減点法で考えるBM25
今回はBM25の式の意味について、「求めていなそうなドキュメントにスコアを与えない」という視点で解説します。
BM25は検索を確率論の考えをベースに考案されています。BM25の式は各ドキュメントがユーザーが求めた物である確率からさまざまな仮定を加えて近似や式変形を施した値になります。
しかし今回はこのアプローチによる説明はしません(以前書いています)。というのもこの式の特性や加えられた仮定を考えるとBM25は「求めた物である確率が高いドキュメントにスコア与える」というより「求めていないドキュメントが紛れ込む可能性を推測し、それらにスコアを与えない」手法だと考えた方がより明確に理解できるのではないかと思っているためです。
この記事ではTF成分とIDFについて「求めていなそうなドキュメント」にどう対処しているかにフォーカスして説明していきます。
TF成分: 単語が出現しない「無関係そうなドキュメント」を減点する
TF成分では検索キーワードに指定された単語をテーマとしていないドキュメントが減点されます。まず前回の各単語
右側のTF成分

出現回数が少ないうちは出現回数の差により大きくスコアが増加する一方で、出現回数が多い場合は出現回数がさらに高くても頭打ちになってほぼ増加しない事がわかります。
その結果として検索順位が上位のドキュメント同士の比較では、あるキーワードの出現回数がどんなに多くても出現しないキーワードがあるドキュメントは大きく減点され、上位争いから落とされてしまいます。つまりBM25は減点されないドキュメントを重視するわけです。
BM25と従来のTF-IDFの違い
従来のTF-IDFではTF成分として出現回数がそのまま使われたりlogが使われたりしていました。TF成分に出現回数やlogを使うと、特定の単語の出現回数が極端に高かったり長いドキュメントが上位に来る傾向がありました。
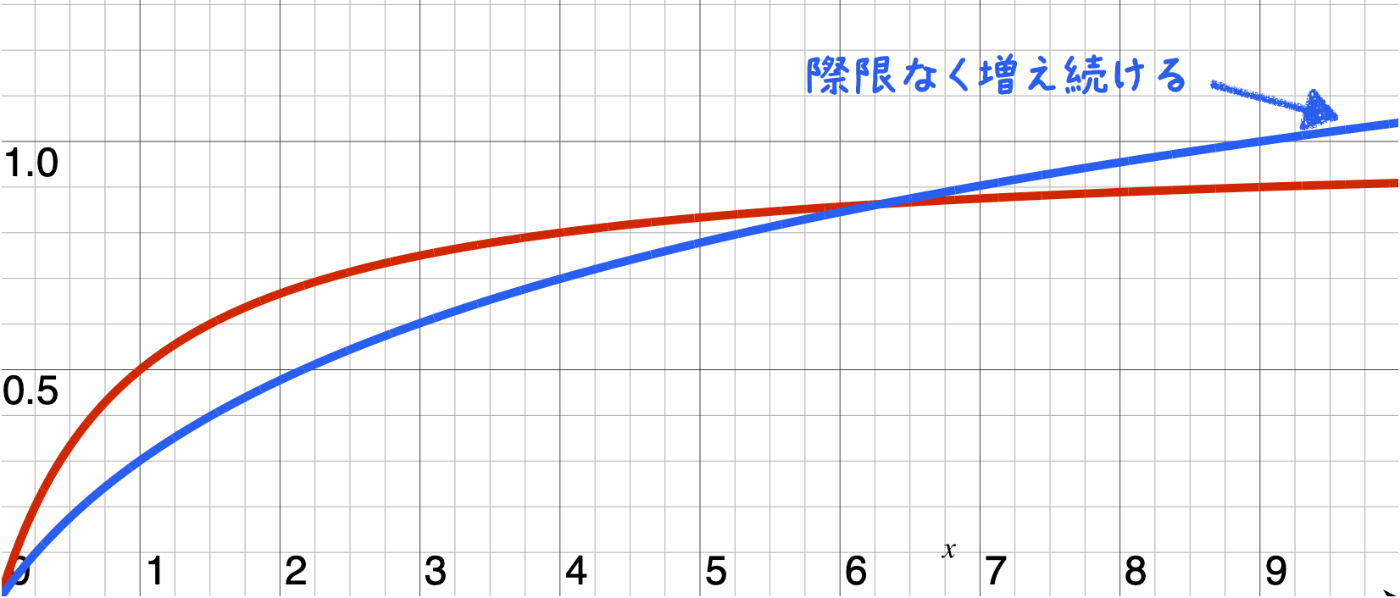
BM25ではスコアに上限があり、また長い文章ではスコアが上がりにくくなるので、上記の問題が比較的起こりにくいです。
つまり従来のTF-IDFと比較しても、加点が抑制された減点の意味合いが強い手法といえます。
TF成分の確率的意味
TF成分の意味について軽く解説します。
TF成分は「
例えば
ただしBM25ではタグのような仮定ではなく、2ポワソンモデルという仮定で値を計算しています[1]。2ポワソンモデルの詳細はここでは省きますが、「
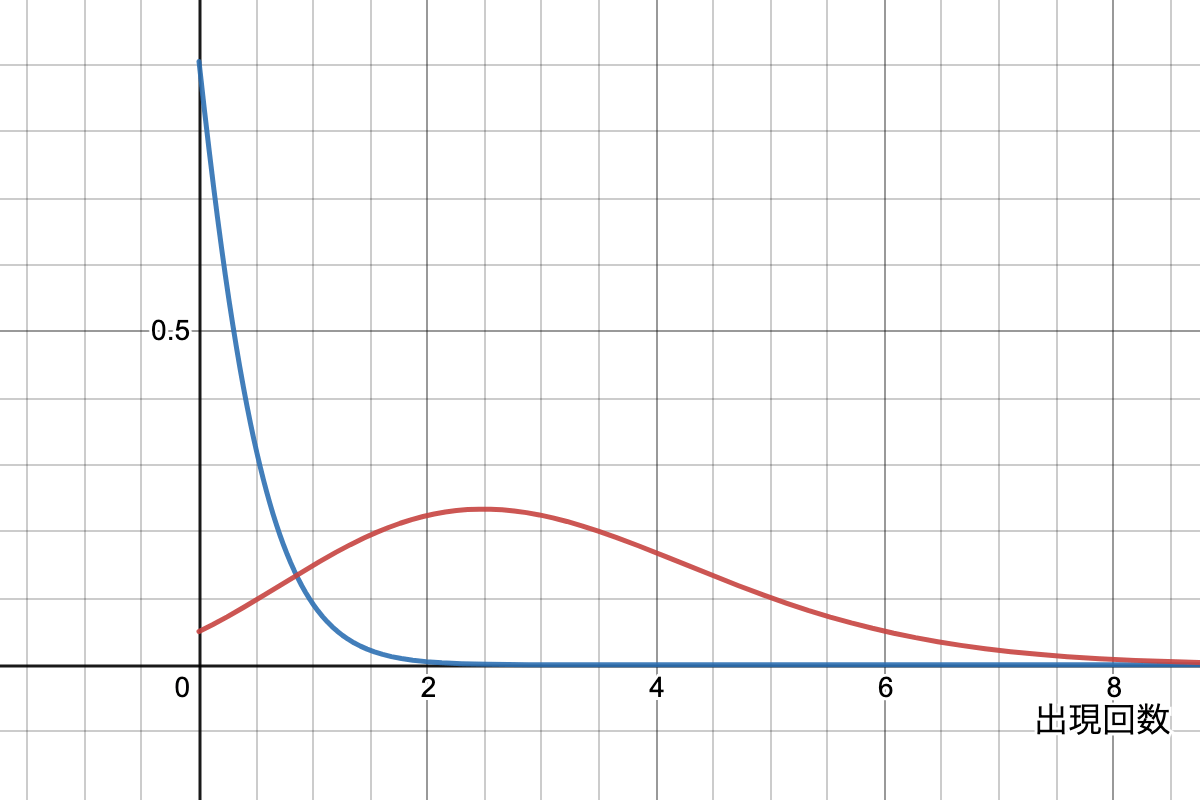
赤色 …
2ポワソンモデルの詳細については以前記事を書きましたので、詳しく知りたい方は読んでもらえると嬉しいです。
IDF: 求めていなそうなドキュメントでも使われる単語の配点を減らす
もう一方の要素であるIDFでは、「その単語で絞り込んだ場合に求めていないドキュメントが混ざってしまうリスク」を見積り、その単語の配点を減らす事になります。こちらの式をもう一度見てみましょう。
IDFは

これを踏まえて「餃子 店」という検索キーワードの配点を考えてみます。
この検索で餃子店のドキュメントが出てくればベストですが、それがない場合「餃子」か「店」のドキュメントが上位に出てくる事になります。一般的な検索エンジンの場合、餃子の方が店よりもドキュメント数が少ないため、餃子のIDFの方が高くなり、結果的に餃子のドキュメントが上位に上がってきます。
これは以下の理由により合理的だと考えられると思います。
-
店のドキュメントを上位にあげる … 他の料理店だけでなく料理以外の店などの無関係なドキュメントが沢山上位に来てしまう。 -
餃子のドキュメントを上位に上げる … 無関係でもテーマの種類はレシピなどに限られる。
つまり、
「たくさんの文章に出てくる単語」
→ 様々なテーマで使われる
→ ユーザーが求めていなそうなドキュメントを拾ってしまう可能性も高い
→ 配点(IDF)を減らす
という事になります。
補足: IDFの確率論的背景
IDFの理論的背景については以前も書いたのですが、今回は「求めていなそうなドキュメント」にフォーカスして説明をします。
IDFの元となる数値は対数オッズ比と呼ばれるもので、薬の効果を調べる場合などに使われる値です。IDFでは「キーワード
条件を満たすドキュメント数を
|
|
|
合計 | |
|---|---|---|---|
| 求めた物 | |||
| 求めた物と違う | |||
| 合計 |
このオッズ比は以下のようになります。無相関の場合は0で、キーワードで絞り込んだ場合に欲しいドキュメントがより得られるようになると数値が大きくなります。
これだと「求めているドキュメント」の数を出す必要が出てくるのですが、BM25ではこれを無視し、求めていないドキュメントだけを比較します。
さらに「求めているドキュメント」は全体からすると極めて少ないと仮定すると、
となりますが、これはIDFの式と同じものです。先ほどの式と比べると+0.5や1+といった調整が消えていますが、これはマッチ数が0だったり全てのドキュメント数だったりした場合に計算できなくなるのを防ぐ調整です。
BM25は検索の意図を補完してはくれない
一方、ドキュメント数が多くてもキーワードが重要なケースもあります。例えば「餃子 店」で検索した場合だと単にお店を探しているケースが多いと考えられ、その場合餃子よりも店の方が上位に上がってきた方が良いでしょう。しかしBM25はこういった検索の背景にある意図を汲み取って優先してくれたりはしません。
こういった意図を反映したい場合は検索キーワードを補完したりスコアリングを調整するなど別の手段を取り入れる必要があるでしょう。
まとめ
ということで、BM25で使われるTF成分とIDFについて「求めていなそうなドキュメントにスコアを与えない」という減点法による視点で解説しました。
次回(こそ)BM25を使ってわかった特性やクセについて紹介し、スコアを調整する際に役立つTipsを紹介しようと思います。
-
パラメーターを調整して
s
Discussion