1.はじめに
AIの話題は日々あふれていますが、具体的な使い方や「何ができるか」を越えて、「それってどんな仕組みで動いているの?」と学び直す機会は、個人的にはあまりありませんでした。
今回、記事を書く機会をいただいたので、今のGPTなど大規模言語モデルの基礎の1つにもなっている2017年の論文 「Attention Is All You Need」 を、改めて深く調べてみました。
本記事は、以下の論文内容を元に理解を深めるためにまとめたものです。
引用: Vaswani et al., Attention Is All You Need, NeurIPS 2017.
arXiv:1706.03762
想定読者
- 「Transformer」や「Self-Attention」という言葉は聞いたことがあるが、計算の流れや仕組みは曖昧な方
- 公式論文は読んだことがあるが、概念をコードや具体例で再確認したい方
- AIエンジニアではないが、仕組みを理解して業務や学習に応用したい方
数式を最小限に抑え、例(果物探しなど)とTypeScriptの最小コードを用いて説明します。
数学や機械学習の専門知識がなくても読み進められる構成にしています。
※この記事は、自分自身の理解を深めるためにも書いています。もし誤りやより良い説明方法があれば、ぜひ教えていただけると嬉しいです。
Attention Is All You Need とは?
2017年にGoogle Brainの研究者らが発表した自然言語処理(NLP)モデルの設計論文です。それまで主流だったRNNやLSTMを使わず、Self-Attention という仕組みだけで文章中の単語同士の関係を捉える Transformer というアーキテクチャ(仕組み)を提案しました。高速な並列処理と高精度な長文理解を実現し、その後のBERTやGPTなど、現在の大規模言語モデル(LLM)のほぼ全ての基盤となっています。
背景 — Transformerが生まれる前
要約:
Transformerが登場する前の自然言語処理は、文章を順番に処理する仕組みが主流でした。
この方法は長い文章や複雑な文脈を扱うのが苦手で、計算のスピードや精度にも限界がありました。
2017年当時の自然言語処理(NLP)では、RNN(Recurrent Neural Network)や、その改良版であるLSTM、GRUといったモデルが主に使われていました。
これらは文章を単語の順番どおりに1つずつ処理する仕組みです。そのため、文が長くなるほど前の情報を覚えておくのが難しくなり、処理にも時間がかかります。
この弱点は実用面にも影響していて、たとえば自動翻訳サービスでは長い文章や複雑な文になると翻訳の精度が下がりやすく、リアルタイム性や大量処理にも向いていませんでした。
こうした背景から、長い文脈を効率よく扱え、同時並行で計算できる新しい仕組みが求められていました。
2. 核心となるアイデア — Self-Attention
要約:
Self-Attentionは、文章の中で「どの単語が、他のどの単語と強く関係しているか」を
一度に計算する仕組みです。
これにより、長い文章でも重要な関係性を見逃さず、しかも高速に処理できます。
Self-Attentionは、Transformerの中核をなす仕組みで、文章中のすべての単語同士の関係を“同時並列”に計算できるという点が最大の革新です。
これにより、従来のRNNやLSTMのように1語ずつ順番に処理する必要がなくなり、長い文章でも高速かつ高精度に文脈を捉えることが可能になりました。
同時並列計算はGPUなどの計算資源を効率的に活用でき、大規模モデルの学習・推論を現実的な速度で実行できる基盤にもなっています。
この仕組みは文章中のすべての単語同士の関係を計算します。
これまでのRNNやLSTMでは、文章を前から順に処理していたため、遠く離れた単語同士の関係を正確にとらえるのが難しく、計算にも時間がかかっていました。
Self-Attentionでは、各単語を3種類の情報に変換します。
- Query(Q):「私は誰に注目すべきか?」という視点
- Key(K):「私はどんな特徴を持っているか?」という指標
- Value(V):「私が持っている実際の情報」
このQとKを組み合わせることで、ある単語が他の単語にどれだけ注目すべきか(重要度スコア)を計算します。
そして、そのスコアに基づいてVの情報を組み合わせ、文章全体をより意味の通る形に変換します。
例えば 「彼はリンゴを食べたが、それは甘かった」 という文では、 「それ」 という単語が 「リンゴ」 と強く関係していることをSelf-Attentionは自動的に見つけます。
こうした仕組みにより、文脈の長い文章や複雑な構造を持つ文章でも、高い精度で理解できるようになります。
次に、ここまでの仕組みを、理解のために、実際にTypeScriptで簡単に実装して動きを見てみます。
3. TypeScriptでSelf-Attentionを実装してみる
3.0 このコードで何をする?(目的とゴール)
- 目的: Self-Attention の計算手順(Q/K/V → スコア → softmax → 出力)を、最小実装で体感する
- 題材: 2つの日本語文(代名詞の参照/因果接続)
- 見どころ: 「それ」「それで」などの語がどこに注意を向けるか(確率分布)を可視化
※学習済みモデルではありません。仕組みの理解にフォーカスします。
3.1 実行環境と前提
- Node.js + TypeScript(外部ライブラリなし)
- 実行コマンド(CommonJSとして実行)
npx ts-node --compiler-options '{"module":"CommonJS"}' self_attention_examples.ts - 再現性のため、乱数はシード固定(createSeededRandom)
3.2 コードサンプル(全文)
まずは雰囲気を掴むために全文を流し読み → 次のセクションで重要ポイントを分解して解説します。
コード全文を見る
// self_attention_examples.ts
// 実行: ts-node self_attention_examples.ts
// 目的: 固定トークン配列の日本語文2例で Self-Attention の注意分布を可視化する
// 例1: 代名詞参照(「それ」→「りんご」)
// 例2: 因果接続(「それで」→ 直前の事象「倒した」など)
//
// 注意: これは学習済みモデルではありません。Self-Attention の計算手順と
// 「注意分布(weights)」の見方を体感するための最小デモです。
// ※本来は mathjs 等の外部ライブラリを使っても良いが、今回は全体像理解のため自前実装。
/* ========================== [@3.3.1 入力データ] =========================== */
const tokensApple = [
"今日", "は", "りんご", "を", "食べた", "。", "それ", "は", "とても", "甘くて", "美味しかった", "。"
]; // 例1: 「今日はりんごを食べた。それはとても甘くて美味しかった。」
const tokensVase = [
"猫", "が", "机", "の", "上", "の", "花瓶", "を", "倒した", "。", "それで", "水", "が", "床", "に", "こぼれた", "。"
]; // 例2: 「猫が机の上の花瓶を倒した。それで水が床にこぼれた。」
const d_model = 16; // 小さめに固定して形を追いやすく
const d_k = 16; // 1ヘッドのキー次元
/* ===================== [@3.3.2 Self-Attention 本体] ====================== */
/**
* X: [S, d_model]
* 「S個のトークンが、それぞれ d_model次元の数値ベクトル で表されて並んでいる」2次元配列(行列)
* 例)「猫 が 花瓶 を 倒した」なら S=5 で、d_model=16 なら形は [5, 16] になる
*
* Wq/Wk/Wv: [d_model, d_k]
* Wq:入力ベクトルから「質問(Query)」を作る変換用の行列
* Wk:入力ベクトルから「鍵(Key)」を作る変換用の行列
* Wv:入力ベクトルから「値(Value)」を作る変換用の行列
*
* 流れ: Q = XWq, K = XWk, V = XWv
* scores = QK^T / sqrt(d_k) // 大きくなり過ぎるスコアを正規化(勾配の暴れ防止)
* weights = softmax(scores) // 行ごとに確率分布(各行の合計=1)
* context = weights · V // 注意重みで情報を合成
*/
function selfAttention(
X: number[][],
Wq: number[][],
Wk: number[][],
Wv: number[][]
) {
const Q = matrixMultiplication(X, Wq);
const K = matrixMultiplication(X, Wk);
const V = matrixMultiplication(X, Wv);
const scores = scale(matrixMultiplication(Q, transpose(K)), 1 / Math.sqrt(d_k));
const weights = softmaxRows(scores);
const context = matrixMultiplication(weights, V);
return { scores, weights, context, Q, K, V };
}
/* ============================ 実行(出力) ============================= */
// —— Apple: 代名詞参照「それ」 ——
{
const vocab = Array.from(new Set(tokensApple));
const embedTable = buildEmbeddingTable(vocab, d_model, 20250812); // 再現性のため固定シード
const X = tokensToMatrix(tokensApple, embedTable);
const Wq = randomMatrix(d_model, d_k, 111);
const Wk = randomMatrix(d_model, d_k, 222);
const Wv = randomMatrix(d_model, d_k, 333);
const attn = selfAttention(X, Wq, Wk, Wv);
printSmallMatrix("Attention Weights (Apple)", attn.weights);
showTopAttention("Apple", tokensApple, attn.weights, "それ", 8);
}
// —— Vase: 因果接続「それで」 ——
{
const vocab = Array.from(new Set(tokensVase));
const embedTable = buildEmbeddingTable(vocab, d_model, 20250813);
const X = tokensToMatrix(tokensVase, embedTable);
const Wq = randomMatrix(d_model, d_k, 444);
const Wk = randomMatrix(d_model, d_k, 555);
const Wv = randomMatrix(d_model, d_k, 666);
const attn = selfAttention(X, Wq, Wk, Wv);
printSmallMatrix("Attention Weights (Vase)", attn.weights);
showTopAttention("Vase", tokensVase, attn.weights, "それで", 8);
}
/* ============== [@3.3.3 今回の割り切りポイント(ユーティリティ)] ============== */
/** ※ 学習や外部ライブラリを使わず、仕組みを追いやすい最小セットだけ自前実装 */
/** 固定シードの擬似乱数生成関数を作る(本来は学習した数値が入る) */
function createSeededRandom(seed: number) {
// 固定シードの擬似乱数(mulberry32 ベース)
return function () {
let t = (seed += 0x6D2B79F5);
t = Math.imul(t ^ (t >>> 15), t | 1);
t ^= t + Math.imul(t ^ (t >>> 7), t | 61);
return ((t ^ (t >>> 14)) >>> 0) / 4294967296;
};
}
/** 行列の掛け算 */
function matrixMultiplication(A: number[][], B: number[][]): number[][] {
const r = A.length;
const n = A[0]?.length ?? 0;
const c = B[0]?.length ?? 0;
if (n !== B.length) {
console.warn("matrixMultiplication: 次元不一致 A: [*,", n, "] B: [", B.length, ",*]");
}
const out = Array.from({ length: r }, () => Array(c).fill(0));
for (let i = 0; i < r; i++) {
for (let k = 0; k < n; k++) {
const aik = A[i][k];
for (let j = 0; j < c; j++) out[i][j] += aik * B[k][j];
}
}
return out;
}
/** 行列の転置(行と列を入れ替える [r, c] → [c, r]) */
function transpose(A: number[][]) {
return A[0].map((_, j) => A.map(r => r[j]));
}
/** スカラー倍(行列の全要素に同じ係数を掛ける=等倍する。)*/
function scale(A: number[][], s: number) {
return A.map(row => row.map(v => v * s));
}
/**
* 行ごとに softmax を適用し、各行を「確率分布」に変換する
* Self-Attentionの文脈では結果は「各単語が他の単語へ向ける注目度(割合)」になる。
* 各行の合計は1。最大値を引いてからexpするのは数値安定化のため。
*/
function softmaxRows(A: number[][]) {
return A.map(row => {
const m = Math.max(...row);
const exps = row.map(v => Math.exp(v - m));
const sum = exps.reduce((a, b) => a + b, 0);
return exps.map(v => v / sum);
});
}
/** 簡易埋め込みテーブル(本来は学習済みだが、ここでは固定シード乱数で代用) */
function buildEmbeddingTable(vocab: string[], d_model = 16, seed = 42) {
const rnd = createSeededRandom(seed);
const table = new Map<string, number[]>();
for (const tok of vocab) {
const v = Array.from({ length: d_model }, () => (rnd() * 2 - 1) * 0.5);
table.set(tok, v);
}
return table;
}
/** トークン列を埋め込み行列 [S, d_model] に変換 */
function tokensToMatrix(tokens: string[], table: Map<string, number[]>) {
return tokens.map(t => table.get(t)!);
}
/** 重み行列のランダム初期化(固定シードで再現性 / 本来は学習で得る) */
function randomMatrix(rows: number, cols: number, seed = 1234, amplitude = 0.2) {
const rnd = createSeededRandom(seed);
return Array.from({ length: rows }, () =>
Array.from({ length: cols }, () => (rnd() * 2 - 1) * amplitude)
);
}
/** [表示用] 指定トークンが「どこに注意しているか」を上位N件表示(行=注目者) */
function showTopAttention(
label: string,
tokens: string[],
weights: number[][],
focusToken: string,
topN = 8
) {
const idx = tokens.findIndex(t => t === focusToken);
if (idx < 0) {
console.log(`(注) "${focusToken}" が見つかりませんでした。`);
return;
}
const row = weights[idx];
const pairs = tokens.map((t, j) => ({ t, j, w: row[j] })).sort((a, b) => b.w - a.w);
console.log(`\n[${label}] 注目トークン tokens[${idx}] = "${tokens[idx]}" の上位参照先:`);
pairs.slice(0, topN).forEach(p => {
console.log(` -> [${p.j}] "${p.t}" weight=${p.w.toFixed(3)}`);
});
}
/** [表示用] 注意分布の先頭だけざっくり表で見る(長文だと巨大になるため) */
function printSmallMatrix(title: string, M: number[][], limit = 12) {
console.log(`\n=== ${title} (先頭${limit}×${limit}のみ表示) ===`);
const r = Math.min(M.length, limit);
const c = Math.min(M[0].length, limit);
for (let i = 0; i < r; i++) {
console.log(M[i].slice(0, c).map(v => Number(v.toFixed(2)).toString().padStart(5)).join(" "));
}
}
3.3 コードリーディングのポイント
3.3.1 入力データ(固定トークン配列)
このコードでは、まず2つの日本語の文章を入力サンプルとして使います。
1つは「今日はりんごを食べた。それはとても甘くて美味しかった。」という文で、「それ」が「りんご」を指しているパターンです。
もう1つは「猫が机の上の花瓶を倒した。それで水が床にこぼれた。」という文で、「それで」が直前の出来事を受けているパターンです。
文章はコンピュータが扱えるように単語ごとに分けられ(トークン化)、配列として固定されています。
また、モデル内部の計算サイズ(d_model や d_k)は小さめ(16)に設定しており、計算の形や流れを追いやすくしています。
3.3.2 Self-Attention 本体
ここは Self-Attention の心臓部であり、全体を理解するうえで 最も重要なパート です。
今回は 「赤くて甘い果物は何?」 という質問を例に、
実際のコードと結びつけながら、Self-Attention の4つのステップを掘り下げて説明します。
-
Q、K、V の作成
文章中の各単語から、「質問(Q)」「鍵(K)」「値(V)」という3種類の情報を作ります。- Q(質問):「赤くて甘い果物は何?」という探す条件。
- K(鍵):各果物の特徴ラベル(例:りんご→赤い・甘い・丸い、バナナ→黄色い・甘い・細長い)。
- V(値):果物そのものの詳細情報(例:りんご→シャキシャキしてジューシー)。
コード対応部分:
const Q = matrixMultiplication(X, Wq); // Qの作成 const K = matrixMultiplication(X, Wk); // Kの作成 const V = matrixMultiplication(X, Wv); // Vの作成 -
関連度スコアの計算
Q(探す条件)とK(候補の特徴)を比較して、「条件にどれだけ合っているか」のスコアを出します。
例:「赤くて甘い」に最も近いのはりんごとさくらんぼなので、この2つが高得点になります。コード対応部分:
const scores = scale( matrixMultiplication(Q, transpose(K)), // QとKの比較 1 / Math.sqrt(d_k) // スコアの正規化 ); -
確率分布化(softmax)
関連度スコアを 0〜1の範囲の割合 に変換します。
これにより、「どの候補にどれだけ注目するか」が数値として表されます。例:
- りんご:0.5
- さくらんぼ:0.4
- バナナ:0.1
この割合は、候補全体で合計が1になり、確率のように解釈できます。
コード対応部分:
const weights = softmaxRows(scores); // 行ごとに確率分布へ変換 -
情報の合成
割合を使って、各果物(V)の情報を重み付きで合成します。
例:「赤くて甘い果物」の情報として、りんごとさくらんぼの特徴が強く反映された説明が完成します。
コード対応部分:const context = matrixMultiplication(weights, V); // 注意重みで情報を合成
簡単なまとめ
Self-Attentionは、「探す条件(Q)」と「候補の特徴(K)」を比べて関連度を求め、その割合に応じて「候補の中身(V)」を合成する仕組みです。
これにより、文中の単語同士が自動的に「どこを見るべきか」を決められるため、従来の固定的な文脈処理とは異なり、文脈ごとに柔軟に注目先を変えられるという特長があります。
さらに Self-Attention の大きな革新は、全単語のQ・K・Vを作った上で行列積でまとめて計算できるため、高い並列性を持つことです。
これにより、大量のテキストでも高速に文脈を理解でき、現代の大規模言語モデルの基盤となっています。
Self-Attention の並列性こそが、LLMの巨大化と高速化を同時に実現した最大の要因のひとつです。
人間が文章を速く読むときも、頭から一語ずつ追うのではなく、重要なキーワード同士を結びつけて流し読みしますよね。
Self-Attentionは、それを計算機的に大規模かつ正確に実現しているとも言えます。
3.3.3 今回の割り切りポイント
本来、Q/K/V の重み行列や単語の埋め込みは学習によって決まりますが、
このデモではあえて学習を行わず、固定シード付きの乱数で初期化しています。
(本来の大規模言語モデルでは大量の文章を学習した結果として、得るものです。)
また、行列計算や可視化も mathjs のようなライブラリを使わず、自前実装にしています。
これは 動きの仕組みを目で追えるようにするため の割り切りです。
4 実行と出力の読み方
出力結果 実行すると以下のような出力結果が表示されます
出力結果を見る(Attentionの重みと注目先の上位表示)
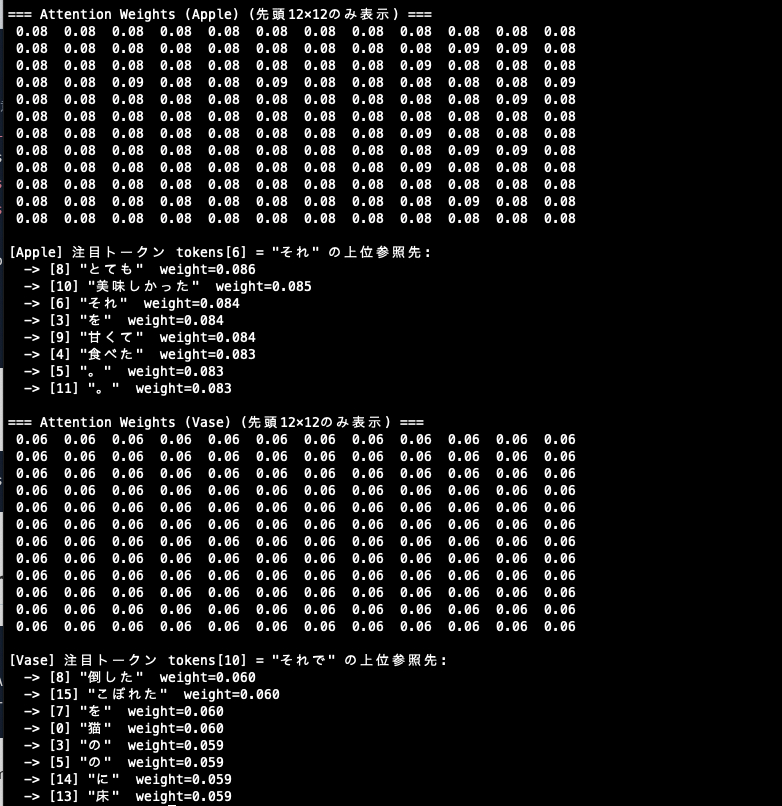
出力の見方(今回は“意味”ではなく“動き”を見るデモ)
このコードは、単語の意味を学習したモデルではありません。
単語のつながりや意味は知らないため、結果はほぼランダムになります。
あくまで Self-Attentionがどんな計算をして、どういう形の結果を返すのか を体験するためのミニデモです。
-
Attention Weights(注意の強さの表)
行は「注目している単語」、列は「注目されている単語」を表します。
各行の数字は合計がほぼ 1 になり、「この単語が他の単語をどれくらい見ているか」の割合を表します。
例えば学習済みモデルなら、「りんご」という単語が「甘い」や「美味しい」といった形容詞を強く見る、といった関連性が表れるでしょう。 -
showTopAttention(...)(上位の参照先表示)
特定の単語が、どの単語を特によく見ているかを順位付きで表示します。
例えば別のサンプル文(「猫が花瓶を倒した。それで水が床にこぼれた。」)では、
学習済みモデルであれば「それで」が「倒した」や「花瓶」といった直前の出来事を強く参照し、
因果関係を反映した結果が得られるでしょう。
実際に意味を持った出力を得たい場合は、学習済みの埋め込みやモデル重みを使う必要があります。
4. Transformer全体像とのつながり
要約:
Self-AttentionはTransformerの一部であり、文章の意味を正しく理解するための「情報のやりとり係」のような役割を果たします。
実際のTransformerでは、この仕組みが複数組み合わされ、さらに位置情報や符号化処理が加わって動きます。
Transformerは大きく エンコーダ(Encoder) と デコーダ(Decoder) の2つのブロックで構成されます。
- エンコーダ は入力文を受け取り、その文の意味を数値情報として整理します。
- デコーダ はその整理された情報をもとに、翻訳文や回答などの出力を生成します。
この中でSelf-Attentionは、各単語が他の単語からどの情報を重視するかを決める役割を担っています。
しかも1回だけではなく、Multi-Head Attention という形で複数並行して行われるため、文の中のさまざまな関係性を同時に把握できます。
さらに、単語の順番を認識させるために Position Encoding(位置情報の付与)が必要になります。
これによってTransformerは「前後の順番も含めて意味を理解できる」ようになります。
5. インパクトと現在への影響
要約:
Transformerは自然言語処理の分野に大きなブレイクスルーをもたらしました。
その設計はBERTやGPTをはじめ、画像や音声の処理など多くの分野に応用されています。
Transformerの登場は、機械翻訳や文章要約、質問応答といった自然言語処理の精度を大きく引き上げました。
特に BERT は文章の理解タスクで圧倒的な精度を出し、GPT シリーズは文章生成に革命を起こしました。
また、 T5 などは翻訳や要約など複数のタスクを一つの枠組みでこなせる汎用性を示しています。
この仕組みはテキストだけでなく、画像認識(Vision Transformer)や音声処理などにも応用され、AIモデルの領域を一気に広げました。
さらに、Self-Attentionの並列計算のしやすさは、学習速度の向上や大規模モデルの実現を後押しし、現在の数千億パラメータ級のモデル開発を可能にしています。
まとめ
今回取り上げた「Attention Is All You Need」は、GPTなどの大規模言語モデルの基盤となるTransformerというアーキテクチャを生み出した論文です。
はじめにで触れた「AIの中身を学び直す」という目的のとおり、背景や仕組みを知ることで、
AIをより深く理解し、活かすための視点を持つことができました。
この記事が、あなたの「ちょっと踏み込んでみよう」というきっかけになれば嬉しいです。
最後に
最後に、ちょっとだけ自分の所属している組織を紹介させてください。
私は、大学を母体に持つ 株式会社クロステック・マネジメント に所属しています。
ここには、挑戦しながら実践を通して学び続けられる環境があります。
先日もAIハッカソンを開催し、エンジニアだけでなく、企画職やデザイナーなど組織全体でAIに触れ、アイデアを形にしました。
こうした活動を通じて、新しい技術を「知る」だけでなく、「挑戦」し、「実践を通して深く学ぶ」機会が日常的にあります。
私たちは、新しい技術やアイデアに一緒に挑戦し、共に学んでいける仲間を歓迎しています。
ご興味のある方は、ぜひお気軽にカジュアル面談でお話ししましょう。

京都芸術大学のテックブログです。採用情報:hrmos.co/pages/xtm/jobs 芸大など5校を擁する瓜生山学園は、通信教育で国内最大手、国内で唯一notionと戦略パートナー契約を結ぶなどDX領域でも躍進、EdTech領域でAIプロダクトを開発する子会社もあり、実は多くのエンジニアがいます。
Discussion