機械学習界隈の職種の分類【個人的な観測記録】
この記事は SmartHR Advent Calendar 2025 シリーズ2の6日目の記事です🎄
はじめに
私は今年の10月に3人目のMLエンジニアとしてSmartHRに入社しました。SmartHR自体は創業してから10年以上経つ会社ですが、「AI機能の開発」は最近になってから力を入れ始めたように思います。その理由は、膨大な費用と時間を投資することで長期的なリターンを狙う「AI機能の開発」というものが、若いSaaS系の企業のスピード感とはマッチしていなかったからなのではないかと考えています。そのためか、古くからSmartHRにいる方から「MLエンジニアって具体的にどういう仕事をするの? データサイエンティストとは違うの?」という疑問を投げかけられたりしています。
そこで今回は、私の 「完全に個人的な観測範囲」 に基づいて、機械学習界隈の職種を分類してみました💡
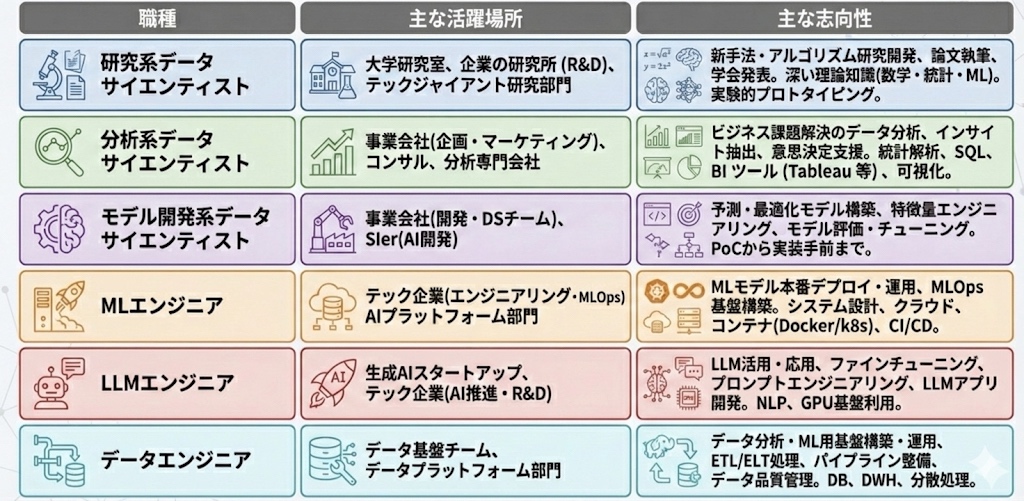
「完全に個人的な観測範囲」に基づいた機械学習界隈の職種一覧
1. データサイエンティスト
この職種は非常に多様で、同じ名前でも全く異なる志向性を持っています。そのため、今回は大きく3つに分類してみました。
1-1. 研究系データサイエンティスト
【主な活躍場所】
学会(NLP, JSAIなど)、大学の研究室、大手企業のR&D部門
【主な志向性】
既存のモデルを使うだけでなく、新しいアーキテクチャを設計し、SoTA(State-of-the-Art:現時点での最高性能)を目指すことに情熱を注ぎます。
彼らの最大の強みは、「表面的な数値に踊らされない」ことです。リーダーボードのスコアだけでなく、そのモデルがなぜ動くのか、本当に汎用性があるのかを論理的・数理的に厳密に評価できます。議論においても安直な結論を急がず、真理を追い求めます。その姿勢はプロジェクトの失敗リスクを抑え、成功率を高めてくれます。
彼らにとっての報酬系は「理論的な新規性」や「正しさ」にあることが多いです。そのため、「とりあえず動けばいいから売上を上げよう」といったアプローチとは、少しリズムが合わないことがあります。議論が結論ファーストにならず、アカデミックな展開になりがちなのも、彼らの誠実さゆえの特性と言えます。

研究系データサイエンティスト
1-2. 分析系データサイエンティスト
【主な活躍場所】
マーケティング部門、経営企画室
【主な志向性】
必ずしも「機械学習モデル」を作ることには固執しません。彼らの得意技はSQLやPandasを駆使した集計と因果推論なども含む統計的アプローチです。
この職種の方々の最大の特徴は、EDA(探索的データ分析)能力の高さとビジネス感度です。「このデータから何が言えるか?」を経営陣に分かりやすく翻訳し、意思決定をナビゲートする能力に長けています。
「レポートによる意思決定支援」をゴールとすることが多いため、システムとして自動化・永続化する「エンジニアリング」の領域には、あまり深入りしない傾向があります。プロダクトにコードを実装するよりも、スピーディに示唆を出すことに特化している方もいます。
分析系データサイエンティスト
1-3. モデル開発系データサイエンティスト
【主な活躍場所】
Kaggle、大手企業の開発部門
【主な志向性】
分析系との違いは、ゴールが「レポート」ではなく「高精度なモデルそのもの」である点です。データ分析も行いますが、それはあくまでモデルを作るための「前処理」という位置付けです。
DeepLearning(画像・自然言語)から、LightGBMなどのテーブルデータ系モデルまで幅広く扱い、与えられた要件の中で極限まで精度を高める技術があります。伝統的な機械学習技術を使いこなすベテランから、最新技術を駆使する若手まで幅広い層がいます。
「ビジネスインパクト」や「運用コスト」もさることながら、モデルの「精度(Accuracy)」を特に追求することに情熱があります。また、Jupyter Notebookという実験室の中では無敵ですが、本番システムに組み込む際の一般的なソフトウェア開発の作法(CI/CDやAPI設計など)には伸びしろがあります。

モデル開発系データサイエンティスト
2. MLエンジニア
【主な活躍場所】
大手企業の開発部門
【主な志向性】
前述の「モデル開発系データサイエンティスト」が、実社会の荒波(本番環境)に適応した場合になる方が多いと思います。
彼らの役割は、職人が作った繊細なモデルを、24時間365日止まらない堅牢なシステムとして実装すること(MLOps)です。スケーラビリティ、推論速度、耐障害性を考慮し、実験コードをプロダクションコードへと昇華させます。機械学習の言葉と、インフラエンジニアの言葉の両方を話せるバイリンガルです。
Web系エンジニア出身者と比較すると、CI/CDやTDD(テスト駆動開発)といったモダンなDevOps文化への適応がまだ途上であることもあります。また、守備範囲が広すぎるため、「広く浅い」ゼネラリストになりがちで、特定の領域の深掘りに時間を割きにくいという悩みを抱えている方もいます。

MLエンジニア
3. LLMエンジニア
【主な活躍場所】
スタートアップから大手企業まで幅広く活躍
【主な志向性】
ChatGPT登場以降の職種です。従来の機械学習の常識を覆す方々です。「データを集めて学習させる」という長い工程をスキップし、APIとプロンプトエンジニアリングを駆使して、RAG(検索拡張生成)やAIエージェントを驚異的な速度でプロトタイピングします。
機械学習の深い数理的知識が必須ではないため、Webサーバーサイドやインフラエンジニアから転身してくるケースも多く、非常に多様性に富んでいます。
時間のかかる従来の機械学習やルールベースよりも、スピード重視でまずはLLMという超便利ハンマーを使う方が多い印象です。

LLMエンジニア
4. データエンジニア
【主な活躍場所】
大手企業の開発部門
【主な志向性】
これまで紹介した全ての職種が活動するための基盤を整備する、極めて重要な存在です。実は多くの企業が今、一番潜在的に必要としていると考えられるのが、この人材です。
データの統合技術に精通し、クラウドのガバナンスやセキュリティ領域まで管理している方もいます。彼らがいるおかげで、他の職種の方々は泥沼に足を取られることなく、分析やモデル開発に専念できます。「自分が目立たなくても、チーム全体が勝てればいい」という、縁の下の力持ちとしてのプロ意識が高い方が多いのも特徴です。
基盤の信頼性と品質を守ることに全力を注いでいるため、機械学習のモデルの中身や分析のアルゴリズムそのものには深入りしないという棲み分けをすることが多いです。

データエンジニア
まとめ
それぞれの職種をニーズ別にまとめると以下のようになります。
- 未知の真理を探究したいなら → 研究系データサイエンティスト
- 経営の羅針盤が欲しいなら → 分析系データサイエンティスト
- 高精度なモデルを開発したいなら → モデル開発系データサイエンティスト
- モデルをプロダクトに搭載したいなら → MLエンジニア
- LLM活用で素早く成果を出すなら → LLMエンジニア
- 上記職種の方々が活躍するための足場を固めるなら → データエンジニア
Discussion