Neo4jのRAGで全文検索+ベクトル検索のハイブリッド検索しよう!でもベクトル検索のデメリットは消せないよ
はじめに
みなさんRAGを使う時のRetriverはもっぱらベクトル検索を使っていますか?
今回はベクトル検索よりも精度が上がると噂のハイブリッド検索に関して書いていきます。
ナレッジグラフをつくるときにも有名なNeo4jは全文検索とベクトル検索の二つを実施できるハイブリッド検索をサポートしていますので、Neo4jをコードも踏まえて実践していきたいと思います!
ではまずハイブリッド検索についてさらっと解説してから、実際にコードを動かして試してみましょう!
ハイブリッド検索=全文検索+ベクトル検索
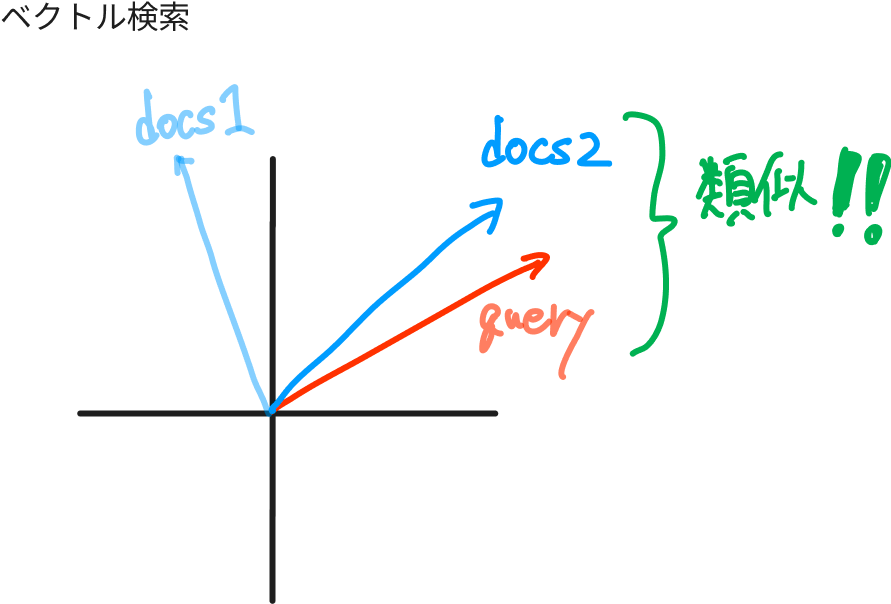
ベクトル検索
ベクトル検索は以下のように文章やクエリをEmbeddingしてベクトル化し、ベクトル間の比較(cos類似度などで比較)することで意味的に近いかどうかを判別します。
全文検索(キーワード検索)
全文検索では文書内に含まれるキーワードをインデックス化し、ユーザーのクエリに含まれるキーワードが文書内にどのように現れるかを基に検索を行います。

ハイブリッド検索
ハイブリッド検索ではこの両方を行います。方法としては、ベクトル検索 の結果と 全文検索の結果をスコア順に並べて、トップKを取得します!

LangChainでNeo4jのハイブリッド検索を実装
では実際にコードを書いていきましょう。
基本的には以下のチュートリアルの内容からコードを書いています。
docker-compose.ymlのコード(dockerコンテナを立ち上げておくこと)
version: '3'
services:
database:
image: neo4j
ports:
- '7687:7687'
- '7474:7474'
environment:
- NEO4J_AUTH=neo4j/pleaseletmein
- NEO4JLABS_PLUGINS=["apoc"]
事前にconfigを定義しておきます。
この時ハイブリッド検索をするにはsearchTypeをhybridに指定しておく必要があります。
const config = {
url: 'bolt://localhost:7687', // URL for the Neo4j instance
username: 'neo4j', // Username for Neo4j authentication
password: 'pleaseletmein', // Password for Neo4j authentication
indexName: 'vectors', // Name of the vector index
keywordIndexName: 'keyword', // Name of the keyword index if using hybrid search
searchType: 'hybrid' as const, // Type of search (e.g., vector, hybrid)
nodeLabel: 'Chunk', // Label for the nodes in the graph
textNodeProperty: 'text', // Property of the node containing text
embeddingNodeProperty: 'embedding', // Property of the node containing embedding
};
では実際の実装に入ります。
流れとしては
ドキュメント取得
→ ドキュメント前処理
→ ドキュメントからNeo4jVectorStoreを作成する。
→ similaritySearchで検索
async initDataIntoGraph() {
// ドキュメントを事前に読み込んで前処理をしておく。
const urls = ['https://note.com/yuma_lightup/n/na5d5555fed8a'];
const docsPromises = urls.map((url) =>
new PlaywrightWebBaseLoader(url).load(),
);
const docs = await Promise.all(docsPromises);
const docsList: string[] = ([] as string[]).concat(
...docs.map((docArray) => docArray.map((doc) => doc.pageContent)),
);
// Split documents
const splitter = new RecursiveCharacterTextSplitter({
chunkSize: 5000,
});
console.log('finished loading documents');
console.log('splitting documents ...');
const docSplits = await splitter.createDocuments(docsList);
//ドキュメントからNeo4jVectorStoreを作成する。
const graph = await Neo4jVectorStore.fromDocuments(
docSplits,
new OpenAIEmbeddings(),
config,
);
//similaritySearchで検索
const res = await graph.similaritySearch(
'What are the advantages of a French press?',
);
console.log(res);
}
Documentからのグラフデータベースを作るとhttp://localhost:7474/browser/に以下のようなグラフが作成されていると思います。

それぞれのノードの内容は以下のようになっています。

ノードのembeddingプロパティを使ってベクトル検索、 textプロパティを使って全文検索を行っているようです。
実際この辺のコードが全部隠蔽されていて、Neo4jVectorStoreがsimilaritySearchをしているとベクトル検索しかしていないように見えました。
めちゃくちゃ不安だったので、一部一緒にコードを見ていきたいと思います。
LangChainでNeo4jのハイブリッド検索のコードを読もう
Neo4jVectorStoreのsimilaritySearchコードを見ていきましょう。
similaritySearch
similaritySearchではクエリを渡すと、クエリを埋め込みしてそれをsimilaritySearchVectorWithScoreに渡していますね。
async similaritySearch(query: string, k = 4): Promise<Document[]> {
const embedding = await this.embeddings.embedQuery(query);
const results = await this.similaritySearchVectorWithScore(
embedding,
k,
query
);
return results.map((result) => result[0]);
}
similaritySearchVectorWithScore
では次にsimilaritySearchVectorWithScoreを見ましょう。
このプロセスではsimilaritySearchVectorWithScoreに大事なロジックが詰まっていますが動作がわかる部分だけ抜いて読みます。
1.ノード取得用のクエリを書く。
特にカスタムのretrievalQueryを書いていない場合は、defaultRetrievalが使われます。
2. そのクエリをsearchTypeによってgetSearchIndexQueryで加工してreadQueryを作成しているようですね。getSearchIndexQueryが大事そうです。
3. 最後にパラメータを作って、this.queryでパラメータをNeo4jに投げて検索してます。
async similaritySearchVectorWithScore(
vector: number[],
k: number,
query: string
): Promise<[Document, number][]> {
const defaultRetrieval = `
RETURN node.${this.textNodeProperty} AS text, score,
node {.*, ${this.textNodeProperty}: Null,
${this.embeddingNodeProperty}: Null, id: Null } AS metadata
`;
const retrievalQuery = this.retrievalQuery
? this.retrievalQuery
: defaultRetrieval;
const readQuery = `${getSearchIndexQuery(
this.searchType
)} ${retrievalQuery}`;
const parameters = {
index: this.indexName,
k: Number(k),
embedding: vector,
keyword_index: this.keywordIndexName,
query: removeLuceneChars(query),
};
const results = await this.query(readQuery, parameters);
.....
}
}
getSearchIndexQuery
なるほど、similaritySearchではsearchTypeによってCypherを加工してNeo4jに投げているだけですね。
じゃあどんな処理をしてるにはどんなCypherを投げているか、ですね!
どのためにはgetSearchIndexQueryを見ていきましょう。
function getSearchIndexQuery(searchType: SearchType): string {
const typeToQueryMap: { [key in SearchType]: string } = {
vector:
"CALL db.index.vector.queryNodes($index, $k, $embedding) YIELD node, score",
hybrid: `
CALL {
CALL db.index.vector.queryNodes($index, $k, $embedding) YIELD node, score
WITH collect({node:node, score:score}) AS nodes, max(score) AS max
UNWIND nodes AS n
// We use 0 as min
RETURN n.node AS node, (n.score / max) AS score UNION
CALL db.index.fulltext.queryNodes($keyword_index, $query, {limit: $k}) YIELD node, score
WITH collect({node: node, score: score}) AS nodes, max(score) AS max
UNWIND nodes AS n
RETURN n.node AS node, (n.score / max) AS score
}
WITH node, max(score) AS score ORDER BY score DESC LIMIT toInteger($k)
`,
};
return typeToQueryMap[searchType];
}
まずは、SearchTypeがvectorだった時のCypherを組み立てみましょう。
※this.~系はNeo4jVectorStoreを作成する時に渡したconfigからできているので一旦無視してください。
CALL db.index.vector.queryNodes($index, $k, $embedding) YIELD node
RETURN node.${this.textNodeProperty} AS text, score,
node {.*, ${this.textNodeProperty}: Null,
${this.embeddingNodeProperty}: Null, id: Null } AS metadata
Cypherクエリの文法を解説しないですが、重要なところだけ解説します。
db.index.vector.queryNodesは$embeddingで「ベクトル検索するよ」です。
ドキュメントを見ると
(日本語訳)与えられたベクトルインデックスに問い合わせる。要求された近似最近傍ノードの数とその類似度スコアを、スコア順に返します。
って書いていますね。グラフ近似最近傍探索をHNSWで実施してるっぽいです。
グラフの近似最近傍探索に関しては以下がすごくわかりやすいです。ぜひ読んで欲しいです。
あとは取得した結果をRETURN以下でこちゃこちゃやっています。それは単に出力を整形しているだけです。
まとめるとSearchTypeがvectorだった時のクエリは「ベクトル検索するよ」のクエリでした。まあそうですよね笑
次にSearchTypeがhybridだった時のCypherを組み立てみましょう。
CALL {
CALL db.index.vector.queryNodes($index, $k, $embedding) YIELD node, score
WITH collect({node:node, score:score}) AS nodes, max(score) AS max
UNWIND nodes AS n
// We use 0 as min
RETURN n.node AS node, (n.score / max) AS score UNION
CALL db.index.fulltext.queryNodes($keyword_index, $query, {limit: $k}) YIELD node, score
WITH collect({node: node, score: score}) AS nodes, max(score) AS max
UNWIND nodes AS n
RETURN n.node AS node, (n.score / max) AS score
}
WITH node, max(score) AS score ORDER BY score DESC LIMIT toInteger($k)
RETURN node.${this.textNodeProperty} AS text, score,
node {.*, ${this.textNodeProperty}: Null,
${this.embeddingNodeProperty}: Null, id: Null } AS metadata
まずvectorの時と同様にdb.index.vector.queryNodesでベクトル検索しています。
次のCALLでdb.index.fulltext.queryNodesを使っていますがこれは全文検索用のクエリですね。
そしてその後のWITH node, max(score) AS score ORDER BY score DESC LIMIT toInteger($k)でベクトル検索と全文検索の結果をスコアで並び替えて上位kを取得しているようですね。
まとめるとSearchTypeがhybridだった時のクエリは「ベクトル検索+全文検索をするよ」のクエリでした。
おおおーーこれで納得だーーー!!
embeddingを使ってベクトル検索 textを使って全文検索を行っているようです。
上部にこのように書きました。
この辺のコードはfromDocumentsのコードを追ってもらえるといいと思います。
ベクトル検索はconfigのembeddingNodeProperty、全文検索はtextNodePropertyで指定されたプロパティーが検索対象になっています。
Neo4jを使ううまみはハイブリッド検索だけではない。
ここまでハイブリッド検索に関して書いてきましたが、正直今回の実装だけは旨みはそこだけではありません。
ハイブリッド検索を行うと、精度が上がり、いい検索ができるかもしれないですが、この検索方法ではベクトル検索の悪い点を排除できません。
ベクトル検索の悪いところを書いていきます。
- 必要な情報がTop Kのドキュメントには含まれていない可能性がある。
- チャンクのサイズによってはエンティティへの参照が失われる可能性もある。(チャンクごとの繋がりがなくなり)
- 上記を解決するためのドキュメント数がわからない。
これらの詳しい話は以下のneo4jのテックブログに書かれています。
この問題点はナレッジグラフを使うことで他の方法で解決することができます。
が、この話は長くなるのでまた別で記事にしようと思います。(たぶん)
最後に
ナレッジグラフ関連のことを書こうと思って色々下書きしてたけど、
Neo4jを多少使うだけで、ナレッジグラフをいい感じに作成できちゃって、いい感じにベクトル検索の悪いところとか解決できちゃうんじゃないか、という勘違いをなくすためにも先にこっちを書きました。(私が勘違いしてただけなんですが...笑)
実際はナレッジグラフ作ったり、ナレッジグラフとドキュメントの紐付けとか、この辺が実は面倒でした。(ちゃんと調べきれていない可能性もある。)
次こそはナレッジグラフの知見を残す!(残さないかもしれない)
Xやってるのでぜひフォローお願いします。
@hudebakonosoto
Discussion