Turing株式会社の自動運転・AIモデル開発チームの岩政(@colum2131)です。
Turingは2030年までに完全自動運転の達成を目指しており、自動運転AI開発から車両開発など、取り組むことは多岐に渡っています。
今回の話は、自動運転AI開発中に出た問題と、ひとまずの解決方法になります。より良い解決策があれば、教えてもらいたいです🙏
Transfomer-EncoderをONNXに変換したい
ONNX(Open Neural Network eXchange)は、機械学習・深層学習モデルを表現するために構築されたオープンフォーマットです。
PyTorchやTensorFlow、scikit-learnなどのフレームワークで学習されたモデルをONNXに変換することでサーバーやエッジデバイスなど多様なハードウェアで運用が可能です。各ハードウェアごとに最適化されたフォーマットにも変換可能であり、例えば、NVIDIAのGPU製品(Jetsonなど)においてTensorRTに変換することで比較的高速な推論が可能になります。
Turingでは、北海道自動運転1周を可能にした技術においてもONNXを活用しました。これにより、限られた計算リソースにおいても運用可能な低いレイテンシを達成することができました。
ONNXとは?
ONNXは、グラフのように表現されることがあります。ONNXグラフの各ノードはオペレータ(Operator)と呼ばれ、MatMul(行列積)やAdd(加算)などの操作がこれに相当します。

https://onnx.ai/onnx/intro/concepts.html
オペレータはopsetでバージョンを指定することができます。このopsetによって、変換できるオペレータやその機能が変わります。高いバージョンほど、単一のオペレータで複数の演算を組み合わせることができます。一方で、ハードウェアアクセラレータ側が、そのopsetに対応していない場合などの問題が発生する場合があります。
ONNXは、Netronというサービスでモデル構造を可視化することができます。例えば、2層のCNN→GlobalAveragePolling→1層のMLPの場合は以下のように可視化されます。

ONNXの詳細な情報は、公式ドキュメントやCyberAgentのONNXモデルのチューニングテクニック (基礎編)を参照してください。特に、「ONNXモデルのチューニングテクニック」は、ONNXモデルの基本的なところから、PINTOさんが公開されているチューニング用のライブラリの使用方法が書かれており、非常に勉強になりました。
ONNXモデルを生成する
PyTorchで構築したモデルをONNXモデルを生成する基本的なワークフローは、 torch.onnx.export を使用することです。
ここで必要な引数は以下の通りです。
- model…torchで生成されたモデル(
nn.Module) - args…入力するダミーの
torch.Tensor(複数入力の場合はTuple[torch.Tensor]) - f…出力ファイル名
- opset_version…opsetのバージョン(オペレータとの関係は公式ドキュメント)
- input_names…入力ノード名リスト
- output_names…出力ノード名リスト
import onnx
import torch
import torch.nn as nn
class SimpleCNN(nn.Module):
def __init__(self, num_classes=1000):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(
in_channels=3, out_channels=32, kernel_size=3, stride=1, padding=1
)
self.conv2 = nn.Conv2d(
in_channels=32, out_channels=64, kernel_size=3, stride=1, padding=1
)
self.relu = nn.ReLU()
self.global_avg_pool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(64, num_classes)
def forward(self, x):
x = self.relu(self.conv1(x))
x = self.relu(self.conv2(x))
x = self.global_avg_pool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
# 出力ファイル名
onnx_file = "simplecnn.onnx"
# モデルのインスタンスを作成
model = SimpleCNN(num_classes=1000)
dummy_input = torch.randn(1, 3, 224, 224)
output = model(dummy_input)
# ONNXモデルに生成
torch.onnx.export(
model=model, # モデルの指定
args=(torch.randn((1, 3, 224, 224))),
f=onnx_file, # 出力ファイル名
opset_version=17, # opsetのバージョン指定
input_names=["input_img"], # 入力ノード名
output_names=["output"], # 出力ノード名
)
これだけでもONNXモデルが生成できますが、不要なオペレータが含まれて効率的ではないモデルが生成されたり、中間出力されるテンソルのshapeが不明だったりします。
そのため、 onnx.shape_inference.infer_shapes を行って型の推定をすることや、onnx-simplifierの onnxsim.simplify を行ってより効率的なモデルに変換することができます。
from onnxsim import simplify
# 型の推定
model_onnx1 = onnx.load(onnx_file)
model_onnx1 = onnx.shape_inference.infer_shapes(model_onnx1)
onnx.save(model_onnx1, onnx_file)
# モデル構造の最適化
model_onnx2 = onnx.load(onnx_file)
model_simp, check = simplify(model_onnx2)
onnx.save(model_simp, onnx_fil
Transfomer-EncoderをONNXに変換したい!が…
ここまででPyTorchで構築したモデルをONNXモデルに変換することが可能になりました。本題のTransformer EncoderをONNXに変換します。
Transformerは、近年話題のLLM(大規模言語モデル)でも重要なアーキテクチャであり、BERTやGPTの言語モデル以外でも、画像認識に特化したVision Transformer(ViT)や、物体検出ではDETRというモデルに広く応用されています。
また、End-to-end自動運転モデルにおいても、Cross-Attentionと呼ばれる構造で、画像の2次元空間の特徴マップから3次元空間に変換する手法や、DETRの拡張した3次元物体検出にも応用されており、様々な分野で強く注目されています。
Transformerの構造に興味がある方は、はまなすなぎささんの「30分で完全理解するTransformerの世界」がおすすめで、30分では理解することが難しいほど非常に濃い内容が説明されています。
PyTorchには、TransformerEncoderとTransformerEncoderLayerが公式で提供されており、このクラスを用いることで簡単にTransformer Encoder(Decoderも)を実装することができます。
ではこちらで、シンプルに2層のTransformer EncoderモデルをONNXモデルに変換しましょう!今回は torch==2.0.1 で行います。
onnx_file = "transformerencoder_2layers.onnx"
encoder_layer = nn.TransformerEncoderLayer(d_model=128, nhead=2)
transformer_encoder = nn.TransformerEncoder(encoder_layer, num_layers=2)
torch.onnx.export(
model=transformer_encoder,
args=(torch.randn((1, 8, 128))),
f=onnx_file,
opset_version=17,
input_names=["input_img"],
output_names=["output"],
)
============= Diagnostic Run torch.onnx.export version 2.0.1+cu118 =============
verbose: False, log level: Level.ERROR
======================= 0 NONE 0 NOTE 0 WARNING 1 ERROR ========================
ERROR: missing-standard-symbolic-function
=========================================
Exporting the operator 'aten::unflatten' to ONNX opset version 17 is not supported. Please feel free to request support or submit a pull request on PyTorch GitHub: https://github.com/pytorch/pytorch/issues.
None
<Set verbose=True to see more details>
...
UnsupportedOperatorError: Exporting the operator 'aten::unflatten' to ONNX opset version 17 is not supported. Please feel free to request support or submit a pull request on PyTorch GitHub: https://github.com/pytorch/pytorch/issues.
できない。opsetのバージョンを変えても変換できません。
どうやら aten::unflatten というオペレータがONNXのおいてサポートされていないことが原因のようで、根本的な原因は、おそらくPyTorchのMultiheadAttentionに原因がありそうでした。
この件については、PyTorchのissueにも上がっており、unflattenに対するcustom operatorを追加することや、PyTorchの2.0以降で発生するためダウングレードすることで解決するそうです。
ただ、Transformer Encoderは基本的なオペレータのみで実装できるはずなので、スクラッチで書けばONNXに変換できるかもしれません。
Transformer Encoderをスクラッチで書く
ということで書きましょう。以下、TransformerEncoderとTransformerEncoderLayerです。
from typing import Callable, Dict, List, Optional, Tuple
import copy
import torch
import torch.nn as nn
import torch.nn.functional as F
class ScaledDotProductAttention(nn.Module):
def __init__(self, dropout: float = 0.1):
super(ScaledDotProductAttention, self).__init__()
self.dropout = nn.Dropout(dropout)
def forward(
self,
query: torch.Tensor,
key: torch.Tensor,
value: torch.Tensor,
mask: torch.Tensor = None,
) -> Tuple[torch.Tensor, torch.Tensor]:
d_k = query.size(-1)
scores = torch.matmul(query, key.transpose(-2, -1)) / (d_k**0.5)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = F.softmax(scores, dim=-1)
p_attn = self.dropout(p_attn)
out = torch.matmul(p_attn, value)
return out, p_attn
class MultiHeadAttention(nn.Module):
def __init__(self, d_model: torch.Tensor, num_heads: int, dropout: float = 0.1):
super(MultiHeadAttention, self).__init__()
assert d_model % num_heads == 0
self.d_k = d_model // num_heads
self.h = num_heads
self.weight_query = nn.Linear(d_model, d_model, bias=False)
self.weight_key = nn.Linear(d_model, d_model, bias=False)
self.weight_value = nn.Linear(d_model, d_model, bias=False)
self.attention = ScaledDotProductAttention(dropout=dropout)
self.weight_output = nn.Sequential(
nn.Linear(d_model, d_model), nn.Dropout(dropout)
)
def forward(
self,
query: torch.Tensor,
key: torch.Tensor,
value: torch.Tensor,
mask: Optional[torch.Tensor] = None,
) -> torch.Tensor:
batch_size = query.size(0)
if mask is not None:
mask = mask.unsqueeze(1)
query = self.weight_query(query)
key = self.weight_key(key)
value = self.weight_value(value)
query = query.view(batch_size, -1, self.h, self.d_k).transpose(1, 2)
key = key.view(batch_size, -1, self.h, self.d_k).transpose(1, 2)
value = value.view(batch_size, -1, self.h, self.d_k).transpose(1, 2)
x, _ = self.attention(query, key, value, mask=mask)
x = x.transpose(1, 2).contiguous().view(batch_size, -1, self.h * self.d_k)
x = self.weight_output(x)
return x
class CustomTransformerEncoderLayer(nn.Module):
def __init__(
self,
d_model: int,
nhead: int,
dim_feedforward: int = 2048,
dropout: float = 0.1,
layer_norm_eps: float = 1e-6,
norm_first: bool = False,
):
super(TransformerEncoderLayer, self).__init__()
self.d_model = d_model
self.norm_first = norm_first
# Self Attention
self.self_attn = MultiHeadAttention(d_model, nhead, dropout=dropout)
# Position-wise Feed-Forward Networks
self.ffn = nn.Sequential(
nn.Linear(d_model, dim_feedforward),
nn.ReLU(inplace=True),
nn.Dropout(dropout),
nn.Linear(dim_feedforward, d_model),
)
self.norm1 = nn.LayerNorm(d_model, eps=layer_norm_eps)
self.norm2 = nn.LayerNorm(d_model, eps=layer_norm_eps)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
def forward(self, src: torch.Tensor, src_mask=None) -> torch.Tensor:
if self.norm_first:
src2 = self.norm1(src)
src2 = self.self_attn(src2, src2, src2, mask=src_mask)
else:
src2 = self.self_attn(src, src, src, mask=src_mask)
src = src + self.dropout1(src2)
if self.norm_first:
src2 = self.norm2(src)
src2 = self.ffn(src2)
else:
src = self.norm1(src)
src2 = self.ffn(src)
src = src + self.dropout2(src2)
if not self.norm_first:
src = self.norm2(src)
return src
class CustomTransformerEncoder(nn.Module):
def __init__(self, encoder_layer: nn.Module, num_layers: int):
super(CustomTransformerEncoder, self).__init__()
self.layers = nn.ModuleList([copy.deepcopy(encoder_layer) for _ in range(num_layers)])
def forward(self, src: torch.Tensor, mask=None) -> torch.Tensor:
output = src
for layer in self.layers:
output = layer(output, src_mask=mask)
return output
これで先ほど同様にONNXモデルに変換します。
onnx_file = f"custom_transformerencoder.onnx"
encoder_layer = CustomTransformerEncoderLayer(d_model=128, nhead=2)
transformer_encoder = CustomTransformerEncoder(encoder_layer, num_layers=2)
torch.onnx.export(
model=transformer_encoder,
args=(torch.randn((1, 8, 128))),
f=onnx_file,
opset_version=17,
input_names=["input_img"],
output_names=["output"],
)
model_onnx1 = onnx.load(onnx_file)
model_onnx1 = onnx.shape_inference.infer_shapes(model_onnx1)
onnx.save(model_onnx1, onnx_file)
model_onnx2 = onnx.load(onnx_file)
model_simp, check = simplify(model_onnx2)
onnx.save(model_simp, onnx_file)
すると、無事ONNXモデルを生成することができました!
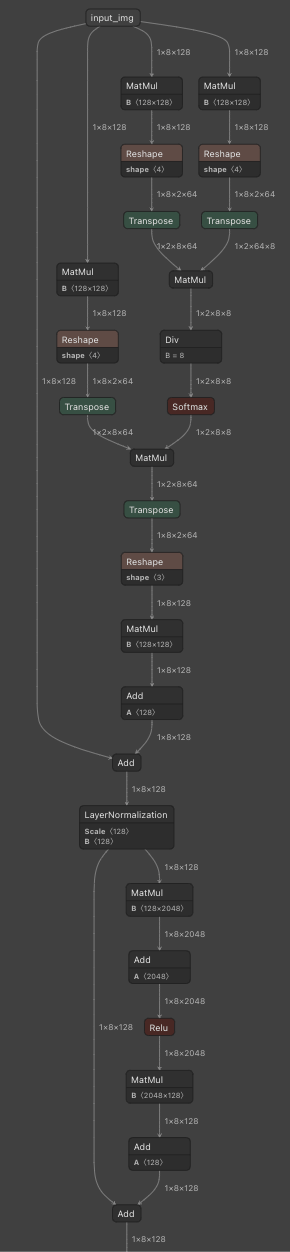
おわりに
今回はTransformer Encoderをスクラッチで書くことで解決しましたが、より良い解決方法があるかもしれません。Transformer構造を導入して、エッジに実装するケースはそこそこありそうなものの、クリティカルな回答はあまりないような感じでした。もし知っている方がいたら教えてもらえると嬉しいです🙌

Discussion
aten::unflattenはこのコミットで追加されました。
Pytorch Stableの2.1を試したら、問題なく動いています。
多分ころんびあさんのPytorchは2.0かもしれません。
pip3 install -U torch torchvision torchaudiogit clone 'https://github.com/pytorch/pytorch.git'
git log --graph | grep -C 10 'aten::unflatten'
うおおお!ありがとうございます!!
試してみますー!(2.1が来ていることに気がついていませんでした😇)