFは0.5です。
RTFは、基本的にはRTF < 1 になるように設計します。RTF > 1 となると、処理速度が音声に追いついておらず、処理が終わっていないのに次の音声が来てしまい、システムの処理許容量を超えるとシステムが止まる恐れがあります。
このため、特にオンライン型の音声認識においては、必ず RTF < 1 になるように調整されています。
STEP2.インスタンスに音声合成したいテキストを渡す
STEP1.で作成した、音声合成インスタンスtext2speechにテキストを渡すことで、音声合成を行います。
import time
import torch
# 作成したい音声のテキストを入力(英語で入力してください)
print(f"Input your favorite sentence in {lang}.")
x = input()
# 音声合成
with torch.no_grad():
start = time.time()
wav = text2speech(x)["wav"]
rtf = (time.time() - start) / (len(wav) / text2speech.fs)
print(f"RTF = {rtf:5f}")
# 作成した音声を表示
from IPython.display import display, Audio
display(Audio(wav.view(-1).cpu().numpy(), rate=text2speech.fs))
コードを上から解説します。
# 音声合成
with torch.no_grad():
start = time.time()
wav = text2speech(x)["wav"]
まず、with文で音声合成処理中に勾配計算を無効にし、メモリを節約します。
text2speech(x)["wav"]では、変数x(ユーザーが入力したテキスト)をwav形式の音声ファイルを作成しています。
勾配計算とは
勾配計算とは、微分を使って損失関数の結果が最小になる点を探るための計算です。勾配計算は、機械学習モデルのトレーニングで一般的に使用される手法です。
損失関数とは、機械学習モデルがどれくらい正しく予測できているか評価する指標です。損失関数の値が小さいほど、モデルの予測が正確と言えます。
例えば、家賃と家の広さの関係を取得するための機械学習モデルを作成するとします。家賃と家の広さは相関関係があるとします。一般的に考えて、家賃が高くなれば、基本的に家は広くなります。
しかし、事故物件やその土地の価値によって、実際の家賃とモデルによる予測値との差が生じることがあります。この差が損失関数の値になります。

音声合成では、学習済みのモデルを使用することが一般的です。これらのモデルはすでに最適化されているため、追加の勾配計算を行う必要はありません。
そのため、no_grad()を呼び、勾配計算を無効にしています。
rtf = (time.time() - start) / (len(wav) / text2speech.fs)
print(f"RTF = {rtf:5f}")
RTF(Real Time Factor)の計算をしています。
RTFは、「処理にかかった実時間」を「実際の音声の再生時間」で割ることで求められます。
処理にかかった時間は、現在時刻から処理開始時刻の差(time.time() - start))から求められます。
実際の音声の再生時間は、音声のサンプル数(len(wav))からサンプリングレート(text2speech.fs)を割ることで求められます。
サンプリングレートって?
サンプリングレートとは、アナログ信号をデジタル信号に変換する際の1秒当たりのサンプル数を指します。
単位はHz(ヘルツ)です。
サンプリングレートが高いほど、通常は音声品質が高くなります。例えば、音楽CDのサンプリングレートは44.1kHzです。
一般的にサンプリングレートは高い方が望ましいとされていますが、音声認識の文脈においては、ある一定以上サンプリングレートを高くしても音声認識率は上がらなくなることがあります。これは、人間の発声による音の高さには限界があるためです。
そのため、人の音声を録音する際はサンプリングレートが16kHz程度あれば十分とされています。
ヘルツ(Hz)は、1秒あたりの振動回数を表す単位で、周波数の単位として使用されます。式で表すと、
周波数[Hz] = 振動した回数[回] / 振動するのにかかった時間[s] です。
したがって、音声の長さ[s] = サンプル数[回] / サンプリングレート[Hz]と表せます。
これにより、音声のサンプル数(len(wav))をサンプリングレート(text2speech.fs)で割ることで、実際の音声の長さを計算しています。

結果
「zenn is the best technical article site(Zennは素晴らしい技術記事サイトです)」と入力した結果です。
RTF = 0.027185 とあり、RTF < 1以下のため、いい感じですね。

コードはGoogle Colabで公開しているため、気になる方は試してみてください。
ESPnet2_ASRとTTSのデモ.ipynb
3.3 事前学習モデルを利用した推論 ASR(音声認識)
ESPnet2でのASR(音声認識)の流れも、2STEPのみです。
- STEP1.事前学習されたモデルから、Speech2Textインスタンスを構築
- STEP2.インスタンスに音声認識したい音声ファイルを渡す
STEP1.事前学習されたモデルから、Speech2Textインスタンスを構築
インスタンス構築のためのコードを載せます。
import time
import torch
import string
from espnet_model_zoo.downloader import ModelDownloader
from espnet2.bin.asr_inference import Speech2Text
d = ModelDownloader()
speech2text = Speech2Text(
# モデルのダウンロードとセットアップ
**d.download_and_unpack('Shinji Watanabe/spgispeech_asr_train_asr_conformer6_n_fft512_hop_length256_raw_en_unnorm_bpe5000_valid.acc.ave'),
device="cuda",
minlenratio=0.0,
maxlenratio=0.0,
ctc_weight=0.3,
beam_size=10,
batch_size=0,
nbest=1 # 最良の結果の数
)
引数nbestは推論の結果の数を指定します。基本的に一番上が一番可能性の高い推論ですが、他の候補が見たい場合は、nbestの数を増やして確認してみてください。
STEP2.インスタンスに音声認識したい音声ファイルを渡す
STEP1.で作成した、音声認識インスタンスspeech2textに音声ファイルを渡すことで、音声認識を行います。
from google.colab import files
from IPython.display import display, Audio
import soundfile as sf
import librosa.display
import matplotlib.pyplot as plt
# オーディオファイルからサンプルを取得する関数
def get_samples(audio_file, target_sr=16000):
data, sample_rate = sf.read(audio_file) # オーディオファイルを読み込み
if sample_rate != target_sr:
# サンプルレートが目標と異なる場合は変換
data = librosa.resample(data, orig_sr=sample_rate, target_sr=target_sr)
return data, sample_rate
# ユーザーにファイルのアップロードを促す
uploaded = files.upload()
# アップロードされた各ファイルに対して処理
for file_name in uploaded.keys():
sample, rate = get_samples(file_name) # サンプルとサンプルレートの取得
nbests = speech2text(sample) # 音声認識を実行
text, *_ = nbests[0] # 最良の結果を取得
# 結果の表示
print(f"Input Speech: {file_name}")
librosa.display.waveshow(sample, sr=rate) # 波形を表示
plt.show()
print(f"ASR推論: {text}") # 認識結果の表示
get_samples()メソッドで受け取った音声ファイルのサンプリングレートを取得します。ここで、もしサンプリングレートが16kHzではない場合、16kHzに変換します。これは、speech2textインスタンスのデフォルトのサンプリングレートが16kHzに設定されており、異なるサンプリングレートの場合、エラーになるためです。
結果
「zenn is the best technical article site(Zennは素晴らしい技術記事サイトです)」と発音した音声ファイルを渡した実行結果です。
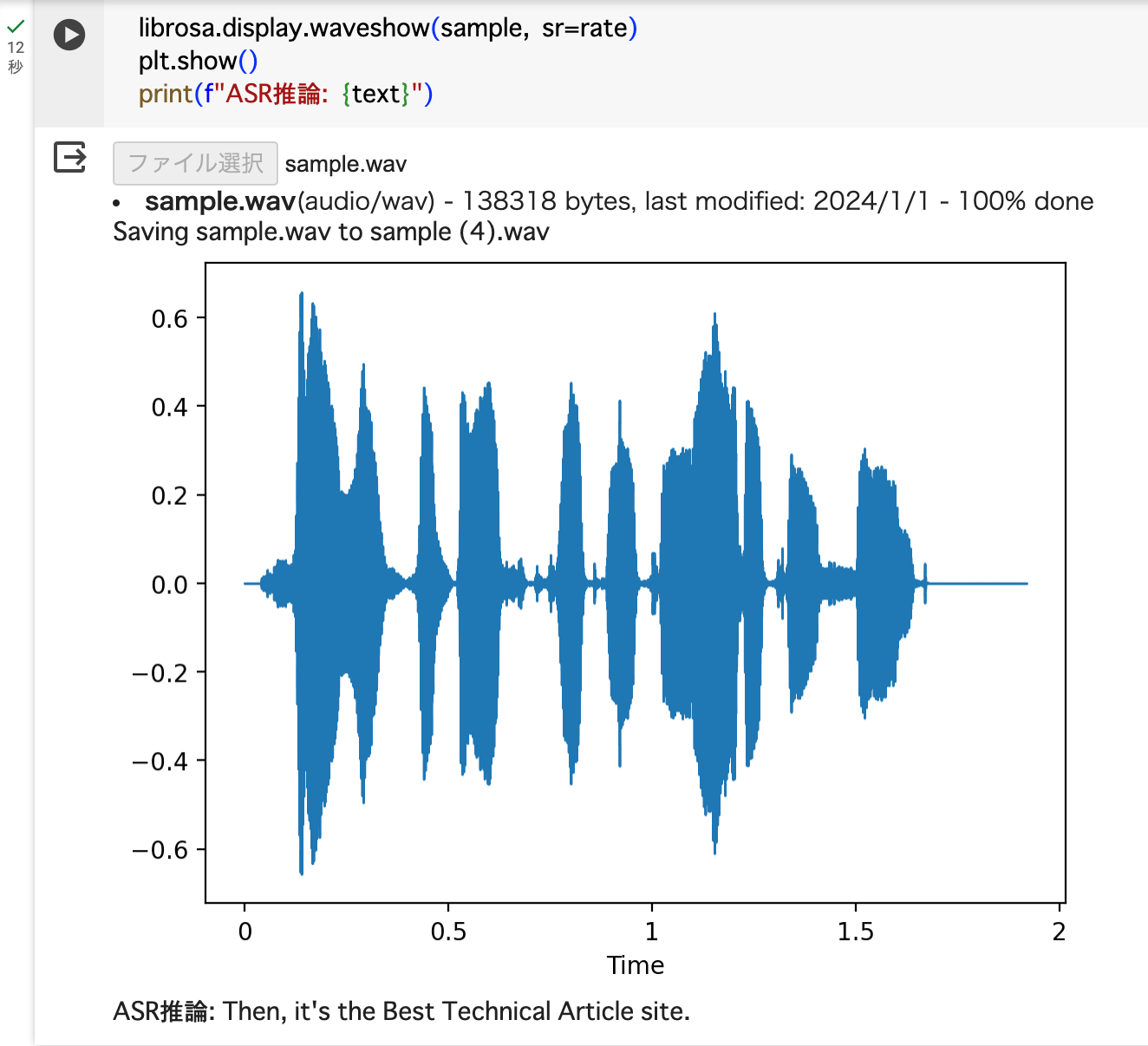
# 音声ファイル
zenn is the best technical article site
↓
# 推論結果
Then, it's the Best Technical Article site.
Zenn(ゼン)がThenになっていますが、概ね合っているのではないでしょうか。
音の波形の見方について、解説します。
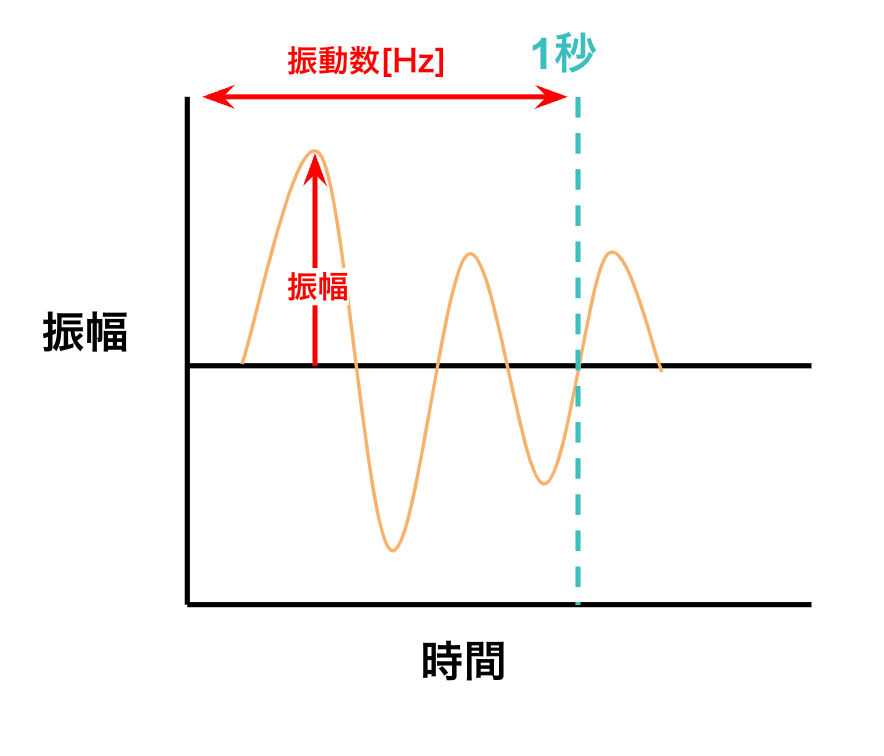
振幅とは、振動の振れ幅のことです。音の大きさは振幅が大きいほど大きくなります。
また、周波数(Hz)の値が大きいほど音は高くなります。図を見る時は、音の波形が詰まっているほど、音が高いことを表しています。
おわりに
今回は「3. E2E 音声処理の実践」に書かれたESPnet2の実践を読み解きました。
参考
RTFについて
CUDAについて
サンプリング・レートについて
Discussion