自分好みのMCPサーバーをPythonで気軽に作ってみる
MCPが世間の話題をかっさらってから少し時間が経ってきて、「MCPとは何かは分かったけど、実際にMCPサーバーを自分で作る方法はよく分からない、ハードルが高い、、」という方は多いのではないでしょうか。
この記事では、「自分でも気軽にMCPサーバーを作れるようになりたい」「自分好みのMCPを作って、CursorやCline, Claudeで使えるようにしたい」という方向けに、Pythonを使って、ゼロからMCPサーバーを立ててLLMで利用するまでの流れをまとめてみました。
この記事で目指すこと
サンプル機能として、PCのローカルフォルダの中に含まれるファイルからRAGを構築して、それらのローカルファイルに基づいた質問応答ができるMCPサーバーを実装します。
環境の構築方法も含めて紹介して、みなさんが今後自分なりのMCPサーバーを手軽に作れるようになることをゴールとしています。
MCPとは何か?については多くの良質な記事がでているため、そちらをお読みください。
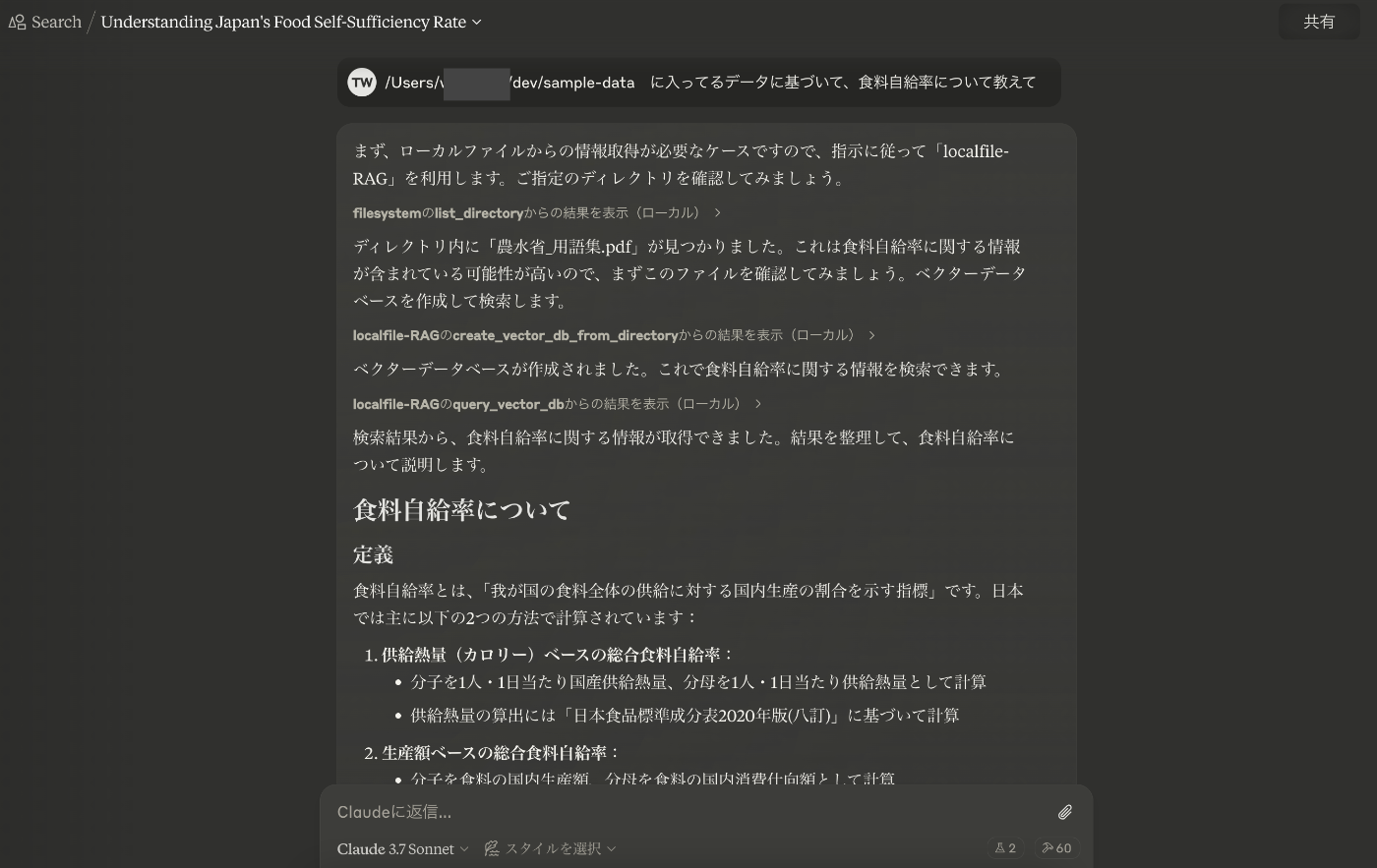
自作MCPの利用イメージ
ローカルフォルダに格納しているPDFをもとに、質問に応答してくれています。
自分が気になった情報を集約しておけば、それらに基づいた質問応答を実現できます。
リポジトリ
とりあえずここで紹介されているMCPをそのまま使ってみたいという方は、こちらのREADMEに沿って実行すれば使えるかと思います。
MCPサーバーの作成手順
環境準備
MCPの実装ではuvというパッケージ管理ツールの利用が推奨されているため、インストールします。
https://docs.astral.sh/uv/#highlights
macの場合は下記コマンドでインストール可能です。
curl -LsSf https://astral.sh/uv/install.sh | sh
uvを利用してプロジェクトを初期化して、仮想環境を作成します。
uv init mcp-test-server
cd mcp-test-server
uv venv .venv
source .venv/bin/activate
必要なパッケージをインストールして、サーバーの処理を記載するserver.pyを作成。
このあとの機能実装で追加のパッケージが必要になった場合は、都度uv addで追加します。
uv add "mcp[cli]"
touch server.py
機能実装
ただの掛け算を行うだけのツールを実装する場合の最小コード例は下記の通りです。
from mcp.server.fastmcp import FastMCP
# FastMCPサーバを初期化
mcp = FastMCP("test")
# ツールを定義。型ヒントやdocstringをきちんと記載する必要がある。
@mcp.tool()
def multiple(a: int, b: int) -> int:
"""
二つの整数を受け取り、それらの積を返す関数。
Args:
a (int): 最初の整数
b (int): 二つ目の整数
Returns:
int: 掛け算の結果
"""
return a * b
# 実行処理
if __name__ == "__main__":
mcp.run(transport="stdio")
@mcp.toolを定義することで、LLMなどのMCPクライアントが利用できるツールを定義できます。MCPサーバーにはこのtoolの他にもpromptやresourceといった機能がありますが、ここでは扱いません。下記記事などを参考にしてください。
それでは、今回実装したい、「ローカルファイルをもとにRAGを実行するMCPサーバー」の処理を実装します。
ここでは、OpenAI APIを用いて、ファイルのアップロード・ベクトルDBの構築・検索による関連文書抽出まで実施しています。
この詳細な実装方法については、趣旨から外れるため詳しくは説明しませんが、ツールとしてはcreate_vector_db_from_directoryとquery_vector_dbの2つの関数を定義しています。
-
create_vector_db_from_directory: フォルダを指定して、そこに含まれるファイルからベクトルDBを作成する。すでに作成済みのベクトルDBと同じ内容である場合は、作成済みのDBを返す -
query_vector_db: ベクトルDBに対して、クエリを投入したときに類似度の高い文書をスコアとともに返す。
MCP特有の記法はほとんどないため、下記をサンプルとしてLLMに与えれば、みなさんの思い思いの処理を実現する関数を実装することは比較的簡単かと思います。
MCPクライアントによる各関数の利用判定は、それぞれの関数の型ヒントやdocstringからなされるため、LLMに手伝ってもらうなりしてきちんと記載しましょう。
import os
import glob
from typing import List, Dict, Any
from mcp.server.fastmcp import FastMCP
from openai import OpenAI
from dotenv import load_dotenv
# .envファイルを読み込む
load_dotenv()
# FastMCPサーバを初期化
mcp = FastMCP("test")
# OpenAIクライアントを初期化
client = OpenAI()
@mcp.tool()
def create_vector_db_from_directory(
directory_path: str,
vector_store_name: str = "local_knowledge",
file_patterns: List[str] = ["*.txt", "*.pdf", "*.docx", "*.md"],
) -> Dict[str, Any]:
"""
指定したディレクトリ内のファイルからベクトルDBを作成する。
すでに同じファイルセットを持つベクトルストアが存在すれば、それを再利用する。
Args:
directory_path (str): ファイルを検索するディレクトリのパス
vector_store_name (str, optional): ベクトルストアの名前。デフォルトは "local_knowledge"
file_patterns (List[str], optional): 処理するファイルのパターン。デフォルトは ["*.txt", "*.pdf", "*.docx", "*.md"]
Returns:
Dict[str, Any]: 処理結果の情報
"""
# ファイルの取得
files = get_files_from_directory(directory_path, file_patterns)
if not files:
return {
"status": "error",
"message": f"指定したディレクトリ '{directory_path}' にパターン {file_patterns} に一致するファイルが見つかりませんでした。",
}
# ファイル名のリストを取得
file_names = set(os.path.basename(file) for file in files)
print(f"file_names:{file_names}")
# 既存のベクトルストア一覧を取得
try:
vector_stores = client.vector_stores.list()
# OpenAIにアップされているファイル一覧を取得し、file_id → filename のマッピングを作成
all_files = client.files.list()
file_id_to_name = {f.id: f.filename for f in all_files.data}
for vs in vector_stores.data:
vector_store_id = vs.id
# それぞれのベクトルストアに含まれるファイルID一覧を取得して、ファイル名に変換
vector_store_files = client.vector_stores.files.list(vector_store_id=vector_store_id)
existing_files = {file_id_to_name[f.id] for f in vector_store_files.data if f.id in file_id_to_name}
# 現在のファイルセットと比較(完全一致するか)
if file_names == existing_files:
print(f"既存のベクトルストアを再利用: {vector_store_id}")
return {
"status": "success",
"message": f"既存のベクトルストア '{vector_store_id}' を使用しました。",
"vector_store_id": vector_store_id,
}
except Exception as e:
print(f"ベクトルストアの取得中にエラーが発生しました: {e}")
# 一致するベクトルストアがない場合、新規作成
vector_store_id = create_vector_store(vector_store_name)
# 処理結果の統計情報
stats = {
"total_files": len(files),
"processed_files": 0,
"failed_files": 0,
"vector_store_id": vector_store_id,
"vector_store_name": vector_store_name,
"file_ids": [],
}
# 各ファイルを処理
for file_path in files:
try:
# ファイルをアップロード
file_id = create_file(file_path)
# ベクトルストアにファイルを追加
add_file_to_vector_store(vector_store_id, file_id)
stats["processed_files"] += 1
stats["file_ids"].append(file_id)
except Exception as e:
stats["failed_files"] += 1
return {
"status": "success",
"message": f"{stats['processed_files']}個のファイルを処理し、ベクトルDBに追加しました。",
"stats": stats,
}
@mcp.tool()
def query_vector_db(query: str, vector_store_id: str, n_results: int = 10) -> Dict[str, Any]:
"""
構築した内部知識DBを検索することで、情報を抽出する。
Args:
query (str): 検索クエリ
vector_store_id (str): ベクトルストアのID
n_results (int, optional): 返す結果の数。デフォルトは10
Returns:
Dict[str, Any]: 検索結果
"""
try:
# ベクトルストアを検索して、類似度の高いテキストを抽出
results = client.vector_stores.search(vector_store_id=vector_store_id, query=query, max_num_results=n_results)
# 結果を整形
formatted_results = []
if hasattr(results, "data") and results.data:
for i, item in enumerate(results.data):
result = {
"rank": i + 1,
"score": item.score,
"text": "\n".join(c.text for c in item.content),
"file_name": item.filename,
}
formatted_results.append(result)
return {"status": "success", "query": query, "results": formatted_results}
except Exception as e:
return {"status": "error", "message": f"クエリの実行中にエラーが発生しました: {e}"}
ヘルパー関数の実装
def get_files_from_directory(
directory_path: str, file_patterns: List[str] = ["*.txt", "*.pdf", "*.docx", "*.md"]
) -> List[str]:
"""
指定したディレクトリ内のファイルを取得する関数
"""
all_files = []
for pattern in file_patterns:
files = glob.glob(os.path.join(directory_path, "**", pattern), recursive=True)
all_files.extend(files)
return all_files
def create_file(file_path: str):
"""
指定したローカルのパスからファイルをアップロードする関数
"""
# ローカルファイルを開いてアップロードする
with open(file_path, "rb") as f:
result = client.files.create(file=f, purpose="assistants")
print(f"ファイル作成完了: {result.id}")
return result.id
def create_vector_store(name: str = "local_knowledge"):
"""
ベクトルストアを作成する関数
"""
vector_store = client.vector_stores.create(name=name)
return vector_store.id
def add_file_to_vector_store(vector_store_id: str, file_id: str):
"""
ベクトルストアにファイルを追加する関数
"""
result = client.vector_stores.files.create(vector_store_id=vector_store_id, file_id=file_id)
return result
最後に、サーバーの起動処理を記載します。
if __name__ == "__main__":
mcp.run(transport="stdio")
テスト
いちいちClaudeアプリなどで作ったMCPサーバーのデバッグを行うのは面倒であるため、公式に用意されているMCP Inspectorという便利ツールを利用します。
下記を実行すると、localで動作確認用画面が立ち上がります。
npx @modelcontextprotocol/inspector uv run server.py

テスト手順
- 左ペインで”Connect”を選択
- 中央のタブで”Tools”を選択
- ”List Tools”を実行
- 検証したいツールを選択
- 右ペインで引数を設定して”Run Tool”を実行
- うまく実行されれば、応答内容がResultに表示される(unicodeエスケープされているため、適宜decodeして確認する)
- 終了後は、CLIでInspectorの実行を終了
MCPクライアントの設定
以下では、Claudeデスクトップアプリ(Mac)の場合の例を紹介します。
- Claudeアプリの設定画面→開発者から「設定を編集」をクリック
- 表示されるclaude_desktop_config.jsonをエディタで開く
- 下記のコードを入力(他のMCPサーバー設定がある場合は追記)
{ "mcpServers": { "localfile-RAG": { "command": "uv", "args": [ "--directory", "/ABSOLUTE/PATH/TO/PARENT/FOLDER/mcp-test-server", "run", "server.py" ] } } }
- Claudeアプリを再起動
- エラー画面がでなければ、MCPサーバーの設定完了
おわりに
この記事では、ローカルファイルについてRAGを行う自作MCPサーバーについて、Pythonでの実装方法を紹介しました。この手順に沿うことで、みなさんの思い思いの処理をMCPサーバーとして実装して、LLMに活用してもらえるようになるかと思います。
記事の内容に関して、分からないこと・気になることなどあればお気軽にコメントいただければと思います!
Discussion