RAG From Scratch をやってみた (3/6) : Query Construction
概要
今回はRAGの構成のなかのQuery Constructionに関する部分を読み解いてみた内容です。
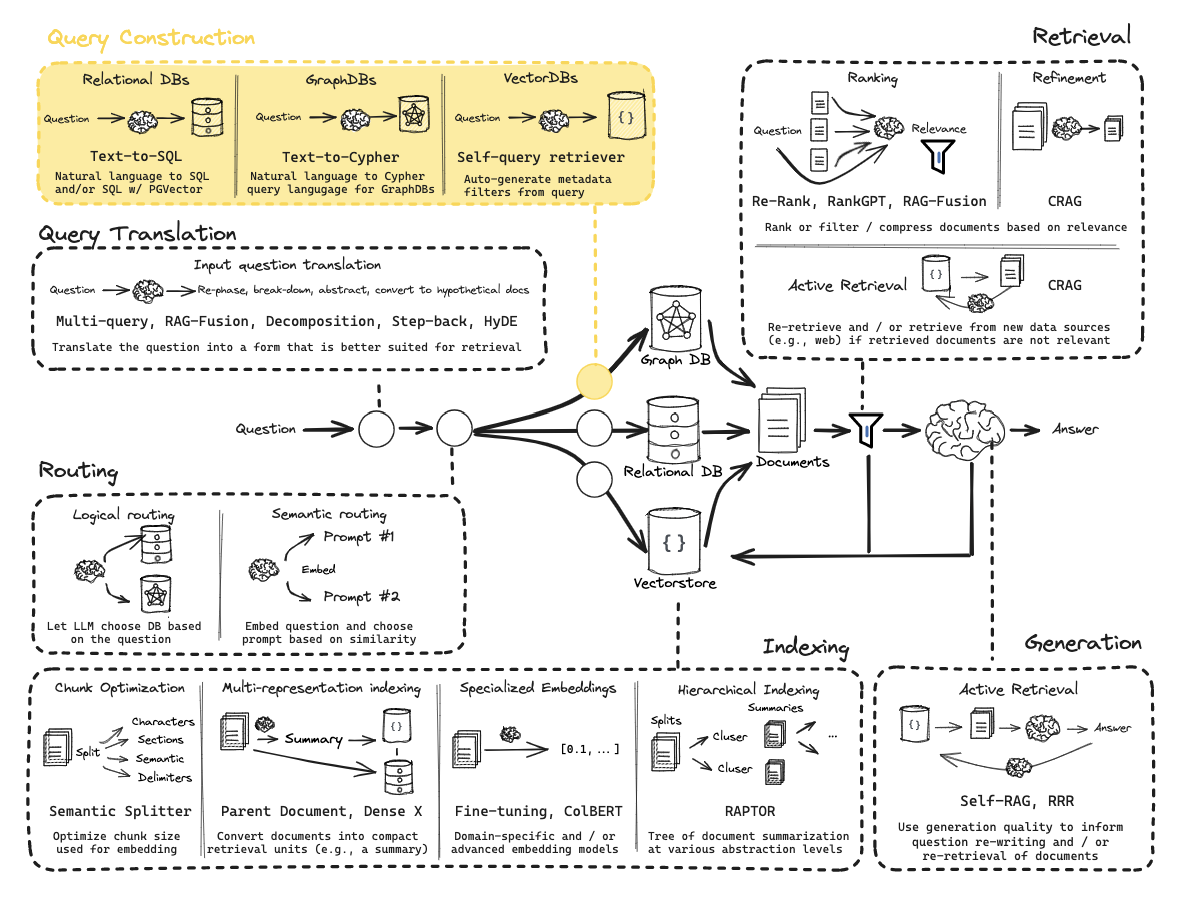
クエリ構築としては、図では以下3手法が載っていますが
- Text-to-SQL(リレーショナルDBに対するアプローチ)
- Text-to-Cypher(グラフDBに対するアプローチ)
- Self-query Retriever(ベクトルDBに対するアプローチ)
今回はコード例が載っていた3. Self-query Retriever をやってみました。
※ 1, 2の方法は以下リンクが紹介されていました。
こちらのnotebookを実行してみながらまとめました。
https://github.com/langchain-ai/rag-from-scratch/blob/main/rag_from_scratch_10_and_11.ipynb
実行環境
必要なライブラリをインストール
! pip install langchain_community tiktoken langchain-openai langchainhub chromadb langchain youtube-transcript-api pytube langchain-yt-dlp
※ 元のコードではyoutubeのmetadata取得でエラーになったため、langchain-yt-dlpを追加でインストールしています。
LLMにはgpt-4o-mini, 埋め込みモデルはtext-embedding-3-largeを使用しました。
Query structuring for metadata filters
ユーザの質問文から、データベースの検索に必要なクエリに構造化する処理です。

多くのVectorStoreはmetadataフィールドを持っています。
そのため、metadataに基づいて特定のチャンク(文章の塊)をフィルタリングすることができます。
YouTubeの字幕のデータベースで見られるmetadataの例を見てみましょう。
例では以下の動画のmetadataを取得しています。
YouTubeのmetadata取得のコード
from langchain_yt_dlp.youtube_loader import YoutubeLoaderDL
# 元のcookbookで利用していたlangchain_community.document_loadersではエラーになったため、
# こちらのライブラリに変更して実行しています
docs = YoutubeLoaderDL.from_youtube_url(
"https://www.youtube.com/watch?v=pbAd8O1Lvm4", add_video_info=True
).load()
docs[0].metadata
このコードを実行して得られる結果は以下です。
{'source': 'pbAd8O1Lvm4',
'title': 'Self-reflective RAG with LangGraph: Self-RAG and CRAG',
'description': 'Self-reflection can greatly enhance RAG, enabling correction of poor quality retrieval or generations. Several recent RAG papers focus on this theme, but implementing the ideas can be tricky. Here, we show that LangGraph can be easily used for "flow engineering" of self-reflective RAG pipelines. We provide cookbooks for implementing ideas from two interesting papers, Self-RAG and C-RAG.\n\nCode:\nhttps://github.com/langchain-ai/langgraph/tree/main/examples/rag',
'view_count': 29955,
'publish_date': '2024-02-07',
'length': 1058,
'author': 'LangChain',
'channel_id': 'UCC-lyoTfSrcJzA1ab3APAgw',
'webpage_url': 'https://www.youtube.com/watch?v=pbAd8O1Lvm4'}
titleに動画のタイトル、descriptionに動画の概要欄、publish_dateに動画の公開日、などが入っていることが確認できます。
このようなYouTubeのmetadata付の字幕データベースが次のようなインデックスをもつ場合
- 各文書の
contentsとtitleに対して非構造化検索を実行できる。 -
view count,publication date,lengthの範囲フィルタリングを使用する。
文章であるユーザの質問文から、データベースを検索するための構造化検索クエリに変換したいです。
そこで、Function Callingを使用して構造化検索クエリのスキーマを定義することができます。
cookbookではまずそのような構造化を行うためのTutorialSearchを定義しています。
`TutorialSearch`の定義
import datetime
from typing import Literal, Optional, Tuple
from langchain_core.pydantic_v1 import BaseModel, Field
class TutorialSearch(BaseModel):
"""ソフトウェアライブラリに関するチュートリアル動画のデータベースを検索する。"""
content_search: str = Field(
...,
description="動画のトランスクリプトに適用される類似検索クエリ。",
)
title_search: str = Field(
...,
description=(
"動画タイトルに適用されるコンテンツ検索クエリの別のバージョン。"
"簡潔で、動画タイトルに含まれている可能性のある重要なキーワードのみを含むべきです。"
),
)
min_view_count: Optional[int] = Field(
None,
description="最小視聴回数フィルター(含む)。明示的に指定された場合のみ使用します。",
)
max_view_count: Optional[int] = Field(
None,
description="最大視聴回数フィルター(除外)。明示的に指定された場合のみ使用します。",
)
earliest_publish_date: Optional[datetime.date] = Field(
None,
description="最も早い公開日フィルター(含む)。明示的に指定された場合のみ使用します。",
)
latest_publish_date: Optional[datetime.date] = Field(
None,
description="最新の公開日フィルター(除外)。明示的に指定された場合のみ使用します。",
)
min_length_sec: Optional[int] = Field(
None,
description="最小動画長さ(秒)(含む)。明示的に指定された場合のみ使用します。",
)
max_length_sec: Optional[int] = Field(
None,
description="最大動画長さ(秒)(除外)。明示的に指定された場合のみ使用します。",
)
def pretty_print(self) -> None:
for field in self.__fields__:
if getattr(self, field) is not None and getattr(self, field) != getattr(
self.__fields__[field], "default", None
):
print(f"{field}: {getattr(self, field)}")
このTutorialSearchを使用して、ユーザの質問文からデータベース検索のためのクエリに変換する処理が以下です。
from langchain_core.prompts import ChatPromptTemplate
system = """あなたはユーザーの質問をデータベースクエリに変換する専門家です。\
あなたはLLMを活用したアプリケーションを構築するためのソフトウェアライブラリに関するチュートリアル動画のデータベースにアクセスできます。\
質問を受けて、最も関連性の高い結果を取得するために最適化されたデータベースクエリを返してください。
もし略語や不明な単語があれば、それを言い換えようとしないでください。"""
prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "{question}"),
]
)
structured_llm = llm.with_structured_output(TutorialSearch)
query_analyzer = prompt | structured_llm
3つのユーザ質問文に対する実行結果を見てみます。
query_analyzer.invoke(
{"question": "chat langchainに関する2023年に公開された動画"}
).pretty_print()
content_search: chat langchain
title_search: chat langchain
earliest_publish_date: 2023-01-01
latest_publish_date: 2023-12-31
query_analyzer.invoke(
{"question": "chat langchainのトピックに焦点を当てた2024年より前に公開された動画"}
).pretty_print()
content_search: chat langchain
title_search: chat langchain
earliest_publish_date: 2020-01-01
latest_publish_date: 2024-01-01
※ こちらの質問文は動作不安定でした・・・。比較的上手く生成された上記の結果も、earliest_publish_date: 2020-01-01は不要ですね。
query_analyzer.invoke(
{"question": "chat langchainのトピックに焦点を当てた2024年より前に公開された動画"}
).pretty_print()
content_search: エージェント マルチモーダルモデル 使用方法
title_search: エージェント マルチモーダルモデル
max_length_sec: 300
Discussion