ベクトル検索の苦手を克服。ナレッジグラフでRAGを作る
TL;DR
- ベクトル検索だと、複数のステップを踏まないと答えられない質問の検索がむずい
- 「TomにEmil Eifrém(Neo4jのCEO)を紹介してくれる人は?」とかを検索むずい
- ナレッジグラフは構造化データと非構造化データをうまく扱えてベクトル検索の苦手を補える
- 課題はあるけどナレッジグラフは、Neo4jとLangchainで構築できるよ。
はじめに
今回はベクトル検索の苦手分野をどうしても補ってあげたいとおもっている筆者やまぐちが、ベクトル検索の苦手を補ってあげられるナレッジグラフに関してまとめていこうと思います。
少々長い記事ですが、ベクトル検索を労ってあげたいと思っている方はぜひ読んでください。
ベクトル検索の限界
以前の記事の最後にも少しだけ記載しましたが、ベクトル検索は以下の問題点があります。
- 必要な情報がTop Kのドキュメントには含まれていない可能性がある。
- チャンクのサイズによってはエンティティへの参照が失われる可能性もある。(チャンクごとの繋がりがなくなり)
- 上記を解決するためのドキュメント数がわからない。
この問題点が起こす問題は「複数のステップを踏まないと答えられない質問に対して検索ができない」です。
例えば以下のような質問をベクトル検索に使うのは難しいでしょう。
- TomにEmil Eifrém(Neo4jのCEO)を紹介してくれる人は?
- ALOX5遺伝子とクローン病との関係は?
- 特定のマイクロサービスに障害が発生した場合、製品にどのような影響がありますか?
- フライトの遅延はネットワークを通じてどのように伝播するのか?
- ソーシャルメディアへの投稿がバイラルになった場合、どのユーザが信用されますか?
referenced by https://medium.com/neo4j/knowledge-graphs-llms-real-time-graph-analytics-89b392eaaa95
「TomにEmil Eifrém(Neo4jのCEO)を紹介してくれる人は?」のような質問に答えるには、自分の知り合いを辿ってEmil Eifrémさんと知り合っている人まで関係を追っていかないといけません。
例えばの文章を見ていきましょう。以下の文章はGPTに適当に作らせたデタラメな文章なので、読む必要はないです。
EmilとTomに関しての文章例
Emil Eifrémは、グラフデータベースの先駆者であり、Neo4jの共同創設者です。彼のビジョンは、複雑なデータ関連性の管理と処理を革新することにありました。Emil Eifrémは、Johan Svenssonと共にNeo4jを開発し、グラフデータベース技術の商用化を推進しました。彼らの共同作業は、データ分析の分野において大きな影響を与え、リンクされたデータの処理を大幅に改善しました。
また、Emil Eifrémは多くの技術者や起業家と協力し、グラフデータベースの普及を促進しました。彼は、Peter Neubauerとの協業を通じて、オープンソースコミュニティにおいても大きな貢献をしました。このコミュニティからのフィードバックとサポートは、Neo4jの進化と成長に不可欠でした。
Emil Eifrémの影響は、単に技術的な面に留まらず、ビジネスやデータサイエンスの分野にも及んでいます。彼のリーダーシップとイノベーションは、グラフデータベースが現代のデータ管理における重要な役割を果たす基盤を築きました。Emil Eifrémの業績は、今日のデータ駆動型アプローチの発展に大きく寄与しています。.....
この協力関係の初期段階では、PeterはSamの指導者としての役割を果たし、彼に業界の知識と技術的な専門知識を提供していました。彼らは特に、データの視覚化とユーザーインターフェイスの設計に関するプロジェクトで協力し、その分野における新しい標準を確立しました。
SamはPeterから多くを学び、彼のガイダンスのもとで自身のスキルと理解を深めました。Peterの経験とSamの革新的なアプローチの融合は、彼らのプロジェクトに特別な魅力をもたらし、業界内での彼らの名声を高めました。
PeterとSamの関係は、専門知識の伝承と新しいアイデアの探求という、相互補完的な関係性によって特徴づけられます。彼らは互いに学び合い、共に成長することで、多くの成功を収めてきました。このような協力関係は、特に技術分野においては、イノベーションの源泉となり得ます。
一方、SamとTomの関係は、別の側面から興味深いものです。彼らは異なる専門分野にいながらも、技術的なイノベーションとビジネスの進化に関する共通の興味を共有していました。TomはしばしばSamの視点に新たな洞察を加え、Samのプロジェクトにおける戦略的な決定に影響を与えていました。このように、SamとTomの関係は、専門知識を超えた互恵的なコラボレーションと深い敬意に基づいていました。
ただおさえて欲しいのは、
- Emil EifrémとPeter Neubauerは知り合い
- Peter NeubauerとSamは知り合い
- SamとTomは知り合い。
ということです。
この質問に答えるためにも、質問を分解してみましょう。
「TomにEmil Eifrém(Neo4jのCEO)を紹介してくれる人は?」
「Emil Eifrémと知り合いの人は?」 → Peter Neubauer
「Peter Neubauerと知り合いの人は?」 → Sam
「Samの知り合いは?」 → Tom
質問:「TomにEmil Eifrém(Neo4jのCEO)を紹介してくれる人は?」 → Samに連絡を取るといいよ!
と、質問に答えるまでに上記の流れが行わなければなりません。
ベクトル検索でLLMが質問に答えるには、上記の知り合い情報を渡してあげないといけません。
では質問に答えるために、上記で記載した仮想ドキュメントにベクトル検索を実施する時の例を考えてみましょう。
ベクトル検索したときに、Top3でとってきたとします。そのときに出てきた人の名前を赤枠で囲んでいます。
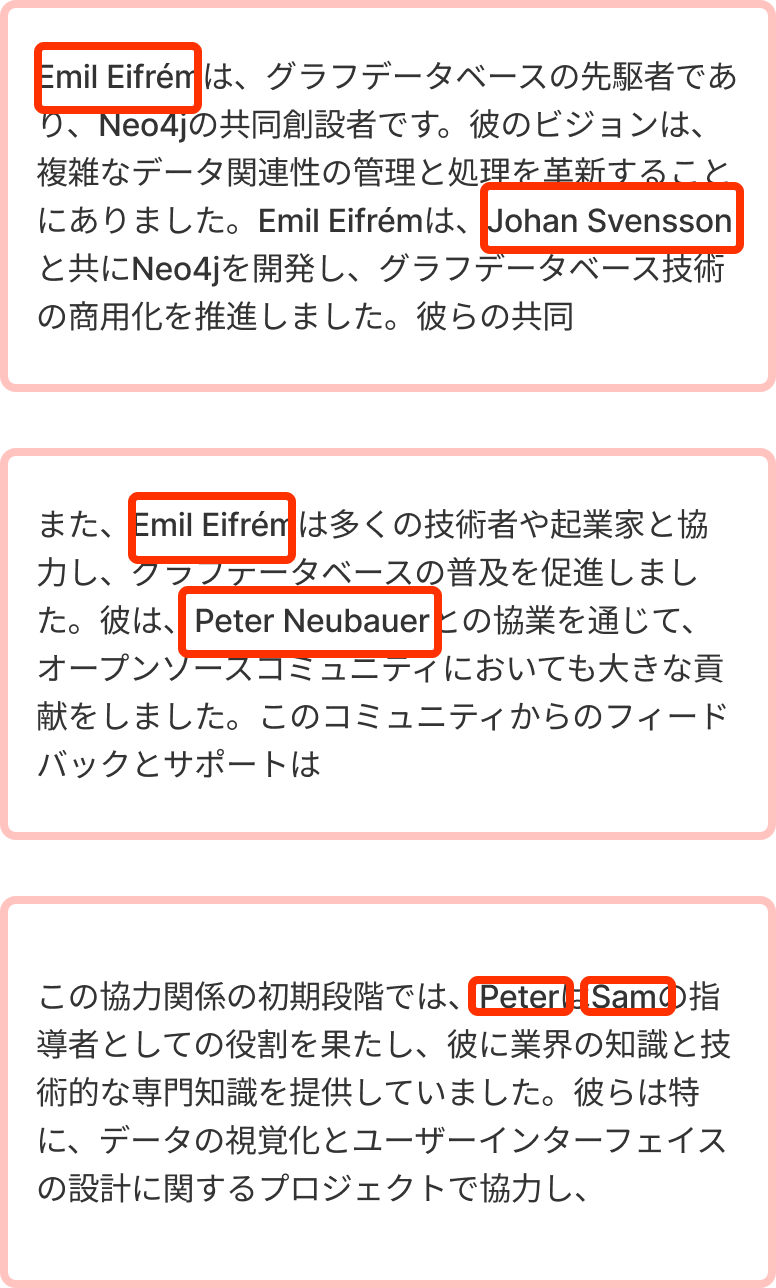
そうすると、ここでの登場人物はEmil、Johan、Peter、Samですね。
すると本当は文章に入っていたはずの、Tomの情報が消えてしまいました。
次に、もしTop3が以下の様に取れてきたらどうでしょうか?
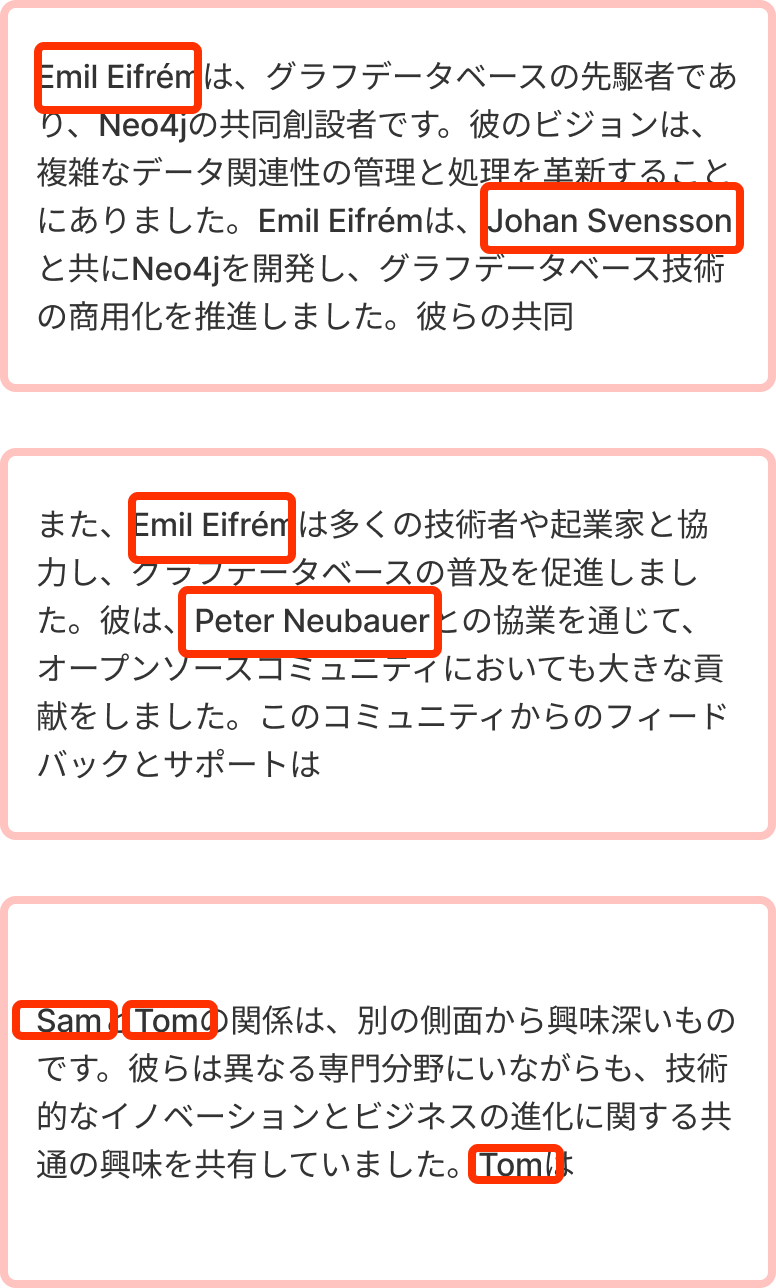 )
)
ここでの登場人物はEmil、Johan、Peter、Sam、Tomですね。
全員出てきていますね!解決!
とはならないですね。なぜなら、これらの文章にPeterとSamの関係性が含まれていません。
なので、「TomにEmil Eifrém(Neo4jのCEO)を紹介してくれる人は?」という回答には答えられないのです。
文章をチャンクで区切るときに大きく取っていれば、もしくはTopKのKを大きくすれば解決するかもしれません。
解決できるだけのチャンクの大きさやTopKのKに関してはわからないのです。
さらにいうとベクトル検索は単純に意味的に近い文章を取得することなので、この様にTomとEmilが出てきていないところ文章を取得してくれるかわかりません。
これを解決するためには二つほど解決策があります。
- エージェントを使用する。
- ナレッジグラフを使用する。
エージェントを使うことでもこの問題は解決することができると思いますが、エージェントは何回もLLMを呼び出すことになり、LLMが吐き出す内容の精度が低ければ費用が高くなってしまう可能性がありますし、パフォーマンス面でも考えるべきところだと思います。
なので、今回はナレッジグラフをつかうことで、ベクトル検索の問題点を解決したいと思います。
ナレッジグラフの強み
ナレッジグラフはエンティティとその関係をグラフで表現するデータモデルになります。以下のような感じです。

グラフへの問い合わせにはCypherというクエリ言語を用いて問い合わせます。(RDBでいうSQL的な)
これを使うとベクトル検索の問題点を解決することができます。
簡単に先ほどの例をナレッジグラフで表してみるとわかりやすいです。
Emil Eifrém ← 知り合い → Peter Neubauer ← 知り合い → Sam ← 知り合い → Tom
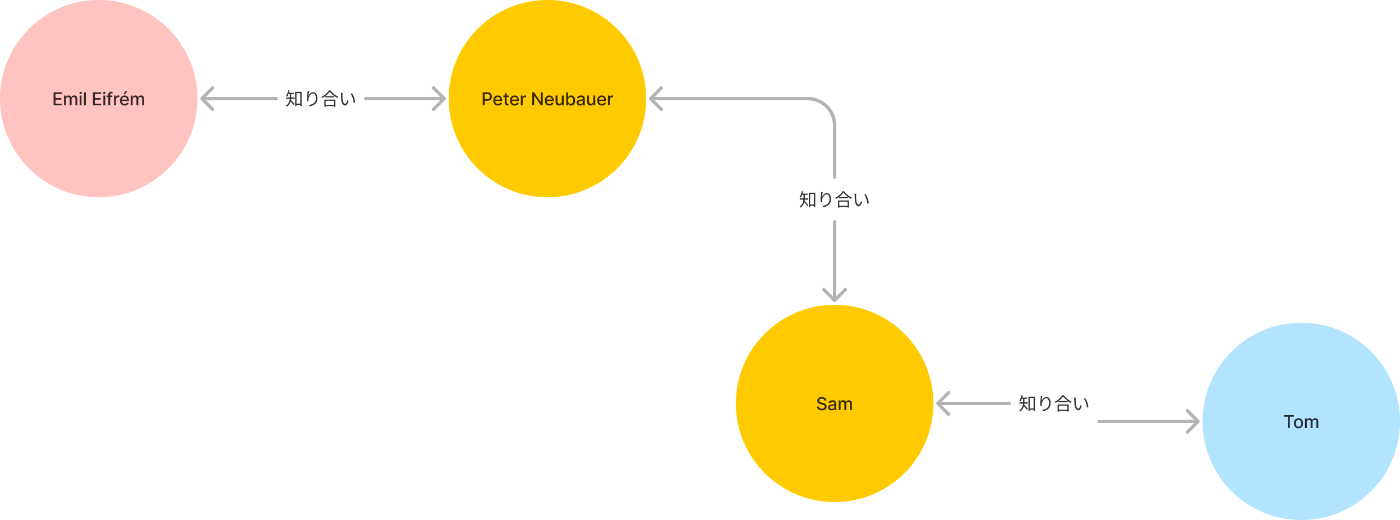
この構造に対してCypherクエリを投げればいいだけです。
実際にRAGとして使う時のイメージで考えてみましょう。
クエリ→LLMでCypherに変換→ナレッジグラフで知り合いを検索→回答「Samに聞けばいい!」

このようになります。簡単ですね。
もちろん場合によっては以下でもいいわけです。
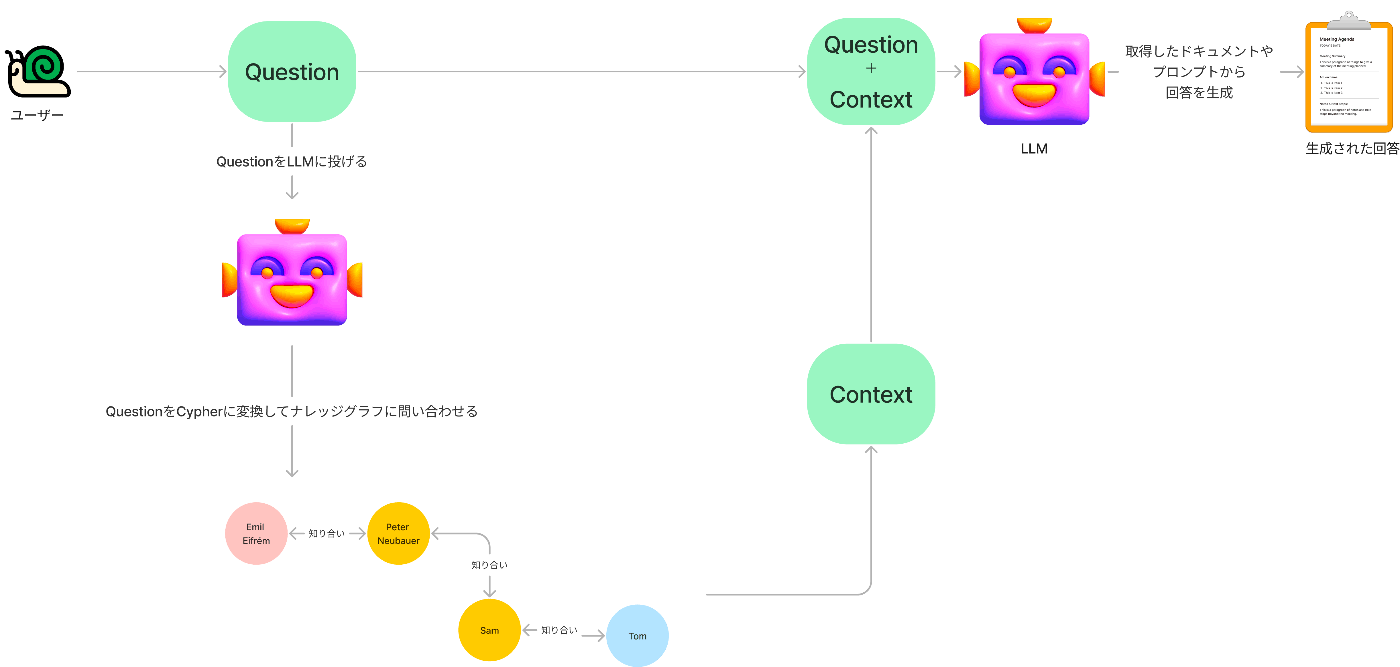
ではここで一旦ナレッジグラフとベクトル検索のRAGでの流れの違いを再度確認しておきましょう。
ベクトル検索:質問 → LLMEmbeddingでベクトルに変換 → ベクトルインデックスに検索
グラフ検索:質問 → LLMでCypherに変換 → ナレッジグラフに検索
| 検索種類 | 流れ |
|---|---|
| ベクトル検索 | 質問 → LLMEmbeddingでベクトルに変換 →ベクトルインデックスに検索 |
| グラフ検索 | 質問 → LLMでCypherに変換 →ナレッジグラフに検索 |
もちろん、ナレッジグラフがベクトル検索より優れているわけではなく、その逆も然りです。
ユースケースごとに使い分けることが大事です。私の見立てでは、ナレッジグラフが適しているケースでもほぼ必ずベクトル検索も使うことになると思います。
というのも、Neo4jでは、ナレッジグラフで構造化データと非構造化データを扱うことができるのです。
なので、ベクトル検索もナレッジグラフ上でできてしまうのです!
ここで一旦まとめると、ナレッジグラフは
- 複数回ステップを経ないと回答できない質問(とくにハルシネーションを起こしたくないとき)に強い
- 構造データと非構造データの両方を扱うことができる
- ナレッジグラフのノードに非構造化データを突っ込んで、ベクトル検索もできる
何となくわかってきたかと思いますが、
ベクトル検索とナレッジグラフでのグラフ検索の両方を使うことで、本当の強みが得られるといってもいいでしょう。
ベクトル検索をして、その後にグラフ検索を実行するなんてことができてしまいます。
以下のCypherの例に強みが垣間見えます。
// find products by similarity search in vector index
CALL db.index.vector.queryNodes('products', 5, $embedding) yield node as product, score
// enrich with additional explicit relationships from the knowledge graph
MATCH (product)-[:HAS_CATEGORY]->(cat), (product)-[:BY_BRAND]->(brand)
OPTIONAL MATCH (product)<-[:BOUGHT]-(customer)-[rated:RATED]->(product)
WHERE rated.rating = 5
OPTIONAL MATCH (product)-[:HAS_REVIEW]->(review)<-[:WROTE]-(customer)
RETURN product.Name, product.Description, brand.Name, cat.Name,
collect(review { .Date, .Text })[0..5] as reviews
//https://neo4j.com/blog/vector-search-deeper-insights から参照
このCypherを解説しましょう。
- queryNodesでベクトル検索を実行しproductを取得。質問をベクトル化した$embeddingで検索します。
- 取得したproductに対して、明示的なリレーションシップを使ってカテゴリとブランドの情報を取得しています。
- このオプショナルで、「製品を購入して5つ星の評価を与えた顧客」を探します。
- オプショナルで、「製品のレビューと、そのレビューを書いた顧客」を探します。
- 最後に、各製品について、製品名、製品説明、ブランド名、カテゴリ名、および最大5件のレビュー(日付とテキスト)を返します。
ベクトル検索した結果から、芋蔓式にハルシネーションなしに情報を取得できるのです。
筆者はナレッジグラフこそこれからはやるRAGのRetrieverだと思っています。
RDBとの比べると?
多くのリレーションをまたぐクエリを書くときにはSQLで書こうとすると、SQL自体複雑になってしまいがちです。
マルチホップなQAをするとなると、そういった面でSQLは複雑になりLLMでの生成精度が落ちてしまいます。
そういった点で、SQLで書くのではなくリレーションをまたぐ処理を書きやすいCypherの方に軍牌が上がりますね。
以下のスライドが参考になります。
複数ホップするクエリがSQL32行→Cypher7行になったらしいですね。
ナレッジグラフを作るための方法
ナレッジグラフの有用性はわかっていただけたとおもいますが 、ここからはナレッジグラフを作成する方法に関して解説していきたいと思います。
LangChainのブログ記事に記載のある方法なので、一次情報を知りたい方はこちらから
以下が全様です。この情報抽出のパイプラインで非構造化データから構造化データのナレッジグラフに落とし込んでいきます。
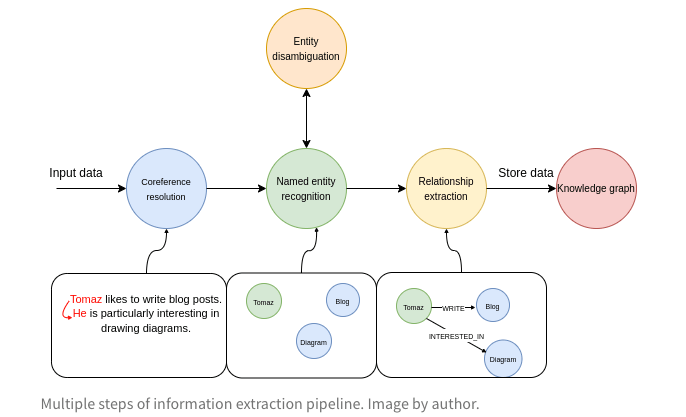
(referenced by https://blog.langchain.dev/constructing-knowledge-graphs-from-text-using-openai-functions/)
これを使うと完璧なナレッジグラフができるわけではありませんが、Betterなナレッジグラフはできるようになります!
各ステップを解説すると大きく4つのステップになります。
- データ入力の段階では、入力されたテキストを Coreference resolution(共参照解決)します。
Coreference resolution(共参照解決)はテキスト内で同じものを指している言葉を全て見つけ出してつなげる作業です。例えば、「彼」や「そのお店」といった代名詞が何を指しているのかを特定するわけですね。 - 次に、Named entity recognition(名前付きエンティティ認識)の段階に移ります。ここでは、テキストに出てくる人名や組織名、場所などの固有名詞を全て見つけ出します。図の例だと、Tomaz、Blog、Diagramという3つのエンティティが登場しています。
- Disambiguation(エンティティ曖昧性解消)がその次に行います。同じ名前や似たような言及があるエンティティを、きちんと区別して認識するんですね。 これやらないと、同じだけで違う名前でノードが作られたりするのでめっちゃ重要です。
- 最後は、Relation extraction(関係抽出)のステップです。ここでは、見つけ出したエンティティ同士の関係性を明らかにします。例えば、図ではTomazとBlogの間にはLIKES(好む)という関係があるのかもしれません。ちなみにここもDisambiguation(エンティティ曖昧性解消)を行うべきです。
これらのステップで完璧ではないですが、大体いい感じのができます。
ナレッジグラフをNeo4jとLangchainで構築する
では実際に実装しながら見ていきましょう!
今回は以下のLangChainさんが出しているExampleを使いながら実装していきます。
Google Colab + Python + Langchainです!
基本以下のGitHubリポジトリのコードと同じコードになります。
neo4j立ち上げのためのdocker-compose.ymlのコード(dockerコンテナを立ち上げておくこと)
version: '3'
services:
database:
image: neo4j
ports:
- '7687:7687'
- '7474:7474'
environment:
- NEO4J_AUTH=neo4j/pleaseletmein
- NEO4JLABS_PLUGINS=["apoc"]
%pip install --upgrade --quiet langchain langchain-openai tiktoken neo4j sqlalchemy wikipedia
import os
import openai
import getpass
from langchain_openai import ChatOpenAI
from langchain.graphs import Neo4jGraph
# 環境変数の設定
os.environ["OPENAI_API_KEY"] = getpass.getpass()
openai.api_key = os.environ["OPENAI_API_KEY"]
# モデルは適当に設定してください
model = ChatOpenAI()
url = "bolt://localhost:7687"
username ="neo4j"
password = "pleaseletmein"
graph = Neo4jGraph(
url=url,
username=username,
password=password
)
ナレッジグラフを表現するためのデータ構造を定義しています。Property、Node、Relationship、KnowledgeGraphクラスを定義し、それぞれのプロパティを指定しています。
from langchain_community.graphs.graph_document import (
Node as BaseNode,
Relationship as BaseRelationship,
GraphDocument,
)
from langchain.schema import Document
from typing import List, Dict, Any, Optional
from langchain.pydantic_v1 import Field, BaseModel
class Property(BaseModel):
"""A single property consisting of key and value"""
key: str = Field(..., description="key")
value: str = Field(..., description="value")
class Node(BaseNode):
properties: Optional[List[Property]] = Field(
None, description="List of node properties")
class Relationship(BaseRelationship):
properties: Optional[List[Property]] = Field(
None, description="List of relationship properties"
)
class KnowledgeGraph(BaseModel):
"""Generate a knowledge graph with entities and relationships."""
nodes: List[Node] = Field(
..., description="List of nodes in the knowledge graph")
rels: List[Relationship] = Field(
..., description="List of relationships in the knowledge graph"
)
ナレッジグラフのノードとリレーションシップを操作するためのユーティリティ関数を定義しています。format_property_key : プロパティのキーをフォーマットします。
props_to_dict : プロパティのリストを辞書に変換します。
map_to_base_node: カスタムのNodeをBaseNodeにマッピングします。
map_to_base_relationship: カスタムのRelationshipをBaseRelationshipにマッピングします。
def format_property_key(s: str) -> str:
words = s.split()
if not words:
return s
first_word = words[0].lower()
capitalized_words = [word.capitalize() for word in words[1:]]
return "".join([first_word] + capitalized_words)
def props_to_dict(props) -> dict:
"""Convert properties to a dictionary."""
properties = {}
if not props:
return properties
for p in props:
properties[format_property_key(p.key)] = p.value
return properties
def map_to_base_node(node: Node) -> BaseNode:
"""Map the KnowledgeGraph Node to the base Node."""
properties = props_to_dict(node.properties) if node.properties else {}
# Add name property for better Cypher statement generation
properties["name"] = node.id.title()
return BaseNode(
id=node.id.title(), type=node.type.capitalize(), properties=properties
)
def map_to_base_relationship(rel: Relationship) -> BaseRelationship:
"""Map the KnowledgeGraph Relationship to the base Relationship."""
source = map_to_base_node(rel.source)
target = map_to_base_node(rel.target)
properties = props_to_dict(rel.properties) if rel.properties else {}
return BaseRelationship(
source=source, target=target, type=rel.type, properties=properties
)
テキストからナレッジグラフを抽出するためのチェーンを作成する関数get_extraction_chainを定義しています。
引数としてallowed_nodesとallowed_relsという2つのオプションのパラメータを受け取ります。
これらのパラメータは、許可されるノードラベルとリレーションシップタイプを指定するために使用されます。情報抽出をより正確に行うために指定します。前回の章で解説した曖昧さを取り除くためですね。
プロンプトで曖昧さの解消はしようとしているので最初は指定する必要はないですが、抽出した結果曖昧さが残るのであれば、allowed_nodesとallowed_relsは指定した方がいいでしょう。
最後に、create_structured_output_chain関数を使用して、指定されたプロンプトとLLMを使用するチェーンを作成します。
import os
from langchain.chains.openai_functions import (
create_openai_fn_chain,
create_structured_output_chain,
)
from langchain_openai import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
llm = model
def get_extraction_chain(
allowed_nodes: Optional[List[str]] = None,
allowed_rels: Optional[List[str]] = None
):
prompt = ChatPromptTemplate.from_messages(
[(
"system",
f"""# Knowledge Graph Instructions for GPT-4
## 1. Overview
You are a top-tier algorithm designed for extracting information in structured formats to build a knowledge graph.
- **Nodes** represent entities and concepts. They're akin to Wikipedia nodes.
- The aim is to achieve simplicity and clarity in the knowledge graph, making it accessible for a vast audience.
## 2. Labeling Nodes
- **Consistency**: Ensure you use basic or elementary types for node labels.
- For example, when you identify an entity representing a person, always label it as **"person"**. Avoid using more specific terms like "mathematician" or "scientist".
- **Node IDs**: Never utilize integers as node IDs. Node IDs should be names or human-readable identifiers found in the text.
{'- **Allowed Node Labels:**' + ", ".join(allowed_nodes) if allowed_nodes else ""}
{'- **Allowed Relationship Types**:' + ", ".join(allowed_rels) if allowed_rels else ""}
## 3. Handling Numerical Data and Dates
- Numerical data, like age or other related information, should be incorporated as attributes or properties of the respective nodes.
- **No Separate Nodes for Dates/Numbers**: Do not create separate nodes for dates or numerical values. Always attach them as attributes or properties of nodes.
- **Property Format**: Properties must be in a key-value format.
- **Quotation Marks**: Never use escaped single or double quotes within property values.
- **Naming Convention**: Use camelCase for property keys, e.g., `birthDate`.
## 4. Coreference Resolution
- **Maintain Entity Consistency**: When extracting entities, it's vital to ensure consistency.
If an entity, such as "John Doe", is mentioned multiple times in the text but is referred to by different names or pronouns (e.g., "Joe", "he"),
always use the most complete identifier for that entity throughout the knowledge graph. In this example, use "John Doe" as the entity ID.
Remember, the knowledge graph should be coherent and easily understandable, so maintaining consistency in entity references is crucial.
## 5. Strict Compliance
Adhere to the rules strictly. Non-compliance will result in termination.
"""),
("human", "Use the given format to extract information from the following input: {input}"),
("human", "Tip: Make sure to answer in the correct format"),
])
return create_structured_output_chain(KnowledgeGraph, llm, prompt, verbose=False)
ナレッジグラフを抽出し、Neo4jデータベースに保存する関数です。
add_graph_documentsの第二引数のinclude_sourceをTrueにするとドキュメントの紐付けも行ってくれます。
ドキュメントを見てみましょう。
def extract_and_store_graph(
document: Document,
nodes:Optional[List[str]] = None,
rels:Optional[List[str]]=None) -> None:
# Extract graph data using OpenAI functions
extract_chain = get_extraction_chain(nodes, rels)
data = extract_chain.invoke(document.page_content)['function']
# Construct a graph document
graph_document = GraphDocument(
nodes = [map_to_base_node(node) for node in data.nodes],
relationships = [map_to_base_relationship(rel) for rel in data.rels],
source = document
)
# Store information into a graph
graph.add_graph_documents([graph_document],True)
指定されたURLのWebページからテキストを抽出し、TokenTextSplitterを使用してテキストをチャンクに分割します。今回はポストコーヒーさんの出している記事から作ろうと思います。
from langchain_community.document_loaders import WebBaseLoader
raw_documents = WebBaseLoader("https://postcoffee.co/magazine/roaster/roaster-lightupcoffee-yumakawano/#:~:text=%E5%B7%9D%E9%87%8E%E5%84%AA%E9%A6%AC%20%2F%20Kawano%20Yuma&text=%E5%BA%97%E8%88%97%E3%82%92%E7%B5%8C%E5%96%B6%E3%81%99%E3%82%8B%E5%82%8D%E3%82%89,%E8%80%85%E5%85%BC%E3%83%90%E3%83%AA%E3%82%B9%E3%82%BF%E3%81%A8%E3%81%97%E3%81%A6%E5%83%8D%E3%81%8F%E3%80%82").load()
text_splitter = TokenTextSplitter(chunk_size=2048, chunk_overlap=24)
# Only take the first the raw_documents
documents = text_splitter.split_documents(raw_documents)
print(documents)
documentsリストの各ドキュメントに対して、extract_and_store_graph関数を呼び出してナレッジグラフを抽出し、Neo4jデータベースに保存します。tqdmライブラリは処理の進行状況を表示したいので使っています。
from tqdm import tqdm
for i, d in tqdm(enumerate(documents), total=len(documents)):
extract_and_store_graph(d)
Disambiguation(エンティティ曖昧性解消)について
allowed_nodesに許可するラベルを入れ込むことで、Disambiguation(エンティティ曖昧性解消)できる。
最初はallowed_nodesなしで実行して、グラフDBを確認して同じ意味だけど違う言葉で作られているものがあれば、allowed_nodesに追加していく形を取るようにしていくのがいいでしょう。
allowed_nodes = ["Person", "Company", "Location", "Event", "Movie", "Service", "Award"]
for i, d in tqdm(enumerate(documents), total=len(documents)):
extract_and_store_graph(d, allowed_nodes)
最後にナレッジグラフに対して質問応答を行うためのGraphCypherQAChainを作成します。
validate_cypherパラメータをTrueに設定することで、リレーションシップの方向をバリデートしてくれます。
# Query the knowledge graph in a RAG application
from langchain.chains import GraphCypherQAChain
graph.refresh_schema()
cypher_chain = GraphCypherQAChain.from_llm(
graph=graph,
cypher_llm=model,
qa_llm=model,
validate_cypher=True, # Validate relationship directions
verbose=True
)
結果
以下のように質問してみました
cypher_chain.invoke({"query": "川野優馬の趣味はなんですか?"})
結果は以下ですね。
> Entering new GraphCypherQAChain chain...
Generated Cypher:
MATCH (p:Person {name: "川野優馬"})-[:HAS_HOBBY]->(h:Hobby)
RETURN h.name
Full Context:
[{'h.name': 'コーヒー'}, {'h.name': 'ナチュラルワイン'}, {'h.name': 'カメラ'}]
> Finished chain.
{'query': '川野優馬の趣味はなんですか?', 'result': '川野優馬の趣味はコーヒー、ナチュラルワイン、カメラです。'}
いろいろ触ったのですが、Cypherへの変換に少し懸念が残りますね。
例えば以下のクエリでも検索できていい気がします。
cypher_chain.invoke({"query": "川野さんの趣味はなんですか?"})
がしかし、結果は以下です
> Entering new GraphCypherQAChain chain...
Generated Cypher:
MATCH (p:Person {name: '川野さん'})-[:HAS_HOBBY]->(h:Hobby)
RETURN h.name
Full Context:
[]
> Finished chain.
{'query': '川野さんの趣味はなんですか?', 'result': '私はその情報を持っていませんので、川野さんの趣味についてはわかりません。'}
確かに川野さんというノードはないですが、いい感じにしてくれないものかと思います。
直近はベクトル検索した後に付随する情報を芋蔓式に取得する、というのが一番有効で最大限活用できる使い方かと思います。
扱った例が悪かったですね...別のをやる気力がわかなかったのでこれで許してください...
最後に
ナレッジグラフ面白いけど、まだ結構技術的には開拓できそうなところがありそうな感じがしますね。
結構大変だけど、今後はナレッジグラフ+RAGがきそうな予感がするなあ。
Xやってるのでぜひフォローお願いします。
@hudebakonosoto
参考
今回の記事を書くのにかなりありがたかったブログたちです。ぜひ読んでみてください。
複数ドキュメントにまたがる質問に対して、ナレッジグラフを使うことで正確な回答ができることを説明してる記事
構造化データの扱いにおけるナレッジグラフの重要性を説明、ベクトル検索では難しい複雑な関係性を持つデータの検索にナレッジグラフが有効であることを述べている記事
ベクトルとKnowlege Graphの比較記事
LLMを使って非構造化テキストから構造化データを抽出し、ナレッジグラフを構築する方法を説明してる記事
Neo4jでインデックスデータを扱いができるようになって、それを褒めてる記事
Neo4Jの埋め込みをノードかする時の実装をしている記事
Discussion