RAG From Scratchをやってみた(6/6): Generation


LangChain公式リポジトリに、以下のRAGの各要素に関する解説コードがあります。(※1年ほど前に公開された内容です。)
今回はRAGの構成のなかのGenerationに関する部分を読み解いてみた内容です。
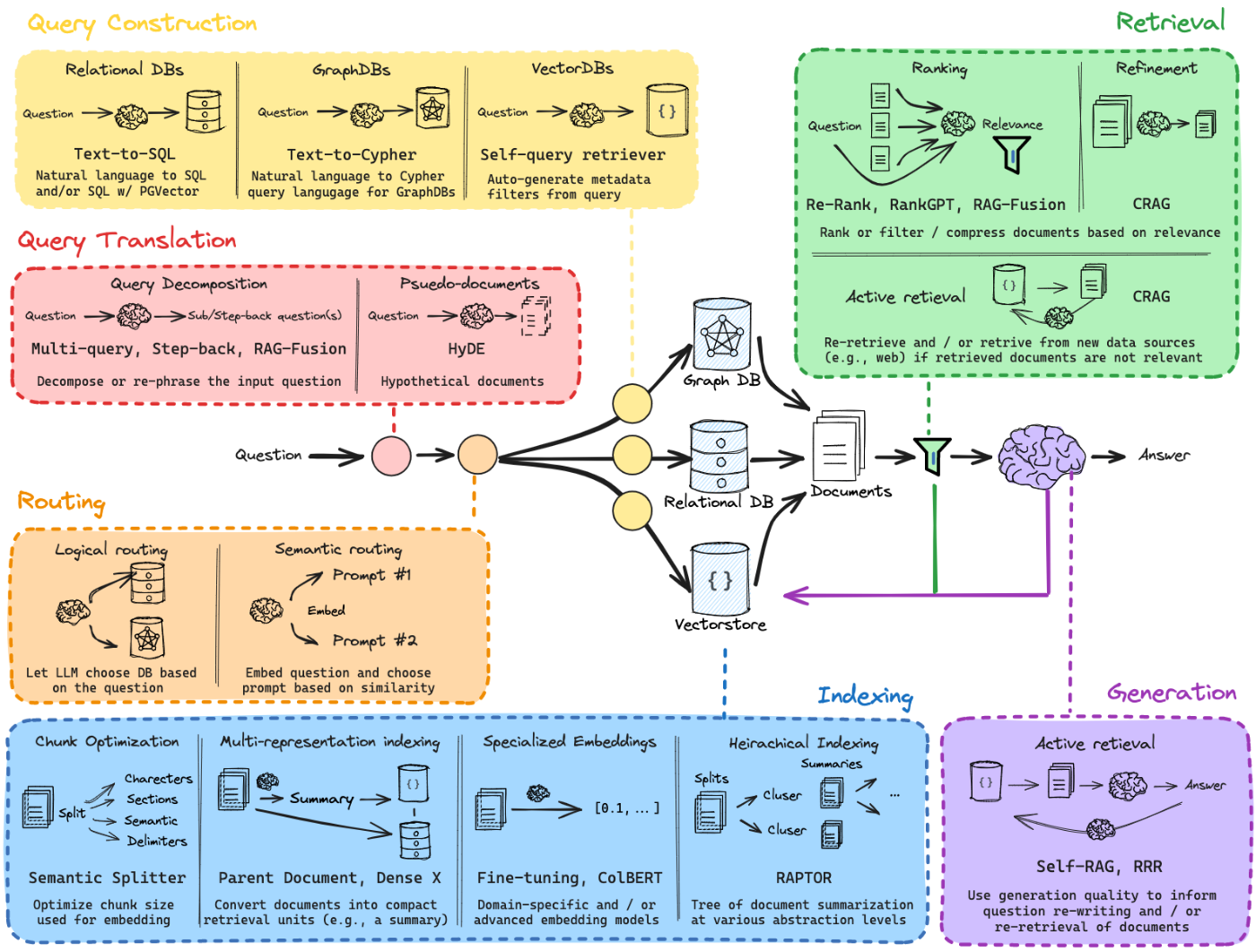
※ 遂にGenerationに焦点を当てた図すら載っていませんでした。。笑 そのため全体像の図を引用しています。Generationは右下の紫に該当する部分です。
Generationは、生成された回答の品質を評価をし、質問文の書き直しや文書の再検索に利用するアプローチです。この図では、以下の2手法が紹介されています。
- Self-RAG
- RRR(Rewrite-Retrieve-Read)
notebook内にはコードサンプルが無く、リンク紹介も不十分だったので関連情報を検索しながら自分なりにまとめています。
こちらのnotebookの17以降がGenerationに関する内容です。
https://github.com/langchain-ai/rag-from-scratch/blob/main/rag_from_scratch_15_to_18.ipynb
実行環境
必要なライブラリをインストール
! pip install langchain-chroma langchain_community tiktoken langchain-openai langchainhub langchain langgraph
環境変数に、OpenAI APIの認証情報等をセットします。(今回はAzure OpenAIのAPIを利用しました。)
環境変数の読み込み
from IPython import display # 結果を見やすくするライブラリインポート
import os
from dotenv import load_dotenv
load_dotenv() # 環境変数を読み込み
os.environ['LANGCHAIN_TRACING_V2'] = 'true'
os.environ['LANGCHAIN_ENDPOINT'] = 'https://api.smith.langchain.com'
# Azure OpenAI Service のAPI情報をセットする
AZURE_OPENAI_ENDPOINT=
AZURE_OPENAI_API_KEY=
# Azureのデプロイメント名をセット
DEPLOYMENT_NAME=
# APIのバージョンをセット
API_VERSION=
# Azureのembedding modelのデプロイメント名をセット
EMBE_DEPLOYMENT_NAME=
# embedding modelのAPIバージョンをセット
EMBE_API_VERSION=
# LangSmithのAPIKEYをセット(ない場合も実行可)
LANGCHAIN_API_KEY=
LLMにはgpt-4o-mini, 埋め込みモデルはtext-embedding-3-largeを使用しました。
Self-RAG
従来のRAG(図の左側)では、検索が必要かどうか、または取得した文書が関連しているかどうかに関わらず固定数(図では常に3件)の文書をLLMへ渡すと、汎用性が低下したり役に立たない回答生成につながる可能性がありました。
Self-RAGは、検索された文書と回答生成結果に対する自己反映/自己採点を組み込んだRAGの構成により、回答の品質と事実性を高めることを目指したアプローチです。
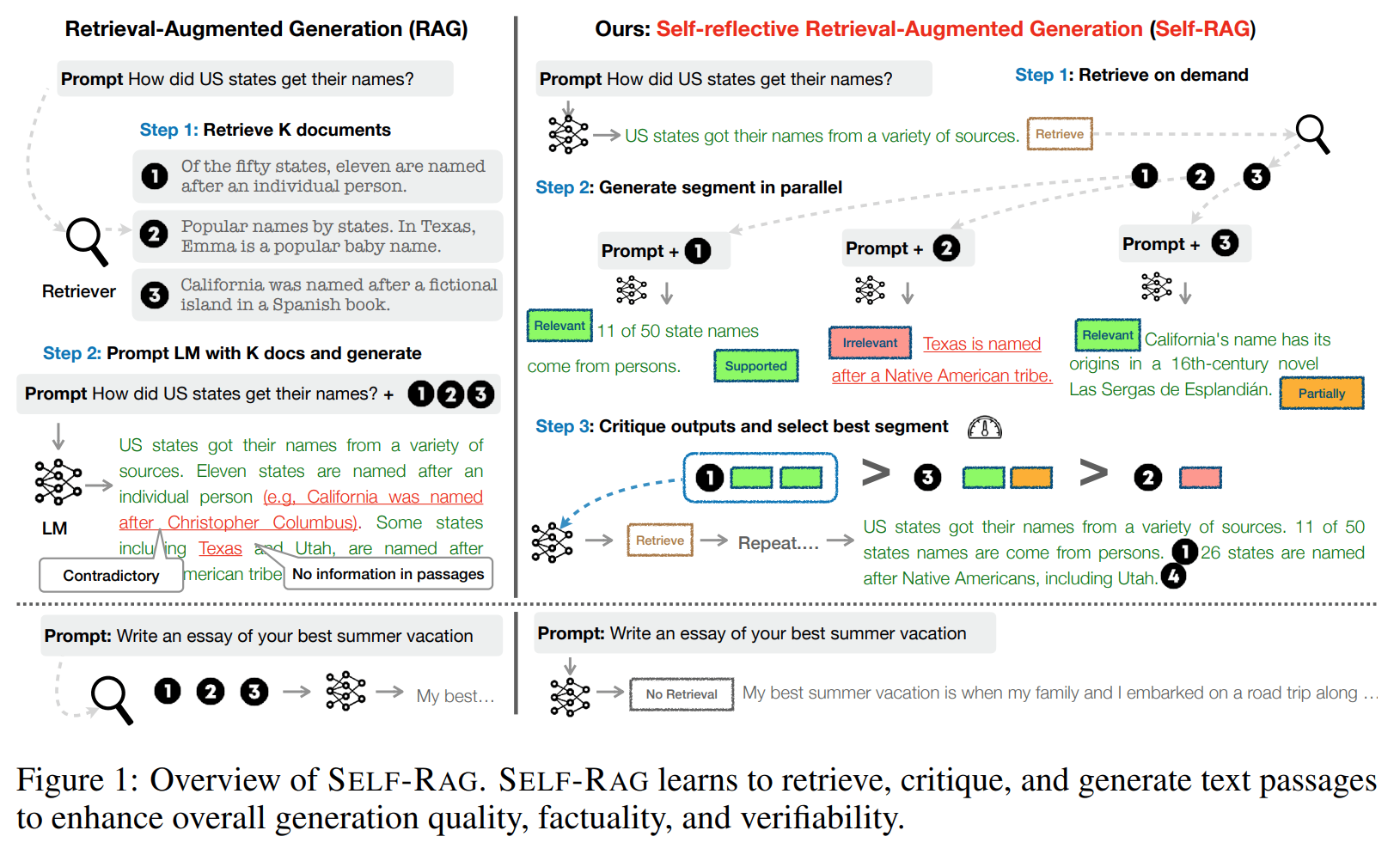
以下の論文で提案された手法です。上図はこちらから引用しました。
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection
以下にLangGraphを用いたSelf-RAGのcookbookが載っているので、こちらを動かしてみます。
(※コード内のコメントやプロンプトは日本語化して動かしています。原文が見たい方は以下を確認ください。)
https://github.com/langchain-ai/langchain/blob/master/cookbook/langgraph_self_rag.ipynb
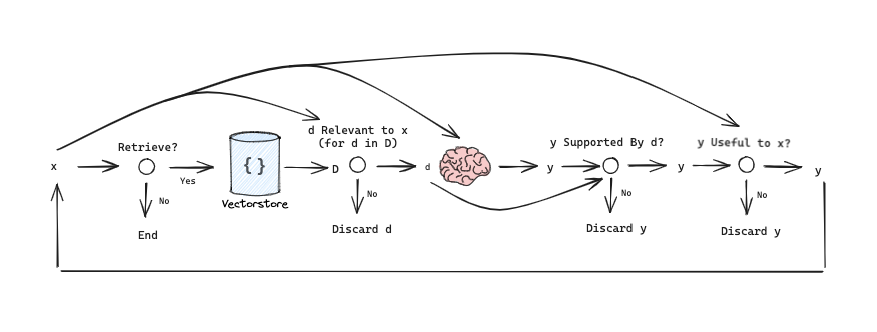
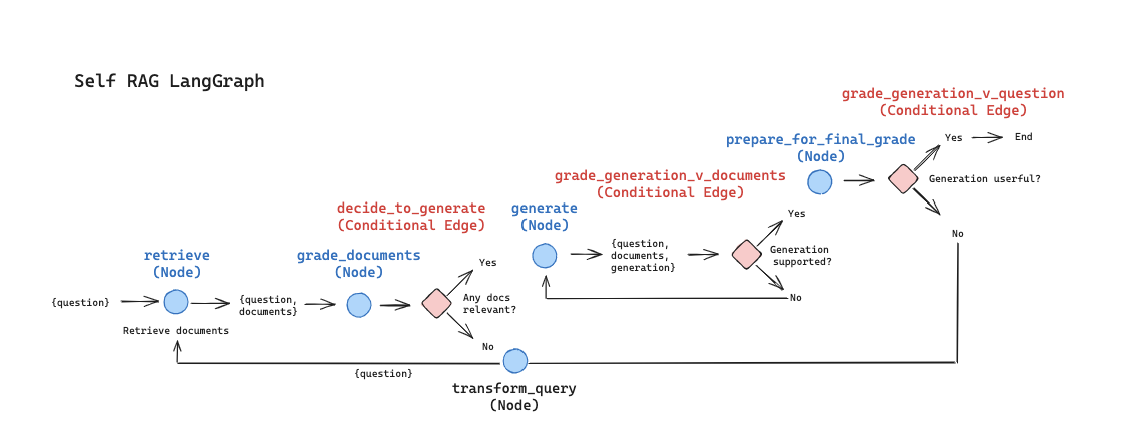
こちらのcookbookに、元論文のSelf-RAGの処理の流れがまとめてあります。(論文のTable 1, Algorithm 1をまとめた内容のようでした)
このフレームワークでは、任意の LM (LLaMA2-7b, 13b) を訓練して、RAGプロセスを制御するトークンを生成する:
- retriever
Rから関連情報を取得すべきか?
- トークン:
Retrieve- 入力:
x (question)ORx (question),y (generation)DチャンクをRから取得するタイミングを決定する。- 出力 :
yes, no, continue
- 検索された文章
Dは質問xに関連しているか?
- トークン:
ISREL- 入力: (
x (question),d (chunk)) fordinDdはxを解くために有用な情報を提供する。- 出力:
relevant, irrelevant(関連する、関連しない)
Dの各チャンクからのLLM生成はチャンクに関連しているか(幻覚など)
- トークン:
ISSUP- 入力:
x (question),d (chunk),y (generation)fordinDy (generation)に含まれる検証に値する文はすべてdでサポートされる。- 出力:
{fully supported, partially supported, no support(完全にサポートされている、>部分的にサポートされている、サポートされていない)
Dの各チャンクからのLLM 生成はx (question)に対する有用な応答であるか?を5段階で評価。
- トークン:
ISUSE- 入力:
x (question),y (generation)fordinDy (generation)はx (question)に対する有用な応答である。- 出力:
{5, 4, 3, 2, 1}
この流れをグラフ構造で表現すると以下の図になります。(cookbookから引用)
Self-RAGの論文の仕組みを参考に、LangGraphで実装するグラフ構造は以下となります。(cookbookから引用)
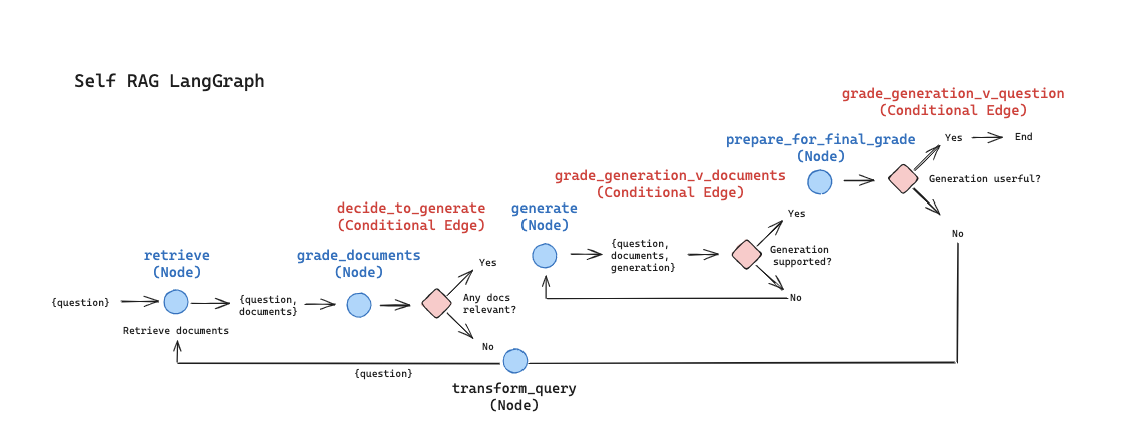
元論文と比較して、若干構成は異なるようです。(Retrieveノードで情報を取得するか?を判断する仕組みが無く質問文の内容に関わらず検索する流れになっている、有用な応答であるか?を5段階評価でなくYes/noの2段階評価にしている、など)
質問対象のベクトルDBの題材は、今回もサツマイモに関するwikipediaを使用します。
Retrieverの用意をするコード
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_chroma import Chroma
from langchain_community.document_loaders import WebBaseLoader
from langchain_openai import AzureOpenAIEmbeddings
urls = [
"https://ja.wikipedia.org/wiki/%E3%82%B5%E3%83%84%E3%83%9E%E3%82%A4%E3%83%A2", # さつまいもに関するwiki
"https://ja.wikipedia.org/wiki/%E7%84%BC%E3%81%8D%E8%8A%8B", # 焼き芋に関するwiki
]
docs = [WebBaseLoader(url).load() for url in urls]
docs_list = [item for sublist in docs for item in sublist]
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=250, chunk_overlap=0
)
doc_splits = text_splitter.split_documents(docs_list)
# Embed
embeddings = AzureOpenAIEmbeddings(
azure_deployment=os.environ.get("EMBE_DEPLOYMENT_NAME"),
openai_api_version=os.environ.get("EMBE_API_VERSION"),
)
# Add to vectorDB
vectorstore = Chroma.from_documents(
documents=doc_splits,
collection_name="rag-chroma",
embedding=embeddings,
)
retriever = vectorstore.as_retriever()
次にSelf-RAGの仕組みをグラフ構造(ノードとエッジ)で構成します。
※ 元のコードはgenerateノードのみLLMはgpt-3.5-turbo, 他のノードではgpt-4-0125-previewが利用されていましたが、このコード内では全てgpt-4o-miniを使用しています。
Self-RAG Graph構成コード
### NodeとEdgeの作成
from typing import Dict, TypedDict
class GraphState(TypedDict):
"""
会話におけるエージェントの状態を表します。
属性:
keys: 各キーが文字列であり、値がリストまたは `operator.add` を使用した加算をサポートする他の構造であることが期待される辞書です。
例えば、メッセージやグラフ全体を通して他のデータを蓄積するために使用できます。
"""
keys: Dict[str, any]
# from langchain import hub
from langchain.output_parsers.openai_tools import PydanticToolsParser
from langchain.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_core.utils.function_calling import convert_to_openai_tool
from langchain_openai import AzureChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
llm = AzureChatOpenAI(
openai_api_version=os.getenv("API_VERSION"),
azure_deployment=os.getenv("DEPLOYMENT_NAME"),
temperature=0
)
### ノード ###
def retrieve(state):
"""
ドキュメントを取得する
引数:
state (dict): エージェントの現在の状態。すべてのキーを含む。
戻り値:
dict: 新しいキー 'documents' を状態に追加した辞書を返す。取得したドキュメントが含まれている。
"""
print("---ドキュメント取得---")
state_dict = state["keys"]
question = state_dict["question"]
documents = retriever.invoke(question)
return {"keys": {"documents": documents, "question": question}}
def generate(state):
"""
回答を生成する
引数:
state (dict): エージェントの現在の状態。すべてのキーを含む。
戻り値:
dict: 新しいキー 'generation' を状態に追加した辞書を返す。生成した回答が含まれている。
"""
print("---回答生成---")
state_dict = state["keys"]
question = state_dict["question"]
documents = state_dict["documents"]
# RAG用のPromptを用意
# prompt = hub.pull("rlm/rag-prompt")
template = """以下の文脈のみに基づいて質問に答えてください:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
# チェーン
rag_chain = prompt | llm | StrOutputParser()
# 実行
generation = rag_chain.invoke({"context": documents, "question": question})
return {
"keys": {"documents": documents, "question": question, "generation": generation}
}
def grade_documents(state):
"""
取得したドキュメントが質問に関連しているかどうかを判定する。
引数:
state (dict): エージェントの現在の状態。すべてのキーを含む。
戻り値:
dict: 新しいキー 'filtered_documents' を状態に追加した辞書を返す。関連するドキュメントが含まれている。
"""
print("---関連性確認---")
state_dict = state["keys"]
question = state_dict["question"]
documents = state_dict["documents"]
# データモデル
class grade(BaseModel):
"""関連性チェックのためのバイナリスコア"""
binary_score: str = Field(description="関連性のスコア 'yes' または 'no'")
# ツール
grade_tool_oai = convert_to_openai_tool(grade)
# ツールを使って LLM をバインド
llm_with_tool = llm.bind(
tools=[convert_to_openai_tool(grade_tool_oai)],
tool_choice={"type": "function", "function": {"name": "grade"}},
)
# パーサー
parser_tool = PydanticToolsParser(tools=[grade])
# プロンプト
prompt = PromptTemplate(
template="""あなたは、取得したドキュメントがユーザーの質問に関連しているかを評価する採点者です。 \n
取得したドキュメントはこちらです: \n\n {context} \n\n
ユーザーの質問はこちらです: {question} \n
もしドキュメントがユーザーの質問に関連するキーワードまたは意味を含んでいれば、それを関連があると評価してください。 \n
ドキュメントが関連しているかどうかを示すバイナリスコア 'yes' または 'no' を付けてください。""",
input_variables=["context", "question"],
)
# チェーン
chain = prompt | llm_with_tool | parser_tool
# スコア
filtered_docs = []
for d in documents:
score = chain.invoke({"question": question, "context": d.page_content})
grade = score[0].binary_score
if grade == "yes":
print("---評価: ドキュメントは関連あり---")
filtered_docs.append(d)
else:
print("---評価: ドキュメントは関連なし---")
continue
return {"keys": {"documents": filtered_docs, "question": question}}
def transform_query(state):
"""
質問を改善するために変換する。
引数:
state (dict): エージェントの現在の状態。すべてのキーを含む。
戻り値:
dict: 新しく生成された質問が保存された辞書を返す。
"""
print("---質問を変換---")
state_dict = state["keys"]
question = state_dict["question"]
documents = state_dict["documents"]
# 質問を改善するためのプロンプトテンプレート
prompt = PromptTemplate(
template="""あなたは、情報検索に最適化された質問を生成しています。 \n
入力を見て、その基になる意味的意図を推論してください。 \n
こちらが最初の質問です:
\n ------- \n
{question}
\n ------- \n
改善された質問を作成してください: """,
input_variables=["question"],
)
# チェーン
chain = prompt | llm | StrOutputParser()
better_question = chain.invoke({"question": question})
return {"keys": {"documents": documents, "question": better_question}}
def prepare_for_final_grade(state):
"""
最終評価のための準備、状態をそのまま通過させる。
引数:
state (dict): エージェントの現在の状態。すべてのキーを含む。
戻り値:
state (dict): エージェントの現在の状態。すべてのキーを含む。
"""
print("---最終評価準備---")
state_dict = state["keys"]
question = state_dict["question"]
documents = state_dict["documents"]
generation = state_dict["generation"]
return {
"keys": {"documents": documents, "question": question, "generation": generation}
}
### エッジ ###
def decide_to_generate(state):
"""
回答を生成するか、質問を再生成するかを決定する。
引数:
state (dict): エージェントの現在の状態。すべてのキーを含む。
戻り値:
dict: 新しいキー 'filtered_documents' を状態に追加した辞書を返す。関連するドキュメントが含まれている。
"""
print("---生成の決定---")
state_dict = state["keys"]
filtered_documents = state_dict["documents"]
if not filtered_documents:
# すべてのドキュメントが関連性チェックでフィルタリングされた場合
# 新しい質問を再生成する
print("---決定: 質問を変換---")
return "transform_query"
else:
# 関連するドキュメントがあるので、回答を生成する
print("---決定: 回答を生成---")
return "generate"
def grade_generation_v_documents(state):
"""
生成した回答がドキュメントに基づいているかどうかを判定する。
引数:
state (dict): エージェントの現在の状態。すべてのキーを含む。
戻り値:
str: バイナリ決定スコア。
"""
print("---生成 vs ドキュメントの評価---")
state_dict = state["keys"]
documents = state_dict["documents"]
generation = state_dict["generation"]
# データモデル
class grade(BaseModel):
"""関連性チェックのためのバイナリスコア"""
binary_score: str = Field(description="サポートされるスコア 'yes' または 'no'")
# ツール
grade_tool_oai = convert_to_openai_tool(grade)
# ツールを使って LLM をバインド
llm_with_tool = llm.bind(
tools=[convert_to_openai_tool(grade_tool_oai)],
tool_choice={"type": "function", "function": {"name": "grade"}},
)
# パーサー
parser_tool = PydanticToolsParser(tools=[grade])
# プロンプト
prompt = PromptTemplate(
template="""あなたは、回答が事実のセットに基づいているかを評価する採点者です。 \n
こちらが事実です:
\n ------- \n
{documents}
\n ------- \n
こちらが回答です: {generation}
回答が事実のセットに基づいているかどうかを示すバイナリスコア 'yes' または 'no' を付けてください。""",
input_variables=["generation", "documents"],
)
# チェーン
chain = prompt | llm_with_tool | parser_tool
score = chain.invoke({"generation": generation, "documents": documents})
grade = score[0].binary_score
if grade == "yes":
print("---決定: サポートあり、最終評価へ進む---")
return "supported"
else:
print("---決定: サポートなし、再生成---")
return "not supported"
def grade_generation_v_question(state):
"""
生成した回答が質問に対応しているかどうかを判定する。
引数:
state (dict): エージェントの現在の状態。すべてのキーを含む。
戻り値:
str: バイナリ決定スコア。
"""
print("---生成 vs 質問の評価---")
state_dict = state["keys"]
question = state_dict["question"]
generation = state_dict["generation"]
# データモデル
class grade(BaseModel):
"""関連性チェックのためのバイナリスコア"""
binary_score: str = Field(description="有用なスコア 'yes' または 'no'")
# ツール
grade_tool_oai = convert_to_openai_tool(grade)
# ツールを使って LLM をバインド
llm_with_tool = llm.bind(
tools=[convert_to_openai_tool(grade_tool_oai)],
tool_choice={"type": "function", "function": {"name": "grade"}},
)
# パーサー
parser_tool = PydanticToolsParser(tools=[grade])
# プロンプト
prompt = PromptTemplate(
template="""あなたは、回答が質問を解決するのに有用かどうかを評価する採点者です。 \n
こちらが回答です:
\n ------- \n
{generation}
\n ------- \n
こちらが質問です: {question}
回答が質問を解決するのに有用かどうかを示すバイナリスコア 'yes' または 'no' を付けてください。""",
input_variables=["generation", "question"],
)
# チェーン
chain = prompt | llm_with_tool | parser_tool
score = chain.invoke({"generation": generation, "question": question})
grade = score[0].binary_score
if grade == "yes":
print("---決定: 有用---")
return "useful"
else:
print("---決定: 有用でない---")
return "not useful"
### Graphの作成
import pprint
from langgraph.graph import END, StateGraph
workflow = StateGraph(GraphState)
# ノードを定義する
workflow.add_node("retrieve", retrieve) # ドキュメントの取得
workflow.add_node("grade_documents", grade_documents) # ドキュメントの評価
workflow.add_node("generate", generate) # 回答の生成
workflow.add_node("transform_query", transform_query) # クエリの変換
workflow.add_node("prepare_for_final_grade", prepare_for_final_grade) # 最終評価準備
# グラフを構築する
workflow.set_entry_point("retrieve")
workflow.add_edge("retrieve", "grade_documents")
workflow.add_conditional_edges(
"grade_documents",
decide_to_generate,
{
"transform_query": "transform_query", # クエリ変換への遷移
"generate": "generate", # 回答生成への遷移
},
)
workflow.add_edge("transform_query", "retrieve")
workflow.add_conditional_edges(
"generate",
grade_generation_v_documents,
{
"supported": "prepare_for_final_grade", # 支持された場合、最終評価準備へ
"not supported": "generate", # 支持されなかった場合、再度生成へ
},
)
workflow.add_conditional_edges(
"prepare_for_final_grade",
grade_generation_v_question,
{
"useful": END, # 有用な場合、終了
"not useful": "transform_query", # 有用でない場合、クエリ変換へ
},
)
# コンパイル
app = workflow.compile()
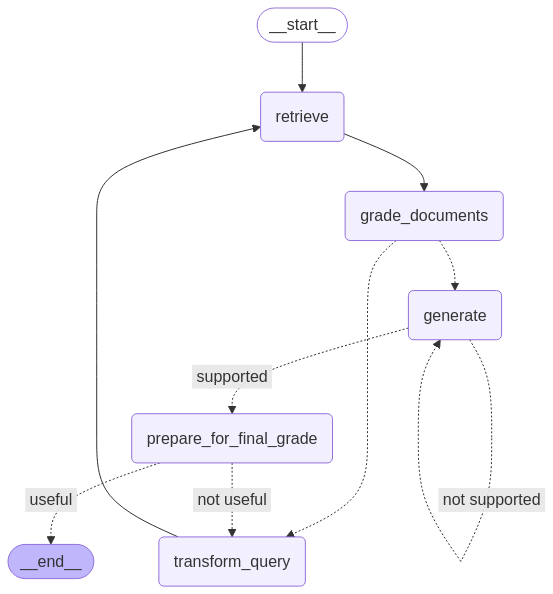
コンパイル後のグラフを可視化すると以下の構成になっていました。
質問文を渡し、回答生成するコード
# 実行
inputs = {"keys": {"question": "サツマイモのさまざまな品種とその味わいや向いている調理方法について詳しく説明してください。"}} # 入力データ(質問)
for output in app.stream(inputs): # アプリケーションのストリームを実行
for key, value in output.items(): # 出力をノードごとに処理
pprint.pprint(f"ノード '{key}' からの出力:")
pprint.pprint("---")
pprint.pprint(value["keys"], indent=2, width=80, depth=None) # ノードのキー部分を表示
pprint.pprint("\n---\n") # 各ノードの出力後に区切り線を表示
print(output['prepare_for_final_grade']['keys']['generation'])
「サツマイモのさまざまな品種とその味わいや向いている調理方法について詳しく説明してください。」に対する実行結果は以下となりました。
---ドキュメント取得---
"ノード 'retrieve' からの出力:"
'---'
{ 'documents': [ Document(id='13ed38a0-83c9-483e-b215-f78a04161762', metadata={'language': 'ja', 'source': 'https://ja.wikipedia.org/wiki/%E3%82%B5%E3%83%84%E3%83%9E%E3%82%A4%E3%83%A2', 'title': 'サツマイモ - Wikipedia'}, page_content='明治時代になり、各地に海外から新品種のサツマイモが導入され、品種改良も進み、現在は多様な品種が栽培されている。'),
Document(id='6a50d8f4-29c9-47df-8cdb-51cd59d54282', metadata={'language': 'ja', 'source': 'https://ja.wikipedia.org/wiki/%E3%82%B5%E3%83%84%E3%83%9E%E3%82%A4%E3%83%A2', 'title': 'サツマイモ - Wikipedia'}, page_content='品種[編集]\n日本におけるサツマイモの品種別栽培面積\n掘り出したサツマイモ'),
Document(id='2e0fedeb-99a8-449f-9ae0-34baeab7e5a4', metadata={'language': 'ja', 'source': 'https://ja.wikipedia.org/wiki/%E3%82%B5%E3%83%84%E3%83%9E%E3%82%A4%E3%83%A2', 'title': 'サツマイモ - Wikipedia'}, page_content='ベルベット - 大正時代にアメリカから日本へ導入された鹿児島で栽培される品種。皮は紅色、中身がオレンジ色でその周囲が紫色をしているのが特徴。粘質で、天ぷらや干し芋にされる[25]。\nシモンイモ - 南アメリカ原産の白甘藷(英語:Ipomoea batatas)は、日本では「シモン芋」とも呼ばれる[要出典]。\n栽培[編集]\nサツマイモ畑'),
Document(id='5de832ba-b48a-4561-857d-41ed996cd327', metadata={'language': 'ja', 'source': 'https://ja.wikipedia.org/wiki/%E3%82%B5%E3%83%84%E3%83%9E%E3%82%A4%E3%83%A2', 'title': 'サツマイモ - Wikipedia'}, page_content='芋の皮の色は紅色や赤紫色の他、黄色や白色がある[3]。芋の中身は主に白色から黄色で、中には橙色や紫色になる品種もある[3]。特に全体が紫で、芋の中身がアントシアニンに由来して紫色のサツマイモを、紫芋(むらさきいも)と呼んでいる[18]。')],
'question': 'サツマイモのさまざまな品種とその味わいや向いている調理方法について詳しく説明してください。'}
'\n---\n'
---関連性確認---
---評価: ドキュメントは関連あり---
---評価: ドキュメントは関連なし---
---評価: ドキュメントは関連あり---
---評価: ドキュメントは関連なし---
---生成の決定---
---決定: 回答を生成---
"ノード 'grade_documents' からの出力:"
'---'
{ 'documents': [ Document(id='13ed38a0-83c9-483e-b215-f78a04161762', metadata={'language': 'ja', 'source': 'https://ja.wikipedia.org/wiki/%E3%82%B5%E3%83%84%E3%83%9E%E3%82%A4%E3%83%A2', 'title': 'サツマイモ - Wikipedia'}, page_content='明治時代になり、各地に海外から新品種のサツマイモが導入され、品種改良も進み、現在は多様な品種が栽培されている。'),
Document(id='2e0fedeb-99a8-449f-9ae0-34baeab7e5a4', metadata={'language': 'ja', 'source': 'https://ja.wikipedia.org/wiki/%E3%82%B5%E3%83%84%E3%83%9E%E3%82%A4%E3%83%A2', 'title': 'サツマイモ - Wikipedia'}, page_content='ベルベット - 大正時代にアメリカから日本へ導入された鹿児島で栽培される品種。皮は紅色、中身がオレンジ色でその周囲が紫色をしているのが特徴。粘質で、天ぷらや干し芋にされる[25]。\nシモンイモ - 南アメリカ原産の白甘藷(英語:Ipomoea batatas)は、日本では「シモン芋」とも呼ばれる[要出典]。\n栽培[編集]\nサツマイモ畑')],
'question': 'サツマイモのさまざまな品種とその味わいや向いている調理方法について詳しく説明してください。'}
'\n---\n'
---回答生成---
---生成 vs ドキュメントの評価---
---決定: サポートあり、最終評価へ進む---
"ノード 'generate' からの出力:"
'---'
{ 'documents': [ Document(id='13ed38a0-83c9-483e-b215-f78a04161762', metadata={'language': 'ja', 'source': 'https://ja.wikipedia.org/wiki/%E3%82%B5%E3%83%84%E3%83%9E%E3%82%A4%E3%83%A2', 'title': 'サツマイモ - Wikipedia'}, page_content='明治時代になり、各地に海外から新品種のサツマイモが導入され、品種改良も進み、現在は多様な品種が栽培されている。'),
Document(id='2e0fedeb-99a8-449f-9ae0-34baeab7e5a4', metadata={'language': 'ja', 'source': 'https://ja.wikipedia.org/wiki/%E3%82%B5%E3%83%84%E3%83%9E%E3%82%A4%E3%83%A2', 'title': 'サツマイモ - Wikipedia'}, page_content='ベルベット - 大正時代にアメリカから日本へ導入された鹿児島で栽培される品種。皮は紅色、中身がオレンジ色でその周囲が紫色をしているのが特徴。粘質で、天ぷらや干し芋にされる[25]。\nシモンイモ - 南アメリカ原産の白甘藷(英語:Ipomoea batatas)は、日本では「シモン芋」とも呼ばれる[要出典]。\n栽培[編集]\nサツマイモ畑')],
'generation': 'サツマイモには多様な品種があり、それぞれに特徴や味わい、向いている調理方法があります。以下にいくつかの品種を挙げて説明します。\n'
'\n'
'1. **ベルベット**:\n'
' - **特徴**: '
'大正時代にアメリカから導入された品種で、鹿児島で栽培されています。皮は紅色で、中身はオレンジ色、その周囲が紫色をしています。\n'
' - **味わい**: 粘質で甘みが強いのが特徴です。\n'
' - **調理方法**: 天ぷらや干し芋にするのに適しています。\n'
'\n'
'2. **シモンイモ**:\n'
' - **特徴**: 南アメリカ原産の白甘藷で、日本では「シモン芋」とも呼ばれています。\n'
' - **味わい**: 甘さが控えめで、さっぱりとした味わいです。\n'
' - **調理方法**: 煮物や蒸し料理に向いています。\n'
'\n'
'これらの品種は、明治時代以降に海外から導入されたもので、品種改良が進むことで現在は多様なサツマイモが栽培されています。それぞれの品種の特性を活かした調理法を選ぶことで、より美味しく楽しむことができます。',
'question': 'サツマイモのさまざまな品種とその味わいや向いている調理方法について詳しく説明してください。'}
'\n---\n'
---最終評価準備---
---生成 vs 質問の評価---
---決定: 有用---
"ノード 'prepare_for_final_grade' からの出力:"
'---'
{ 'documents': [ Document(id='13ed38a0-83c9-483e-b215-f78a04161762', metadata={'language': 'ja', 'source': 'https://ja.wikipedia.org/wiki/%E3%82%B5%E3%83%84%E3%83%9E%E3%82%A4%E3%83%A2', 'title': 'サツマイモ - Wikipedia'}, page_content='明治時代になり、各地に海外から新品種のサツマイモが導入され、品種改良も進み、現在は多様な品種が栽培されている。'),
Document(id='2e0fedeb-99a8-449f-9ae0-34baeab7e5a4', metadata={'language': 'ja', 'source': 'https://ja.wikipedia.org/wiki/%E3%82%B5%E3%83%84%E3%83%9E%E3%82%A4%E3%83%A2', 'title': 'サツマイモ - Wikipedia'}, page_content='ベルベット - 大正時代にアメリカから日本へ導入された鹿児島で栽培される品種。皮は紅色、中身がオレンジ色でその周囲が紫色をしているのが特徴。粘質で、天ぷらや干し芋にされる[25]。\nシモンイモ - 南アメリカ原産の白甘藷(英語:Ipomoea batatas)は、日本では「シモン芋」とも呼ばれる[要出典]。\n栽培[編集]\nサツマイモ畑')],
'generation': 'サツマイモには多様な品種があり、それぞれに特徴や味わい、向いている調理方法があります。以下にいくつかの品種を挙げて説明します。\n'
'\n'
'1. **ベルベット**:\n'
' - **特徴**: '
'大正時代にアメリカから導入された品種で、鹿児島で栽培されています。皮は紅色で、中身はオレンジ色、その周囲が紫色をしています。\n'
' - **味わい**: 粘質で甘みが強いのが特徴です。\n'
' - **調理方法**: 天ぷらや干し芋にするのに適しています。\n'
'\n'
'2. **シモンイモ**:\n'
' - **特徴**: 南アメリカ原産の白甘藷で、日本では「シモン芋」とも呼ばれています。\n'
' - **味わい**: 甘さが控えめで、さっぱりとした味わいです。\n'
' - **調理方法**: 煮物や蒸し料理に向いています。\n'
'\n'
'これらの品種は、明治時代以降に海外から導入されたもので、品種改良が進むことで現在は多様なサツマイモが栽培されています。それぞれの品種の特性を活かした調理法を選ぶことで、より美味しく楽しむことができます。',
'question': 'サツマイモのさまざまな品種とその味わいや向いている調理方法について詳しく説明してください。'}
'\n---\n'
関連性確認のノードで、2つ目と4つ目のチャンクが"関連あり"と判断され、その2件のみが回答生成に使われています。---生成 vs ドキュメントの評価---でも生成した回答がドキュメントに基づいていると判定されて最終評価へ進んでいる流れが確認できました。
最終出力は以下となりました。
サツマイモには多様な品種があり、それぞれに特徴や味わい、向いている調理方法があります。以下にいくつかの品種を挙げて説明します。
1. **ベルベット**:
- **特徴**: 大正時代にアメリカから導入された品種で、鹿児島で栽培されています。皮は紅色で、中身はオレンジ色、その周囲が紫色をしています。
- **味わい**: 粘質で甘みが強いのが特徴です。
- **調理方法**: 天ぷらや干し芋にするのに適しています。
2. **シモンイモ**:
- **特徴**: 南アメリカ原産の白甘藷で、日本では「シモン芋」とも呼ばれています。
- **味わい**: 甘さが控えめで、さっぱりとした味わいです。
- **調理方法**: 煮物や蒸し料理に向いています。
これらの品種は、明治時代以降に海外から導入されたもので、品種改良が進むことで現在は多様なサツマイモが栽培されています。それぞれの品種の特性を活かした調理法を選ぶことで、より美味しく楽しむことができます。
質問文を「紅はるかにはどのような特徴があるかを説明してください。」に変えて、同様のコードで実行してみます。
---ドキュメント取得---
"Output from node 'retrieve':"
'---'
{ 'documents': [ Document(id='14d3f7b4-1855-4db7-9bd9-95df85bf1d29', metadata={'language': 'ja', 'source': 'https://ja.wikipedia.org/wiki/%E3%82%B5%E3%83%84%E3%83%9E%E3%82%A4%E3%83%A2', 'title': 'サツマイモ - Wikipedia'}, page_content='紅はるか(べにはるか) -'),
Document(id='a7c7ce55-de12-4ac1-921a-bbaa0c6f6112', metadata={'language': 'ja', 'source': 'https://ja.wikipedia.org/wiki/%E3%82%B5%E3%83%84%E3%83%9E%E3%82%A4%E3%83%A2', 'title': 'サツマイモ - Wikipedia'}, page_content='紅赤(べにあか) - かつて関東地方の代表的な品種で、皮が鮮やかな赤紫色で細長いのが特徴。細すぎるのは繊維が多い。加熱すると中が濃い黄色になって甘味が強く、焼き芋や栗金団用に人気がある[25]。'),
Document(id='9f1c696b-feec-4f79-b8b6-0be80d11da09', metadata={'language': 'ja', 'source': 'https://ja.wikipedia.org/wiki/%E3%82%B5%E3%83%84%E3%83%9E%E3%82%A4%E3%83%A2', 'title': 'サツマイモ - Wikipedia'}, page_content='鳴門金時と同じ高系14号系の品種。「九州121号」と「春こがね」を交配させて誕生した。[24]名前の由来は、食味や外観が既存品種よりも「はるか」に優れていることから。甘味が強く、水分が多めで、蒸し芋や干し芋にすると美味しい[23]。農林水産省の統計によれば、紅はるかの全国作付け面積は2012年産で2037ヘクタール、20'),
Document(id='901be39a-1349-4467-a0fd-f6aaacea5bd7', metadata={'language': 'ja', 'source': 'https://ja.wikipedia.org/wiki/%E3%82%B5%E3%83%84%E3%83%9E%E3%82%A4%E3%83%A2', 'title': 'サツマイモ - Wikipedia'}, page_content='^ a b 舟和」芋ようかん値上げ\u3000「紅あずま」仕入れ難航\u3000焼き芋人気、「紅はるか」転作続々 朝日新聞、2024年2月2日閲覧\n\n^ a b c d e f g h i j k l 猪股慶子監修 成美堂出版編集部編 2012, p.\xa0107.\n\n^ “べにはるか | 農研機構”. www.naro.go.jp. 2024年7月31日閲覧。\n\n^ a b c d e f g h 講談社編 2013, p.\xa0184.')],
'question': '紅はるかにはどのような特徴があるかを説明してください。'}
'\n---\n'
---関連性確認---
---評価: ドキュメントは関連あり---
---評価: ドキュメントは関連なし---
---評価: ドキュメントは関連あり---
---評価: ドキュメントは関連あり---
---生成の決定---
---決定: 回答を生成---
"Output from node 'grade_documents':"
'---'
{ 'documents': [ Document(id='14d3f7b4-1855-4db7-9bd9-95df85bf1d29', metadata={'language': 'ja', 'source': 'https://ja.wikipedia.org/wiki/%E3%82%B5%E3%83%84%E3%83%9E%E3%82%A4%E3%83%A2', 'title': 'サツマイモ - Wikipedia'}, page_content='紅はるか(べにはるか) -'),
Document(id='9f1c696b-feec-4f79-b8b6-0be80d11da09', metadata={'language': 'ja', 'source': 'https://ja.wikipedia.org/wiki/%E3%82%B5%E3%83%84%E3%83%9E%E3%82%A4%E3%83%A2', 'title': 'サツマイモ - Wikipedia'}, page_content='鳴門金時と同じ高系14号系の品種。「九州121号」と「春こがね」を交配させて誕生した。[24]名前の由来は、食味や外観が既存品種よりも「はるか」に優れていることから。甘味が強く、水分が多めで、蒸し芋や干し芋にすると美味しい[23]。農林水産省の統計によれば、紅はるかの全国作付け面積は2012年産で2037ヘクタール、20'),
Document(id='901be39a-1349-4467-a0fd-f6aaacea5bd7', metadata={'language': 'ja', 'source': 'https://ja.wikipedia.org/wiki/%E3%82%B5%E3%83%84%E3%83%9E%E3%82%A4%E3%83%A2', 'title': 'サツマイモ - Wikipedia'}, page_content='^ a b 舟和」芋ようかん値上げ\u3000「紅あずま」仕入れ難航\u3000焼き芋人気、「紅はるか」転作続々 朝日新聞、2024年2月2日閲覧\n\n^ a b c d e f g h i j k l 猪股慶子監修 成美堂出版編集部編 2012, p.\xa0107.\n\n^ “べにはるか | 農研機構”. www.naro.go.jp. 2024年7月31日閲覧。\n\n^ a b c d e f g h 講談社編 2013, p.\xa0184.')],
'question': '紅はるかにはどのような特徴があるかを説明してください。'}
'\n---\n'
---回答生成---
---生成 vs ドキュメントの評価---
---決定: サポートあり、最終評価へ進む---
"Output from node 'generate':"
'---'
{ 'documents': [ Document(id='14d3f7b4-1855-4db7-9bd9-95df85bf1d29', metadata={'language': 'ja', 'source': 'https://ja.wikipedia.org/wiki/%E3%82%B5%E3%83%84%E3%83%9E%E3%82%A4%E3%83%A2', 'title': 'サツマイモ - Wikipedia'}, page_content='紅はるか(べにはるか) -'),
Document(id='9f1c696b-feec-4f79-b8b6-0be80d11da09', metadata={'language': 'ja', 'source': 'https://ja.wikipedia.org/wiki/%E3%82%B5%E3%83%84%E3%83%9E%E3%82%A4%E3%83%A2', 'title': 'サツマイモ - Wikipedia'}, page_content='鳴門金時と同じ高系14号系の品種。「九州121号」と「春こがね」を交配させて誕生した。[24]名前の由来は、食味や外観が既存品種よりも「はるか」に優れていることから。甘味が強く、水分が多めで、蒸し芋や干し芋にすると美味しい[23]。農林水産省の統計によれば、紅はるかの全国作付け面積は2012年産で2037ヘクタール、20'),
Document(id='901be39a-1349-4467-a0fd-f6aaacea5bd7', metadata={'language': 'ja', 'source': 'https://ja.wikipedia.org/wiki/%E3%82%B5%E3%83%84%E3%83%9E%E3%82%A4%E3%83%A2', 'title': 'サツマイモ - Wikipedia'}, page_content='^ a b 舟和」芋ようかん値上げ\u3000「紅あずま」仕入れ難航\u3000焼き芋人気、「紅はるか」転作続々 朝日新聞、2024年2月2日閲覧\n\n^ a b c d e f g h i j k l 猪股慶子監修 成美堂出版編集部編 2012, p.\xa0107.\n\n^ “べにはるか | 農研機構”. www.naro.go.jp. 2024年7月31日閲覧。\n\n^ a b c d e f g h 講談社編 2013, p.\xa0184.')],
'generation': '紅はるか(べにはるか)は、食味や外観が既存品種よりも「はるか」に優れていることが特徴です。甘味が強く、水分が多めで、蒸し芋や干し芋にすると特に美味しいとされています。また、鳴門金時と同じ高系14号系の品種であり、「九州121号」と「春こがね」を交配させて誕生しました。',
'question': '紅はるかにはどのような特徴があるかを説明してください。'}
'\n---\n'
---最終評価準備---
---生成 vs 質問の評価---
---決定: 有用---
"Output from node 'prepare_for_final_grade':"
'---'
{ 'documents': [ Document(id='14d3f7b4-1855-4db7-9bd9-95df85bf1d29', metadata={'language': 'ja', 'source': 'https://ja.wikipedia.org/wiki/%E3%82%B5%E3%83%84%E3%83%9E%E3%82%A4%E3%83%A2', 'title': 'サツマイモ - Wikipedia'}, page_content='紅はるか(べにはるか) -'),
Document(id='9f1c696b-feec-4f79-b8b6-0be80d11da09', metadata={'language': 'ja', 'source': 'https://ja.wikipedia.org/wiki/%E3%82%B5%E3%83%84%E3%83%9E%E3%82%A4%E3%83%A2', 'title': 'サツマイモ - Wikipedia'}, page_content='鳴門金時と同じ高系14号系の品種。「九州121号」と「春こがね」を交配させて誕生した。[24]名前の由来は、食味や外観が既存品種よりも「はるか」に優れていることから。甘味が強く、水分が多めで、蒸し芋や干し芋にすると美味しい[23]。農林水産省の統計によれば、紅はるかの全国作付け面積は2012年産で2037ヘクタール、20'),
Document(id='901be39a-1349-4467-a0fd-f6aaacea5bd7', metadata={'language': 'ja', 'source': 'https://ja.wikipedia.org/wiki/%E3%82%B5%E3%83%84%E3%83%9E%E3%82%A4%E3%83%A2', 'title': 'サツマイモ - Wikipedia'}, page_content='^ a b 舟和」芋ようかん値上げ\u3000「紅あずま」仕入れ難航\u3000焼き芋人気、「紅はるか」転作続々 朝日新聞、2024年2月2日閲覧\n\n^ a b c d e f g h i j k l 猪股慶子監修 成美堂出版編集部編 2012, p.\xa0107.\n\n^ “べにはるか | 農研機構”. www.naro.go.jp. 2024年7月31日閲覧。\n\n^ a b c d e f g h 講談社編 2013, p.\xa0184.')],
'generation': '紅はるか(べにはるか)は、食味や外観が既存品種よりも「はるか」に優れていることが特徴です。甘味が強く、水分が多めで、蒸し芋や干し芋にすると特に美味しいとされています。また、鳴門金時と同じ高系14号系の品種であり、「九州121号」と「春こがね」を交配させて誕生しました。',
'question': '紅はるかにはどのような特徴があるかを説明してください。'}
'\n---\n'
紅はるか(べにはるか)は、食味や外観が既存品種よりも「はるか」に優れていることが特徴です。甘味が強く、水分が多めで、蒸し芋や干し芋にすると特に美味しいとされています。また、鳴門金時と同じ高系14号系の品種であり、「九州121号」と「春こがね」を交配させて誕生しました。
関連性確認では、2件目以外は"関連あり"と判断されました。"関連あり"と判断されたチャンクを見てみると、文章をみて"関連あり"と判断できているものもあれば、"紅はるか"というキーワードが含まれていれば"関連あり"と判断してしまっているように見えるものもありました。この辺りは改善の余地ありですね。
最終出力は以下でした。
紅はるか(べにはるか)は、食味や外観が既存品種よりも「はるか」に優れていることが特徴です。甘味が強く、水分が多めで、蒸し芋や干し芋にすると特に美味しいとされています。また、鳴門金時と同じ高系14号系の品種であり、「九州121号」と「春こがね」を交配させて誕生しました。
LangGraphの公式チュートリアルにもSelf-RAGがありました。
上記のcookbookと比較して、若干グラフの構成が異なりますが(ノード数が1つ少ない)おおよその流れは同様でした。
https://langchain-ai.github.io/langgraph/tutorials/rag/langgraph_self_rag/
RRR(Rewrite-Retrieve-Read)
以下の論文で提案された手法で、図もこちらから引用しています。
Query Rewriting for Retrieval-Augmented Large Language Models
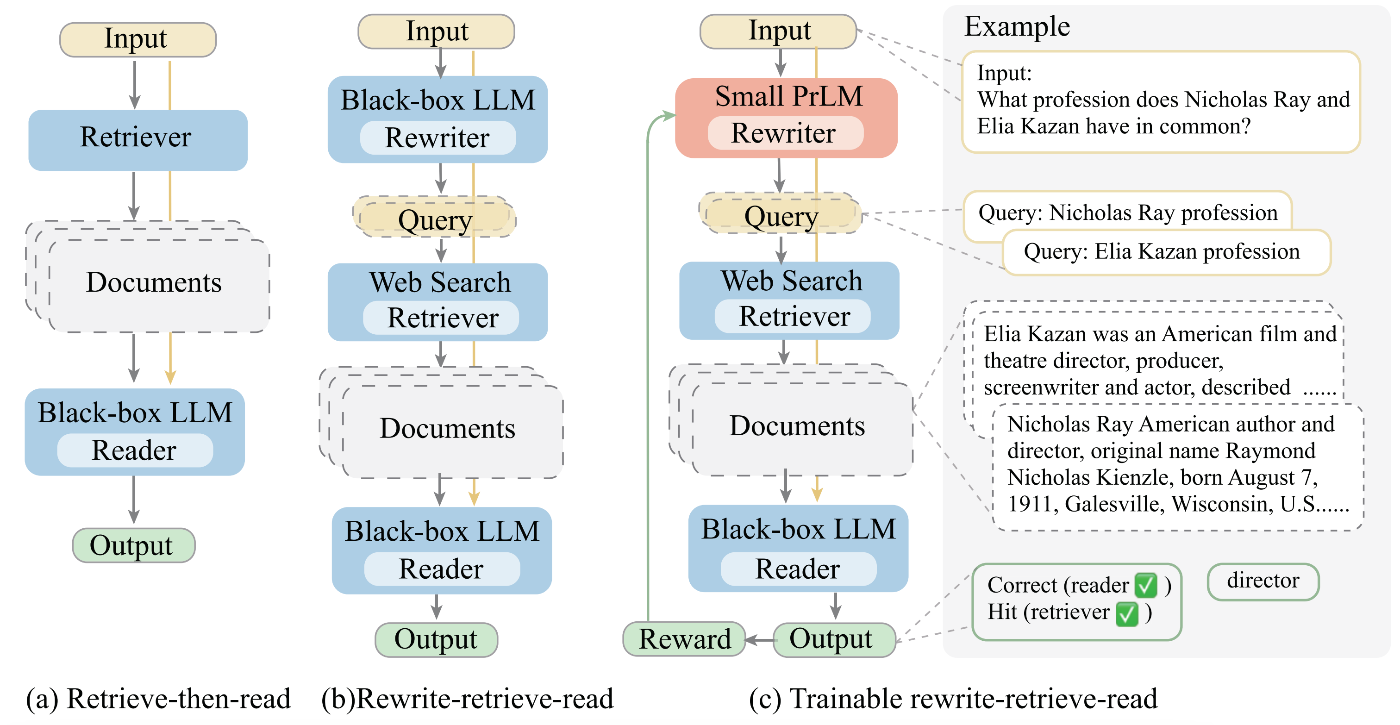
(b)がRewrite-Retrieve-Read(RRR)の仕組みになっており、ユーザの質問文を、Web検索に向いた複数クエリへ書き換え(Rewrite)してから情報取得(Retrieve)し、LLMへ読ませて(Read)最終回答を生成させる流れです。
論文のメインは(c)のRRRのフレームワークを基にLLMの最終出力を評価し、その結果のフィードバックを使用して小さな言語モデルSmall PrLMをトレーニングしてクエリ書き換え専用モデル(Rewriter model)を構築するためのパイプラインのようです。
以下にlangchainによるRRRのサンプルコードが公開されています。
https://github.com/langchain-ai/langchain/blob/master/cookbook/rewrite.ipynb
コードの中身は、ユーザ質問文をWeb検索向きな検索クエリへ変換する処理でした。
以下の記事で紹介したようなクエリ変換やクエリ構築に近い考え方と思いますので、この記事内では省略します。
おわりに
LangChain公式リポジトリに公開されているRAG From Scratchをやってみたシリーズは今回で最後となります。最後になるにつれてリポジトリにコード例が載っておらず、自分で調べながらまとめる内容になってしまいましたが、プロンプトテンプレートの中身を確認したり、日本語訳して仕組みまで確認することができたので、これまでなんとなくの理解だったRAGの要素技術に対する理解が深まった気がします。
参考
-
https://github.com/langchain-ai/rag-from-scratch/blob/main/rag_from_scratch_15_to_18.ipynb
-
https://github.com/langchain-ai/langchain/blob/master/cookbook/langgraph_self_rag.ipynb
-
https://langchain-ai.github.io/langgraph/tutorials/rag/langgraph_self_rag/
-
https://github.com/langchain-ai/langchain/blob/master/cookbook/rewrite.ipynb
Discussion