Daniel Murfet氏による特異学習理論(SLT)解説を読んだ感想
特異学習理論(SLT)のディープラーニングへ適用した研究を推進する一人であるメルボルン大学の
Daniel Murfet先生のインタビューが今後のディープラーニング、AIの理解と発展、特にアラインメント問題に関して非常に示唆に富む内容であったので概略、感想を日本語で書きます。
口語であり非常に長く、やや難解な内容も含むので読む際は各種自動翻訳等を併用することをおすすめします。
元のPodcastの動画はこちらです(Youtube)
lesswrong.com にはSLTをはじめとしたAI,ディープラーニング、ベイズ理論に関するカジュアルな形式の記事が多数投稿されています。
研究コミュニティー https://devinterp.com/
discordもあるらしいです。
以下の感想、概略は本文の章立てと大まかには一致しますが一部順序や構成が異なるところが有ります。
特異学習理論との出会い
もともとMurfet氏は代数幾何を専門とし導来圏や弦理論(!)との関係の研究をしてきたそうです、そして線形論理という制約のある論理学とその幾何学との研究もしてしていたそうでかなり高度な上に幅広いことをされていたそうです。2012年以降のディープラーニングブームにも着目し、AlphaGoなどの圧倒的性能を見て数学者としての直感からかなにか理論的背景があるのではないかと感じるようになったそうです。
渡辺澄夫先生の著書"Algebraic Geometry and Statistical Learning Theory"(gray book)
を最初に読んだときには代数幾何が統計学に役立つとは信じられずしばらく置いておいていたが大規模機械学習の理解に使えるのではないかと思い直して取り組むようになったそうです。
特異学習理論に詳しい人は10年前には東工大の渡辺澄夫先生とその教え子の周辺に限定されていたようです(以前Gray bookの読み会やってました)。Alexander Oldenzielさんという人がAIアラインメント(後述)に使えるのではないかと言ってきてそこでもまた最初は役に立たないのではないかと思いつつもやがてスケーリング則のような実験的な普遍性が見られることから背後にそれを裏付けるなんらかの理論が存在するのではないかと思うようになったそうです。
SLTが主張するところのベイズ推定においてサンプルサイズを増やすにつれ複雑な特異点から簡単な特異点へと段階的に推定される事後分布が変化してく様子と相転移(後述)、発生生物学との類推などを語るうちにインタビュアーのDaniel Filanさんと出会いこのインタビューができたそうです(個人的には発生生物学と機械学習、AIの類推としては学習と、推論または生成との関係が個体発生と系統発生に対応付けられるのではないかという指摘を以前ブログに書きました。スピングラスを用いて同様の研究をしている人たちがいて、ニューラルネットをランダムスピン系で近似し性質を説明する古くからある研究の流れとも関係しているので概念は緩やかにつながっているのですが、厳密な数学的対応関係、相違点、どちらかにどちらかの知見を輸入できるという主張はまだできていないまたは発見できていないです。)
局所学習係数(LLC)
特異学習理論を知っている前提で説明すると局所学習係数とは学習係数(実対数閾値,RLCT)

(”The Local Learning Coefficient: A Singularity-Aware Complexity Measureより引用)青紫の上面の"水位"が増加に対する青紫の容積の増加具合の指数がλで正規モデルの場合は次元/2に対応し、局所的なパラメーターの次元を分数にも拡張した量担っています。The RLCT Measures the Effective Dimension of Neural Networksも参照
単に複雑、大規模なニューラルネットに関してLLCを求めただけではどれくらいの数値誤差があるのかがわかりませんが、既知の統計モデルのRLCTの厳密解と比較することでその精度を見積もっています。
詳しくは論文”The Local Learning Coefficient: A Singularity-Aware Complexity Measure” とその解説
も見てみてください。
他の理論との関係
相転移
相転移とニューラルネット、DNNとの関連、類似性に関しては膨大な研究があります。
古くはReluを使ったニューラルネットをp-spin glassとみなした場合のレプリカ対象性の破れの研究
The Loss Surfaces of Multilayer Networks
がとそれに続く研究があり、最近ではAmbrogioniさんらによる拡散モデル、Flow mathingの生成過程における相転移的な見方を深めた研究
[2305.19693] Spontaneous Symmetry Breaking in Generative Diffusion Models
[2508.19897] The Information Dynamics of Generative Diffusion
があります。SLTのベイズ推定での段階的な特異点の選択は一見するとスピングラスの温度などに対する連続的な相転移に対応してそうですが、背後にある数学的原理は異なるように見えます。LLCはニューラルネットの特定のパラメーター値、統計物理でいうとミクロな状態に対応する量です。それがマクロに見えているというのは奇妙な状況です。
物理学において特異点解消を用いるようなとマクロな状態の区別、学習プロセスに相当する相転移に類似した段階的な遷移、とくに連続的な統計量の変化を伴うスピングラスなどのランダム系との関連について
ChatGPT5先生に聞くと調子よく関係あると言って両者のアナロジー滔々とを語ってくれたのですが、個人的にはこれをベースに、批判的な視点を加えて自力で理解を深めたいところです。
ベイズ推定とSGDの違い
ディープラーニング、AIの学習ではloss関数の一回微分のみをつかう通常確率的勾配降下法(SGD)が使われます。2回微分を使う自然勾配降下法なども存在し、モデル(のなすパラメーター)の属する多様体の玉率と関係していて情報幾何学的に興味深いのですが、計算の軽さ、鞍点を回避できる性能からSGD程は普及していないようです。大域最適解が求められる見込みがあるのなら使える計算資源をフルに使った最大のネットワークでの唯一の最適なパラメーターのみがあればよくSGDを使うのに問題はありません。一方ベイズ推定ではパラメーターの分布関数(事後分布)を求めるのでSGDや他の最適化のようにステップごとにパラメーター空間のある点から近い点へ遷移していくという描像が成り立ちません。事後分布の分布関数としてのパラメーター空間をMCMCのような重み付きランダムウォークで遷移していくという方法も考えられ、それに近いのがSGLD(Stochastic Gradient Langevin Dynamics)です。
が、誤差が問題になることがあると前述の論文では指摘されています。一般の中小規模のベイズ推定ではNUTS HMCを実装したstan(Rstan,Pystan),pymc,pyroなどが使われています。
簡単なToy modelでは相転移SGDでもベイズ推定同様の相転移が見られることが示されており、
変分ベイズとSGDに関しては
Variational Bayesian Neural Networks via Resolution of Singularities が関係しそうです。
Stochastic Gradient Descent as Approximate Bayesian Inference
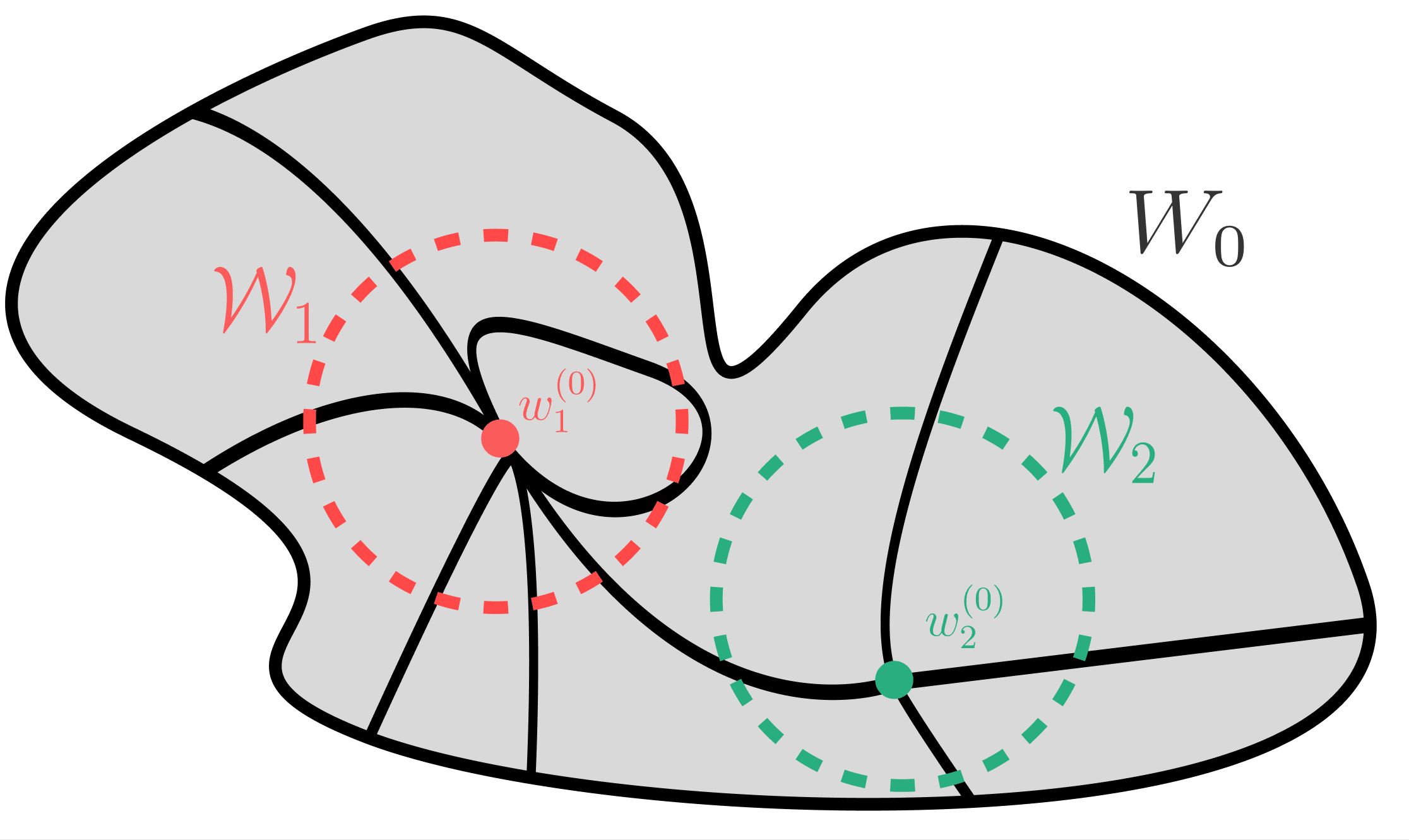
NTKをどう理解するか
DNNの性質(double descent, scaling則、宝くじ仮説など)を明快に説明する統一理論は今ところないようですが(私の見解)、有力なものとしてNeural Tangent Kernel(NTK)があります。Murfet氏は専門家ではないと断ったものの、初期状態に近い場合には各素子の値が独立とみなせるのでNTKの幅無限大の近似は成り立つのではないかとしています。高次元パラメーター空間では最適解が初期値に近いのではないかという仮説については深層学習の原理に迫るでも触れられています。
2つの理論はそれぞれDNNのある側面をよく説明しているのでそれらが重なる領域が必ずあるはずです。
帰納的バイアス
コルモゴロフ複雑性、あるいはSolomonoff分布などで記述されうる データが持つ情報量、圧縮したデータサイズの下限はモデルが正規の場合は最小記述長(MDL)と一致し、Murfet氏はここでは「チューリングマシンのテープの長さ」と表現しています。特異モデルに関してはそうは言い切れず、MDL,BICの係数の特異版である(局所)学習係数(WBICの正則化項)は誤り訂正に関わっているのではないかとMurfet氏は予想しています。真の分布から得られた不完全なデータから得られる過ちが過学習という意味ではそれは既にMDL,BICの正則下降に含まれており、特異であることによる追加の要素であるのではないかと個人的には思いました。Murfet氏はTransformerにみられる機能を持ったヘッドの一つであるバックアップヘッドの機能からニューラルネットには誤り訂正機能があるのではないかという考えに至ったそうです。
では他にも多数の機能をもったヘッドの発見、提案が紹介されています。
誤り訂正や堅牢性への帰納的バイアスがBIC,MDLとWBICの違いだけでなく、SLTにおける高次元の非自明な特異点による学習係数で説明できるかどうかも課題になるかと思います。
個人的にはここでの話はAndrew Gordon Wilson氏によるDeep Learning is Not So Mysterious or Differentで述べられていた柔らかい帰納バイアス(soft inductive bias)の存在に関する研究における論理の飛躍を埋めることができるのではないかと考えています。 個人的に小規模ニューラルネット、NN以外のモデルに関して数値実験を行っていますが結果は芳しくありません。より大規模なデータ、ネットワークに対して起きる現象なのか、想定外の本質的なSLTに関する特性が寄与しているのかを追求する必要があります。
SLTのAIアラインメントへの貢献の可能性
理論はある現象を明確に、一般化して他の現象と関連付けて説明するだけで、対象に直接影響を与えることはありません。そのため工学よりも自然科学でより重視されます。しかしニューラルネット、AIの学習においてはその内部で起こっていることが複雑、別の言葉で言えば適切な概念でまだ説明できていないためにSLTのような理論が必要だという意見があります。一方でAIは工学的産物であり性能がその全てとも言え、性能の指標を正しく設定しないとおかしな、あるいは危険なものが出来上がってしまいます。
AIアラインメントという用語はAIの動作(学習時の目的関数)を人間の意図や嗜好、特に倫理に一致させることを意味するそうです。特に広告などの推薦システム、ChatGPTなどのLLMを用いた生成AI、模倣学習や強化学習を用いた自動運転やロボットへの応用ではAI、機械学習モデルが高報酬を得るために設計者の本来の意図とは異なった、危険な挙動を示したり、非倫理的な振る舞いをしてしまうことが問題となっています。
このAIアラインメントとSLTの関係についての議論がこの対話の多くの部分を締めています。SLTがこの現実的、工学的問題にどう役立つのかについてMurfet氏は当初否定的な意見だったそうですが、ニューラルネットの能力向上、いわゆるスケーリング則に普遍性が見られ何らかの理論的基盤がありそうだという確信から、SLTがアラインメント問題にも役立つのではないかと考えるようになリ、アラインメント問題が主要な研究モチベーションになるに至ったそうです。
自然界のデータのパターン、構造を識別をする際にパターンの各部分にも深さと浅さがある、Murfet氏の言い方だと深いものよりも浅いものの方が汎化しやすい、能力、性能はアラインメントよりも汎化しやすいという仮説を主張しています(lesswrongの(Nate Soares氏による別の投稿ではこれを急激な左折(sharp left turn)と呼んでいます。
)。この仮説(発達的解釈可能性型の理解アプローチ)は動物、特に人間における進化と個体の学習の対比していると批判されることもあるそうですが、データ集合の各部に深さ浅さ、濃淡の違い(分布の各部の太さや濃さのイメージ)があるのは当然であり、このことから学習の過程、学習データの深さ浅さ、濃淡の違いによるモデルの変化の仕方の関係に着目しているそうです。ベイズ推定では特異点の(RLCTで測られる)特異性の大きさに沿った順序での学習が行われること、ここでも個人的にはSGDとベイズ推定の違いを埋めることがSLTを帰納的バイアスの理解へとつなげると思いました。
AIのアラインメントの試みがデータの構造化を経由する場合、データ分布が変化したときに何が起こるかという点において、学習に人為的な介入をする場合、特に人間の介入がある強化学習(RLHF)はデータ内のより深い構造によて打ち負かされる可能性があるという主張をしています。
一方で強化学習に関しては帰納的バイアスが有効に働く可能性があるとも述べています(この考え方は人間の介入があった方がアラインメントできるという素朴な直感に反します。DNNに正則化項を明示的に入れないほうがいいのと似ていて、パターン認識における幾何学の役割(後述)でも同様のことが言えます)。
ディープラーニングの歴史を振り返ると実験、実践が先行し、理論的な判別性能、汎化性の評価は常に後回し担っているような気がします。かつての理論物理学のように理論の予言が数値実験による発見を予測することはできるのでしょうか。
例としていままでのニューラルネットにおけるloss関数の鞍点への停留は Resnet,Unetなどによって回避されてきましたが、それらは発明が先で、情報幾何的な描像との結びつけはあとになって再発見されたように思えます。TransformerのAttention(注意機構)の高性能、計算、推論性能は同様に説明できるでしょうか?LLMの学習におけるgrokkingがloss関数の鞍点への停留のメカニズムだけでは説明できず、SLTや他の新しい理論で説明できるかもしれないということはありえるでしょうか?
Soares氏の「急激な左折(sharp left turn)」では少数のチームがアラインメントを達成したAIを開発しそれが狭い訓練データの枠を外れてインターネット上のデータのみならずそれを構造化するあらゆる学問分野を学習、習得し、問題解決に使ってしまうAGI、個人と比べたら圧倒的に広範な知識と既存の全ての学問、実践的知識を習得し、高速で解決策を導き出す”超知能”になるだろうというのです。
人間は家や都市、農業や工業に至るまで外部の環境を変えることで生態学でいう適応度を生物学的進化が起こるよりもはるかに速く増殖していて、それが他の動物との大きな違いです。理想的にはAIも同様にそれが可能であろうという説明の仕方をしています。「急激な左折」の意味はAIの再帰的な自己改善に限らず、現状人間だけが持っている”汎用的な知能”を指すそうです。個人的にはコンピューターなどの道具、道具を作る道具…を込みでの再帰的思考を物理的な道具として現実化する能力、環境を主体的に変えること道具を再帰的な自己改善効果の掛け合わせ以上のものは想像できませんでした。(しかし恒星間移動を実現できず、太陽のエネルギーのほんの僅かしか利用できずに未だ化石燃料に頼っている人間集団の知能がそこまで高いでしょうか?)…とSF小説のようでありながら数年内には実現しそうな状況についての対話が続きます。
SLTはAIの性能に関係するか
アラインメントの話はさらに続きます。いまやAI研究はかつての原子核物理学のような世界の命運を左右するような立場にあります。SLTはその中では小さな余り知られていない存在ですが一般に理論研究が世界をいい方向、あるいは悪い方向(破滅(doom))に向かわせることがありうるのだろうかという疑問があります。
(機械)日本語訳より
フィラン:
AIをより汎用的に、ひいてはより破滅的な結果をもたらす能力を高めることに取り組む人々と、AIが破滅的な結果を引き起こさないようにすることに取り組んでいる人々がいます。ある研究を評価する際には、その研究が能力と整合のどちらをどの程度向上させているのかを自問する必要があります。もし、もし能力が整合よりもはるかに向上しているのであれば、それは良くない、あるいはあまり期待できないと考えるかもしれません。
SLTについては、例えば、もしより優れた理論が確立されれば、破滅と破滅を防ぐのとでは同程度に寄与する、あるいは防ぐよりも破滅への寄与が大きいかもしれない、だから研究を止めるべきだ、という批判がなされるかもしれません。
マーフェット:
(中略)破滅に直面した途端、解決策を提示され、実際には回避するのはそれほど難しくなかったと分かったら、非常に恥ずかしい思いをする、というものです。少人数の人間が数年間、真剣に考えれば済む話
未だ知られていない理論によるAI,ニューラルネットの性能の予測が可能だとして、そのような研究が成されるべきかという幾つもの仮定と憶測を置いたふんわりした話になっていってしまいます。すごいAI(込みの社会経済システム)に振り回されて、何らかの指標(株価、GDPやCo2排出量、人口)をみると極端で予測不可能な変化をするのがシンギュラリティーであるというのが個人的理解です。
楽観論(Filan氏の言葉では「平凡なアラインメントに対する楽観主義」)としては「すごい人がすごい頑張って性能(に関するスケーリング則)が成り立っているような感じでアラインメントも量的な問題として解決できる」(AIの能力に関する話が人間や研究者集団の能力の話にすり替わってしまっているようにも思えます)、悲観論としてはSLTなど理論がアラインメント問題に対して光速度不変の原理や熱力学第二法則のようにある種の限界を設定できる可能性がある、と言っているように思えました。大規模なモデルではoverparameterization、汎化性能が向上しスケーリング則が成り立つのはなぜか、その説明とSLTが関係するのかはまた別の問題です。
それとは少し異なる切り口でMurfet氏はアラインメント問題の解決、理解に関して閾値、理解の崖が存在するかが、AGIの完成、破滅が起こりうるかどうかの分かれ道になるかと言っています。
そのようなメタ理論的な話がtimaeusというなんかすごそうな名前のサークル?で議論が繰り返されて来たそうです(The Local Learning Coefficient: A Singularity-Aware Complexity Measureの著者もTimaeus所属です)
非常に一般的なメタ理論に対する主張としてシンギュラリティーは不可知論と言え、理論研究、AIの性能、アラインメント問題が解決可能化否か、それが社会に与える影響が予測ができなくなるというのは情報量の少ない、”平凡な”主観分布と言えるかもしれません。
残された指標、重複度mと特異ゆらぎ
gray bookや以下のスライドではRLCT(学習係数)以外にも学習の特性に関わっていそうな指標がありまる。
特異点解消の仕方によらない双有理不変量と呼ばれる量です。これらがニューラルネットの学習や性能にどのように関係するかはほとんど研究されていません。重複度mと特異ゆらぎが取り上げられています。先述の線形行列モデルに関する青柳先生の論文を見るとmが飛び跳ねるように変化しているのが見られます。
特異ゆらぎは実際には観測できない”真の分布”と観測できる訓練誤差との差異を表現する双有理不変量です。
代数幾何学では有理変換に対して不変な双有理不変量がよく研究されている一方、ベイズ統計とそれに近い統計物理学ではデータ数Nに対するスケール変換に対して(繰り込み)不変な量、物理学一般では位相不変量が重要視されています。どのような変換に着目してその不変量の性質を説明するのが学問分野の違いに対応するのでしょうか?あるいは相互の量を対応させることはできるのでしょうか?
未解決問題リスト
で複数の研究プロジェクトが走っており、そのdiscordに未解決問題リストがあります。
個人的ToDo、研究ネタリスト
既に挙げた疑問をリスト化します、既に解決しているものもあるかもしれません。
- 機械学習、AIにおける学習と生成の関係が生物の個体発生と系統発生に対応付けられるのではないかという指摘をスピングラスでの研究を経由して、厳密な数学的対応、相違点、どちらかにどちらかの知見を輸入できるという主張ができるか
- 学習プロセスに相当する相転移に類似した段階的な遷移、とくに連続的な統計量の変化をスピングラスなどのランダム系の理論を援用して説明することはできるか(ChatGPT5説)
- 簡単なToy modelでみられた相転移はSLTで説明される学習過程におけるLLCの変化と同じものを見ているとみなせるか
- NTKとSLTはどのように関係あるいは住み分けられるか
- 誤り訂正や堅牢性への帰納的バイアスがSLTにおける高次元の非自明な特異点による学習係数で説明できるか、RLCTの小さい非自明な特異点があることで学習にどのような特徴が見えるか。
- Deep Learning is Not So Mysterious or Differentで述べられていた柔らかい帰納バイアス(soft inductive bias)はSLTで説明できるものなのか?
- ベイズ推定で特異性の大きさ(RLCT)に沿った順序で解が選ばれる描像をSGDが使われる通常の機械学習にどう適用すればよいか? 参考Variational Bayesian Neural Networks via Resolution of Singularities、
Stochastic Gradient Descent as Approximate Bayesian Inference - Transformer, Attention(注意機構)の高性能、計算、推論性能はSLTなどの理論で説明できるか、LLMの学習におけるgrokkingがloss関数の鞍点への停留のメカニズムだけでは説明できず、SLTや他の新しい理論で説明できるかもしれないということはありえるか?
- 大規模なモデルではoverparameterization、スケーリング則が成り立つこととSLTはどう関係するのか
- SLTにおける双有理不変量、ベイズ統計とそれに近い統計物理学におけるデータ数Nに対するスケール変換に対して(繰り込み)不変な量、物理学一般における位相不変量(c.f. Chern類、Witten指数)のどれに着目するかで学問が分類されるのか、相互の不変量を異なる分野で使うことはできるのか(ChatGPT説)
gray bookの最後にベイズ統計と特異統計学の量と概念の対応表がある。
| 正規 | 特異 | |
|---|---|---|
| 代数 | 線形代数 | 環とイデアル |
| 幾何 | 微分幾何 | 代数幾何 |
| 解析 | 実数値関数 | 関数に値を持つ関数 |
| 確率論 | 中心極限定理 | 経験過程 |
| パラメーター集合 | 多様体 | 解析集合 |
| モデルとパラメーターの関係 | 一意 | 一意でない |
| 真のパラメーター | 一点 | 実解析集合 |
| Cramer-Rao不等式 | あり | 意味を成さない |
| フィッシャー情報行列 | 正定値 | 半正定値 |
| 漸近正規性 | あり | なし |
| 機械学習における予測値 | 漸近的に有効 | 有効でない |
| ベイズ事後分布 | 正規分布 | 特異な分布 |
| (モデルの)正規型 | 2次形式 | 正規交差 |
| 基本的な変換 | 同型変換 | 双有理写像 |
| 学習係数 | d/2 | λ |
| 特異ゆらぎ | d/2 | ν |
| 確率的複雑さ | d/2*log(n) | λ*log(n) |
| 情報量基準 | AIC | WIAC |
| 相転移 | なし | なし |
| 例 | 正規、線型回帰、予測 | 混合分布、ニューラルネット、隠れマルコフ過程 |
幾何学との関係
偉い人によると幾何学とはパターンとその間の不変性を対象とした学問である(と記憶していましたが少し違って群とそれが作用する多様体の組のことらしい)です。
インタビューでは抽象的な条件F,Gの間の関係F or G,F and Gという簡単な この例では代数曲線f(x)=0,g(x)=0がF,Gに対して条件F or Gはf(x)*g(x)=0, F and Gは
PFN岡野原さんの著書「対象性と機械学習」、雑誌数理科学の「データの幾何学と機械学習」
などではデータが持つ幾何学的対称性をモデルに組み込むことができ、そのような研究が幾何学的機械学習という一大分野を築いていることが述べられています。また岡野原さんの「拡散モデル」では拡散モデルなどのエネルギーベースドモデルは直接計算されることはないものの分配関数、自由エネルギーと言った量に複雑な対称性や保存則を組み合わせて組み込みやすいという性質が高性能に貢献していると書かれていたと記憶しています。しかしこのインタビュー、最近の幾つかの研究ではニューラルネットが規則性を明示的に与えられなくても学習する帰納的バイアスを持っているという主張が主に展開されています。
では「機械学習のエルランゲン・プログラム」と幾何学的機械学習を呼んでいます。工学としてのAIに立ち戻るとAIの性能(識別率、汎化性能、速度、電力比性能)の指標を持って規則性を理解したとすることが初めて幾何学を理解したと言えることになるかもしれません。
幾何学のバックグラウンドを持った人たちとの研究が複数進行中で、そのような人を募集中だそうです。discord, Murfet氏のTwitter(X)のDMをしてくださいとのことです。
論文紹介
以下はSLT、DNNの汎化性能で関係する論文紹介です。
特異学習理論入門(日本語含む)
- 本"Algebraic Geometry and Statistical Learning Theory"(gray book)
- 渡辺澄夫先生によるまとめ(英語)
- singular learning theory: connecting algebraic geometry and model selection in stat
- 特異モデルとベイズ学習
- 人工知能×特異点論=?(青柳先生)
- losswrongのまとめ
- Deep Learning is Singular, and That's Good
- My Criticism of Singular Learning Theory このインタビューでも触れられています。根本的な批判というよりSLTを深く理解するための鋭い指摘や限界を示す反例です。
LLC論文とその解説
- ”The Local Learning Coefficient: A Singularity-Aware Complexity Measure”
- 解説 https://zenn.dev/xiangze/articles/2249f2221b0a5d
- https://docs.google.com/presentation/d/1KcHtDiNSla7cUCG70yW5XTnhfT5hPzp8MYL2y-SvFcs/edit?usp=sharing
Discussion