音声認識技術を全く知らないWebエンジニアが、E2E解説文論を頑張って読み解く(前半:E2Eの概要)
はじめに
私は普段Web開発のお仕事をしています。ご縁があって、音声認識に関する案件に携わることになったため、学習しています。本記事は、音響学会誌で刊行されたの解説文論「End-to-End音声処理の概要とESPnet2を用いたその実践」を素人が読み解き、なんとかまとめた記事です。
初めてこの文論を読んだ時は目が滑って頭に入らなかったですが、何回も読み直していくうちに理解できるようになりました。端的に必要な情報をまとめられていて、素晴らしい解説文論です。このような資料を無料で公開してくださった、林 知樹(株式会社 Human Dataware Lab.)さま、誠にありがとうございます。
文論では「理論」と「実践」の二部構成になっており、本まとめ記事でも前編と後編で分けます。
今回は「理論」についてまとめます。
「1.はじめに」
深層学習の発展に伴い,音声処理の分野でも,すべての処理をニューラルネットワークのみで完結させる End-to-End(E2E)アプローチが有力な選択肢の一つとなりつつある。
1行目から知らない単語がどんどん出てきて面食らっていますが一つ一つ見ていきましょう。
深層学習(ディープラーニング)って?
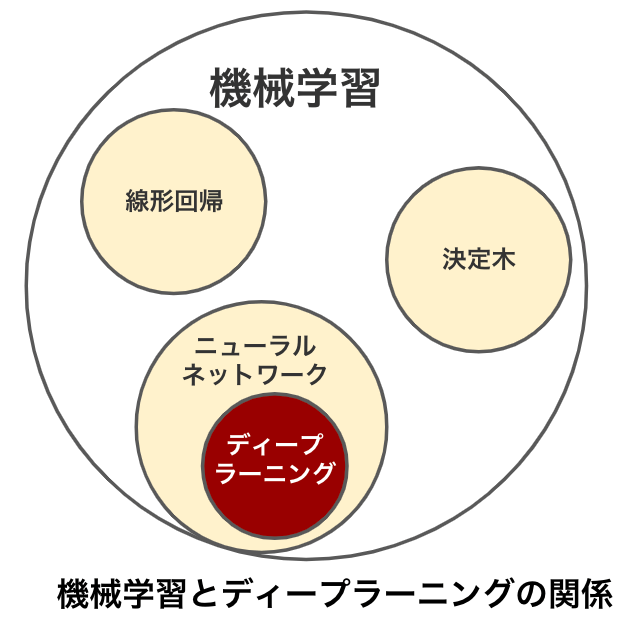
近年、注目されている深層学習(ディープラーニング)は、機械学習の手法の1つです。深層学習(ディープラーニング)は、ニューラルネットワークを用いて、人間の脳のように学習する機械学習の手法です。深層学習(ディープラーニング)は画像認識や音声認識、自動運転など、さまざまな分野で成果を出しています。
機械学習にはさまざまな手法が存在し、有名なのは「決定木」、「線形回帰」、「ニューラルネットワーク」などがあります。
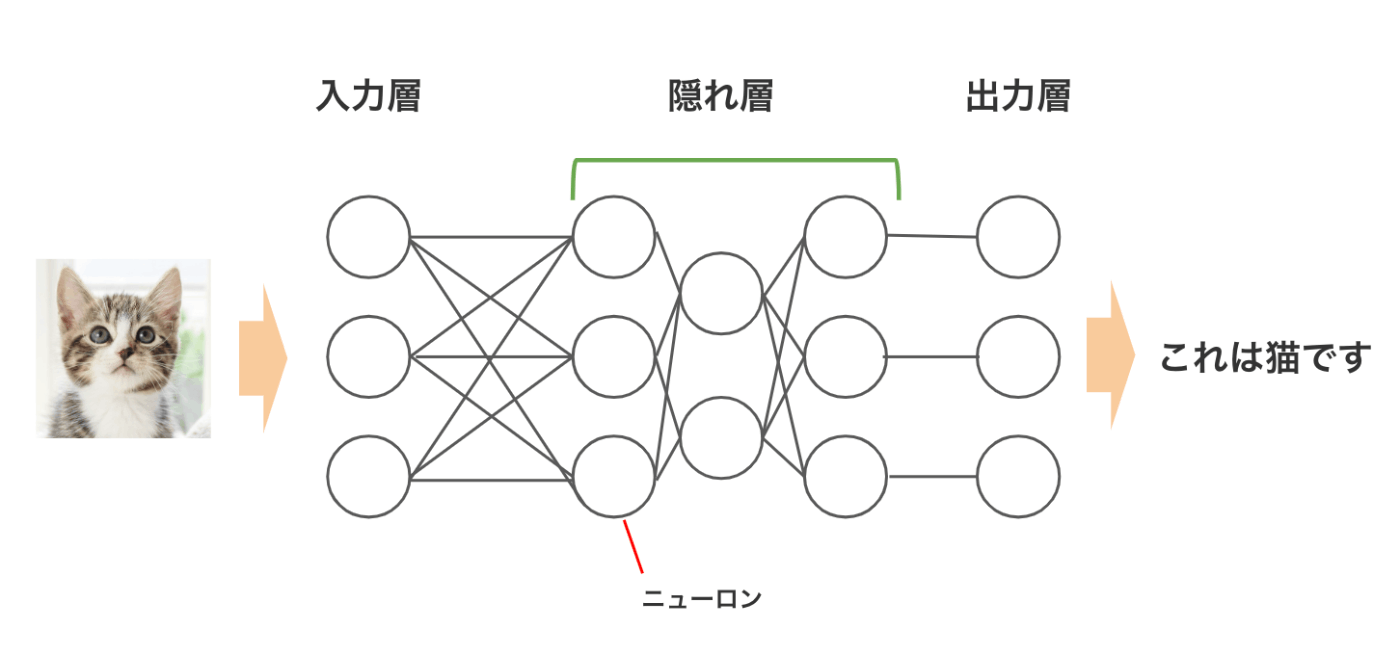
ニューラルネットワークとは、人間の脳内にある神経細胞(ニューロン)とそのつながりを模した機械学習のモデルです。

ニューラルネットワークは、入力層、出力層、隠れ層から構成されます。入力層はデータを入力する層、出力層は結果を出力する層です。そして隠れ層は入力層からデータを引き継ぎ、さまざまな計算を行います。隠れ層が多いほど複雑な分析ができ、隠れ層が3層以上あるニューラルネットワークをディープラーニングと呼びます。
End-to-End(E2E)アプローチって?
ディープラーニングの手法の一つにEnd-to-End(E2E)アプローチが存在します。E2Eの読み方はツーエンドだそうです。
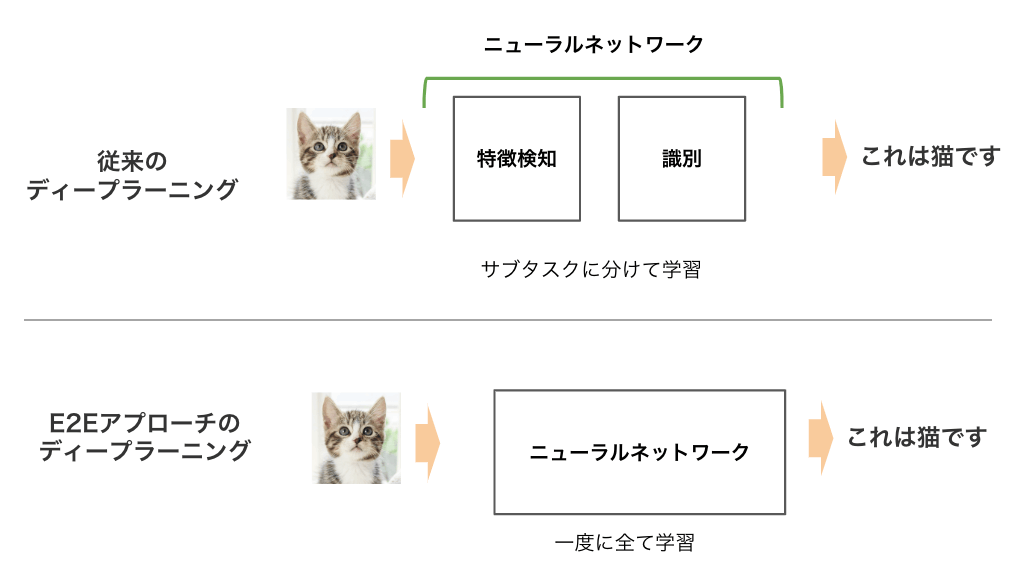
E2Eアプローチは1つのタスクに対して,ニューラルネットワーク中の入力層から出力層までの全層を一貫して学習する学習手法です。逆に、1つのタスクを、2つ以上のモデルで手分けして,それぞれ個別にモデルを学習する場合は、E2E学習とは言いません。
もう一度1行目を見てみましょう
深層学習の発展に伴い,音声処理の分野でも,すべての処理をニューラルネットワークのみで完結させる End-to-End(E2E)アプローチが有力な選択肢の一つとなりつつある。
つまり、「音声認識の分野でE2Eアプローチが有効な手段」、と仰っているのでしょう。
音声認識(ASR)の分野では,大規模コーパスを利用したベンチマークにおいて,従来のニューラルネットワークと隠れマルコフモデル(HMM)のハイブリッドシステム(DNN-HMM)を上回る性能が報告されている
ははは、また目が滑りそうな2行目ですが(素人)、一つずつ読み解きます。
音声認識(ASR)って?
音声認識技術(ARS)は、人が話した声を文字テキストに変換する技術です。
ASRはAutomated Speech Recognition、自動音声認識の略です。
音声認識の学習用データには大量のコーパスが必要です。「コーパス(Corpus)」とは、文章や音声を大規模に収集したデータベースのことです。
隠れマルコフモデル(HMM)のハイブリッドシステム(DNN-HMM)
音声認識を行うモデルの一種に隠れマルコフモデル(HMM)があります。隠れマルコフモデルの説明は省きますが、よく使われているモデルなんだなと思っておけば大丈夫です。
End-to-End(E2E)アプローチは隠れマルコフモデルより後にでた技術で、従来の方式より精度が高くなっています。

もう一度、2行目を見てみましょう。
音声認識(ASR)の分野では,大規模コーパスを利用したベンチマークにおいて,従来のニューラルネットワークと隠れマルコフモデル(HMM)のハイブリッドシステム(DNN-HMM)を上回る性能が報告されている
つまり、「音声認識の分野でも、E2Eアプローチは従来のモデルより高性能だよ」、と仰っているのでしょう。
End-to-End(E2E)アプローチの利点
E2Eアプローチの利点を文論では以下のように述べています。
- 系列から系列への変換問題として、様々なタスクを統一的な枠組みで扱える点
- システム全体を同時に最適化できる点
な、なるほど。。。
E2Eの利点①:系列から系列への変換問題として、様々なタスクを統一的な枠組みで扱える点
系列から系列、というのは音声系列からテキスト系列への変換を指しています。
従来では、この音声からテキストへ変換する際、複数のサブタスク(音声の特徴抽出、音韻モデリング、単語認識など)が必要でした。
しかし、E2Eアプローチでは、音声認識のプロセスを一つのモデルで行います。一つのモデルにすることにより、設計がシンプルになります。
E2Eの利点②:システム全体を同時に最適化できる点
従来のモデルでは、サブタスクをそれぞれ個別に最適化し、さらにサブタスク同士の繋ぎこみを調整する必要がありました。E2Eアプローチでは、システム全体が一つのモデルとして機能するため、このモデルをトレーニングすることで、すべての部分が連動して最適化されます。
「1.はじめに」のまとめ
音声認識の分野においてEnd-to-Endアプローチは有効な手段である。
End-to-Endアプローチはのシステム全体に一つのニューラルネットワークを持つという特徴があり、従来の隠れマルコフモデルよりも高性能である。
「2. 最近のE2E音声処理の研究動向」
2.1 音声認識分野(ASR)における発展
E2E-ASRモデルの発展について、以下のような傾向が挙げられます。
- ポイント1.認識性能の向上
- 従来のDNN-HMMハイブリッドモデル(隠れマルコフハイブリッドモデル)より高い性能
- ポイント2.複合的なタスク処理ができるようになる
- 高音と低音を別音源で流す、マルチチャネル信号に対応
- 発話に対しさらに発話を重ねるオーバーラップに対応
- ポイント3.推論の高速化、ストリーミング化
これらの発展の要因の一つにNLP(自然言語処理)で流行した技術がASR(音声認識技術)に流用されている背景があります。
今後はASRだけでなくNLPなど他の分野の動向も追っていく必要があります。
E2E-ASRモデルについて
E2E-ASRモデル(E2Eアプローチの音声認識技術)には、一般的に以下のようなモデルが存在します。
- CTC:Connectionist Temporal Classification
- RNN-T:RNN Transducer
- Attention S2S:Attentionを用いたSeq2Seq
それぞれ、重要なモデルのため1つづつ解説していきます。
CTC(Connectionist Temporal Classification)
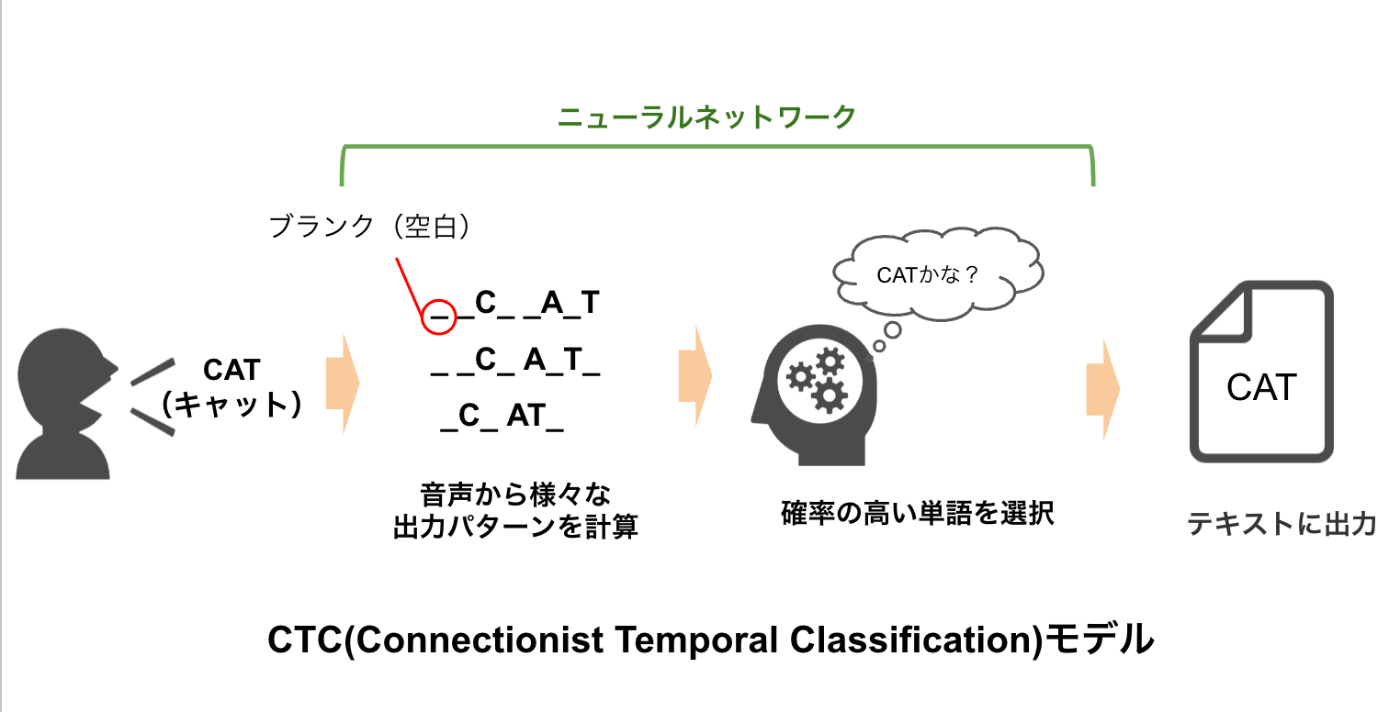
CTCは、音声の各フレーム(音の区切り)がどの文字に対応するかを識別する手法です。
CTCは、音声波形をフレームに分割し、各フレームがどの文字に対応するかを予測します。空を意味する特殊記号「_(ブランク)」を導入することで、音声の区切りを表現します。
CTCはフレームごとに文字を出力する他に、過去の出力を参照しないという特徴があります。そのため、音声が長くなると、正確性が低下する傾向があります。
具体的な例
音声「キャット(CAT)」を認識する場合、以下のような「_(ブランク)」と文字のパターンが考えられます。
_ _C_A_T_
_C_A_T_
_C_AT_ _
...様々なパターンが存在
この中から、最も確率の高いパターンを選んだ後、ブランクを削除することで、テキスト出力しています。
RNN-T(RNN Transducer)
RNN-Tは、CTCを拡張したEnd-to-End音声認識モデルです。
CTCと同様に、音声波形をフレームに分割し、各フレームがどの文字に対応するかを予測します。しかし、CTCとは異なり、過去の出力を参照することで、より正確な認識を実現しています。
これにより、CTCよりも長い音声でも、精度が高く認識できるようになります。ただし、RNN-Tは、CTCより精度が上がる分、計算量が大きくなります。
Attention S2S(Attention Sequence-to-Sequence)
Attention S2S(注意機構型 S2S)モデルは、E2E音声認識モデルの中で最も高い認識精度を達成しているモデルです。
Attentionは、入力データのどの部分が重要かを文脈から分析するメカニズムです。
Sequence-to-Sequence(S2S)は、ある配列を別の配列に変換するモデルです。音声認識のS2Sでは、音声配列からテキスト配列に変換します。
E2E-ASRモデルのまとめ
| モデル | 特徴 | メリット | デメリット |
|---|---|---|---|
| CTC | 最もシンプル | シンプルで理解しやすい、学習データの準備が容易 | 音声波形の系列が長くなると正確さが低下 |
| RNN-T | CTCを拡張 | CTCよりも正確な音声認識が可能、学習データの準備が容易 | CTCよりも計算量が大きい |
| Attention S2S | Attentionを用いたSeq2Seqモデル | CTCやRNN-Tよりも正確な音声認識が可能、CTCやRNN-Tよりも柔軟な表現が可能 | CTCやRNN-Tよりも学習データの準備が複雑 |
2.2 テキスト音声合成(TTS)における発展
E2Eアプローチを用いたテキスト音声合成(TTS)において、以下のような傾向が挙げられます。
- ポイント1. 品質や安定性の向上
- 従来は非常に長いテキストや同じ単語が繰り返されると、音声の欠落があった
- Attention技術を活用することで、音声信号のノイズなどの影響を受けにくい認識を実現
- ポイント2. 可制御性の向上
- 従来は複数話者の音声合成や発話様式の変更が困難であった
- 近年、生成音声のピッチ制御を行うモデルが登場している
- ポイント3. 生成速度の向上
「2. 最近のE2E音声処理の研究動向」まとめ
最近のE2E-ASR(音声認識技術)は「認識性能の向上」「複雑なタスク処理が可能になる」など発展を遂げています。
また、E2E-TTS(テキスト音声合成)においても「品質向上」「生成速度の向上」など、日々進化しています。
おわりに
「End-to-End音声処理の概要とESPnet2を用いたその実践」の解説を行いました。
音声認識は全くの畑違いですが、こうして新しい技術を学ぶのも面白いですね^^
Discussion