Stable DiffusionのUnetをjson化する
Stable DiffusionのネットワークをAIアクセラレーターに適した形で読ませるためにonnxをjson化して編集したい。
使用したライブラリのVersionは
onnx 1.15.0
torch 2.2.1
transformers 4.39.1
accelerate 0.28.0
huggingface-hub 0.21.4
これより古いとエラーがでてくる(dockerを使ったほうが良さそう)。
例えばtorchのaten::scaled_dot_product_attentionがONNX似できない問題は
で対応済み
diffusersのソースコード内のdiffusers/scripts/convert_stable_diffusion_checkpoint_to_onnx.py
あるいはここに書かれているところからスクリプトをダウンロードして実行すると
VAE encoder,VAE decoder,text encoder, safety_checker,Unetのonnxファイルが生成される。safety_checker(センシティブ画像のチェックのためのモジュール)が最も大きいのは興味深い。Unetはパラメーターサイズが2GBを超えたため分離されパラメーターはweights.pbとして保存された。
ファイルサイズ
VAE encoder
Unet拡大
Attention拡大
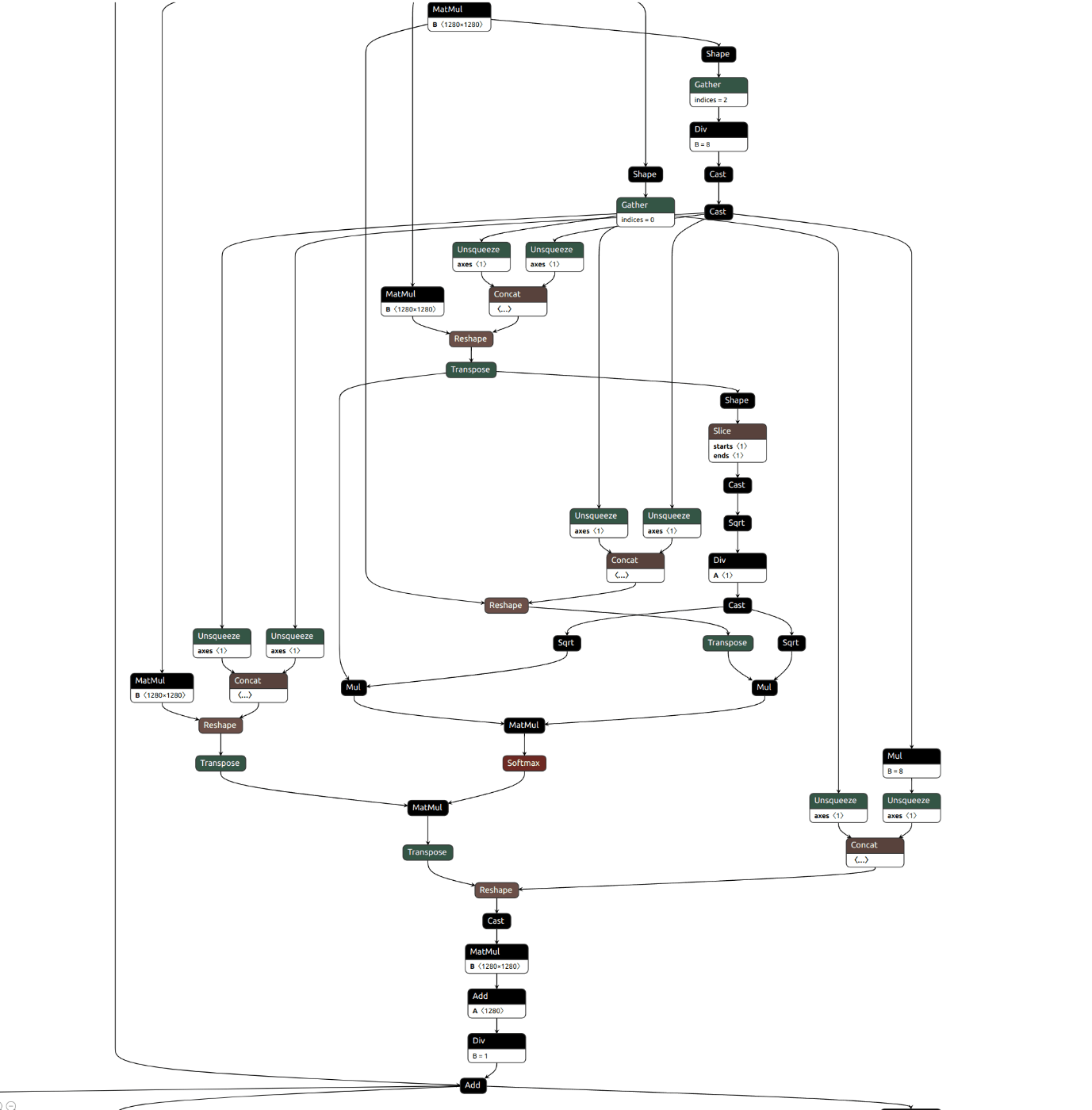
Unet全体

diffusersのUnetをそのままonnx化したものは巨大すぎてNETRONでは見れたもののonnx2jsonやprotocol bufferのダンプは強制終了してしまった。そこでネットワークの層数を減らして出力してみることにした。以下のようにconvert_stable_diffusion_checkpoint_to_onnx.pyを変更した。
# Copyright 2022 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import argparse
import os
import shutil
from pathlib import Path
import torch
from torch.onnx import export
import onnx
from diffusers.models import UNet2DConditionModel
from diffusers.onnx_utils import OnnxRuntimeModel
from packaging import version
is_torch_less_than_1_11 = version.parse(version.parse(torch.__version__).base_version) < version.parse("1.11")
def onnx_export(
model,
model_args: tuple,
output_path: Path,
ordered_input_names,
output_names,
dynamic_axes,
opset,
use_external_data_format=False,
):
output_path.parent.mkdir(parents=True, exist_ok=True)
# PyTorch deprecated the `enable_onnx_checker` and `use_external_data_format` arguments in v1.11,
# so we check the torch version for backwards compatibility
if is_torch_less_than_1_11:
export(
model,
model_args,
f=output_path.as_posix(),
input_names=ordered_input_names,
output_names=output_names,
dynamic_axes=dynamic_axes,
do_constant_folding=True,
use_external_data_format=use_external_data_format,
enable_onnx_checker=True,
opset_version=opset,
)
else:
export(
model,
model_args,
f=output_path.as_posix(),
input_names=ordered_input_names,
output_names=output_names,
dynamic_axes=dynamic_axes,
do_constant_folding=True,
opset_version=opset,
)
@torch.no_grad()
def convert_models(output_path: str, opset: int, fp16: bool = False):
dtype = torch.float16 if fp16 else torch.float32
if fp16 and torch.cuda.is_available():
device = "cuda"
elif fp16 and not torch.cuda.is_available():
raise ValueError("`float16` model export is only supported on GPUs with CUDA")
else:
device = "cpu"
# pipeline = StableDiffusionPipeline.from_pretrained(model_path, torch_dtype=dtype).to(device)
unet=UNet2DConditionModel(
down_block_types= ["DownBlock2D"],# "CrossAttnDownBlock2D"),
up_block_types = ["UpBlock2D"],# "CrossAttnUpBlock2D"),
mid_block_type = ("UNetMidBlock2DCrossAttn"),
#block_out_channels = (320, 640, 1280, 1280)
block_out_channels = (1280,1280)
)
output_path = Path(output_path)
num_tokens= 77
text_hidden_size= 1280 #768
unet_sample_size = 64
unet_in_channels = unet.config.in_channels #4
#mat1 and mat2 shapes cannot be multiplied (154x768 and 1280x320)
unet_path = output_path / "model.onnx"
print(unet_in_channels ,unet_sample_size )
onnx_export(
unet,
model_args=(
torch.randn(2, unet_in_channels, unet_sample_size, unet_sample_size).to(device=device, dtype=dtype),
torch.randn(2).to(device=device, dtype=dtype),
torch.randn(2, num_tokens, text_hidden_size).to(device=device, dtype=dtype),
False,
),
output_path=unet_path,
ordered_input_names=["sample", "timestep", "encoder_hidden_states", "return_dict"],
output_names=["out_sample"], # has to be different from "sample" for correct tracing
dynamic_axes={
"sample": {0: "batch", 1: "channels", 2: "height", 3: "width"},
"timestep": {0: "batch"},
"encoder_hidden_states": {0: "batch", 1: "sequence"},
},
opset=opset,
use_external_data_format=True, # UNet is > 2GB, so the weights need to be split
)
del unet
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--output_path", type=str, required=True, help="Path to the output model.")
parser.add_argument(
"--opset",
default=14,
type=int,
help="The version of the ONNX operator set to use.",
)
parser.add_argument("--fp16", action="store_true", default=False, help="Export the models in `float16` mode")
args = parser.parse_args()
convert_models(args.output_path, args.opset, args.fp16)
convert_stable_diffusion_checkpoint_to_onnx.pyとの主たる違いは
- Unetのexport部分のみ残した
- pretrained modelを読み込まずファイルパスを削除、直接Unetを宣言する。
- 解像度を下げる層(down_block),上げる層()をそれぞれ一層のみに変更
unet=UNet2DConditionModel(
down_block_types= ["DownBlock2D"],# "CrossAttnDownBlock2D"),
up_block_types = ["UpBlock2D"],# "CrossAttnUpBlock2D"),
mid_block_type = ("UNetMidBlock2DCrossAttn"),
#block_out_channels =
block_out_channels = (1280,1280)#(320, 640, 1280, 1280)
)
onnx export時に設定するUnetへの入力パラメーターを
num_tokens= 77
text_hidden_size= 1280 #768
unet_sample_size = 64
unet_in_channels = unet.config.in_channels #4
と決め打ち
ただし
RuntimeError: Failed to import diffusers.pipelines.stable_diffusion.pipeline_onnx_stable_diffusion because of the following error (look up to see its traceback):
Failed to import transformers.models.clip.image_processing_clip because of the following error (look up to see its traceback):
Descriptors cannot be created directly.
If this call came from a _pb2.py file, your generated code is out of date and must be regenerated with protoc >= 3.19.0.
If you cannot immediately regenerate your protos, some other possible workarounds are:
1. Downgrade the protobuf package to 3.20.x or lower.
2. Set PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python (but this will use pure-Python parsing and will be much slower).
More information: https://developers.google.com/protocol-buffers/docs/news/2022-05-06#python-updates
というエラーが出てきたため
export PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python
とした。その結果をNETRONでみたものが以下

このjsonをから演算スケジュールを決定できるようにテンソルのメモリ配置などを決定するコンパイラを作っていきたい。
参考
既にIntel CPUやAMD GPU用にonnx runtimeを用いて実行する方法が多く解説され、ベンチマークが取られている。
ORTStableDiffusionXLPipelineをもちいてモデルを読み込む
各GPU向けの最適化とベンチマーク
独自実装したネットワークのONNXへのエクスポート
Discussion